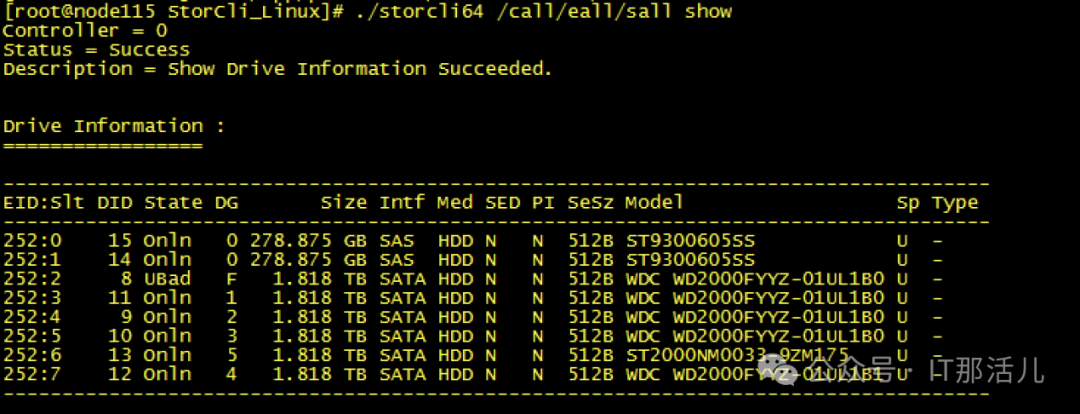
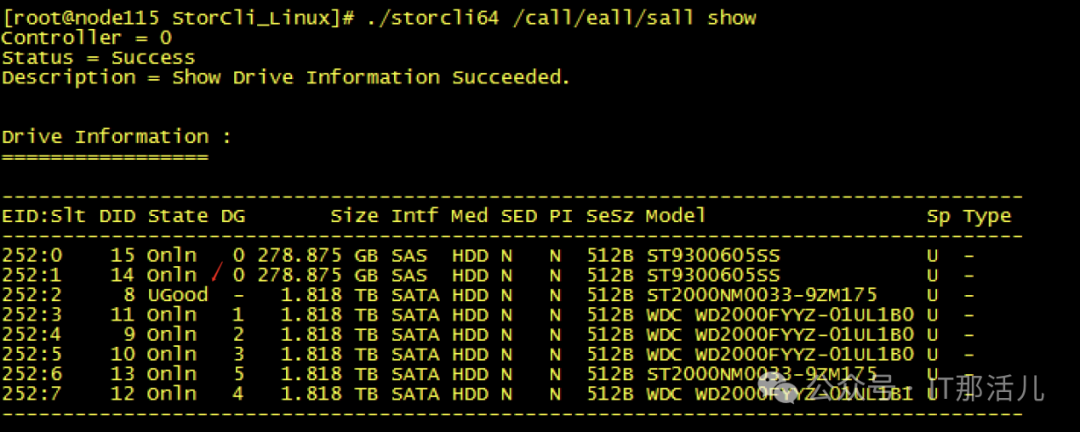
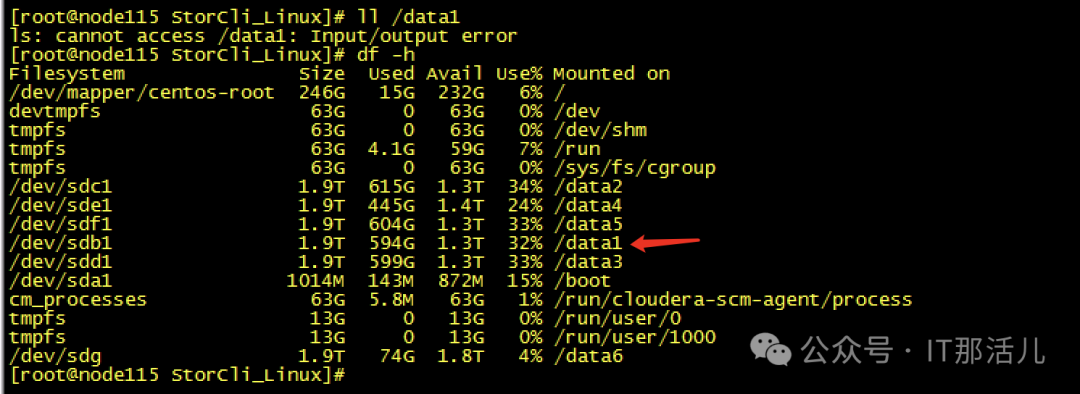
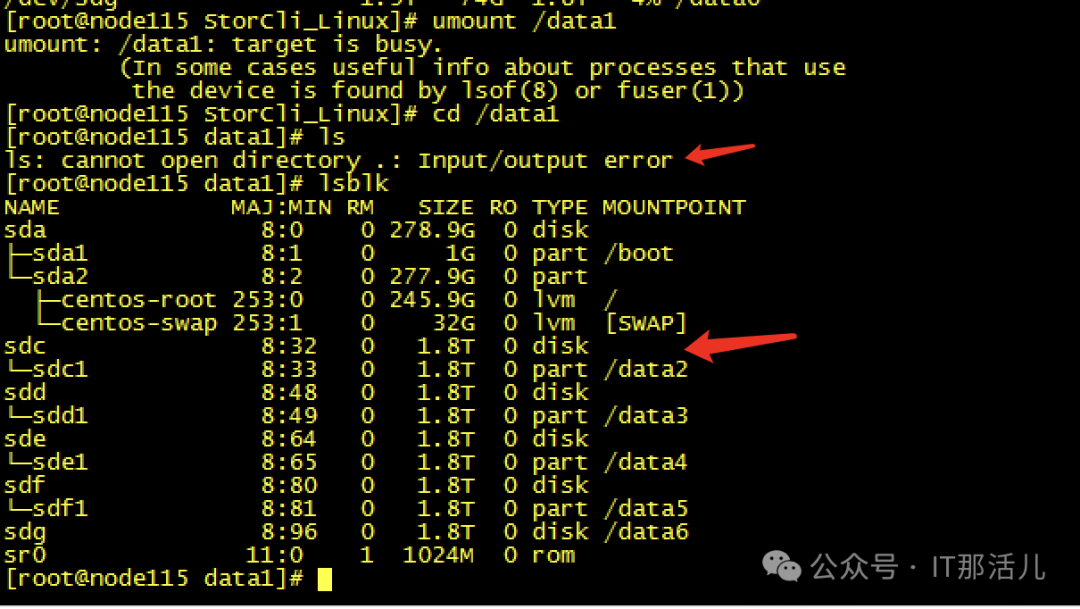
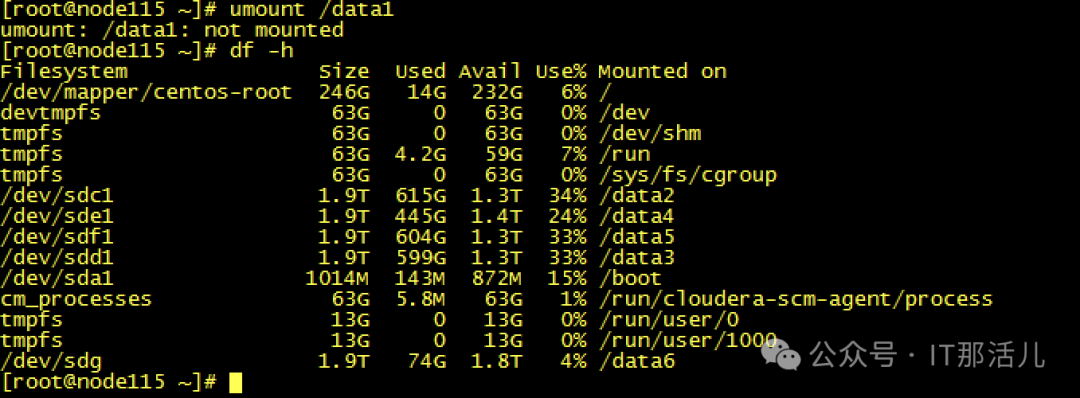
