




摘要
像适应性I/O系统(Adaptable I/O System,ADIOS)这样的高性能计算(HPC)I/O中间件通常负责协调应用程序间的数据传输。这类系统产生的元数据I/O经常导致显著的扩展和性能瓶颈。
本文探讨了利用DAOS存储系统来改进元数据I/O的机会。DAOS是一种针对高端系统(如Aurora超级计算机)的新型存储解决方案。我们研究了基于DAOS的不同存储机制,并探讨了集成ADIOS中间件I/O引擎的权衡和设计空间。提出了一种新的DAOSArray-ChunkSize对齐引擎,该引擎无需对应用程序进行任何修改,即可实现高达2.3倍的性能提升,相较于现有的DAOS-POSIX接口。
论文题目:Optimizing Metadata Exchange: Leveraging DAOS for ADIOS Metadata I/O
作者:Ranjan Sarpangala Venkatesh,Greg Eisenhauer,Norbert Podhorszki,Dmitry Ganyushin,Scott Klasky,Ada Gavrilovska
I.引言
随着HPC中数据量的急剧增长,I/O开销已成为一个主要瓶颈。为应对这一问题,已采取多种措施来提高I/O带宽和并发性。然而,HPC中的元数据管理,尽管常被忽视,但其重要性不容忽视。应用程序规模和复杂性的增长同时增加了元数据的量和复杂度。最近的研究表明,元数据对整体HPC I/O效率具有深远影响。仅仅增加硬件资源并不能从根本上解决元数据问题。特别是在进入以Aurora超级计算机为代表的百亿亿(exascale)次计算时代时,我们预见这种趋势将持续。
为了更有效地应对HPC和数据中心系统中的I/O瓶颈,并充分利用新型存储设备的性能优势,存储计算领域引入了Intel DAOS(Distributed Asynchronous Object Storage,分布式异步对象存储)。DAOS旨在简化软件栈与新型存储技术(包括持久性内存和NVMe设备)的集成。DAOS在与持久性内存交互时最小化了软件开销,从而充分利用这些技术相对于传统存储设备(如HDD/SSD)的性能优势。该系统支持零拷贝和异步I/O操作。基本上,DAOS引入了一种对象接口,自然支持键值和数组格式。此外,为确保与现有系统的兼容性,DAOS在其本地DAOS数组对象接口之上集成了POSIX模拟层。
尽管DAOS在HPC I/O中的优势备受关注,但对HPC元数据I/O特殊需求的关注较少。本文中的“元数据”特指由I/O系统(如ADIOS、MPI-IO、HDF5和NetCDF)生成的元数据,这些系统支持复杂HPC工作流的执行。在这些I/O中间件系统的背景下,元数据是在写入特定数据过程中生成的,供下游工作流组件(即读取节点,readers)定位该数据使用。鉴于元数据I/O相关的性能挑战日益加剧,本文重点研究利用DAOS进行元数据I/O的影响。
特别是,我们关注高性能I/O系统ADIOS。ADIOS广泛应用于橡树岭国家实验室和其他几个国家实验室,因其在管理大规模数据方面的高效性,特别是在性能和可扩展性至关重要的环境中。其灵活的框架和对各种数据格式的支持,使其成为推动复杂科学研究(包括实时数据处理、气候建模、天体物理学等领域的大规模模拟)的重要工具。ADIOS已在多个最近获得戈登贝尔奖的应用中使用,如粒子在单元代码WarpX和气候模拟E3SM。
在ADIOS中,每个写入(writer)节点生成的元数据都会存档在稳定存储中。为满足ADIOS读取节点端的语义需求,每个读取节点通常必须访问每个写入节点生成的所有元数据。因此,元数据的访问模式往往与应用数据不同,因为在多节点应用中,每个读取节点通常只访问全部数据的一个子集,但需要访问全部元数据以定位这些数据。这进一步凸显了研究新存储技术在元数据特定性能影响方面的需求,而DAOS正是我们工作的核心。先前的ADIOS元数据存储和访问实现依赖于POSIX文件,并受到POSIX设计固有限制的约束。尽管DAOS提供了键值和数组对象接口,并在最近的性能评估中展示了其有效性,但确定使用这些接口传输ADIOS元数据的最佳策略仍是一个复杂的挑战。
揭示了基于POSIX语义的ADIOS元数据处理的困难,并指出了这些困难在WarpX大规模应用中如何显著影响元数据的端到端传输时间(详见第II节)。 探讨了使用DAOS键值和数组对象传输ADIOS元数据的复杂设计空间(第IV节),并详细说明了我们在为ADIOS贡献的新DAOS引擎中所作出的具体决策(第V节)。 利用模拟E3SM和WarpX元数据I/O模式的基准测试,评估了ADIOS中DAOS元数据引擎的性能,分析了元数据大小、节点数量以及长期运行应用对提交、获取元数据及端到端元数据传输时间的影响(第VI节)。 展示了新的基于DAOS数组的引擎在大规模环境下为ADIOS元数据提供的端到端传输时间,相比POSIX接口快了2.3倍。对于WarpX应用,DAOS将元数据I/O时间减少了超过4倍,从原先超过应用I/O时间的20%降至仅5%。
值得注意的是,虽然本研究专注于ADIOS中的一个元数据模式,即每个写入Rank为其数据项生成元数据,每个读取Rank使用此元数据来定位所需数据,但我们认为这种模式足够通用,能够代表其他HPC I/O中间件(如HDF5和PnetCDF)的元数据存储和访问需求。尽管我们的实验基于ADIOS,并与现有的基于POSIX的ADIOS元数据存储实现进行了比较,但我们相信这些结果可以推广到具有类似元数据存储和访问需求的其他系统。
II.研究动机
如上文所述,过去针对HPC I/O领域的研究主要聚焦于如何最大化向存储介质传输大量数据的速率,而往往忽视了像ADIOS这样的系统产生的元数据问题,这些元数据主要用于识别和提供对单个数据块的访问。在传统观念中,元数据相较于数据本身通常被认为是较小的部分,因此在HPC I/O中并未受到特别的重视。
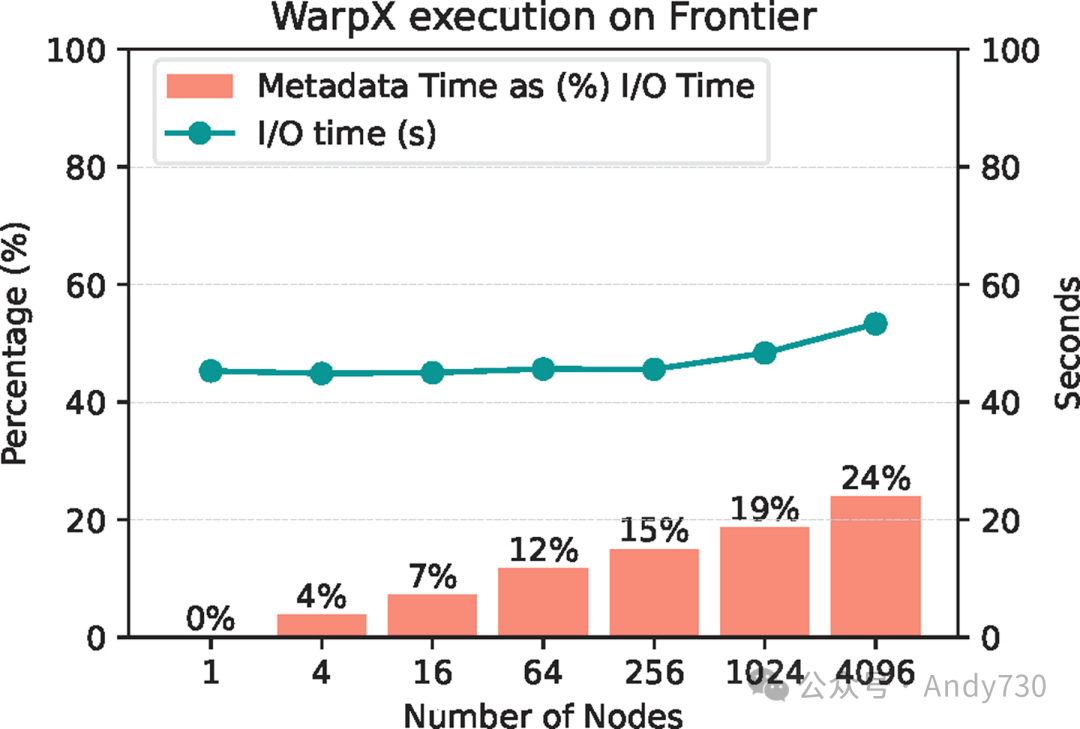 图1:ADIOS元数据时间相对于总体I/O时间的成本递增趋势
图1:ADIOS元数据时间相对于总体I/O时间的成本递增趋势
为了挑战这一观点,我们引入了图1的性能基准,该图展示了WarpX在不同规模下的I/O特性(在Frontier上测得)。具体来说,这张图不仅显示了总体I/O时间(绿线,右侧刻度),还清晰地展示了元数据收集时间在I/O时间中的相对占比(以橙色条形表示的百分比)。随着计算规模的增加,每个Rank的I/O时间保持相对稳定,而ADIOS从所有CPU Rank写入数据。然而,ADIOS的元数据收集和写入时间却显著增长,其占比甚至高达总I/O时间的24%。这种趋势不仅局限于WarpX,还同样适用于其他元数据密集型应用程序,如E3SM。
