





摘要
海马体索引理论
书架区(新皮质):这是存放书籍的地方,你可以在这里找到每一本书。这些书籍代表了你处理和存储的各种信息和记忆。 索引卡区(海马体):这是一个存放索引卡的地方。每张索引卡上写着关于书籍的详细信息,比如书名、作者、主题等。索引卡帮助你快速找到你需要的书籍。
检索框架
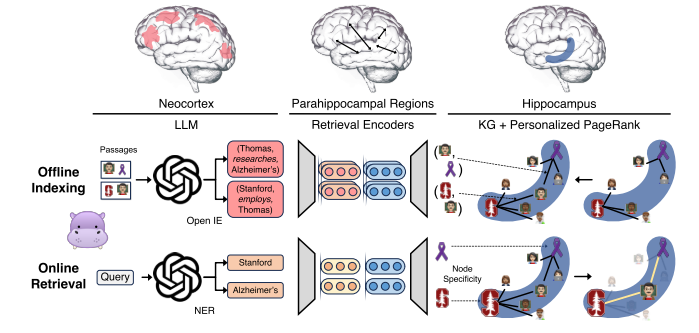
离线索引(Offline Indexing): 新皮质模拟:左侧的第一个大脑图像代表新皮质区域,这里的信息被提取并转化为知识图谱。同时,合成的旁海马区(PHR)检测同义词。例如,在例子中,“Thomas, researches, Alzheimer's”和“Stanford, employs, Thomas”这样的三元组被提取并整合进知识图谱。 知识图谱构建:右侧的大脑代表海马体及其周边区域,这里的信息来自新皮质,并被组织成知识图谱。在这个过程中,通过开放信息提取,将文本中的事件抽取出来,形成三元组结构,例如:“Thomas-researches-Alzheimer's”和“Stanford-employs-Thomas”。 在线检索(Online Retrieval): 记忆检索模拟:最下方的流程图展示了在线检索阶段的工作流程,首先从查询中提取关键信息,也就是查询实体。然后,这些实体被链接到知识图谱中的相应节点,链接依据是通过检索编码器确定的相似性。最后,通过个性化PageRank算法,从查询节点出发进行图搜索,以找到最相关的记忆片段。 知识图谱检索:右侧展示了知识图谱检索的过程,箭头表示信息流,中间的大脑用彩色线条表示不同类型的关联。 整体架构: 离线索引和在线检索之间的联系:离线索引阶段负责从大量文本数据中提取有用信息并将其组织成知识图谱;在线检索阶段则利用这些知识图谱来快速准确地响应用户的查询请求。
实现方法
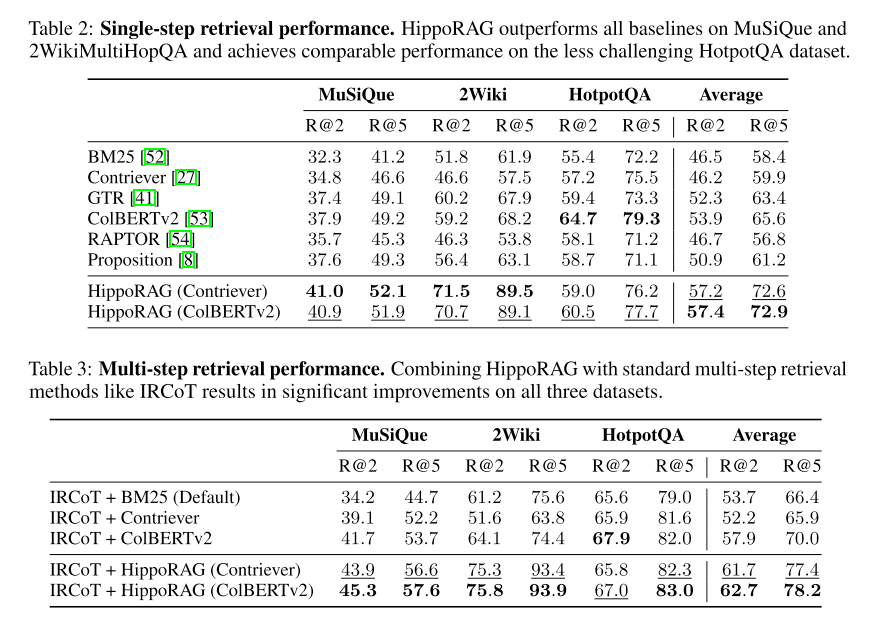
实验结论总结

编者简介

文章转载自向量检索实验室,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
