




摘要
当前的数据中心架构沿袭多年,以服务器为主要构建单元,但这种传统模式面临着资源利用不足的挑战。原因在于应用程序部署时,为应对潜在的最坏情况,资源往往被过度分配。具体而言,服务器可能快速耗尽过量分配的内存资源,而其CPU资源却未能得到充分利用。
针对此问题,我们提出了一种新的资源管理思路:将资源解耦,而非紧密绑定至服务器。通过允许每种资源根据实际需求独立分配、利用和释放,我们旨在解决资源利用率低下的问题。新兴的高性能通信协议,如CXL,为资源解耦的实际应用提供了技术支撑。
基于以上分析,我们认为是时候重新审视整个数据中心架构了。本文提出了一种“分离式数据中心”(DDC,Disaggregated Datacenter)的概念,并借助成熟的计算机架构设计方法论对其进行了阐述。
前言
业界诸多数据中心运营商都报告了资源利用不足的情况。例如,AWS的CPU利用率极低,仅为7%到17%之间[1];谷歌数据中心报告的CPU利用率为28%到56%[2];阿里巴巴的数据中心在大部分时间内CPU利用率在20%到50%之间,同时伴随着80%到100%的内存利用率[3]。这些数据表明,当今数据中心普遍存在严重的资源利用不足问题。
这一问题的根源在于应用程序的部署方式以及它们共享服务器资源的方式。为了避免数据交换至硬盘,应用程序通常被分配了足以满足其最坏情况需求的内存。然而,这会导致CPU资源过剩,因为上述数据中通常没有足够的内存可供使用。此外,资源利用不足还会带来成本上的负面影响,增加数据中心的采购和运营成本。具体而言,部分资源成本被浪费,且即使在空闲时,这些资源仍会消耗电力。
针对资源利用不足的问题,一个自然的解决方案是彻底避免资源的紧密耦合。如果内存和CPU资源能够单独分配,不考虑服务器的界限,理论上就能精确地分配每种资源所需的数量,从而解决利用问题。这种资源的解耦将使数据中心从“以服务器为中心”转变为“以资源为中心”的模型,每种资源在逻辑上被独立地汇集和管理,不再受其它资源的限制。
在存储领域,这种资源解耦已经存在。数据中心通常拥有多个存储服务器,被多个客户端节点共享。在最新的研究中,也有学者探讨了内存解耦的类似概念,尽管这些提议主要基于直觉和临时方法,难以进行直接比较。
同样的思想在最近关于内存的研究中已经被探讨过,尽管这些提议主要依赖于直觉判断和非系统性的方法,这使得它们难以进行比较。
技术现状
资源解耦是当前数据中心领域的一个热门话题,其相关研究贡献丰富。我们最近对这些研究的分析揭示了不同提案和实现的广泛多样性。这些提案大多可以归类为两种主要的架构类型,如图1所示:
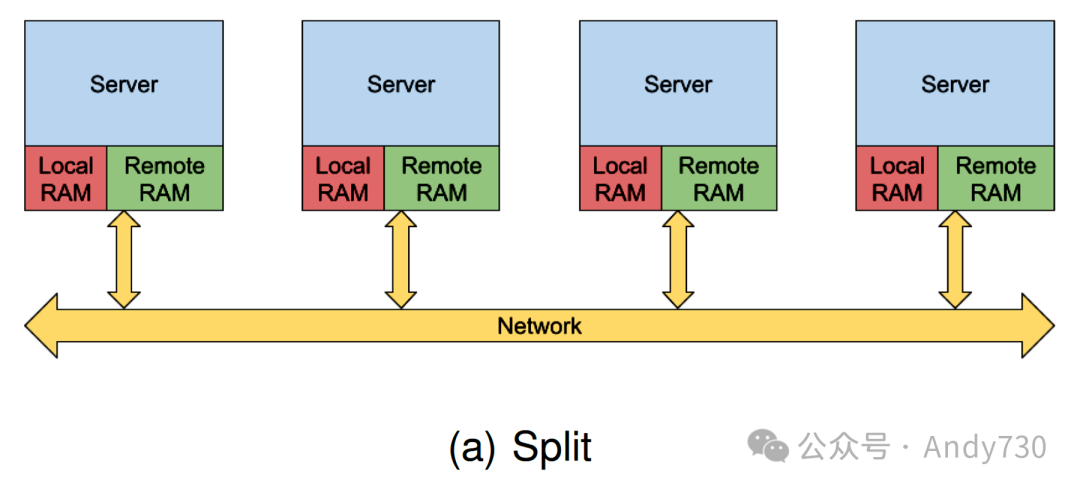
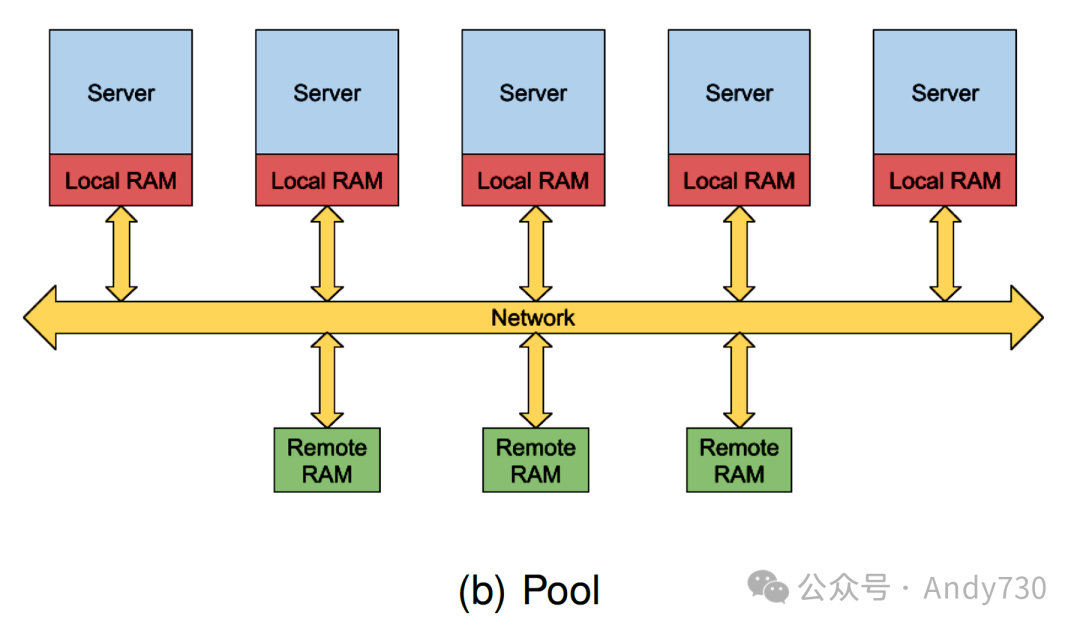 图1:内存解耦系统架构图(宏观层次)
图1:内存解耦系统架构图(宏观层次)
拆分架构(Split architecture):通常基于通用服务器构建。服务器资源被拆分,其中一部分资源专供本地服务器使用,而其余资源则被公开用于数据中心中的其它节点。这种架构的实现大多依赖于软件、虚拟化程序或操作系统。
池化架构(Pool architecture):在这种方案中,资源更为解耦且被集中管理。通常,这种架构的集群包含专用的内存节点和计算节点。计算节点仍然配备一定量的内存,可作为远程内存的缓存。这种架构的实现可以基于软件、虚拟化程序、操作系统,甚至硬件。
限制
尽管研究中考察的几乎所有提案都遵循上述两种常见架构之一,但它们的实现方式在多个细节上存在差异。研究还指出了现有技术的以下不足之处:
推断依据:许多研究缺乏的关键因素是对架构选择背后原理的充分阐述。大多数架构选择基于直觉判断、个人观点或实现便利性。这导致许多研究试图一步到位地实现完整功能的架构,而非采用分而治之的策略逐步解决这一高度复杂的问题。因此,大多数研究仅与未进行解耦的基准进行比较,而非与其它分离式提案进行对比。
设计与应用的简易性:以往的研究通常片面强调设计的简易性,而忽视了应用的难易程度。举例来说,许多研究聚焦于软件层面的实现,因为软件是最容易部署的,但这种方式却需要对现有应用进行修改甚至完全重写。相比之下,硬件层面的实现(如果能保持向后兼容性)在应用时反而更方便,但设计难度却更大。我们认为,由于大多数数据中心每隔三到五年左右就要进行升级([7]),因此硬件升级的成本本来就无法避免,所以硬件层面反而是更优的选择。
延迟:分离式系统的主要限制因素之一是延迟,其主要来源于两方面。第一是软件延迟,它是使用各种软件网络协议栈、在不同软件层之间切换(例如,从应用程序到容器再到操作系统)以及所有必需的故障处理和陷阱等造成的。这一部分延迟可以通过将实现层移得更接近硬件来降低。第二个主要因素是请求传输(request fabric)延迟。这一部分延迟是不可避免的,尽管可以通过仔细选择网络协议、拓扑结构和交换基础设施来加以改善。像CXL[4]和RIFL[5]这样一类新型的高吞吐量、低延迟网络协议的出现,有望大幅降低分离式系统的延迟
数据共享:大多数近期研究基本忽略了数据共享问题,因为支持数据共享和一致性可能会极大地增加系统设计的复杂性。事实上,据我们所知,允许在分离式内存中共享数据的潜在节省尚未得到充分研究或量化。然而,鉴于在典型数据中心中,应用程序可能部署在多个复制的实例上,这些实例在相同的数据集上运行,允许在分离式内存中共享数据可能会带来显著效益。
洞察:最大化现有成果的价值
在分离式数据中心(DDC)中,有五个核心组件,包括计算单元、内存、存储、互连网络以及管理层,用于管理和控制所有这些不同的组件。我们的出发点非常直接:它们与传统计算机的组件相似,尽管规模上有所不同,但两者之间有明显的相似之处。
数据中心中的计算节点可以视作数据中心的处理器,而远程内存则类似于任何计算机可用的本地DRAM。基于这种思考方式,分离式数据中心类似于传统的多核计算机,因此,计算机的设计理念同样适用于构建分离式数据中心。例如,在计算和内存节点之间引入缓存可能会非常有用,同时还可以利用类似于当今微处理器中的缓存一致性协议等技术。在这种情况下,内存解耦的额外层次成为计算机内存层次结构的自然扩展,如图2所示。
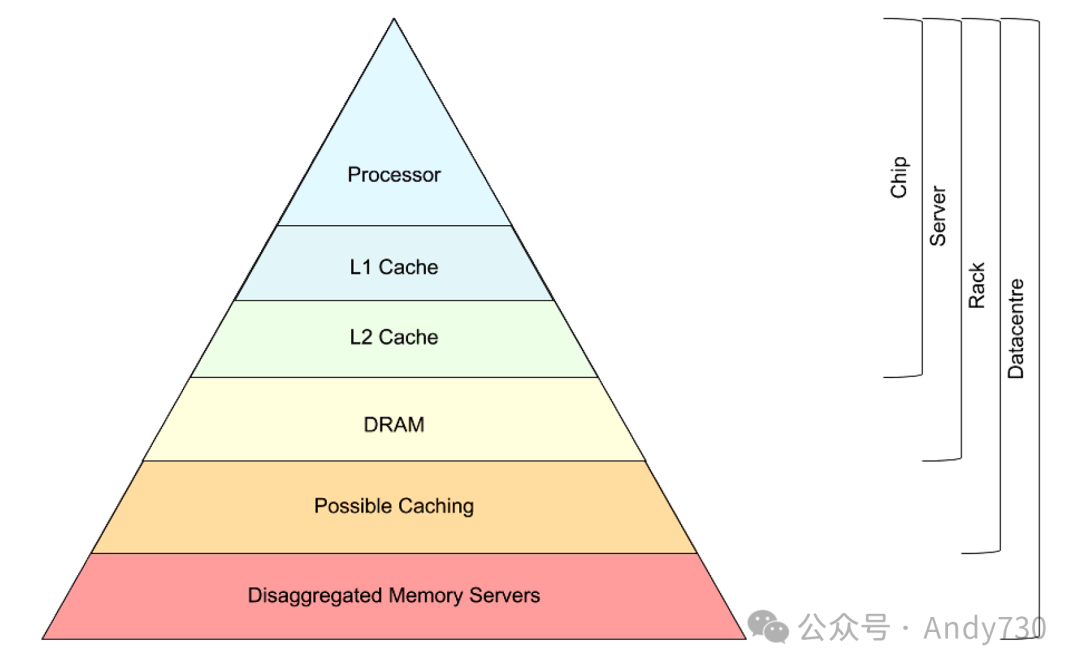 图2:数据中心中扩展的内存层次结构
图2:数据中心中扩展的内存层次结构
要使这种架构具有实际应用价值,必须满足以下要求:
应用的简易性:为了成功实现数据中心架构的根本变化,必须满足两个关键方面。首先,数据中心运行着各种应用程序,从图形处理、数据库、机器学习到科学计算等。重写所有这些应用程序以适应新架构几乎是不现实的。相反,新架构必须提供向后兼容性。其次,架构必须提供一个简单直接的编程模型,以便于开发新应用程序。基于我们之前的类比,成熟的基于线程的共享内存模型成为首选的编程模型。理论上,现有的多线程应用程序应能够在此类系统上继续运行而无需修改,尽管规模要大得多。
性能:现代微处理器设计旨在隐藏缓存未命中(cache misses)和长内存访问(long memory accesses)的延迟。然而,这种延迟掩盖技术的有效性是有限的,一旦性能出现下降,这一点就变得尤为关键。对于分离式数据中心而言,这一点尤为显著,因为大规模数据中心内存的层级结构和网络连接增加了额外的挑战,这要求实现更低的延迟和更高的带宽。
