




上一章节,我们了解了Ingester将接收的数据存储在LiveTrace结构对象中。这一章节将带来源码解读Ingester是如何根据配置的时间频率和保留LiveTrace在Ingester的时间将数据异步写入持久化存储。
Ingester的启动
在程序启动,初始化Ingester对象时将会注册loop方法至service(在前面章节中接收了service被serviceManager管理生命周期)
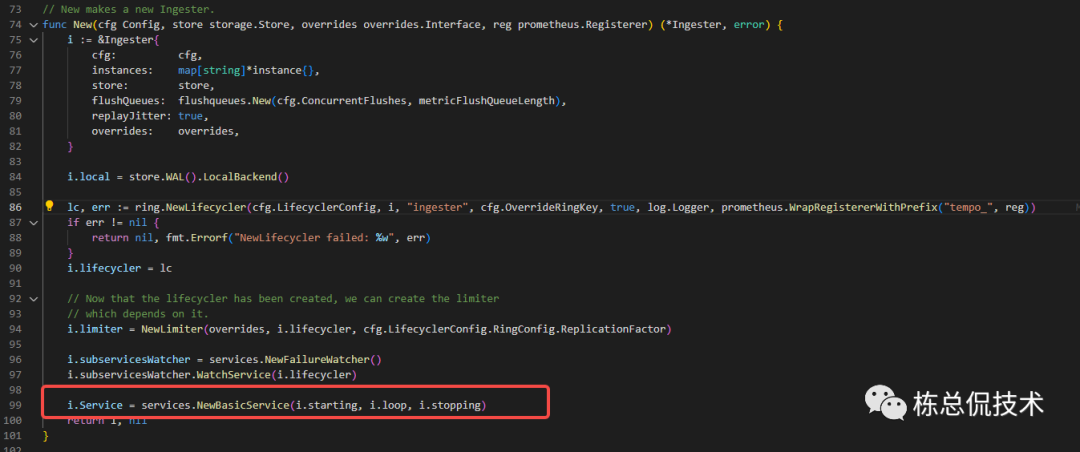
在初始化Ingester时,分别注册了starting、loop、stopping三个函数,分别表示service生命周期三个状态运行的回调函数
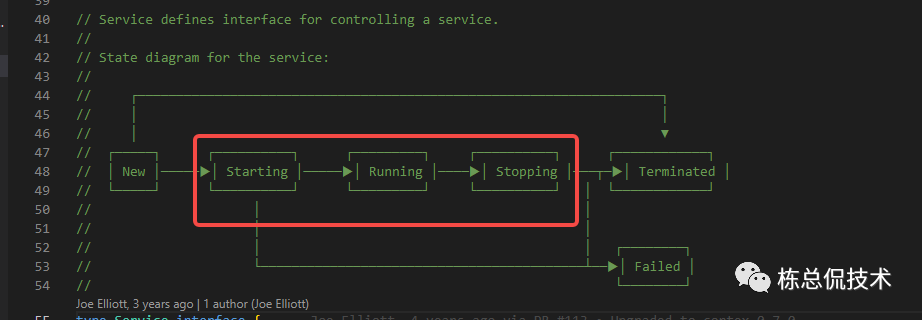
在starting、loop都根据配置启动了若干Goroutine来处理LiveTrace的各个阶段最终将Trace数据写入持久化存储。
loop(ctx context.Context) error
考虑到处理LiveTrace的处理顺序,我们先讲解loop函数
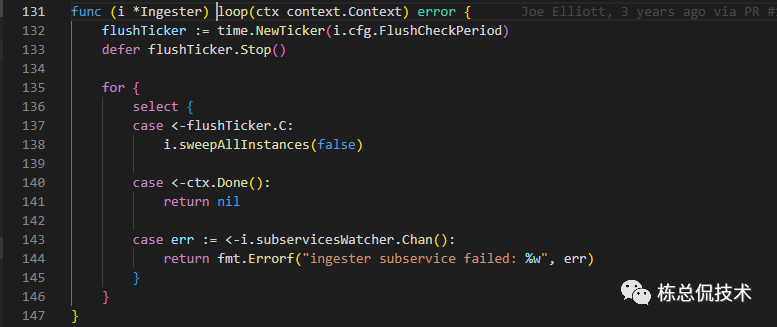
loop函数中根据flush_check_period配置周期性对Ingester中的LiveTrace处理,最终写入completingBlocks,表示当前Blocks正在完成中。
sweepInstance
