




Chroma 是一个开源的嵌入式数据库,通过使知识、事实和技能可以插入到 LLM 中,从而轻松构建 LLM 应用程序。这里可以了解它的工作原理。
翻译自 Exploring Chroma: The Open Source Vector Database for LLMs 。
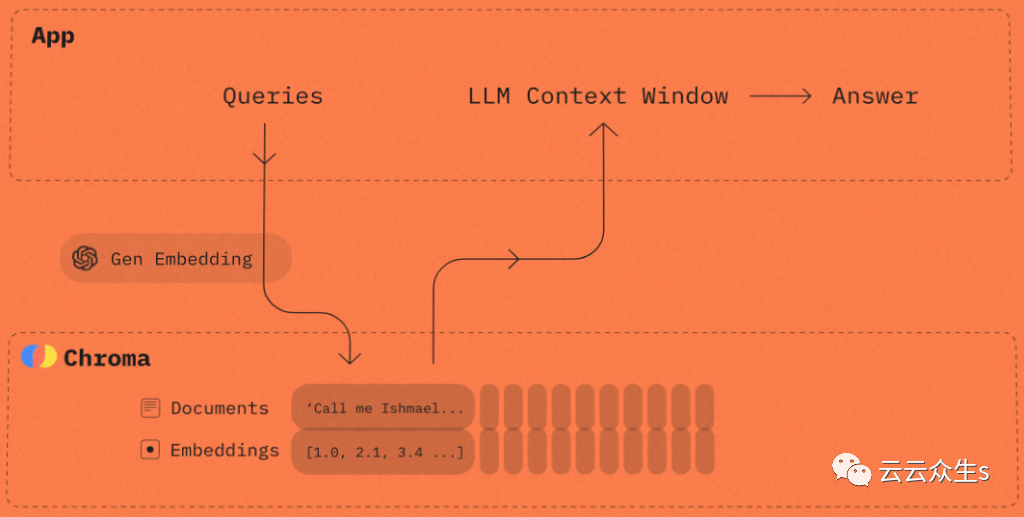
大型语言模型的崛起加速了存储词嵌入的向量数据库的采用。
向量数据库以向量形式存储数据,充分利用了先进的机器学习算法的潜力。它实现了高度高效的相似性搜索,这对于包括推荐系统、图像识别和自然语言处理在内的人工智能应用至关重要。
在向量数据库中,每个存储的数据点都被表示为多维向量,捕捉了复杂数据的本质。高级索引方法,如 k-d 树或哈希,有助于快速检索相似的向量。这种架构为数据密集型行业创造了高度可扩展且高效的解决方案,改变了我们处理大数据分析的方式。
在本文中,我们将更详细地介绍 Chroma ,一个轻量级的开源向量数据库。
Chroma 概述
Chroma 可用于 Python 或 JavaScript 代码以生成词嵌入。它具有一个简单的 API ,可用于针对在内存中或客户端/服务器模式下运行的数据库后端。开发人员可以安装 Chroma ,使用 Jupyter Notebook 中的 API 进行原型设计,然后在生产环境中使用相同的代码,该环境可以在客户端/服务器模式下运行数据库。
在内存中运行时,Chroma 数据库集合可以保存为 Apache Parquet 格式的磁盘文件。由于生成词嵌入是一项昂贵的任务,将它们保存以便稍后检索可以降低成本和性能开销。
现在,让我们来看看 Chroma 向量数据库的运作方式。
通过 Python 使用 Chroma
使用 Chroma 的第一步是通过 pip 安装。
一旦安装完成,您可以将该模块导入到您的代码中。
现在,让我们创建一个字符串列表,我们将对其进行编码以生成嵌入。
phrases = ["Amanda baked cookies and will bring Jerry some tomorrow.","Olivia and Olivier are voting for liberals in this election.","Sam is confused, because he overheard Rick complaining about him as a roommate. Naomi thinks Sam should talk to Rick. Sam is not sure what to do.","John's cookies were only half-baked but he still carries them for Mary."]
