




站在开发的角度,我们通常需要评估改动影响的范围,站在测试的角度,我们需要知道要怎么测,测的怎么样了?精准测试能很好的解决这些问题,这有助于提升项目的质量,同时降低研发和测试的工作量。但是目前市面上一些优秀的精准测试平台都很"精准"的避开了前端的精准测试,为此我们只能自己在这上面做个探索!
理解含义
百度百科:精准测试是一套计算机测试辅助分析系统。精准测试的核心组件包含的软件测试示波器、用例和代码的双向追溯、智能回归测试用例选取、覆盖率分析、缺陷定位、测试用例聚类分析、测试用例自动生成系统,这些功能完整的构成了精准测试技术体系。
我们简单点理解:就是准确分析出改动影响到的范围,自动生成(推荐)测试用例的过程。
需求背景
基于过去的一年,支付前端至少有三分之一的线上问题都是由于漏测、场景评估遗漏所导致,我们探索一种可以快速评估影响范围的工具,于是精准测试就进入了我们的视野。当下市面上有不少精准测试平台,比如smartEye,星云测试,云音乐的天玑平台以及各个部门自己搭建的未命名测试平台等等,不过这些工具都只做了服务端以及少量的移动端精准分析,前端精准测试的讨论一般都是浅尝辄止,于是我们打算自己在前端精准测试上做一个探索实践。
面临困难
为什么做前端精准测试会比较少呢?我认为归根究底还是因为性价比相对较低。「前端出现问题的严重程度相对较低,实现前端精准测试的复杂度相对较高」。从支付金融行业来说,前端问题也可能是个大问题,所以保障质量是非常重要的事情,那么就让我们看看前端精准面临的一些困难吧。
缺少相关成熟的基建
精准测试中非常重要的一环就是覆盖率的计算和统计,这块我们一般会采用一些开源的产品,如下:
| 编程语言 | 代码覆盖率工具 | star | 更新评率 |
|---|---|---|---|
| JAVA | JaCoCo | 3.9K | 常更新 |
| C/C++ | Gcov | 8.3K(GCC) | 常更新 |
| PHP | xdebug | 3K | 常更新 |
| Python | Coverage.py | 2.7K | 本月内有更新 |
| GO | GoCov | 0.8K | 8个月前 |
| Javascript | istanbuljs | 0.9K | 3年前 |
