




Alexander Booth, Asst Director of Research & Development, Texas Rangers Ali Ghodsi, Co-Founder and CEO, Databricks Bilal Aslam, Sr. Director of Product Management, Databricks Darshana Sivakumar, Staff Product Manager, Databricks Hannes Mühleisen, Creator of DuckDB, DuckDB Labs Matei Zaharia, Chief Technology Officer and Co-Founder, Databricks Reynold Xin, Chief Architect and Co-Founder, Databricks Ryan Blue, CEO, Tabular Tareef Kawaf, President, Posit Software, PBC Yejin Choi, Sr Research Director Commonsense AI, AI2, University of Washington Zeashan Pappa, Staff Product Manager, Databricks
Ali Ghodsi
对Tabular的收购,Tabular是由Apache Iceberg的原始创始人创办的一家公司。关于如何让Delta Lake和Apache Iceberg这两种格式更加融合,关于兼容性或互操作性,我们宣布了Unity的GA,将数据存储于Unity这一通用格式,用户将能同时享受这两种格式的优势。我们得到了这两个项目的所有原始创始人的支持,确保Unity能与这两个项目无缝对接。 关于Genie,许多公司致力于通用智能,这些模型在回答历史、数学等各类问题时表现突出。但我们更专注于数据智能。数据智能并非简单的通用智能,而是聚焦于用户数据、定制数据及组织的专有数据。我们追求的是以合理的成本并保护隐私的方式来实现这一目标。 复合AI系统以及昨天发布的代理框架,使用户能够构建属于自己的复合AI系统。 关于数据仓库的洞察,以及过去两年中性能的提升。具体来说,就BI工作负载而言,过去两年中,我们在BI上运行的并发工作负载上实现了73%的性能提升。 AI/BI是我们从头开始构建的项目,它融入了生成式AI的概念,彻底改变了当前的BI工作方式。
Yejin Choi
我今天将和大家分享一些看似不可能但实则可行的“可能性”。

去年,当被问及印度初创企业如何为印度打造基础模型时,Sam Altman曾表示这几乎是不可能的。在此,我想对印度初创企业说,不要因此放弃希望。事实上,类似的对话不仅可能发生在印度,也可能发生在美国的其他地方,任何大学或研究机构都有可能实现,而并不需要庞大的计算资源。

现在,我们面临一个挑战:如何以环保的方式“烹饪”你的小型语言模型,并确保它与真正的大模型一样“美味”。
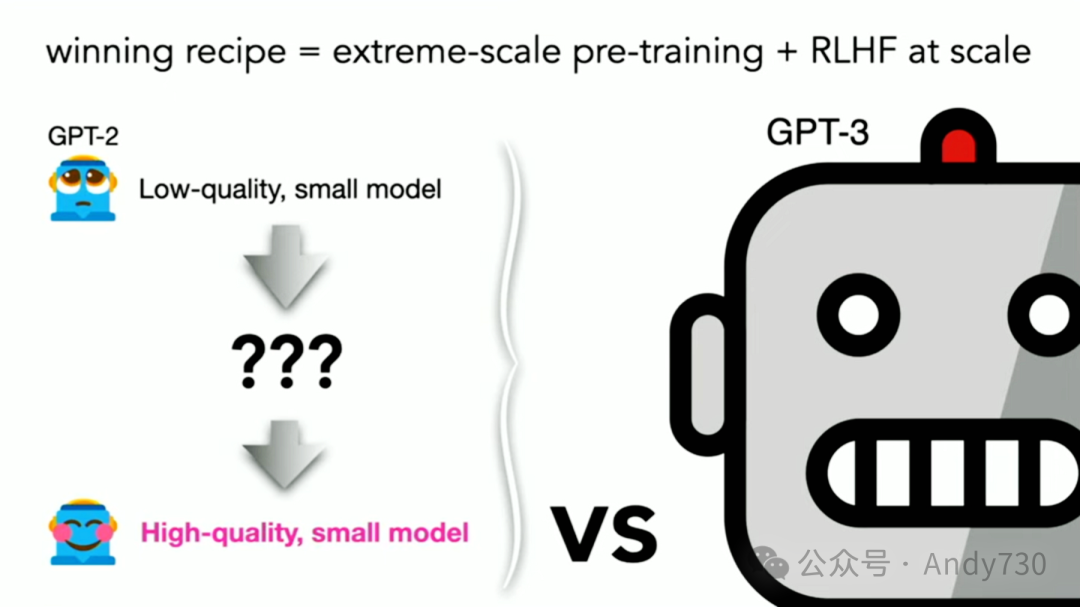
目前,成功的秘诀似乎在于大规模的预训练和后训练,如RLHF(Reinforcement Learning from Human Feedback)。但如果我告诉你,我打算从GPT-2开始,那个鲜少被提及的小而低质量的模型出发,你或许会觉得这有些不可思议。然而,我们将尝试创造或提炼出一个高质量的小模型,让它与那些可能强大两个数量级的模型竞争。

