




历史学习笔记
继续学习HDFS的相关知识,DataNode工作机制解析
概述
DataNode通常在每个节点都会部署一个,主要用于存储数据。负责处理客户端的读写请求,根据NameNode的指令执行数据块的创建、删除、追加、复制等操作。
DataNode的主要功能:
管理所在节点上存储数据的读写,及存储每个文件的数据块
定期向NameNode汇报该节点的数据块元数据信息
执行数据的pipeline复制
工作机制
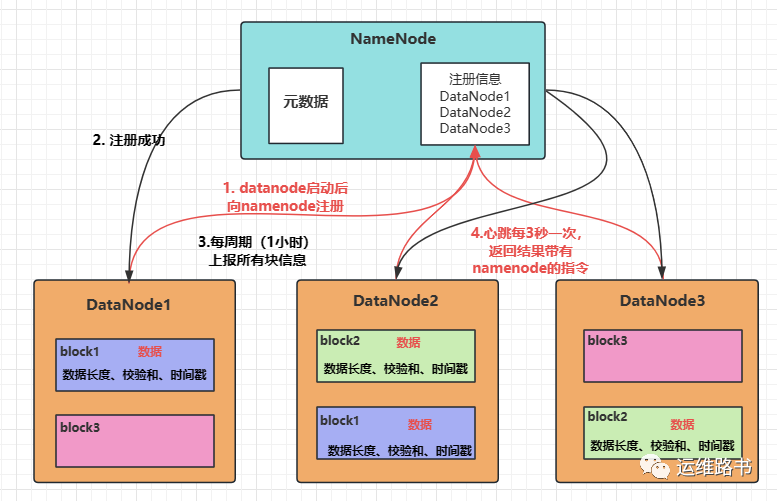
DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令。如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
存储格式
DataNode 上的数据块以文件形式存储在本地磁盘上,包括两个文件:
文件的数据块
数据块元数据(长度、校验和、时间戳等)
进入某一个 DataNode 节点,找到数据块存储的路径,如下所示:
[root@hadoop-01 ~]# ls -l-rw-r--r-- 1 hdfs hdfs 49 Jul 8 16:51 blk_1080255312-rw-r--r-- 1 hdfs hdfs 11 Jul 8 16:51 blk_1080255312_6514554.meta-rw-r--r-- 1 hdfs hdfs 49 Jul 8 16:51 blk_1080255316-rw-r--r-- 1 hdfs hdfs 11 Jul 8 16:51 blk_1080255316_6514558.meta
可以看出,HDFS 数据块的文件名组成格式为:
blk_*:数据块,保存具体的二进制数据;
blk_*.meta:数据块的元数据(长度、校验和、时间戳等)。
数据完整性
1)当DataNode读取block的时候,它会计算checksum
2)如果计算后的checksum,与block创建时值不一样,说明block已经损坏。
3)client读取其他DataNode上的block。
4)DataNode在其文件创建后周期验证checksum
超时机制
由于 DataNode 故障无法与 NameNode 通信,NameNode 不会立即把该节点标记为不可用。要经过一段时间,这段时间可称为超时时长。
HDFS 默认的超时时长为 10分钟 + 30秒,超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
dfs.namenode.heartbeat.recheck-interval 默认为 5分钟
dfs.heartbeat.interval 默认为 3秒
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property><name>dfs.namenode.heartbeat.recheck-interval</name><value>300000</value></property><property><name> dfs.heartbeat.interval </name><value>3</value></property>
多目录配置
通过修改 hdfs-default.xml 文件的相关配置,设置相关 DataNode 数据目录。如下所示:
<property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}01/dfs/data,file://${hadoop.tmp.dir}02/dfs/data</value></property>
回收站机制
如果开启回收站功能,被删除的文件在指定的时间内,可以执行恢复操作,防止数据被误删除情况。
HDFS 内部具体实现则是在 NameNode 中启动一个后台线程(Emptier),该线程专门管理和监控文件系统回收站下面的文件,对于放进回收站的文件且超过生命周期,就会自动删除。
通过修改 core-site.xml 文件的相关配置,如下所示:
<property><name>fs.trash.interval</name><value>1440</value></property>
fs.trash.interval=0,表示禁用回收站机制
1440 单位为分钟即24小时后删除
配置文件修改立即生效,不需要重启HDFS!!!需要分发到集群的每一个数据节点上。
回收站默认路径为 usr/root/.Trash/Current
当需要恢复文件时,需要使用mv命令手动恢复