看的出来js的覆盖率工具不管是维护度和star都是比较低的(而且是唯一选择),在这期间我们需要做不少的兼容(成本依旧低于新开发),当然这个还不是重点,要知道js只是前端三架马车中的一架而已,另外的HTML和CSS就没有覆盖率统计工具,这个都需要需要我们自己来实现。
开发语言带来的困难
比起java这些可以直接做静态语言分析的语言,前端三架马车的分析则尤为困难,一方面js作为动态语言,无法通过调用链分析做出完整的链路分析,同时由于其作为弱类型语言的特点,代码书写异常灵活,全局变量可能会泛滥使用。另一方面,html和CSS作为界面和样式代码,和一般的语言执行有着本质上的区别,无法通过插入执行代码(插桩)的方式来监控代码的执行情况。那HTML和CSS应该如何来进行代码遍历?最后就是3驾马车之间的互相纠葛,互相影响,又给代码分析带来了更大的困难,如下图
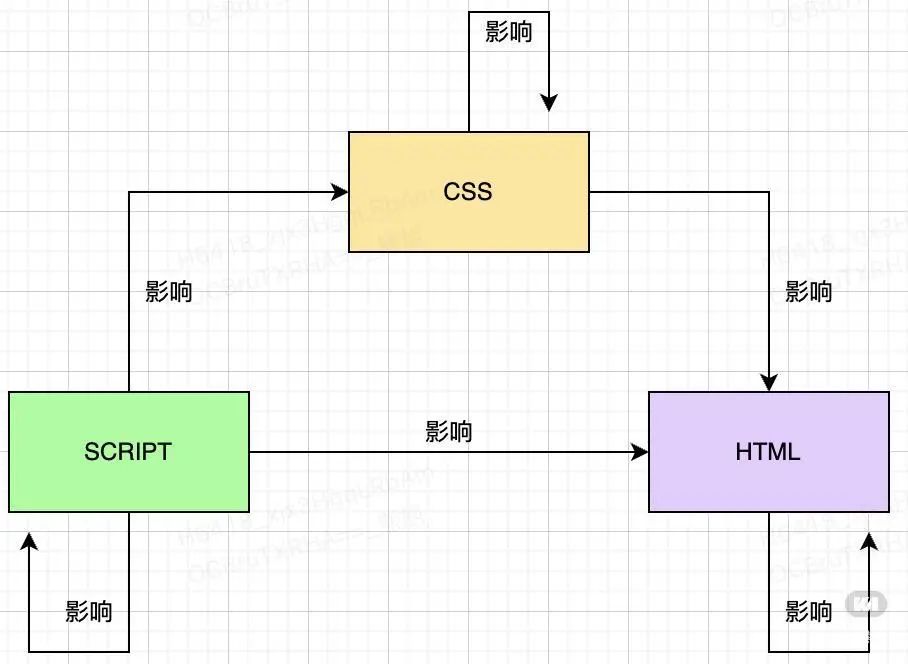
层出不穷的框架模板
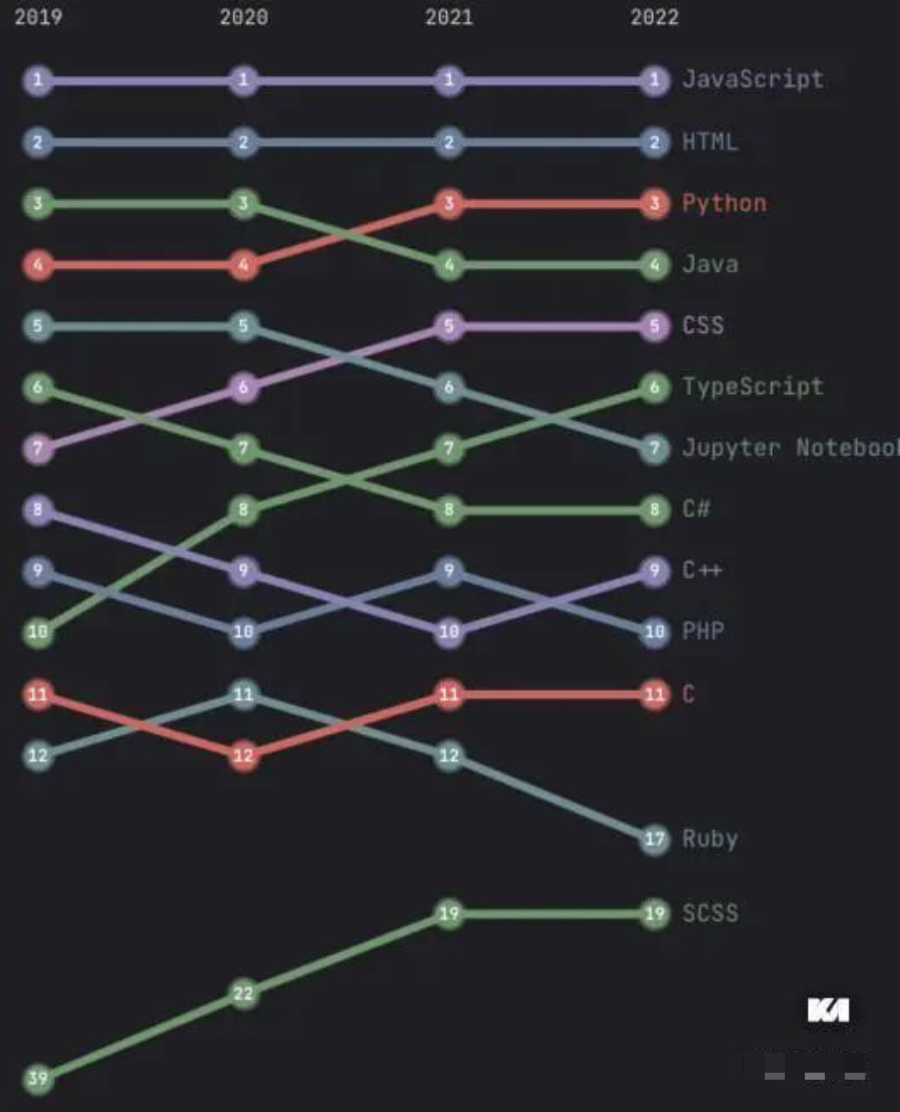
总所周知,前端框架的数量非常的多,迭代频率也非常高,从github的更新排行版上就能看得出来,三架马车分列1,2,5名,还有加速增长的ts和scss,比起其他端可以说遥遥领先。
三架马车每个都有非常多二次封装的框架,不同框架的写法又多种多样,给代码分析带来了很大的困难。即便是同一个框架依旧有多种写法,就拿vue来说,分别有Composition API、ts+class、setup、jsx等多种写法,每种写法在代码范围分析上又有一定的差异,所以繁多的框架模板也是前端精准分析测试的一个大难点。
难以维护的UI用例
精准测试还有很重要的一点就是UI测试用例推荐,不同于后端较为稳定的接口服务,页面的改动会更加的容易频繁,而任何一个改动都可能会导致测试用例的变更,所以UI测试用例的维护也是一个很大的工作量,基于大部分团队人力问题,UI测试用例很难做到常更常新。这也会成为制约精准测试的一个点。
解决方案
如何给代码打桩
基于以上难点,我们需要一个一个来想办法解决,首先要解决的就是基建问题,js已经有了Istanbuljs来做代码打桩和覆盖率的收集,那么html和css该如何来做呢?