遍历instances(租户)对LiveTrace数据进行裁剪

获取可以进行裁剪的Trace

tracesToCut
这里用到一个配置项trace_idle_period,表示trace需要在Ingester停留多长时间后才刷新至wal存储(tempodb)。

tracesToCut方法根据满足停留trace_idle_period时间的LiveTrace,将这些trace从租户的liveTrace列表(map)中删除掉。
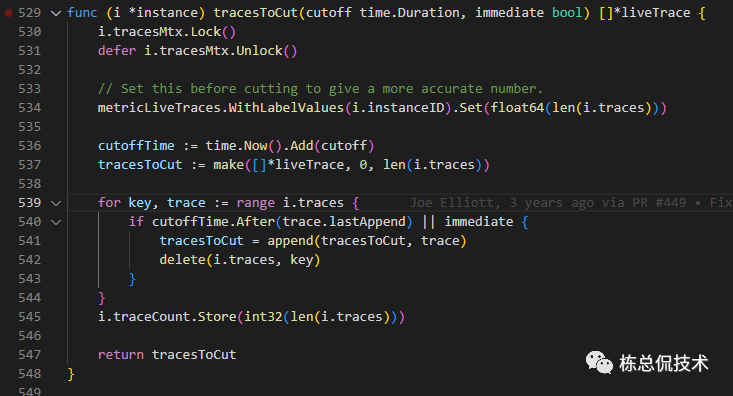
这段代码请大家帮我一起解读下,既然需要LiveTrace保留在内存中trace_idle_period时间,那么
cuttoffTime应该等于当前时间减去需要保留的时间,
小于cuttoffTime时间被添加的Trace应该被裁剪。
所以这里应该是:
cutoffTime := time.Now().Sub(cutoff)
大家觉得这块代码逻辑是否有问题呢?
writeTraceToHeadBlock
将获取的需要裁剪的LiveTrace数据按照TraceID排序后,将trace结构按照指定的编码格式转化为[]byte,并写入headblock(注意这是Trace进入Ingester的第一个中间产物)
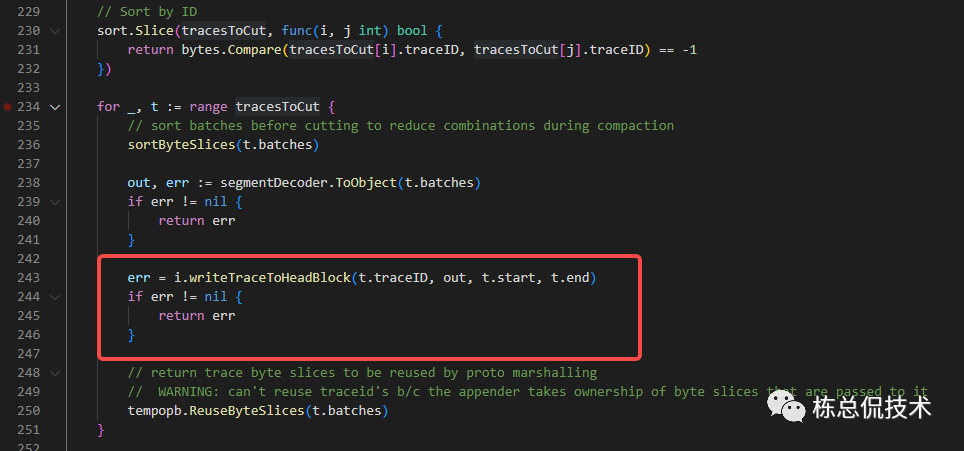
当前版本使用的是v2.Encoding编码格式:

