




百度数据仓库 Palo 是基于业内领先的 OLAP 数据库 Apache Doris 构建的 MPP 架构云数据仓库。数据仓库诞生之初是为了解决企业在信息化过程中面临的数据量激增、数据格式多样化以及决策需求提升等问题。从 20 世纪 70 年代由麻省理工学院的研究员提出将业务处理系统和分析系统分开的架构思路以来,数据仓库经历了几十年的发展,并在1991年被正式定义和广泛认可。
进入 2000 年以后,随着数据规模的增长,数据仓库在各大互联网企业中得到了广泛应用。亚马逊、谷歌、微软和 IBM 都推出了各自的数据仓库,如大家耳熟能详的 Amazon Redshift、Google BigQuery、Microsoft Azure SQL Data Warehouse等。同样在这个时期,由于业务规模的发展,百度作为互联网企业也需要解决数据分析过程中数据量增长、性能要求提升带来的各种问题,因此研发了自家的数据仓库技术 PALO,并把代码捐献给开源给社区,取名 Doris。
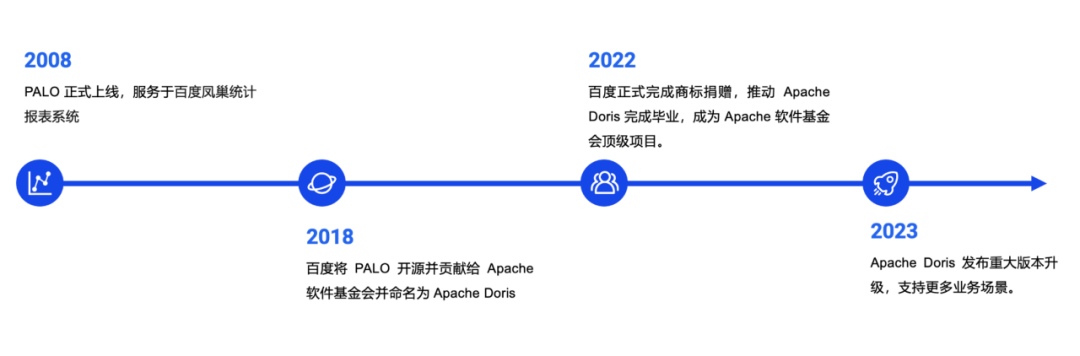
百度 PALO 的诞生
在2000年代,百度随着中文互联网的发展进入了快速发展阶段。百度支持广告主访问在线报表的广告系统,需要满足百万级别用户的大数据量、多场景的查询分析需求。由于业务增长,基于 mysql 的数据查询系统开始捉襟见肘,出现了如性能无法满足,需要频繁扩容,运维复杂等问题。而在当时业界的商业数据库也有成本高、性能一般的问题,且商业数据库多是封闭的,问题的排查难度也很高。
为了解决了统计分析和报表查询的数据效率问题,百度借鉴行业经验,研发了百度 OLAP Engine,服务于百度凤巢、网盟以及 Feed 的各个广告系统,肩负着海量统计数据的存储任务。但是,由于之前使用的是 MySQL 查询层,OLAP Engine 实际上只是单一地为报表类型服务的存储引擎,而在分布式管理方面存在不足。加之使用 MySQL 查询,查询引擎时常成为性能瓶颈。从 2014 年开始,百度开始将 OLAP Engine 改造为分布式存储引擎,自带 sharding 和 replication, 然后采用 Impala 作为分布式查询引擎来替代 MySQL,并正式命名为 Palo。
2018年,百度将 Palo 贡献给了 Apache 软件基金会并重新命名为 Apache Doris,进入了开源开放的共建阶段。而 Palo 则作为百度云商业化产品,不仅包含 Doris 引擎,还包含云产品的各项产品功能,可以简单认为 百度 PALO 是基于 Doris 的云数仓产品。