在现有的ADIOS基于POSIX的元数据处理实现中,所有写入者的元数据都通过MPI收集到一个单一Rank,并写入一个POSIX文件。随后,读取应用程序会通过读取该文件来访问元数据。在本研究中,我们将探讨用DAOS实现的基于对象的方法取代这种基于文件的方法所带来的影响。如前文所述,其他自描述的HPC I/O中间件可能会采用不同的方式处理元数据,例如将其与数据捆绑在一起。然而,由于元数据的访问需求往往与数据不同,因此将其分离是有意义的。我们坚信,这种通用的元数据存储/访问模式——即,在各个写入Rank上生成的元数据必须以某种方式使每个读取Rank能够访问以启用数据访问——足以代表其他HPC I/O中间件的元数据处理策略。
需要强调的是,虽然人们可能会考虑如何改进基于文件的元数据存储和访问方法,但这并非我们此项工作的重点。相反,我们关注的是如何利用DAOS对象模型提供的优势来应对当前的问题。为此,我们主要利用现有的实现作为动机和性能基线。这尤其具有价值,因为1)DAOS POSIX接口的存在使我们能够在相同的硬件环境中比较两个不同的接口;2)现有的POSIX实现在大多数情况下对ADIOS来说是足够的,因此并不至于糟糕到无法作为合适的比较对象。
III.背景
A.ADIOS
ADIOS [13] 是一个专为HPC I/O设计的中间件库,它向应用程序提供高级数据抽象,并简化了应用程序内存与各种HPC中间件(如网络、文件、广域网或直接内存访问通道)之间数据传输、存储和检索的复杂性。其主要目标是为前沿HPC计算资源上的百亿亿次级应用程序提供最优的存储和网络带宽。尽管ADIOS支持在线耦合(例如,运行中数据源与接收器之间的直接连接),但本研究主要聚焦于稳定存储的I/O。在ADIOS中,稳定存储主要用于大型科学活动的检查点保存以及仿真数据的后处理。
在ADIOS中,I/O抽象采用了集体和时间步长的方法,通过读取节点组和写者节点组内的Begin/EndStep()调用来管理同步。在每个I/O时间步内,应用程序可以通过Put()将数据放入存储,或通过Get()从存储中获取数据,这些操作均针对预定义的ADIOS变量进行。这些变量可以表示从单个命名值到跨MPI驱动应用程序节点分布的多维数组等多种ADIOS数据结构。
ADIOS元数据
在ADIOS中,为了方便数据发现,每当ADIOS操作写入数据时,它都会同时生成元数据。这些元数据包含输出变量的名称、类型、维度、在ADIOS全局数组空间中的虚拟位置(起点和计数),以及存储中数据块的确切位置和大小。通常,为了满足ADIOS中的Get()请求,每个读取节点都需要访问每个写者节点为特定时间步生成的完整元数据集。这意味着,尽管实际数据读取模式可能因应用需求而异,但元数据交换通常遵循更统一的全收集传输机制。
ADIOS中的元数据传输
在当前的ADIOS POSIX引擎中,如图2所示,所有写者节点在每个时间步生成的元数据被聚合到节点0,并写入专门的元数据文件。在读取节点端,节点0获取写者的元数据,并通过MPI广播将其分发给其他读取节点。
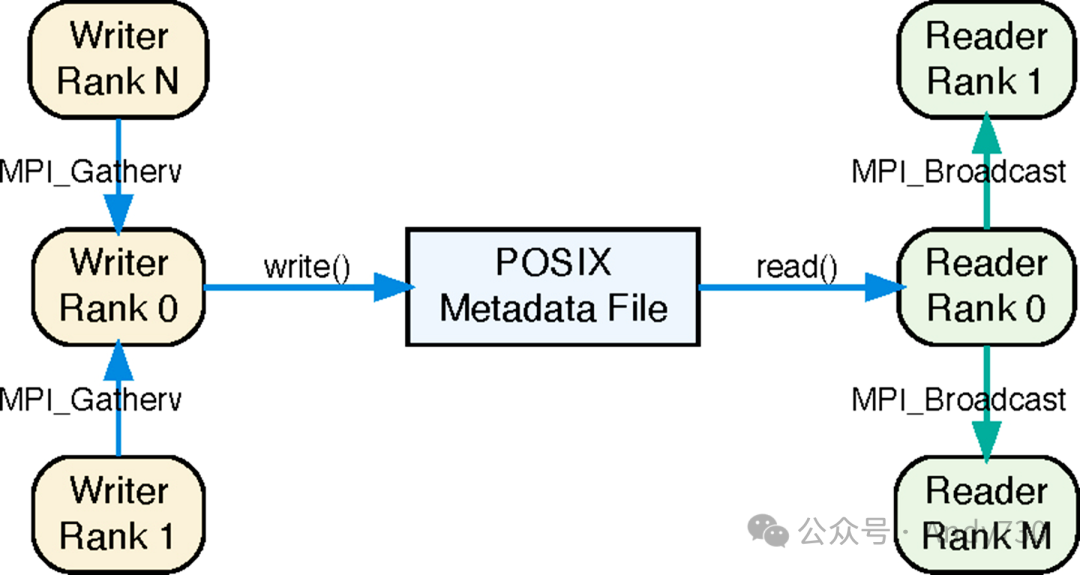 图2:ADIOS - POSIX引擎示意图
图2:ADIOS - POSIX引擎示意图
元数据稳定时间:涵盖从元数据初始创建到写者将其安全存储在稳定存储中的所有步骤,确保元数据的持久性和可访问性。 元数据获取时间:指从稳定存储中获取元数据,并使其对所有读取节点可用的过程,以便它们能够访问和使用数据。 元数据端到端传输时间:稳定时间和获取时间的总和。
鉴于我们主要关注大规模数据,我们的分析主要聚焦于每个时间步内的持续元数据传输开销,而非单一成本。
B.DAOS
分布式异步对象存储(DAOS)是一个面向字节寻址存储的开源对象存储系统 [7]。其设计旨在提供低延迟和高带宽的存储访问,适用于包括数据中心、传统HPC以及AI/ML任务在内的多种使用场景。DAOS利用存储类内存(SCM)和NVMe来提升性能和效率。最初,DAOS使用SCM来高效处理小型、延迟敏感的I/O操作和元数据。此外,NVMe驱动器提供了额外的容量和高带宽,而开放结构接口(Open Fabrics Interfaces)确保了低延迟访问。DAOS的数据路径完全在用户空间,通过远程直接内存访问(RDMA)实现零拷贝。此外,DAOS本质上提供了一个对象接口,可以在此之上实现POSIX、MPI-IO和HDF5等中间件层。
DAOS目标
每个DAOS服务器节点将其PMEM和NVMe存储划分为多个DAOS目标。与每个DAOS插槽相关联的独立DAOS引擎守护进程负责这些目标的I/O处理。为了优化性能和可靠性,DAOS对象分布在这些目标之间。
DAOS容器和快照
DAOS容器作为对象地址空间,由唯一的容器ID区分。DAOS中的快照是轻量级的,并被标记有其创建时间对应的纪元。在创建之后,快照将保持可读状态,直到被明确删除。此外,容器的内容可以恢复到特定快照捕获的状态。
DAOS对象
DAOS引入了键值和数组对象。
键值对象提供了put和get功能,其值可以是可变长度的数据块。单个键值对象能够容纳多个键值对,这些键通过哈希运算来确定它们存储在哪个DAOS目标上。
数组则提供了一个逻辑上的一维数组。每个DAOS数组都由其单元大小和块大小来定义,这些属性在创建时确定。块大小指的是在数据写入到另一个目标之前,可以连续存储在一个目标中的元素序列长度。单元大小则指定了单个元素的大小。数组内的所有元素都位于同一个DAOS目标中。DAOS数组支持矢量I/O,允许在单个daos_array_write/read()调用中跨多个不同范围进行读写操作。
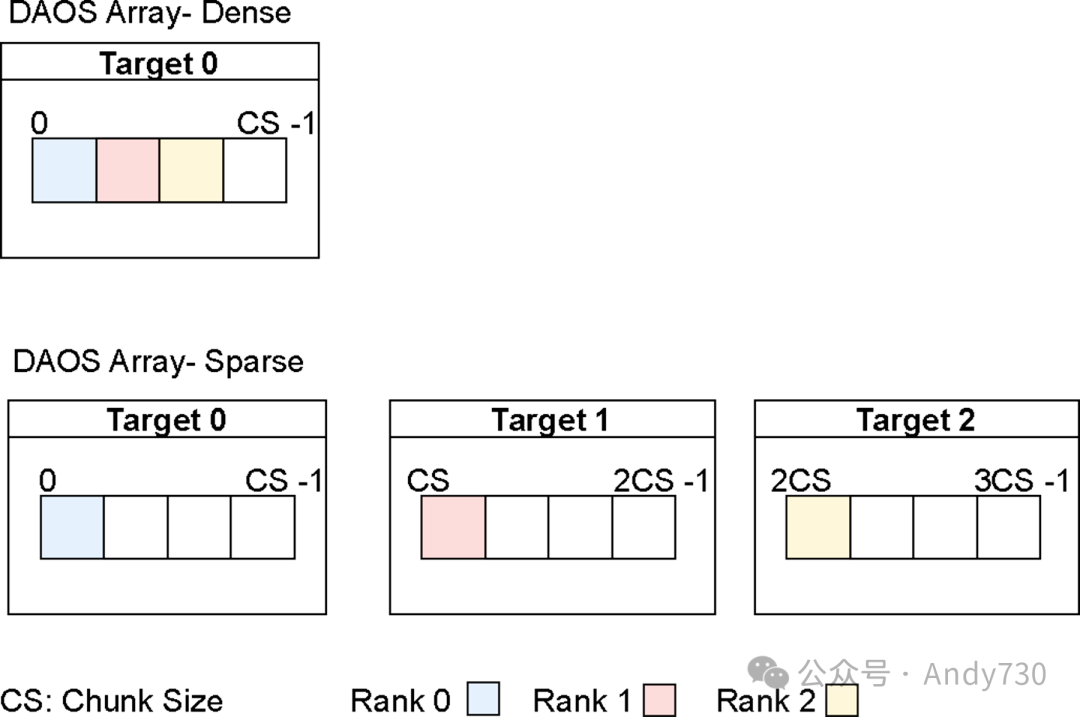
图3:DAOS数组布局展示
图3展示了由三个节点写入的稠密和稀疏数组,其范围小于块大小。这在特定场景下尤为重要,因为单个写者节点的ADIOS元数据通常小于块大小。在稠密数组场景中,节点写入的是连续的范围,这些范围全部位于同一个DAOS目标中。相反,在稀疏数组场景中,节点在块边界处写入数据,因此这些范围被分布在三个不同的目标上。由于DAOS目标绑定到有限的计算资源,DAOS数组的布局会对性能产生影响,这将在后续讨论中详细阐述。