在tempodb\encoding\v2\wal_block.go的struct walBlock 是对应v2版本的编码具体实现。
在这个文件内可以看到将tarce 编码后Append至appender对象的具体实现
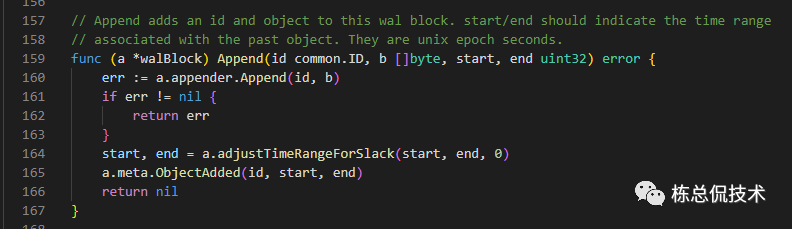
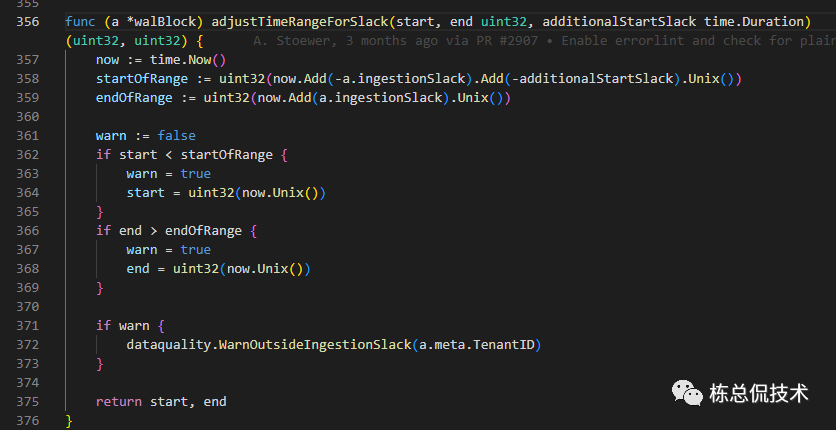
更新当前block的开始时间start、结束时间end
将更新的时间写入·meta(元数据),同时更新存入的object数量、最小的TraceID、最大的TraceID
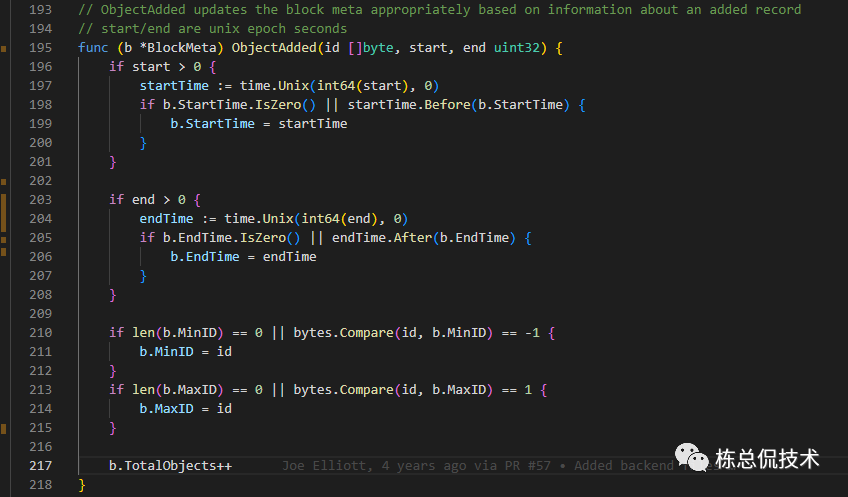
以上就是将LiveTrace写入headBlock的整个过程。
meta.json
我们通过在持久化存储里任意一个block内的meta.json文件,可以看到与BlockMeta的属性是对应的,每个属性具体的含义,参考下面的json文件各属性的说明:
{
"format":"vParquet2", # 编码格式
"blockID":"f3a401c3-69a5-4cf1-90fb-bb74ef5a4f16", # block的uuid
"minID":"B1Oy1T5RxuHjDFC13HIMMw==", #最小traceid
"maxID":"9hdXGVqXaOKogtWkck7FIw==", #最大traceid
"tenantID":"tenant1", #租户名称
