




随着经济形势越发动荡,企业比以往任何时候都更加关注降本增效,在一家公司的IT预算中,云成本是除了人力成本外,最大的一项支出,笔者所在的公司今年的IT预算对比去年几乎腰斩(老板潜台词:“要么降低云成本,要么我就裁员”),于是今年我们团队(基础设施和SRE团队)最大的KPI就是,尽一切可能降低云成本。

通过分析业务,调研开源解决方案和自研相关组件,在保证稳定性的前提下,实现EC2成本从 约10万美金/月下降到了约4万美金/月,节省比例高达60% 。
01 云成本分析
首先就是要完成云成本的洞察,弄清楚钱究竟花在哪些地方了,我们是一家跨境电商公司,所以选择了AWS作为唯一云厂商,为了追求资源弹性、系统韧性和开发敏捷性,我们在2022年就完成了全部业务容器化改造,所有的应用都部署在EKS(Elastic Kubernetes Service,AWS托管版Kubernetes)上,是典型的云原生架构。
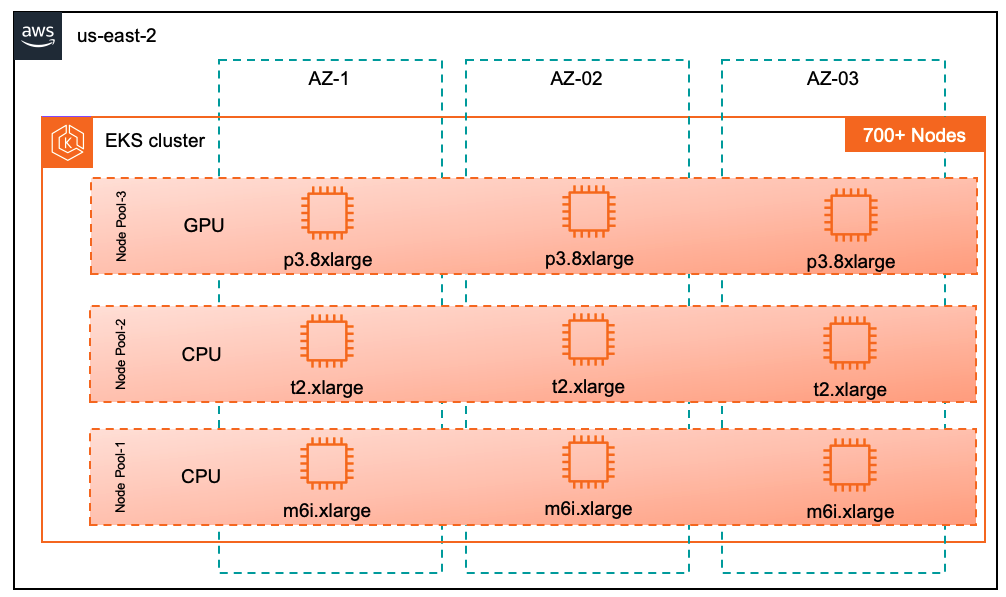
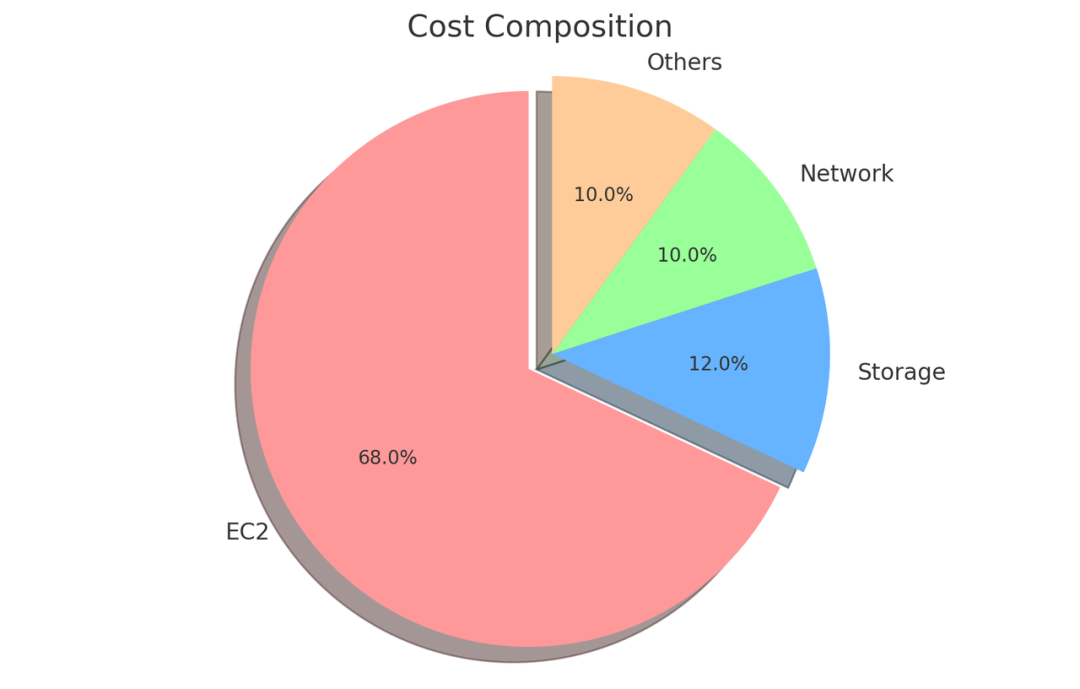
在我们的AWS账单中,成本构成 EC2占绝对大头,大概68%,剩下的存储占12%,网络占10%,其他PaaS层云服务占比不到10%。
02 算力分析 & 优化
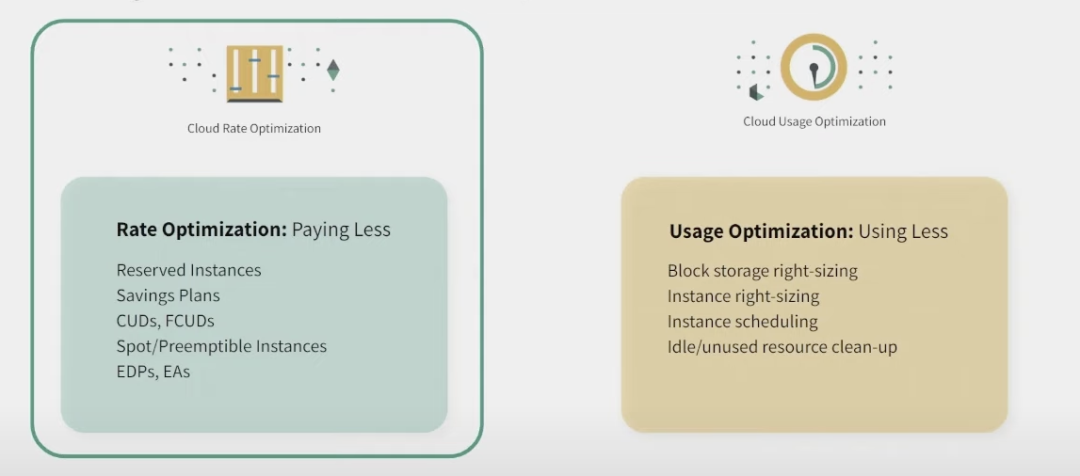