可扩展性:当今的数据中心具有可扩展性,意味着可以在数据中心持续运行的同时增加或减少更多的服务器。分离式数据中心也必须符合这一要求。然而,在分离式数据中心中,存在两种主要类型的可扩展性。第一种是水平可扩展性,通过增加或减少计算组件或内存组件来实现,确保数据中心持续稳定运行。第二种是垂直可扩展性,这是传统数据中心所不具备的能力。通过增加或减少内存层次结构的层次(如额外的缓存级别)来满足数据中心的需求,可以实现垂直可扩展性,这可能需要动态地重新定义网络互连。
容错性:传统数据中心中的节点故障是常见事件,必须得到妥善处理。此外,由于停电或其它原因造成的大规模故障也并不罕见。如果不支持或启用容错性,这些故障的结果将是灾难性的。同样,这些约束条件也适用于分离式数据中心。它必须具备主动支持容错性的能力,通过在非故障硬件上恢复应用程序并在可接受的延迟内实现,以及通过允许复制或数据持久性来被动对抗故障。
基于上述要求和约束条件,我们认为基于硬件的池化架构应成为分离式数据中心的首选架构。仅从性能要求来看,非基于硬件的实现可能会因延迟较高而被淘汰。此外,如上所述,基于硬件的实现扩展内存层次结构将支持共享内存、多线程模型,并进而支持向后兼容性。
此外,在“技术现状”部分讨论的一般架构中,只有池化架构(与拆分架构相反)能够更好地实现垂直和水平的可扩展性。值得注意的是,我们并没有完全排除拆分架构,因为它们可以被视为池化架构的特殊情况,其中本地内存部分类似于专有缓存,而所有远程内存部分仅形成一个NUMA(非一致性内存访问)结构。
因此,在本文的后续部分,我们将基于这种基于硬件的类似池的架构,从计算机架构的角度进行设计,并探讨设计其组件的潜在方法,以及研究人员需要关注的设计空间参数。
计算节点
在分离式数据中心(DDC)中,计算节点可以看作是现代服务器的精简版。计算节点将主要包含其处理器、本地DDR内存以及高速网络互连(如CXL接口),用于与远程内存进行交互,而不附带其它多余的外围设备。在此场景下,本地DDR内存不再担任主内存的角色,而是作为一个大型的基于DRAM的缓存层级存在。因此,所有围绕DDR内存的基本变化都将是对当前服务器架构的革新。例如,内存控制器将被重新设计,同时担任缓存控制器的角色,处理缓存替换、清除等操作。内存/缓存控制器还将通过网络接口与下一级缓存(如果存在)或远程内存进行连接。
鉴于我们的架构中计算节点的精简性,我们预计它们将采用紧凑的刀片服务器式服务器设计,可能允许多个这样的刀片服务器在背板式机箱中并排安装。计算刀片服务器的概念在之前的架构中已被提及[8],尽管是在不同的场景中。这种计算节点的架构不仅适用于CPU,还可能适用于GPU和其它加速器。
缓存
在我们设想的架构中,至少存在一级额外的缓存,即计算节点的本地DDR。是否需要额外的缓存层级取决于多种因素,包括本地DDR缓存的大小和参数、网络互连及其拓扑结构、分离式数据中心的规模等。设计这些新的缓存层级在原则上与设计微处理器缓存没有本质区别,只是规模更大。
除了计算刀片服务器外,我们设想在每个粒度层级上都设置一级缓存。例如,计算刀片服务器的背板可以包含一个在整个背板上共享的缓存刀片服务器。第二级缓存可能位于机架中,供机架内的计算背板共享,依此类推。这些缓存层级的放置取决于不同粒度计算资源之间的互连方式,以及缓存本身的大小、带宽等参数。无论缓存位于何处或与其连接的计算资源的粒度如何,所有这些缓存都将遵循相同的高级架构设计。缓存将由DDR内存组成,配备一个具有两个专用互连接口的内存控制器,一个向上连接(至计算刀片服务器)和一个向下连接(至额外的缓存或内存节点)。