"startTime":"2023-12-11T09:02:07Z", # 包含所有trace的开始时间
"endTime":"2023-12-11T09:44:07Z", # 包含所有trace的借宿时间
"totalObjects":20, # 总额span数量
"size":28066, # block的总空间占用
"compactionLevel":4,
"encoding":"none",
"indexPageSize":0,
"totalRecords":1,
"dataEncoding":"",
"bloomShards":1,
"footerSize":9608
}
CutBlockIfReady
我们再回到sweepInstance,在CutCompleteTraces之后,就会执行CutBlockIfReady。CutBlockIfReady会将上一步的产物headBlock进行处理,最终写入completingBlocks对象。
headBlock转化为completingBlocks的时机,依赖两个配置:
max_block_duration:每个租户支持保留的block的时间
max_block_bytes:每个租户支持保留的block大小
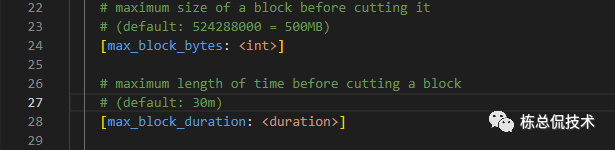
CutBlockIfready判断时间、大小满足要求后,将headblock赋值给compltingBlocks,同时重置headblock,最终返回这个block的ID。
记录这一次转化为compltingBlocks的操作至enqueue,类型为opKindComplete。

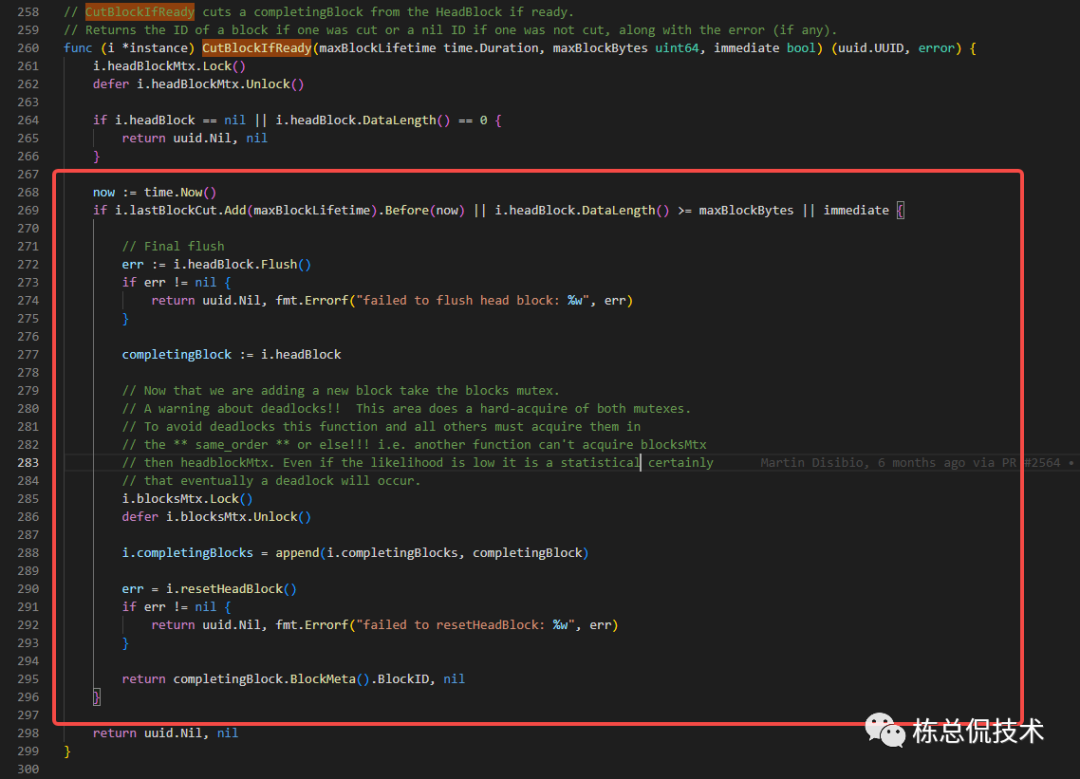
starting
在staring函数中将会启动若干Goroutine将上一步产生的compltingBlocks真正的写入tempodb,且将写入成功的compltingBlocks转化为completeBlocks。
flushLoop
在flushLoop中根据配置concurrent_flushes的个数并发启动Goroutine来并发处理compltingBlocks。
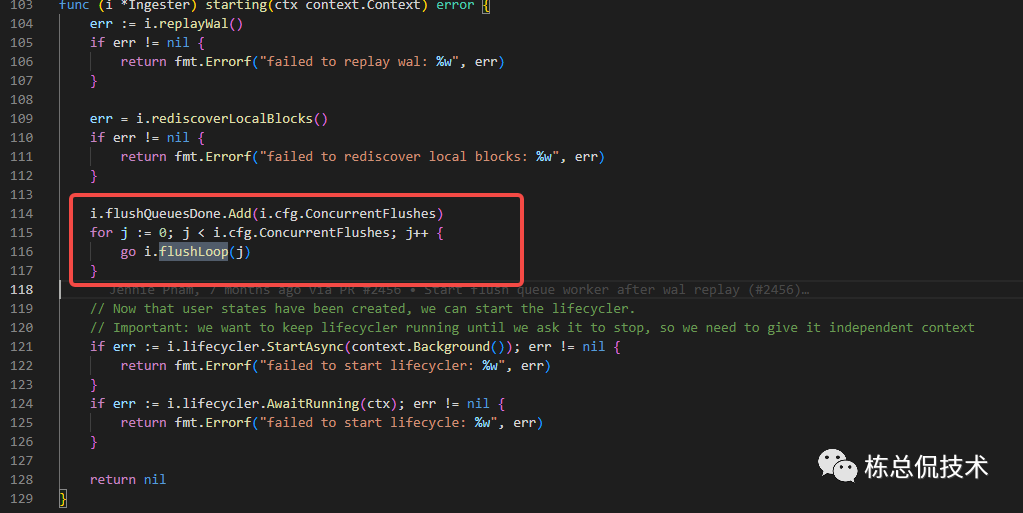
handleComplete
handleComplete是将数据写入tempodb的过程。写入成功后将compltingBlocks转化为completeBlocks。
这里的writer 是个Interface,具体的实现是一个存储在内存的存储数据库tempodb。
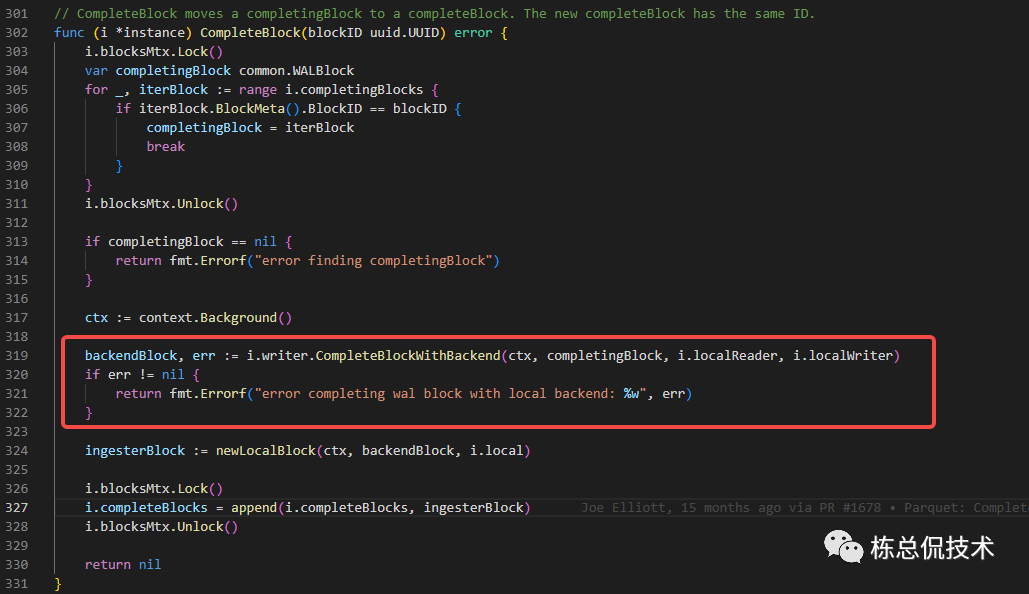
如果写入tempodb失败,会重试maxCompleteAttempts次数(3次)
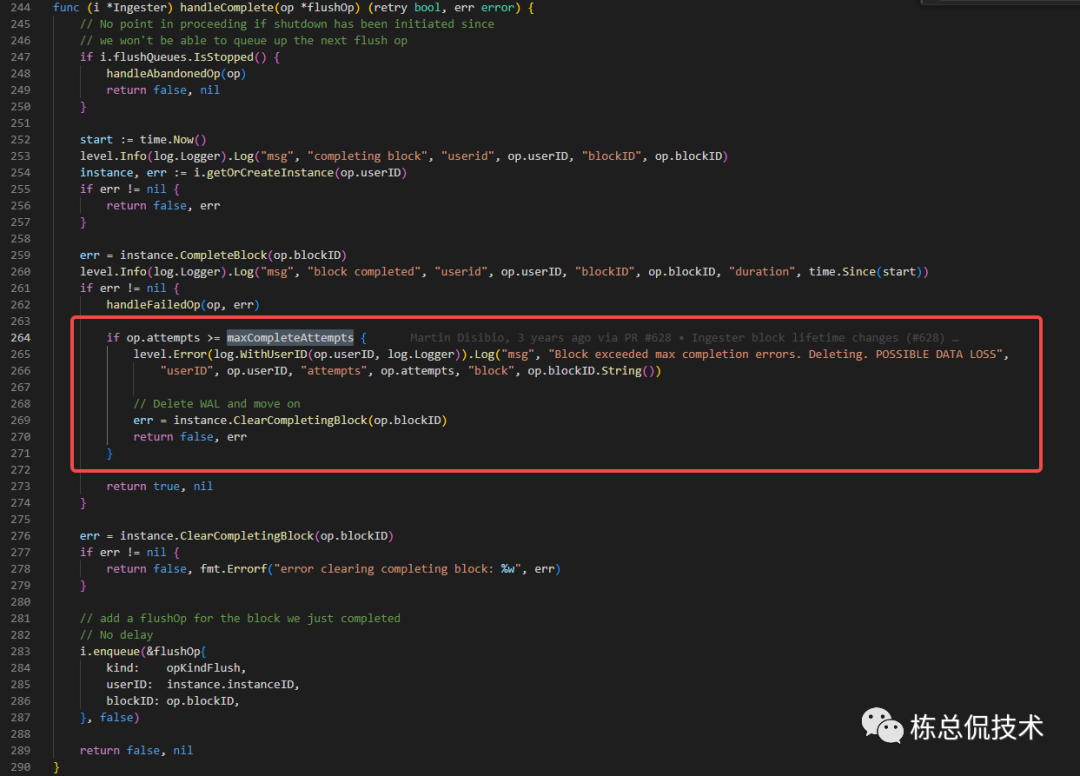
