




核心观点
市场压力:当前MDS虽然粘性强,但市场力量正在推动其转型,特别是工具的商品化风险正在逼迫领导者做出改变。
应用于数据栈的类比:分布式扩展的管理能力在很多工作负载中不再是必需的,导致现代数据平台的复杂度超出实际需求。
计算引擎的多样化趋势:未来可能会看到更多的专用计算引擎取代传统大规模并行处理(MPP)系统。
RAG(检索增强生成)与多代理框架:未来数据平台可能会加入RAG等功能,并逐步向多代理系统方向发展,形成类似企业组织结构的多层协作框架。
未来专用数据引擎的兴起:像DuckDB这样的单节点引擎的受欢迎程度正在快速上升,它们可能成为未来数据平台中的“小型钢厂”,削弱传统大平台的市场。
自动化与代理技术的未来:代理技术的兴起将为未来自动化和智能应用提供广阔的市场空间,MDS的未来发展可能围绕这一新领域展开。
-----
计算性能的快速提升和现代数据栈(MDS)的日益复杂已超出大多数传统分析工作负载的需求。目前,绝大部分分析任务仅涉及小规模数据集,通常可在单节点上执行,这削弱了分布式、高度可扩展数据平台的价值主张。因此,我们认为,最初为仪表盘服务的MDS必须演进为智能应用平台,以协调复杂的数据资产并支持多代理应用系统。尽管数据平台具有粘性,但我们观察到市场力量正在联手对现有商业模式施加压力。
我们邀请了Fivetran首席执行官George Fraser参与讨论。作为一家基础设施软件公司,Fivetran对数据流、数据规模、数据来源及其使用方式的演变有着独特的洞察。在本期节目中,我们探讨了一个假设:许多在数据平台上进行的分析工作可能面临被"足够好"且具成本效益的工具商品化的风险,这迫使当前MDS领导者不得不考虑转型。
克莱顿·克里斯滕森(Clay Christensen)的理论在关键时刻再次显现其重要性
我们的许多听众可能熟悉克里斯滕森在牛津大学的系列经典讲座,他以极其简洁的方式阐述了颠覆性创新理论。主要内容概括如下:
 https://www.youtube.com/watch?v=rpkoCZ4vBSI
https://www.youtube.com/watch?v=rpkoCZ4vBSI
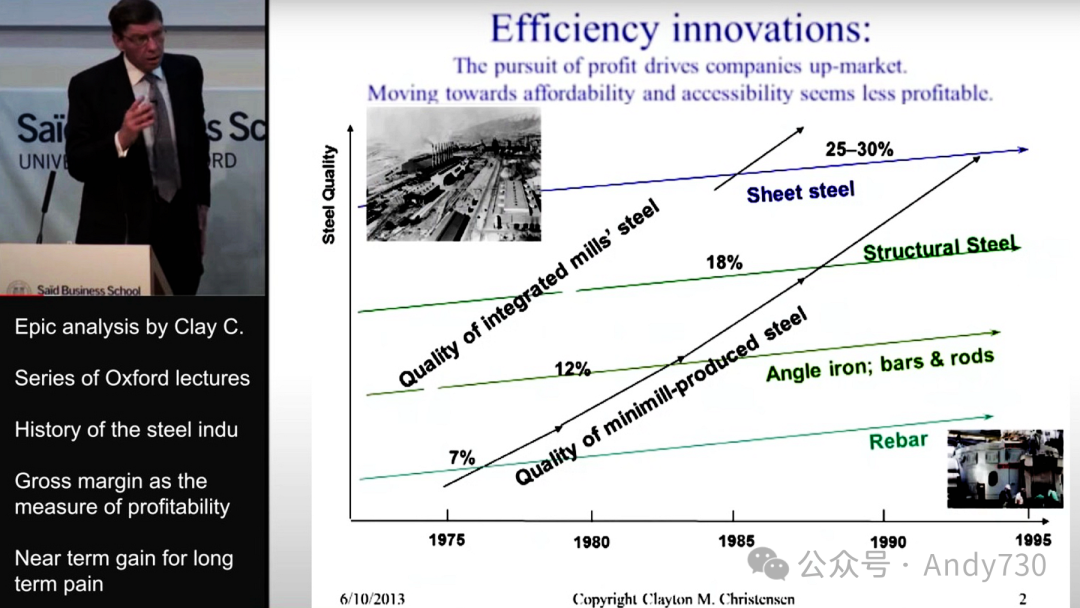
克里斯滕森以钢铁行业为例解释他的模型。历史上,大部分钢铁由综合钢厂生产,建造这样一个钢厂需投资100亿美元。随后出现了"小型钢厂",它们使用电弧炉熔化废金属,能以比综合钢厂低20%的成本生产钢材。
小型钢厂在1960年代末变得可行。由于其产品质量普遍较差,小型钢厂最初瞄准了钢筋市场。综合钢厂认为"让小型钢厂接手这7%低利润率的业务"。如上图所示,随着综合钢厂逐步退出钢筋市场,它们的利润率有所改善,这让它们感到安然无忧。然而,当最后一家综合钢厂在70年代末退出钢筋市场时,价格骤降,该市场变成了商品化市场。随后,小型钢厂逐步向上渗透到利润较高的角钢和型钢市场,最终导致综合钢厂模式崩溃,除一家外全部破产。
克里斯滕森指出,类似情况在汽车行业(以丰田为例)和其他多个行业都曾发生。我们在计算机系统领域也观察到这一现象。我们认为,尽管存在一些显著差异,但类似的动态可能也会在软件行业发生,尤其是在数据平台栈领域。
将钢铁行业案例应用于现代数据栈生态系统
下图展示了克里斯滕森案例中钢铁行业与数据领域的类比。
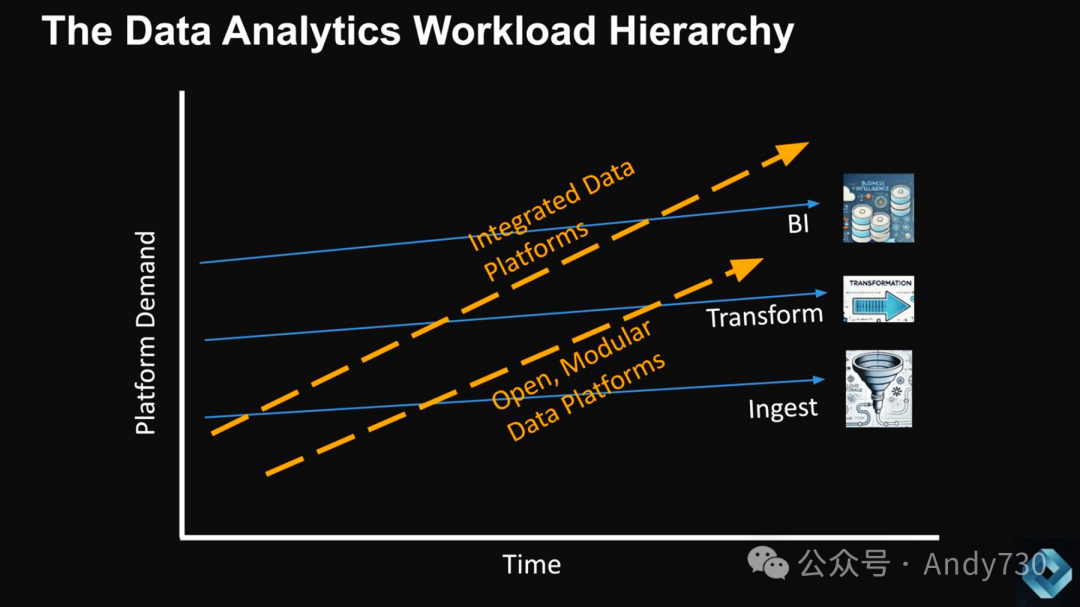
数据导入、转换和商业智能分别对应钢筋、角钢和型钢。需要强调的是,我们在此类比中讨论的是对数据平台的需求。尽管用于从应用程序中提取数据的连接器较为复杂,但相比于当今数据平台日益增长的规模和复杂性,将数据加载到系统中的需求相对较小。换言之,对于大多数工作负载而言,分布式扩展管理能力的复杂度已超出实际需求。现代数据平台为了证明其复杂度的合理性,必须向更高层次的工作负载迁移。