关于缓存设计的许多细节目前尚不明确,例如如何划分内存以保存必要的元数据和目录、缓存行大小是否足够、缓存的替换、插入和逐出策略,以及缓存的组织方式(如关联性)。这些将是我们未来工作的重点。
一致性和缓存一致性(Consistency and Coherence)
由于我们致力于保持向后兼容性,我们架构的内存一致性模型将严格遵循计算节点处理器所使用的模型。例如,基于x86的系统应维持TSO(Total Store Order,完全存储定序)一致性模型,类似地,基于ARMv8的系统应维持RC(Release Consistency,释放一致性)模型等。
另一方面,缓存一致性机制可能需要重新设计。首先,显然基于窥探(snooping)的一致性机制不适用于分离式架构,因为它在扩展性方面存在局限。此外,它还需要大量的广播操作,这对于网络互连来说将是巨大的负担,而网络互连本身已是一种稀缺资源。因此,在我们的通用架构中,基于目录(directory)的一致性成为首选方案。至于一致性协议的具体实现,将留待未来进一步研究。
然而,基于目录的一致性并非没有缺陷。缓存未命中将导致向父目录发送请求,然后父目录会向一个或多个共享者发送一个请求,以使其数据无效或降级,然后一个共享者向原始请求者发送响应。这一系列操作意味着网络互连上更多的压力以及每个未命中带来的额外延迟。为了缓解这两个问题,先前的研究[10] [11] 提出利用交换机在网络互连中的中心位置,并使用可编程交换机来实现目录,从根本上减少这些延迟。虽然可编程交换机在内存资源上受限,可能会限制或影响实现的目录大小,但我们相信这种方法的扩展性能够支持更大的解决方案。
内存节点
在我们设想的架构中,内存节点是一种无主动处理组件的设备,即它们不包含CPU或其它主动处理单元。相反,它们将仅包括一个或多个DDR或HBM内存控制器,以及一个或多个与上层网络互连接口,以及必要的解码和切换逻辑来映射互连端口和内存控制器之间的关系。类似的内存刀片服务器的概念已在[9] [8]等文献中提出。作为一种优化措施,内存节点可以升级以支持一些计算单元,这些计算单元可以位于或非常靠近内存控制器,以支持近内存计算(Near-Memory Computing, NMC)的应用场景。从根本上讲,内存节点与当前服务器的传统主内存没有本质区别,主要区别在于它们位于不同层级的网络互连之后。
虚拟内存
在我们的讨论中,我们尚未涉及虚拟内存。当扩展内存层次结构以包含额外层级时,一种自然的倾向是相应地扩展虚拟内存基础设施(如TLB,Translation Lookaside Buffer,翻译后备缓冲器)及其层级。然而,这可能并非高效之举。页面错误发生时,会在每个TLB层级(通常,每个缓存层级都有一个TLB层级)中引发缺失,直至到达托管页面表的内存刀片服务器。更糟糕的是,在此阶段执行页面表遍历(在页面表中搜索条目)会导致访问远程内存的延迟,因为相关数据很可能不在缓存中。简而言之,如果不重新设计,即使是页面错误或TLB未命中这样不常发生的事件,也可能导致过长的延迟。
例如,可能的优化方案之一是将页面表遍历操作从处理器端(通常是实现此操作的地方)转移到托管页面表的内存节点,这样做较为简便。另一个思路是在每个计算节点的本地DRAM上托管“私有”页面表,这将减少页面错误时的遍历行程,使其与传统服务器的性能相当。还有一种方法是重新考虑在整个层次结构中使用基于虚拟地址的缓存(即根据数据的虚拟地址而非物理地址存储数据的缓存),尽管在基于虚拟地址的缓存中维护一致性更为困难,这使得它们在当今的第一级缓存之外的地方不受青睐。我们将这些和其它潜在解决方案的研究留待未来进行。
互连与网络
