




OpenObserve(简称 O2)是一个用 Rust 开发的开源云原生可观测平台,专为日志、指标、追踪而构建,设计用于 PB 级工作。
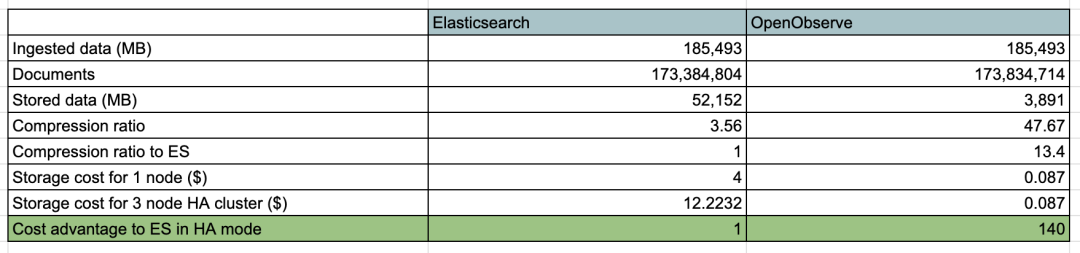
与需要理解和调整大量配置置的 Elasticsearch 相比,它简单且易于操作。在 2 分钟内即可启动并运行 OpenObserve。对于使用 API 获取数据并执行搜索的用户来说,OpenObserve 可以无缝替代 Elasticsearch。OpenObserve 带有自己的用户界面,无需单独安装。与 Elasticsearch 相比,使用 OpenObserve 可以将日志存储成本降低约 140 倍。
相关概念
在详细了解 O2
之前,我们需要了解一些相关概念,这些概念是 O2
的基础。
Organizations(组织)
组织是 OpenObserve 中对各种流、用户、功能进行分组的逻辑实体。组织可以代表一个企业、企业的一个部门或一个应用程序。所有流、用户、功能等都限定在一个组织范围内。
Streams(流)
OpenObserve 中的流是共享相同源的事件序列(日志/指标/跟踪),例如来自特定应用程序的日志或来自企业的日志。比如日志就是一种流,用于记录来自应用程序的事件。
Functions(函数)
OpenObserve 中的函数可在摄取和查询期间使用,以帮助增强高级功能,如丰富、编辑、日志缩减、合规性等。函数是使用 VRL
脚本定义的。
Parquet
O2
中的数据以 parquet
格式存储,这是一种列式存储格式,查询和存储效率很高。
Timestamp(时间戳)
_timestamp
在 OpenObserve 中被视为时间戳列,如果 _timestamp
或 @timestamp
不存在于正在摄取的数据中,我们会将 _timestamp
添加到每个记录,其 NOW
值为微秒精度。
对于键为 _timestamp/@timestamp
的输入数据,对于值我们支持以下数据类型/格式:
微秒 字符串值 RFC 3339 和 ISO 8601 日期和时间字符串,例如 1996-12-19T16:39:57-08:00RFC 2822 日期和时间字符串,例如 Tue, 1 Jul 2003 10:52:37 +0200
如果用户想要支持 _timestamp/@timestamp
以外的键,用户可以使用 ZO_COLUMN_TIMESTAMP
配置来指定时间戳键。
User Roles(用户角色)
OpenObserve 中的用户可以具有 admin
或 member
角色。与具有 member
角色的用户相比,具有 admin
角色的用户拥有更大的权限,例如,具有 admin
角色的用户可以将其他用户添加到组织中。
架构
OpenObserve 可以在单节点下运行,也可以在集群中以 HA 模式运行。
单节点模式
单节点模式也分几种架构,主要是数据存储的方式不同,主要有如下几种:
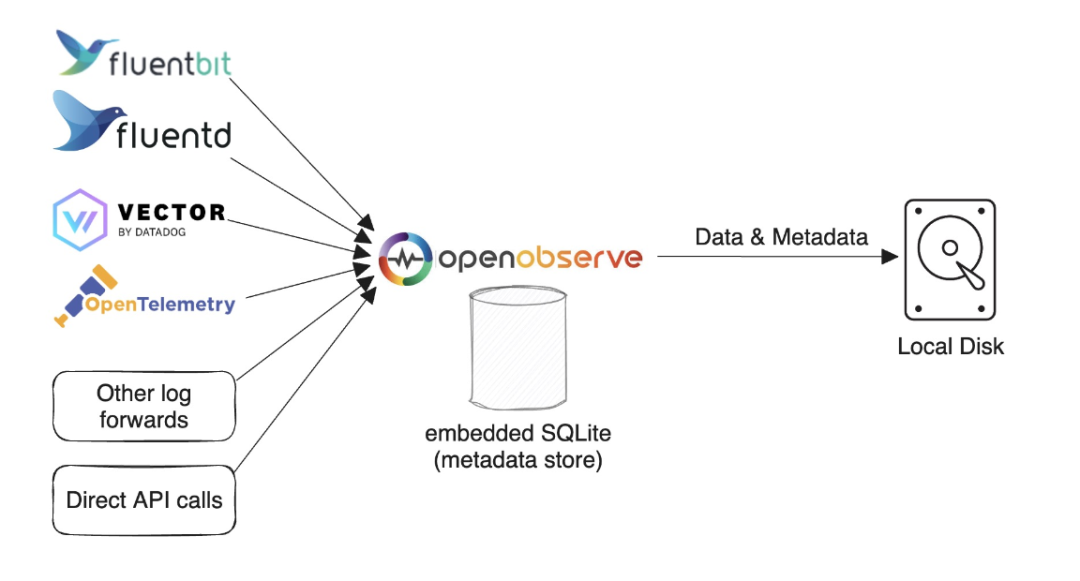
SQLite 和本地磁盘模式
如果你只需要进行简单使用和测试,或者对高可用性没有要求,可以使用此模式。当然你仍然可以在一台机器上每天处理超过 2 TB 的数据。在我们的测试中,使用默认配置,Mac M2 的处理速度为约 31 MB/秒,即每分钟处理 1.8 GB,每天处理 2.6 TB。该模式也是运行 OpenObserve 的默认模式。
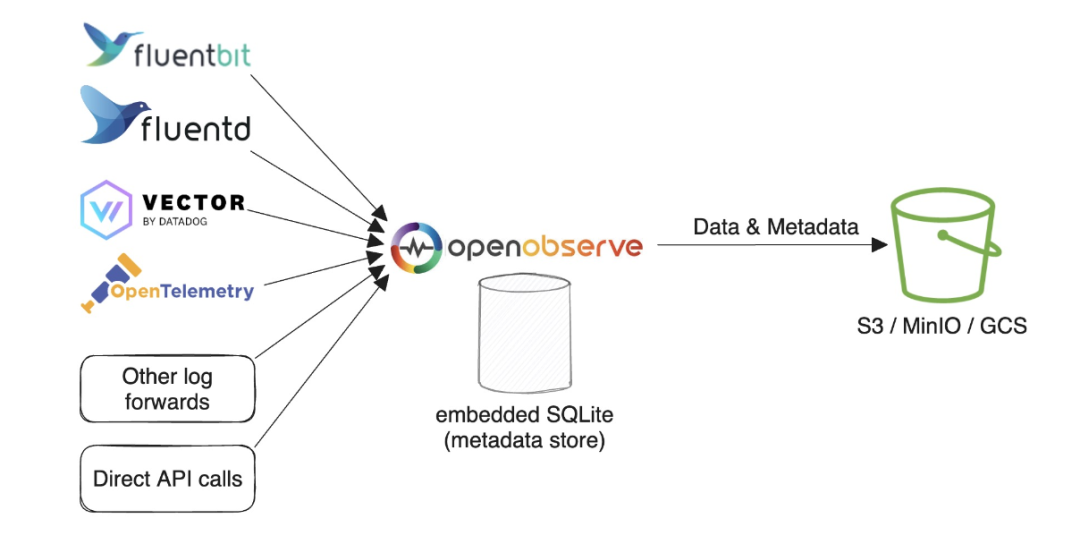
SQLite 和对象存储模式
该模式和 OpenObserve 的默认模式基本上一致,只是数据存在了对象存储中,这样可以更好的支持高可用性,因为数据不会丢失。
高可用模式
HA 模式不支持本地磁盘存储,该模式下,OpenObserve 主要包括 Router
、Querier
、Ingester
、Compactor
和 AlertManager
节点(组件),这些节点都可以水平扩展以适应更高的流量。另外使用 Etcd 或 NATS 用作集群协调器并存储节点信息,还用于集群事件。MySQL/PostgreSQL 用于存储组织、用户、函数、报警规则、流模式和文件列表(parquet
文件的索引)等元数据。对象存储(例如 s3、minio、gcs 等)存储 parquet
文件的数据。

Ingester
Ingester
用于接收摄取请求并将数据转换为 parquet
格式然后存储在对象存储中,它们在将数据传输到对象存储之前将数据临时存储在 WAL
中。
OpenObserve 中摄取的数据默认根据年月日和小时进行分区,我们还可以指定用于对数据进行分区的分区键。
数据摄取流程如下所示:
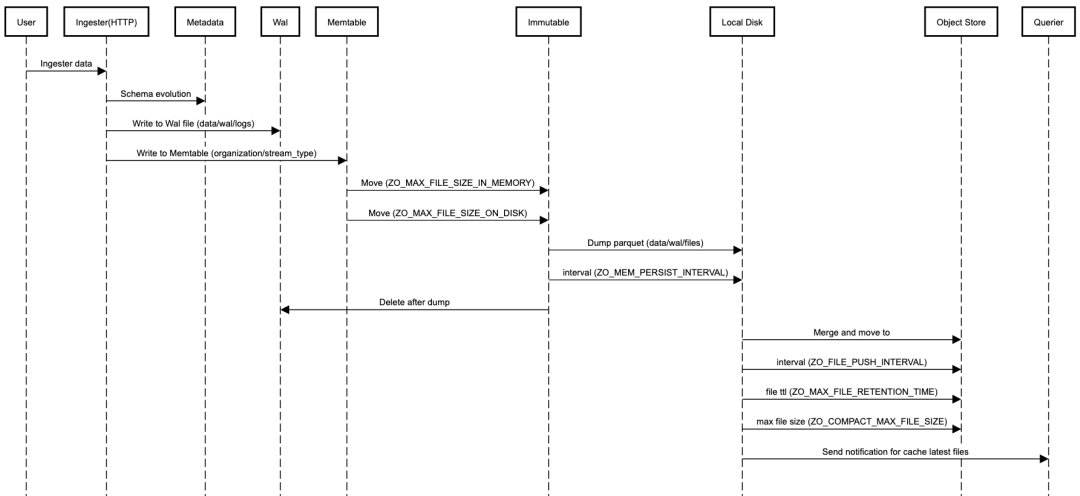
从 HTTP gRPC API 请求接收数据。 逐行解析数据。 检查是否有任何用于转换数据的函数(摄取函数),按函数顺序调用每个摄取函数 检查时间戳字段,将时间戳转换为微秒;如果记录中不存在时间戳字段,则设置当前时间戳。 检查流 schema 以确定 schema 是否需要演变。在这里,如果我们发现需要更新 schema 以添加新字段或更改现有字段的数据类型,则获取 lock
来更新 schema。评估实时报警(如果为流定义了任何报警)。 按小时桶中的时间戳写入 WAL
文件,然后将请求中的记录转换为Arrow RecordBatch
并写入Memtable
。为每个 organization/stream_type
创建Memtable
,如果仅为日志摄取数据,则只有一个Memtable
。WAL 文件和 Metable
是成对创建的,一个 WAL 文件有一个Memtable
。WAL 文件位于data/wal/logs
。当 Memtable
大小达到ZO_MAX_FILE_SIZE_IN_MEMORY = 256MB
或 WAL 文件达到ZO_MAX_FILE_SIZE_ON_DISK = 128MB
时,我们将Memtable
移动到Immutable
并创建一个新的Memtable
和 WAL 文件用于写入数据。每 ZO_MEM_PERSIST_INTERVAL=5
秒会将Immutable
转储到本地磁盘。一个Immutable
将生成多个parquet
文件,因为它可能包含多个流和多个分区,parquet
文件位于data/wal/files