这听起来可能有些不现实,特别是当你可能已经听说过一些论文,它们声称模仿大型语言模型是一个虚假的承诺。

虽然这些论文对于特定的评估实验设置是真实的,但不要过于概括或过度解读,认为所有小语言模型都无法与大型模型相提并论。

实际上,有许多反例表明,任务特定的符号知识提炼可以在不同任务和领域中发挥作用,其中一些就来自我的实验室。

今天让我只专注于一个任务,那就是如何学会用语言进行抽象。

为了简化这一任务,我们将句子摘要作为我们在开源项目(OSS)中的首个挑战。我们的目标是在没有大规模预训练、没有RLHF以及没有大规模监督数据集的情况下实现这一目标,因为并非所有情况下这些资源都是可用的。但通常,我们至少需要这三种资源中的至少一种。那么,在没有这些资源的情况下,我们如何在与大型模型竞争时表现出色呢?
关键的直觉是,当前AI的好坏取决于其训练数据。我们必须有一些优势,不能毫无优势可言。因此,这种优势要来自数据。此外,我们必须合成数据,因为如果数据已经存在于互联网上,OpenAI肯定已经抓取过了。这对你来说并不是优势,他们也拥有这些数据。因此,你必须创造一些真正新颖、甚至更优质的东西。
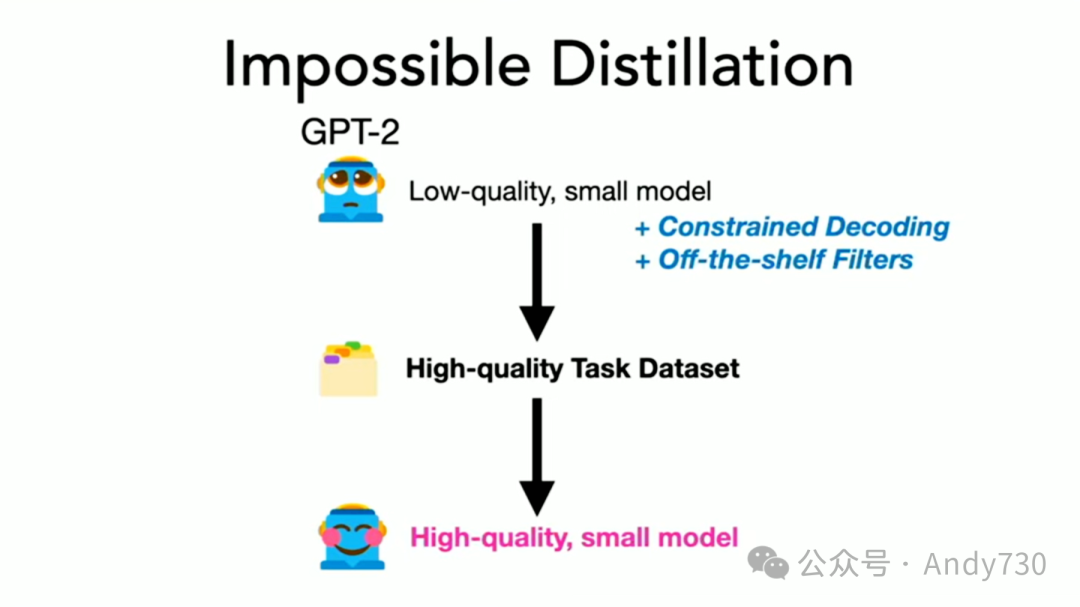
通常,提炼是从一个大模型开始的,但我们将摒弃这一传统思路,向你展示我们可能忽视的可能性。我将以GPT-2为例,这个相对低质量的模型,仅作为演示之用。接着,我将介绍一些创新方法,并简述如何制作一个高质量的数据集,用它来训练一个小模型,使其成为一个特定任务的强大工具。
唯一的问题是,GPT-2甚至无法理解你的提示。它无法进行提示工程。如果你使用GPT-2来总结句子,它可能会产生一些毫无意义的输出。但你可以再试一次,因为通常存在随机性。你可以尝试数百个不同的示例,但你会发现几乎总是不尽如人意,只有不到0.1%的结果是满意的。然而,要记得,有志者事竟成。
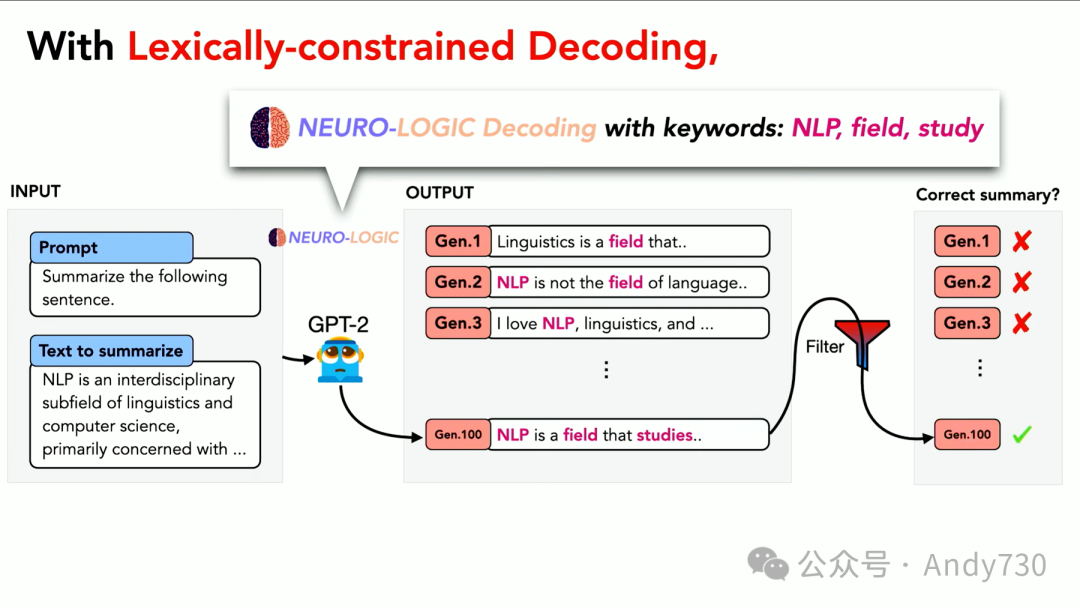