DAOS文件系统(DFS)上的POSIX仿真
DFS提供了一个结构化的POSIX命名空间,支持文件和目录结构。本质上,DFS文件是通过DAOS数组概念来实现的,其块大小为1MB,单元大小为一个字节。应用程序通过FUSE守护进程访问这个仿真的POSIX命名空间。此外,使用LD_PRELOAD的拦截库确保POSIX读/写操作完全绕过操作系统。
IV.DAOS对象的设计选项
尽管DAOS的键值(KV)和数组接口提供了简洁的接口,但关于如何使用和配置它们存在许多不同的选项。选择最适合给定API并能有效提供最佳端到端性能的选项并不简单。因此,为了充分利用DAOS的KV或基于数组的接口,需要在几个维度上仔细考虑设计空间,如图4所总结。
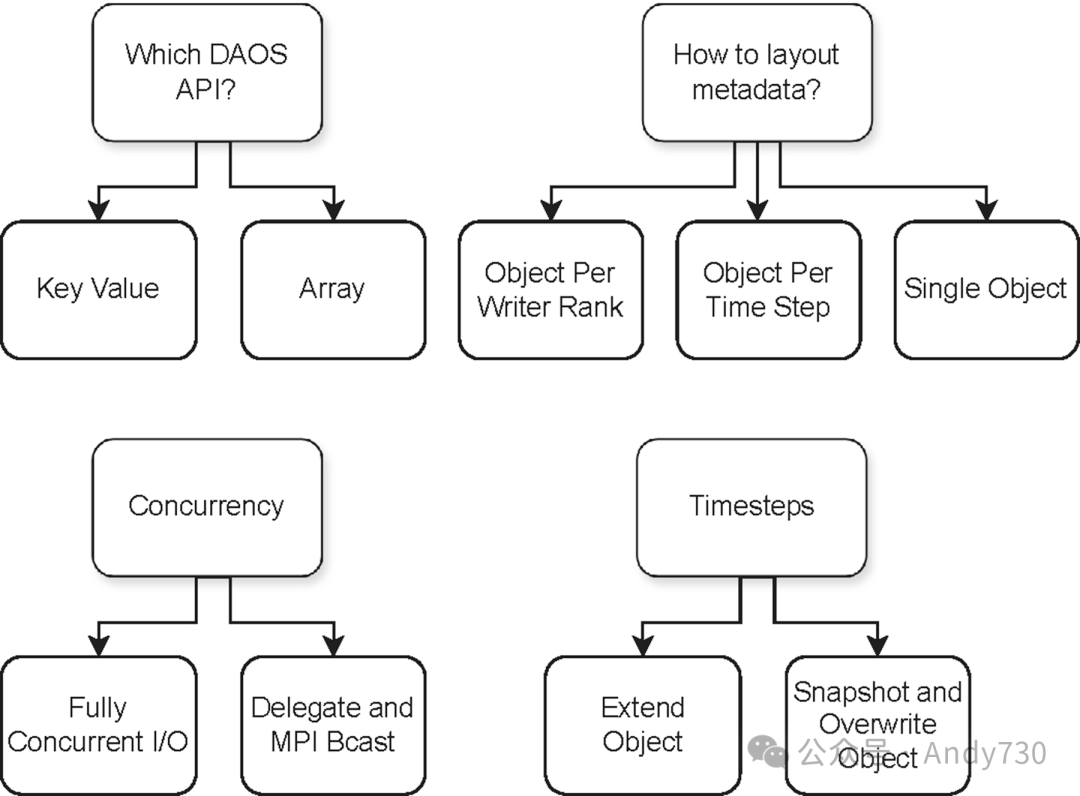 图4:设计空间布局图
图4:设计空间布局图
在深入探讨这些选项之前,重要的是要指出DAOS对象与常见对象概念的不同。DAOS键值对象并非只包含一个键值对,而是一个“存储”,可以在同一个DAOS键值对象中存储多个键值对。另一方面,DAOS数组对象容纳一个单一的数组,类似于具有可扩展范围的文件,可以是稠密的或稀疏的。
此外,键值和数组之间的I/O语义差异会对性能产生影响。写入DAOS键值对象的元数据不需要写者之间的协调,每个写者可以用唯一的键字符串更新其元数据。然而,如果对象是共享的,DAOS数组可能需要写者节点之间的协调,以确定数组偏移。在读取节点端,DAOS数组可以利用矢量I/O,将来自多个范围的所有写者的元数据读取到单个连续的内存块中。然而,对于键值对象,每个元数据块都需要单独的DAOS键值操作。鉴于这些优缺点,我们评估了键值和数组的设计选项。
元数据布局
在DAOS对象上布局元数据时,需要在稳定性和获取时间之间做出权衡。针对两种DAOS API,我们探讨了三种元数据布局方案:
每个写者节点一个对象:随着写者节点数量增至数千,需要创建相应数量的DAOS对象。虽然DAOS能够高效处理大量对象的创建,但在实际读写之前,这些对象必须被打开。同时打开大量对象会增加应用程序的启动时间。然而,所有打开操作可以在初始阶段完成,并在整个仿真运行期间重复使用相同的句柄,这意味着相关开销与应用程序规模成正比,且不会随时间增长。此方案的一个主要限制是,由于每个写者节点拥有独立对象,DAOS数组在读取时无法从矢量I/O中获益,因此内存注册成本与键值操作类似。
每个时间步一个对象:在此方案中,DAOS数组在读取时能够利用矢量I/O,因为同一个ADIOS时间步的所有元数据都存储在一个对象中。但在读取节点端,每个时间步都需要新的打开调用。这种频繁创建和打开新对象的过程会影响长时间运行应用程序的稳定性和获取时间。
单个对象:在此方案中,启动时由写者节点0创建对象,发出打开调用,获取对象句柄,并将其广播给所有其他节点。该句柄在多个时间步中重复使用。在读取节点端执行类似步骤。由于仅使用一个对象,无论实验规模或持续时间如何,相关开销都是固定的。重要的是,DAOS数组在读取时能够受益于矢量I/O。
读写并发
在ADIOS中,每个读取者都需要从每个写入者获取元数据。我们考虑了两种使用异步Get()的方法(因为同步Get()对于大量写入者来说太慢)。第一种方法是并发方法,每个读取者同时访问元数据。第二种方法是任务委托给读取者排名0,然后它将元数据广播给所有其他读取者。在并发方法中,如果有M个写入者和N个读取者,元数据获取需要M × N组完整的ADIOS元数据读取。而委托方法仅需要M组完整的ADIOS元数据读取,接着是N次MPI Bcast操作。图5显示了使用DAOS KV对象时,224个写入者和不断增加的读取者数量下的元数据获取时间。显然,并发方法并不具备可扩展性。使用委托方法时,MPI Bcast随着读取者数量的成本增加远小于并发访问引起的减速。因此,在设计和实现DAOS元数据引擎时,我们已纳入读取者侧的委托机制。DAOS数组也有类似的权衡,因此在设计和实现时也纳入了读取者侧的委托。
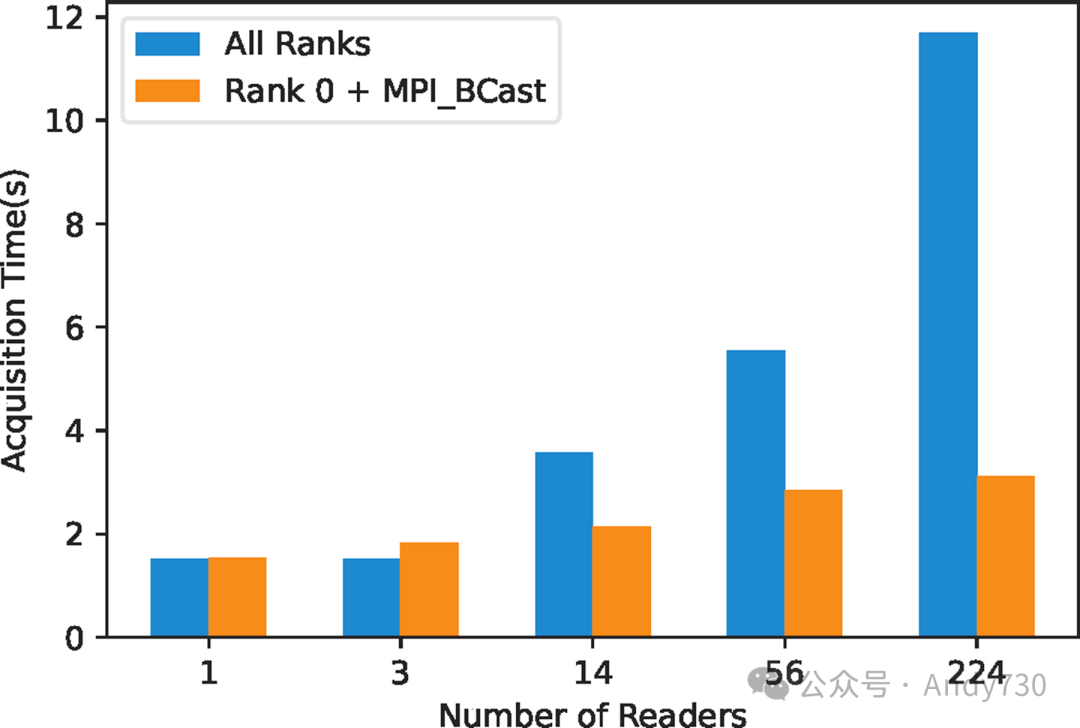 图5:比较使用DAOS KV实现的“每个Rank读取”与“Rank 0读取 + MPI_Bcast”方法的性能(注意:总元数据量保持不变,尽管读取Rank数量增加)
图5:比较使用DAOS KV实现的“每个Rank读取”与“Rank 0读取 + MPI_Bcast”方法的性能(注意:总元数据量保持不变,尽管读取Rank数量增加)
在写入者一侧,元数据写入是并行化的,以避免序列化带来的开销,因为之前的分析已经表明这是昂贵的。
ADIOS时间步管理
鉴于ADIOS是基于时间步操作的,我们有两种方式来表示时间步的演变。第一种方法是扩展当前的DAOS对象。在DAOS数组的情况下,这意味着写入新的区段;在KV中,则是添加带有标识排名和时间步的键的新条目。第二种方法利用DAOS对象重用和DAOS容器快照机制。这涉及在后续时间步中由一个排名覆盖以前的区段或键值条目。快照的创建由写入者排名0负责。通过打开相关的快照来访问给定ADIOS时间步的元数据。
使用快照重用方法简化了在给定时间步中将元数据偏移传递给读取者的过程。但在读取者一侧,需要在元数据可访问之前事务性地打开快照。
设计决策
综合考虑上述权衡和ADIOS元数据I/O的要求,我们优先选择了以下设计选项:鉴于易用性、DAOS数组在矢量I/O中的性能优势,以及在传递DAOS对象元数据(不同于ADIOS元数据)给读取者时最小化的启动成本和开销,我们决定使用一个单一对象来存储所有元数据。通过所有写入者排名的并发写入实现元数据的稳定化。然而,元数据的获取被委托给读取者排名0并进行广播。ADIOS时间步管理基于扩展DAOS对象。在后续章节中,我们将通过评估基于快照的机制的可行性来证明这一选择的合理性。
V.ADIOS元数据I/O的DAOS引擎
基于上一节所述设计空间探索得出的设计决策,我们评估了这些决策在基于KV和数组的ADIOS元数据I/O引擎中的应用。
A.ADIOS DAOS-KV引擎
在引擎初始化阶段,写入者排名0负责创建一个DAOS KV对象,并将其对象ID广播给所有其他排名,此过程仅需执行一次。在每个时间步结束时,每个写入者会利用daos_kv_put()函数将其元数据存储为一个独特的键值条目,其中键的格式为"StepN-RankID",而对应的值则是元数据缓冲区。