ClearCompletingBlock
如果CompletingBlock成功转化为completeBlocks(表示已经写入到维护的tempodb),需要清理对应的CompletingBlock,并释放对应的内存空间。

最终又会记录这次转化操作至enqueue,只是操作类型与上一步不同为opKindFlush。
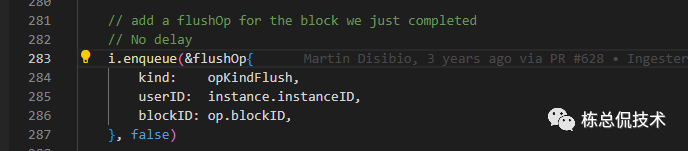
handleFlush
再次回到flushLoop,在该函数中同时也会根据ClearCompletingBlock中记录的opKindFlush操作执行任务。
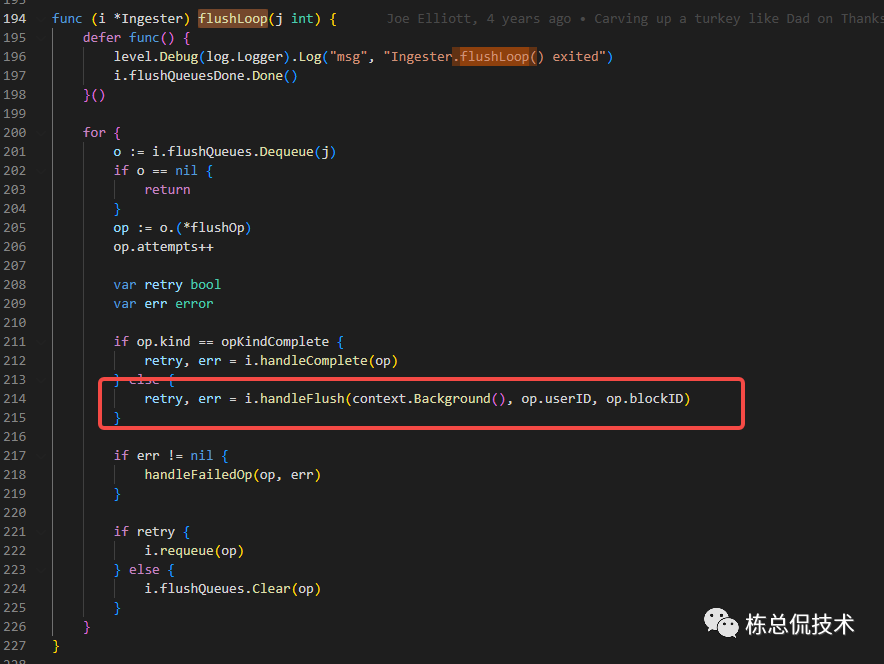
在handleFlush中会从completeBlocks中取还未flush的Block(flushedTime为0)
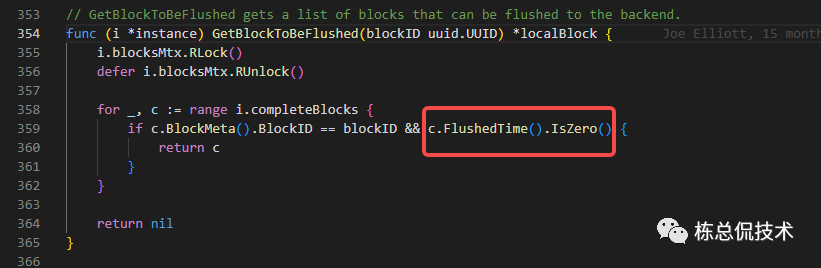
然后写入store
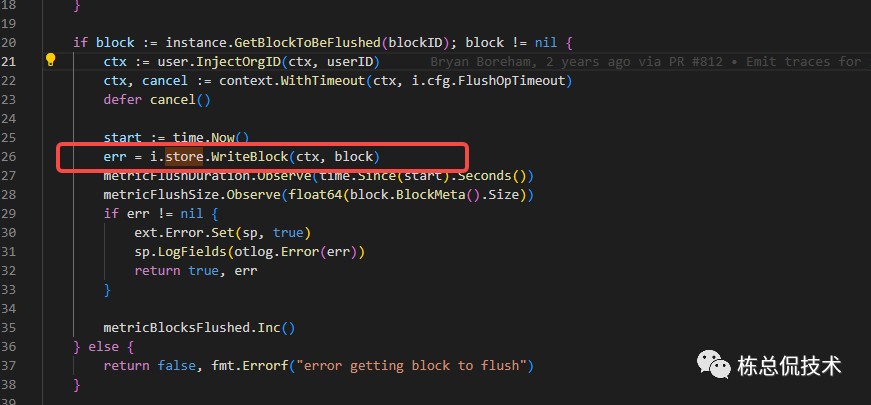
store在最开始初始化app时按照各模块的依赖已经初始化,表示对应使用的存储,所以到这里才是真正的写入持久化存储。

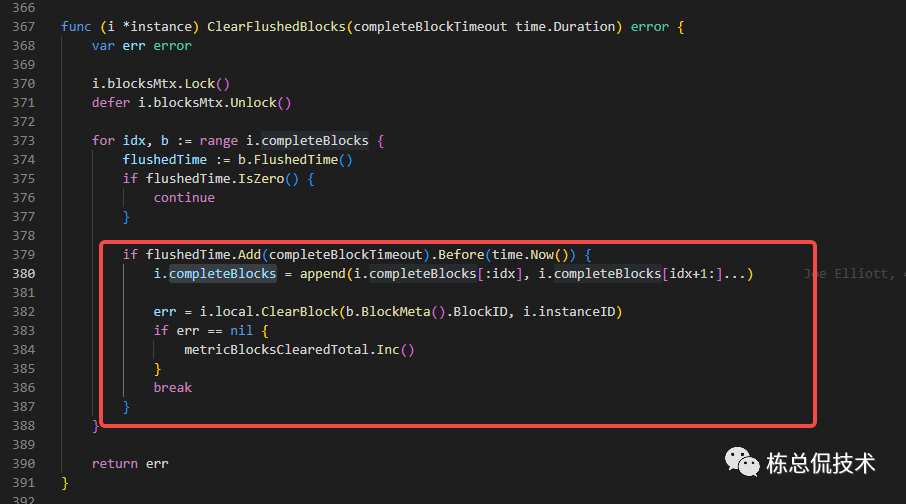
ClearFlushedBlocks