值得注意的是,这一类比与钢铁行业存在差异。综合钢厂在"层级"上达到了极限,没有进一步的扩展空间,最终走向失败。而像Snowflake和Databricks这样的公司仍有可拓展的总潜在市场(TAM)机会。
Fivetran对数据行业的独特洞察
在此背景下,我们邀请了Fivetran首席执行官George Fraser参与讨论。Fivetran是定义现代数据栈(MDS)的标志性公司之一。Snowflake、Fivetran、dbt和Looker被视为最初MDS中的"四骑士"。
以下ETR幻灯片展示了Fivetran在市场中的显著地位。
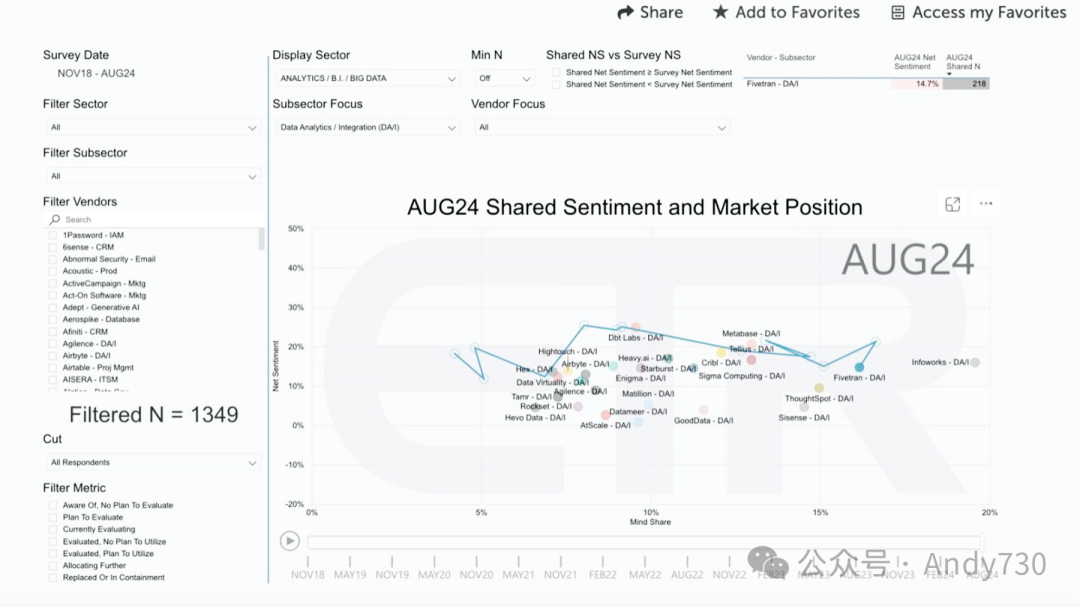
该数据源自2024年8月对1349名IT决策者的调查,呈现了ETR数据集中数据/分析/集成领域的新兴公司(即私有公司)。纵轴表示净情绪指数,即对产品使用意图的衡量,横轴代表市场认知度。蓝色曲线显示了自2020年以来Fivetran的显著增长趋势。
问题1:George Fraser,当前的现代数据栈在复杂性与规模上的发展,是否已超越了大多数工作负载的实际需求?
大数据的实际规模
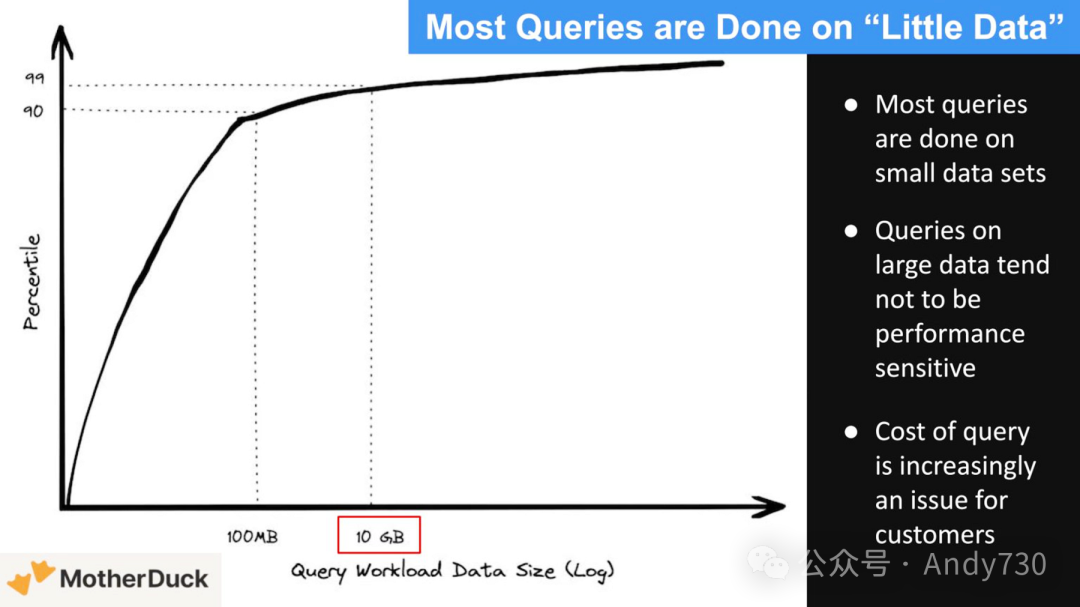
让我们深入探讨数据规模问题。下方数据显示,仅10%的查询超过100MB,另9%达到10GB。因此,99%的查询都在10GB以下。这主要是因为大多数查询针对的是新鲜数据,而价值也正体现在这些数据上。这些数据来自Mother Duck,具体来自Jordan Tigani的博客《大数据已死……》。Tigani曾任Google BigQuery产品负责人,现为Mother Duck的CEO。尽管这些数据已有几年历史,我们认为它仍反映当前市场情况。
问题2:George Fraser,Jordan的数据是否反映了当今的现实?
