




内容摘要
AI基础设施(计算/网络/存储)不均衡:计算密度和网络性能大幅提升,但存储性能却没有跟上。 GPU利用率不足:GPU利用率通常只能达到30%-40%,存储系统成为限制性能的瓶颈,导致计算资源未能充分利用。 数据停滞问题:多个并行管道中的每个步骤都具有其独特的数据存储特性(高带宽、小文件读写、元数据查找、低延迟、低成本),导致数据无法高效地在系统中流动 WEKA高性能数据解决方案:WEKA提供高性能数据的统一软件解决方案,自动处理性能需求,优化管道中每个步骤的性能。GPU利用率从30%到40%提升至80%以上,提升了模型训练速度和响应能力。 WEKA特色能力:高性能存储层、混合存储方案、融合模式、自动扩展功能、兼容常见存储协议、文件系统。
-----[以下为正文]-----
大家好,我是WEKA云业务的Phil Curran。今天,我将与大家分享关于数据架构的选择,以及这如何影响并推动云端AI开发的能力。
大多数AI开发人员对GPU架构、成本、可访问性和可持续性等关键问题都了如指掌。然而,目前,许多AI领域的公司正面临一系列与高性能数据相关的新兴挑战。接下来,我将解析其中的一些挑战,并提供一些建议,帮助大家克服或避免在AI部署过程中遇到的瓶颈。
首先,让我简要介绍一下WEKA。WEKA实际上是在云端诞生的。我们于2017年在AWS re:Invent大会上推出,致力于为客户提供一个现代化的数据平台,专门用于AI和性能密集型工作负载。我们独特的方法为客户在数据性能、巨大可扩展性方面带来了显著提升,并简化了数据操作。WEKA客户可使用统一软件代码库处理每个工作负载,并享有完全的基础架构灵活性,确保应用程序在最适合其业务发展的环境中运行。

如今,客户使用WEKA软件驱动最性能密集的应用程序,几乎覆盖所有主流云平台。无论是AWS、Azure、Google Cloud还是Oracle,甚至是在数据中心上运行的通用硬件上,都有WEKA的身影。最近,我们的客户还在许多新兴的GPU云中运行用于AI训练和模型开发的工作负载。
这一趋势并不令人意外,但值得一提的是,AI应用的爆炸式增长确实催生了一波新的工作负载,这些工作负载要么迁移到云端,要么在云端构建。这些新的工作负载主要关注于最性能密集的应用程序,例如大型语言模型训练、高性能计算以及一系列行业领域的应用。
