




数据的质量和标签的准确有效对用户营销的最终效果起到了决定性的作用。为此,沉淀出一套适合当前业务的离线大数据质量保障方法,提供可被参考和复用的场景解决方案是非常有必要的。
1 测试背景
网易支付建立了一套用户标签体系,用以对支付亿级别的用户池进行用户分层,精准地找出活动高配人群实施有效的用户营销策略,最终提升交易金额占比。
用户标签体系基于大数据的离线计算和分析,覆盖用户域、交易域、风险域和营销域等,数据的质量和标签的准确有效对用户营销的最终效果起到了决定性的作用。
为此,沉淀出一套适合当前业务的离线大数据质量保障方法,提供可被参考和复用的场景解决方案是非常有必要的。
2 测试目标
用户标签数据是通过离线ETL过程从源系统载入数据仓库,再通过数据仓库各层的ETL处理,最终计算出业务需要的数据。通过大数据离线ETL的测试,主要实现以下三个目标:
1)验证数据是否已按预期方式转换并加载到目标系统。
2)验证数据质量是否具备完整性、一致性、唯一性、准确性和合法性。
3)验证用户标签的业务逻辑处理是否符合预期。
3 测试方法
3.1 数据链路
在进行大数据测试之前,首先需要了解数据的流转过程,这样才能对流转过程中的环节进行有针对性的测试。大数据处理可以分为三个部分:数据采集与存储、数据计算、数据输出与展示。
数据采集与存储就是将业务系统产生的数据、日志等同步到大数据平台的HDFS进行存储,主要采用离线传输的方式实现数据的全量和增量同步。然后通过Hive构建分层的离线数仓,每一层都表示在上一个数据层处理的结果,分为数据接入层(ODS)、数据明细层(DWD)、数据汇总层(DWS)和数据应用层(ADS)。
数据计算是大数据处理的核心,可以分为批处理、流计算、查询分析和图计算。数据同步系统导入的数据存储在HDFS,MapReduce、Hive、Spark等计算任务读取HDFS上的数据进行计算,再将计算结果写入HDFS。
大数据计算产生的数据还是写入到HDFS,但业务系统不可能到HDFS中读取数据,所以必须要将HDFS中的数据导出到数据库中,导出后业务系统、报表系统等就可以直接访问数据库中的数据,实时展示给用户或提供各种统计报表。下图所示为基于大数据平台的离线数据流转过程。

3.2 数据血缘
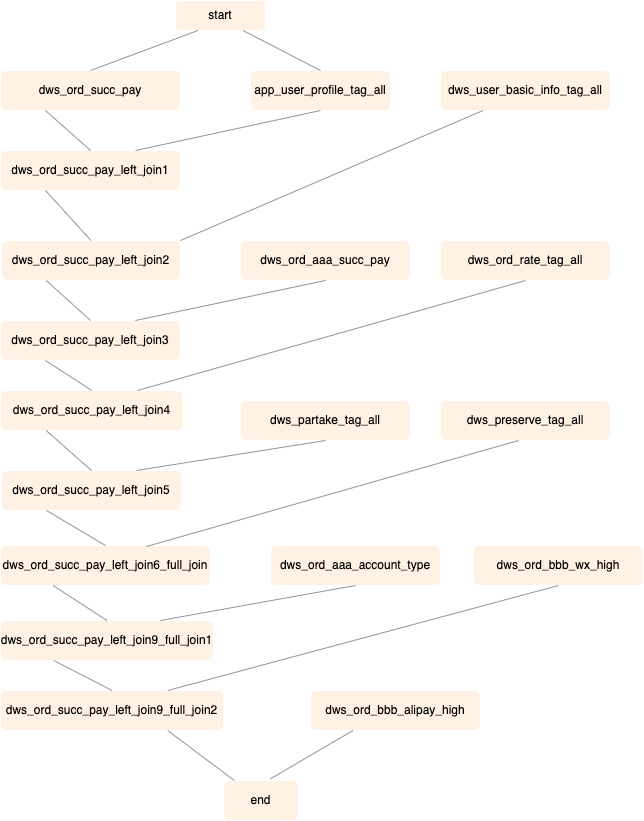
了解数据整体链路后,我们针对具体离线任务进行血缘关系分析。下图所示为用户标签实际业务场景的血缘关系图,从中可以看到数据来源的多样性、数据的可追溯性和数据的层次结构。一个任务调度流从start到end经过了多层数据流转,即存在多层血缘关系。借助血缘关系图,并结合业务逻辑来分析数据转换前后的数据量和数据值的一致性。
3.3 数据验证
数据结果验证的要求可以从以下几方面考虑:
1)计算过程符合业务逻辑、运算符及函数使用正确。
2)异常值、脏数据、极值以及特殊数据(零值、负数等)的处理符合预期,字段类型与实际数据一致。
3)主键构成合理,按照去重规则对记录进行去重处理。
4)数据输入、输出满足规定格式。
具体地,结合业界数据质量评估标准,可以从完整性、一致性、准确性、唯一性、业务逻辑等方面进行检查。
3.3.1 完整性
完整性是数据质量的基础保障。在进行数据的完整性校验时,通过缺失值分析检查字段的完整性,通过表基础分析检查记录的完整性。数据缺失主要包括整行记录的缺失和记录中某个字段信息的缺失。表基础分析包括分析表中的数据量和数据量波动。
1)统计字段信息的缺失数量和缺失率
select
count(*) as total_rows,
count(case when user_id is null then 1 end) as missing_values,
count(case when user_id is null then 1 end) / count(*) as missing_percentage
from dws_user_offline_label;
2)统计分区表各分区记录数
select date_version, COUNT(*)
from dws_user_offline_label
where date_version >= concat(substr(md5('20231124'),1,8),':')
group by date_version;
