




导读
关于Kaggle上的SQL Mutual Fund Performance 代码
上文提到,Kaggle是一个数据建模和数据分析竞赛平台,US Funds dataset from Yahoo Finance是Kaggle上的一个数据集。
Kaggle上不仅提供了数据,也提供了很多数据科学工作者的代码。在Kaggle上,US Funds dataset from Yahoo Finance数据集对应的分析代码有19个:
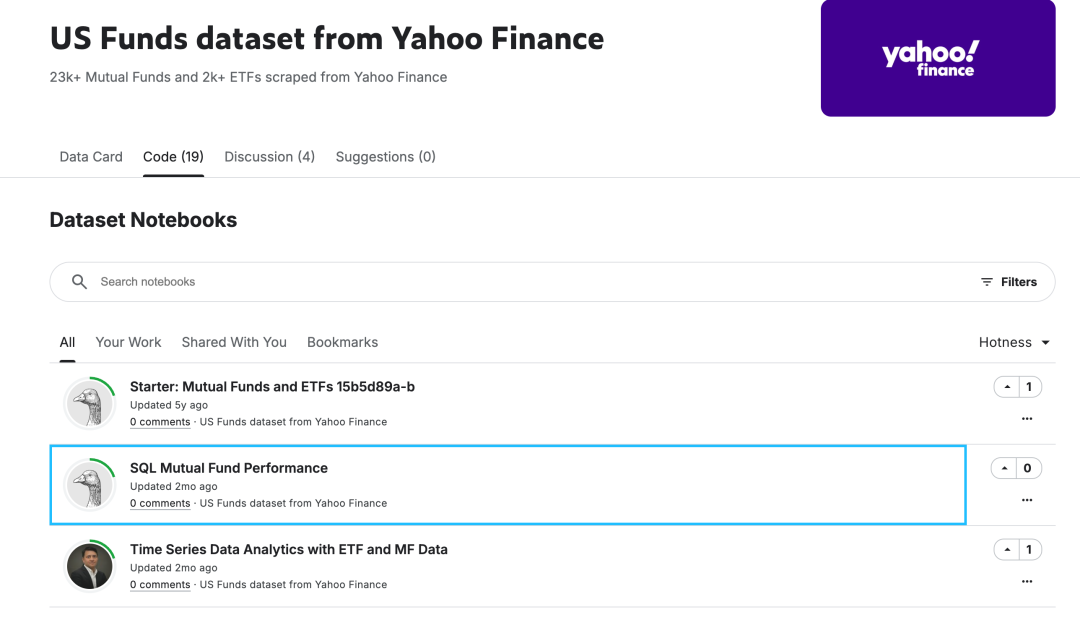
其中“ SQL Mutual Fund Performance ”立即引起了笔者的关注。
代码地址:https://www.kaggle.com/code/sophianguyn/sql-mutual-fund-performance
先看一下该代码的总结:
问题陈述-本项目的目标是使用 SQL 分析共同基金数据,以确定关键业绩趋势、风险与回报矩阵以及费用预测。随着投资机会的增加,了解这些方面对于投资者做出明智的决策至关重要。此分析旨在对基金进行分类、比较业绩并了解风险回报权衡,为投资者和基金经理提供宝贵的见解。 结论-分析揭示了共同基金业绩、风险评级和回报评级的重要趋势。通过根据业绩和风险回报矩阵对基金进行分类,我们确定了高绩效和低绩效基金:高绩效基金:持续表现出高评级和有利风险回报率的基金。低绩效基金:评级低且风险回报率较差的基金。此外,不同时间范围(3、5 和 10 年)的费用预测提供了对不同基金相关成本的全面了解。例如,“13D Activist Fund”和“361 Funds”等基金多年来的费用趋势高于其他基金。这种整体视角有助于做出更好的投资决策,因为它可以突出各种共同基金的业绩潜力和成本影响。 技术-使用 SQL 对数据进行分类和聚合。基金业绩、风险评级和回报评级的比较分析。3 年、5 年和 10 年期间的费用预测分析。可视化关键发现以增强可解释性。 如果我有更多时间,我可能会做 集成更复杂的统计模型,根据历史数据预测未来表现。对市场条件对共同基金业绩的影响进行更深入的分析。实施高级可视化工具以创建更具交互性和更详细的数据可视化表示。
问题引入:这些 SQL 代码可以跑在云器Lakehouse 上么?