集中力量办大事,于是我们决定从最大的EC2成本着手,要解决的第一个问题。对于成本优化,在业界通常有两种方向:利用率优化(使用更少的机器机器,即Using Less)和费率优化(利用云厂商的折扣优惠,即Paying Less),下面我们从这两个方面展开分析。
2.1 利用率优化
2.1.1 节点利用率优化
首先我们定义一下节点利用率:(所有Pod的资源request) (所有EC2的资源总和)。
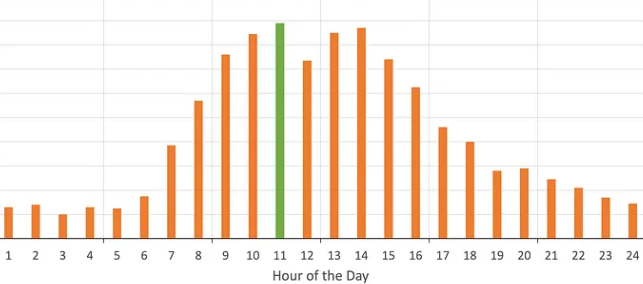
通过分析我们的业务,存在白天业务负载高,HPA扩容业务Pod的实例数,晚上业务负载低,HPA缩容实例数。整体业务负载类似如下图。但是我们的EC2数量是根据峰值业务规模购买的,并没有根据业务负载实时增加或者释放,造成在非高峰时间段,整体EC2的节点利用率只有10%左右,造成非常大的浪费。
那么此点的解决方案就非常显而易见了,通过根据业务的资源请求,实时伸缩节点,在业务高峰时增加节点,业务低谷是减少节点。
通过查找业界开源解决方案,有 Cluster Autoscaler(CA) 和Karpenter[1],大致有如下区别:
| 能力 | Cluster Autoscaler | Karpenter |
|---|---|---|
| Node级别的autoscaling | ✅ | ✅(伸缩速度快三倍) |
| 支持优雅处理Spot中断 | ❌ | ✅ |
| 支持node rightsizing | ❌ | ✅ |
| 节点扩容支持调度属性感知(如Topology spread) | ❌ | ✅ |
| 支持资源碎片整理(binpack) | ❌ | ✅ |