例如在媒体和娱乐领域,云端工作室因其灵活性已成为大多数工作室的默认操作模式。艺术家需要低延迟、零滞后和零丢失,这些都是基本要求。在金融服务领域,银行和对冲基金则利用AI建模加速诈骗检测和算法训练,同样需要低延迟来提供实时分析。而在生命科学、药物发现和动态处理等领域,客户对I/O低延迟和高带宽有着巨大的需求。如今,他们希望能在云端或高密度共享基础设施上运行这些工作负载。

实际上,我们观察到客户可用的基础设施存在不平衡。这些工作负载因多种原因迁移到云端。其中一个重要原因是云服务商在性能方面取得的显著进步。回顾过去5到10年,云服务商提供的计算性能和网络性能都有了大幅提升。近5年来,计算密度提高了4倍,这在很大程度上是由视频驱动的。现在,许多云实例类型都支持GPU加速,这在提高计算性能方面带来了巨大的提升。在网络方面,我们已经转向400GbE,甚至更先进的网络技术也在不断涌现。因此,由于计算和计算机网络堆栈中的性能提升,我们看到越来越多的客户开始将AI和HPC工作负载转移到云端。
这个堆栈其实由三大支柱构成。虽然计算密度和网络性能的大幅提升使得客户能够完成以往难以达成的任务,但存储却开始成为瓶颈。无论是本地还是云端,传统的数据存储解决方案均难以满足这些大型或加速计算集群对高性能数据的需求。因此,许多组织的整个AI数据管道速度变得迟缓。总的来说,问题主要集中在以下几个方面:GPU利用率低下(通常只能达到30%或40%的利用率)、模型训练和调整时数据加载时间过长(导致模型启动和运行缓慢)、繁重的元数据操作和元数据查找拖慢了模型训练过程本身,以及数据停滞(涉及元数据查找和I/O混合器问题)。
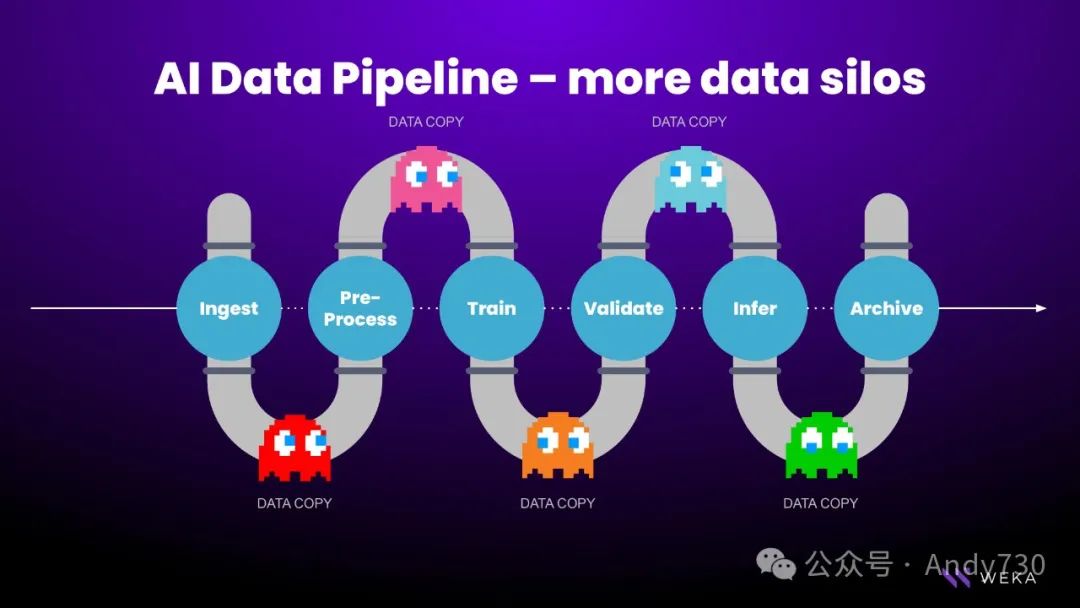
除了数据性能,另一个挑战在于这些工作负载通常运行在复杂的数据管道中,这个例子恰好展示了一个典型的AI数据管道。事实上,在我提到的所有不同应用场景中,比如药物发现、视觉效果制作,或者开发进行自然语言处理的自动驾驶车辆,类似的数据管道都相当普遍。这个管道中的每个步骤都具有其独特的数据存储特性。