在分离式数据中心中,互连无疑是至关重要的组件。它不仅影响计算、缓存和内存刀片服务器的设计选择,还决定了解耦的程度,即分离式数据中心的规模。实际上,如果没有当今网络技术的进步,任何形式的解耦都是不可能实现的。
不幸的是,对于支持大规模解耦所需网络的带宽和延迟要求尚不明朗。先前的研究如[12]和[13]旨在探寻这些要求,但在收集此类数据的底层系统方面存在限制。我们认为是时候在更贴近实际条件的场景下重新审视这些要求了。未来的研究应当深入调查实现解耦所需的网络协议、拓扑结构和交换基础设施。这将有助于确定新兴网络协议如CXL [4]和RIFL [5]的可用性,并揭示未来网络研究的需求(如果需要的话)。
存储
当前,在传统数据中心中,唯一真正解耦的组件是存储。这种情况已经持续多年。通常,每个服务器都会有一定量的存储空间,但也会存在具有海量存储空间及冗余以实现容错性的存储服务器,这些服务器将被整个数据中心共享。这一模式已经很好地融入了我们的理念,在远程内存之上增加了内存层次结构的额外层级。
然而,分离式架构提供了一个独特的机会,考虑采用不同的存储架构可能会带来益处。换句话说,构建一个统一的存储和内存层次结构,或者说统一的易失性和持久性内存空间可能是一个值得探索的方向。尽管一些先前的研究[14]已经提出使用非易失性内存作为远程内存,但我们认为将之前讨论的内存刀片服务器设计为同时适用于存储的方式更加符合我们提出的架构。这样的统一内存--存储层次结构可以避免在存储和内存之间不必要地移动页面。相反,更频繁使用的页面可以驻留在速度更快的内存中,而较少访问的页面可以驻留在存储或非易失性内存中。
然而,仍有一个问题待解,即如何从用户的角度来看待这种统一内存。内存是按字节寻址的,而存储通常使用命名数据的方法(如目录和文件)。在统一的层次结构中,不清楚应采用什么方法来保持向后兼容性。我们将这些方面的探索和决策留待未来工作。
设计与原型制作
计算机架构和内存层次结构设计通常借助模拟器进行辅助,模拟器允许操作和探索不同的设计参数,以及测试新的/不同的架构或组织。由于我们迄今描述的组件与传统计算机的对应组件非常相似,我们建议也使用传统计算机架构模拟器来探索和设计内存分离式系统,尽管这些模拟器可能需要修改/扩展以适应如此大规模的系统。使用这种模拟器将为比较和评估不同设计提供标准化的方法,这在内存解耦领域是极为需要的。
通过利用商业可用的FPGA板,也可以对这些设计进行原型制作,其中许多板配备了两个100Gbps接口,以及适用于原型制作缓存、内存和存储节点的DDR4/HBM和NVMe。这种板的变种包括MPSoC FPGA(与CPU核心紧密耦合的FPGA),也适用于原型制作计算节点。事实上,FPGA甚至可用于最终实现,而不仅仅是原型制作,这将为利用它们的现场可编程性开辟有趣的途径,正如我们后续描述的那样。
管理层
图3展示了我们提出的架构示例。该架构包括不同类型的计算节点及其本地DRAM缓存。再下一层是一个或多个缓存刀片服务器,它们可以存在于不同级别的分组(如一个机架)中。我们架构的最后一部分是一组存储和内存刀片服务器,以及网卡,以便与外部环境进行通信。
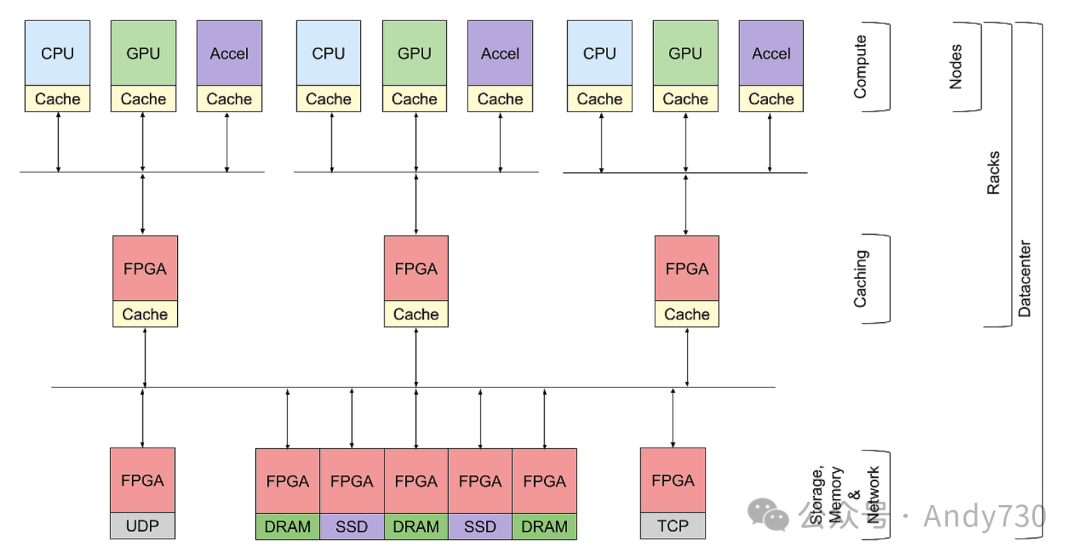 图3:我们提出的架构示例图。上层代表异构计算节点,其本地DRAM作为缓存层。中间层展示了基于FPGA的缓存的一个层级。底层则是混合远程内存/存储层,以及用于与外部接口的NIC。此图简化了互连网络,未详细展示拓扑结构和作为目录的交换基础设施。
图3:我们提出的架构示例图。上层代表异构计算节点,其本地DRAM作为缓存层。中间层展示了基于FPGA的缓存的一个层级。底层则是混合远程内存/存储层,以及用于与外部接口的NIC。此图简化了互连网络,未详细展示拓扑结构和作为目录的交换基础设施。