3.3.2 一致性
数据的一致性是指数据来源、存储和数据口径是否统一,检查项主要包括数据记录规范的一致性、数据逻辑的一致性和数据记录的一致性。
1)多项数据间固定逻辑关系一致
SELECT COUNT(*), IF(COUNT(*) > 0, 'fail', 'pass')
FROM dws_user_offline_label
WHERE (obspwboa_30d > 0 and obspwboa_30d <=0) OR (obspwooc_30d > 0 AND obspwooc_30d <= 0);
2)数据流转前后数据记录一致
select count(*), if(count(*) > 0, 'fail', 'pass')
from (
select user_id from dws_ord_succ_pay_order where partition_date = '20231112'
union all
select user_id from dws_ord_succ_pay_order where partition_date = '20231112'
) t
left join (
select user_id
from dws_user_offline_label
where date_version = concat(substr(md5('20231112'),1,8),':')
) t1 on t.pay_user_id = t1.pay_user_id
where t1.user_id is null;
3.3.3 准确性
数据的准确性是指数据记录的信息是否存在异常或错误。使用异常值分析、值域分析、数据分布分析和功能相关性分析等方法来检查数据的准确性。
1)数据格式为数值且最多保留4位小数
SELECT COUNT(*), IF(COUNT(*) > 0, 'fail', 'pass')
FROM dws_user_offline_label
WHERE (obspwboa_30d REGEXP '^[0-9]+(\.[0-9]{1,4}})?$' = 0); -- 0表示不匹配
2)字段是否为空、为NULL或 NULL字符串
SELECT COUNT(*), IF(COUNT(*) > 0, 'fail', 'pass')
FROM dws_user_offline_label
WHERE (length(user_id) = 0 or user_id is null or lower(user_id) = 'null');
3)字段枚举值的数据分布
SELECT pwu, count(pwu) frequency
FROM dws_user_offline_label
group by pwu;
3.3.4 唯一性
唯一性主要分析表数据中主键是否唯一,确保数据无重复记录。检查主键唯一性的方法比较简单。
SELECT COUNT(user_id), COUNT(distinct user_id)
,IF(COUNT(user_id) = COUNT(distinct user_id), 'pass', 'fail')
FROM dws_user_offline_label
WHERE date_version = concat(substr(md5('20231128'),1,8),':');
4 业务逻辑
考虑到更加定制化的业务标签校验和不依赖于模板或自定义规则的独立性,我们可以针对具体的业务标签独立开发离线业务核对表,更加灵活和直观的进行数据质量监控。建表流程包括创建Hive表、写入业务监控标签、配置质量监控、配置线上调度和报警、生成质量报告。
4.1 创建Hive表
1)如果表已经存在,先进行删除再创建临时表。
2)临时表命名符合规范:datawarehouse_temp.temp_xxx。
3)建表字段都使用comment注释。
drop table if exists datawarehouse_temp.temp_xxx;
create table if not exists datawarehouse_temp.temp_xxx (
id string comment '账号id',
id_before string comment '账号id-打通前',
......