completeBlocks写入存储后,会继续保留配置的complete_block_timeout时长,超过complete_block_timeout时间后,将会对completeBlocks进行清理,并释放对应的内存空间。
complete_block_timeout配置表示被写入存储后,block在Ingester中还保留多长时间

达到保留时间后,Ingester将会从内存中彻底清理掉已经写入存储的completeBlocks。
Enqueue
在上述将headblock转化为CompletingBlock和将CompletingBlock转化为completeBlocks的两个过程都有将操作记录至Enqueue

在Enqueue中,会等待10秒钟首先判断处理下一步任务的flushQueues是否已经停止
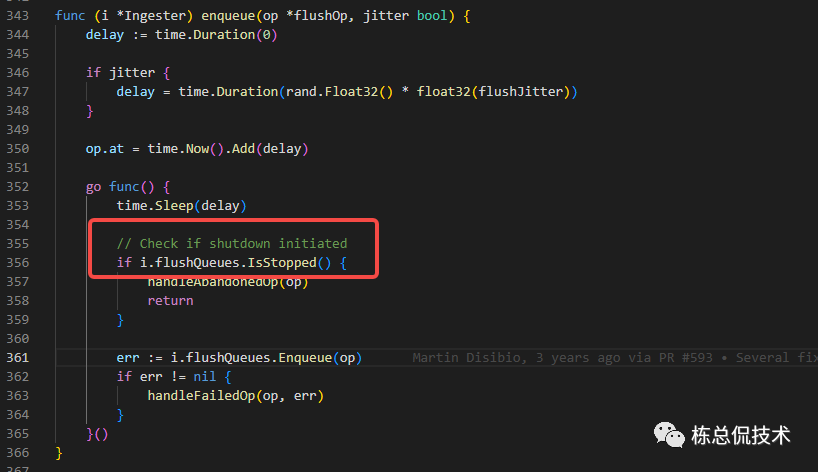
若已经停止,则记录日志
Abandoning op in flush queue because ingester is shutting down
再检查对应的处理过程是否已经处理完成

若未处理完成,会重新排入队列
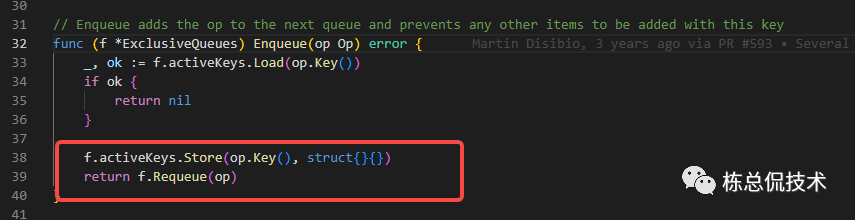
若出现异常,则会记录错误日志
error performing op in flushQueue
通过判断activeKeys中是否存在当前操作的key认为任务是否完成:
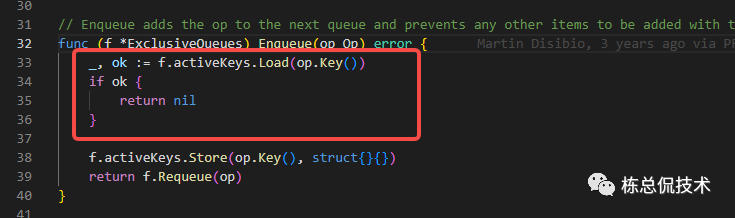