在我们构建的架构中,设计的最后一个关键组件是管理层。由于我们的系统与传统计算机系统的结构非常相似,理论上可以使用未经修改的操作系统,但这远非管理这些资源的最佳方式。我们认为对传统操作系统进行一些修改是必要的,而其它一些修改可能是有益的改进:
资源监控
在数据中心环境中,操作系统在启动时建立设备连接和内存映射列表是远远不够的。由于系统可能随时发生动态变化,包括内存和计算资源的增减,因此必须实施持续的资源监控和更新内存/资源列表。与传统计算机不同,数据中心中的操作系统必须能够预期并适应这种动态变化。
这种扩展性的需求源于多个方面。首先,数据中心运营商需要能够灵活地扩展或缩减资源以满足不断变化的工作负载需求。在不必要的情况下,部分资源可以被关闭或休眠,这对于功耗敏感的数据中心尤为关键。其次,数据中心需要能够快速响应设备故障,以最小化对业务运行的影响。这些故障可能发生在任何类型的资源上,且缓解措施需灵活多变,详细讨论将在后续研究中展开。然而,数据中心操作系统必须做好应对这些故障的准备。
为了解决这些问题,我们采用了类似LegoOS的设计思路。具体来说,一些计算节点将作为操作系统节点,这些节点也需要进行冗余设计以避免单点故障。每种类型的资源都将运行一个监视器(无论是在软件中还是在硬件中),这些监视器将定期向操作系统节点发送状态和使用统计信息。操作系统节点则负责处理所有应用程序部署、内存分配请求以及从硬件故障中恢复等任务,这些任务都基于定期收集的状态信息。为了减轻操作系统在微观级别执行任务的负担,如不必要的通信开销,操作系统应专注于宏观层面的部署和分配决策。例如,操作系统可能决定在某个特定的内存刀片服务器上分配内存,或在相邻的计算刀片服务器上部署某个应用程序。然而,具体的内存地址分配或线程关联等微观细节应由每个刀片服务器上的监视器处理。这种设计使得操作系统在资源分配上呈现出一种分层结构。
在内核中实施这些更改或应用这些修改后,操作系统的其余部分可以继续正常工作,将数据中心规模的计算机视为一个巨大的传统计算机。现有的调度、分配等算法可以保持不变,但它们在如此大规模环境下的适用性和性能优化将是未来工作的重点。
软件定义架构
随着FPGA技术的发展,如今它们配备了高达100Gbps甚至400Gbps的接口,使得FPGA不仅适用于原型设计,还可能完全实现数据中心的组件。这为数据中心带来了前所未有的可编程性优势。
具体来说,如果使用FPGA板构建高速缓存,那么这些缓存的特性和功能可以在运行时进行修改。例如,如果发现某种替换策略与特定类型的应用程序不匹配,我们可以立即升级为效果更佳的替换策略。更基础的变更也是可行的,如改变缓存的组织结构、关联性等。这些功能只能通过基于FPGA的实现来实现。在缓存的情况下(但不仅限于缓存),可能需要将缓存的状态和统计信息暴露给操作系统。
同样的概念也可以应用于更宏观的层面,即数据中心的互连网络。如果这些网络的交换设备是基于FPGA的或至少是可编程的交换机,那么我们就可以在运行时动态修改整个架构。可以动态地暴露或隐藏缓存层,FPGA刀片服务器的功能也可以完全修改,比如从缓存节点转变为内存节点,反之亦然。在这种情况下,除了计算刀片服务器之外,我们几乎可以拥有一个完全软件定义的内存层次结构。
结论
本文提出了一种自上而下的方法来设计分离式内存数据中心,旨在易于应用、保持向后兼容性和可扩展性。我们将数据中心视为一个单一的大规模计算机,并讨论了其组件的可能设计和管理方式。此外,我们还提出了一种研究方法,以促进对该领域的定量分析和比较。我们期望本文能为未来在该领域的研究提供启示。