云器Lakehouse支持SQL和Python等语言进行数据分析,这就激发了笔者对其中“SQL Mutual Fund Performance”SQL代码的好奇心:
❓这些SQL代码可以跑在云器Lakehouse上,以进一步分析上文导入到Lakehouse的数据么?
SQL Mutual Fund Performance包括了如下查询:
查询 1:四年内(2018-2021)最高和最低平均评级
查询 2:每只基金的平均同比评级
查询 3:关键评级 KPI 同比比较表
查询 4:根据基金表现和风险回报矩阵对基金进行分类
查询 5:表现和风险与回报矩阵分析
查询 6:业务审查的风险与回报矩阵分析
查询 7:最高营业额分析
查询 8:费用项目趋势
SQL 特点与复杂度分析
凡事先谋而后动,在决定正式代码迁移之前,先仔细阅读一下“SQL Mutual Fund Performance”代码,分析其特点和复杂度。快速看下查询 2(每只基金的平均同比评级)的SQL代码(Pandas SQL语法):
SELECT *FROM (SELECT*,SUM(c.yr_18 + c.yr_19 + c.yr_20 + c.yr_21) 4 AS avg_ratingFROM (SELECTb.fund_long_name,MAX(b.yr_2018) AS yr_18,MAX(b.yr_2019) AS yr_19,MAX(b.yr_2020) AS yr_20,MAX(b.yr_2021) AS yr_21FROM (SELECTa.fund_long_name,CASE WHEN a.year = '2018' THEN a.avg_rating ELSE 0 END AS yr_2018,CASE WHEN a.year = '2019' THEN a.avg_rating ELSE 0 END AS yr_2019,CASE WHEN a.year = '2020' THEN a.avg_rating ELSE 0 END AS yr_2020,CASE WHEN a.year = '2021' THEN a.avg_rating ELSE 0 END AS yr_2021FROM (SELECTstrftime('%Y', inception_date) AS Year,fund_long_name,ROUND(AVG(morningstar_overall_rating), 