首先看看js的打桩原理:1)分析js,解析成AST树,2)遍历AST树,在每一个可执行节点前插入一段打桩代码,按照js顺序执行的特点,只要打桩代码被执行到了,那后面这段代码自然也会被执行到。3)打桩代码执行的时候就会在全局变量中做记录,从而统计到执行情况,4)将数据上传到服务器,汇总分析后实现覆盖率的统计。
html和css显然没有办法通过插入执行代码的方式来实现覆盖率统计的。从执行层面来说,html和css最终还是以UI的方式呈现给用户看,用户看到了那就等于代码执行到了,而用户是否看到取决于内容是否在浏览器可视界面出现过,所以HTML的代码覆盖率完全可以从页面元素的曝光度来做统计了。Intersection Observer API提供了一种异步检测目标元素与祖先元素或 viewport 相交情况变化的方法。比起传统的scorll+getBoundingClient模式,IntersectionObserver 是一个异步API,不会阻塞GUI渲染线程,同时在代码上也更加的简单。当然这个API是有兼容性问题的,那就加个polyfill呗,甚至不加问题也不大,毕竟仅在测试环境使用的话又有多大关系呢!
const observer = new IntersectionObserver(callback, options)
observer.observe(xxx)
既然定下来了判断HTML覆盖的标准是曝光,那实现打桩也就比较容易了,通过对HTML的AST分析,把元素所在的源码信息(文件、行列等)作为属性放在标签上就可以嘞。最后运行的时候动态获取页面上打上了这些标的元素,再通过IntersectionObserver监听就好了
....
// 创建需要插入到元素上的属性
let injectAttr = `$1 x-sweeper-path="${this.filePath}" x-sweeper-html="${htmlRangeInfo}"`
.....
// 查找页面上所有需要监听的元素
document.querySelectorAll("[x-sweeper-path]")
.....
解决完HTML,那css又该如何打桩呢?其实CSS不用单独打桩,因为css是无法单独存在的,作为样式最终效果都体现在了html上,所以只需要判断当前的CSS改动影响了哪些HTML,然后将这些改动的HTML打上桩就好了。
如何做影响分析
前面我们分析了如何给3架马车去打桩,接下来的要做的就是明确要给哪些代码打桩。回到需求背景,精准测试是为了解决漏测,范围评估遗漏的问题,所以需要打桩的代码就是改动的代码以及被影响的代码。改动的代码比较的容易获取,直接使用api从gitlab上拉取diff就好了,影响的代码才是一个非常大的难点。回看图1,除了会影响自身,css的改动会影响html,js的改动会影响css和html,此外页面模块之间还存在相互引用和相互影响。接下去,我们就从单文件影响和跨文件影响分析两个方面来探讨这个问题。
单文件影响分析
在纯HTML和css文件中,单个元素的改动只需要标记当前元素即可。唯有一种情况需要考虑, 那就是删除或则隐藏了元素,因为没有办法在页面上再曝关该元素,所以我们需要往上找到父元素进行标记,也就是影响到了父元素。而js代码相对来说互相影响就比较大了,而js的影响可以总结为『定义方影响了使用方』,比如变量参数变了,那使用该参数的地方就被影响了,函数实现变了,那使用该函数的也自然受到了影响。所以找到所有的影响方就可以了,借助AST解析,拿下这块不在话下(如果有兴趣,将在后续的文章中做详细的分享,难点就在于处理js灵活多变的写法)。至此,我们是否已经获取到了单文件中初步的影响范围呢?