在数据接入方面,需要高带宽以支持数据传输。接着,为了驱动预处理,需要在小文件上进行频繁的读写操作。在模型训练和验证阶段,需要处理大量的元数据查找,并以高I/O和低延迟进行快速读取,以确保训练周期的高效性。最后,一旦得到结果,需要将模型结果归档到长期存储中,并将该模型反馈到影响AI应用程序的环节中。这要求大量的读取带宽来存储结果,同时,也需要价格合理的块存储服务来进行长期存储。
以往,许多存储供应商为不同的应用场景构建了特定的存储设备。这意味着用户需要五个或六个不同的存储系统来支持每一个应用场景。然而,在云端,这样的做法既不实际也不经济。我们无法承受将数据复制到每个不同存储系统所需的时间和成本。我们需要一个更好的解决方案。
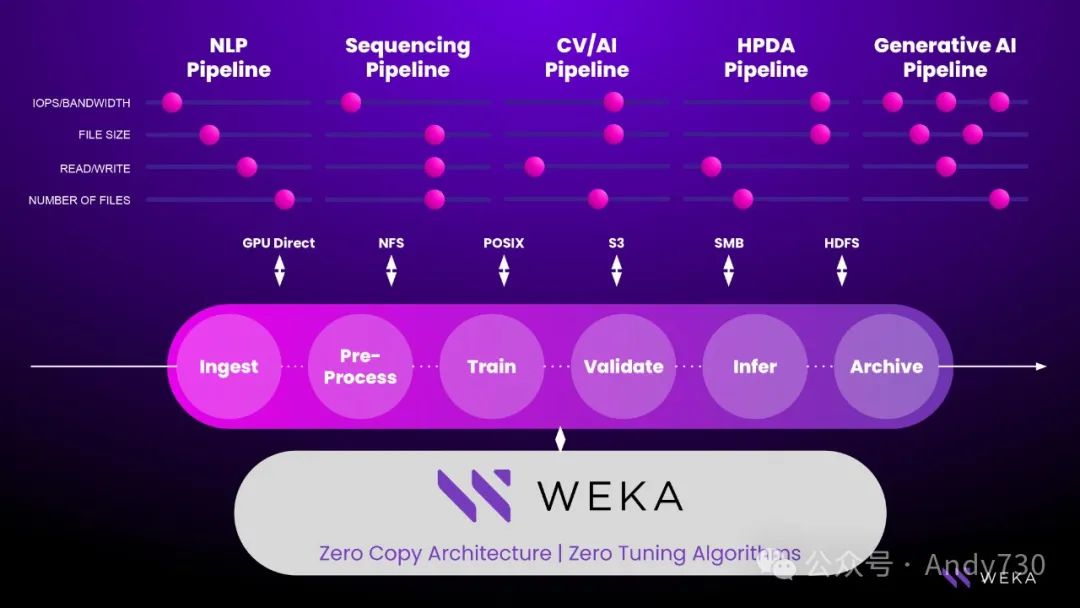
实际上,问题远比单个数据管道和相关的复制管理、性能问题更为复杂。特别是在AI训练和调整的场景中,多个管道可能并行运行,但它们处于不同的管道阶段。这使得情况变得更加复杂。我们将这种情况称为“吉他弦滑动”,但这实际上是对AI数据管道更为真实的描述。在任何给定时间,都可能看到三到四种不同的AI和存储配置文件同时运行。
WEKA提供的是一个高性能数据的统一软件解决方案,它优化了管道中每个步骤的性能。无论处于需要高I/O以提供低延迟、大带宽、处理大量读写、小文件或元数据查找的阶段,WEKA数据平台都能自动处理每个配置文件的性能需求,无需大量手动调整,也无需频繁复制和移动数据。
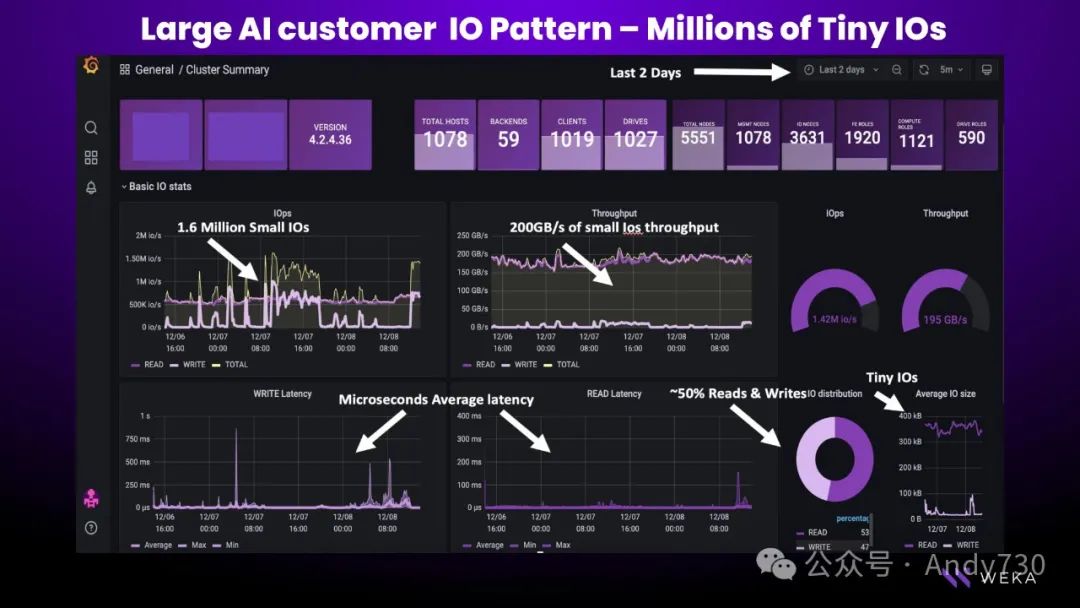
接下来,让我们通过一个实际案例来展示这一点。这个客户正在AWS中训练自然语言处理AI模型。他们的研究人员和分析师正在处理数据,用于模型构建和推理。在这种环境中,延迟非常关键。更快的模型训练速度意味着更快的查询响应和更短的上市时间,这对开发人员来说至关重要。关键在于充分利用GPU和P4、P5等高性能实例。当我们首次与客户接触时,经常会看到类似的工作负载配置文件,GPU利用率在30%到40%左右。但客户过渡到使用WEKA后,凭借我们提供高性能数据的能力,GPU利用率提升到了80%以上。
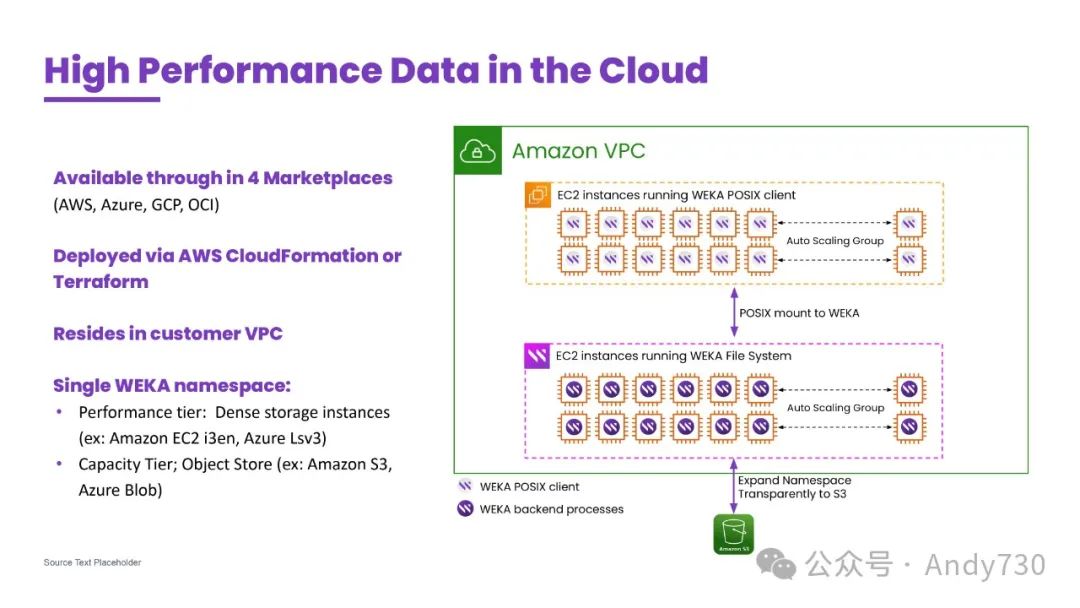