2) AS avg_ratingFROM mutualfunds mGROUP BY fund_long_name, strftime('%Y', inception_date)ORDER BY fund_long_name, strftime('%Y', inception_date) DESC) a) bGROUP BY b.fund_long_name) cGROUP BY c.fund_long_name) dORDER BY d.avg_rating DESC;
特点
使用公共表表达式(CTE): 通过WITH子句定义了一个名为expense的CTE,用于计算每个基金家族的费用趋势。这使得查询结构更加清晰和模块化。 条件聚合: 使用SUM和CASE WHEN语句来计算不同时间段内的费用趋势。这种方法允许在单个查询中进行复杂的条件聚合。 联合查询(UNION ALL): 使用UNION ALL将多个子查询的结果合并在一起,每个子查询代表不同的时间段(3年、5年、10年)的费用趋势。 分组和聚合: 在最终的查询中,使用GROUP BY和MAX函数对不同基金家族的费用趋势进行分组和聚合。
复杂度
查询嵌套: 查询包含多个嵌套的子查询和CTE。 条件逻辑: 使用了多个CASE WHEN语句来处理不同的条件逻辑。 性能考虑: 由于查询涉及多个聚合操作和条件计算,对数据平台对大数据集的计算性能要求高。
SQL 作业迁移步骤计划
云器Lakehouse内置有SQL IDE开发工具,包括代码智能提示、版本管理、测试和发布等,愉快的迁移过程就此开始:
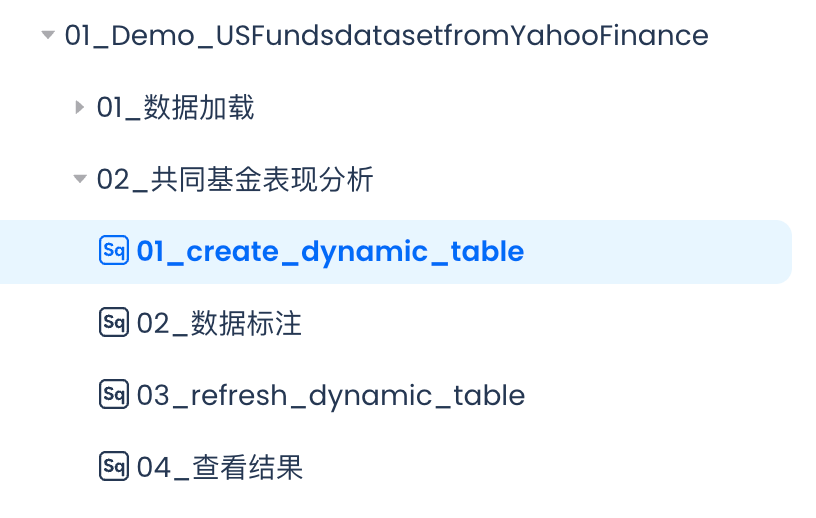
在上文数据加载的基础上规划本次迁移的四个步骤:
用动态表(Dynamic table)来存放计算结果,考虑到底表变化和结果表都是统计结果,非常适合用动态表来简化数据加工逻辑。 数据标准:对数据进行详细注释,方便团队理解和大模型理解数据结构。 刷新动态表:不同于传统的大数据INSERT INTO/OVERWRITE的结果刷新方式,云器Lakehouse的动态表采用增量计算技术,通过REFESHESH 动态表的方式只对变化数据进行计算,从而大幅提升了数据刷新速度并降级计算成本,从而提高性价比,达到降本增效的目的。 查看结果,通过SELECT语句查看计算结果。
实施 SQL 作业迁移