平时开发中,我们接触到更多的是各种框架文件,比如vue的sfc文件,react的jsx文件,Svelte文件等等,这些都不是纯粹的html、css和js文件。拿vue文件举例,它包含了"模板"、"脚本"和"样式"三大模块,而模板代码中包含了脚本的变量,脚本会动态更改模板和样式,样式也会直接影响当前文件的布局,这些使得单文件的分析变得复杂。按照惯例,我们依旧需要先将代码分别解析成AST树,官方很贴心的提供了@vue/compiler-sfc 库,可以直接帮助我们抽离出来,每个模块都包含了源代码以及对应的行列信息,模板甚至已经解析好了AST。
{
descriptor: {
filename: 'anonymous.vue',
source: '<template>\n' +
'<p>{{ greeting }} World!</p>\n' +
'</template>\n' +
'\n' +
'<script>\n' +
'export default {\n' +
'data () {\n' +
' return {\n' +
' greeting: "Hello"\n' +
' };\n' +
'}\n' +
'};\n' +
'</script>\n' +
'\n' +
'<style scoped>\n' +
'p {\n' +
'font-size: 2em;\n' +
'text-align: center;\n' +
'}\n' +
'</style>\n',
template: {
type: 'template',
content: '\n<p>{{ greeting }} World!</p>\n',
loc: [Object],
attrs: {},
ast: [Object],
map: [Object]
},
script: {
type: 'script',
content: '\n' +
'export default {\n' +
'data () {\n' +
' return {\n' +
' greeting: "Hello"\n' +
' };\n' +
'}\n' +
'};\n',
loc: [Object],
attrs: {},
map: [Object]
},
scriptSetup: null,
styles: [
[Object]
],
customBlocks: [],
cssVars: [],
slotted: false,
shouldForceReload: [Function: shouldForceReload]
},
errors: []
}
切割成3个模块之后,每个模块内部的影响就可以遵循之前的做法了。而接下来要做的就是分析模块间的影响,这里又涉及多了非常多的情况,列举其中一些典型的场景和做法:
js操作dom元素的方法会影响到页面展示,比如常规的document.getElementById ,vue的this.$refs.xx等等,我们需要把这些方法都遍历出来,然后进行分析
data属性、watch函数、filter函数等的更改,也需要收集起来传递个模块解析模块,分析影响
外部引入或则内部定义的组件有所变更,需要将变化传递到模板上
样式熟悉过有所更改,需要寻找到影响到的模板元素
…….
嗯,看下来这是个体力活!
跨文件影响分析
比起单文件分析,跨文件分析的实现难度显然要高很多。所谓牵一发而动全身,A文件改动了x方法,可能影响到了B文件的y方法,从而再影响到了C文件的z方法,以此类推可能会有一个非常长的链路,除此之外,还需要考虑一些隐式的全局的影响,组件样式的影响,再加上前端语言灵活多变的写法,要想完全理清还是有不少难度的。当然遇事先不急,还是先来盘一盘要做的事情和面临的一些困难。
| 序号 | 要做的事情 | 怎么做?难点在哪? |
|---|---|---|
| 1 | 需要知道改动点影响了哪些功能? | 王炸问题,也就是最终需要解决的问题,不妨先放一放,把问题再拆一拆 |
| 2 | 如何知道当前文件引用了多少外部功能? | 1、需要分析所有显式的js模块引入方案,比如es6 modules、commonjs、umd等2、需要分析所有显示css以及css库(less,scss等)的模块导入方案3、需要分析使用的全局变量以及样式4、需要分析注册到框架上的方法或则属性,比如挂在在vue.prototy上的一些方案,可以直接在页面中通过this去使用….. |
| 3 | 如果判断引入的外部功能来自于哪个文件 | 1、显示的引入单单通过路径判断出来是不准确的!别名、monorepo方案等都会有影响2、挂载在this上的方法模块更是没有办法得知文件路径3、全局变量的改动来自哪里? |
| 4 | 如何快速的遍历分析整个代码,如何避免死循环 | 1、实际代码会存在a影响b,b影响c,c再影响a的情况,数据存储的时候如何避免死循环?2、全量遍历代码是否比较慢,是否会导致构建时间大大延长,从而降低测试效率。 |
第一个问题其实就是多文件分析想要解决的最终问题,能够通过改动点找到所有的影响范围,然而这个却很难直接获取到的,只能通过解决2,3,4的问题来间接得到这个数据。
第2个问题的难点在于他还是个体力活,通过对代码的AST遍历解析,理论上我们能够获取到所有的引入,但是要理清所有的引入方式以及在每种方式中准确获取到用到属性或则方法,仅拿es6 modules的引入方式来看就有以下多种方式
import defaultExport from "module-name";
import * as name from "module-name";
import { export1 } from "module-name";
import { export1 as alias1 } from "module-name";
import { default as alias } from "module-name";
import { export1, export2 } from "module-name";
import { export1, export2 as alias2, ... } from "module-name";
import { "string name" as alias } from "module-name";
import defaultExport, { export1, ... } from "module-name";
import defaultExport, * as name from "module-name";
import "module-name";
...