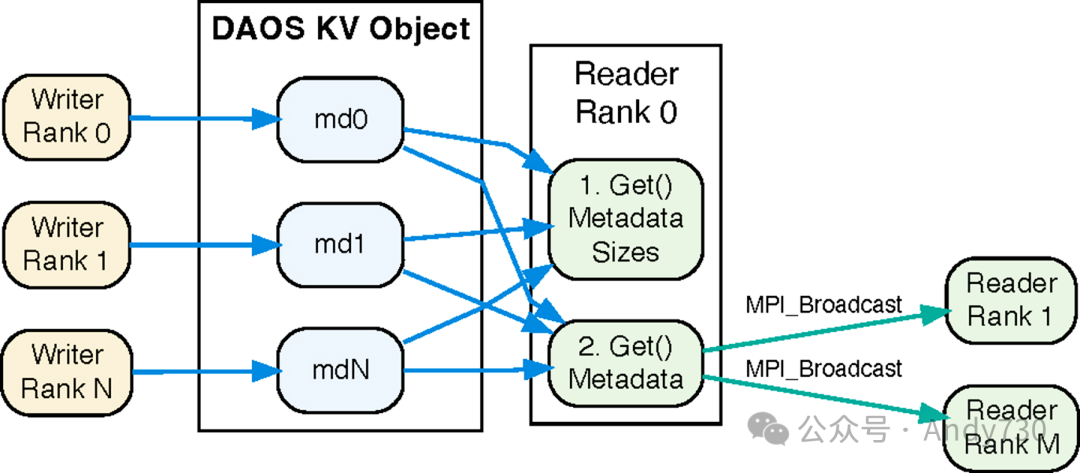 图6:ADIOS DAOS-KV引擎:每个写入者的元数据以键值对形式存储在单个对象中
图6:ADIOS DAOS-KV引擎:每个写入者的元数据以键值对形式存储在单个对象中
在读取端,读取者排名0通过两步过程来收集所有元数据。首先,它使用daos_kv_get()函数和键"StepN-RankID"及NULL值缓冲区来确定每个写入者排名的元数据大小。在确定了总元数据大小后,排名0会分配所需的内存。随后,它再次调用daos_kv_get(),并传入键"StepN-RankID"和之前分配的内存缓冲区metadata_buffer来检索实际的元数据。这些元数据随后会被广播给所有其他读取者排名。
B.ADIOS DAOS-Array引擎
在引擎初始化阶段,写入者排名0会创建一个DAOS数组对象,并将其ID广播给所有其他排名。该数组的块大小和单元大小分别被设置为1MB和1字节,类似于DFS。对于当前工作负载,1MB的块大小已经足够大,但可以根据实际需求进行配置。此外,还会创建一个DAOS KV对象来存储元数据的大小信息。
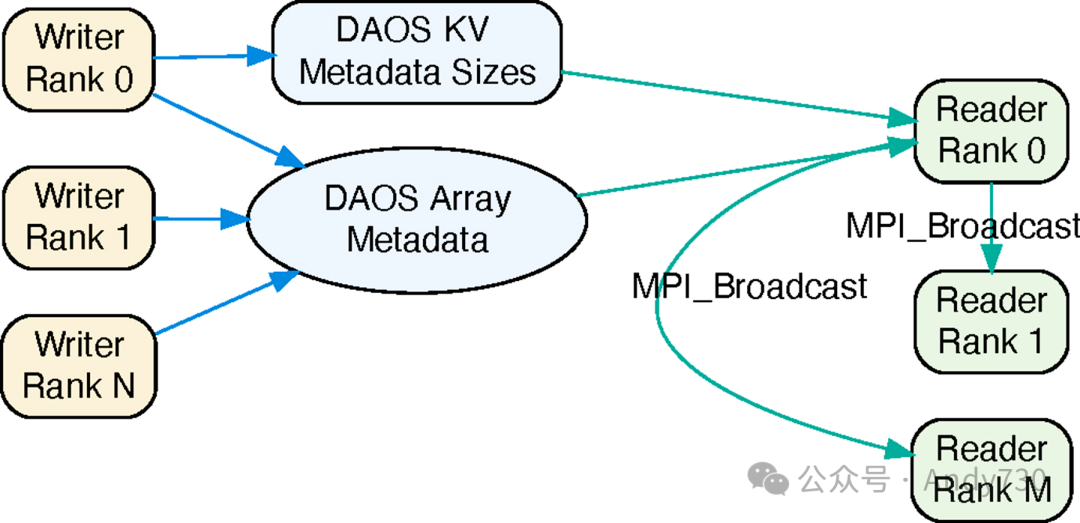 图7:ADIOS DAOS-Array引擎:每个写入者的元数据作为区段存储在单个数组中
图7:ADIOS DAOS-Array引擎:每个写入者的元数据作为区段存储在单个数组中
在每个时间步中,每个写入者排名会利用MPI_Allgather()函数来共享他们的元数据大小。之后,写入者会根据各自的排名顺序计算出在DAOS数组中的唯一偏移量,并通过daos_array_write()函数将其元数据写入。写入者排名0会使用daos_kv_put("StepN", list_metadata_sizes)来记录KV对象中所有写入者的元数据大小。
在读取端,排名0首先从KV对象中检索list_metadata_sizes来计算总元数据大小。在分配了必要的内存后,它会使用daos_array_read()函数从DAOS数组中读取所有写入者的元数据。随后,这些元数据会被广播给所有其他读取者排名。
VI.评估
A.目标
DAOS-KV和DAOS-Array引擎如何影响不同大小的ADIOS元数据的稳定化和获取时间? 并发对DAOS引擎性能有何影响? 在大规模环境中,不同DAOS引擎对整体端到端元数据传输时间有何影响? 在长时间运行且包含大量ADIOS时间步的计算中,不同DAOS引擎的表现如何?
最终目标是确定哪种DAOS引擎在元数据传输中最为高效。
B.方法论
实验测试平台
实验在剑桥数据驱动发现服务(CSD3)的Ice Lake集群上进行。每个计算节点都配备了双插槽38核的Intel® Xeon® Platinum服务器,搭载2.60GHz 8368Q CPU和512GB的DRAM。系统包括DAOS v2.2,部署在基于2.2GHz 8352Y CPU的10个双插槽32核Intel® Xeon® Platinum服务器上。每个服务器拥有4.2 TB的PMEM存储,包括256GB的Optane DIMM和16个3.8TB的NVMe驱动器。所有服务器通过双HDR200 InfiniBand网络连接。
实验设计
为了评估不同DAOS引擎对稳定化和获取时间的影响,我们首先分别测量了这两个阶段的性能(§VI-C)。接着,我们结合这些测量结果来报告对端到端测量的影响(§VI-E)。这些测量考虑了不同的并行级别以及每排名和每时间步的元数据大小。我们进一步研究了长时间模拟对不同引擎性能的影响(§VI-F)及其运行时开销,特别是针对稀疏DAOS Array引擎(§VI-G)。
基准测试
关于元数据相关I/O问题的动机观察是在ORNL的Summit和Frontier系统上进行的,但这两个系统都不支持DAOS。尽管我们计划未来在Aurora上进行进一步的研究,但本文中的评估仅限于通过英国剑桥集群访问的DAOS系统。为了专注于元数据I/O行为并避免配置复杂应用工作流的复杂性,我们采用了基准测试来模拟真实应用中的元数据交换。在ADIOS中,每个写入者排名在每个时间步结束时都会生成一个元数据块,其中包含其写入的所有变量的信息。因此,为了评估的目的,我们使用了一个ADIOS工具[14],它能够生成每个写入者排名在每个时间步中大小相同的元数据。我们通过调整ADIOS变量和相应数组的数量来配置元数据的大小。每排名的元数据大小是恒定的,因此总元数据大小会随着排名数量的增加而成比例增长。
我们增加了排名的数量,范围从64到1024不等。写入者和读取者在计算分区上执行,而DAOS服务器则部署在单独的存储节点组中。读取者的数量与写入者的数量相同。
为了验证基准测试结果所揭示的趋势,我们还测量了在使用WarpX进行激光尾场加速模拟时的稳定化时间。在WarpX中观察到的DAOS引擎的相对性能与基准测试中观察到的类似。
测量
为了在ADIOS中收集时间数据,我们使用了Caliper,这是一款专为高性能计算中的性能测量和代码插桩设计的工具[15]。我们在DAOS引擎的EndStep()和BeginStep()点使用Caliper来记录元数据的稳定化和获取时间。由于ADIOS写入者在各个时间步之间生成的元数据相似,因此报告的时间代表了1000个时间步内每排名的平均值。
C.DAOS引擎对稳定化和获取时间的影响
我们针对每次迭代中每排名生成的不同元数据量的应用场景,对元数据的稳定化和获取时间进行了细分。第一个场景对应于E3SM气候建模应用,其元数据大小为56 KB。在第二个场景中,我们关注的是更小的元数据,即5 KB,以评估元数据大小如何影响不同DAOS引擎之间的相对差异。较小的元数据大小类似于WarpX中的元数据大小,后文我们将对此进行测量。
大元数据 - E3SM (56KB)
对于56KB的元数据,如图8所示,DAOS-KV和DAOS-Array的稳定时间比DAOS-POSIX快了一个数量级。POSIX的稳定时间随着节点数量的增加而显著增长,因为它通过排名0串行化元数据的稳定过程。相比之下,DAOS-KV和DAOS-Array则能够并行写入元数据。
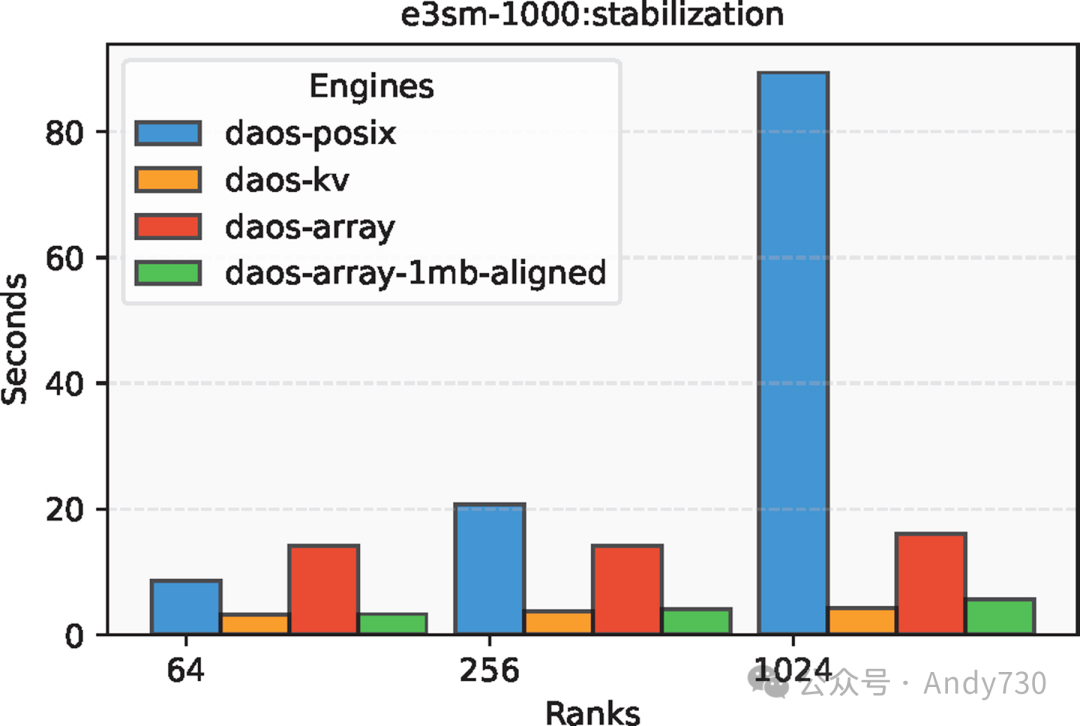 图8:E3SM中不同DAOS引擎在56KB元数据下的稳定时间对比
图8:E3SM中不同DAOS引擎在56KB元数据下的稳定时间对比
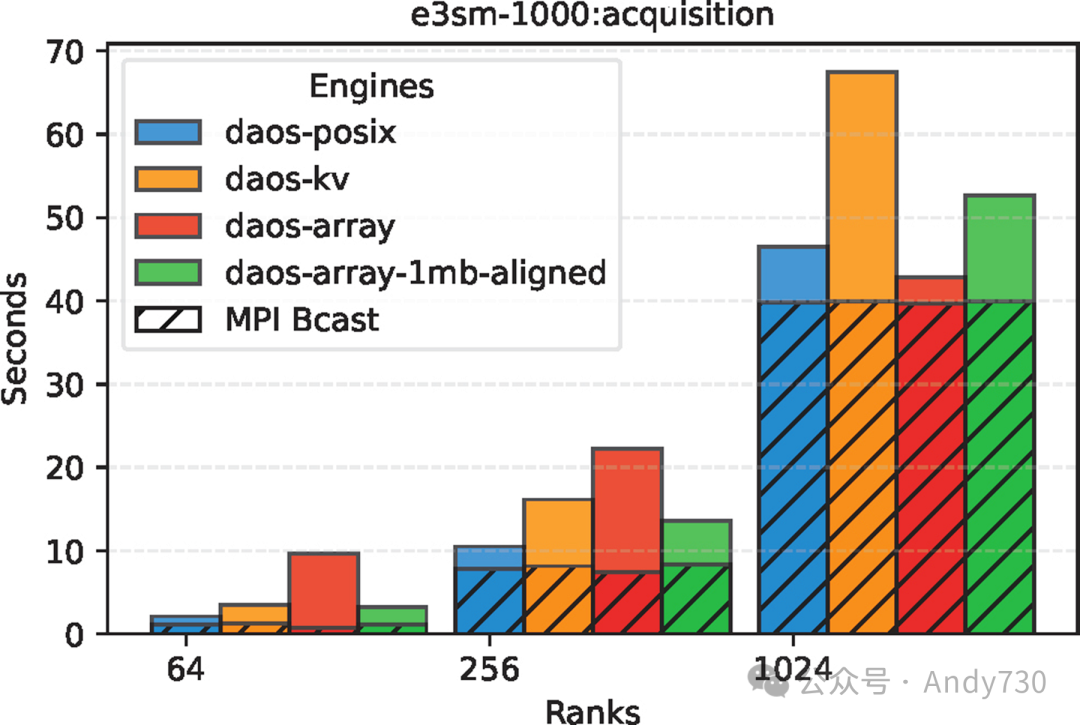 图9:E3SM中不同DAOS引擎在56KB元数据下的获取时间对比