标准EC2实例内存容量超过大多数查询数据集规模
让我们继续通过MotherDuck的数据来探讨当前市场动态。
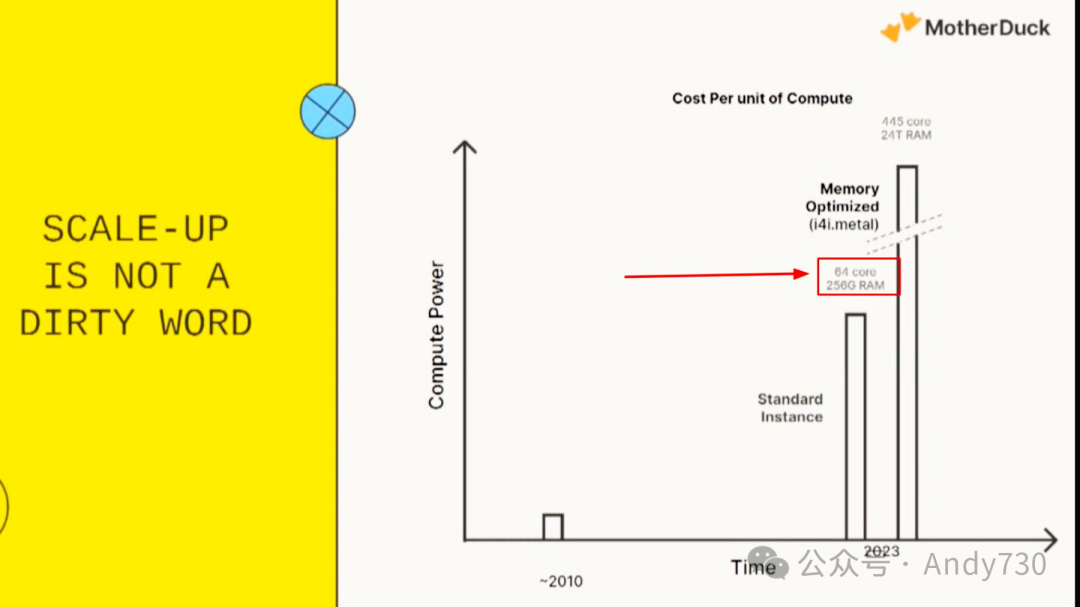
上图显示标准AWS EC2实例配备256GB内存,意味着可将整个数据集加载至内存,因此绝大多数查询和工作负载只需一个节点即可处理。需要明确的是,并非所有查询都在内存中完成,但关键在于,当今大多数情况下,无需分布式多节点集群即可完成查询。
问题3:George Fraser,你分析了Snowflake和Redshift关于工作负载规模的最新数据。结合你的经验,客户在选择计算/执行引擎时,成本如何分布,特别是在当前环境下?
专用数据引擎会成为未来的"小型钢厂"吗?