因为我们需要拿到具体引入的方法,才能基于这个方法再去寻找影响到的点,所以在处理上会有差异。而如何判断诸如vue原生上的方法是原本就有的还是注入的呢?我们先看第三个问题,可以一并解决这个问题。
第三个问题中主要包含了2方面的难点,第一个难点是我们需要找到哪些是引入的源代码,哪些是引入的三方库,对此大家很容易有以下的理解:
import lodash from 'lodash'; // 不带路径,三方库
import MyComponent from './MyComponent'; // 带了路径,本地代码
这样理解是否正确呢?不完全对,因为存在不少的例外情况,比如别名设置,比如只是引用node_modules下的功能,比如monorepo架构中跨项目的引用等等,这里也有2个思路来解决,一个是直接到node_modules中去寻找是否包含了该引用包,一个是去package.json或则lock文件中找,只要能找到就是三方库,否则就是本地代码,具体的实现方案可在后续分享中展开说说。
第二个难点是由于各个系统实现上的差异,程序本身很难知道全局或则注入的方法来自于哪个文件,对应的功能模块是什么?那么不妨让我们来告诉程序吧,通过一个配置文件(请注意这个配置文件很重要,不少节点的流转都依赖这个文件,别名的的配置也在这个文件中),姑且称之为“x”文件,把当前系统中定义的所有全局变量或则自定义框架注入方法的映射放入到配置文件中给到程序去读取就好了,比如:
{
$toast:"src/plugins/toast",
$sentry:"src/plugins/sentry"
.....
}
这样的话我们就能很轻松的知道哪些是注入的方法以及对应的路径是什么。担心维护成本吗?我相信源代码中一定会有类似的映射逻辑在,只需要引入做下转换即可,后续不需要再次维护。
再来看第四个问题,主要点就是需要分析的快,因为一般都要测试了才会去构建代码,这个时候如果构建时间很长,必然会导致测试效率的降低。其中文件影响分析需要遍历整个文件,耗时可能会比较长,那完全可以考虑把这个事情前置了,在代码pull或则merge的时候就做一次全文件的依赖分析,当然为了数据不陷入死循环,存储的时候采用map的方式只做了一层父子关系存储。