迁移过程非常顺利,基本上是个ICP(Information Copy&Paste)的过程。每一个查询的迁移过程如下:
1.从“SQL Mutual Fund Performance”Copy代码。
代码地址:https://www.kaggle.com/code/sophianguyn/sql-mutual-fund-performance
2.粘贴到云器Lakehouse的SQL IDE。
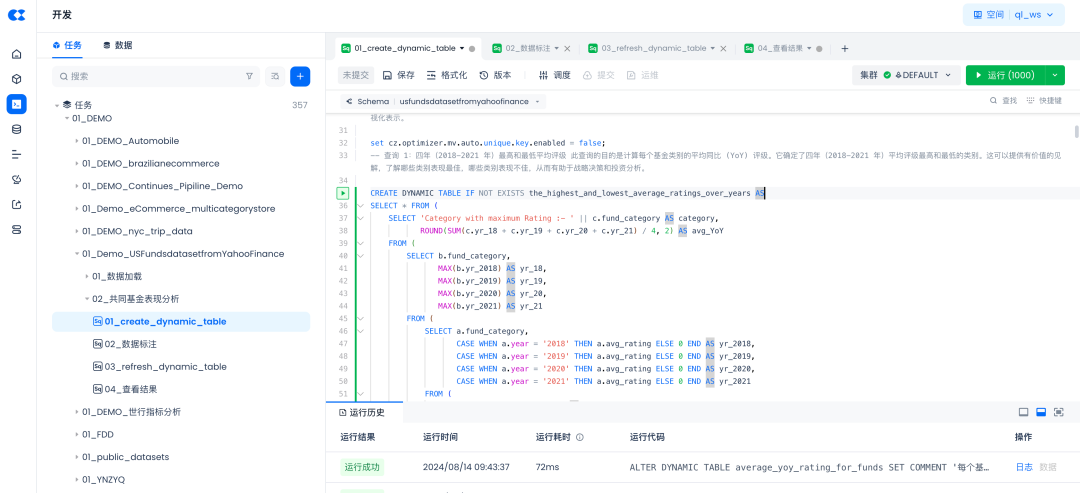
3.先跑通SELECT语句,跑通后检查结果正确。
a.语法修改:使用IDE的查找替换功能,将strftime('%Y', inception_date) 改为year(inception_date)
b.检查结果:
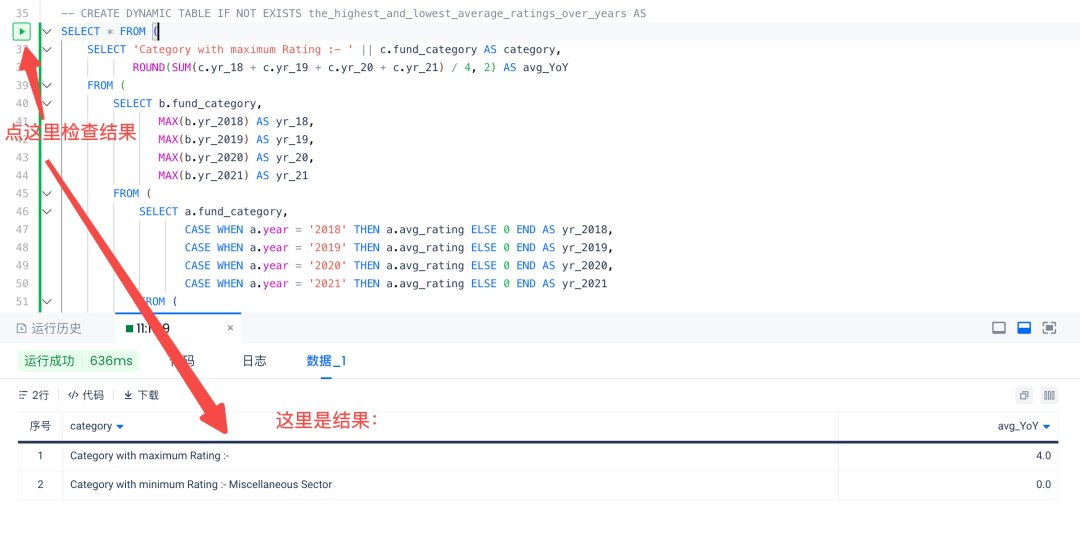
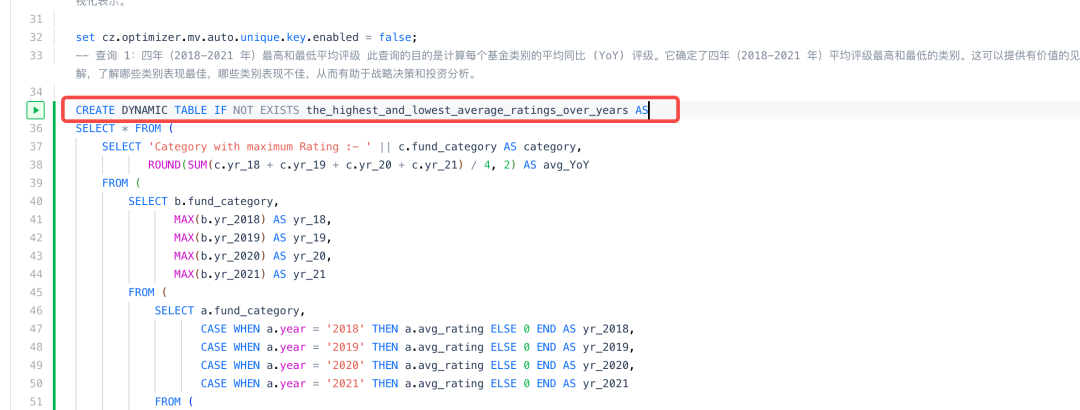
4.根据SELECT语句创建动态表。
CREATE DYNAMIC TABLE IF NOT EXISTS the_highest_and_lowest_average_ratings_over_yearsASSELECT ***
5.迁移后完整代码
❤️(因篇幅原因省略部分,可通过https://www.yunqi.tech/resource/blogs/technical-lakehouse-kaggle-data-sql看完整代码)
set cz.optimizer.mv.auto.unique.key.enabled = false;-- 查询 1:四年(2018-2021 年)最高和最低平均评级 此查询的目的是计算每个基金类别的平均同比 (YoY) 评级。它确定了四年(2018-2021 年)平均评级最高和最低的类别。这可以提供有价值的见解,了解哪些类别表现最佳,哪些类别表现不佳,从而有助于战略决策和投资分析。CREATE DYNAMIC TABLE IF NOT EXISTS the_highest_and_lowest_average_ratings_over_years ASSELECT * FROM (SELECT 'Category with maximum Rating :- ' || c.fund_category AS category,ROUND(SUM(c.yr_18 + c.yr_19 + c.yr_20 + c.yr_21) 