上面我们简要回顾了百度PALO的发展历程。从最初的简单查询分析加速,到如今支持湖仓加速、冷热分层、日志分析等多元化场景的高级特性,百度PALO能够有这样的发展脉络,是其对数据分析需求变化的紧密跟踪,也反映了数据仓库技术发展趋势。
数据仓库的发展趋势
近年来,由于企业数据规模的扩大以及分析场景的复杂化,为了解决这些问题,很多公司的技术架构从单一模式逐步转变为多元数据源的复杂构架,这导致了系统维护成本的上升和数据的冗余存储和处理。因此,业界最新的数据仓库的技术发展正逐渐向统一架构、降低运维和使用成本的方向演进。出现了如:在离线一体、流批一体、湖仓一体等趋势。
而业务方面,随着商业决策、电商营销等实时业务场景越来越重要,数据的时效性要求也不断提升,在这些场景中充分体现了“时间就是金钱”;同时,数据分析的需求不再仅限于数据分析师,越来越多的业务人员也需要进行数据分析。因此,数据仓库需要具备更低的分析门槛、更低的学习成本,更低的响应时延及更高的并发支持。
总的来看,当前企业数据分析的需求主要集中在时效性、性价比、统一性和易用性上。因此数据仓库的技术有融合的趋势,融合实时,数仓,数据湖,云原生等多能力。
其中,数据仓库和云生态结合,因为具有有灵活性和易于运维等特点,整体其性价比较高,所以越来越得到企业的青睐。亚马逊、谷歌、微软等云计算巨头也都于 2010 年左右推出了各自的云上数据仓库产品,也有其他软件企业加入赛道。以近年来的明星产品 Snowflake 为例, 2020 年上市首日市值更是飙升至708亿美元,吸引了包括沃伦·巴菲特在内的著名投资者关注。Snowflake 之所以成功,一方面其性能快速,支持数据实时入仓,并且具有高计算弹性;另一方面期支持用户选择灵活的订阅服务,完全免运维的服务方式支持开箱即用。用户可以体验到高性价比的自助式数据分析服务。
目前百度 PALO 也在性能和云原生方面不断发展, PALO 2.0 版本于 2024年6月在百度智能云正式发布,旨在为客户提供更稳定、功能更强,服务更优质的云数据仓库。新版本的关键更新主要体现在性能提升和云原生方面。接下来,我将为大家简要介绍 2.0 版本的关键特性和能力。
百度 PALO 2.0关键能力
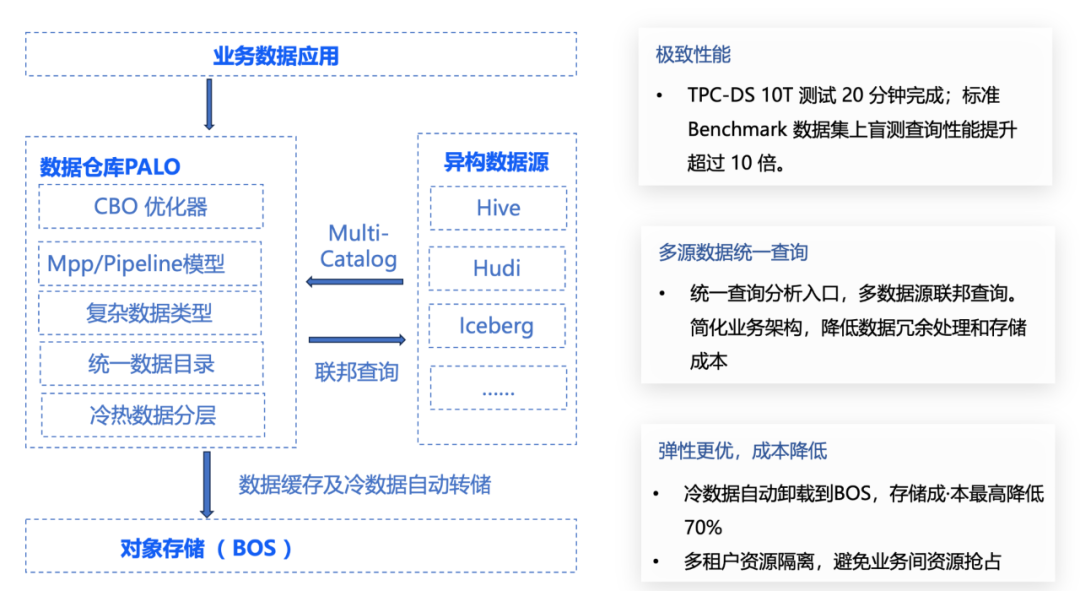
性能更强,查询能力更丰富
PALO 2.0 版本在标准 Benchmark 数据集上盲测查询性能提升超过 10 倍,具备更智能的全新查询优化器 ,TPC-DS 10T 规模 20 分钟可轻松通过,更节省用户资源和成本。
引入了全新的行列混合存储以及行级 Cache 及其他优化,点查询并发能力提升 20 倍,单点并发达到 30000QPS。可以替代一些使用 Hbase 和 Redis 的场景,可以帮助用户简化架构,降低系统维护成本。