我们还需要一个唯一标识上述字符串的字符串列表。
ids = ["001", "002", "003", "004"]
还可以为每个带有对原始来源的引用或指针的字符串关联附加的元数据。这是完全可选的。对于我们的教程,我们将添加一些虚拟元数据。这被构造为字典对象的列表。
metadatas = [{"source": "pdf-1"}, {"source": "doc-1"}, {"source": "pdf-2"}, {"source": "txt-1"}]
现在,我们拥有了可以存储在 Chroma 中的所有实体。让我们初始化客户端。
chroma_client = chromadb.Client()
如果您想将数据持久化到磁盘,可以将保存数据库的目录位置传递给它。
chroma_client = chromadb.PersistentClient(path="/path/to/save/to")
Chroma 将一组相关内容称为一个集合(collection)。每个集合都有文档,这只是一系列字符串,充当文档的唯一标识符的 ids ,以及可选的元数据。
嵌入是集合的重要组成部分。它们可以根据 Chroma 内部包含的词嵌入模型隐式生成,或者您可以基于 OpenA I、 PaLM 或 Cohere 的外部词嵌入模型生成它们。Chroma 使集成外部 API 以自动化生成嵌入并将其存储变得容易。我们将在本教程的下一部分更详细地探讨这个概念。
Chroma 默认使用 Sentence Transformers 的 all-MiniLM-L6-v2 模型创建嵌入。这个嵌入模型可以为各种任务生成句子和文档嵌入。这个嵌入函数在您的本地机器上运行,并可能需要下载模型文件,这将自动发生。
由于我们依赖于 Chroma 提供的内置词嵌入模型,所以我们只会摄取数据,并让 Chroma 自动为集合中的每个文档生成嵌入。
我们可以继续创建一个集合。
collection = chroma_client.create_collection(name="tns_tutorial")
现在,我们准备将文档插入集合。
collection.add(documents=phrases,metadatas=metadatas,ids=ids)
我们可以快速检查插入的文档是否生成了嵌入。
您应该会看到自动生成的嵌入已添加到集合的嵌入列表中。
现在,我们可以在集合上执行相似性搜索。让我们搜索与短语 “Mary got half-baked from John” 匹配的短语。请注意,它只与一个文档有相似的含义,但不是完全匹配。
results = collection.query(query_texts=["Mary got half-baked cake from John"],n_results=2)
当访问结果变量时,它的内容如下:
{'ids': [['004', '001']],'distances': [[0.4699302613735199, 1.333911657333374]],'metadatas': [[{'source': 'txt-1'}, {'source': 'pdf-1'}]],'embeddings': None,'documents': [["John's cookies were only half-baked but he still carries them for Mary.",'Amanda baked cookies and will bring Jerry some tomorrow.']]}
基于距离,列表中的第一个文档是一个完美匹配。我们现在可以直接访问元素以获取实际短语。嵌入元素为空,因为获取每个查询的嵌入是昂贵的。但在幕后,Chroma 正在执行余弦相似性搜索,该搜索基于存储为向量的嵌入。
print(results['documents'][0][0])
Chroma 数据库还支持基于元数据或 ids 进行查询。这使得根据文档的来源进行搜索非常方便。
results = collection.query(query_texts=["cookies"],where={"source": "pdf-1"},n_results=1)print(results)
上述查询首先执行相似性搜索,然后根据 where 条件过滤查询,该条件指定了元数据。
最后,让我们删除集合。
在本教程的下一部分中,预计将于下周发布,我们将扩展学院奖聊天机器人以使用 Chroma 向量数据库。敬请关注。
以下是您可以在自己的计算机上尝试的完整代码。
import chromadbphrases = ["Amanda baked cookies and will bring Jerry some tomorrow.","Olivia and Olivier are voting for liberals in this election.","Sam is confused, because he overheard Rick complaining about him as a roommate. Naomi thinks Sam should talk to Rick. Sam is not sure what to do.","John's cookies were only half-baked but he still carries them for Mary.",]ids = ["001", "002", "003", "004"]metadatas = [{"source": "pdf-1"}, {"source": "doc-1"}, {"source": "pdf-2"}, {"source": "txt-1"}]chroma_client = chromadb.Client()collection = chroma_client.get_or_create_collection(name="tns_tutorial")collection.add(documents=phrases,metadatas=metadatas,ids=ids)collection.peek()results = collection.query(query_texts=["Mary got half-baked cake from John"],n_results=2)print(results['documents'][0][0])results = collection.query(query_texts=["cookies"],where={"source": "pdf-1"},n_results=1)print(results)collection.delete()