回到"够用"的工具可能使数据栈像钢铁行业一样商品化的观点。
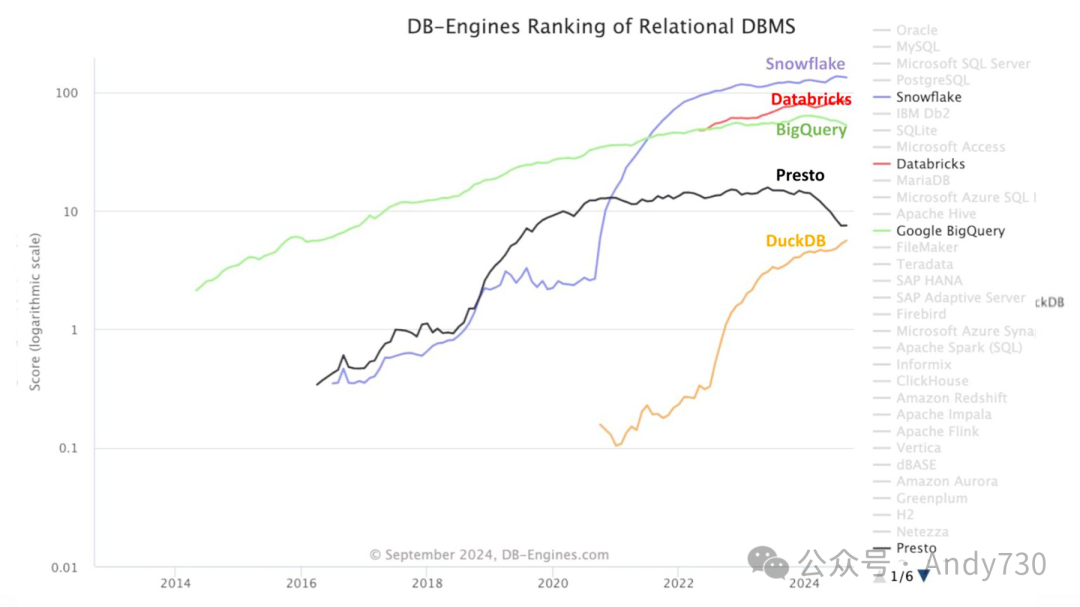
以下是来自DB-Engines的最新数据,该网站是衡量数据库引擎流行度的权威来源。图表显示了DuckDB相较于其他数据平台流行度的上升趋势。自2020年以来,DuckDB的受欢迎程度提高了近两个数量级。DuckDB是开源且单节点的,如果我们用钢铁行业类比,它是"小型钢厂",而Snowflake、Databricks和BigQuery则是"综合钢厂"。
问题4:George Fraser,你观察到的情况如何?开源分析型数据库的采用是否在增长?你认为它会侵蚀集成数据平台的市场份额吗?
问题5:George Fraser,你深入了解了当今集成供应商在速度和简便性上的改进,如Snowflake的声明式数据管道、增量更新、低延迟的数据导入和处理,并能直接为仪表板提供数据。这种端到端的简化提升了独立组件或单节点系统无法实现的效果。换言之,今天的MDS(现代数据平台)厂商能否像综合钢厂无法做到的那样,重新定义行业标准?
MDS参与者如何扩大其可服务市场?
为证明当今集成数据平台的复杂性合理性,我们认为它们需要增加新功能。以下列出MDS参与者可追求的三种新元素:1) 添加RAG(检索增强生成);2) 协同层;3) 多代理系统。这些都是Snowflake和Databricks等公司正在研究或有机会通过合作关系实现的功能,以吸收集成简便性,超越传统底层工作负载的需求。
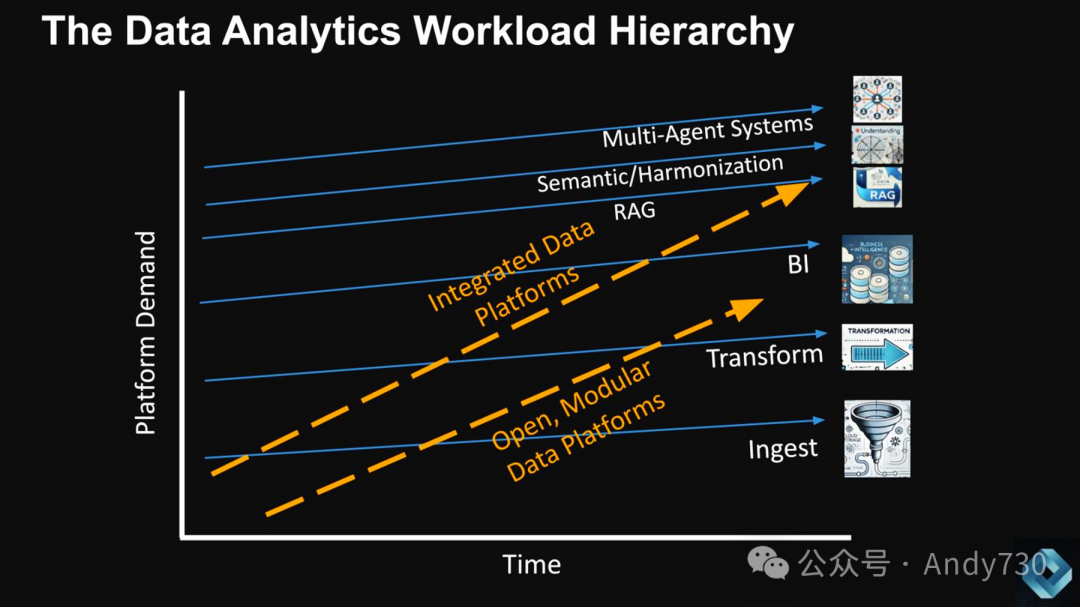
值得注意的是,与钢铁行业的类比不同,综合钢厂无法向更高层次迁移。然而,在数据平台领域,如果期望所有数据都"说同一种语言"(例如在BI世界中通常是度量和维度),当尝试在整个应用程序生态系统中实现这一点时,会变得非常复杂。目标是确保无论何种分析或应用程序与数据交互,数据的含义始终保持一致。这是一个复杂的挑战,也为提供新价值创造了机会。
我们在与Snowflake的Benoit Dageville的节目中讨论了这一点,也与Relational AI的Molham Aref和Enterprise Web的Dave Duggal进行过对话。这几乎是在向一种新型数据库发展,它作为抽象层存在。当数据平台逐步向这一层次迈进时,它为应用程序开发者提供了集成的简便性,使他们工作更为高效。