我们拥有多个不同的思路序列,其中就包括我们的“神经逻辑解码”(NeuroLogic Decoding)。这是一种即插即用的推理时间算法,能够将任何逻辑约束融入语言模型输出中,适用于任何现成的模型。我们可以将其嵌入并使用它来指导输出的语义空间。
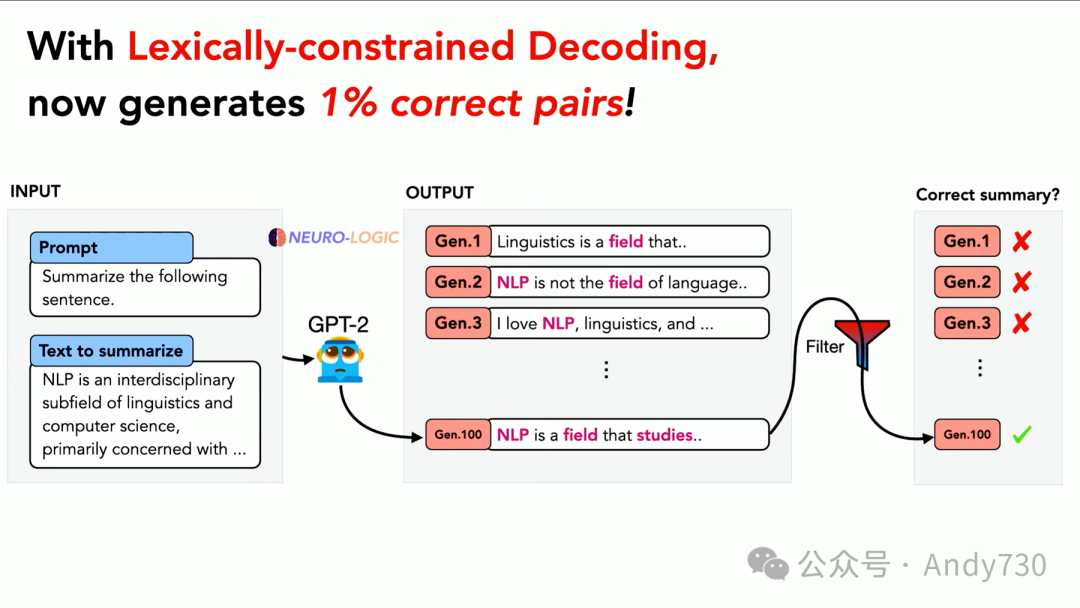
然而,由于GPT-2的表现并不理想,即使有了这个算法,成功率也仅约为1%。但这并不是零。
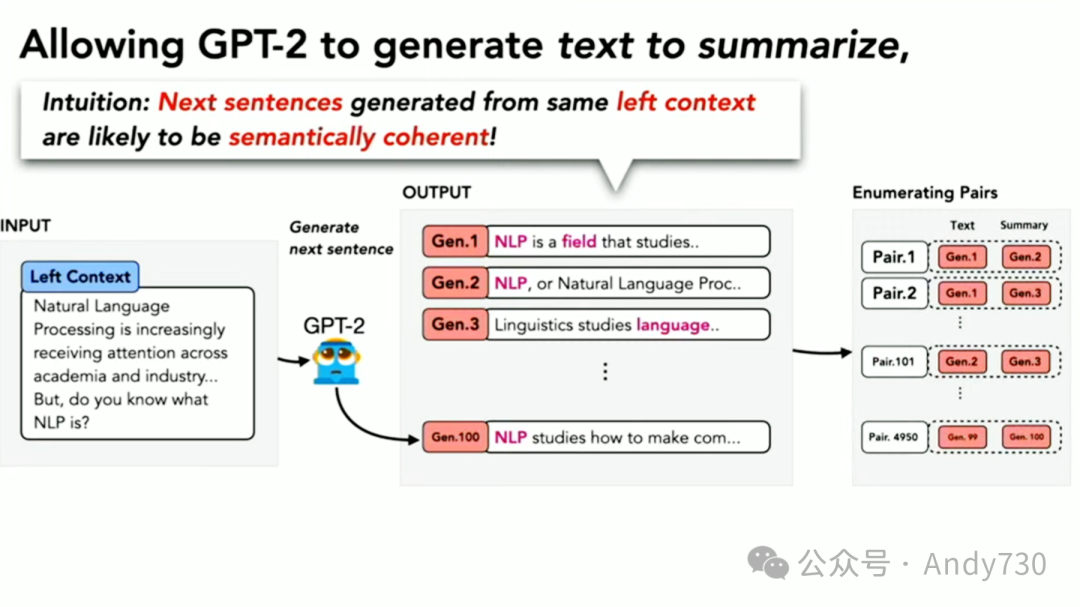
现在,我们正在取得一些进展,因为如果我们生成了大量的样本并进行筛选,实际上可以通过这种方式获得一些优质的例子。
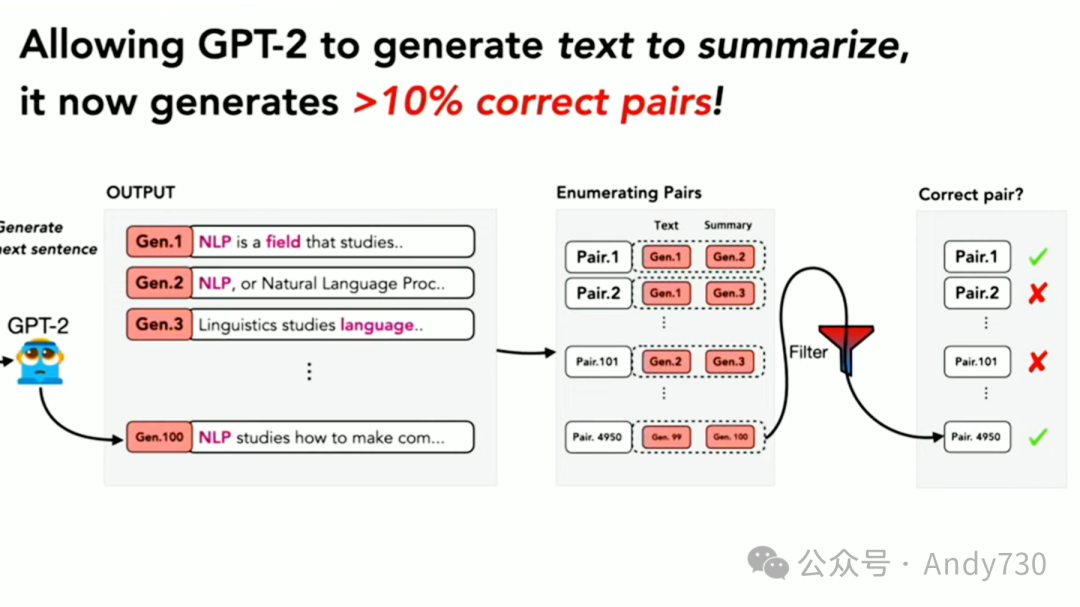
随后,我的聪明的学生们提出了许多不同的构想。我们已经找到了一些方法,将成功率提高到超过10%,这使得找到好的例子变得更加容易。
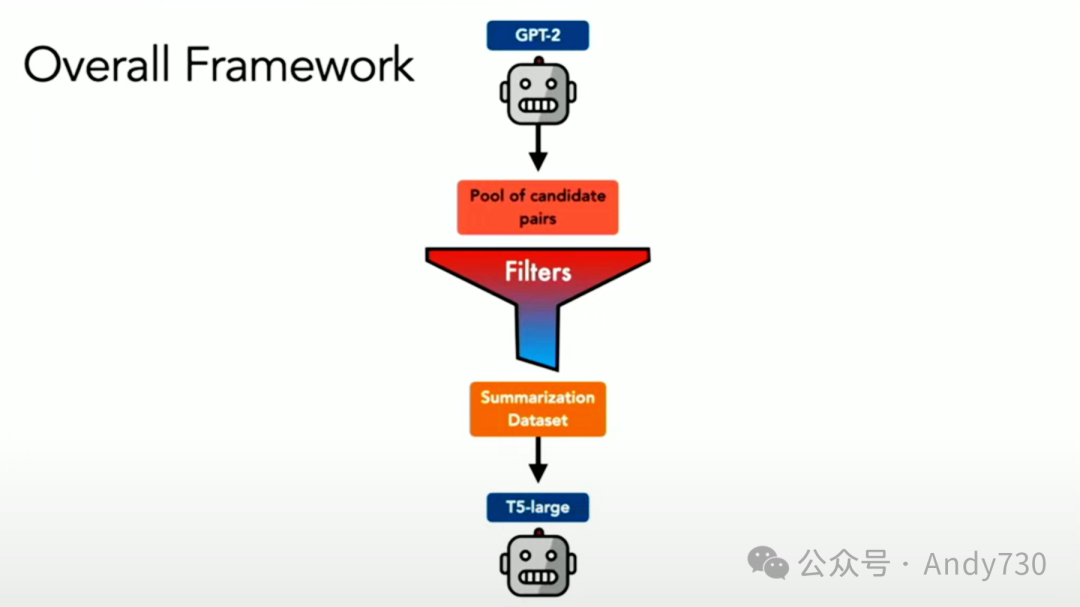
整体框架大致如下:从一个表现欠佳的教师模型开始,生成大量数据点。但由于数据中有很多噪音,必须进行严格的过滤。在这里,我们采用了一个三层过滤系统。
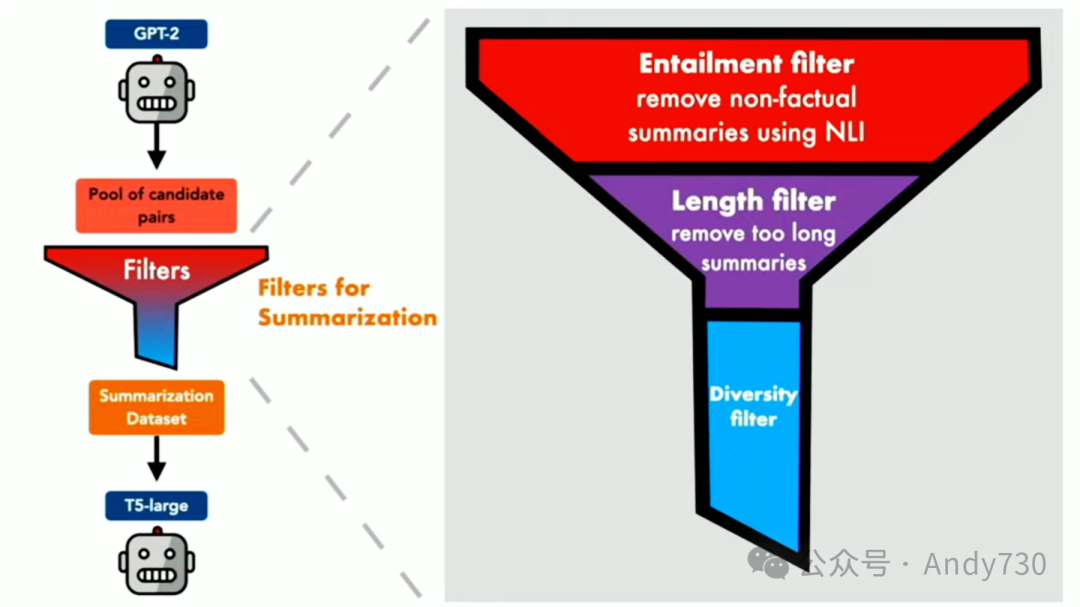
我想强调第一个过滤层:蕴涵过滤器(Entrailment filter)。它基于一个现成的蕴涵分类器,可以判断一个摘要是否从原始文本中逻辑蕴涵出来。尽管这个分类器并非完美,可能只有70%到80%的准确率,但在积极用它来过滤数据时,它已经足够好了。
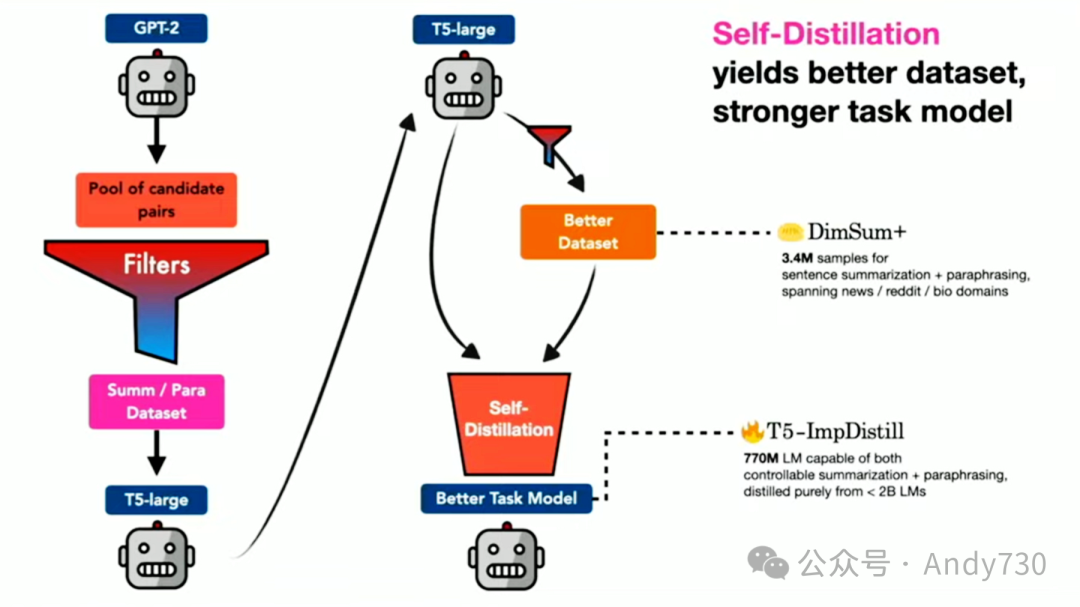
接下来,我们使用这些数据来训练更小的模型,这些模型将成为下一代学生的教师模型。
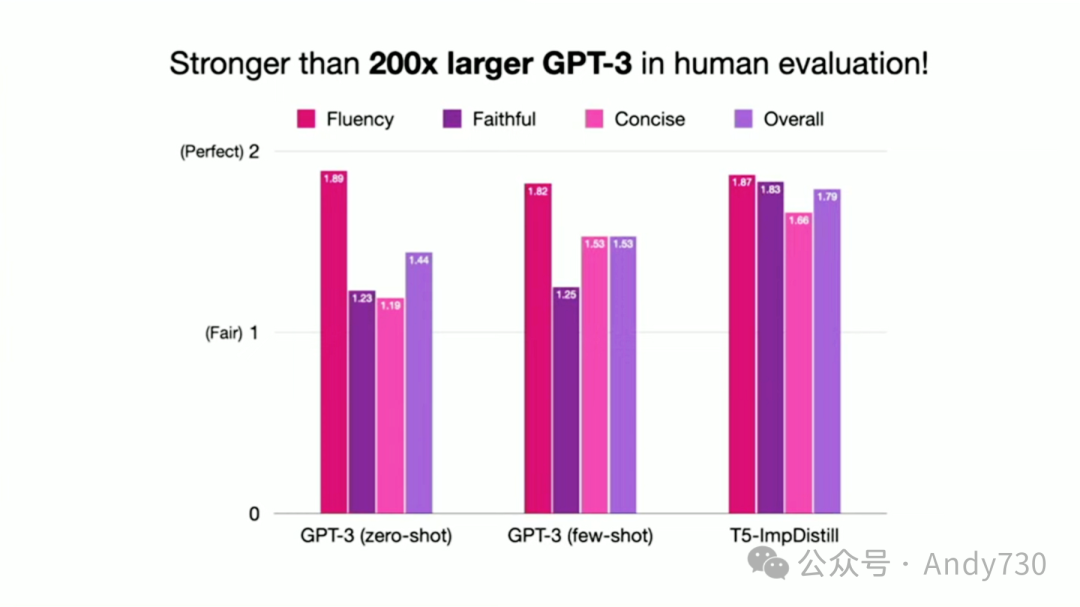
经过几次迭代,最终产生了高质量的提炼数据和模型。当我们将这种方法与当时最顶尖的模型GPT-3进行对比时(这实际上是在ChatGPT发布之前进行的),我们能够击败当时的最佳总结模型GPT-3。