让我们深入了解这是如何实现的,以及我们如何真正帮助客户解决这一问题。有时,客户可能会面临传统存储和数据的“戈耳迪之结”(Gordian Knot)般的困境,无论是在本地还是云端。正如我之前提到的,WEKA在AWS、Azure、Google和Oracle等四大主要云平台上均可使用,并且用户可以在任何对其业务有意义的地方运行WEKA高性能数据平台。
我以AWS为例,但这些概念同样适用于Azure。当看到EC2实例时,可以将其视为Azure虚拟机;当看到自动扩展组时,它对应于Azure虚拟机规模集。在Google和Oracle Cloud中,也有类似的概念。
WEKA软件在EC2实例集群上运行。我们更倾向于在AWS上使用I3实例,而在Azure环境下则使用Lsv3。如今,我们利用云服务商的存储优化型基础架构实例,它们配备了每个实例都连接的大量NVMe闪存存储。正是这一点,我们用来驱动高性能。这也是WEKA软件的特色之一,它可以聚合一组实例中所有的NVMe闪存。我们从一个至少包含六个实例的集群开始,并根据需要扩展至所需规模,以满足性能要求。
该软件将这些实例中的闪存内存进行聚合,以形成一个高性能的存储层。但考虑到并非所有数据都需要如此快速且成本高昂的存储层,我们实际上还添加了一个S3存储桶,作为工作环境的后端,并构成了一个大规模的数据湖。这样,既能享受到S3的经济性长期存储,又能获得高性能的存储体验,并且还能实现扩展。
当然,我们将其呈现为一个文件系统,供应用程序使用,也支持客户的应用程序使用,兼容任何存储协议。无论是SMB、NFS,还是在容器化环境中,都支持CSI驱动程序。
WEKA的这种独特方法带来了几个值得深入探讨的影响,以及它们如何帮助客户实现所需的性能、经济性和扩展性。首先是高速闪存和低成本对象存储的结合,都统一在统一命名空间中。将S3的经济性大数据湖与高性能的NVMe闪存相结合,提供了性能与行业领先经济性的完美融合。