| 支持多种EC2选型 | ❌,受限于Node Group的节点类型 | ✅ |
| node伸缩性能 | 较慢,多层接口调用(managed node group->autoscaling group->ec2创建) | 较快(ec2 fleet接口->ec2创建) |
从上表可以发现,Karpenter从节点选择策略和性能等多方面,都完全超越了Cluster Autoscaler,完美符合我们的应用场景。这里重点介绍一下Karpenter三大提升利用率的核心能力:节点智能选型、node rightsizing和binpack碎片整理。
在开始前,首先介绍一下Karpenter的NodePool,通过配置NodePool,能够限制选择实例类型,如我们使用的NodePool配置如下:
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: karpenter.k8s.aws/instance-category
operator: NotIn
values:
- p
- g
- gr
- key: kubernetes.io/arch
operator: In
values:
- amd64
- key: kubernetes.io/os
operator: In
values:
- linux
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- on-demand
其代表在选择节点时,考虑AWS上无GPU(p,g,gr代表GPU机型)的所有x86架构机型,弄更多配置请查看:https://karpenter.sh/preview/concepts/nodepools/
因为我们本次实施的集群均为CPU节点,所以先排除了GPU节点,Karpenter也可以用来优化GPU成本,而且效果非常好,后面我们会分享更多GPU算力的优化,敬请关注!
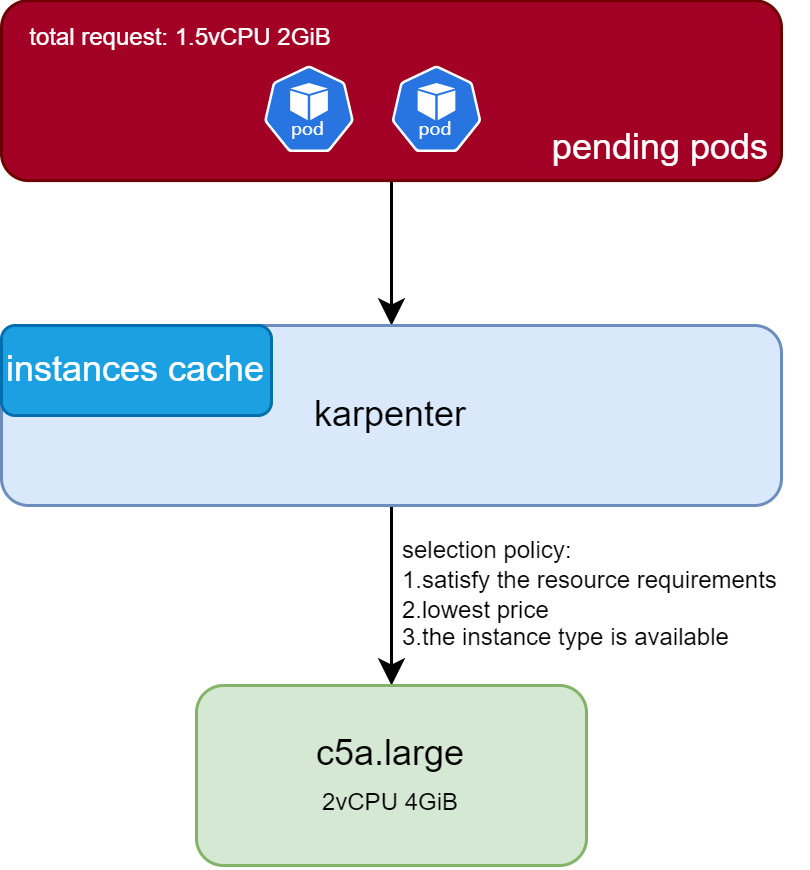
节点选型如上图所示,假设多个Pending Pod,总资源request为1.5C 2GiB,Karpenter在内存中缓存有AWS所有机型的规格和价格相关信息,最后会从容量大于1.5C 2GiB,同时匹配NodePool要求的机型中,选择有余量并且价格最低的机器。当然你也可以通过Karpenter NodePool做一些节点限制,比如只能选择某些高性能芯片(如c7a,芯片为AMD EPYC 9R14)的机型。
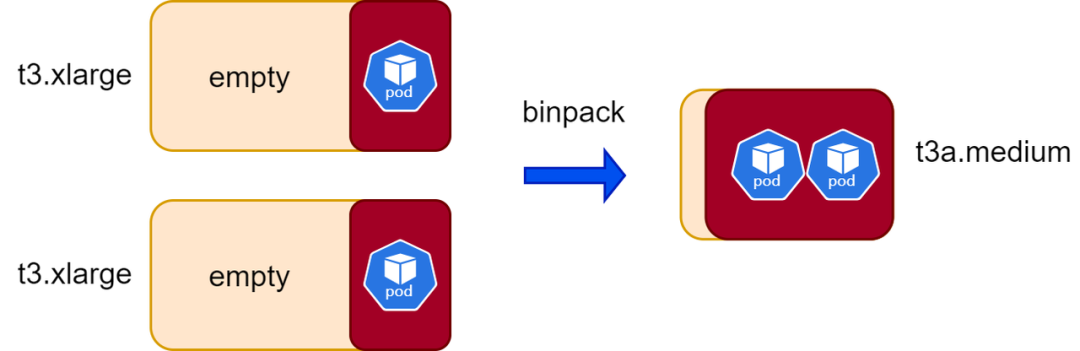
binpack碎片整理如上图所示,在多台较大节点利用率不高时,Karpenter会将其合并到一台规格较小的节点,同时删除之前的2台较大节点,达到节省成本的目的。

Node righsizing如上图所示,在一个节点利用率较低时,Karpenter会将其驱逐到一个规格更小的节点,同时删除之前的较大节点,达到节省成本的目的。
2.1.2 Workload利用率优化
首先我们定义一下workload利用率:(workload的资源usage) (workload的资源request)。
