




在上一章节了解了Distributor组件对Trace数据的处理后,Distributor将会通过Grpc接口PushBytesV2将数据发送给Ingester组件,这一节我们就从PushBytesV2方法为入口,通过阅读源码了解Ingester组件的数据接收流程。。
PushBytesV2
直接代码全局搜索PushBytesV2,将会在modules\ingester\ingester.go文件中找到函数的实现。

#readonly
判断是否只读

返回只读Error
ErrReadOnly = errors.New("Ingester is shutting down")
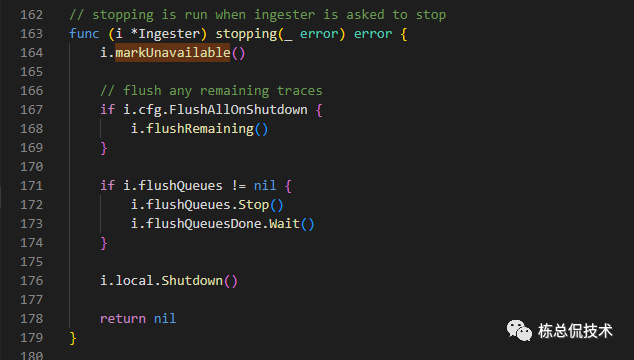
通过搜索readonly变量,可以看到在程序退出前,会将实例标注为Unavailable,设置readonly为true。
getOrCreateInstance
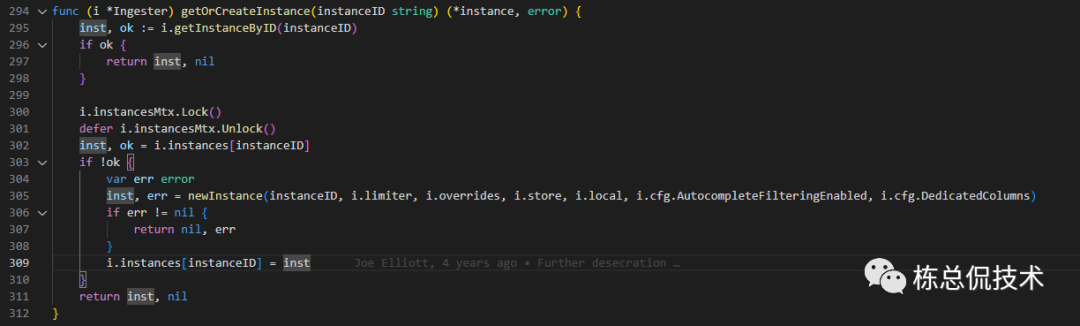
读取租户信息,根据租户名称获取或创建Instance,一个Instance对象表示对一个租户数据处理的管理对象。

从instances(map[instanceID]instance)中根据租户名称获取Instance,不存在则创建Instance。
newInstance
创建Instance会根据限流参数等封装Instance结构,同时会resetHeadBlock
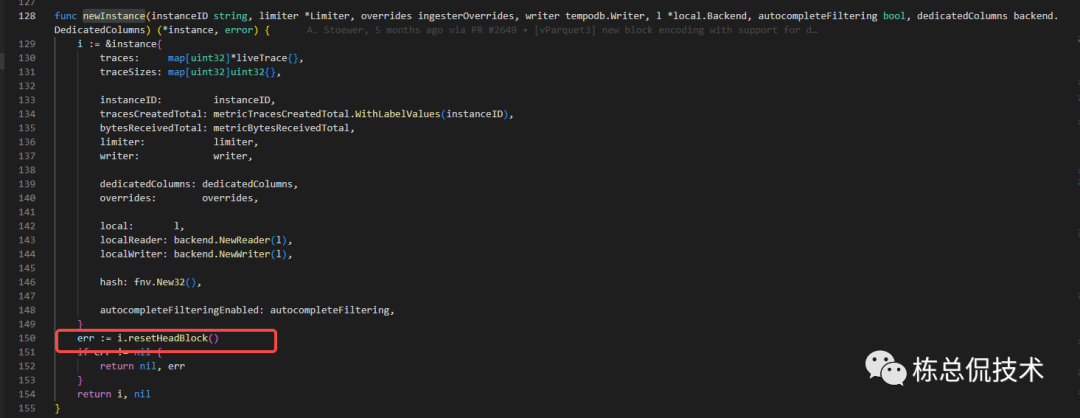
resetHeadBlock将会重置一个携带uuid的block,后续需要将数据写入持久化存储,就是对这个block的处理。
PushBytesRequest
遍历当前Instance(租户)的所有Trace数据包,对Instance内的Trace进行处理,根据一些条件(由配置决定)是否需要写入持久化存储、是否需要从Ingester的内存中清理掉

PushBytes
记录指标
measureReceivedBytes将累加记录接收的总Trace包大小,通过/metrics接口供Prometheus采集业务监控的指标。

判断TraceID是否合法(长度为16位)

判断是否超过租户支持的LiveTrace数量
LiveTrace表示Ingester已经接收,但是还未写入存储并从内存中清除掉的Trace数据。

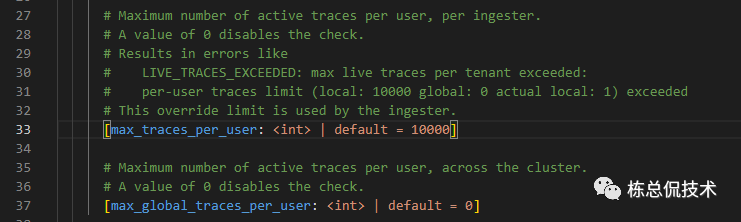
租户支持的LiveTrace数量由两个参数决定max_traces_per_user
、max_global_traces_per_user
,若为0则不进行限制。
max_traces_per_user
由Instance的单个实例所拥有,表示单个Ingester实例的限制数量
max_global_traces_per_user
由所有的Ingester实例共有,表示总的Ingester限制数量,那么单个Ingester实例的限制数量= max_global_traces_per_user/ 实例数量
若两者均配置,则取两者中较小的那个非零值。
而limit现在大小由globalLimit对应的单个副本的限制大小、和localLimit较小的值决定。globalLimit表示总的限制,单个的限制大小=总限制/存活的副本数*设置的副本数