接下来要说的是自动扩展功能。在这里,可以看到WEKA集群如何实现自动扩展。由于WEKA软件运行在一组实例上,这些实例可以是EC2实例或Azure VM,我们利用了自动扩展的能力,既可以扩展,也可以缩减。可以将WEKA想象成一个具有韧性自动扩展属性的系统,用户已经习惯了计算资源的韧性自动扩展,但将其应用到存储上同样有效。如果需要增加性能,可以触发自动扩展,向WEKA集群中添加更多实例。如果需要更多的I/O、更低的延迟,可以向WEKA集群中添加更多的VM或EC2实例,这在AI训练场景中非常理想,例如大型语言模型的训练。用户不会为一段固定的时间持续运行该模型训练。可以扩展工作环境以提供所需的I/O和低延迟,当模型训练完成后,可以缩减资源,甚至在项目结束时完全关闭。这种扩展后缩减的想法在实际应用中非常有价值,因为不会为未使用的容量或性能存储付费。
另一方面,由于我们在高性能存储和容量存储的不同层面上运作,我们可以独立地扩展容量或性能。在WEKA中,不会因为满足性能要求而不得不添加额外的容量。永远不会为实际上没有使用的云资源付费。我们能够帮助客户极大地提高资源利用效率。
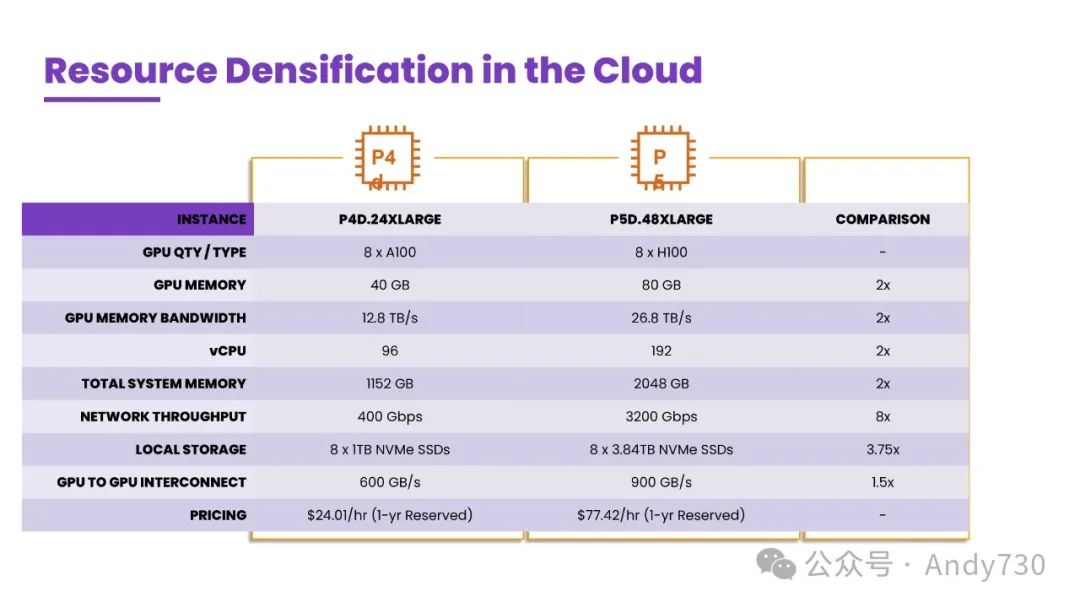
接下来,我想回顾一下我们在云中看到的基础设施创新,并分享一些WEKA正在与客户合作开发的其它增强和创新,以及这些创新在AI模型训练和开发中能够为您带来的优势。为此,我们必须认识到云中资源的密度有多高——我想再次谈谈资源密集化,并深入探讨。想想现在在云中可用的资源量。我们正在关注AWS的最新一代和上一代加速计算实例,即来自AWS的GPU加速计算实例。当然,包括配备了新H100的P5实例和上一代NVIDIA A100 GPU的P4实例。从简要对比来看,P5实例在资源量上仅比上一代增加了一倍,但vCPU数量增加了4倍,可用的网络带宽也增加了4倍。这标志着我们在云中计算和存储资源的利用上取得了巨大的进步。
如果回到核心观点上,那就是许多在云端进行模型训练和开发的HPC领域客户,因为采用传统存储解决方案,常常受到存储性能的制约。他们难以充分发挥这些资源的潜力。不论GPU利用率达到30%还是40%,总是有超过一半的资源在云端进行高性能操作时未能得到有效利用。
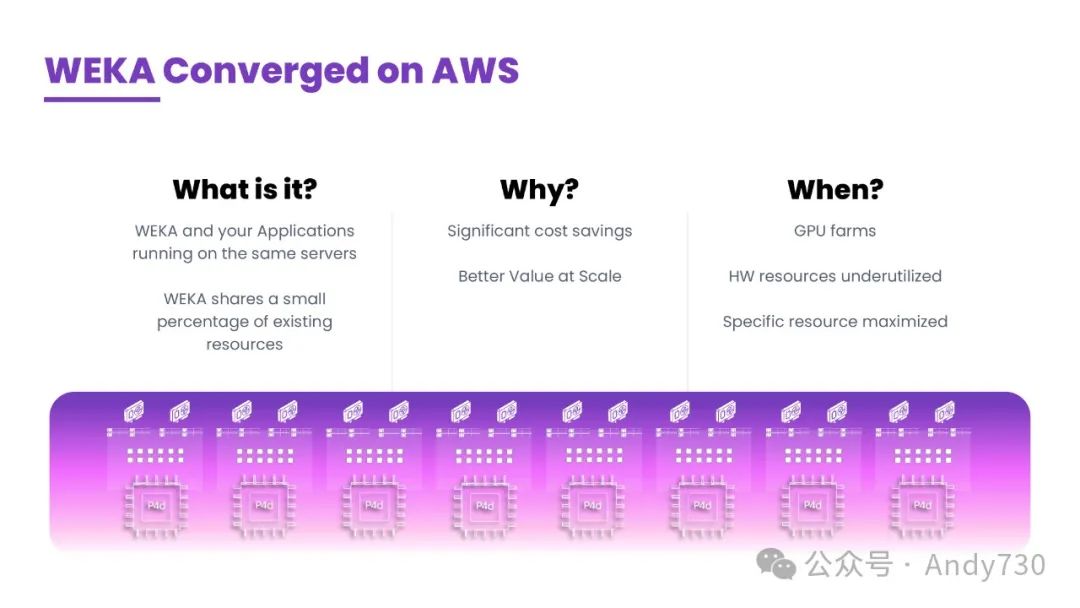