目前业界比较通用的解决方案是VPA或类似解决方案(如crane),但是如果和HPA使用不当,可能会造成冲突,所以目前我们没有采用。
比如我一个deployment请求资源为100MiB,HPA设置在70%时扩容。因为业务量较少,deployment长期处于40MiB的使用量,VPA根据历史usage将资源request设置为50MiB,此时利用率大于70%,会触发HPA持续扩容,这个不是我们期待的。要设计一个通用的解决方案去适配使用HPA(包括不同metrics)的业务和未使用HAP的业务难度较大。
而且在集群中,我们存在部分Java业务,此类业务启动时耗费的资源是启动后使用资源的好几倍,VPA是根据历史数据推荐,并不能很好的适配此类场景。
2.2 费率优化
云厂商对同一种节点实例,有不同类型,同一类型又有不同的计费模式,如在aws有按需计费(on-demand),预留实例计费/Savings Plan计费(承诺用量后获得折扣,一般是按需7折左右),Spot计费(一般是按需计费的2折左右)。
这里着重介绍一下spot实例,AWS全球有500万台服务器,不可能每时每刻都有人用,所以一定有闲置资源,AWS就会把这个闲置资源拿出来“甩卖”,价格通常是按需实例的1-3折,非常便宜,但是AWS随时会把Spot实例回收掉,并且回收机制完全黑盒,也就意味着应用面临随时中断的风险,如下是m6i.xlarge在us-east-1(N. Virginia)不同计费模式的价格对比:
| 实例类型 | On Demand 价格 | Spot价格和折扣 | Savings Plan价格和折扣 |
|---|---|---|---|
| m6i.xlarge(4C16G) | $140.16/月 | $42.559/月,3折 | $102.97/月,7折 |
可以发现Spot相比on-demand和savings plan,有更大的折扣价,而且Savings Plan有一个缺点,即使深夜服务器我没使用,也要为此付费,还有1-3年的合同锁定期,完全丧失了云的“弹性”,等于把云当成物理机房使用,可想而知,成本是非常高昂的。所以综合下来,我们希望直接使用Spot实例,当AWS回收Spot实例时,至少会提前2min发送中断通知[2],需要在这2min之内,把业务迁移到其他节点,Karpenter处理逻辑如下:
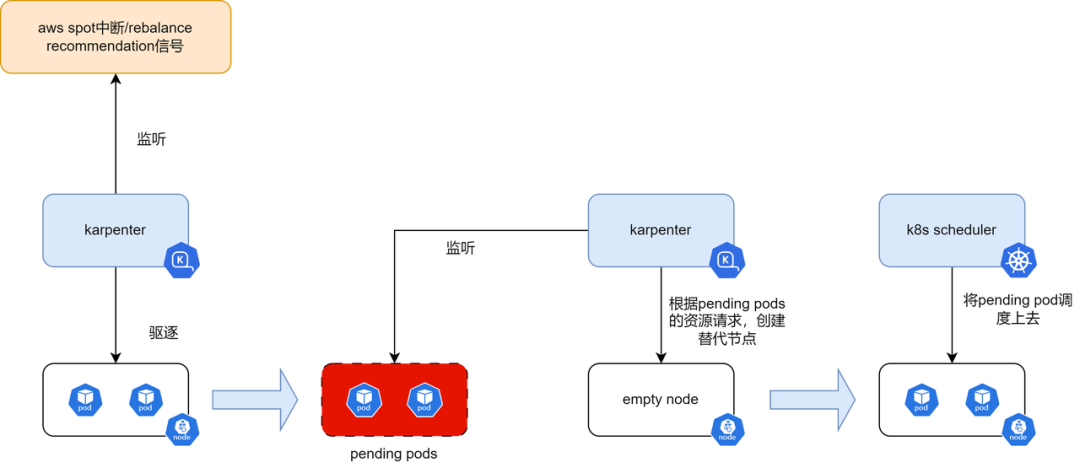
根据如上处理逻辑,对于一个业务的所有Pod,如果能在收到中断信号后,在2min之内迁移到其他节点,理论上这种业务是完美适合spot节点的。
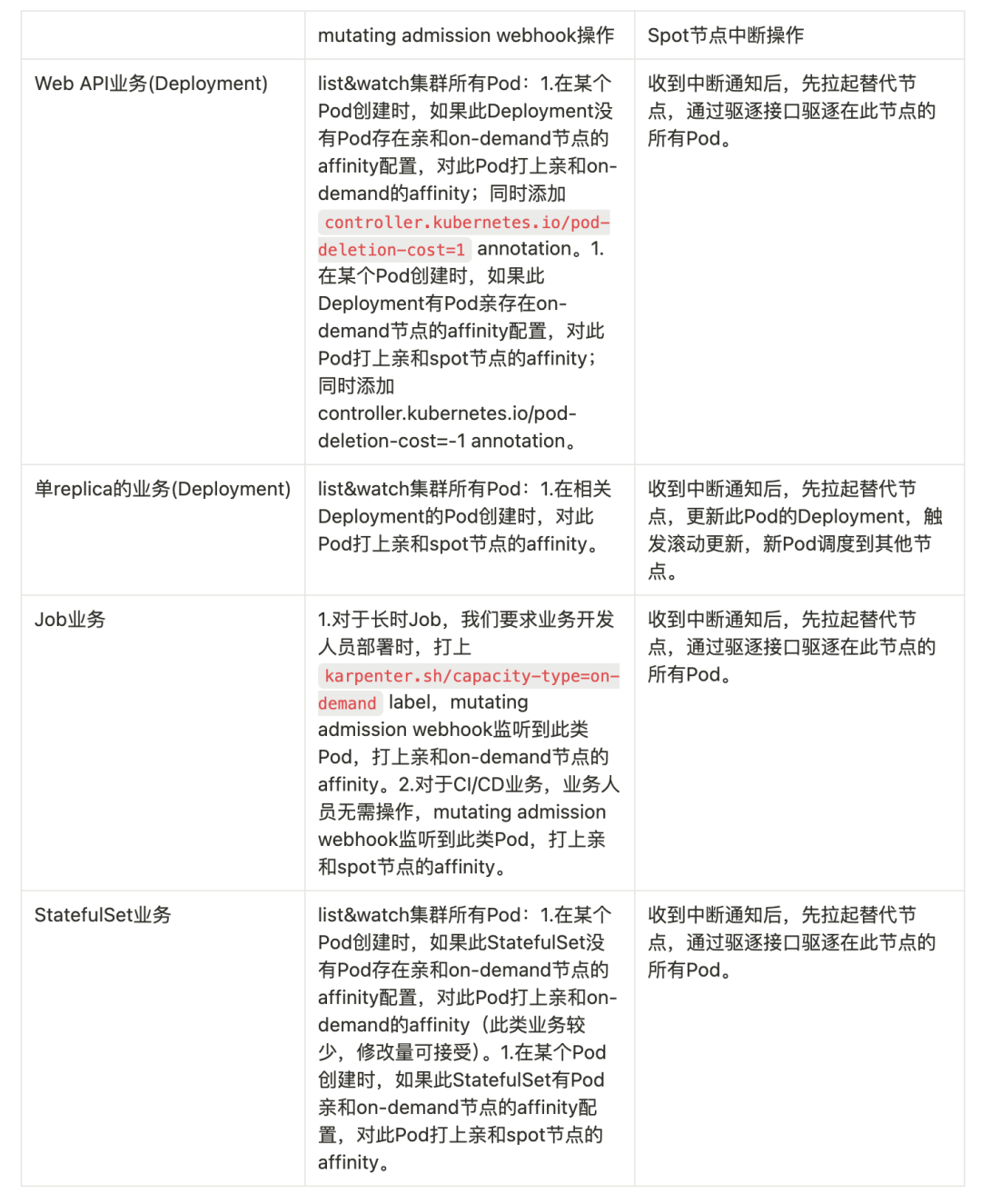
对于我们的业务,我们分析并对其做了如下划分:
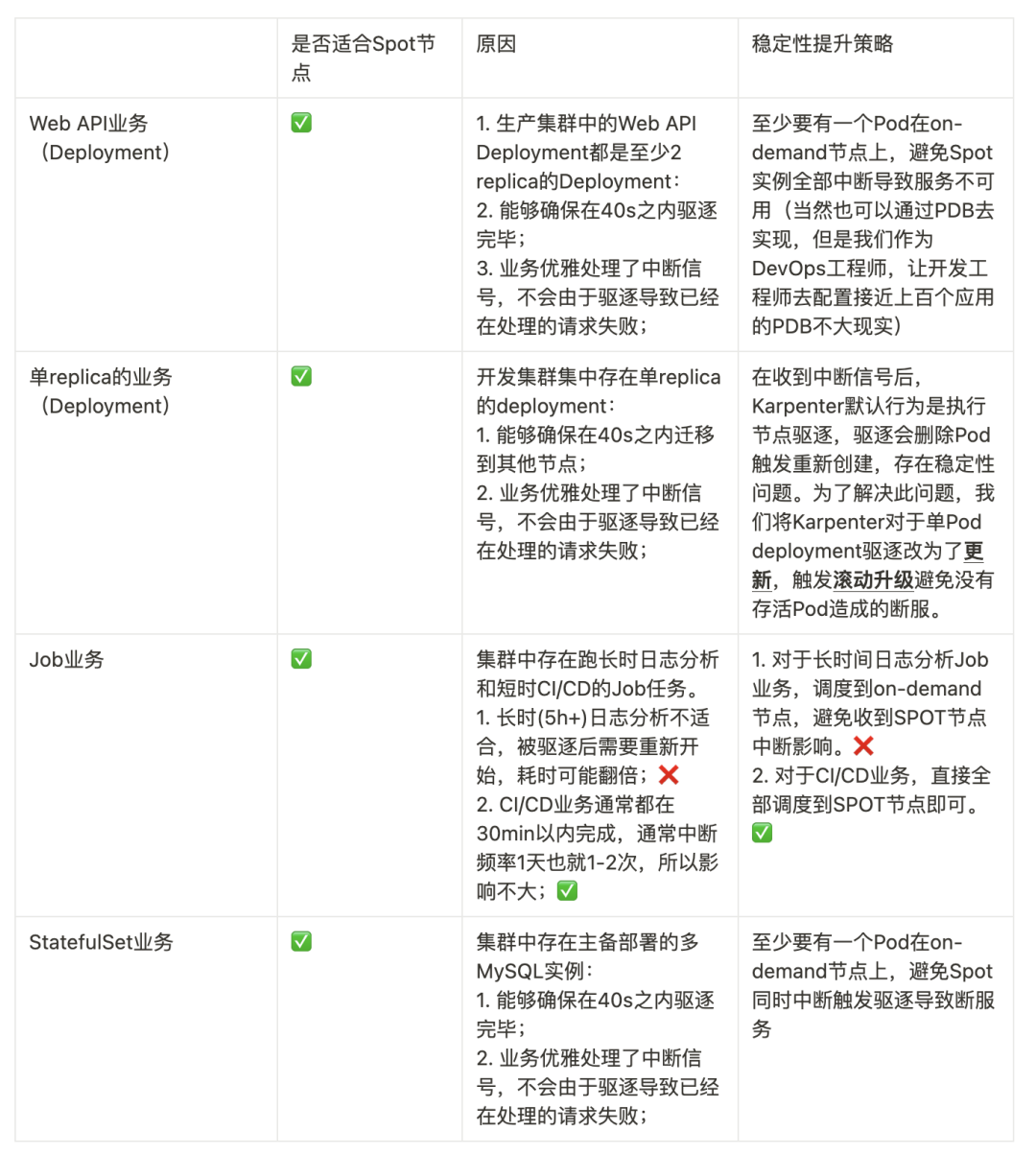
对于如上表格中的具体设计,我们将在下面章节展开。
03 架构 & 实现
根据如上分析,我们的整体架构实现如下:
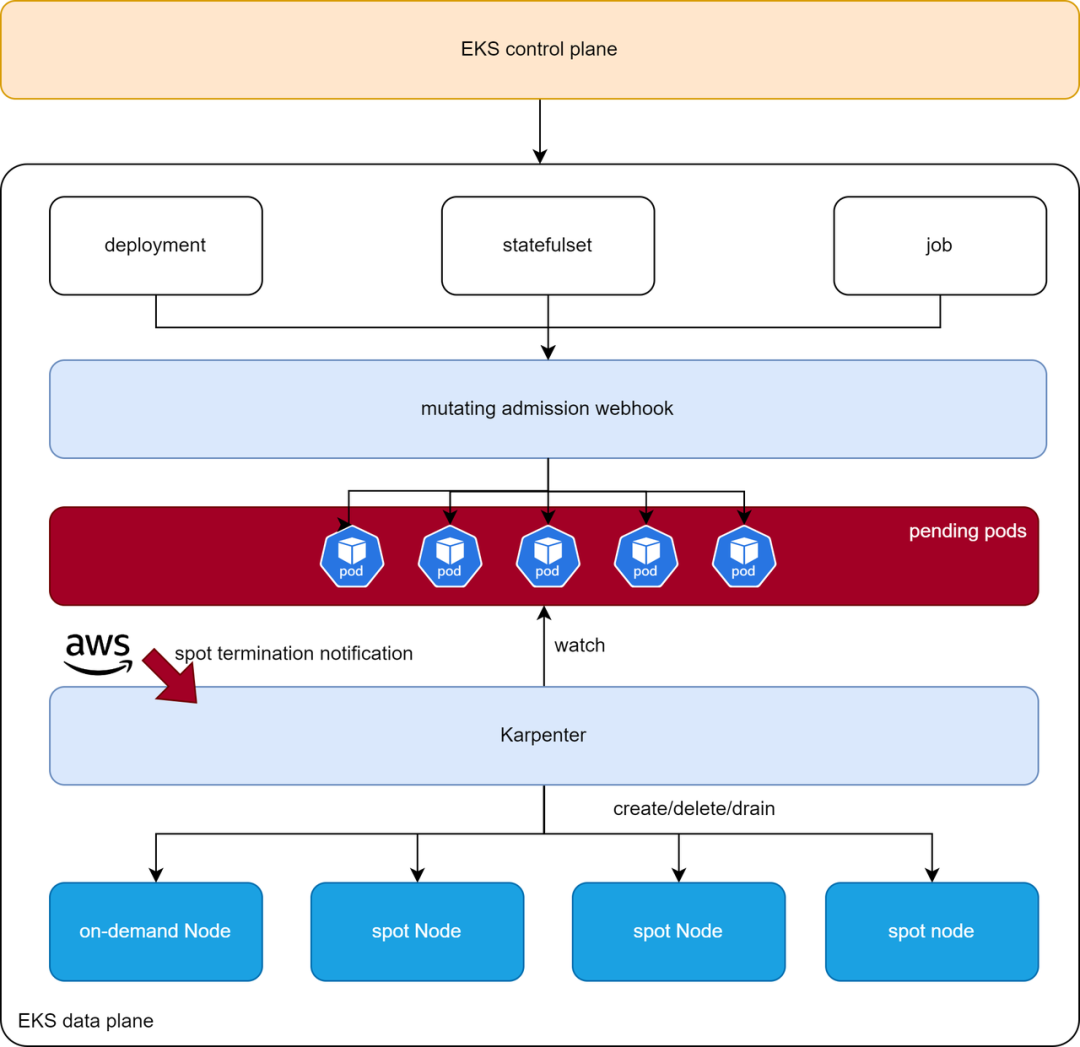
用户部署应用时(Deployment/StatefulSet/Job),1)mutating admission webhook对应用的Pod进行操作,控制应用级别的Pod分布;2)Karpenter根据Pod资源要求,创建/删除节点;3)同时在从AWS端收到spot中断通知时,迁移spot节点上面的Pod,其中我们主要实现如下功能:
实现了一个mutating admission webhook,监听对于服务(Deployment/StatefulSet/Job)的Pod创建和分布,对其进行patch affinity,亲和spot/on-demand节点; 修改了Karpenter对单replica deployment Pod的驱逐逻辑,走滚动升级接口而不是驱逐接口; Karpenter在收到中断通知时,默认是先驱逐此节点的Pod(出现Pending Pod),然后由Pending pod触发新节点创建,在Node新创建出来之前,业务可能出现稳定性问题;我们修改为先拉起替代节点(耗时40s左右),然后驱逐此节点(耗时40s左右),能在2min后的节点销毁到来之前完成,稳定性得到提升。
这里详细描述 a 点。首先,spot节点存在label: karpenter.sh/capacity-type=spot
,on-demand节点存在label: karpenter.sh/capacity-type=on-demand
。所以,对于需要调度到spot节点的Pod,通过mutating admission webhook自动添加如下affinity:
...