这也与RAG(检索增强生成)相关。
目前,RAG利用LLM(大语言模型)来解析不同的数据块,但为了真正有效,它还需要一个语义层。这就是所谓的GraphRAG。图表中的下一层是当LLM能够采取行动并调用工具时,而无需为每个步骤进行预编程。这就是代理(agents)的作用,你需要一个多代理框架来组织这些代理,形成一个类似于企业组织结构的体系。
这些都是当今应用平台可以演进的层次,不同于钢铁行业类比中无法升级的情况。这是我们将在未来几个月乃至几年内持续探索的领域,跟踪应用平台的演变。
未来智能应用程序栈的潜在形态
现在让我们回顾一下我们对现代数据和应用程序栈演进的设想,以支持智能数据应用。
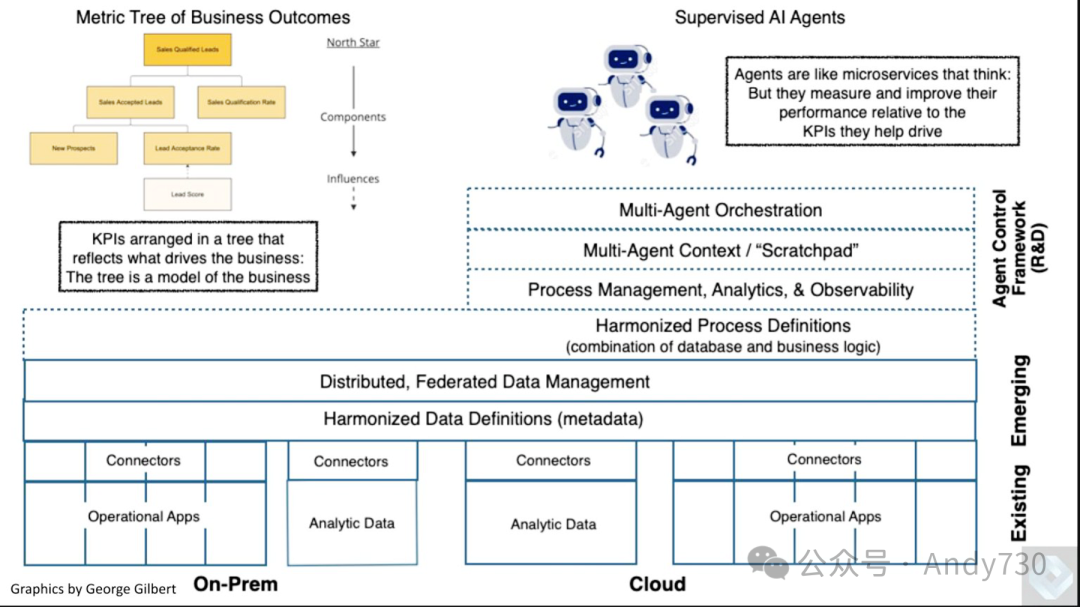
我们曾提出过智能数据应用程序栈演进的愿景。一个关键点是缺少协同层,有时也称为语义层。图表右上角展示了一个尚未开发的新领域,代表多代理平台。我们报道过Salesforce、Microsoft和Palantir等公司正在研究或发展这些新功能。但它们局限于各自的应用领域。而UiPath、Celonis等新兴参与者则有机会跨越单一应用领域,构建横向的多代理平台,打破应用组合中的价值壁垒。
因此,这不仅是Snowflake和Databricks之间的竞争,还有其他公司加入竞争,因为这些公司都有志成为构建智能数据应用的平台。
自动化领域参与者将争夺代理价值
下图是Insight Capital的图表,展示了代理领域的一些新兴参与者。我们不期望你能读懂这张图的细节,但要点是,这里有众多潜在参与者可以作为合作伙伴、并购目标或竞争对手。现有和新成立的公司正迅速涌现,争夺这一关键层次的市场。
几十年来,应用程序的定义由数据库和数据模型构成。流程和工作流是应用程序逻辑,最后是呈现逻辑。这形成了各个自动化孤岛。重新定义这一复杂领域的设想是通过协同层抽象所有这些孤岛,然后在其上构建代理框架。这个代理框架将允许所有这些角色或功能性、专业化的代理在企业级的更大范围内协同工作,映射顶层目标并自下而上执行。
我们认为这是未来五到十年内,AI实现投资回报的最大挑战和机遇。
问题6:George Fraser,你能否评论一下今天的讨论如何与这样一个观点相契合:虽然现代数据平台具有高粘性,但我们强调的某些紧张关系表明,数据湖可能会以许多人未曾预料的方式发生转变?