Source:Mohammad Ewais, Paul Chow; DDC: A Vision for a Disaggregated Datacenter; 20 Feb 2024
Disaggregated:解耦的、分离式 Disaggregation:解耦、分离 Disaggregated Datacenter:分离式数据中心 Disaggregated system:分离式系统 Disaggregated memory:分离式内存 Memory disaggregation systems:内存解耦系统 Resource disaggregation:资源解耦 Split architecture:拆分架构 Pool architecture:池化架构
REFERENCES
1. H. Liu, “A Measurement Study of Server Utilization in Public Clouds,” in 2011 IEEE Ninth International Conference on Dependable, Autonomic and Secure Computing, Dec. 2011, pp. 435–442. 2. J. Patel et al., “Workload Estimation for Improving Resource Management Decisions in the Cloud,” in 2015 IEEE Twelfth International Symposium on Autonomous Decentralized Systems, Mar. 2015, pp. 25–32. 3. J. Guo et al., “Who limits the resource efficiency of my datacenter: an analysis of Alibaba datacenter traces,” in Proceedings of the International Symposium on Quality of Service, Phoenix, Arizona, Jun. 2019, pp. 1–10. 4. D. Sharma, S. Tavallaei, “Compute express link 2.0 white paper,” Tech. Rep., 2020. 5. Q. Shen, J. Zheng, and P. Chow, “RIFL: a reliable link layer network protocol for data center communication,” IEEE/OSA J. Opt. Commun. Networking, vol. 14, no. 3, p. 111, Mar. 2022. 6. M. Ewais and P. Chow, “Disaggregated Memory in the Datacenter: A Survey,” IEEE Access, vol. 11, pp.20688–20712, 2023. 7. H.-A. Ounifi et al., “Model-based Approach to Data Center Design and Power Usage Effectiveness Assessment,” Procedia Comput. Sci., vol. 141, pp. 143–150, Jan. 2018. 