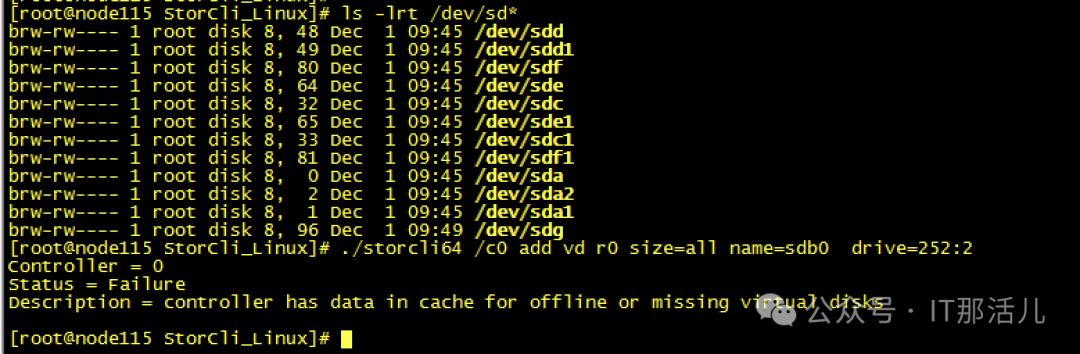
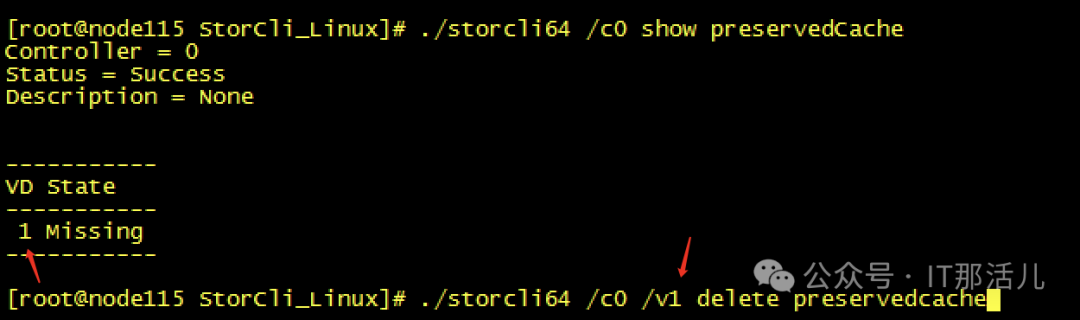
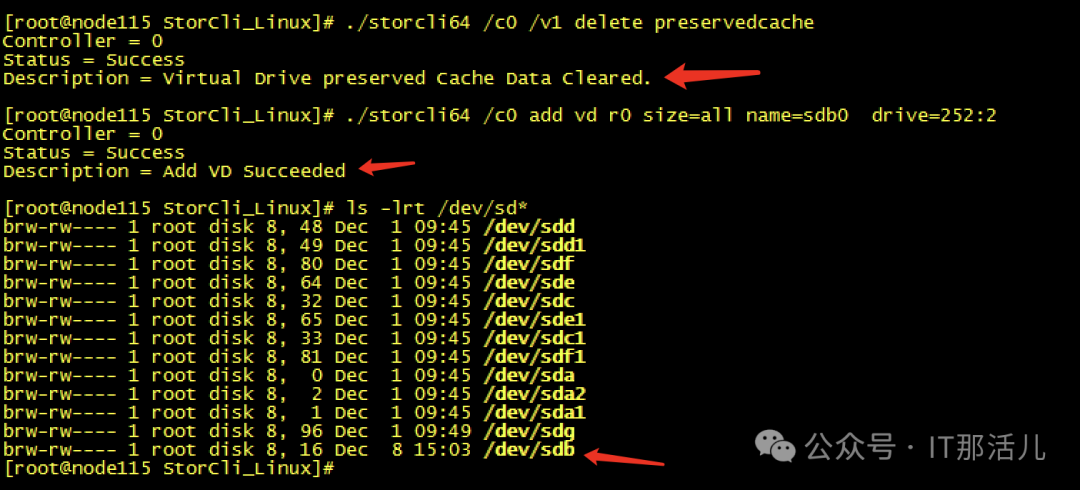
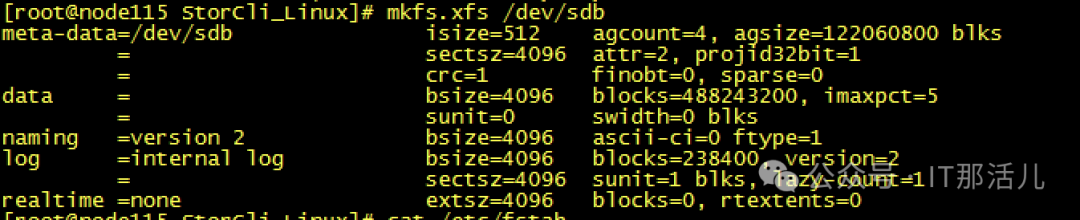