但自从ChatGPT发布以来,它几乎无所不能,包括摘要功能。那么我们为什么还要费这么大劲呢?这里还有一个看似不可能完成的任务,现在我们要与ChatGPT-3.5一较高下。为了增加挑战的难度,我们不仅要摘要句子,还要摘要整个文档。而且,我们还要在不依赖那个现成的蕴涵分类器的情况下完成所有这些。我的意思是,其实你可以这么做,就像学术研究中,我们想看看能在多大程度上挑战关于规模的普遍假设。


我们在InfoSumm中的新工作采用了一种信息论提炼方法,其核心思想是,我们不再使用那个现成的蕴涵过滤系统,而是运用一些方程式。

这个方程式实际上只有三行条件概率分数,可以使用现成的语言模型进行计算。


我们就不深入探讨方程式的细节了。如果你重新排列这个方程式,可以将其解释为点间互信息的特殊情况,你可以用它来过滤你的数据。
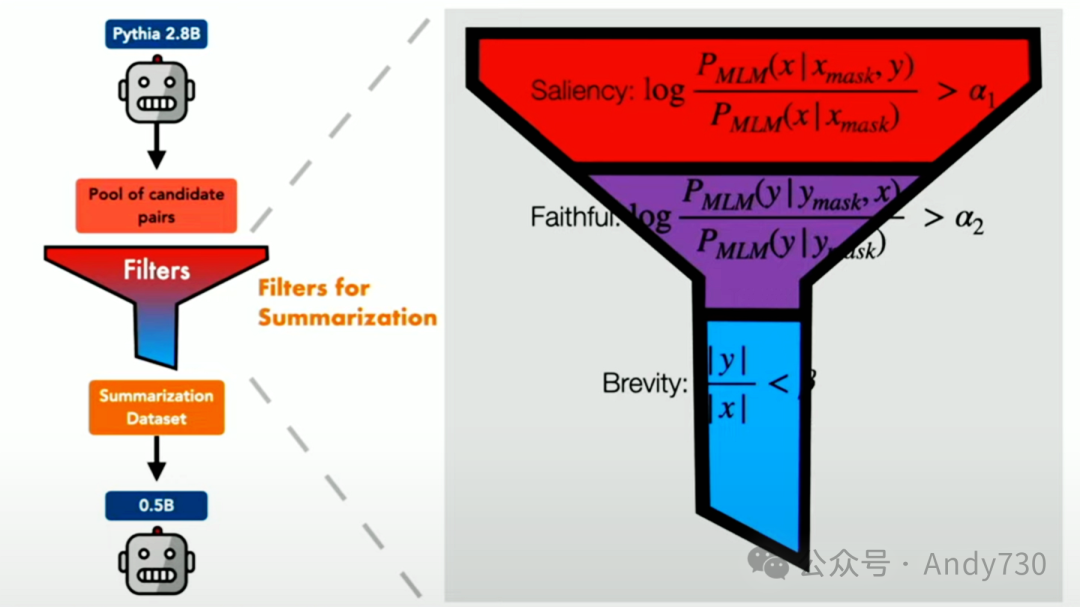
因此,我们沿用了之前的整体框架;现在我们使用的是Pythia 2.8B型,因为我们觉得它比GPT-2稍微好一些。在过滤方面,我们现在使用了之前提到的三个简短方程式。
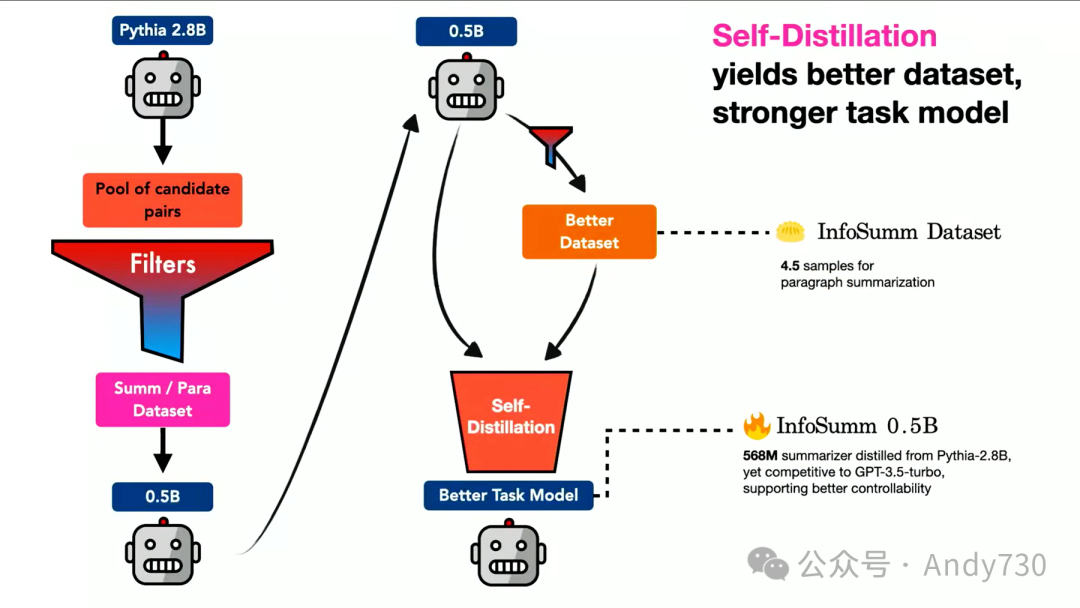
然后,我们进行同样的操作。不过这一次,我们使用的模型更小,只有5亿参数。这最终产生了高质量的摘要数据集以及模型。
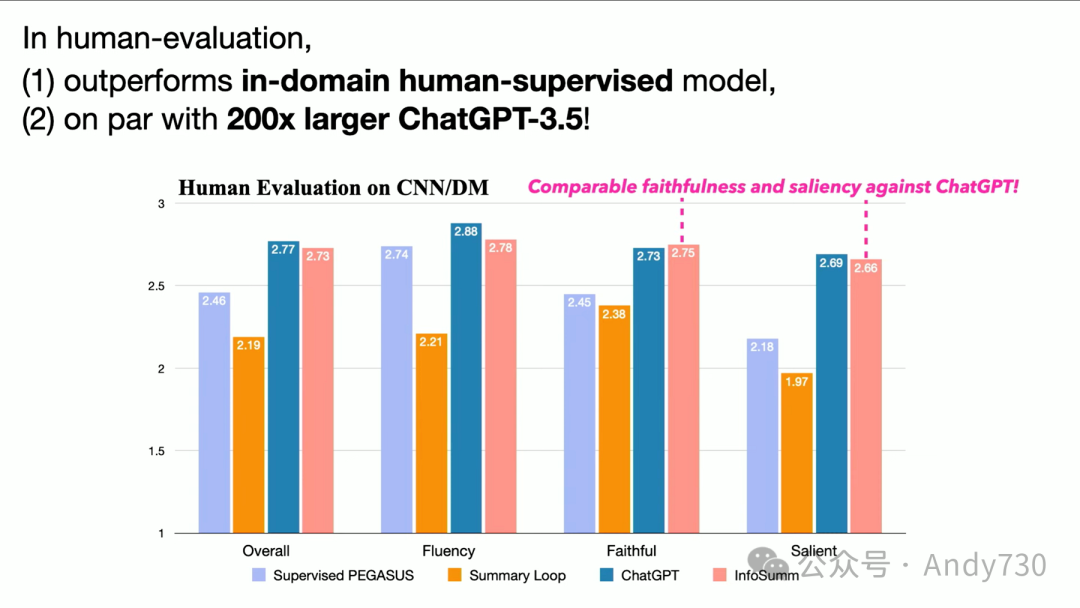
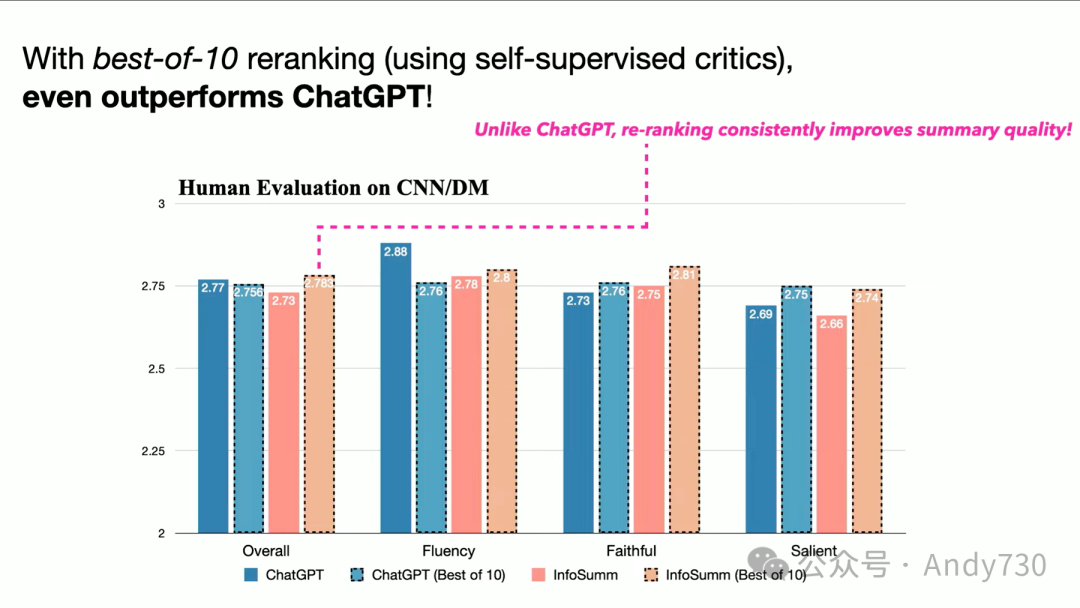
我们的成果如何呢?正如我们承诺的那样,至少对于这个任务来说,我们的表现要么与ChatGPT 3.5相当,要么更好,这取决于如何设置评估挑战和基准。大家可以在我们的论文中查看更多细节。

总之,我展示了我们是如何学会摘要文档的,而且并不依赖于极端规模的预训练模型和许多其他大规模操作。这两篇论文背后真正的研究问题是关于如何学会抽象,因为现在的做法只是让模型变得越来越大,越大越好。但是人类,你和我,实际上并不能真正记住所有的上下文,比如一百万个token。没有人能够记住一百万个上下文token。你只是瞬间地将我告诉你的一切抽象出来,但你仍然记得我到目前为止所说的内容。这是人类智能真正令人惊叹的地方,而我们还不知道如何通过AI模型有效地构建它。我相信这是可能的。我们只是还没有足够努力,因为我们被规模的魔力所迷惑。


