




上一篇文章对Hadoop的概念和基础理论做了简要介绍
接下来会对Hadoop的三大组件逐一的详细解析
本期先来看存储系统 HDFS
HDFS简介
HDFS: Hdaoop分布式文件系统
Hdaoop核心组件之一,位于大数据生态圈的最底层,用于解决海量数据存储问题。
HDFS是横跨多台计算机上的文件存储系统
HDFS是一种能够在普通硬件上运行的分布式文件系统,具有高度容错的特性,适用于大数据集的应用程序,适合存储TB和PB级别的数据
HDFS使用多台计算机存储文件,并且提供统一的访问接口,可以像访问一个普通的Linux文件系统一样使用分布式文件系统
HDFS应用场景
适合场景:
大文件
数据流式访问
一次写入多次读取
低成本部署,廉价PC
高容错
不适合场景:
小文件
数据交互式访问
频繁任意修改
低延迟处理
HDFS特性
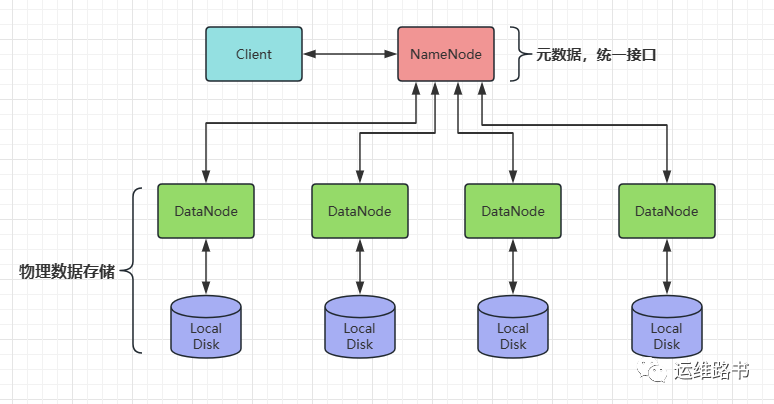
官方HDFS架构图
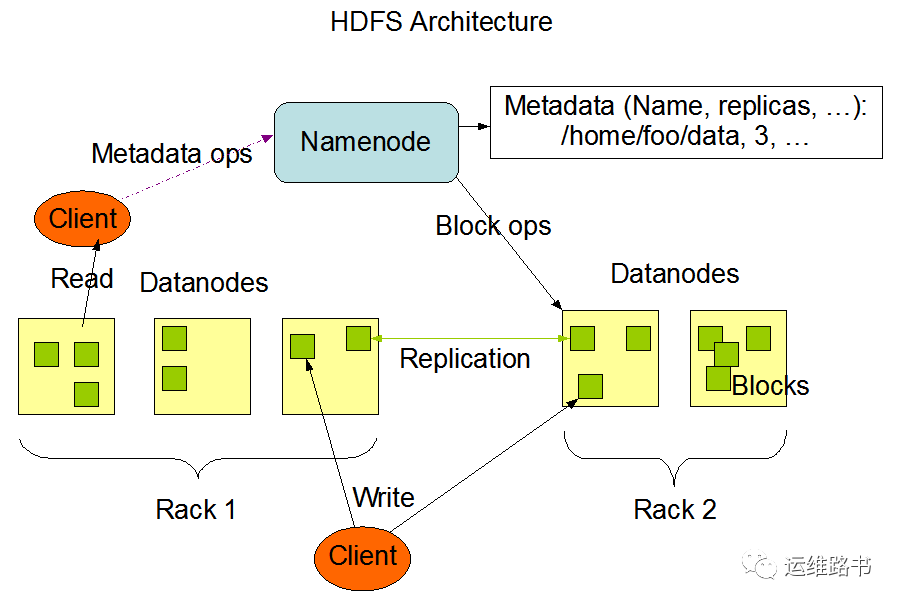
概述:
主从架构
分块存储
副本机制
元数据记录
抽象统一的目录结构(namespace)
HDFS角色与职责
主角色:NameNode
NameNode 职责:
NameNode仅存储HDFS的元数据:文件系统中所有文件的目录树,并跟踪整个集群中的文件,不存储实际数据。
NameNode 知道HDFS中任何给定文件的块列表及其位置,使用此信息NameNode知道如何从块中构建文件。
NameNode 不持久化存储每个文件中给个块所在的datanode的位置信息,这些信息会在系统启动时从DataNode中重建。
NameNode 是Hadoop集群中的单点故障。
NameNode 所在机器通常会配置大量内存。
从角色:DataNode
DataNode 职责:
DataNode 负责最终数据块block的存储。
DataNode启动时,会将自己注册到NameNode并汇报自己负责持有的块列表。
当某个DataNode关闭时,不会影响数据的可用性,NameNode将安排由其他DataNode管理的块进行副本复制。
DataNode所在机器通常配置大量的硬盘空间,因为实际数据存储在DataNode中。