。每 ZO_FILE_PUSH_INTERVAL=10
秒,我们检查本地parquet
文件,如果任何分区总大小超过ZO_MAX_FILE_SIZE_ON_DISK=128MB
或任何文件已在ZO_MAX_FILE_RETENTION_TIME=600
秒前,分区中的所有此类小文件将被合并为一个大文件(每个大文件将最大为ZO_COMPACT_MAX_FILE_SIZE=256MB
) ,它将被移动到对象存储。
Ingester 包含三部分数据:
Memtable
中的数据Immutable
中的数据WAL 中的 parquet
文件尚未上传到对象存储。
这些数据都需要能够被查询到。
Router
Router
(路由器)将请求分发给 ingester
或 querier
,它还通过浏览器提供 UI 界面,Router 实际上就是一个非常简单的代理,用于在摄取器和查询器之间发送适当的请求。
Querier
Querier
(查询器)用于查询数据,查询器节点是完全无状态的。数据查询流程如下:
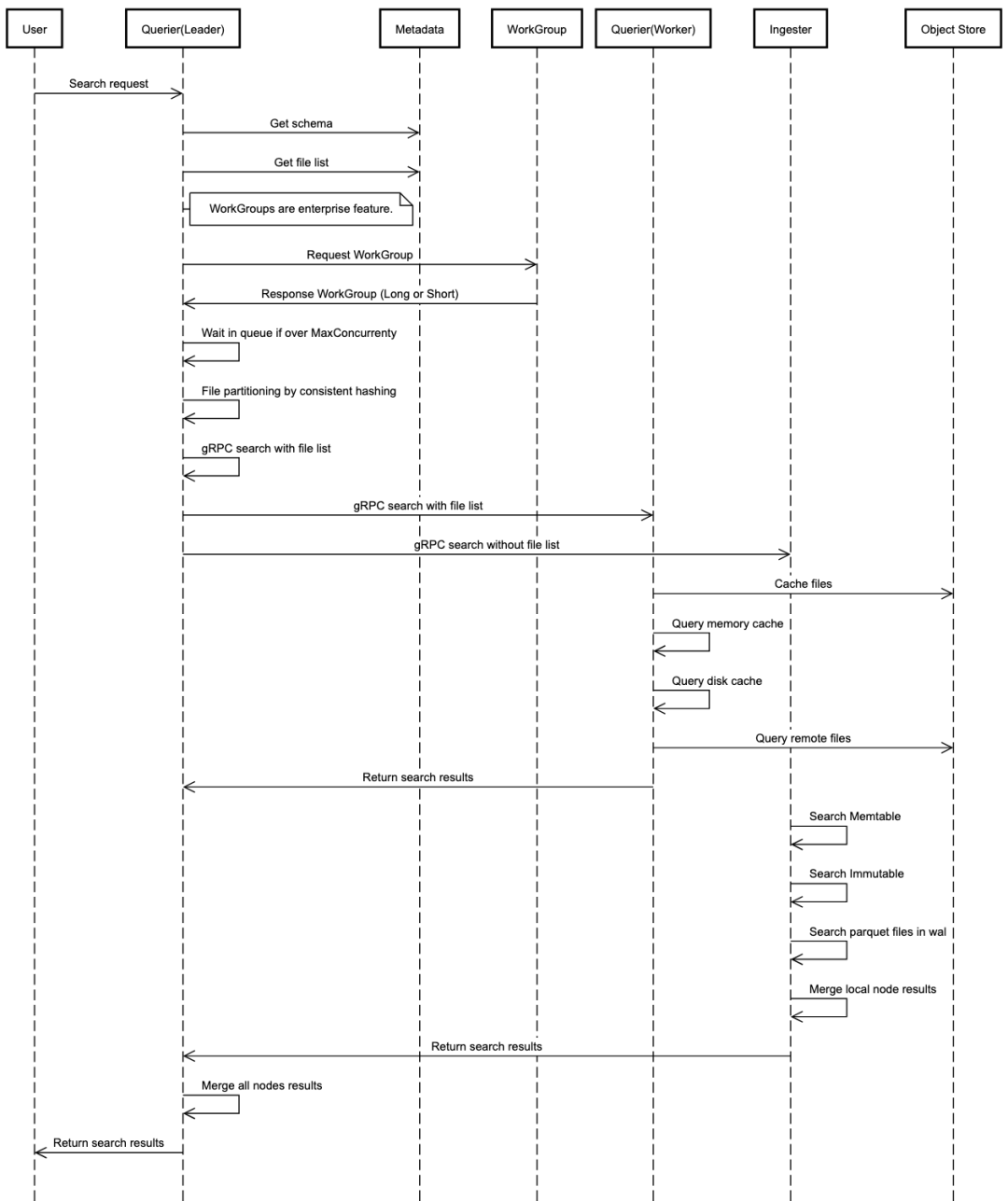
使用 http API 接收搜索请求。接收到查询请求的节点成为该查询的 LEADER
查询器。其他查询器都是WORKER
查询器,用于查询。LEADER
解析并验证 SQL。LEADER
找到数据时间范围并从文件列表索引中获取文件列表。LEADER
从集群元数据中获取查询器节点。LEADER
对每个查询器要查询的文件列表进行分区。例如如果需要查询 100 个文件,并且有 5 个查询器节点,则每个查询器可以查询 20 个文件,LEADER
处理 20 个文件,WORKERS
各处理 20 个文件。LEADER
调用每个WORKER
查询器上运行的 gRPC 服务,将搜索查询分派到查询器节点。查询器间通信使用 gRPC 进行。LEADER
收集、合并并将结果发送回用户。
提示:
默认情况下,查询器将在内存中缓存 parquet
文件。我们可以使用环境变量ZO_MEMORY_CACHE_MAX_SIZE
配置查询器用于缓存的内存大小。默认缓存是使用特定查询器可用内存的 50% 来完成的。在分布式环境中,每个查询器节点只会缓存一部分数据。 我们还可以选择在内存中缓存最新的 parquet
文件。当Ingester
生成新的Parquet
文件并将其上传到对象存储时,Ingester
将通知查询器缓存该文件。
Compactor
Compactor
(压缩器)会将小文件合并成大文件,使搜索更加高效。Compactor
还处理数据保留策略、full stream 删除和文件列表索引更新。
AlertManager
AlertManager
运行标准报警查询、报告作业并发送通知。
安装
由于 O2
用到的各个存储可选方案较多,这里我们选择使用 PostgreSQL
作为元数据存储,Minio
作为对象存储,Nats
作为集群协调器(建议使用 Nats
,为了向后兼容,目前仍然支持 Etcd
)。
接下来同样我们使用 Helm
来安装 O2
:
helm repo add openobserve https://charts.openobserve.ai
helm repo update
官方的这个 Helm Chart 默认会部署 PostgreSQL,但是需要提前安装对应的 cloudnative-pg operator
:
kubectl apply --server-side -f \
https://raw.githubusercontent.com/cloudnative-pg/cloudnative-pg/release-1.23/releases/cnpg-1.23.1.yaml
然后我们就可以在 Helm Chart 中使用 PostgreSQL 了,此外为了启用 Minio
和 Nats
,我们需要在 values.yaml
中进行配置,修改后的 values.yaml
如下所示
# o2-values.yaml
# auth:
# ZO_ROOT_USER_EMAIL: "root@example.com" # default user email
# ZO_ROOT_USER_PASSWORD: "Complexpass#123" # default user password
ingester:
headless:
enabled: true
persistence:
enabled: true
storageClass: "nfs-client"
querier:
persistence: # If enabled it will be used for disk cache. Highly recommend to enable this for production
enabled: true
storageClass: "nfs-client"
service:
type: NodePort
nats:
enabled: true
container:
image:
repository: library/nats
registry: dhub.kubesre.xyz
config:
cluster:
enabled: true
replicas: 3
jetstream:
enabled: true
fileStore:
enabled: true
pvc:
enabled: true
size: 20Gi
storageClassName: "nfs-client"
natsBox:
container:
image:
registry: dhub.kubesre.xyz
reloader:
image:
registry: dhub.kubesre.xyz
minio:
enabled: true # if true then minio will be deployed as part of openobserve
mode: standalone # or distributed
persistence:
storageClass: "nfs-client"
consoleService:
type: NodePort
nodePort: 32001
# Postgres is used for storing openobserve metadata.
# Make sure to install cloudnative-pg operator before enabling this
postgres:
enabled: true
pgadmin:
enabled: false
spec:
instances: 2 # creates a primary and a replica. replica will become primary if the primary fails
storage:
size: 10Gi
pvcTemplate:
storageClassName: "nfs-client"
然后我们就可以安装 O2
了:
$ helm upgrade --install o2 openobserve/openobserve -f o2-values.yaml --namespace openobserve --create-namespace
Release "o2" does not exist. Installing it now.
NAME: o2
LAST DEPLOYED: Sat Aug 24 17:29:23 2024
NAMESPACE: openobserve
STATUS: deployed
REVISION: 1
NOTES:
1. Get the application URL by running these commands:
export NODE_PORT=$(kubectl get --namespace openobserve -o jsonpath="{.spec.ports[0].nodePort}" services o2-openobserve)
export NODE_IP=$(kubectl get nodes --namespace openobserve -o jsonpath="{.items[0].status.addresses[0].address}")
echo http://$NODE_IP:$NODE_PORT
安装完成后,我们可以通过 kubectl get pods -n openobserve
查看所有的 Pod 是否正常运行。
$ kubectl get pods -n openobserve
NAME READY STATUS RESTARTS AGE
o2-minio-5ff8c55559-g6255 1/1 Running 0 43m
o2-nats-0 2/2 Running 0 32m
o2-nats-1 2/2 Running 0 33m
o2-nats-2 2/2 Running 0 33m
o2-nats-box-588fb755c4-6qxl2 1/1 Running 0 43m
o2-openobserve-alertmanager-95796f856-c6xlg 1/1 Running 0 43m
o2-openobserve-compactor-7f9b8cdb6b-kr8sp 1/1 Running 0 31m
o2-openobserve-ingester-0 1/1 Running 0 32m
o2-openobserve-postgres-1 1/1 Running 0 43m
o2-openobserve-postgres-2 1/1 Running 0 42m
o2-openobserve-querier-0 1/1 Running 0 43m
o2-openobserve-router-58dc4b8fd7-vl42p 1/1 Running 0 31m
$ kubectl get svc -n openobserve
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
o2-minio ClusterIP 10.96.2.46 <none> 9000/TCP 43m
o2-minio-console NodePort 10.96.0.196 <none> 9001:32001/TCP 43m
o2-nats ClusterIP 10.96.2.18 <none> 4222/TCP 43m
o2-nats-headless ClusterIP None <none> 4222/TCP,6222/TCP,8222/TCP 43m
o2-openobserve-alertmanager ClusterIP 10.96.1.79 <none> 5080/TCP,5081/TCP,5082/TCP 43m
o2-openobserve-compactor ClusterIP 10.96.0.207 <none> 5080/TCP,5081/TCP 43m
o2-openobserve-ingester ClusterIP 10.96.2.154 <none> 5080/TCP,5081/TCP 43m
o2-openobserve-ingester-headless ClusterIP None <none> 5080/TCP,5081/TCP 43m
o2-openobserve-postgres-r ClusterIP 10.96.0.123 <none> 5432/TCP 43m
o2-openobserve-postgres-ro ClusterIP 10.96.3.208 <none> 5432/TCP 43m
o2-openobserve-postgres-rw ClusterIP 10.96.0.165 <none> 5432/TCP 43m
o2-openobserve-querier ClusterIP 10.96.3.13 <none> 5080/TCP,5081/TCP 43m
o2-openobserve-router NodePort 10.96.3.228 <none> 5080:31984/TCP,5081:32212/TCP 43m
使用
安装完成后,我们可以通过 http://<NODE_IP>:31984
访问 O2
的 Web 界面,然后就可以开始使用了。
使用默认的用户名 root@example.com
和密码 Complexpass#123
登录,然后就可以看到 O2
的主界面了。
因为现在我们还没有向 O2
中发送任何数据,所以暂时没有任何数据。我们可以切换到采集页面,里面就有各种遥测数据的采集方式。
示例数据导入
这里我们可以先使用 JSON API 来加载一些示例日志数据来了解一下 OpenObserve 的基本使用方法。先使用下面命令下载示例日志数据:
$ curl -L https://zinc-public-data.s3.us-west-2.amazonaws.com/zinc-enl/sample-k8s-logs/k8slog_json.json.zip -o k8slog_json.json.zip
$ unzip k8slog_json.json.zip
然后使用下面命令将示例日志数据导入到 OpenObserve 中:
$ curl http://<NodeIP>:31984/api/default/default/_json -i -u "root@example.com:Complexpass#123" -d "@k8slog_json.json"
HTTP/1.1 100 Continue
HTTP/1.1 200 OK
content-length: 71
content-type: application/json
x-api-node: o2-openobserve-ingester-0
access-control-allow-credentials: true
date: Sat, 24 Aug 2024 10:31:05 GMT
vary: accept-encoding
{"code":200,"status":[{"name":"default","successful":3846,"failed":0}]}%
收据导入成功后,刷新页面即可看到有数据了:
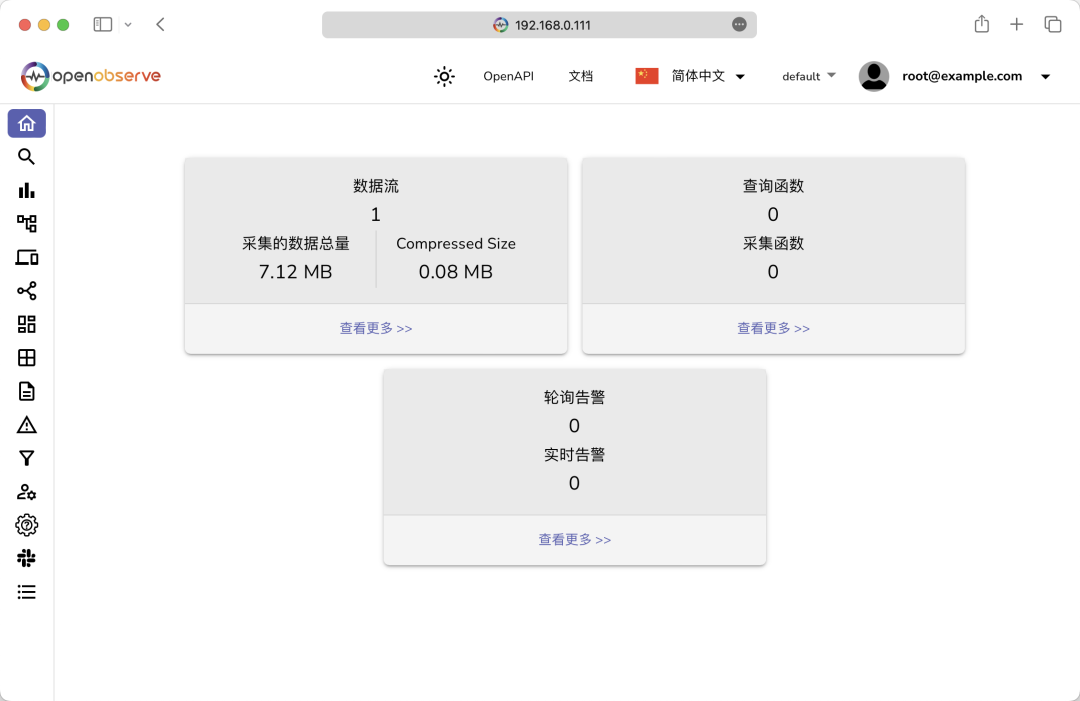
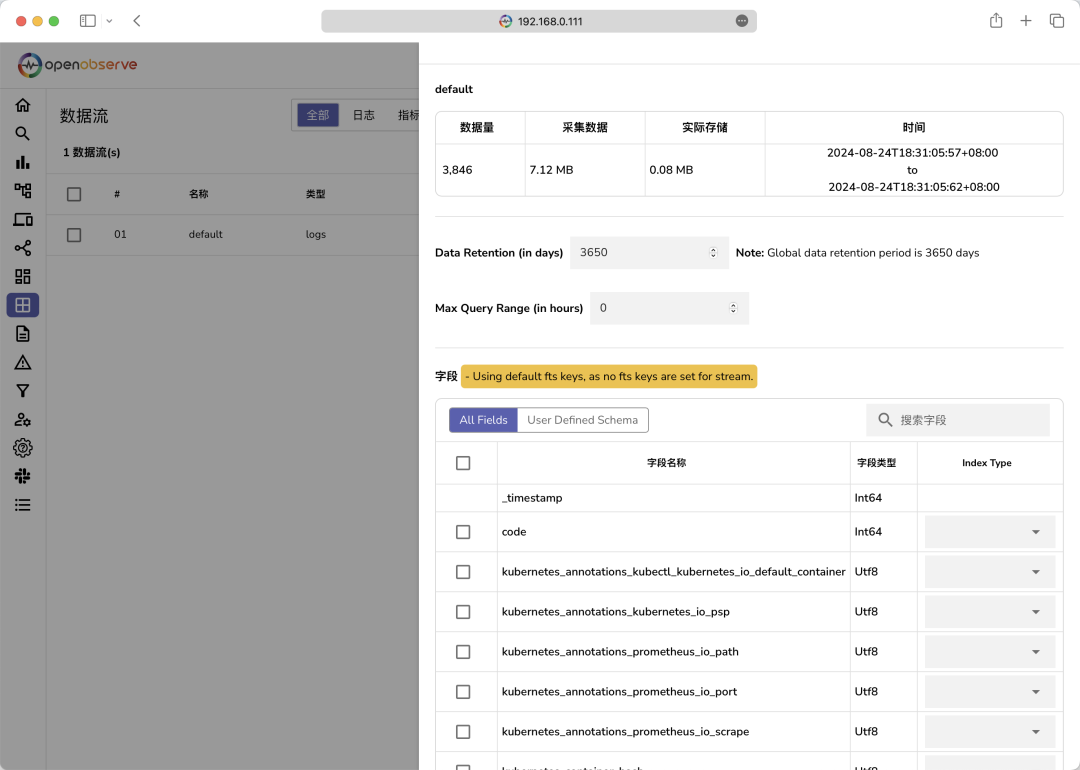
在数据流页面可以看到我们导入的数据元信息:
然后切换到日志页面,从左侧的下拉列表中选择索引为 default
,就可以看到日志数据了:

现在我们就可以去根据直接的需求去查询日志了,比如要使用倒排索引搜索包含单词 error
的所有字段:
在查询编辑器中使用 match_all('error')match_all
仅搜索配置为全文搜索的字段。默认字段集包括log
、message
、content
、data
、events
、json
。如果你希望全文搜索时扫描更多字段,可以在数据流页面进行配置。在特定字段中进行全文搜索应该使用str_match
函数。
要在没有倒排索引的情况下搜索包含单词 error
的所有字段:
match_all_raw('error')
,区分大小写。match_all_raw_ignore_case(error)
,这是不区分大小写的。match_all_raw
函数仅搜索配置为全文搜索的字段。默认字段集是log
、message
、content
、data
、events
、json
。如果希望全文搜索时扫描更多字段,可以在数据流设置下进行配置。应该使用str_match
在指定字段中进行全文搜索。
如果仅搜索 log
字段中的 error
,可以使用 str_match(log, 'error')
,这比 match_all_raw
更有效,因为它在单个字段中搜索。
同样如果我们要搜索包含 code
为 200 的所有日志条目,则可以直接使用 code=200
查询即可,其中 code
是一个数字字段。如果要搜索 code
字段不包含任何值的所有日志条目,可以使用 code is null
,但是需要注意使用 code=' '
不会产生正确的结果;同样的搜索 code
字段具有某个值的所有日志条目,则可以使用 code is not null
,但是不能使用 code!=' '
。另外也可以使用 code > 399
或者 code >= 400
来搜索 code
大于 399 或者大于等于 400 的所有日志条目。
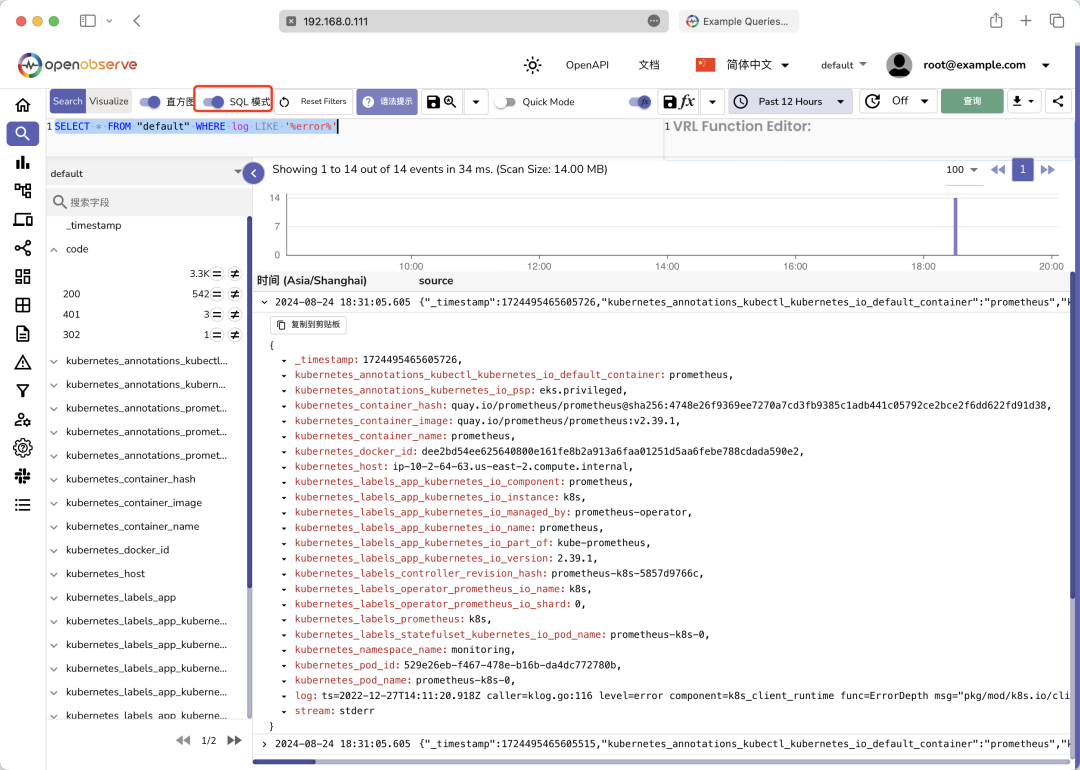
此外我们还可以勾选 SQL 模式
来使用 SQL 查询语句来查询日志数据:
同样现在我们可以去 Minio 中查看数据是否已经被正确的存储,使用用户名 rootuser
和密码 rootpass123
即可登录成功。

可以看到对象存储中已经有了我们的 parquet
文件数据。
采集 Kubernetes 观测数据
O2
还支持通过 OpenTelemetry 采集器导入数据。这里我们可以使用 OpenTelemetry
来采集 Kubernetes 集群的观测数据,首先我们需要安装 OpenTelemetry
的 Operator
,由于 OpenTelemetry
的 Operator
依赖 cert-manager
,所以我们需要先安装 cert-manager
:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.13.1/cert-manager.yaml
等待 cert-manager
安装完成后,我们就可以安装 OpenTelemetry
的 Operator
了:
$ kubectl get pods -n cert-manager
NAME READY STATUS RESTARTS AGE
cert-manager-cainjector-65c7bff89d-rxjts 1/1 Running 0 64s
cert-manager-cbcf9668d-tlz2k 1/1 Running 0 64s
cert-manager-webhook-594cb9799b-c5sd8 1/1 Running 0 64s
$ kubectl apply -f https://github.com/open-telemetry/opentelemetry-operator/releases/latest/download/opentelemetry-operator.yaml
$ kubectl get pods -n opentelemetry-operator-system
NAME READY STATUS RESTARTS AGE
opentelemetry-operator-controller-manager-fd5689558-lchr7 2/2 Running 0 61s
然后我们就可以来安装 OpenTelemetry 的 Collector
了,为了方便使用 O2 官方的 Helm Chart 已经提供了一个定制的 Chart 包,我们可以直接使用它,该采集器可以:
从 K8s 集群中捕获日志、指标和 Events 事件并将其发送到 O2 在集群中配置 auto-instrumentation
