




一、简介
ProtoBuf是一种结构数据序列化方法,它可用于(数据)通信协议、数据存储等。
序列化是指将结构数据或对象转换成能够被存储和传输(例如网络传输)的格式,同时应当要保证这个序列化结果在之后(可能在另一个计算环境中)能够被重建回原来的结构数据或对象。
ProtoBuf可简单类比于XML,其具有以下特点:
- 语言无关、平台无关。ProtoBuf支持Java、C++、Python等多种语言,支持多个平台
- 高效。比XML更小(3~10倍)、更快(20~100倍)、更为简单
- 扩展性、兼容性好。你可以更新数据结构,而不影响和破坏原有的旧程序
json格式
{
"srv_is_master":1,
"master":{ "ip":"127.0.0.1", "port":8898 }
......
}xml
<id>1</id>
<name>xxxx</name>
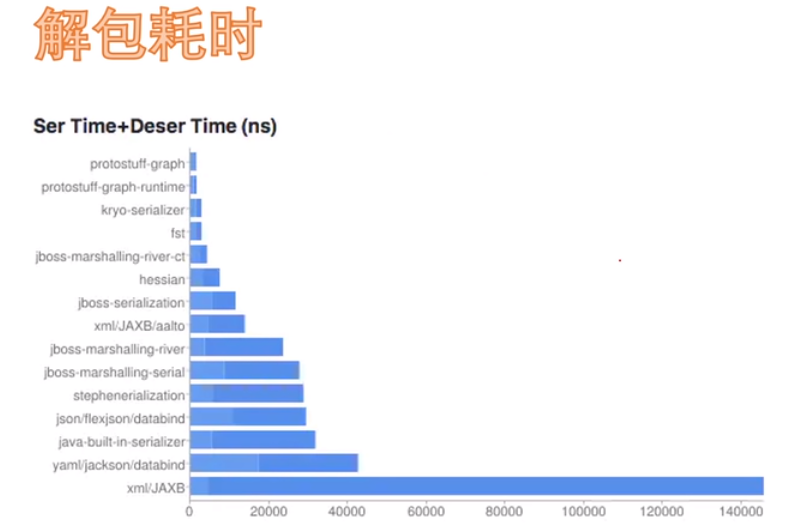
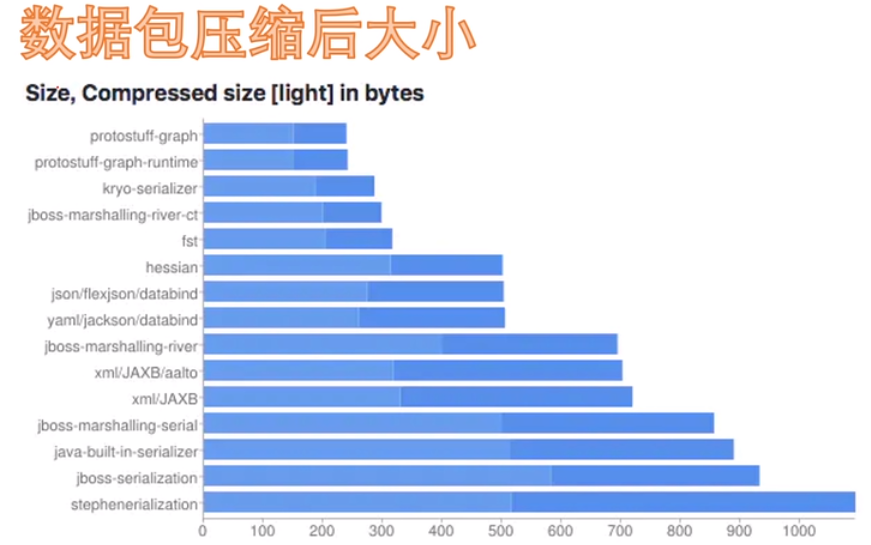
......Protobuf与其他工具解包耗时与压缩大小对比:
二、语法规则
2、1定义数据结构
这里以官网的例子来说明。
syntax = "proto2";
package tutorial;
message Person {
optional string name = 1;
optional int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
optional string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phones = 4;
}
message AddressBook {
repeated Person people = 1;
}Protobuf通过创建.proto文件,来定义数据结构。
一般,首先会声明此.proto文件使用的语法版本是proto2还是proto3,使用syntax="proto2"或者syntax="proto3"语句来声明。
.proto文件以package声明包名,以防止不同项目之间的命名冲突。在C++中,生成的类将放在与包名匹配的namespace(命名空间)中。
定义一个message类型:
message是包含一组类型字段的集合。许多标准的简单数据类型都可用作字段类型,包括bool、int32、float、double和string。还可以使用其他message类型作为字段类型在消息中添加更多结构。也可以在message中定义嵌套其他message类型。
这里列举一下各语言的数据类型对应于protobuf中的类型:
.proto Type | Notes | C++ Type | Java Type | Python Type | Go Type |
double | double | double | float | *float64 | |
float | float | float | float | *float32 | |
int32 | 使用可变长度编码。编码负数的效率低,如果字段可能有负值,请改用 sint32 | int32 | int | int | *int32 |
int64 | 使用可变长度编码。编码负数的效率低,如果字段可能有负值,请改用 sint64 | int64 | long | int/long | *int64 |
uint32 | 使用可变长度编码 | uint32 | int | int/long | *uint32 |
uint64 | 使用可变长度编码 | uint64 | long | int/long | *uint64 |
sint32 | 使用可变长度编码。有符号的 int 值。这些比常规 int32 对负数能更有效地编码 | int32 | int | int | *int32 |
sint64 | 使用可变长度编码。有符号的 int 值。这些比常规 int64 对负数能更有效地编码 | int64 | long | int/long | *int64 |
fixed32 | 总是四个字节。如果值通常大于 228,则比 uint32 更有效。 | uint32 | int | int/long | *uint32 |
fixed64 | 总是八个字节。如果值通常大于 256,则比 uint64 更有效。 | uint64 | long | int/long | *uint64 |
sfixed32 | 总是四个字节 | int32 | int | int | *int32 |
sfixed64 | 总是八个字节 | int64 | long | int/long | *int64 |