4, 2) AS avg_YoYFROM (SELECT b.fund_category,MAX(b.yr_2018) AS yr_18,MAX(b.yr_2019) AS yr_19,MAX(b.yr_2020) AS yr_20,MAX(b.yr_2021) AS yr_21FROM (SELECT a.fund_category,CASE WHEN a.year = '2018' THEN a.avg_rating ELSE 0 END AS yr_2018,………………
数据标注
这里是数据工程师的美德了!小伙伴们需要更好的理解数据,大模型也同样需要。
ALTER DYNAMIC TABLE the_highest_and_lowest_average_ratings_over_yearsSET COMMENT '四年(2018-2021 年)最高和最低平均评级 此查询的目的是计算每个基金类别的平均同比 (YoY) 评级。它确定了四年(2018-2021 年)平均评级最高和最低的类别。这可以提供有价值的见解,了解哪些类别表现最佳,哪些类别表现不佳,从而有助于战略决策和投资分析。';ALTER DYNAMIC TABLE average_yoy_rating_for_fundsSET COMMENT '每个基金的平均同比 (YoY) 评分 此查询根据基金的 fund_long_name 计算每个基金的平均同比 (YoY) 评分。它汇总了每年(2018、2019、2020 和 2021)的评分,并计算这些年的平均评分。从此分析得出的业务推论包括确定平均同比评分最高和最低的基金类别、突出显示不一致之处和趋势以及确定评分为 0 的类别。此信息对于了解各种基金类别随时间推移的业绩动态至关重要。';ALTER DYNAMIC TABLE comparison_table_for_key_rating_kpis_yoySET COMMENT '关键评级 KPI 同比 (YoY) 比较表 此查询生成关键评级 KPI 同比 (YoY) 比较表。KPI 包括:平均评级 (avg_rating):衡量基金组合的整体表现。回报评级 (avg_return_rating):评估基金产生的产出或回报程度。风险评级 (avg_risk_rating):评估与基金相关的风险程度。