自动埋点,以捕获Java
、.Net
、nodejs
、python
和Go
语言编写的应用程序的链路追踪
使用我们这里安装的 O2 集群的认证信息覆盖默认的认证信息:
# o2c-values.yaml
exporters:
otlphttp/openobserve:
endpoint: http://o2-openobserve-router.openobserve.svc.cluster.local:5080/api/default
headers:
Authorization: Basic cm9vdEBleGFtcGxlLmNvbTpScmtORWxpenhCWWV4Qzhr # 替换成自己的
stream-name: k8s_logs # 替换成自己的数据流名称
otlphttp/openobserve_k8s_events:
endpoint: http://o2-openobserve-router.openobserve.svc.cluster.local:5080/api/default
headers:
Authorization: Basic cm9vdEBleGFtcGxlLmNvbTpScmtORWxpenhCWWV4Qzhr # 替换成自己的
stream-name: k8s_events
agent:
enabled: true
tolerations: # 如果需要在 master 节点上运行,需要添加这个容忍
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
其中 endpoint
地址为 O2
的 router
的 FQDN 地址,Authorization
中 Basic
后面 的值为用户名:TOKEN
的 base64
编码(可以在 O2
采集页面获取),stream-name
为数据流名称。然后直接使用下面命令安装 OpenTelemetry
的 Collector
即可:
$ helm upgrade --install o2c openobserve/openobserve-collector -f o2c-values.yaml --namespace openobserve-collector --create-namespace
Release "o2c" does not exist. Installing it now.
NAME: o2c
LAST DEPLOYED: Sun Aug 25 10:30:59 2024
NAMESPACE: openobserve-collector
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
If everything proceeded without errors then your cluster is now sending logs and metrics to OpenObserve.
You can add following to your pods/namespaces to auto instrument your applications to send traces:
1. Java: instrumentation.opentelemetry.io/inject-java: "openobserve-collector/openobserve-java"
2. NodeJS: instrumentation.opentelemetry.io/inject-nodejs: "openobserve-collector/openobserve-nodejs"
3. Python: instrumentation.opentelemetry.io/inject-python: "openobserve-collector/openobserve-python"
4. DotNet: instrumentation.opentelemetry.io/inject-dotnet: "openobserve-collector/openobserve-dotnet"
5. Go: instrumentation.opentelemetry.io/inject-go: "openobserve-collector/openobserve-go" , instrumentation.opentelemetry.io/otel-go-auto-target-exe: "/path/to/container/executable"
6. OpenTelemetry SDK environment variables only: instrumentation.opentelemetry.io/inject-sdk: "true"
我们可以查看 OpenTelemetry
的 Collector
是否正常运行:
$ kubectl get pods -n openobserve-collector
NAME READY STATUS RESTARTS AGE
o2c-openobserve-collector-agent-collector-46r82 1/1 Running 0 10m
o2c-openobserve-collector-agent-collector-cbtnn 1/1 Running 0 10m
o2c-openobserve-collector-agent-collector-kkczz 1/1 Running 0 10m
o2c-openobserve-collector-gateway-collector-0 1/1 Running 0 10m
o2c-openobserve-collector-gateway-targetallocator-59c4468dxmfts 1/1 Running 0 10m
其实这里我们部署的采集器就是一个 agent
和一个 gateway
,在前面的额 OpenTelemetry 章节已经学习过了,只是这里我们是将数据导出到了 O2
中。
现在我们就可以去 O2
中查看我们的数据了,切换到数据流页面,可以看到我们的数据流已经被成功的导入了:
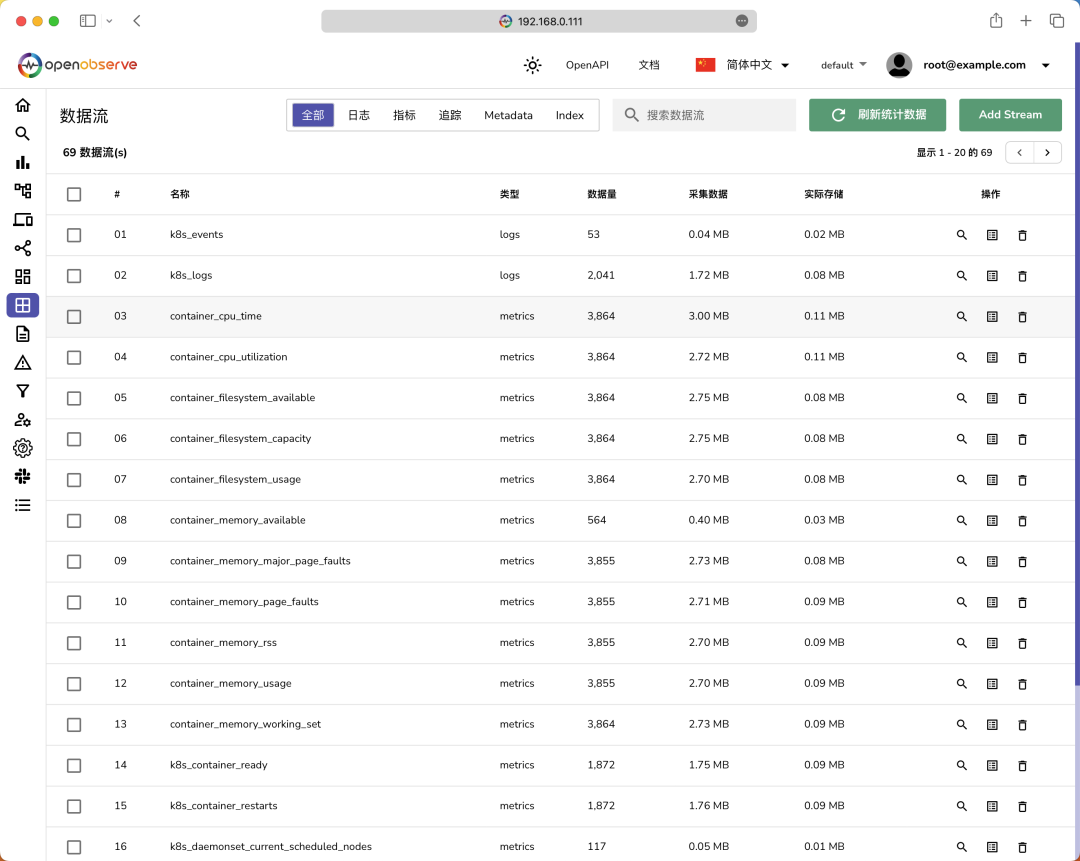
可以看到现在我们的数据流中已经有了 k8s_logs
和 k8s_events
两个日志数据流,分别对应我们的日志和事件数据。除此之外还有很多 metrics