经过前面几个问题的解决,这个时候数据是这样子的(列出了“我”依赖了多少个其他模块):
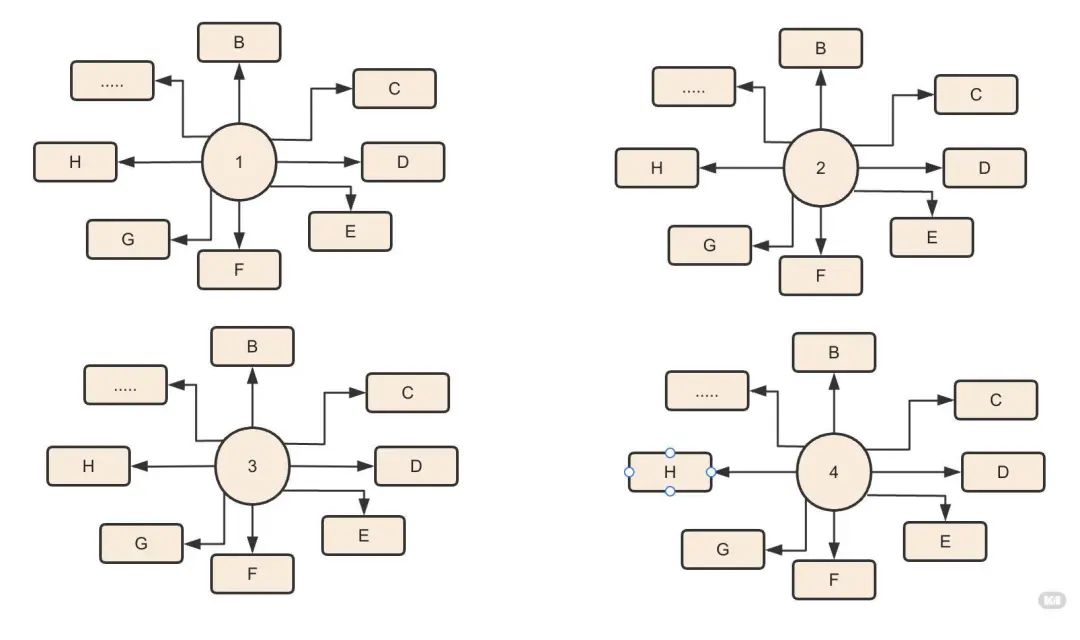
那再去找到底有哪些模块依赖了“我”是不是就变得很简单了。只要去遍历获取,一直取到没有了或则重复了为止,当然这里还有个细节,前面存储的维度是页面(模块)维度,而我们分析的时候需要到函数维度。
影响拓展
到这里不知道大家是否发现了一个问题,一般外部引入的都是一个完整方法、变量或则组件,但是很多时候只是修改了几行代码。所以,在做单文件分析的时候还少做了一件事情,那就是“扩展影响”。简单的来说就是我们需要把代码的影响拓展到第一个可输出的作用域。还是来举一个例子,有以下代码:
export function demo1(a, b) {
- return a + b
+ return a - b
}
function demo2(a) {
return demo1(a, 0)
}
如果修改了第二行“return a+b” 直接通过这行改动是无法匹配到外部调用的,这只是个内部执行过程,所以需要向外找,这个时候就会找到demo1,demo1是有可能被外部引用的,这个没什么疑问吧。接下来看demo2,它虽然调用了demo1方法,但是没有export导出,看起来是个内部方法啊!但是,别忘了这可是js,只要文件被直接引用,里面的方法就可以被调用,所以如果更改了第二行,就需要延伸影响到["demo1","demo2"]两个方法,再去匹配调用方了。
结合构建过程
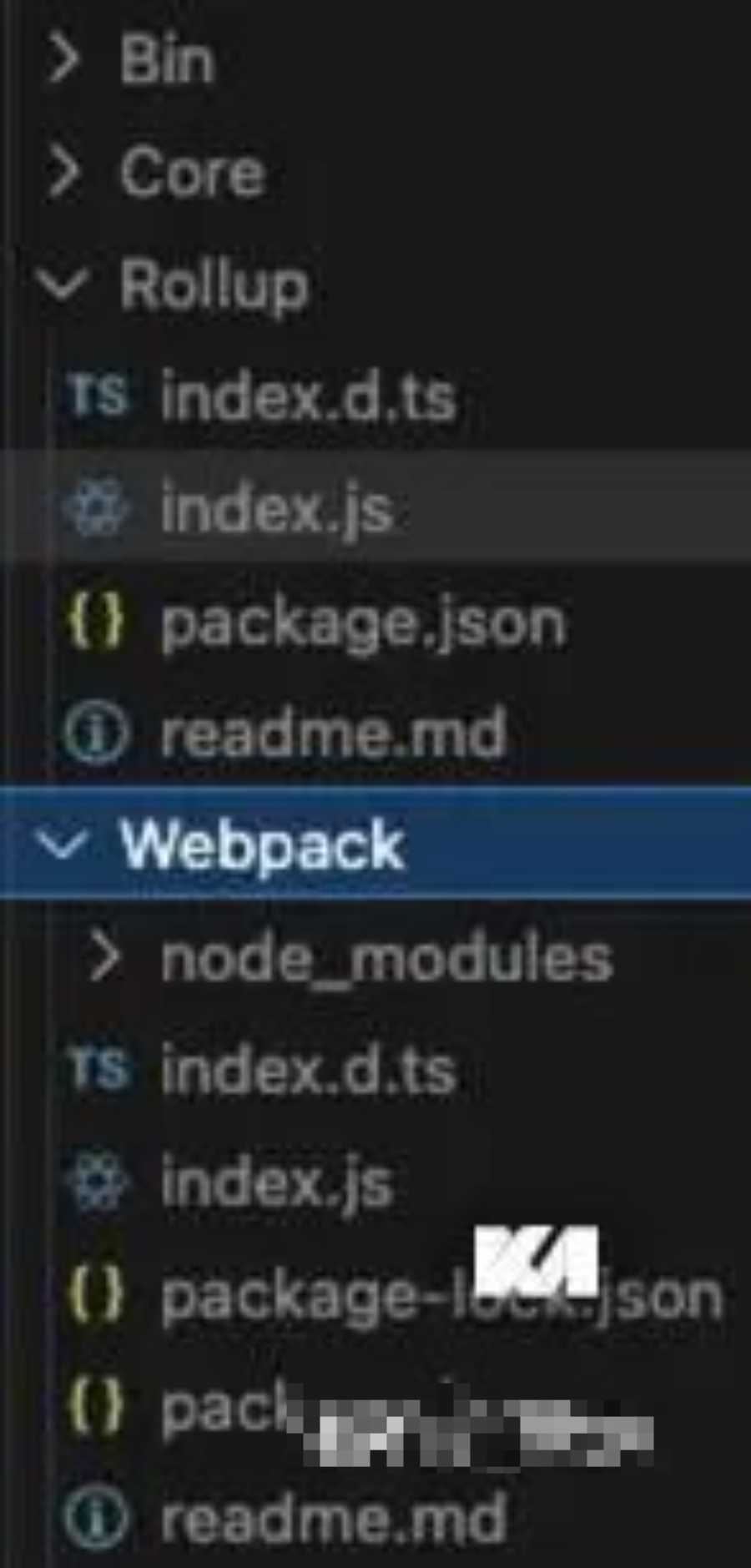