最后,作为第三个看似不可能完成的任务,任务是让经典的统计n-gram语言模型在某种程度上与神经语言模型相关联。
在座的有多少人还在讨论n-gram模型?在这里,我们将n取为无穷大。我们将在数万亿个token上计算这个,并且响应时间应该是极快的,我们甚至不会在这上面使用单个GPU。让我告诉你这是多么困难。

假设,如果你要在经典的n-gram语言模型中索引五万亿个token,其中n等于无穷大,那么你大致上需要查找2400万亿个独特的n-gram序列,然后枚举、排序、计数和存储它们,这可能需要大约32PB的存储空间,甚至更多。但这太多了,我们无法做到。
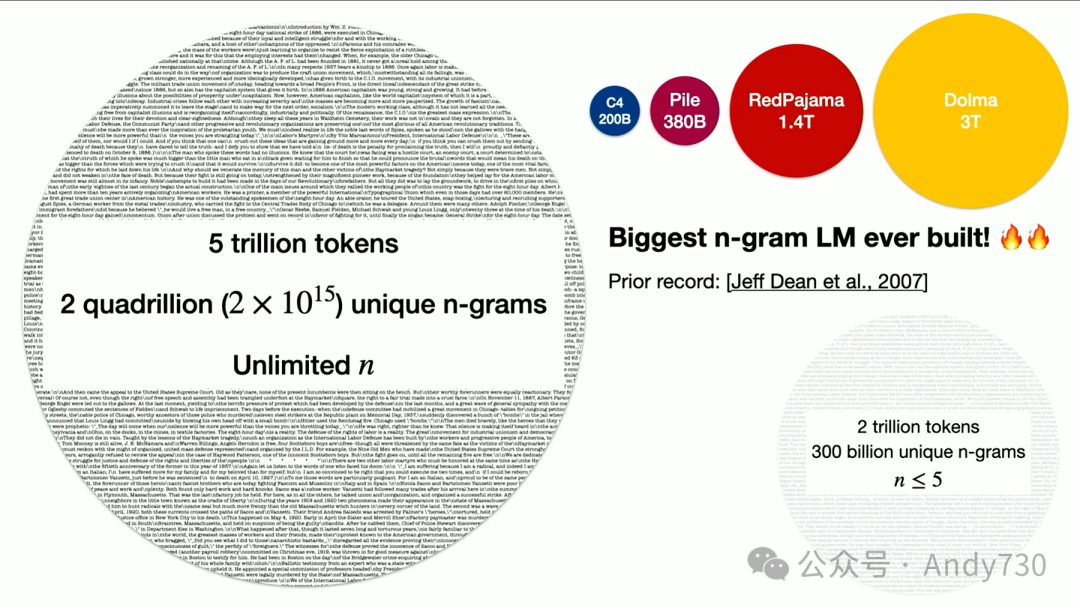
如果你看一下其他人曾经构建的大规模经典n-gram模型,那就是谷歌在2007年由Jeff Dean等人完成的,他们只扫描了两万亿个token。那时候的数据量已经非常庞大了,达到了五个n-gram,这已经给他们带来了大约3000亿个独特的n-gram序列,他们必须对其进行枚举、排序、计数等。因此,在那之后,很多人并没有做太多的扩展工作。那么,我们到底如何才能将这个扩展到无穷大呢?

在我揭示我们所做的工作之前,我邀请大家查看这个在线演示,如果有兴趣的话。可以搜索任何你想要的单词或短语。这里有一个示例,高亮显示了一个包含48个字符的单词。
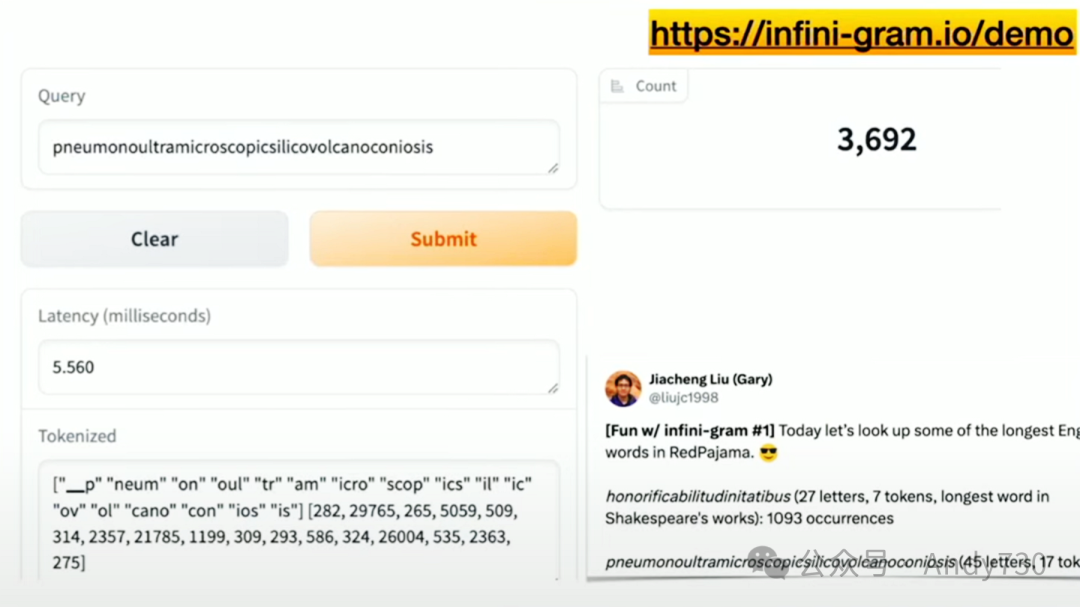
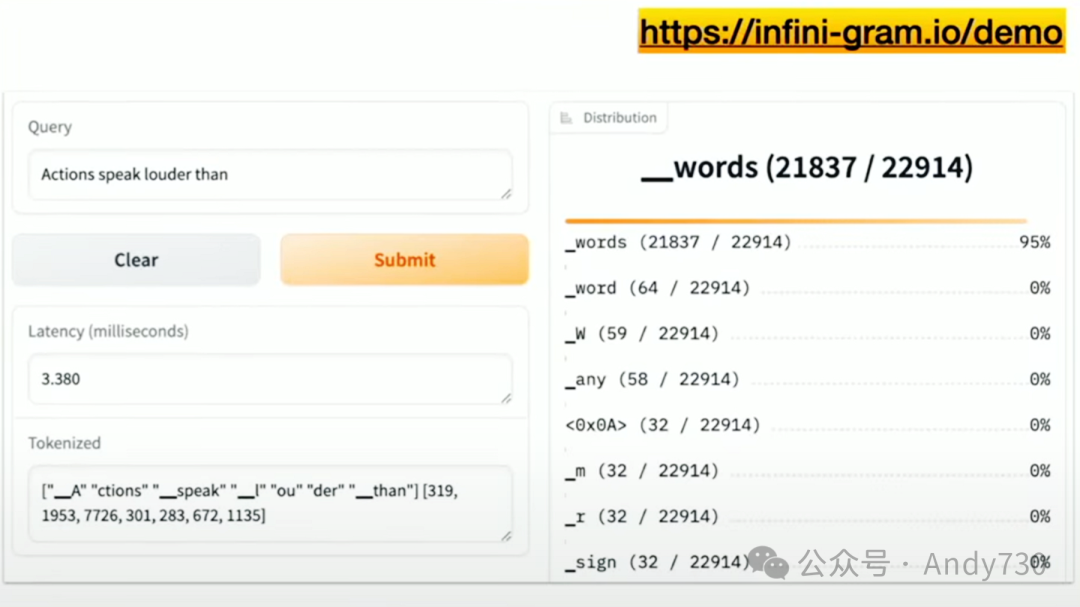
我不知道这个词为何存在,但它不仅存在,而且如果你搜索它,会发现有3000多个实例。它还显示了查询所需的时间,即5.5毫秒,并展示了如何对这个长单词进行分词处理。你也可以尝试搜索多个单词,查看后续的词是什么。例如,搜索“actions speak louder than what”,这将展示网页上接下来会出现什么词。同样,速度非常快。
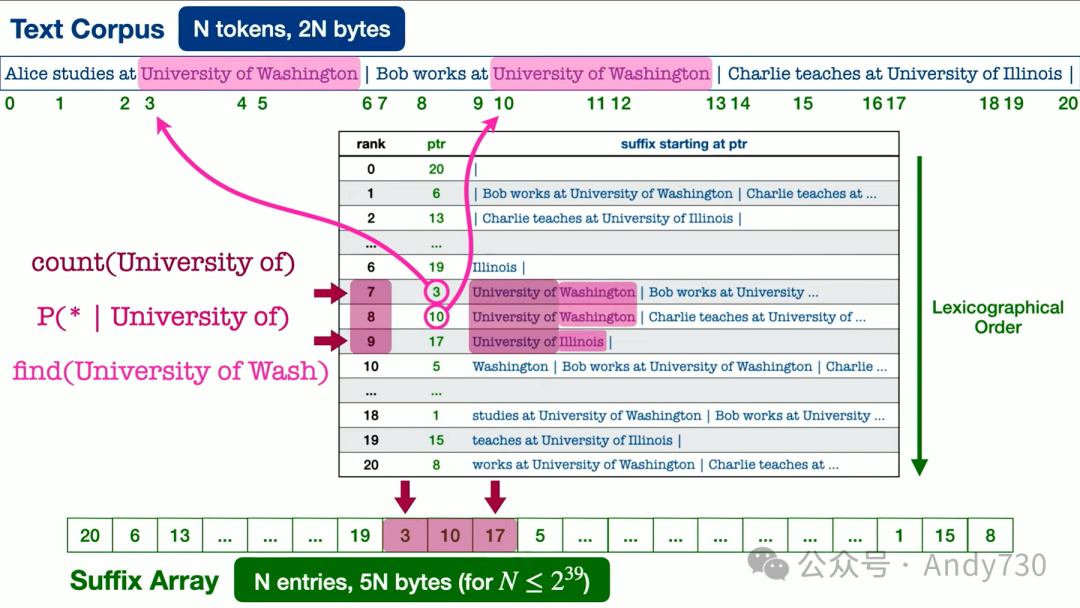
那么,我们具体做了什么呢?你可能会惊讶于这个想法的简洁性。有一种叫做后缀数组的数据结构,可能并非所有算法课程都会教授,但部分课程会涵盖。这是一个精心实现的数据结构。因此,我们使用这个后缀数组来索引整个网络语料库。事实上,我们并没有预先计算任何n-gram统计数据,我们只是准备好这个数据结构,当你进行特定的查询时,我们会实时计算。由于这个数据结构的特性,我们可以非常快速地完成这一过程,尤其是在使用C++语言实现时。我知道人们在涉及AI研究时通常不再使用C++,但实际上它在性能上表现得更出色。