查询根据基金的 fund_long_name 汇总每个基金的这些 KPI,并计算 2018、2019、2020 和 2021 年的平均值。';ALTER DYNAMIC TABLE categorizing_funds_based_on_their_performance_and_risk_return_matrixSET COMMENT '根据基金的表现和风险回报矩阵对基金进行分类 此查询旨在通过根据基金的表现和风险回报矩阵对基金进行分类来确定绩效趋势。它有助于业务团队了解不同基金的表现及其相关的风险和回报特征。评级:反映基金的表现。风险评级:表示与基金相关的风险程度。回报评级:表示基金的产出或回报程度。该查询根据基金的平均评级将基金分为“表现良好”和“表现不佳”。它还将基金分为四个风险回报类别:高风险高回报、高风险低回报、低风险低回报和低风险高回报。';ALTER DYNAMIC TABLE performance_and_risk_vs_return_matrix_analysisSET COMMENT '绩效和风险与回报矩阵分析 此查询评估各种共同基金的绩效和风险回报状况,以进行业务审查。它比较了表现良好和表现不佳的基金的数量,并将它们归类为不同的风险回报矩阵。';ALTER DYNAMIC TABLE risk_vs_return_matrix_analysis_for_business_reviewSET COMMENT '业务审查的风险与回报矩阵分析。此查询分析各种共同基金的风险与回报矩阵,以帮助业务审查团队了解绩效趋势。重点是确定属于四类的基金:高风险高回报、低风险高回报、高风险低回报以及低风险低回报。业务推断是顶级组是低-低和高-高,检查点是评估低-低基金的数量,以确定对于普通客户来说低多少。';ALTER DYNAMIC TABLE highest_turnover_analysisSET COMMENT '最高周转率分析,分析按基金全名、基金类别、投资类型和规模类型分类的共同基金的最大年度持股周转率。目标是确定哪个基金或类别的周转率最高,从而深入了解每个细分市场的流动性和活动水平。';ALTER DYNAMIC TABLE average_expense_projectionsSET COMMENT '费用项目趋势-Average Expense Projections,分析并总结了不同时间范围内(3 年、5 年和 10 年)共同基金的费用预测。