类型的数据流,可以看到指标中的每一个标签都是一个独立的 stream
数据流。
我们可以切换到日志页面,选择数据流 k8s_logs
,就可以看到我们采集的 K8s 集群的日志数据了:

同样我们选择数据流 k8s_events
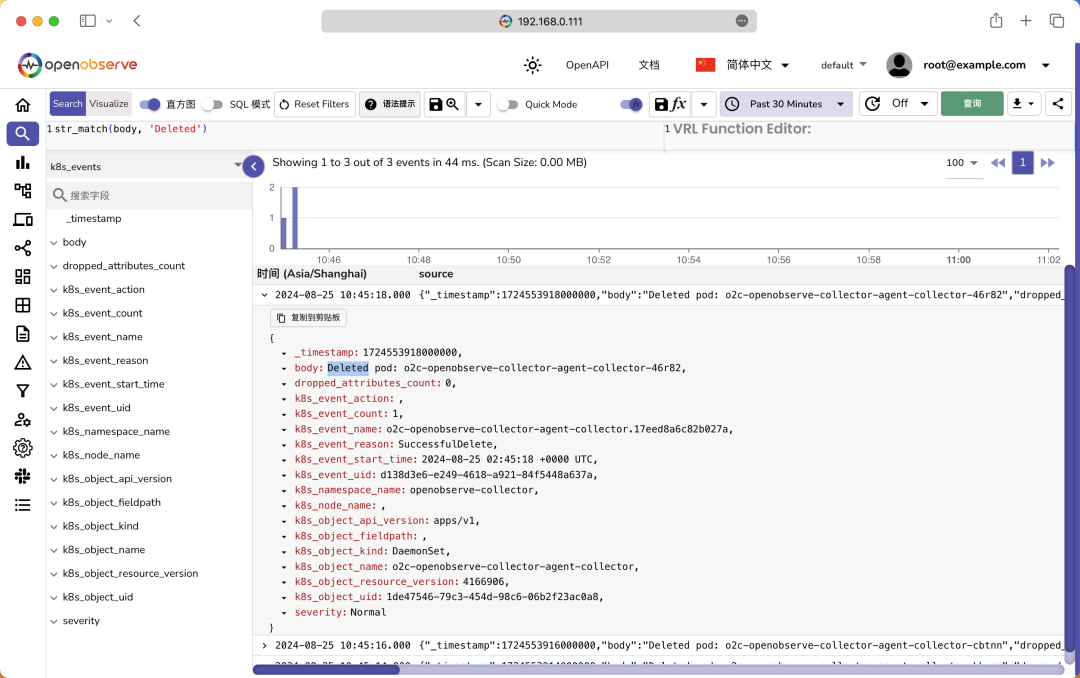
,就可以看到我们采集的 K8s 集群的事件数据了:
对于指标数据流,我们可以切换到指标页面,选择数据流 k8s_metrics
,就可以看到我们采集的 K8s 集群指标数据了:
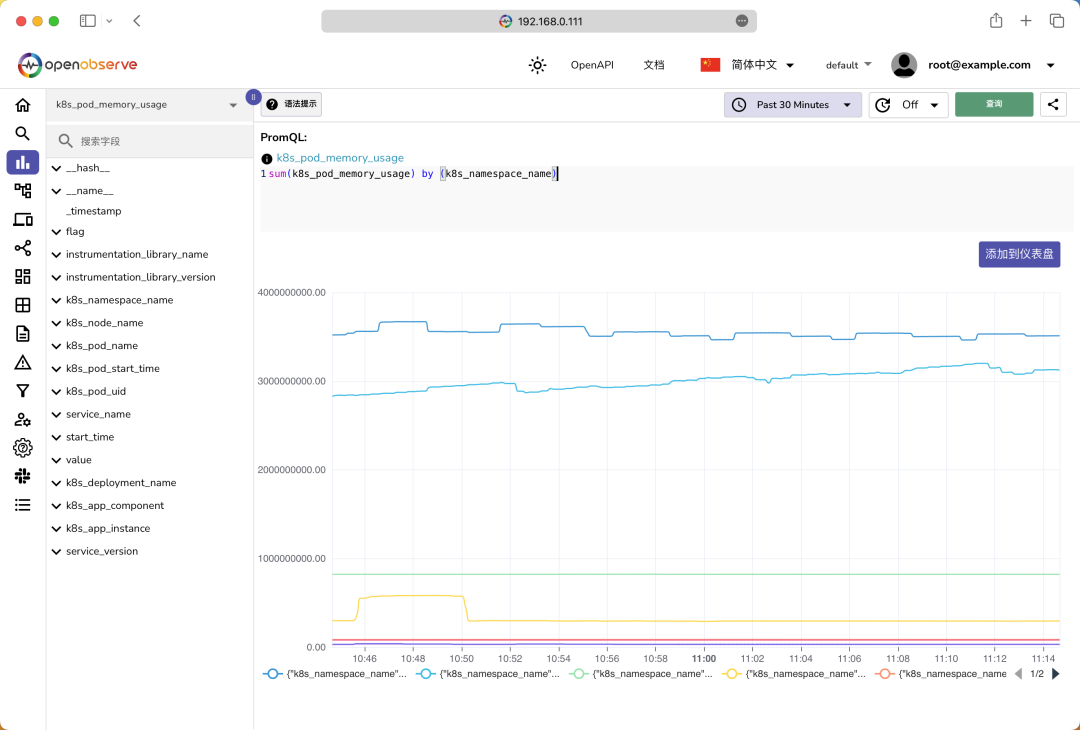
左侧我们可以选择一个指标,然后就可以看到这个指标的标签列表,然后我们就可以在右侧填写 PromQL 语句来查询数据了,比如我们这里查询每个命名空间的内存使用情况,则可以使用下面的 PromQL 语句:
sum(k8s_pod_memory_usage) by (k8s_namespace_name)
查询结果如下图所示:
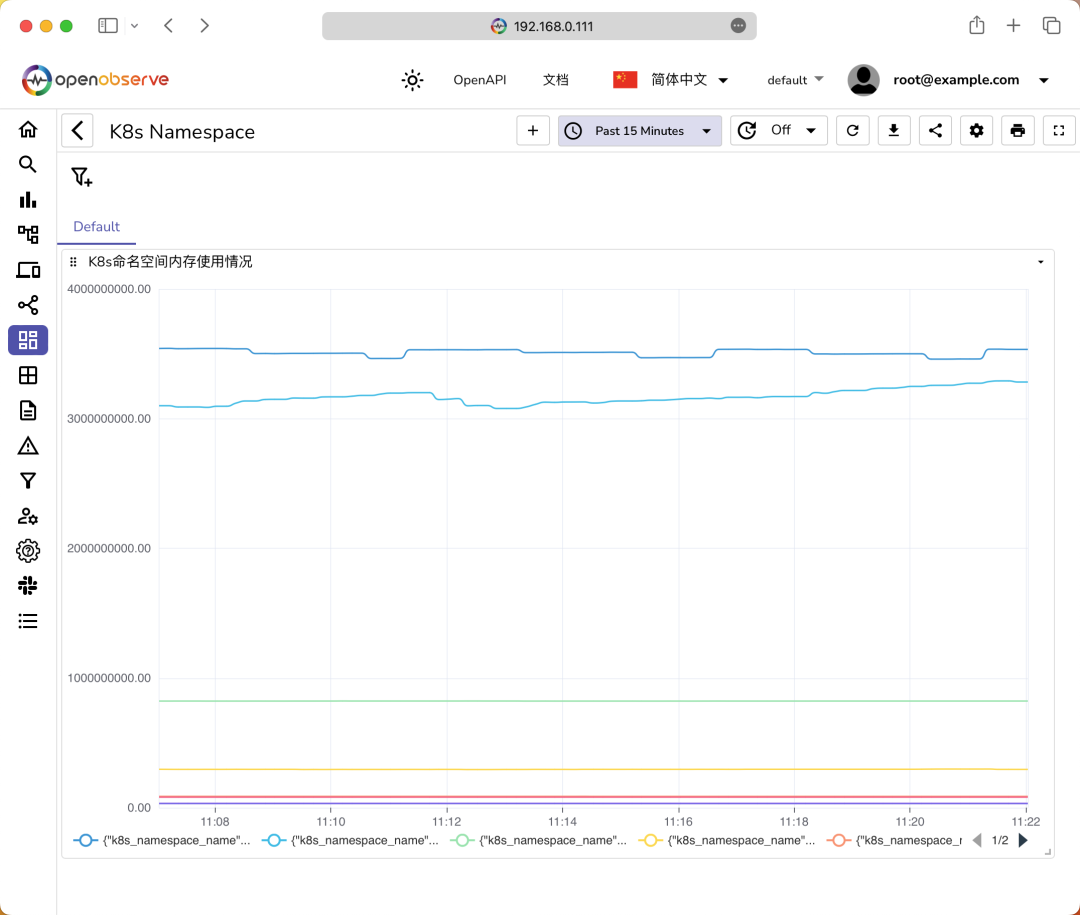
如果我们需要经常查询这个指标,这可以将其添加到仪表盘中,点击页面中的添加到仪表盘按钮即可,然后在仪表盘页面就可以看到我们的仪表盘了:
和 Grafana 类似,我们也可以编辑面板,在面板右上角点击Edit Panel
,就可以进入面板编辑页面了,点击最右侧的配置按钮,就可以编辑面板了,比如我们这里可以选择图例的单位、图例的显示名称等,编辑后可以点击应用按钮预览,如果满意可以点击保存按钮保存:

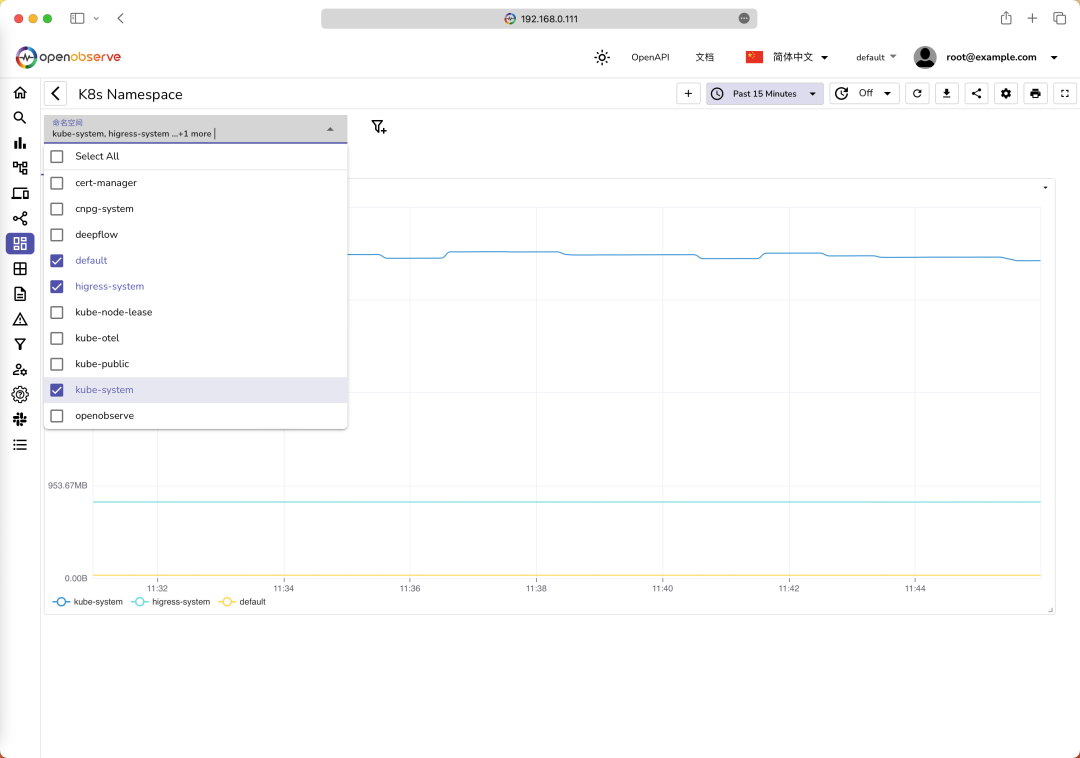
同样我们也可以和 Grafana 一样配置一个变量,然后在面板上展示这个变量,比如我们这合理可以添加一个 namespace
变量,其值可以从 k8s_namespace_phase
这个数据流中获取,如下图所示:

当然现在我们需要去修改下面板的 PromQL 查询语句,需要将变量 namespace
传入,更改成:sum(k8s_pod_memory_usage{k8s_namespace_name =~ "$namespace"}) by (k8s_namespace_name)
即可:

现在我们就可以在面板上通过筛选 namespace
变量来查看不同命名空间的内存使用情况了:
接下来还有链路追踪的数据,因为上面我们安装的 OpenTelemetry
的 Collector
已经自动为我们创建了自动埋点的 Instrumentation
对象,如下所示:
$ kubectl get instrumentation -n openobserve-collector
NAME AGE ENDPOINT SAMPLER SAMPLER ARG
openobserve-dotnet 99m http://o2c-openobserve-collector-gateway-collector.openobserve-collector.svc.cluster.local:4318 parentbased_traceidratio 1
openobserve-go 99m http://o2c-openobserve-collector-gateway-collector.openobserve-collector.svc.cluster.local:4318 parentbased_traceidratio 1
openobserve-java 99m http://o2c-openobserve-collector-gateway-collector.openobserve-collector.svc.cluster.local:4318 parentbased_traceidratio 1
openobserve-nodejs 99m http://o2c-openobserve-collector-gateway-collector.openobserve-collector.svc.cluster.local:4317 parentbased_traceidratio 1
openobserve-python 99m http://o2c-openobserve-collector-gateway-collector.openobserve-collector.svc.cluster.local:4318 parentbased_traceidratio 1
可以看到上面的 Instrumentation
对象已经配置了端点地址、采样器和采样器参数,地址就是我们的 OpenTelemetry
的 Collector
的地址(gateway
类型的),采样器是 parentbased_traceidratio
,参数是 1
,表示采样率为 1
。
针对上面的这些语言编写的应用,我们就可以进行自动埋点,只需要在应用的 Pod
中添加对应的 Annotation
即可:
Java: instrumentation.opentelemetry.io/inject-java: "openobserve-collector/openobserve-java"DotNet: instrumentation.opentelemetry.io/inject-dotnet: "openobserve-collector/openobserve-dotnet"NodeJS: instrumentation.opentelemetry.io/inject-nodejs: "openobserve-collector/openobserve-nodejs"Python: instrumentation.opentelemetry.io/inject-python: "openobserve-collector/openobserve-python"Go (Uses eBPF): instrumentation.opentelemetry.io/inject-go: "openobserve-collector/openobserve-go"instrumentation.opentelemetry.io/otel-go-auto-target-exe: "/path/to/container/executable"
这里我们可以部署一个微服务 HOT Commerce 来演示在 Kubernetes 环境中如何使用 OpenTelemetry Operator 进行自动埋点,并将数据发送到 OpenObserve 中。