主角色辅助角色:SecondaryNameNode
注意:不是namenode的备份节点
Secondary NameNode 充当NameNode 的辅助节点,但不能替代NameNode 。
主要是帮助主角色进行元数据文件的合并动作,可以通俗理解为主角色的 “秘书”。
HDFS写文件流程
核心概念
1
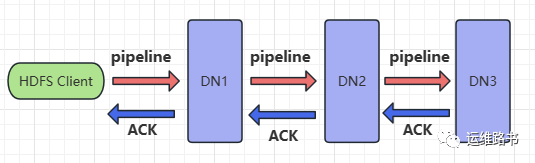
Pipeline管道
Pipeline, 管道,这是HDFS在上传文件写数据过程中采用的一种数据传输方式。
客户端将数据块写入第一个数据节点,
第一个数据节点保存数据之后再将块复制到第二个数据节点,
后者保存后将其复制到第三个数据节点。
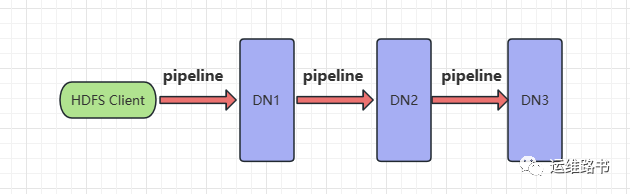

为什么DataNode之间采用pipeline线性传输?
为什么不是一次性发送给三个DataNode的拓扑式传输呢?

01
数据以管道的方式,顺序地沿着一个方向传输,这样能够充分利用每台机器的带宽,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时
02
在线性推送模式下,每台机器所有的出口带宽都用于以最快的速度传输数据,而不是在多个接收者之间分配带宽。
2
ACK应答响应
ACK (Acknowledge character) 即确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。
HDFS pipeline管道传输数据的过程中,传输的反方向会进行ACK校验,确保数据的传输安全。
3
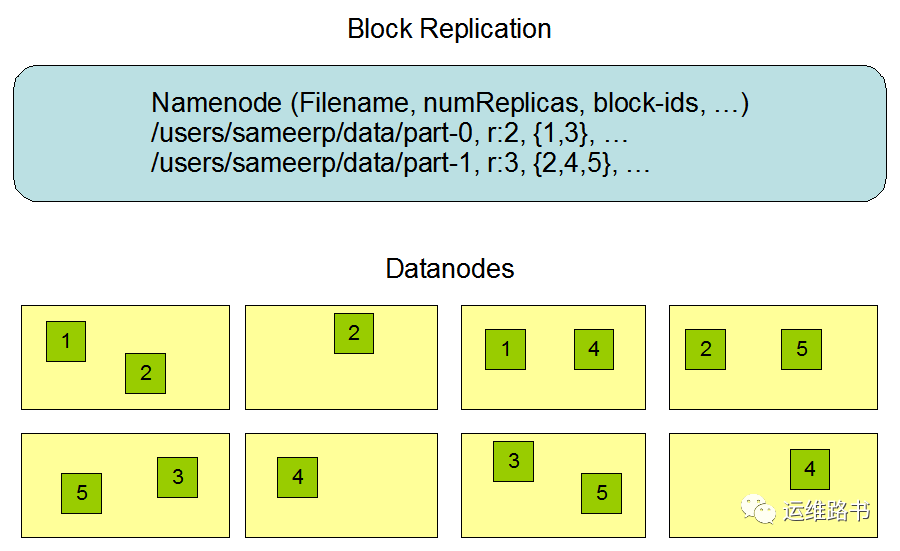
默认3副本存储策略
默认副本存储策略由 BlockPlacementPolicyDefault指定
第一块副本:优先客户端本地,否则随机。
第二块副本:不同于第一块副本的不同机架
第三块副本:第二块副本相同机架的不同机器
如果不存在多个机架或者没有机架感知,则第二三块副本选择随机存储,总之不能将三个副本存储在同一台机器上。
写文件流程
HDFS写文件流程图
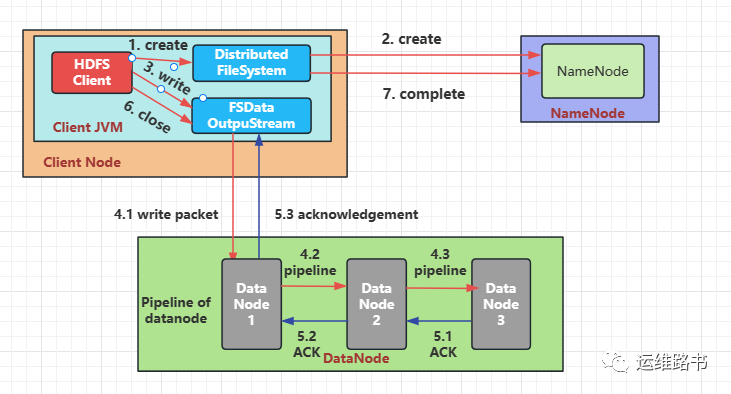