新增 支持 Pipeline 执行模型,能使任务占用的计算资源更快的释放和再利用,充分利用 CPU 资源,更省资源。
PALO 2.0 版本支持了 array/json/struct/map/variant 等复杂数据类型,提供了非结构化数据分析能力,以更好满足半结构化数据的分析需求,降低业务的复杂性。
云原生能力
2.0 版本支持冷热数据分层,大大降低存储成本,用户建表时可以配置转冷策略,当数据到期后,冷数据会自动从云磁盘CDS存储迁移至成本更低的百度对象存储 BOS 上。该功能支持分区级或表级配置,用户存储成本最高可降低 70%。
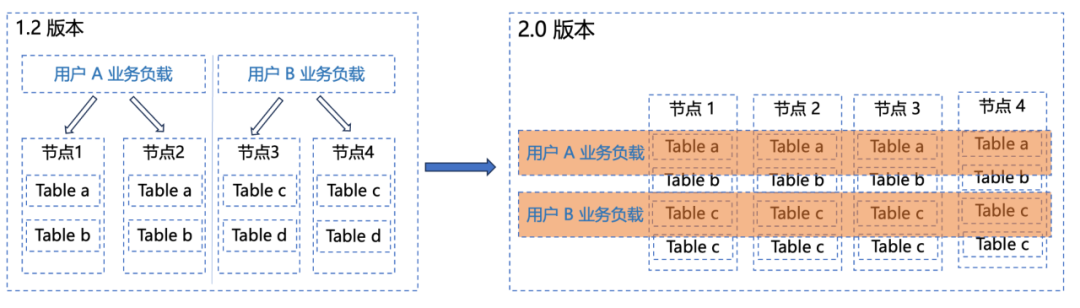
2.0 版本提供了更加完善的多租户资源隔离能力,并解决了 1.2 版本的节点级资源隔离导致的资源碎片化的问题。PALO 2.0 版本新增工作组 (Work Group) 为每个 Group 上配置单个 BE 能够使用资源(CPU,内存) 实现 BE 节点内的软隔离。当集群资源紧张时,将自动 Kill 组内占用内存最大的若干个查询任务以减缓集群压力。当集群资源空闲时,多个 Workload 将共享集群可用空闲资源并自动突破阈值,继续使用系统内存以保证查询任务的稳定执行。Workload Group 还支持设置优先级,通过预先设置的优先级进行资源分配管理,同时为避免业务负载过高时,新的查询继续提交影响正在执行的查询,Workload Group 支持了查询排队功能。当查询达到预设的最大并发时,新提交计划会进入排队逻辑,当队列已满或等待超时,查询会被拒绝,以此来缓解高负载下系统的压力。
未来展望
自2023年9月开始,PALO 2.0 版本在百度内部的数十条业务线中进行了内测,覆盖了在线、离线等众多不同的业务场景。经过了9个月的测试和问题修复,其稳定性得到了更有力的保证。未来,PALO将持续发展和优化产品能力。
首先,PALO 会继续坚持稳定性优先的产品策略,不断推出基于内核引擎的 LTS 版本,将支持更友好的数据备份和恢复,并在已有的集群高可用性基础上进一步加强容灾备份能力。
此外 PALO 还将加强与百度智能云的生态结合,如与百度数据湖管理与分析平台 EDAP 进行融合,提供便捷、快速的湖仓查询使用体验。
从长远来看,PALO 将进一步云原生化,向着Serverless 演进,帮助用户更低成本的进行数据分析;与 AI 的结合也是 PALO 的探索方向,我们会调研 结合AI技术,帮助客户进行智能数据管理和数据建模等。
总而言之,PALO 将不断进行技术和产品建设,致力于为用户提供实时、高性能、高性价比的云数仓产品。