再次回到flushLoop,可以看到在执行完任务后将会对Queues进行清理,此时会释放cativeKey里对应的opKey
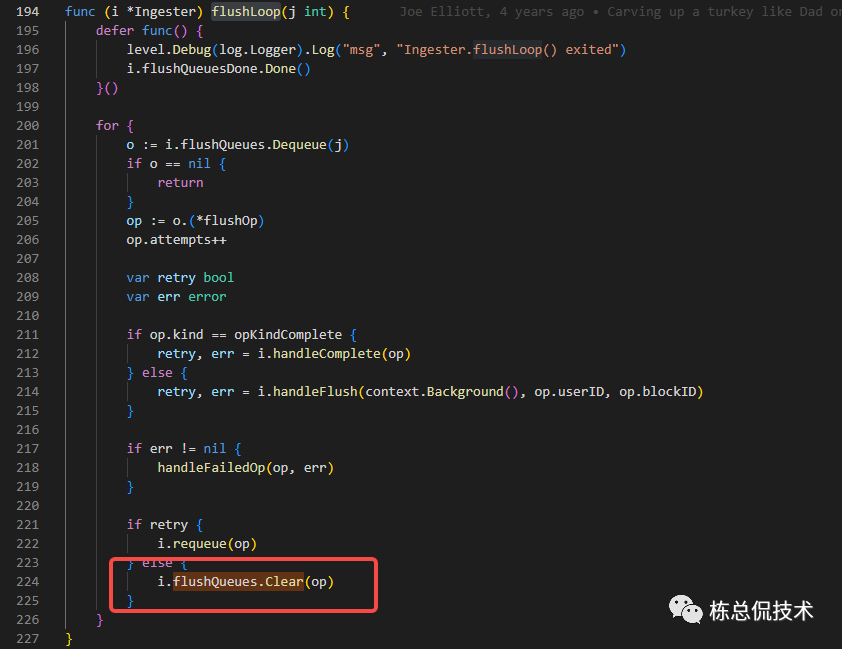
当然,这里在处理失败后会给一次重试的机会。
所以在出现上述错误日志时,需要考虑增加 concurrent_flushes 配置。
以上为Ingester接收指标到指标写入存储的整个过程。结合对Distributor代码的解读,已经完成了Trace数据写入过程的完整解读。
阅读过前面系列文章的读者应该知道从数据进入到Distributor到Ingester写入存储,经过了很多的过滤和拦截判断。下一节将会带来所有的拦截判断和对应的错误日志输出、错误返回信息、错误指标信息,以及对哪些配置进行调整优化的汇总讲解。
这里再留下一个值得讨论的问题,在Tempo中多次作业处理的过程是通过维护的队列+锁+Goroutinue实现的,其实以上的过程很容易联想到FanOut模型,如果使用FanOut模型结合着Go的Goroutinue和Channel机制,是否能够进一步的提升效率和简化上述代码呢?
往期回顾:
Grafana Tempo源码解读(三)Ingester组件接收Trace数据的过程
Grafana Tempo源码解读(二)Distributor对Trace数据的处理和发送至Ingester
Grafana Tempo源码解读(一)Distributor建立监听接收Trace数据