这个应用包含 5 个简单的微服务,每个微服务都是用不同的编程语言编写的:
/-> review (python)
/
frontend (go) -> shop (nodejs) -> product (java)
\
\-> price (dotnet)
该应用对应的 Kubernetes 资源清单文件如下:
# hotcommerce.yaml
apiVersion: v1
kind: Service
metadata:
name: price
namespace: hotcommerce
spec:
selector:
app: price
ports:
- protocol: TCP
port: 80
targetPort: 80
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: price
namespace: hotcommerce
spec:
replicas: 1
selector:
matchLabels:
app: price
template:
metadata:
labels:
app: price
annotations:
instrumentation.opentelemetry.io/inject-dotnet: "openobserve-collector/openobserve-dotnet"
spec:
containers:
- name: price
image: public.ecr.aws/zinclabs/sample-price-service-dotnet:3
imagePullPolicy: Always
ports:
- containerPort: 80
resources:
limits:
cpu: "1"
memory: "544Mi"
requests:
cpu: "100m"
memory: "448Mi"
---
apiVersion: v1
kind: Service
metadata:
name: review
namespace: hotcommerce
spec:
selector:
app: review
ports:
- protocol: TCP
port: 80
targetPort: 8004
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: review
namespace: hotcommerce
spec:
replicas: 1
selector:
matchLabels:
app: review
template:
metadata:
labels:
app: review
annotations:
instrumentation.opentelemetry.io/inject-python: "openobserve-collector/openobserve-python"
spec:
containers:
- name: review
image: public.ecr.aws/zinclabs/sample-review-service:51
imagePullPolicy: Always
ports:
- containerPort: 8004
resources:
limits:
cpu: "1"
memory: "544Mi"
requests:
cpu: "100m"
memory: "448Mi"
---
apiVersion: v1
kind: Service
metadata:
name: product
namespace: hotcommerce
spec:
selector:
app: product
ports:
- protocol: TCP
port: 80
targetPort: 8003
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: product
namespace: hotcommerce
spec:
replicas: 1
selector:
matchLabels:
app: product
template:
metadata:
labels:
app: product
annotations:
instrumentation.opentelemetry.io/inject-java: "openobserve-collector/openobserve-java"
spec:
containers:
- name: product
image: public.ecr.aws/zinclabs/sample-product-service-java:53
imagePullPolicy: Always
env:
- name: REVIEW_SERVICE_URL
value: "http://review.hotcommerce.svc.cluster.local"
- name: PRICE_SERVICE_URL
value: "http://price.hotcommerce.svc.cluster.local"
ports:
- containerPort: 8003
resources:
limits:
cpu: "1"
memory: "1048Mi"
requests:
cpu: "100m"
memory: "1048Mi"
---
apiVersion: v1
kind: Service
metadata:
name: shop
namespace: hotcommerce
spec:
selector:
app: shop
ports:
- protocol: TCP
port: 80
targetPort: 8002
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: shop
namespace: hotcommerce
spec:
replicas: 1
selector:
matchLabels:
app: shop
template:
metadata:
labels:
app: shop
annotations:
instrumentation.opentelemetry.io/inject-nodejs: "openobserve-collector/openobserve-nodejs"
