




点击关注公众号,干货第一时间送达

上篇文章:Hadoop 系列(三)配置 JDK 和 Hadoop
小编演示了如何配置 Jdk 和 Hadoop 环境变量。
其中,先需要上传包,然后再写配置文件。
这只是在 hadoop102 一台虚拟机上的操作,
我们还有 hadoop103,hadoop104两台机器,勉强可以再在这两台机器上再操作两遍。
但是,如果有几十台,上百台机器呢?
总不能分别在各个机器上,上传文件,再配置环境变量吧?
岂不是,太太太太太太麻烦了!!!
所以,我们需要写一个方便操作的脚本,能够支持我们,
只需要上传一次文件,只配置一次环境变量,然后通过脚本分发,其他机器也能同步相同的文件,和配置。
岂不是,美滋滋!!!
(写分发脚本前,需要先介绍了两个 linux 自带的同步文件指令,scp 和 rsync。如果想直接看脚本的小伙伴,可以直接跳转到第三步骤)
一、scp 命令介绍
scp (secure copy)安全拷贝,可以实现服务器与服务器之间的数据拷贝。
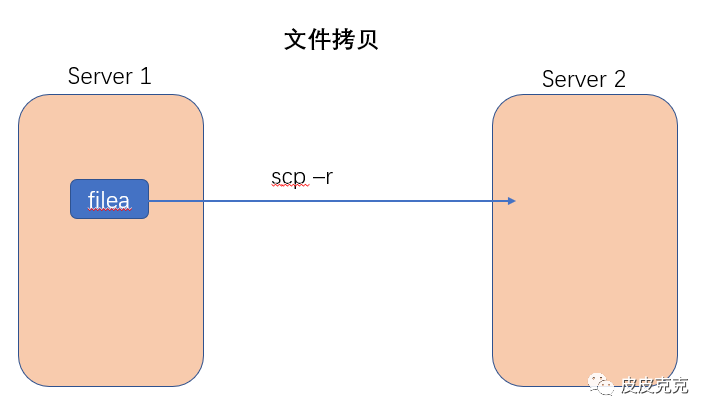
1,语法
scp -r pdir/fname user@host:pdir/fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
2,实操
(友情提示:下面的操作,因为小编之前已经配置过 SSH 免密登录,所以不需要输入密码,如遇到需要输入密码情况的小伙伴,可以翻看小编之前的文章:Hadoop 系列(二)SSH 免密登录,进行配置即可)
前提准备:在 /home/jack/opt/software/testdir 目录下,新建文件 a.txt,用于测试
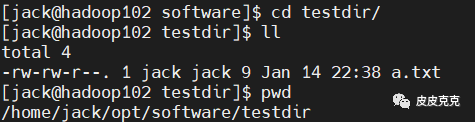
2.1 在 hadoop102 上,将 hadoop102 中 /home/jack/opt/software/testdir 目录拷贝到 hadoop103 上
[jack@hadoop102 software]$ scp -r testdir/ jack@hadoop103:/home/jack/opt/module
查看 hadoop103 的 路径:/home/jack/opt/module/testdir
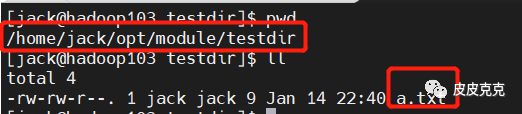
2.2 在 hadoop103 上,将 hadoop102 中 /home/jack/opt/software/testdir 目录拷贝到 hadoop103 上 (友情提示:记得把刚才测试生成的文件删除)
[jack@hadoop103 module]$ scp -r jack@hadoop102:/home/jack/opt/software/testdir ./
查看 hadoop103 的 路径:/home/jack/opt/module/testdir
这次不用贴图了吧
2.3 在 hadoop104 上,将 hadoop102 中 /home/jack/opt/software/testdir 目录拷贝到 hadoop103 上 (友情提示:记得把刚才测试生成的文件删除)
[jack@hadoop104 ~]$ scp -r jack@hadoop102:/home/jack/opt/software/testdir jack@hadoop103:/home/jack/opt/module/
能看出端倪不?
看出来的都是小可爱!送你一朵小红花
scp 命令介绍完了,再介绍一个 rsync 命令。
二、rsync 命令介绍
rsync 远程同步工具,主要用于备份和镜像。具有速度快、避免复制相同和支持符合链接的优点。
rsync 和 scp 的区别:
用 rsync 做文件的复制要比 scp 速度快,rsync 只对差异文件更新;
而 scp 是把文件都复制过去了。
1,语法
rsync -av pdir/fname user@hostname:pdir/fname
命令 参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
参数说明:
-a 归档拷贝
-v 显示复制过程
2,实操
(通过上面 scp 的颜色,我们在 hadoop102 testdir 目录下已有 a.txt 文件,并且 hadoop103 testdir 路径下,也有该文件)
前提准备:
先在 hadoop102 testdir 目录下再新增个 b.txt 文件,使用 rsync 命令做同步
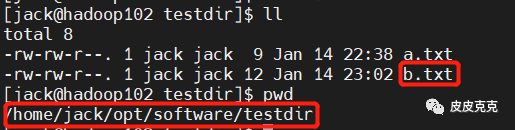
执行:
[jack@hadoop102 software]$ rsync -av testdir/ jack@hadoop103:/home/jack/opt/module/testdir