8. K. Katrinis et al., “Rack-scale disaggregated cloud data centers: The dReDBox project vision,” in 2016 Design, Automation & Test in Europe Conference & Exhibition (DATE), Mar. 2016, pp. 690–695. 9. K. Lim et al., “Disaggregated memory for expansion and sharing in blade servers,” Comput. Archit. News, vol. 37, no. 3, pp. 267–278, Jun. 2009. 10. Q. Wang, Y. Lu, E. Xu, J. Li, Y. Chen, and J.Shu, “Concordia: Distributed Shared Memory with InNetwork Cache Coherence,” in 19th USENIX Conference on File and Storage Technologies (FAST 21), 2021, pp. 277–292. 11. S. Lee et al., “MIND: In-Network Memory Management for Disaggregated Data Centers,” in Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles, Virtual Event, Germany, Oct. 2021, pp. 488–504. 12. S. Han et al., “Network support for resource disaggregation in next-generation datacenters,” in Proceedings of the Twelfth ACM Workshop on Hot Topics in Networks, College Park, Maryland, Nov. 2013, pp. 1–7. 13. P. X. Gao et al., “Network requirements for resource disaggregation,” in 12th USENIX symposium on operating systems design and implementation (OSDI 16), Nov. 2016, pp. 249–264. 14. Y. Shan et al., “Distributed shared persistent memory,” in Proceedings of the 2017 Symposium on Cloud Computing, Santa Clara, California, Sep. 2017, pp. 323–337. 15. Z. Mwaikambo et al., “Linux kernel hotplug CPU support,” in Linux Symposium, 2004, vol. 2, p. 2004. 16. Y. Shan et al., “LegoOS: A Disseminated, Distributed OS for Hardware Resource Disaggregation,” in 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), 2018, pp. 69–87.
--【本文完】---
近期受欢迎的文章:
更多交流,可添加本人微信
(请附姓名/单位/关注领域)