成本如何呢?我们仅花费了几百美元来索引整个数据集,即使为API提供服务,你也可以用相对较低的成本完成,即使在没有GPU的情况下,速度也非常快。不同类型的API调用的延迟只有几十毫秒。你可以用这个API做很多事情。
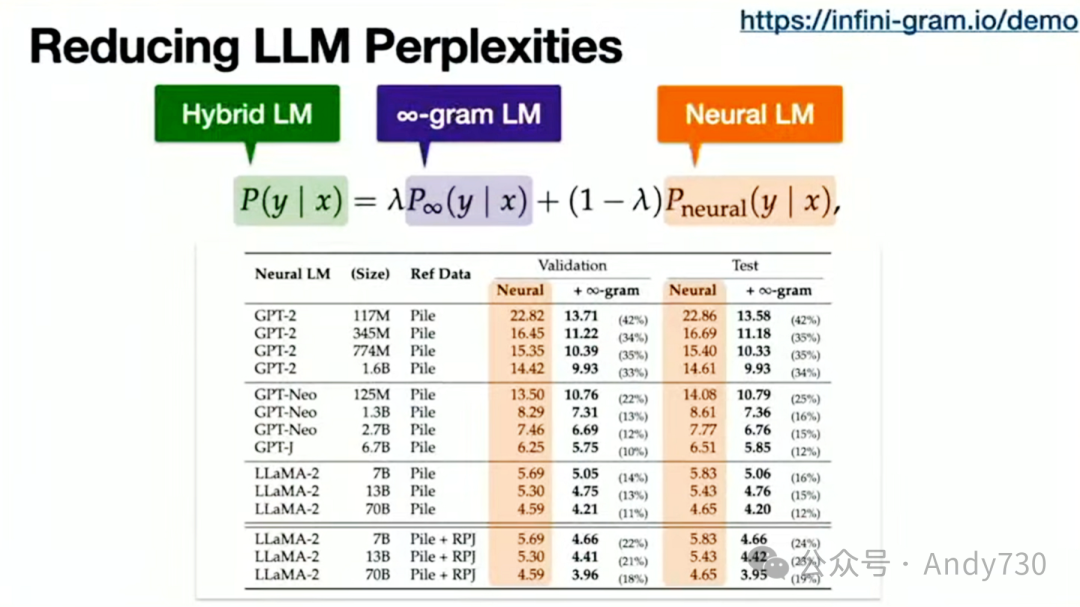
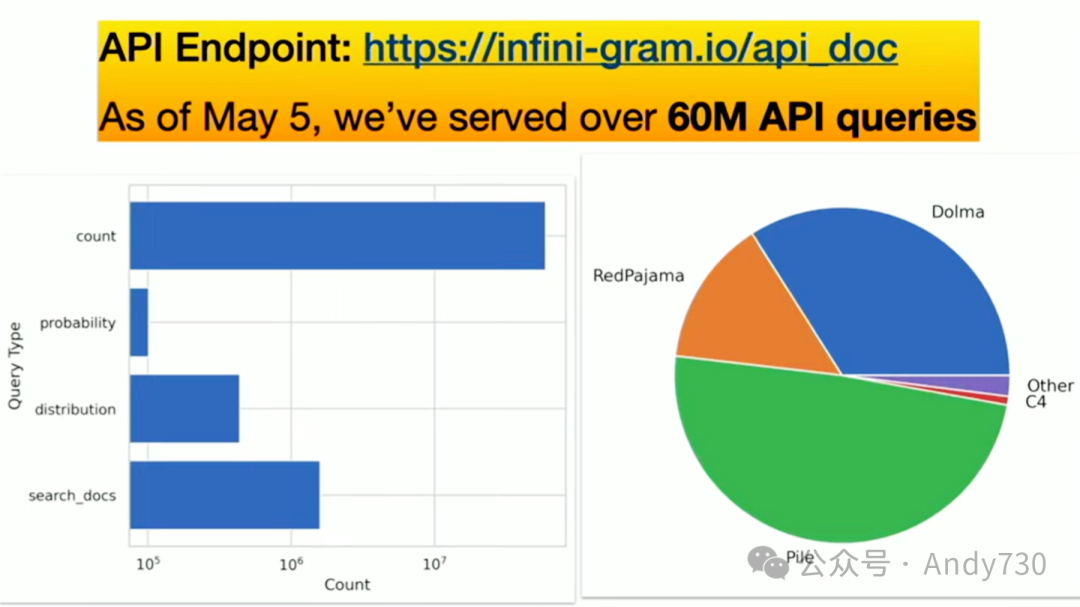
我现在可以分享的一件事是,你可以将我们的解决方案与你的神经语言模型结合使用,以降低困惑度,这是人们通常用来评估语言模型整体质量的指标。这只是我希望看到的冰山一角。实际上,我正在研究其他一些东西,但目前还不能分享。不过,我们几周前开始提供这个API端点,已经为6000万次API调用提供了服务,这还不包括我们自己的访问量。因此,我很好奇人们将如何使用我们的解决方案。
总结一下,我演讲的TL;DR(太长不看,请给摘要)是:

AI,至少在当前形式下,表现如何取决于它所接收的数据质量。

过去10年的AI通常主要依赖于人类生成的数据,但未来可能真的会依赖于AI生成的数据。我知道很多人对此表示担忧,可能认为其质量不高或存在偏见,因此不能简单地使用,而需要采用更创新的方法。但有许多证据表明这实际上是有效的。
Meta的SAM(Segment Anything Model)是图像分割上合成注释的一个例子,它借助了人类验证,但仅凭人类是无法完成这么多图像样本的注释工作的。另一个例子是Microsoft对大量不需要的教科书进行了处理。

同样,这是一个情况,当你拥有真正高质量的数据,如教科书质量的数据被合成时,你实际上可以在许多不同的任务上与更大规模的模型竞争。尽管在某些方面它可能不像更大的模型那样通用,但对于满足许多商业需求来说,这是令人惊奇的。你可能不需要通才,而需要的是专家。此外,教科书所强调的是,质量才是关键;不仅仅是数量,更重要的是质量。

Dalle-3模型就是一个例子。为什么它突然比Dalle-2模型表现更好?大部分原因是因为它使用了更好的标题(caption)。但这些更好的标题是怎么来的呢?先前的模型已经使用了所有好的标题。对,他们是通过合成这些标题来获得的。