bool | bool | boolean | bool | *bool | |
string | 字符串必须始终包含 UTF-8 编码或 7 位 ASCII 文本 | string | String | str/unicode | *string |
bytes | 可以包含任意字节序列 | string | ByteString | str | []byte |
Protobuf会对设置的字段值进行类型检查,以确保其有效。64位或无符号32位整数在解码时始终表示为long,但如果在设置字段时给出int,则可以为int。在所有情况下,该值必须适合设置时的类型。
必须使用以下修饰符之一注释每个字段:
- required:必须提供该字段的值,否则该消息将被视为“未初始化”。如果序列化一个未初始化的message将导致断言失败。
- optional:可以设置也可以不设置该字段(零次或一次)。
- repeated:该字段可以重复任意次数(包括零次)。重复值的顺序将保留,可以使用索引来取相应的元素。可以将repeated字段视为动态大小的数组。
设置optional元素的默认值,可以使用[default = xxx]语句来设置,例如:
optional int32 result_per_page = 3 [default = 10];如果未为optional元素设置可选字段值,则使用默认值:
- 字符串默认值为空字符串。
- 字节类型默认值是空字节。
- 布尔类型默认值为false。
- 数值类型默认值为0。
- 枚举类型默认值是第一个枚举元素,它必须为0。
- 消息类型字段默认值为null。
对于嵌入message,默认值始终是消息的“默认实例”或“原型”,其中没有设置任何字段。调用访问器以获取尚未显式设置的optional(或required)字段的值始终返回该字段的默认值。
由于一些历史原因,标量数字类型的repeated字段不能尽可能高效地编码。新代码应使用特殊选项[packed = true]来获得更高效的编码。例如:
- repeated int32 samples = 4 [packed=true];
将字段设置为required类型是一个值得谨慎思考的事情,谷歌的一些工程师得出的结论是,使用required弊大于利,他们更喜欢只使用optional和repeated。在proto3中已经为兼容性彻底抛弃required。
还可以为字段指定复合类型,包括枚举和其它的message类型。枚举常量必须在32位整数范围内。由于enum值在线上使用varint encoding,负值编码效率低,因此不推荐使用,建议在message外部定义enums,好处是可以被所有message复用。
可以在其他message类型中定义和使用message,即在某message嵌套定义另一个message类型。如果要在其父消息类型之外重用此消息类型,调用时使用xxx.type的形式,如:
message SearchResponse {
message Result {
required string url = 1;
optional string title = 2;
repeated string snippets = 3;
}
repeated Result result = 1;
}
message SomeOtherMessage {
optional SearchResponse.Result result = 1;
}message定义中的每个字段都有唯一编号。这些数字以message二进制格式标识字段,并且一旦message被使用,这些编号就无法再更改。标签号1-15比起更大数字需要少一个字节进行编码,因此以此进行优化,可以将这些标签用于常用或重复的元素,将标记16和更高的标记留给不太常用的可选元素。repeated字段中的每个元素都需要重新编码编号,因此repeated字段特别适合使用此优化。
int32,uint32,int64,uint64和bool都是兼容的。因此可以将字段从这些类型更改为另一种类型,而不会破坏向前或向后兼容性。但是解析出一个不符合相应类型的数字,将获得与在C++中将该数字转换为该类型时相同的效果(例如,如果将64位数字作为int32读取,它将被截断为32位)。
只要字节是有效的UTF-8,string 和 bytes 就是兼容的。
可以在单个.proto文件中定义多种messages类型,但是这会导致膨胀,建议每个.proto文件包含尽可能少的message类型。
可以使用C/C++语法风格的注释//和/* ... */为.proto文件添加注释。
可以通过导入来使用其他.proto文件中的定义。要导入另一个.proto的定义,可以在文件顶部添加一个import语句:
import "path/to/proto_file/file_name.proto";三、编译