单个租户接收Trace包的限流
判断当前租户的liveTrace包大小+即将接收的Trace包大小是否超过配置的单个租户最大Trace(max_bytes_per_trace)
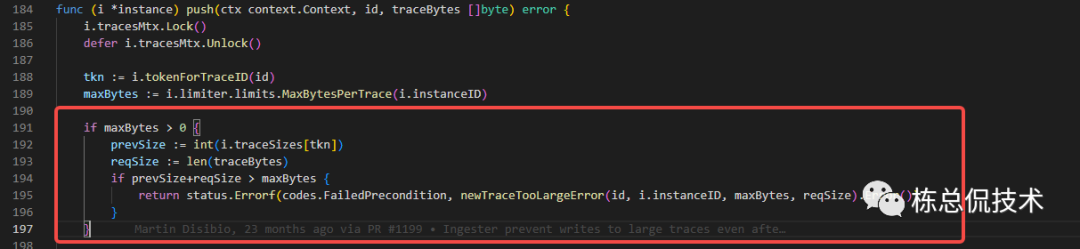
max_bytes_per_trace默认值为5MB
LiveTrace
具有相同TraceID的多个Trace对象将会存储在一个LiveTrace对象中,在Instance中维护了一个Map,key为对TraceID hash后的tkn,通过tkn从Map中取是否具有当前TraceID的LiveTrace对象,有则直接返回,没有则创建一个新的返回。
可能同一个调用链经过若干个微服务,每个微服务发送这条trace中的若干个span,,所以一条Trace的多个Span组在不同的时间到达Ingester。

将当前接收的Trace数据写入Livetrace对象,并更新当前Instance(租户)的traceSizes
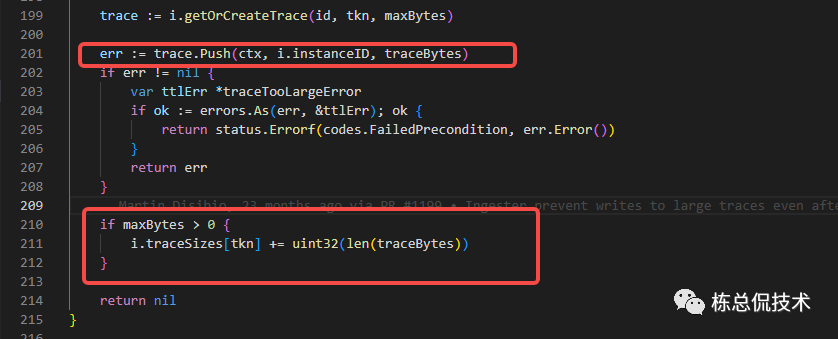
判断LiveTrace的数据包大小是否超过配置值
在liveTrace.Push(ctx, i.instanceID, traceBytes)方法中,累加之前接收的span大小,再次判断Trace当前的总包大小是否超过最大支持。
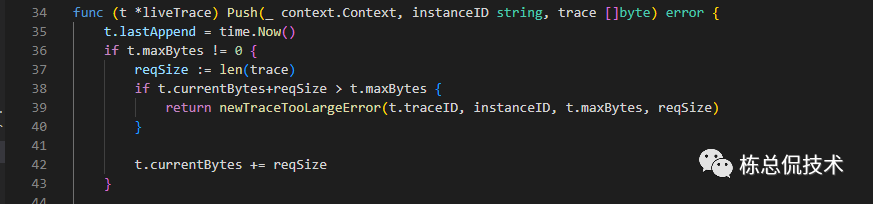
该限制由配置max_bytes_per_trace决定,默认支持5MB
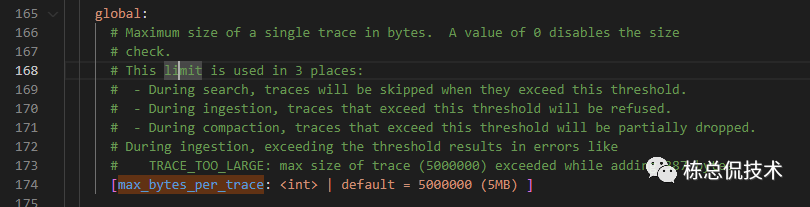
global:
# Maximum size of a single trace in bytes. A value of 0 disables the size
# check.
# This limit is used in 3 places:
# - During search, traces will be skipped when they exceed this threshold.
# - During ingestion, traces that exceed this threshold will be refused.
# - During compaction, traces that exceed this threshold will be partially dropped.
# During ingestion, exceeding the threshold results in errors like
# TRACE_TOO_LARGE: max size of trace (5000000) exceeded while adding 387 bytes
[max_bytes_per_trace: <int> | default = 5000000 (5MB) ]
对Trace的span进行排序后,将Trace的SpanAppend至LiveTrace,同时更新当前LiveTrace的开始时间、结束时间
到这里Ingress就完成了数据的接收完整的代码解读。Ingester接收的Trace数据最终会存储在LiveTrace结构的对象中。下一章节将会带来源码解读Ingester是如何将LiveTrace写入持久化存储以及从内存中清空LiveTrace对象的。