图9:E3SM中不同DAOS引擎在56KB元数据下的获取时间对比
图9展示了E3SM案例的获取时间。获取时间包括MPI Bcast时间和I/O读取时间,其中MPI Bcast时间取决于读取节点的数量,而I/O时间受写入器数量的影响。DAOS引擎的选择仅影响I/O读取时间。在1024个节点时,DAOS-KV-async-get的获取时间比DAOS-Array慢1.2倍。这是因为DAOS-KV-async-get在每个时间步都会发出1024个daos_kv_get()请求,这显然增加了开销。每次调用daos_kv_get()都需要单独的RDMA缓冲区注册。随着写入器数量的增加,KV条目的数量也增加,这种开销变得尤为显著。然而,daos_array_read()则能够将多个范围的向量I/O合并到一个连续的缓冲区中,只需一次RDMA缓冲区注册。
D.小元数据 - 5KB
图10展示了5KB小元数据的稳定时间。与之前的情况不同,DAOS-Array的稳定时间比DAOS-KV慢了25倍。在DAOS-Array引擎中,写入器节点按顺序将各自的元数据连续写入数组,这导致了密集的数组布局,减少了存储元数据的目标数量。每个目标都有有限数量的RDMA缓冲区。大量并发的daos_array_write()操作争夺这些缓冲区,导致显著的减速。
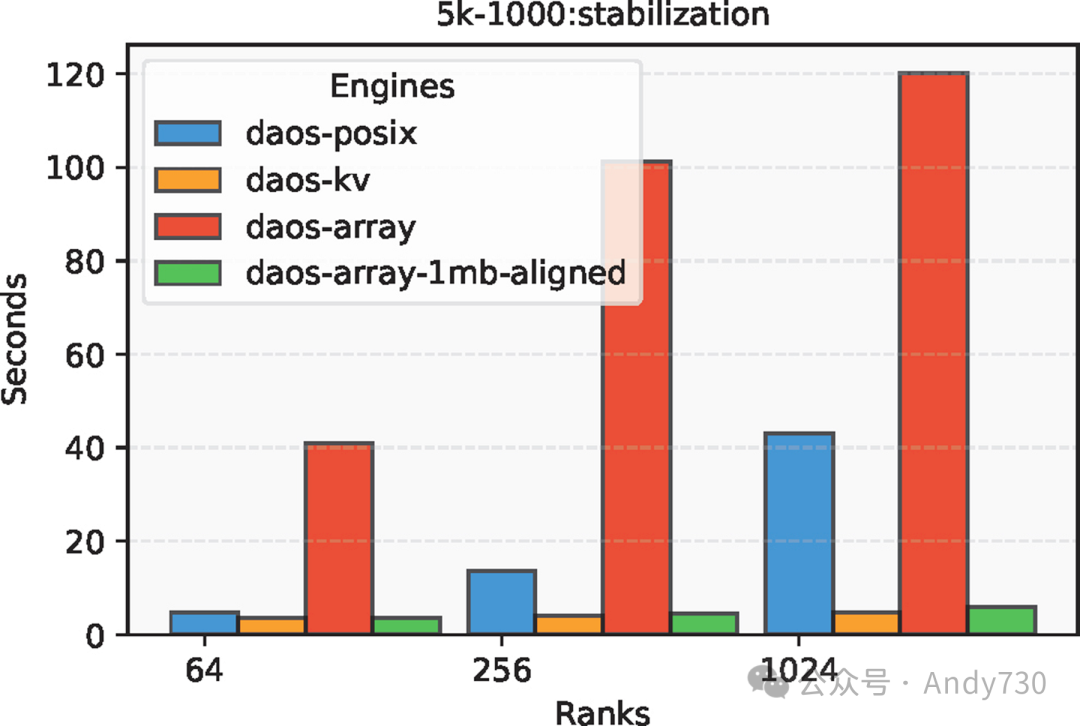 图10:小型元数据(5KB)情况下不同DAOS引擎的稳定时间对比
图10:小型元数据(5KB)情况下不同DAOS引擎的稳定时间对比
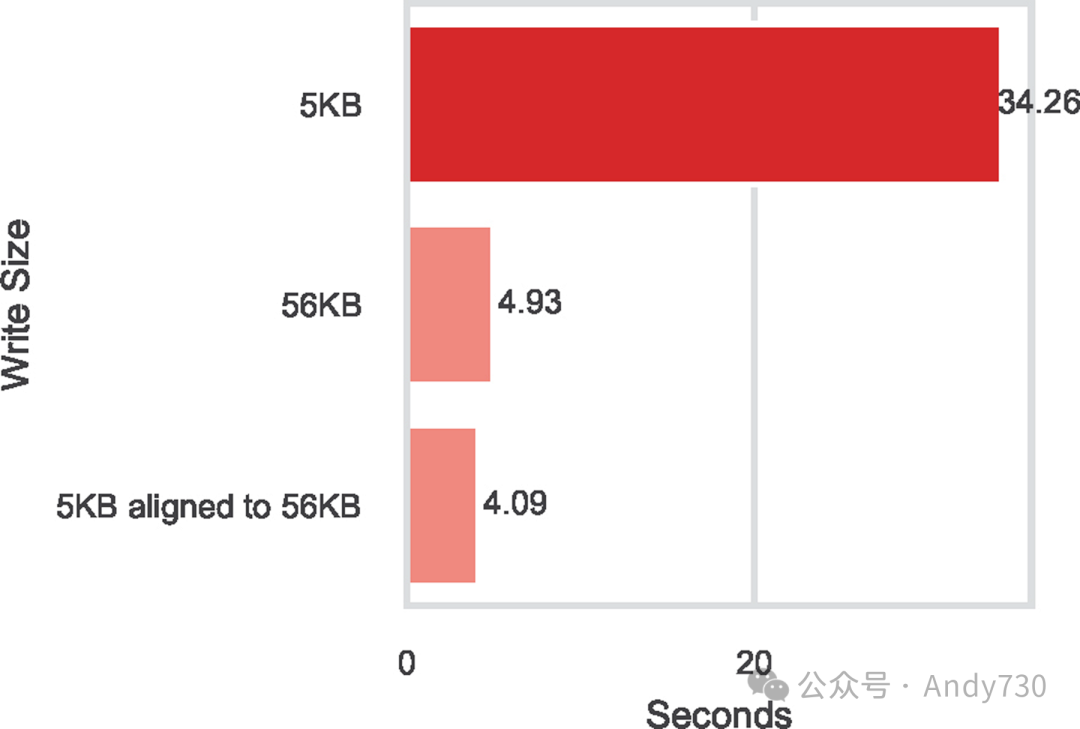 图11:对齐的5KB和56KB元数据大小下daos_array_write()时间对比
图11:对齐的5KB和56KB元数据大小下daos_array_write()时间对比
为了进一步说明这种DAOS-Array行为,我们创建了一个定制基准测试,使用5KB和56KB的元数据,分别使用200和20个写入节点。时间步数为100。在这两种情况下,每个时间步写入的数据总量大约为1MB。我们特意将5KB的写入对齐到DAOS-Array中的56KB边界。这种对齐确保了更稀疏的布局和数据在更多目标上的分布。作为参考,我们还展示了200个写入节点情况下5KB未对齐的结果。图11显示了对齐的5KB和56KB的daos_array_write()时间相似,这与图8和图10中观察到的56KB和5KB之间的明显差异不同。
回到图10,DAOS-Array-ChunkSize-aligned引擎有效地解决了元数据分布不均的问题。它通过优化元数据在目标间的分布,显著减少了资源竞争。因此,DAOS-Array-ChunkSize-aligned的稳定时间得到了大幅提升,比DAOS-Array快了25倍,与DAOS-KV相当。
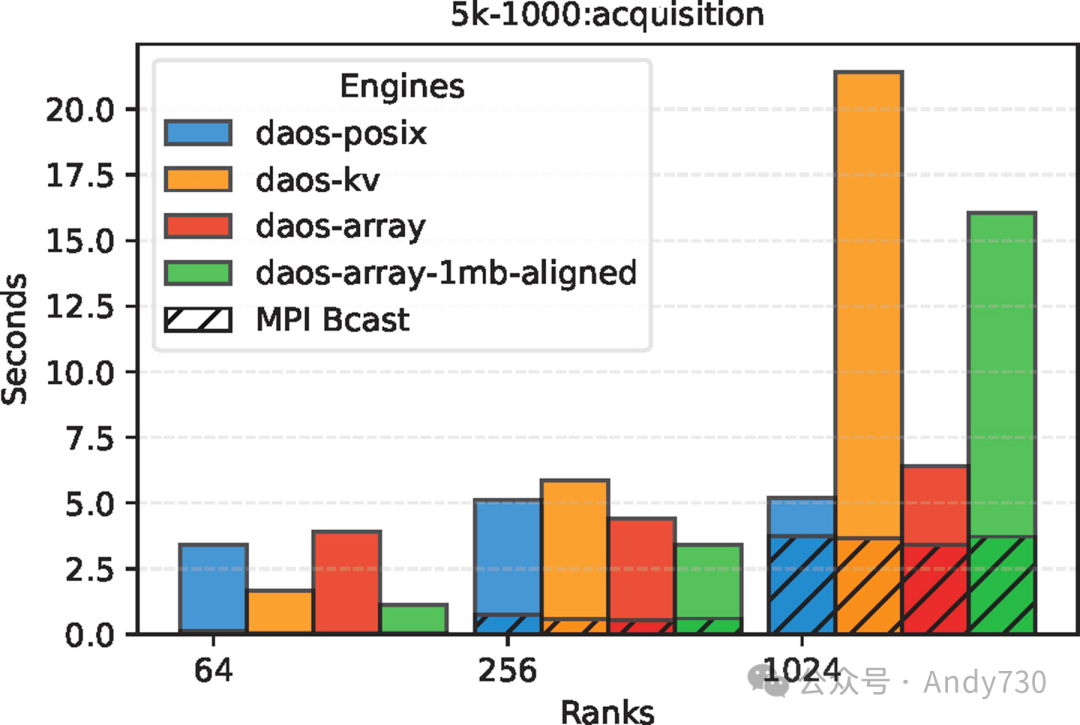 图12:小型元数据(5KB)情况下不同DAOS引擎的获取时间对比
图12:小型元数据(5KB)情况下不同DAOS引擎的获取时间对比
图12展示了5KB元数据的获取时间。在DAOS-KV中,对于小于20KB的值,daos_kv_get()会在RPC调用后直接返回,无需RDMA传输。然而,许多直接执行的操作效率不如daos_array_read()提供的向量I/O。在1024个节点时,DAOS-KV-async-get的获取时间分别比DAOS-Array和DAOS-Array-ChunkSize-aligned慢了1.33倍和3.35倍。尽管DAOS-Array-ChunkSize-aligned在写入时相较于DAOS-Array有显著优势,但在读取时却比DAOS-Array慢了2.5倍。这是因为DAOS-Array中元数据是连续布局的,允许从单个目标读取更大的数据块(1MB),而不是从多个目标读取多个小的5KB数据块。值得注意的是,DAOS-POSIX比DAOS-Array-aligned快,这是因为ADIOS中的POSIX引擎依赖一种优化,即每次读取时预取最多16MB的元数据,甚至超出了当前时间步的需求。在DAOS数组的情况下,我们尚未集成这种优化;因此,在5KB元数据的获取时间上,DAOS-POSIX更快。我们在Argonne的Aurora机器上量化了这种优化的影响,比较了带有和不带有预取优化的DAOS-POSIX,结果显示了大约2.5倍的差异。我们确认,在Aurora上,DAOS-POSIX和DAOS-Array之间的差异与图12中展示的差异相近。不过,尽管有这一点小优势,但DAOS-POSIX的端到端时间(见图13b)仍然比Array和KV慢,这主要受稳定时间的影响。
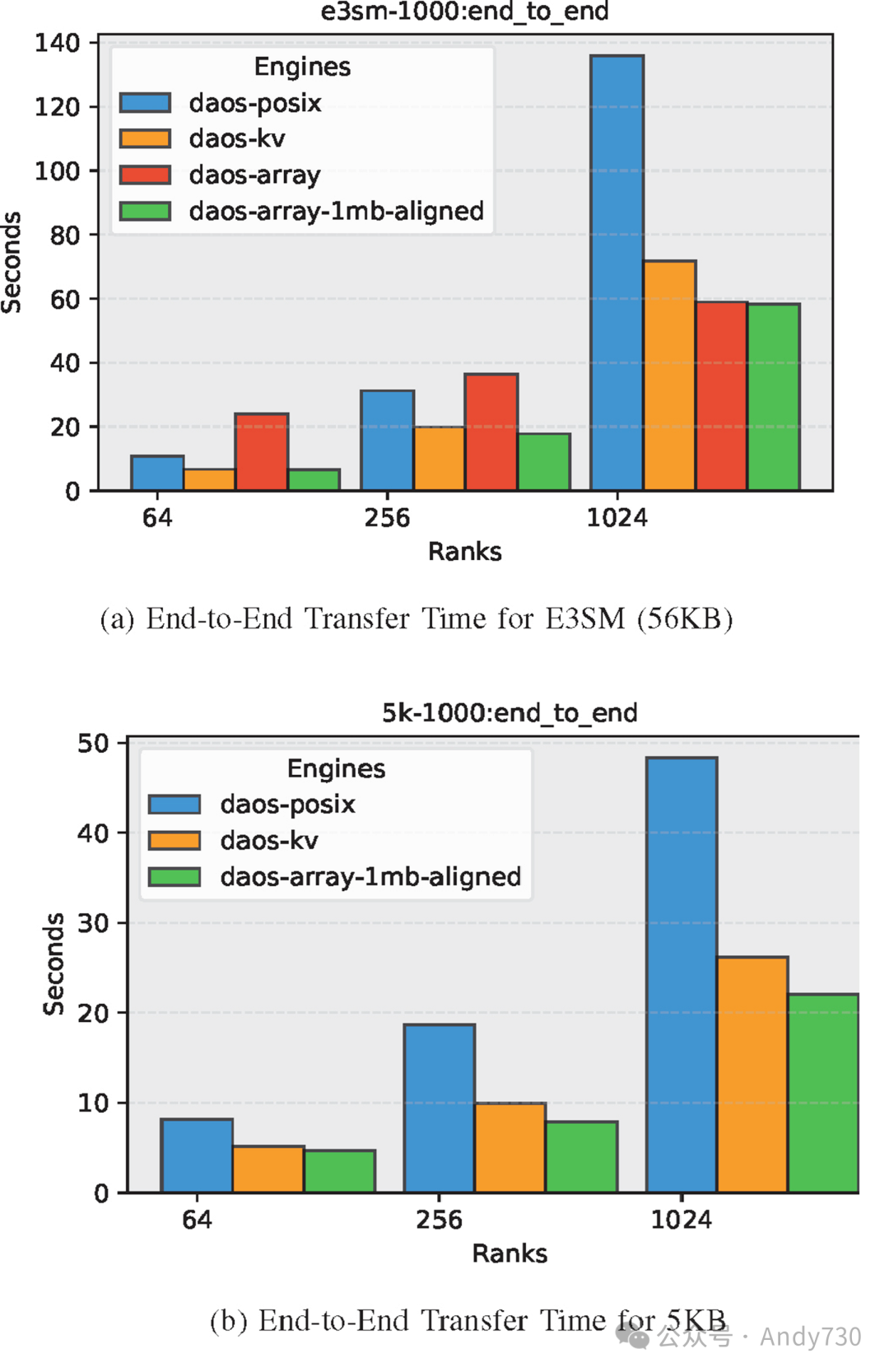 图13:不同元数据大小下不同DAOS引擎的端到端传输时间对比
图13:不同元数据大小下不同DAOS引擎的端到端传输时间对比
E.端到端传输时间
我们综合了不同DAOS引擎选项的上述观察结果,展示了两种应用场景的端到端传输时间。结果如图13a和13b所示。对于E3SM(56 KB)案例,DAOS-Array-ChunkSize-aligned的端到端传输时间几乎与DAOS-Array相当,同时比DAOS-POSIX快2.3倍,比DAOS-KV-async-get快23%。DAOS-POSIX的稳定时间主导了其元数据的端到端传输时间。对于5KB元数据,DAOS-Array-ChunkSize-aligned再次展现了最佳的元数据端到端传输时间,比DAOS-POSIX快2.1倍。由于稳定时间差异较大,DAOS-Array的端到端时间表现不佳,因此未在图13a中显示以便于阅读。尽管DAOS-Array-ChunkSize-aligned的获取时间比DAOS-Array慢,但稳定时间的提升使其端到端传输时间比DAOS-KV-async-get快20%。
F.长时间运行应用的考量
初步结果基于1000个时间步长的测试,帮助我们理解了在合理时间尺度上稳定化和获取时间之间的权衡,并排除了性能较差的引擎选项。为了进一步在长时间运行的应用背景下评估这些观察结果,我们增加了实验规模,将时间步长从1000增加到10000。
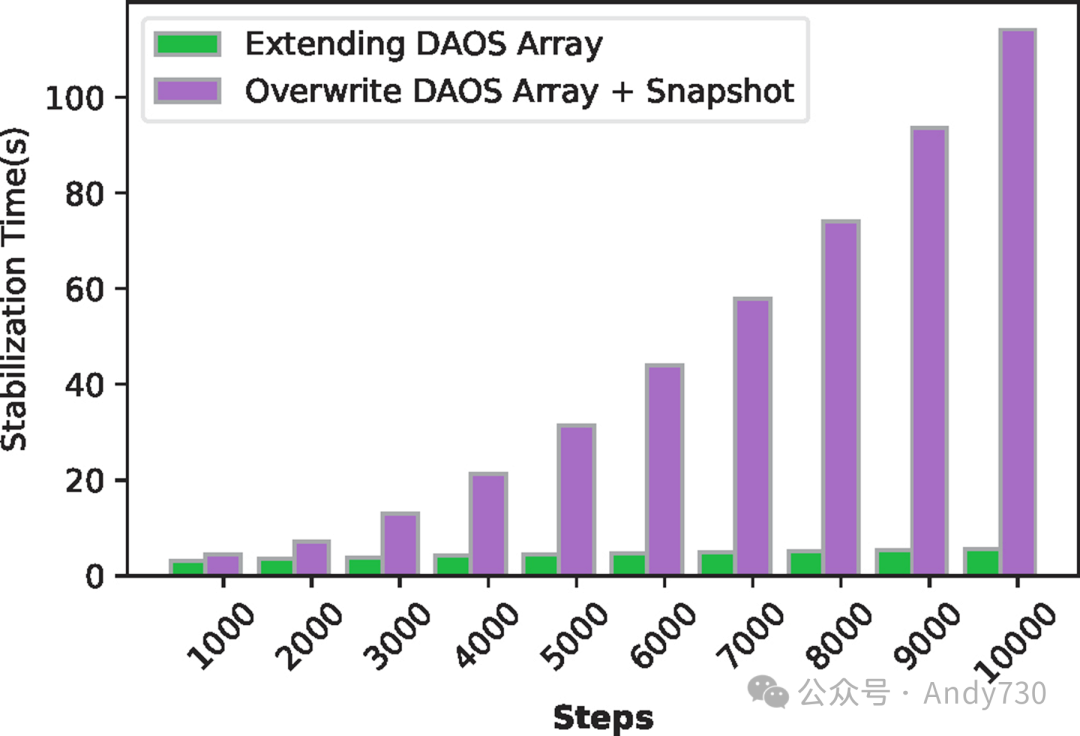 图14:使用64个写入Rank时,有无DAOS快照的稳定时间对比