这就是你获得高质量数据的方式。当然,你必须谨慎地做这件事,但有许多例子表明,包括我自己实验室的工作在内的任务特定符号知识提炼,都显示这实际上可以使较小的模型释放出隐藏的潜力。因此,这实际上关乎你数据的质量、新颖性和多样性,而不仅仅是数量。
Ali Ghodsi
加入Databricks的主要好处是什么?为什么要实现统一?
Ryan Blue
我从未想过要让用户担心格式问题。格式一直是我们作为一个平台承担更多责任的方式,也是从那些担心这些问题的人那里承担责任的方式。当我们开始时,人们担心的是数据操作是否具有原子性。因此,这一章节实际上是关于我们如何消除选择和担忧的,我是否为未来10年做出了正确选择?这对人们来说是一种沉重的负担,我认为我们只是希望确保一切都是兼容的,我们都朝着同一个标准的方向前进,如果可能的话。希望我们能实现这一点。
Ali Ghodsi
我相信我们会实现这一点的。你之前听过一个讲座,大概是这样说的:“我希望你们不需要了解Iceberg中的这些格式细节。”这是那个讲座的标题吗?
Ryan Blue
我不想让任何人去考虑表格式或文件格式等琐碎的事情。这些实际上是对人们在工作中真正想完成的事情的巨大干扰。我希望人们能够专注于从他们的数据中获得价值,而不是被这些琐事所困扰。这正是我作为一个技术狂热者所热衷的问题。就把这些琐事交给我们吧。
Ali Ghodsi
嘿,作为一个技术狂热者,我很喜欢这个观点。我认为这非常棒。我们让成千上万的人学会了如何进行数据资产交易,并理解了那些他们原本不会在意的基础知识。
每个人都对起源的故事感兴趣,所以你能给我们讲讲Iceberg是如何诞生的吗?它的历史是怎样的?
Ryan Blue
在Netflix,我们确实面临了许多不同的问题领域。其中,原子性就是一个大问题,我们对事务和数据的变化持怀疑态度。我们还遇到了诸如正确性等问题,比如无法正确地重命名列等。我们意识到,所有这些用户问题的根源都在于格式层面。我们的格式过于简单,只是Hive格式,所以我们决定采取行动。我认为真正的转折点其实是在我们开源Iceberg并开始与社区合作时,因为事实证明每个人都面临这个问题,与社区合作能让我们更快地解决。这是一次令人惊叹的经历。
Ali Ghodsi
在那之前,你参与了Parquet项目的启动,是吗?在那里是否也讨论过这种原子性等问题?
Ryan Blue
这确实是我参与Parquet项目时的一部分经验,它影响了我们在这里所做的工作。因为有几件事情不仅仅是文件级别的问题,而是涉及表级别的更深层次问题,比如一个表的当前模式是什么。你不能仅仅通过查看所有文件来确定这一点。是的,很多人可能认为这是我们第一次讨论这些问题,但实际上并不是。我们多年来一直在讨论这个问题。我很高兴我们终于找到了一个令人信服的解决方案。我认为我们以前总是各自为战,但现在我们已经到了一个阶段,两种格式都足够成熟,我们实际上在重复努力,最合理的做法就是开始合作,尽量避免两者之间的重复。
Ali Ghodsi
我想这里很多人都在想,这对Apache Iceberg社区意味着什么?
Ryan Blue
嗯,我感到非常兴奋,因为我认为这是对Iceberg社区的一个巨大承诺和相当大的投资,也是对Delta Lake和Iceberg整体生态健康的积极贡献。我个人非常热衷于参与这个过程,并解决一系列有趣的工程问题。
Ali Ghodsi
很高兴与你合作,共同推动Delta、Uniform、Iceberg等所有这些格式的发展,让人们再也不必关心这些格式的问题了。
Shant Hovsepian

首先,Delta Lake现在要宣布Delta Lake Uniform的GA。
Uniform是什么呢?实际上,它是两个词的缩写:通用格式。这是我们实现完全Lakehouse格式互操作性的方式。对于Delta、Iceberg、Hudi等这些不同的格式,它们本质上都是基于Parquet的数据文件集合,以及一些附加的元数据。所有这些格式都使用相同的MVCC事务技术来确保数据的一致性。
我们想,既然LLMs已经改变了语言处理的格局,我们是否也能找到一种方法,将这些元数据转换为不同的格式,这样你只需要保存一个数据副本?

这正是我们正在通过Uniform实现的目标。Uniform GA支持将数据写入Delta格式,然后以Iceberg、Hudi等格式读取。我们与Apache Iceberg和Hudi团队紧密合作,使这成为可能,并将继续与Iceberg团队合作,以进一步完善它。Uniform的一个主要优点是几乎没有明显的性能开销,速度非常快。用户将获得出色的功能,如Liquid Clustering。它支持各种不同的数据类型,包括映射、列表、数组,最重要的是,它具有生产就绪的目录支持。通过Uniform,它是Iceberg REST目录API使用的唯一实时实现之一,对所有使用Uniform的用户都适用。

已经有超过4EB的数据通过Uniform加载。我们有数百个客户正在使用它,其中一个客户,特别是M Science,正如你在这里所看到的,他们非常高兴能够只保存一份数据副本,这降低了他们的成本并获得了更好的价值。

正是像Uniform这样的创新,真正使Delta Lake成为了最受欢迎的开源Lakehouse格式。昨天,Delta上已经处理了超过9EB的数据,每年有超过十亿个集群在使用它,这是一个巨大的增长,比去年增长了2倍。
如果你和我一样,当看到这些数字时,我简直不敢相信有9EB的数据量。直到昨天,我们还在反复检查代码,确保这些数字计算无误,因为每天流入Delta的数据量实在是太大了。Delta已经被大多数财富500强公司应用,并在生产环境中被超过1万家公司使用。
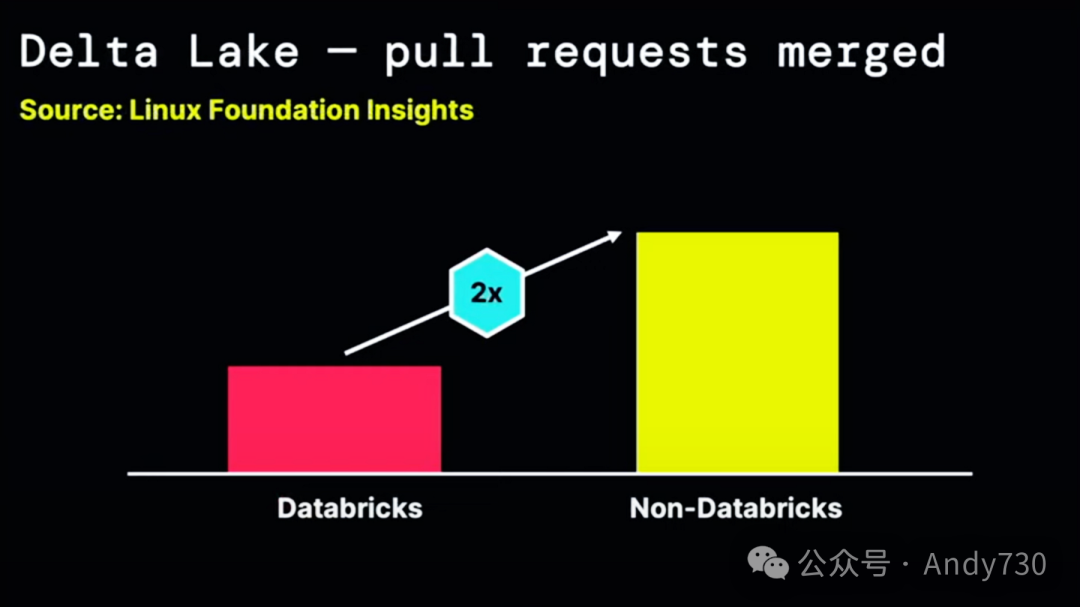
Delta拥有众多新功能,但最引人注目的数字是,超过500位贡献者。值得一提的是,根据Linux基金会的项目分析网站,大约66%的Delta贡献来自Databricks之外的公司。

正是这个活跃的社区让我们倍感兴奋,并帮助我们实现了大量如今已经投入使用的创新功能。这些功能都经过了时间的考验,非常令人赞叹,比如Change data feed、Log conpactions等。我特别喜欢最近推出的Row IDs功能。此外,Delta还引入了删除向量这一功能。删除向量允许你快速更新数据并进行DML操作。在很多情况下,它比合并操作快10倍。

如果你有大量的数据转换(DBT)工作负载或正在对数据进行大量操作更改,删除向量将大大简化你的工作。由于这些删除向量功能,我们已经节省了超过100万亿行的数据重写操作。对于所有Databricks用户,这一功能已经默认启用。
正是通过这些功能,我们还能够解锁访问支持Delta的丰富工具生态系统。而现在,随着Uniform GA的发布,我们也能够获得与Hudi和Iceberg生态系统相同的访问权限。因此,如果你有工具和有趣的SDK、应用程序,它们现在都是Delta家族的一部分,这都要归功于Uniform。在连接器方面,Trino Rust连接器有了显著的改进。这里正在发生许多令人赞叹的创新。
这些创新在很大程度上要归功于我们开发的新组件——Delta Kernel。实际上,Delta Kernel是一个小型库,你可以将其直接集成到你的应用程序或SDK中。它包含了Delta格式的所有逻辑、版本更改和新功能。这使得人们更容易集成和采用Delta,并且最重要的是,能够保持与最新功能的同步。
我们已经看到了这一点。Delta Rust连接器在社区的支持下取得了惊人的进展。就在几周前,在谷歌的I/O大会上,BigQuery宣布了对Delta的全面支持。最近,DuckDB也为Delta添加了全面支持。
最棒的是,我们有幸邀请到Hannes Mühleisen,他是DuckDB的联合创始人之一,DuckDB Labs的首席执行官,也是计算机科学教授,他将为我们介绍他们如何将Delta集成到DuckDB中。
Hannes Mühleisen
正如Shanta所说,我是DuckDB背后的核心成员之一。
DuckDB是什么?它是一个小巧但功能强大的分析数据管理系统。它支持SQL,无需任何外部依赖。
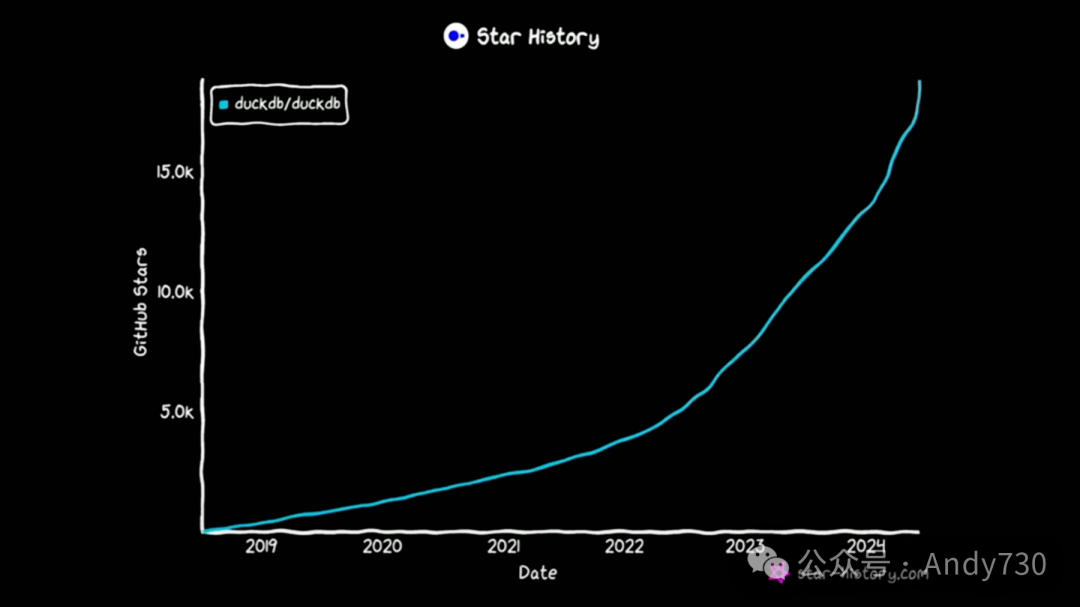
去年,我第一次在这个舞台上谈到了DuckDB,那真是个激动人心的时刻。但自那时起,DuckDB的发展取得了长足的进步。DuckDB的采用量增长惊人。我们见证了许多令人难以置信的事情。例如,GitHub上的星星数量在一年内翻了一番,几乎达到了2万。实际上,我们距离2万的目标只有一步之遥,所以如果你今天愿意点赞,我们或许就能达到这个目标。
而就在上周,我们实际上发布了DuckDB 1.0版本。这对我们来说是一个重要的里程碑。这是我们六年来在数据管理系统研发方面的结晶。DuckDB 1.0版本意味着什么?它表明我们现在拥有了一个稳定的SQL语言和各种API。最重要的是,从这一刻起,我们的DuckDB存储格式将保持向后兼容。