Source:Is the Modern Data Stack Out Over Its Skis? David Vellante, George Gilbert; September 07, 2024
参考资料
公司概述
Fivetran是一家领先的数据集成公司,提供自动化的数据迁移平台。成立于2012年,总部位于加利福尼亚州奥克兰,Fivetran已经发展到超过1176名员工,拥有10个国际办事处。到2022年,该公司已筹集到7.28亿美元的资金,估值达到56亿美元。
产品
Fivetran的核心产品是一个完全托管的数据管道,能够自动从各种来源(如SaaS应用程序、数据库和云服务)提取数据,并将其复制到数据仓库中。它提供了超过200个预构建的连接器,可以在几分钟内设置,无需任何编码。该平台监控连接器的变化、停机和架构更新,确保可靠且零维护的数据管道。
商业模式
Fivetran采用混合定价模型,结合了基于SaaS的订阅层和基于消费的计费。客户根据每月复制的数据行数进行付款,更高的层级提供更多用户、功能和更快的同步。这种模式使Fivetran的收入增长与客户的数据增长保持一致。
优势
自动化数据管道:Fivetran的预构建连接器和监控功能消除了手动构建和维护管道的需要。 快速获取洞察:通过自动化数据迁移,Fivetran使客户能够快速访问集成数据,以进行分析和AI/ML应用。 可扩展和可靠:该平台随着客户数据量的增长而扩展,并通过其监控和维护确保可靠的数据交付。 广泛的连接性:Fivetran支持多种数据源,从流行的SaaS应用到小众数据库,满足多样化的数据集成需求。
增长与荣誉
Fivetran经历了快速增长,2022年预计收入达到1.9亿美元,同比增长141%。该公司拥有超过5000名客户,包括财富500强公司和行业领导者。Fivetran被评为优秀工作场所,2022年在《财富》杂志和Great Place to Work的“湾区最佳工作场所”榜单中排名第二。它还获得了来自Google Cloud、Snowflake和Databricks等云数据平台的多个合作伙伴奖项。
---【本文完】---
近期受欢迎的文章:
更多交流,可加本人微信
(请附中文姓名/公司/关注领域)