前面说过,精准测试的影响分析、打桩过程都需要遍历项目文件,而构建过程中也需要遍历整个项目文件,为了复用这个过程,就需要把打桩过程和构建过程结合到一起。基于Istanbuljs的打桩,很容易就能找到babel-plugin-istanbul这个库,但是并不是每个项目工程都会有babel的,比如一些ts工程.所以我们放弃了直接使用这个库,而是使用Istanbuljs提供的几个基础库,分别封装成基于各个构建工具的loader或则plugin,当然在封装中我们需要注意2个点,1)在执行插装代码之前,源码不能被改动,不然行列会有偏差 2)把结果传递给下一个处理器,包括因为打桩产生的soucemap。最终我们会产出4种输出,分别是适配webpack的【webpack-laoder】,适配vite和rollup的【rollup-plugin】,在命令行使用的【bin】,可以直接调用的【core】,结构大致如下:
数据收集
前面已经做好了数据的影响分析,基本上是做好了打桩这个事情,接下来要做的事情就是把数据收集上来,有以下几个问题需要解决:
如何存储数据不丢失
如何完整上报一个流程的数据
如何把诸多的请求给清洗合并
如何保证当前执行的页面没有被其他代码“污染”
首先看看数据是怎么存储的,按照Istanbuljs的做法,会把数据存储到全局变量window.coverage中,但是全局数据一旦刷新或则页面跳出就丢了,当然可以做一些离开前自动上报的功能,但是这个时候上报可能会变的比较频繁,后续做数据汇总会显得更加困难,所以我们需要持久化存储下,把数据在localstorage中再放一份。没有采取能把数据保存的更好的浏览器插件方案,是因为首先H5页面不方便使用插件,其次该功能主要还是开发和测试使用,经过大家的协商还是觉得不使用插件更加简单。
再来看怎么算一份完整的数据,我们通常以一次需求为一份数据,那哪些测试属于一份数据呢。还是那个观点,如果程序难以区分,那就让我们告诉他,所以在开始测试和结束测试前都使用人为的填入的方式告知,使用overmind(任务管理系统)的id作为汇总的点,就是不管测试了多少次,只要overmind号是一样的,那就是一次测试,如下图,左下角提供了开始采集以及最后上报的按钮。