此分析有助于了解费用趋势并识别具有重大费用预测的基金家族。';ALTER DYNAMIC TABLE expense_trend_analysis_by_fund_familySET COMMENT '费用项目趋势-Expense Trend Analysis by Fund Family,分析并总结了不同时间范围内(3 年、5 年和 10 年)共同基金的费用预测。此分析有助于了解费用趋势并识别具有重大费用预测的基金家族。';ALTER DYNAMIC TABLE yoy_fund_expense_comparisonSET COMMENT '费用项目趋势-Year-over-Year Fund Expense Comparison,分析并总结了不同时间范围内(3 年、5 年和 10 年)共同基金的费用预测。此分析有助于了解费用趋势并识别具有重大费用预测的基金家族。';
执行完上述代码,看下小伙伴们是不是就更好理解你的数据产出啦(你不是一个人在战斗!):

刷新动态表
当第一次建好动态表或者之后在底表数据发生变化时,可以通过执行如下语句刷新动态表里的数据:
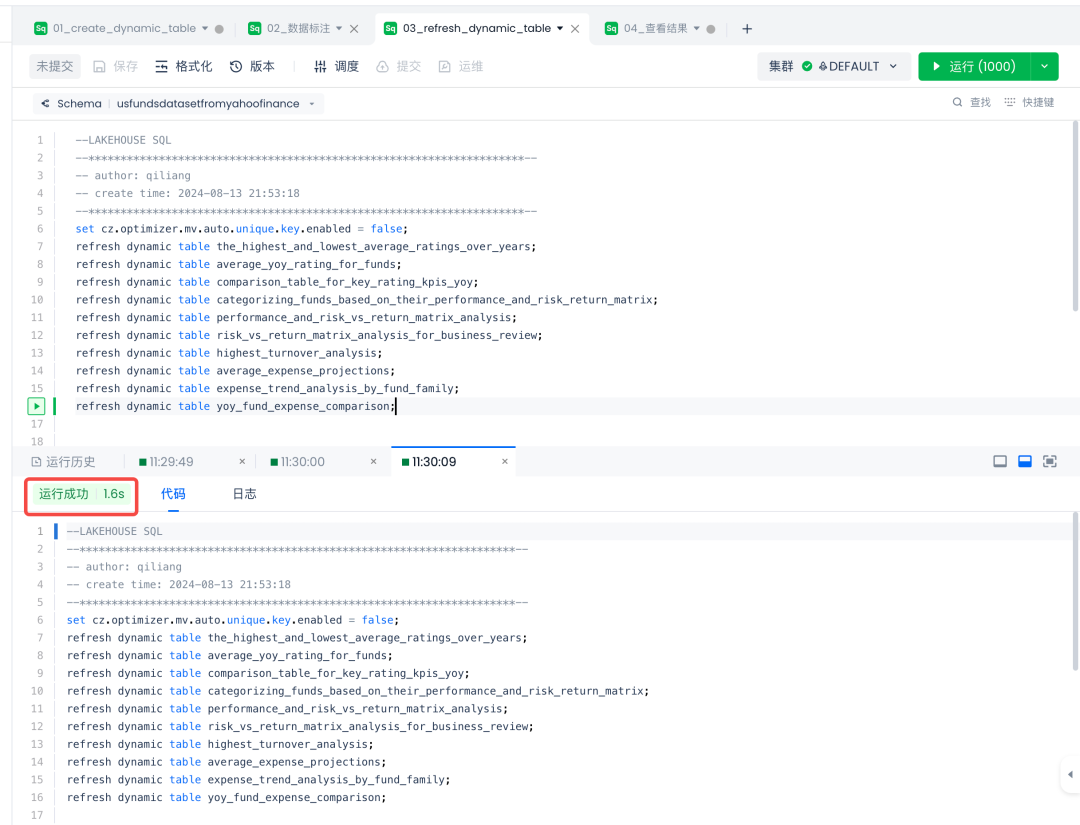
可以看到在云器Lakehouse执行上述10个动态表的结果刷新,仅用了1.6秒。而这10个刷新动作的底表有7千多万行数据,之前担心执行性能的问题,发现也不是问题嘞。
set cz.optimizer.mv.auto.unique.key.enabled = false;refresh dynamic table the_highest_and_lowest_average_ratings_over_years;refresh dynamic table average_yoy_rating_for_funds;refresh dynamic table comparison_table_for_key_rating_kpis_yoy;refresh dynamic table categorizing_funds_based_on_their_performance_and_risk_return_matrix;refresh dynamic table performance_and_risk_vs_return_matrix_analysis;refresh dynamic table risk_vs_return_matrix_analysis_for_business_review;refresh