我们正在与多家客户合作,推广我们所谓的“融合模式”。WEKA在AWS上的融合模式,即我们提出了一种架构,旨在更好地利用这些密集计算类型中可用的资源,从而实现巨大的资源效率提升和成本的大幅降低。简单来说,我们建议在云中,将数据操作和应用程序部署在同一计算基础架构上。这就是我们所说的WEKA在AWS上的融合模式。
首先,我们会对客户的环境进行评估。在模型训练或AI开发项目中,我们通常讨论的是运行大型P4d或P5实例集群。这些是GPU优化、GPU加速的实例,我们可以利用这些实例获得最新的NVIDIA GPU加速器,以驱动模型训练和加速计算操作,并配备大量的NVMe闪存来运行备份。
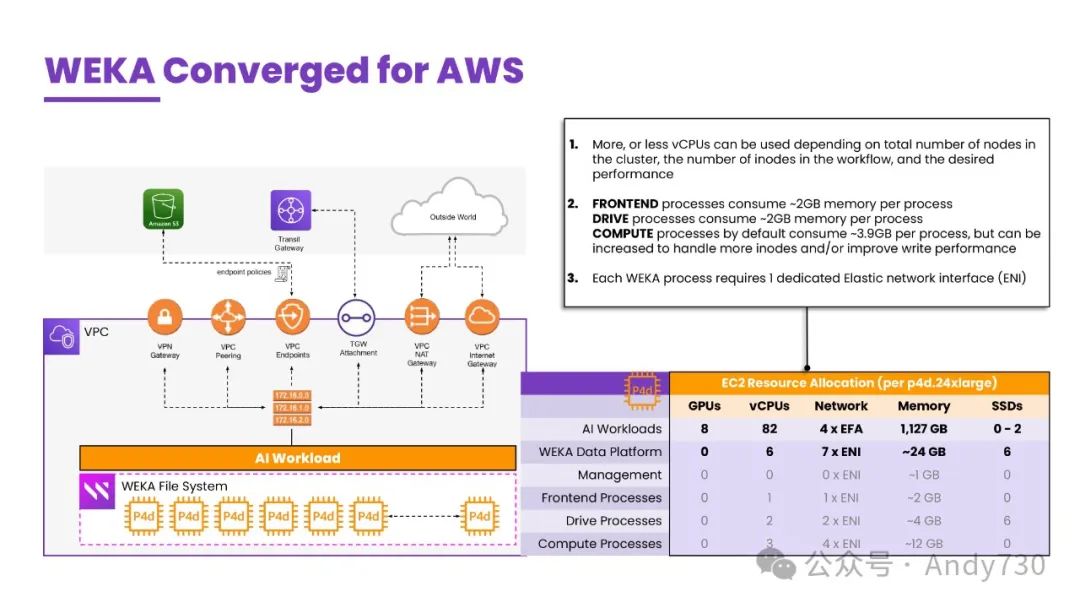
接下来,我们可以利用客户的环境,为WEKA分配一小部分计算资源。稍后我会详细介绍一些细节。我们会使用计算和网络资源,并尽可能多地消耗闪存存储,因为这是实现高性能存储的关键。我们会创建一个WEKA集群,这个集群是从客户的生产环境中独立出来的。在这种情况下,我们使用P4d实例。在这个集群上,我们运行数据操作。一个客户可能会使用大约8到10个节点的集群。在此,我将以某个客户为例进行说明。通常,一个典型的客户可能会有数百个,甚至500或1000个P4d或P5实例组成他们自己的集群。如果需要高性能,我们可能会使用8-10个实例,甚至可能多达100个。但我们会将这一环境中的一小部分实例分配给WEKA集群。通常,这是一个包含6到8个实例的基本集群。我们可以在AWS中实现超过100万IOPS的性能,稍后我会分享一些来自客户的统计数据。我们将这些资源分配给工作负载,从而为客户提供高性能。
我们要做的是将这些资源分配给WEKA数据平台。在这个例子中,我们从92个可用的vCPU中取出了6个。我们使用了70个IOPS和约24GB的RAM。这只是每个实例的分配情况。当将8-10个或更多的EC2实例组合在一起时,WEKA就拥有了一个相当强大的环境。当然,我们会尽可能地利用那些NVMe闪存,因为我们正在推动高性能存储操作。

那么,客户何时会考虑运行融合模式呢?原因何在?实际上,归根结底是为了通过更好地利用大规模资源来推动经济效益。为了详细阐述这一点,我想先通过一个传统环境的例子来说明,然后讨论在云中使用WEKA的不同实现方式。