在.proto文件中定义了数据结构,这些数据结构是面向开发者和业务程序的,并不面向存储和传输。当需要把这些数据进行存储或传输时,就需要将这些结构数据进行序列化、反序列化以及读写。
通过protoc编译器生成接口代码。这些代码可以操作文件中描述的message类型,包括获取和设置字段值、将message序列化为输出流、以及从输入流中解析出message等。
Protc编译器可以生成不同语言的接口代码:
对于C++,编译器从每个.proto生成一个.pb.h和一个.pb.cc文件,其中包含文件中描述的每种message类型对应的类。
对于Java,编译器为每个message类型生成一个.java文件(类),以及用于创建message类实例的特殊Builder类。
Python编译器生成一个模块,其中包含.proto中每种message类型的静态描述符,然后与元类一起使用以创建必要的Python数据访问类。
对于Go,编译器会生成一个.pb.go文件,其中包含对应每种message类型的类型。
protoc --proto_path=IMPORT_PATH --cpp_out=DST_DIR path/to/file.proto- IMPORT_PATH指定在解析导入指令时查找.proto文件的目录。如果省略,则使用当前目录。可以通过多次传递--proto_path选项来指定多个导入目录;它们将按顺序搜索。-I = IMPORT_PATH可以用作--proto_path的缩写形式。
你可以提供一个或多个输出指令:
--cpp_out在DST_DIR中生成C++代码。
--java_out在DST_DIR中生成Java代码。
--python_out在DST_DIR中生成Python代码。
注意,如果输出存档已存在,则会被覆盖;编译器不够智能,无法将文件添加到现有存档中。
- 必须提供一个或多个.proto文件作为输入。可以一次指定多个.proto文件。虽然文件是相对于当前目录命名的,但每个文件必须驻留在其中一个IMPORT_PATH中,以便编译器可以确定其规范名称。
四、使用
查看.h文件可以看到一些通用的方法,这部分方法是根据具体的message中定义的变量名来具体命名,但是它们都有固定的前后缀,如set_、has_、mutable_、clear_、add_、_size等等。
每个message类还包含许多其他方法,可用于检查或操作整个message,包括:
bool IsInitialized() const; //检查是否已设置所有必填required字段
string DebugString() const; //返回message的人类可读表达,对调试特别有用
void CopyFrom(const Person& from); //用给定的message的值覆盖message
void Clear(); //将所有元素清除回empty状态GOOGLE_PROTOBUF_VERIFY_VERSION宏用来验证链接到编译的头文件版本是否正确。
每个protocol buffer类都有使用protocol buffer二进制格式读写所选类型message的方法。包括:
bool SerializeToString(string* output) const; //序列化消息并将字节存储在给定的字符串中。
bool ParseFromString(const string& data); //解析给定字符串到message
bool SerializeToOstream(ostream* output) const; //将message写入给定的C++的ostream
bool ParseFromIstream(istream* input); //解析给定C++ istream到message
bool SerializeToArray(void *data, int size) const; //将message序列化并存储在给定的字节数组中。必须设置所有必填字段。
bool MessageLite::ParseFromArray(const void* data, int size); //从给定的字节数组中解析到message。一般在程序的最后调用google::protobuf::ShutdownProtobufLibrary()方法,来清理被protobuf申请的对象。对于大部分的程序可能是不必要的,因为进程退出操作系统会负责回收所有的内存,但是如果使用的内存泄露检查工具要求释放所有已申请的对象,或者某个进程可能需要加载和卸载多次,可以使用此方法来强制清除protocol buffer中的所有内容。
五、小结
ProtoBuf具有数据结构化和数据序列化的能力。XML、JSON更注重数据结构化,关注可读性和语义表达能力;ProtoBuf更注重数据序列化,关注效率、空间、速度,可读性差,语义表达能力不足。