图14:使用64个写入Rank时,有无DAOS快照的稳定时间对比
DAOS数组与快照的比较
首先,我们评估了DAOS容器快照机制作为ADIOS I/O的一种手段,而不是直接扩展DAOS数组对象。DAOS容器快照机制很好地满足了给定时间步长内一致的ADIOS元数据需求。在这种方法中,所有写入排名按照其排名顺序在预定偏移量处写入元数据。在每个时间步长结束时,排名0捕获容器的快照。图14展示了在仅使用64个写入排名的情况下,通过使用或不使用快照的DAOS数组在不断增加的ADIOS时间步长上的稳定化时间对比。使用快照时,写入者在相同偏移量处覆盖其元数据,而不使用快照时,元数据在每个时间步长上写入新的偏移量。我们观察到,随着时间步长的增加,基于快照的方法性能逐渐下降。在DAOS数组中,被覆盖的区间被标记为待垃圾回收。尽管快照阻止了存储空间被立即回收,但触发垃圾回收需要遍历DAOS的内部结构,成本较高。随着覆盖区间数量的增加,这种开销也随之增加。相反,不使用快照的方法避免了覆盖,消除了由于垃圾回收而导致的性能下降,即使在大量ADIOS时间步长的情况下也能保持较低的稳定化时间。
重新审视长时间运行应用的大元数据I/O
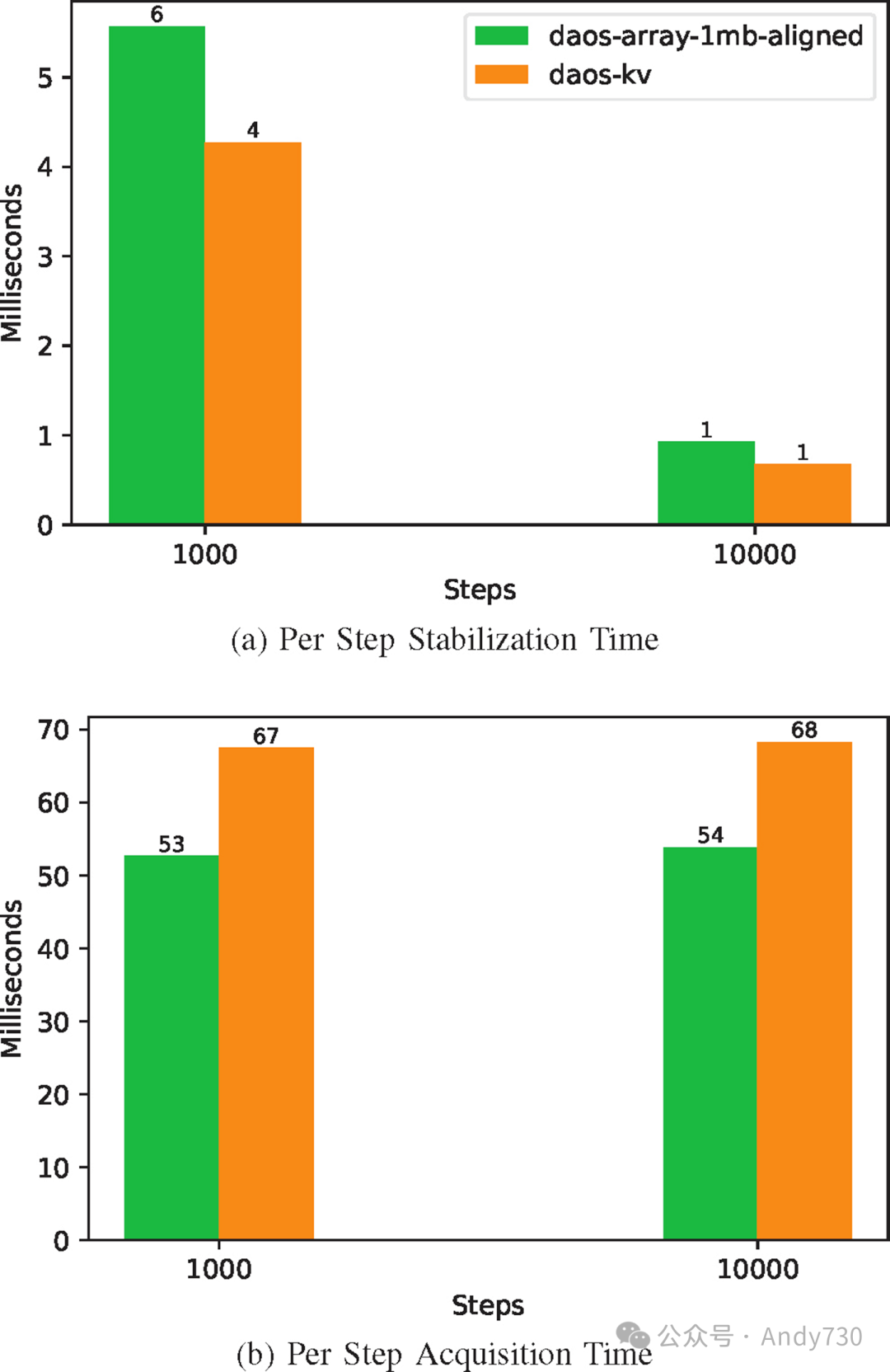 图15:评估增加步数对E3SM每个时间步长稳定时间和获取时间的影响(56KB元数据)
图15:评估增加步数对E3SM每个时间步长稳定时间和获取时间的影响(56KB元数据)
我们进一步探讨了随着时间推移,前一部分结果中表现最佳的两个引擎(DAOS-Array-ChunkSize-aligned和DAOS-KV-async-get)在稳定化和获取成本上的变化。我们测量并分析了两个关键指标:每个时间步长所需的时间和每字节传输的成本,同时时间步长从1000增加到10000。图15a显示,当时间步长从1000扩展到10000时,平均每个时间步长的稳定化时间减少了五倍。这种减少是由于初始设置成本随时间步长的增加而得到分摊。这些成本包括初始I/O任务,如与verbs提供程序的连接设置和队列对创建。在图15b中,随着步长从1000到10000的增加,每个时间步长的获取时间保持相对稳定。这是因为虽然存在相同的初始成本,但由于每个读取排名所消耗的元数据显著多于每个写入排名所生成的元数据,这些成本得以更快分摊。这是因为每个读取排名读取整个元数据,而写入排名仅写入其自己的元数据。然而,关键点在于,与容器快照不同,DAOS-Array-ChunkSize-aligned非常适合长时间的ADIOS应用。
扩展成本与排名数量的关系
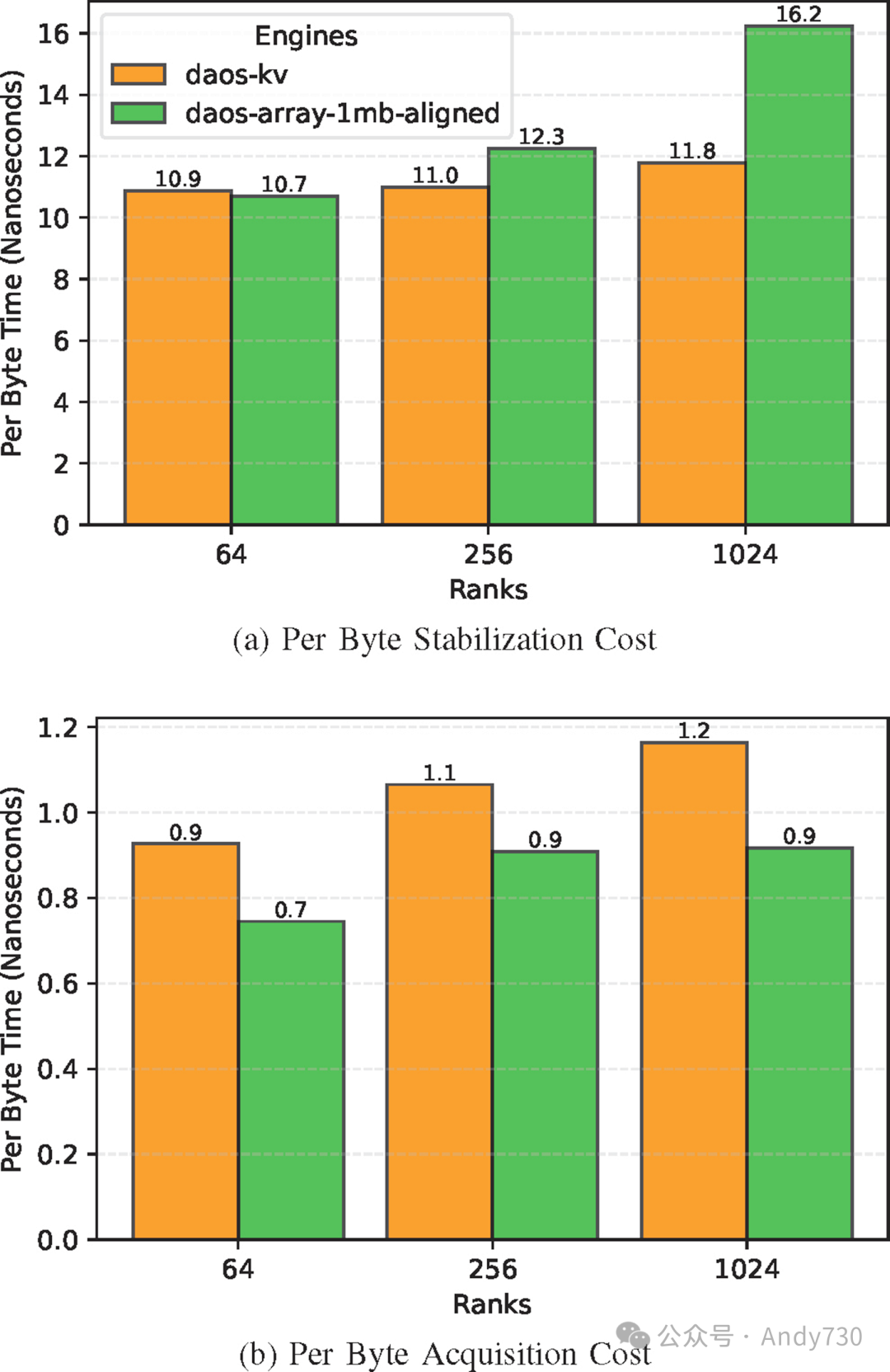 图16:使用每字节成本测量,随着Rank数量增加的DAOS引擎稳定性和获取效率(E3SM 56KB元数据)
图16:使用每字节成本测量,随着Rank数量增加的DAOS引擎稳定性和获取效率(E3SM 56KB元数据)
除了测量大量ADIOS时间步长对元数据传输性能的影响外,我们还需要评估与排名数量相关的扩展成本。因此,我们测量了每字节的稳定化和获取时间。每字节时间是根据每个排名的总数据稳定或获取量除以时间计算得出的。图16a和16b显示,随着排名数量的增加,每字节时间略有增加,而总元数据增加了四倍。
G.使用空闲DAOS数组的存储开销
DAOS数组块大小是存储分布的单位,而非分配单位。它确保从一个块边界到下一个块边界的所有数组元素都在目标上得到保证放置。然而,当写入小于块大小的区间时,不会分配整个块大小。虽然这可能会产生额外的DAOS对象元数据存储开销,但DAOS-Array和DAOS-Array-ChunkSize-aligned执行完成后,DAOS上的可用空闲空间并未出现可测量的差异。我们使用1024个排名将时间步长增加到20000,每个时间步长写入56 KB元数据,并再次运行E3SM基准测试,创建了1.14 TB的元数据。如果DAOS-Array-ChunkSize-aligned分配1 MB块,那么理论上需要20 TB的存储。然而,DAOS存储空闲空间查询报告表明,DAOS-Array和DAOS-Array-ChunkSize-aligned的空闲空间相同,这证实了使用稀疏数组不会引入额外的存储开销。
H.WarpX激光尾波场模拟
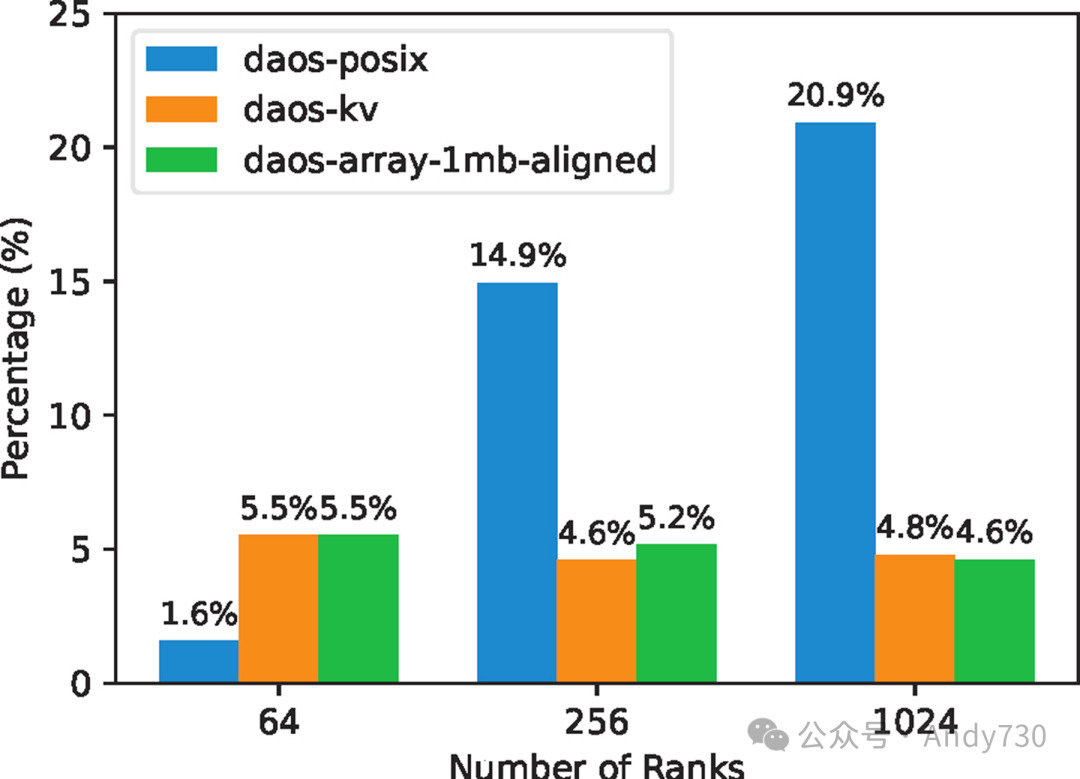 图17:WarpX中稳定时间占执行时间的百分比
图17:WarpX中稳定时间占执行时间的百分比
为了评估DAOS元数据引擎在完整应用中的性能,我们运行了WarpX激光尾波场模拟,进行了1000次迭代,每10次迭代写入一次ADIOS数据输出。模拟设置包括128 x 128 x 256单元的离散网格,采用了自适应网格细化(AMR)和最大网格尺寸以及16的分块因子,以优化计算效率。图17显示了稳定化时间占执行时间的百分比。这次WarpX执行的元数据大小为几KB,这些结果与图10中5KB稳定化的性能趋势相似。在此情况下,WarpX在Cambridge CS3D机器上执行,因此绝对测量值与图1中ORNL的Frontier的结果不直接可比。然而,对于1024的基线DAOS-POSIX测量值,也约占总体I/O时间的21%。而对于DAOS-KV-async-get和DAOS-Array-ChunkSize-aligned,这一时间降至约4.5%。这证实了合理使用DAOS接口可以显著降低元数据I/O成本。
VII.贡献总结
通过我们的评估,我们揭示了基于POSIX的元数据处理在实际应用(如WarpX和E3SM)中产生的显著成本。DAOS的Array和KV API为我们提供了解决元数据传输问题的契机。然而,在ADIOS环境中实现DAOS并非易事。我们提出了关于数据布局和并发的不同设计选项,并分析了它们在写入端和读取端的权衡。
新开发的DAOS-Array-ChunkSize-aligned引擎在大量ADIOS时间步长下,为不同元数据大小提供了改进的端到端传输时间。我们将DAOS-Array-ChunkSize-aligned引擎的性能与DAOS-KV-async-get和DAOS-POSIX引擎进行了对比。结果表明,DAOS-KV-async-get和DAOS-Array-ChunkSize-aligned的稳定时间比DAOS-POSIX快一个数量级。尽管两者稳定时间相似,但DAOS-Array-ChunkSize-aligned的获取时间比DAOS-KV-async-get快高达23%。DAOS-Array-ChunkSize-aligned的端到端传输时间比DAOS-POSIX快多达2.3倍。这些新引擎已开源,并可在[16]处获取。
