Reflexion: Language Agents with Verbal Reinforcement Learning 本文是由Northeastern University, Massachusetts Institute of Technology, Princeton University联合发表,主要通过反思的形式来提升 Agent 的决策能力。
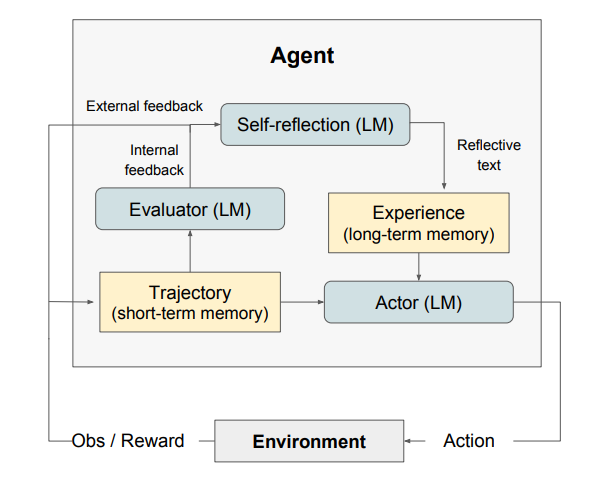
Reflexion 方法主要由三个独立但相互协作的模块构成:首先是 Actor 模块,记作 ,负责生成文本和动作;其次是 Evaluator 模块,标记为 ,它的作用是对 Actor 模块的输出进行评估;最后是 Self-Reflective 模块,简写为 ,它提供语言增强信号用来促进 Actor 模块的自我优化。
2.1 Actor
Actor 是基于大型语言模型构建的,它能够根据状态观察来生成必要的文本和执行动作。这与经典的基于策略的强化学习场景相似,作者在t时刻从当前策略 中选取一个动作或生成,同时从环境中获取一个观察。作者研究了包括 Chain of Thought 和 ReAct 在内的多种执行者模型。这些多样化的生成模型使他们在 Reflexion框架下探究文本和动作生成起到了指导性作用。
2.2 Evaluator
在 Reflexion框架内,Evaluator 扮演着至关重要的角色,其核心任务是评定 Actor 产出成果的品质。Evaluator 接收 Actor 产出的路径作为数据输入,并据此计算出一个奖励值,这个值旨在量化其在特定任务环境中的表现水平。为了使 Evaluator 的表现更好,作者根据任务类型的不同,设置了不同的奖励函数。如在推理任务,作者基于完全匹配(EM)评分的奖励函数,确保生成的输出与预期解决方案紧密对齐。在决策制定任务中,作者采用针对特定评估标准的预定义启发式函数,以确保决策过程能够高效地产生符合既定目标和约束的解决方案。