spec:
containers:
- name: shop
image: public.ecr.aws/zinclabs/sample-shop-service-nodejs:51
imagePullPolicy: Always
env:
- name: PRODUCT_SERVICE_URL
value: "http://product.hotcommerce.svc.cluster.local"
ports:
- containerPort: 8002
resources:
limits:
cpu: "1"
memory: "544Mi"
requests:
cpu: "100m"
memory: "448Mi"
---
apiVersion: v1
kind: Service
metadata:
name: frontend
namespace: hotcommerce
spec:
type: NodePort
selector:
app: frontend
ports:
- protocol: TCP
port: 80
targetPort: 8001
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
namespace: hotcommerce
spec:
replicas: 1
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
annotations:
instrumentation.opentelemetry.io/inject-go: "openobserve-collector/openobserve-go"
instrumentation.opentelemetry.io/otel-go-auto-target-exe: "/app"
spec:
containers:
- name: frontend
image: public.ecr.aws/zinclabs/sample-frontend-service-go:51
imagePullPolicy: Always
env:
- name: SHOP_SERVICE_URL
value: "http://shop.hotcommerce.svc.cluster.local"
ports:
- containerPort: 8001
resources:
limits:
cpu: "1"
memory: "543Mi"
requests:
cpu: "100m"
memory: "438Mi"
注意上面的每个 Deployment 应用中,我们都添加了对应的 instrumentation.opentelemetry.io/inject-xxx
的 Annotation
,这样就可以实现自动埋点了。
直接使用下面命令部署 HOT Commerce 应用即可:
kubectl create ns hotcommerce
kubectl apply -f hotcommerce.yaml
部署完成后,我们先查看所有的服务是否正常运行:
$ kubectl get pods -n hotcommerce
NAME READY STATUS RESTARTS AGE
frontend-57c47854f7-8cwbp 1/1 Running 0 6m56s
price-5d99b949b8-gzqr6 1/1 Running 0 6m56s
product-85f94894f-7s8hw 1/1 Running 0 6m56s
review-98bc7596f-ptbhk 1/1 Running 0 6m57s
shop-966895886-hgpxt 1/1 Running 0 6m56s
$ kubectl get svc -n hotcommerce
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend NodePort 10.96.3.25 <none> 80:30826/TCP 4m42s
price ClusterIP 10.96.1.147 <none> 80/TCP 4m43s
product ClusterIP 10.96.3.134 <none> 80/TCP 4m42s
review ClusterIP 10.96.1.22 <none> 80/TCP 4m43s
shop ClusterIP 10.96.2.4 <none> 80/TCP 4m42s
我们可以通过 http://<NodeIP>:30826
访问 frontend
服务了,当我们访问 frontend
服务时,OpenTelemetry
会自动为我们的应用程序生成链路追踪数据,并将其发送到 OpenTelemetry Collector,然后 Collector 会将数据发送到 OpenObserve 中。
$ curl http://192.168.0.111:30826/item/1
{"description":"This is a sample product.","id":1,"in_stock":10,"name":"Sample Product","price":100,"rating":5,"review":"This is a great product!","warehouse_location":"A1-B2"}
然后我们就可以在 O2
中查看到有 traces
类型的数据流了。切换到追踪页面,就可以看到我们采集到的链路追踪数据了:
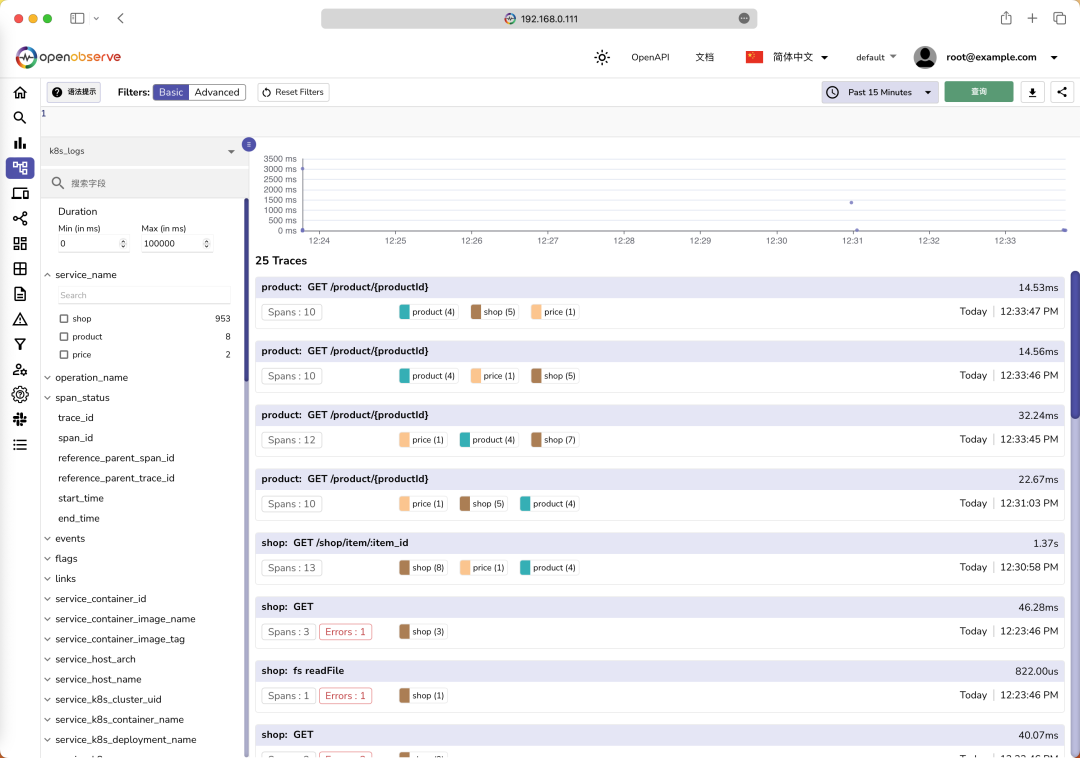
点击一个 Trace ID,就可以查看这个链路追踪的详细信息了:
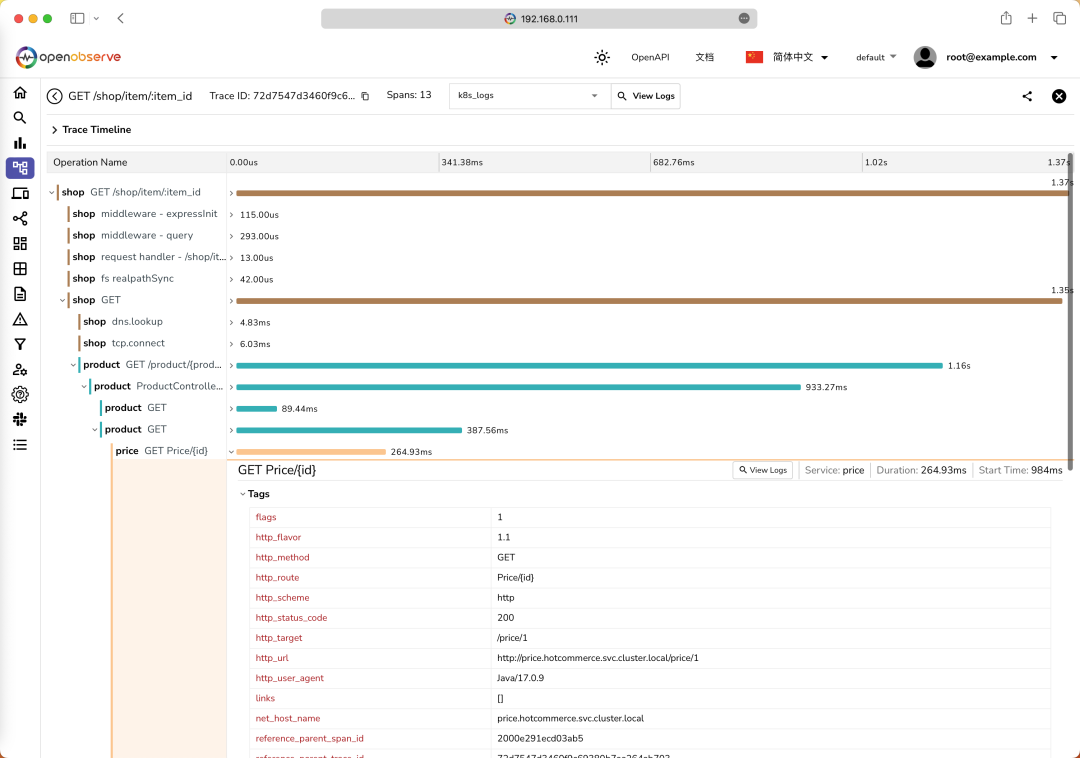
这里我们可以看到这个链路追踪的详细信息,包括每个服务的调用时间、调用耗时、调用结果等信息。
到这里我们就实现了在 OpenObserve 中查看我们的 K8s 集群的观测数据,当然同样的对于非 K8s 集群的应用也可以直接将数据采集到 OpenObserve 中,比如 Fluentd、Vector、Prometheus、OpenTelemetry Collector 等。
此外 O2 还有很多其他功能,比如报警、函数、前端性能监控等,可以关注后续文章。
参考文档
https://openobserve.ai/docs/