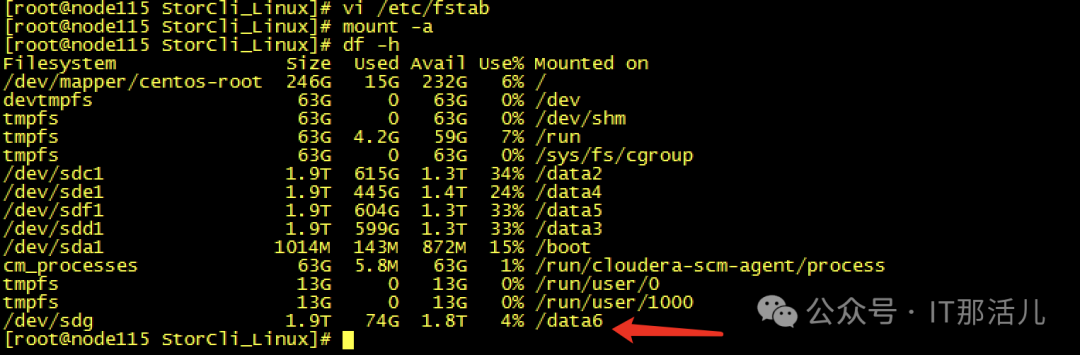
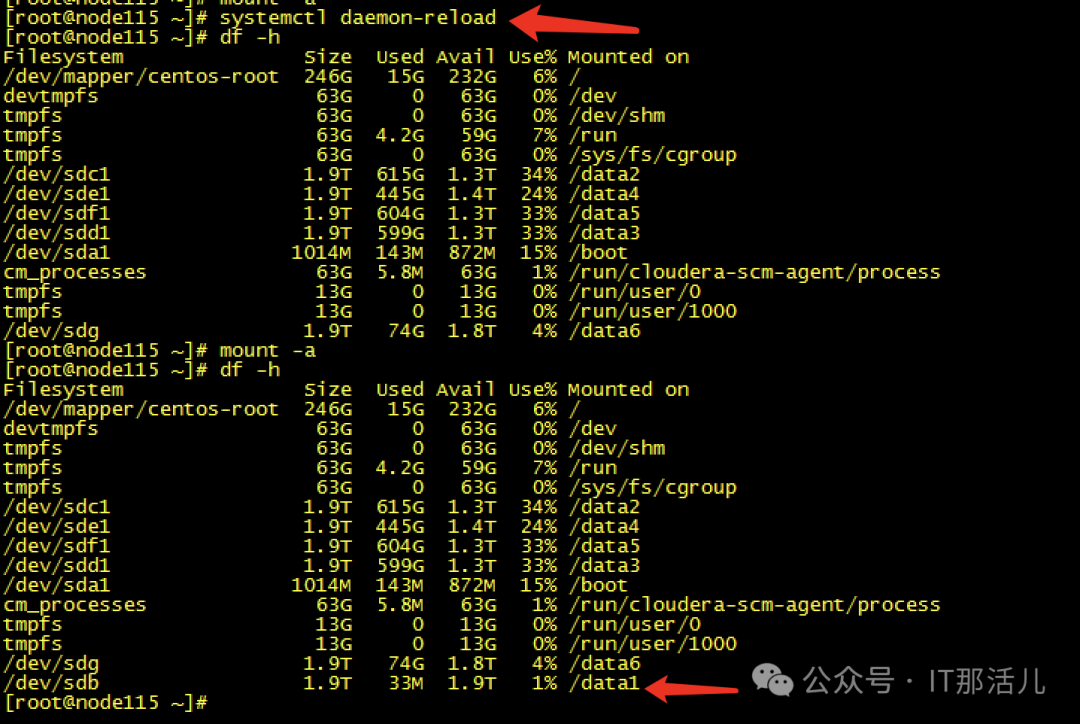
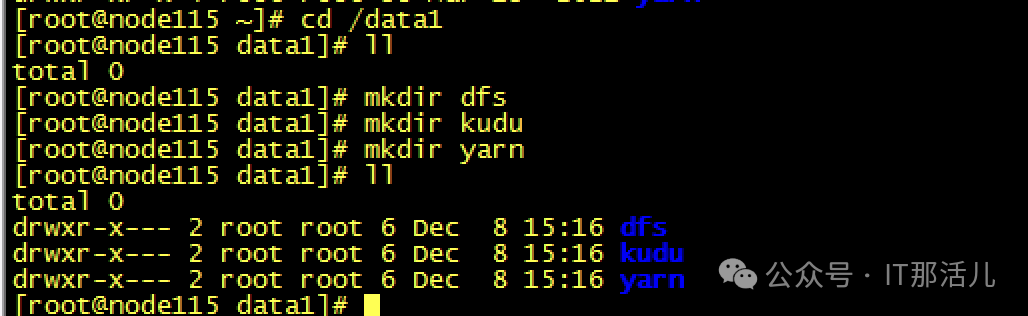
Step7cache清理完成后,再次创建raid0,发现可以创建成功并识别到新的磁盘sdb可以mkfs和挂在磁盘再次进行使用了:Step8此时新的问题再次出现,mount过后发现没有新的盘出现,而且无任何报错Step9 检查系统日志messages,发现给出了我们的答案原因大致是data1可能与之前的旧sdb还有绑定关系,我们需要手动reload一下,识别新的sdb。systemctl daemon-reload,执行此命令后再次挂载,我们发现已经可以正常使用/data1:测试使用,一切正常。恢复hdfs服务正常:至此,硬盘更换并重新使用完成。 END