1.
HDFS客户端创建对象实例DistributedFileSystem,该对象中封装了与HDFS文件系统交互的操作方法。
2.
调用DistributedFileSystem对象的create()方法,通过RPC请求NameNode创建文件。NameNode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过,NameNode就会为本次请求记下一条记录,返回FSDataOutputStream输出流对象给客户端用于写数据。
3.
客户端通过FSDataOutputStream输出流开始写入数据。
4.
客户端写入数据时,将数据分成一个个的数据包(packet 默认64K),内部组件DataStreamer请求NameNode挑选出适合存储数据副本的一组DataNode地址,默认是3副本存储。
4.1.
DataStreamer将数据包流式传输到pipeline的DataNode1
4.2.
DataNode1存储数据包后将它发送到pipeline的DataNode2
4.3.
DataNode2存储数据包后将它发送到pipeline的DataNode3
5.
传输的反方向上,会通过ACK机制校验数据包传输是否成功。
6.
客户端完成数据写入后,在FSDataOutputStream输出流上调用close()方法关闭。
7.
DistributedFileSystem联系NameNode告知其文件写入完成,等待NameNode确认。
因为NameNode已经知道文件由哪些块组成(DataStream请求分配数据块),因此仅需等待最小副本数上传成功,即可成功返回。最小副本数由参数dfs.namenode.replication.min指定,默认值是1。
小结
小结
NameNode是HDFS系统访问的唯一入口,只有访问NameNode才能告诉客户端能不能上传以及把数据上传到哪。因为NameNode维护着元数据,管理着DataNode的状态。
数据实际上传过程是客户端直接与DataNode交互,采用pipeline管道的方式,以数据包的形式传输数据。同时在传递的反方向上进行ACK校验。
数据存储默认采用三副本策略