在传统模式下,如果在云中使用基于Lustre的解决方案,可以看到该架构的大致情况。同样,运行计算和应用程序(或模型训练)的环境是专用的,然后连接到Lustre存储环境。但Lustre存储环境是单独的基础设施。显然,通过紧密耦合,我们可以尽可能地接近并驱动高性能操作。Lustre解决方案在云中提供了非常好的性能。但如果查看定价表,我认为这里的关键在于资源效率和经济性。我记得上次查看时,云中的100TB Lustre环境大约需要花费72万美元。当然,如果用户有自己的EDP或储蓄计划,费用可能会更低。但以此为基准,我们对比一下,中间的WEKA环境也是100TB。但这是典型的传统WEKA,它在专用EC2实例上运行,部署在云中。对于那100TB的WEKA环境,大约只需支付一半的费用。这是总成本,当考虑WEKA软件加上驱动高性能数据的EC2实例以及客户可能想添加到后端的任何S3存储时。
这里我们讨论的是两种专用模式环境。现在,通过利用那些未充分利用的可用资源,可以看到使用WEKA软件的成本可以降低到大约10万美元。这样做的原因在于,这里不需要额外的基础设施。这完全是WEKA软件的客户所需支付的费用。或者,已经支付了EDP基础设施的费用,比如EC2实例等,这些支持着数据操作。这就是我们在云中实现大规模利用的方式。同时,这也是一种环保解决方案,因为无需部署额外的基础设施来支持数据操作。就像在P4和P5上实现极高的资源效率一样,这种方式在云中消耗更少的资源。
当然,融合模式并非适用于所有情况。但以下是一些指导原则。再次强调,关键在于大规模。如果正在构建一个拥有数百或数千个GPU加速实例的大型语言模型训练环境,那么这种方法将非常有益。我们提供了很好的定制方案,实现最佳的经济效益。用户将不得不在此进行一些复杂的权衡,因为在相同的资源上运行完整的高性能数据平台、应用程序和模型训练环境。存储的应用程序将具有不同的韧性模型、不同的故障域以及任何给定时间下的不同性能配置文件。每一方都需要了解并清楚知道他们可用的资源以及在任何给定时间下可以期望的性能。
只需巧妙地部署一个出色的作业调度器,如Slurm这样的资源编排工具,它就能处理资源分配和隔离。这些都是基础且必要的要求。对于大型环境,如果对作业调度和Slurm的一些操作复杂性表示满意,那么对于大型语言模型训练的大多数应用程序来说,这就是当前的理想状态。这些大型高性能环境正是其非常合适的应用场景。