因为测试是可能一个反复的过程,并不是一次就能把一个需求功能全部测试完的。那么如何把多次提交的同一个overmind号数据进行合并呢?要知道由于中途需要修改bug,修改变更需求,源代码可能是不一样的,对应最后需要计算覆盖率的母本也是不一样的,所以不仅每次提交需要根据commit号去寻找母本,同时还需要把每两次的提交之间数据再做合并计算!这个过程比较复杂,后续分享中再聊吧。
除此之外还有一个更加棘手的问题,那就是回归环境并不是一个需求单独使用的,其他需求合入的代码就会带来”污染代码“,我们没办法识别哪些代码是污染代码。当然最好的办法就是每个功能都在特定的测试子环境去测试,但这无疑增加了测试的工作量,我们暂时也没有找到特别好的解决方法,如果你有好的解决方案还希望能沟通交流。剩下的就是把结果展示出来了:
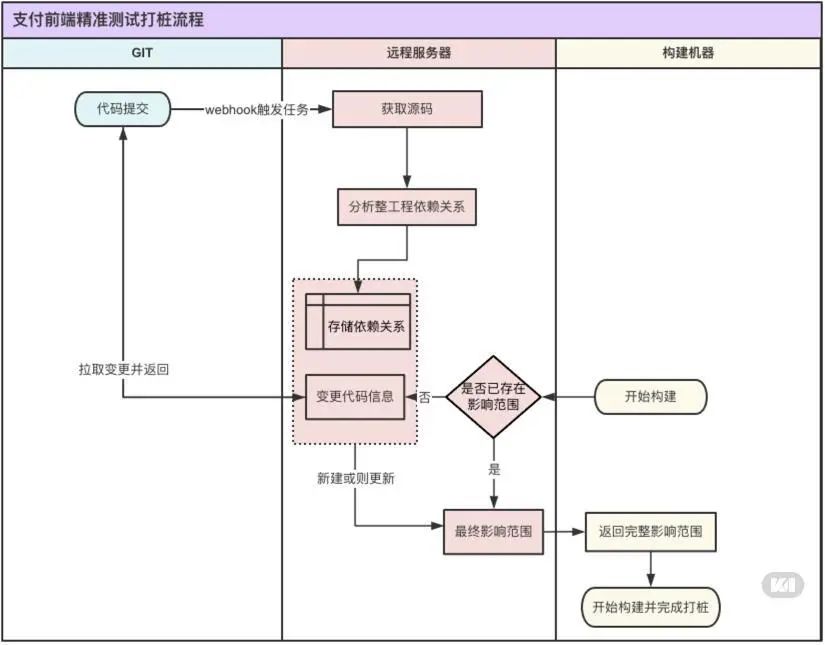
整体实现
前面说了挺多,感觉挺乱的,在这里再汇总下。总的来说还是分为了2个过程,一个就是打桩的过程,把分析代码嵌入到源码中,大致过程如下:
另外一个就是数据上报解析的过程,大致如下:
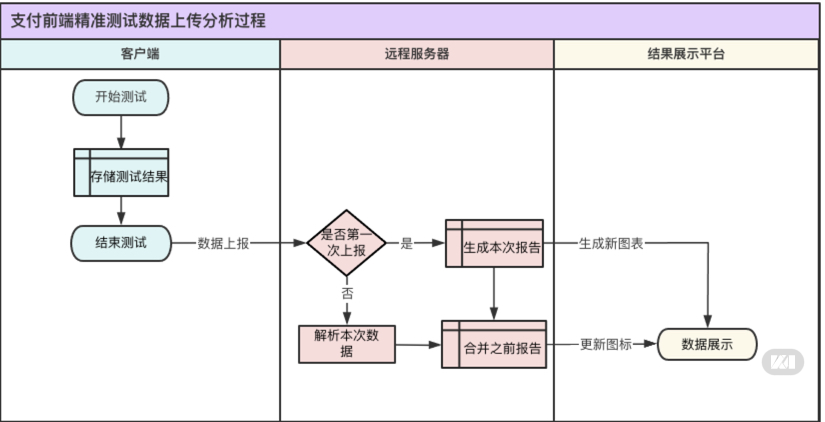
看起来过程还是比较简单得,但是每其中有不少复杂的处理判断逻辑,比较遗憾的是目前由于团队人力问题还没有很好的把UI测试用例维护起来,缺少了很重要的用例推荐以及自动化运行这一步。
作用效果
纳入标准,作为测试卡点,自测没有达到一定比例将无法提测,作为上线卡点,测试没有达到一定覆盖比例将无法上线
由于目前刚上线,漏评估漏测试问题的改善程度将在后续补充,预计可以减少此类80%以上的线上问题
有了衡量标准,开发的自测情况有明显提升,线下问题也变的更少了
后续规划
整个功能中还存在非常多不完善的地方,需要解决完善,后续需要支持更多的框架模板,比如svelet、ejs、ftl等等
在整个支付部门所有外部系统中推广使用,并完善测试用例可以做到动态推荐,自动运行。
结合AI的能力继续提升精准度与覆盖范围
-- End --
点击下方的公众号入口,关注「技术对话」微信公众号,可查看历史文章,投稿请在公众号后台回复:投稿