) COMMENT '标签核对表'
partitioned by (partition_date string)
STORED AS PARQUET;
4.2 写入监控数据
1)采用insert overwrite table方式覆盖写入。
2)用select查询语句选择要插入到监控表的数据。
3)使用多个子查询实现复杂逻辑的数据选取。
insert overwrite table datawarehouse_temp.temp_test partition (partition_date = ${dateBefore})
select t.id, t1.id, t2.id, t3.id
from table_1 t1
left join table_2 t1 on t1.id = t2.id
left join table_3 t3 on t1.id = t3.id
......
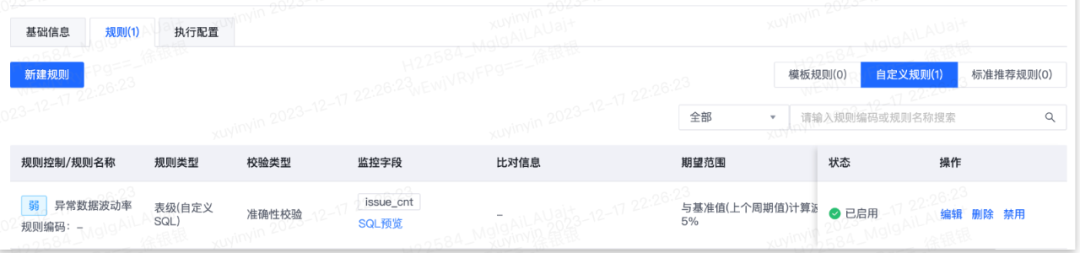
4.3 配置质量监控
1)数据质量监控可以定时检查数据质量,在任务运行完成后立即触发质量规则校验,第一时间感知问题数据。
2)不同强弱的规则决定任务节点在数据质量不达标时是否失败退出,有效阻止脏数据向下蔓延、扩大影响。
4.4 线上调度和报警
1)离线任务开发完成上线后,可设置调度时间、任务依赖上游、执行队列、优先级、失败设置等。
2)可在任务或节点运行开始、运行超时、运行失败、运行完成、运行超时时触发报警并通知责任人。
3)为了保证数据产出的及时性,对调度优先级越高的任务,设置更加严格的告警规则。

5 数据监控
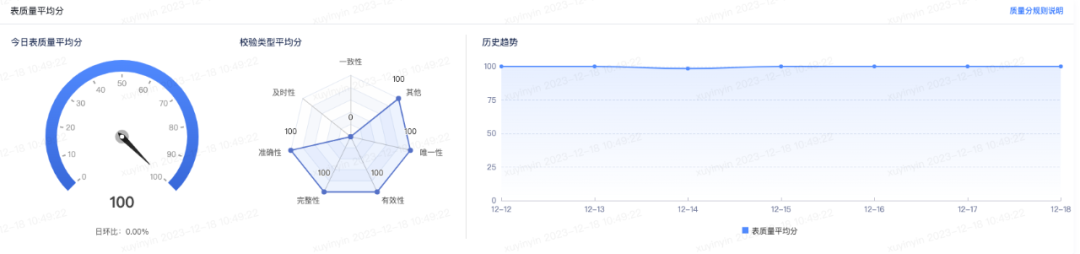
当次任务运行结果的验证,是一次性的、静态的过程,通常在数据处理流程的早期进行。而数据质量监控是连续性的、动态的过程,可以在数据处理流程的各个阶段进行。加上数据质量问题繁杂,人工检测效率低且不全面,通常会使用数据质量监控平台来进行质量风险监控。下图所示为通过稽核校验来监控数据质量的执行流程图。

-- End --
点击下方的公众号入口,关注「技术对话」微信公众号,可查看历史文章,投稿请在公众号后台回复:投稿