我们希望WEKA能在各个应用程序与WEKA自身之间表现得像一个“好公民”。我们不希望应用程序直接访问支持WEKA存储平台的实例,因为这可能会开始影响系统稳定性。尽管工作本身具有一定的韧性,但我们不希望干扰其正常运行。因此,制定良好的变更控制政策、限制root访问权限并随时间管理这些操作是极其重要的。

WEKA融合模式的早期应用者之一是Stability AI。大多数人可能都熟悉Stability。他们是一家领先的开源生成式AI公司,是Stable Diffusion XL模型的创作者。如今,为了推动模型训练,Stability依赖于AWS上超过4000个GPU加速实例的集群,这些实例主要由NVIDIA A100 GPU提供动力。用于训练这些模型的数据集是2PB的闪存,他们预计在未来的几年中,随着从文本到视频、再到完整的3D成像的转变,这一数据量可能会超过10PB。当他们开始构建他们的环境时,他们使用的传统基于Lustre的存储架构遇到了我们之前提到的所有存储瓶颈,导致那些昂贵且难以找到的GPU的平均利用率仅为30%左右。他们曾尝试为过量配置Lustre集群存储系统,但遇到了规模限制。如今,Stability已经在AWS上部署了WEKA融合模式,覆盖了大约400台P5实例中的全部,以支持当前的数据环境。工作环境大约是2.5TB的闪存和5TB的对象存储。
这里的结果确实令人印象深刻。他们发现,WEKA能够在处理非常小和混合类型的文件时提供显著的性能提升,并推动GPU的使用效率。他们能够满足其模型训练的时间表和要求,并将GPU利用率从30%提高到80%以上。这是解决经济效益问题的关键。他们将数据基础设施的成本降低了60%以上,并将模型训练时间从几周缩短到几小时。

Source:Phil Curran; How the Right Data Architecture can Accelerate your Cloud-Based AI Initiatives; March 2024
--【本文完】---
近期受欢迎的文章:
更多交流,可添加本人微信
(请附姓名/单位/关注领域)