验证:
然后去hadoop103对应路径下,查看新增的 b.txt 的时间,明显和 a.txt 不是一起的。

结论:本次执行 rsync 只是同步了 hadoop102 和 hadoop103 两个路径下差异的文件,不是 scp 那样的全面复制。所以可知,rsync 的执行速度会比 scp 高快,也是比 scp 更常用的命令。
然后,终于来到我们要介绍的 xsync 文件分发脚本
这个脚本不是 linux 自带的,不是 scp、rsync 那种。
需要我们自己写 shell 脚本。
不难
三、xsync 集群分发脚本命令编写
1,查看 PATH 环境变量,进入其中
[jack@hadoop102 ~]$ echo $PATH

可以看到,/home/jack/bin 路径存在 PATH 环境配置中,所以我们需要把 xsync 脚本写在该路径下,这样执行后,就可以全局生效了,不用再单独配置环境变量。
2,新增脚本文件
#!/bin/bash
#1,判断参数
if [ $# -lt 1 ]
then
ehco Not Enough Arguments!
exit;
fi
#2,变量集群节点,当前只有三台主机,后面增加主机后,在该处修改即可
for host in hadoop102 hadoop103 hadoop104
do
echo ===================== $host ========================
#3,遍历所有目录,挨个发送
for file in $@
do
#4, 判断文件是否存在
if [ -e $file ]
then
#5,获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6,获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
#7,使用 rsync 命令,真正执行文件同步
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
3,修改脚本文件权限
[jack@hadoop102 bin]$ chmod 777 xsync

xsync 文件变为可执行文件
4,验证
hadoop102:/home/jack/opt/software

hadoop103:/home/jack/opt/software

hadoop104:/home/jack/opt/software
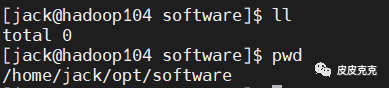
3台主机,相同路径下。
在 hadoop102 执行集群分发命令,把 testdir 目录及目录下文件分发给各个节点:
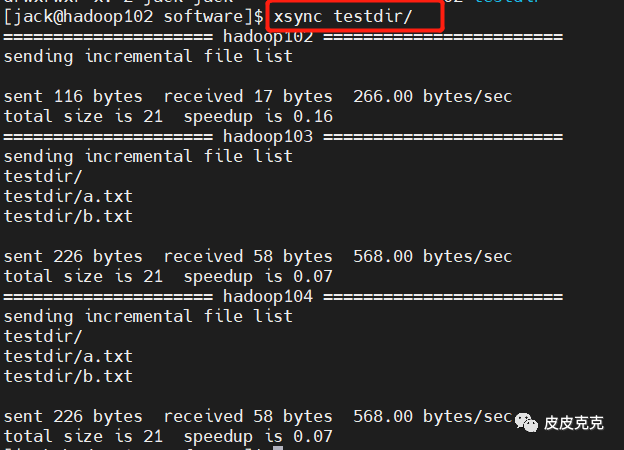
然后查看 hadoop103,hadoop104 对应路径下:
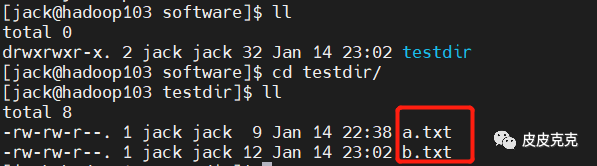
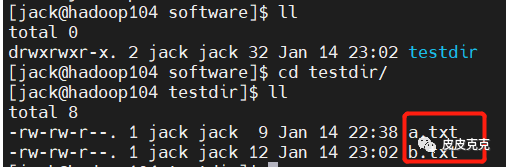
即表示文件集群分发成功
简单吧?