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: node.kubernetes.io/capacity
operator: In
values:
- spot
...
使用 preferredDuringSchedulingIgnoredDuringExecution
而不使用 requiredDuringSchedulingIgnoredDuringExecution
是为了避免没有spot资源导致最后无法调度。对于需要调度到on-demand的Pod,通过mutating admisssion webhook自动添加如下affinity:
...
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- key: node.kubernetes.io/capacity
operator: In
values:
- on-demand
...
同时,我们需要考虑缩容场景,如果不对缩容做相关控制,可能导致on-demand节点上面的Pod全部被缩容导致只有在spot节点,从而因为spot节点同时中断导致断服。所以在缩容时,优先缩容在spot节点上的Pod,此处通过 controller.kubernetes.io/pod-deletion-cost
annotation 实现:
对于亲和spot节点的Pod,mutating admission webhook对其添加 controller.kubernetes.io/pod-deletion-cost=-1
的annotation;对于亲和on-demand节点的Pod,mutating admission webhook对其添加 controller.kubernetes.io/pod-deletion-cost=1
的annotation;
Karpenter在创建节点去承载这些Pod时,会考虑如上设置的affinity,创建on-demand/spot节点,通过对业务应用混合部署(on-demand/spot)的形式,达到即稳定,又低成本。
最后综合以上描述,对于我们4种类型业务,我们的 mutating admission webhook/增强Karpenter 做如下操作:
通过如上手段,我们多个集群的EC2成本从 约10万美金/月 下降到了 约4万美金/月,节省比例高达60%,同时在开发和生产集群,2个月以来稳定性都没有出现问题。
04 Serverless真的便宜?
为了应对此类波峰波谷业务,我们也调研了AWS Lambda,AWS Fargate,以一个程序(2Core/2GiB)运行一小时为例,消耗成本(us-east-2)对比如下,发现Lamda成本是EC2的1.5倍:
| AWS Lambda[3] | EKS Fargate[4] | EKS/EC2[5] |
|---|---|---|
| 0.1198$ | 0.0896$ | 0.077$,使用c5a.large(2Core/4GiB),还有2GiB的剩余 |
最后我们还是选择了 EKS + EC2 的使用形式,结合我们修改后的Karpenter,即享受到了极致的折扣(按需伸缩节点,使用Spot并且无业务中断),也避免了后续被Savings Plan绑定的风险。Karpenter + EKS 完全重塑了我们底层基础设施的使用方式,让我们的底层基础设施具备极速弹性同时,具备最高的性价比,已经成为我们企业底层基础设施的最佳实践。
05 展望
Karpenter开源版本目前只能根据Pod的资源request,负责节点的选择、创建和删除,未对业务稳定性做深入设计,后续我们将会贡献此篇文章中的mutating admission webhook到开源社区中。同时,Karpenter现在只支持了Azure和AWS,后续我们将适配国内云,如阿里云[6]。欢迎添加我们的小助手(请备注:Karpenter),加入我们的Karpenter中文社区:

参考资料
[1] - https://github.com/aws/karpenter-provider-aws [2] - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-instance-termination-notices.html , https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/rebalance-recommendations.html [3] - https://aws.amazon.com/lambda/pricing/ [4] - https://aws.amazon.com/fargate/pricing/ [5] - https://aws.amazon.com/ec2/pricing/on-demand/ [6] - https://github.com/cloudpilot-ai/karpenter-provider-alicloud