VIII.相关工作
Jialin Liu等人[17]在HPC I/O的背景下评估了不同的对象存储。他们的研究强调了对象存储相较于POSIX在可扩展性上的优势。研究使用了专为Ceph/RADOS[18]、Openstack Swift和Intel DAOS设计的三个HDF5虚拟对象层插件。评估结果显示,大多数对象存储的主要I/O粒度是整个对象,而POSIX中的粒度更为精细。与此不同,DAOS数组API提供了I/O描述符,允许选择性访问对象的部分。在I/O带宽和相关成本方面,DAOS优于RADOS和Swift。Liu等人还指出了将HDF5的层次数据模型映射到对象固有的扁平命名空间所需的辅助工具。尽管ADIOS可能不支持层次数据模型,但它确实支持多维数组,这意味着ADIOS有类似需求。另一项研究[19]探讨了在HPC工作流中优化使用Optane传输数据的方式。
最近的一项研究[20]探索了在DAOS对象接口上运行HDF5的性能。这种以对象为中心的设计使HDF5能够摆脱传统的基于块的存储,从而绕过了POSIX的限制。在基于文件的存储中,HDF5对象的实例化需要排名之间的协调,这导致了资源密集型的I/O集体操作。当与DAOS集成时,HDF5对象创建的时间显著减少。此外,与DAOS键值接口的集成使得HDF5能够引入新的映射功能。DAOS HDF5 VOL还支持异步I/O,从而提高了存储带宽的利用率。本论文的结果与这些研究互为补充,因为我们的重点是理解低级DAOS接口之间的权衡,特别是在元数据I/O的背景下。
IX.结论
在本文中,我们探讨了DAOS中存储ADIOS级元数据的几种方法,深入研究了KV和Array接口,并将这些方法的性能与当前基于POSIX的ADIOS元数据存储机制进行了对比。测量结果显示,基于数组的方法,即每个ADIOS排名在对应于DAOS块大小的增加偏移量处写入其元数据贡献,是我们研究的最佳方案,其性能实际上比在POSIX文件中存储元数据快多达2.3倍。尽管部分实验是在模拟环境中进行的,模拟了ADIOS引擎存储元数据的活动,但我们已在ADIOS中开发了一个可用的DAOS引擎,该引擎使用Array接口在DAOS中存储ADIOS元数据。目前,从ADIOS BP5引擎派生的DAOS引擎仍使用POSIX文件(通过DAOS POSIX支持)存储数据,但我们希望这项工作能为未来的研究提供指导,最终实现一个全DAOS对象引擎,带来更加优化的数据存储行为。
本文还增加了探索中间件级元数据在HPC I/O中性能影响的研究成果。如第II部分所述,像WarpX这样的应用会将24%的数据写入时间用于元数据开销。我们期望这项工作能够推动未来的研究,不仅在中间件级元数据处理方面,而且在DAOS在百亿亿次HPC场景中的应用方面。
REFERENCES
[1] P. Braam, “The Lustre storage architecture,” arXiv preprint arXiv:1903.01955, 2019.
[2] F. Schmuck and R. Haskin, “GPFS: A Shared-Disk file system for large computing clusters,” in Conference on File and Storage Technologies (FAST ’02), 2002.
[3] S. R. Alam, H. N. El-Harake, K. Howard, N. Stringfellow, and F. Verzelloni, “Parallel I/O and the metadata wall,” in Proceedings of the sixth workshop on Parallel Data Storage, 2011, pp. 13–18.
[4] R. Macedo, M. Miranda, Y. Tanimura, J. Haga, A. Ruhela, S. L. Harrell, R. T. Evans, J. Pereira, and J. Paulo, “Taming metadata-intensive hpc jobs through dynamic, application-agnostic qos control,” in 23nd IEEE International Symposium on Cluster, Cloud and Internet Computing (CCGrid). IEEE, 2023.
[5] Argonne National Laboratory, “Aurora Supercomputer,” https://www. alcf.anl.gov/aurora, Argonne Leadership Computing Facility, 2023, accessed: July 18, 2023.
[6] J. Lofstead, I. Jimenez, C. Maltzahn, Q. Koziol, J. Bent, and E. Barton, “Daos and friends: a proposal for an exascale storage system,” in SC’16: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2016, pp. 585– 596.
[7] M. Hennecke, “Daos: A scale-out high performance storage stack for storage class memory,” Supercomputing frontiers, p. 40, 2020.
[8] J. Izraelevitz, J. Yang, L. Zhang, J. Kim, X. Liu, A. Memaripour, Y. J. Soh, Z. Wang, Y. Xu, S. R. Dulloor et al., “Basic performance measurements of the intel optane dc persistent memory module,” arXiv preprint arXiv:1903.05714, 2019.