dynamic table highest_turnover_analysis;refresh dynamic table average_expense_projections;refresh dynamic table expense_trend_analysis_by_fund_family;refresh dynamic table yoy_fund_expense_comparison;
也可以周期性的调度上述代码:
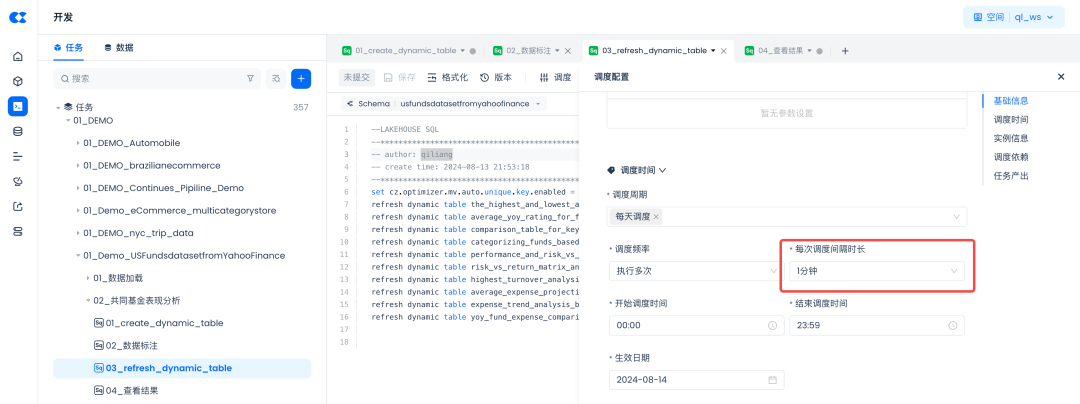
通过设置每次调度间隔时长为1分钟,这样就可以将动态表的数据新鲜度保持在分钟级了,也就是说当底表数据发生变化1分钟后,结果表的结果就会自动被刷新了。
关于云器Lakehouse动态表详细解释,参考:https://www.yunqi.tech/documents/dynamic_table_summary
查看结果
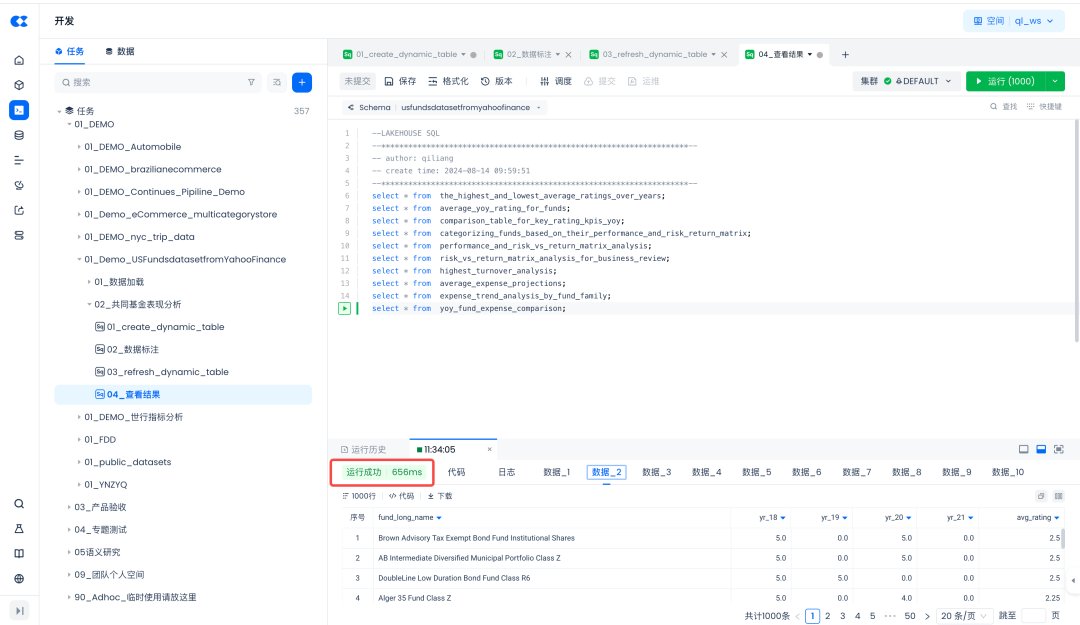
一次查询10个动态表里的结果,仅用了656毫秒。
性能体验
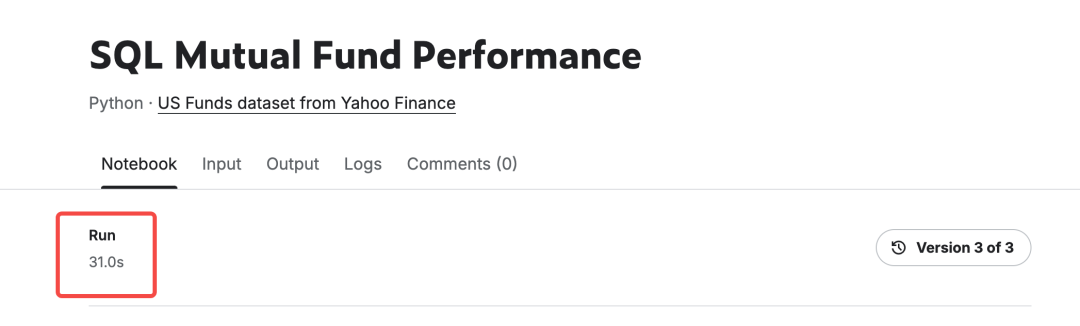
同样的数据在Notebook里运行需要31秒,迁移到云器Lakehouse后,计算和分析的过程仅需要2.3秒,从性能体验的角度看提升了13.5倍,这对数据工作人员而言,确实能够大幅降低时间成本,提高工作效率。
总结
好的数据分析,好的AI效果,总是离不开好的数据。而数据工程又是个繁琐、耗时、需要很大耐心的工作。通过上述实验,将“SQL Mutual Fund Performance”那些复杂的SQL代码迁移到云器Lakehouse的心得总结如下:
云器Lakehouse SQL语法高度兼容Pandas SQL,迁移过程基本上是个粘贴拷贝的过程,只有一个微小的函数语法改动。 云器Lakehouse的SQL IDE提供了版本管理、测试、调度和发布集成环境,提高了开发效率。 云器Lakehouse的动态表技术大幅提升了在大数据量下的性能体验,对比Notebook运行有13.5倍的性能提升。 因为简单,所以美好。整个实验都是在云器Lakehouse上完成,这给整个实验带来了简单美的体验。相信因为简单,可以让更多数据爱好者更顺利的玩转数据。
END
▼点击关注云器科技公众号,优先试用云器Lakehouse!
关于云器
往期推荐