[9] IO500, “IO500 Submission 621,” https://io500.org/submissions/view/ 621, IO500, 2023, accessed: July 18, 2023.
[10] Q. Liu, J. Logan, Y. Tian, H. Abbasi, N. Podhorszki, J. Y. Choi, S. Klasky, R. Tchoua, J. Lofstead, R. Oldfield et al., “Hello adios: the challenges and lessons of developing leadership class i/o frameworks,” Concurrency and Computation: Practice and Experience, vol. 26, no. 7, pp. 1453–1473, 2014.
[11] Patrick Riley, “Berkeley Lab-Led WarpX Project Key to 2022 Gordon Bell Prize,” https://cs.lbl.gov/news-media/news/2022/ berkeley-lab-researchers-lead-two-gordon-bell-finalist-teams/, 2022.
[12] Association for Computing Machinery (ACM), “Using next generation exascale supercomputers to understand the climate crisis,” https://www.acm.org/media-center/2023/november/gordon-bell-climate-2023, 2023.
[13] J. F. Lofstead, S. Klasky, K. Schwan, N. Podhorszki, and C. Jin, “Flexible io and integration for scientific codes through the adaptable io system (adios),” in Proceedings of the 6th international workshop on Challenges of large applications in distributed environments, 2008, pp. 15–24.
[14] “ADIOS2 PerfMetaData,” https://github.com/ornladios/ADIOS2/blob/ master/testing/adios2/performance/metadata/PerfMetaData.cpp.
[15] D. Boehme, T. Gamblin, D. Beckingsale, P.-T. Bremer, A. Gimenez, M. LeGendre, O. Pearce, and M. Schulz, “Caliper: performance introspection for hpc software stacks,” in SC’16: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2016, pp. 550–560.
[16] R. S. Venkatesh and G. Eisenhauer, “DAOS Object Based Metadata Engines in ADIOS2,” https://github.com/ranjansv/ADIOS2, 2024.
[17] J. Liu, Q. Koziol, G. F. Butler, N. Fortner, M. Chaarawi, H. Tang, S. Byna, G. K. Lockwood, R. Cheema, K. A. Kallback-Rose, D. Hazen, and M. Prabhat, “Evaluation of hpc application i/o on object storage systems,” in 2018 IEEE/ACM 3rd International Workshop on Parallel Data Storage and Data Intensive Scalable Computing Systems (PDSWDISCS), 2018, pp. 24–34.
[18] S. A. Weil, S. A. Brandt, E. L. Miller, D. D. Long, and C. Maltzahn, “Ceph: A scalable, high-performance distributed file system,” in Proceedings of the 7th symposium on Operating systems design and implementation, 2006, pp. 307–320.
[19] R. S. Venkatesh, T. Mason, P. Fernando, G. Eisenhauer, and A. Gavrilovska, “Scheduling HPC Workflows with Intel Optane Persistent Memory,” in 2021 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE, 2021, pp. 56–65.
[20] J. Soumagne, J. Henderson, M. Chaarawi, N. Fortner, S. Breitenfeld, S. Lu, D. Robinson, E. Pourmal, and J. Lombardi, “Accelerating HDF5 I/O for exascale using DAOS,” IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 4, pp. 903–914, 2021.
--【本文完】---
近期受欢迎的文章:
更多交流,可添加本人微信
(请附姓名/单位/关注领域)