让我们稍微后退一步,看看DuckDB是如何融入整个生态系统的。如果我们看看世界上最广泛使用的数据工具Excel,再对比一个功能强大的系统如Spark,它们之间仍然存在相当大的差距。有很多数据集在Excel中无法使用,但可能又太小,无法真正利用Spark。因此,DuckDB真正适用于数据分析的最后一英里,在这里,你可能不需要整个数据中心来计算某些东西。
例如,你可能已经在Spark中处理了日志文件,现在是时候使用DuckDB进行一些最后一英里的分析,制作一些图表等。这就是DuckDB在这个大局中所扮演的角色。但现在,我们必须以某种方式将数据从Spark传输到DuckDB。那么我们应该怎么做呢?
显然,我们会选择现有的最适合的工具,CSV可能不是最佳选择。

通常,大家使用Parquet文件来完成这一任务。显然,Spark和DuckDB都可以读写Parquet文件,所以这种方法非常有效。

我们都听说过更新和模式演变等问题,这也是Lakehouse格式出现的原因。今天,我们正式宣布支持Delta Lake的DuckDB,这将是全面支持,无需任何额外配置。但值得一提的是,我们已经完成了多个类似的集成,而Delta Lake集成的特别之处在于,我们采用了Databricks与社区共同开发的Delta Kernel。它意味着我们无需像过去那样从头开始构建,比如像Parquet reader那样。实际上,我们可以将很多读取Delta文件的复杂工作交给Delta Kernel处理,同时在引擎内部保持我们的运算符等组件。
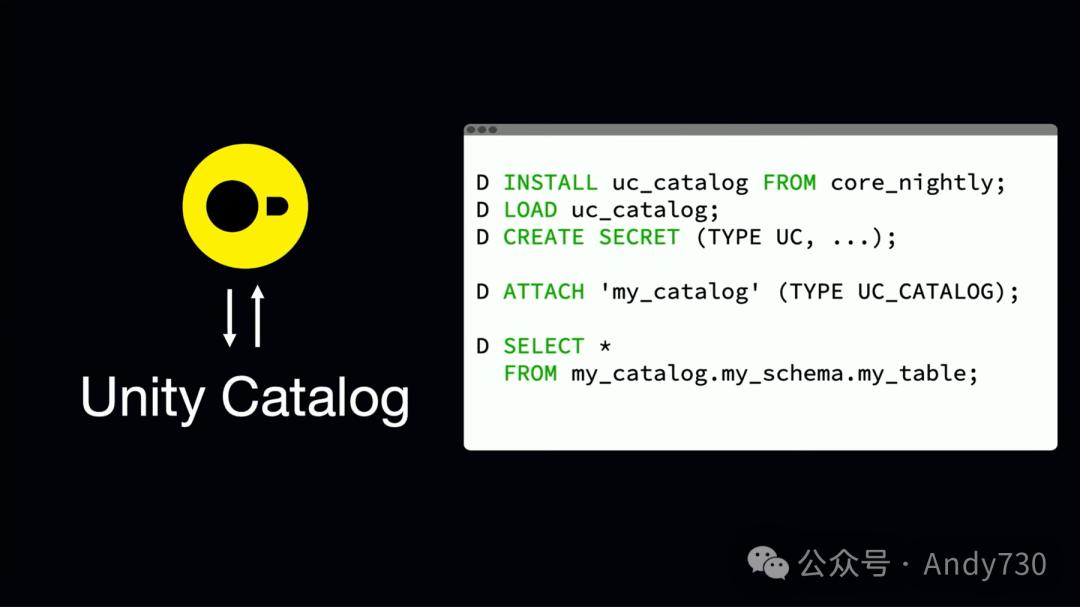
此外,我们还为DuckDB开发了一个扩展,可以与Unity目录进行通信。有了这个扩展,我们可以在目录中轻松找到Delta Lake表,并通过DuckDB直接与之交互。因此,你可以看到这个脚本,如果你现在安装DuckDB,它实际上是可以直接运行的。你可以安装这个Unity目录扩展,创建你的密钥(就像凭据一样),然后你就可以像读取本地表一样读取这些表了。

Delta扩展已经加入DuckDB不断增长的扩展列表中。例如,还有其他用于Iceberg、Vector搜索、空间等功能的扩展。作为一个开源项目和小团队,我们对Tabular和Databricks让Delta Lake和Iceberg更加紧密地联系在一起感到非常兴奋。对我们来说,这意味着我们不必为同一个问题维护两个不同的工具。这减少了我们的工作量,我相信每个人都会从中受益。

我要宣布一件小事,我们今天实际上正在推出这个新功能。我之前提到了DuckDB的扩展,现在我们已经看到了DuckDB扩展的大量增长。从现在起,我们将推出社区扩展,这意味着每个人都可以制作DuckDB扩展,发布它们,安装它们就像在你本地的DuckDB中输入'install'命令一样简单。
Shant Hovsepian
这种集成非常出色。那么,我们如何在此基础上更进一步呢?
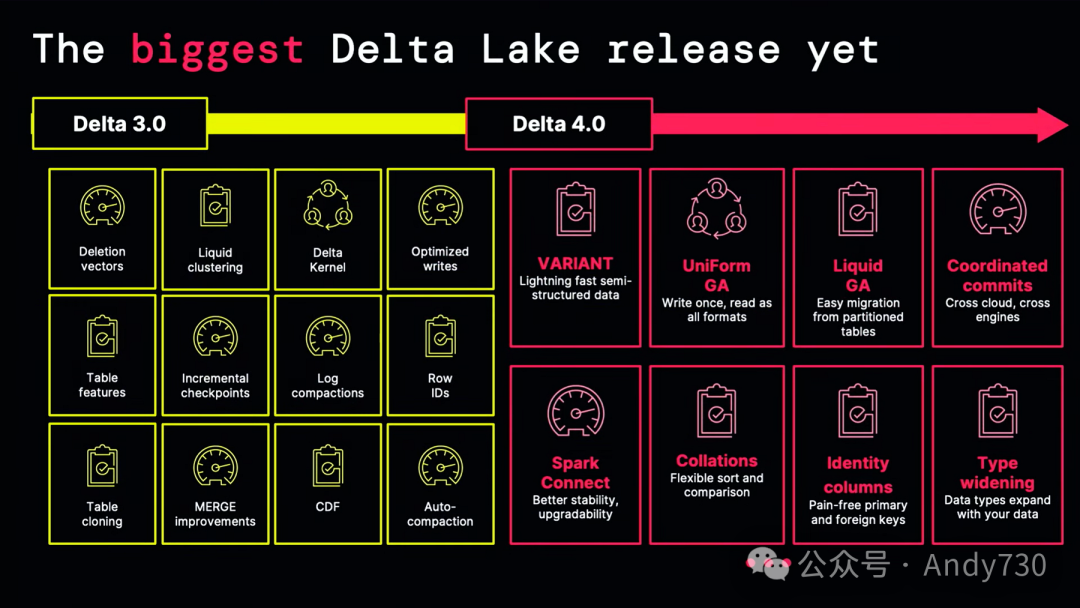
Delta 4.0是自其诞生以来Delta最大的变革。它充满了新功能和改进。诸如Coordinated commits、Collations各种新功能,使得处理各种不同类型的数据集变得更加容易。

Liquid Clustering现在作为Delta 4.0的一部分正式推出。通过Liquid Clustering,我们解决了许多人面临的一个挑战:分区。分区虽然对性能有好处,但也很复杂。过度分区会导致小文件问题,而选择错误的分区策略可能会带来很多麻烦。
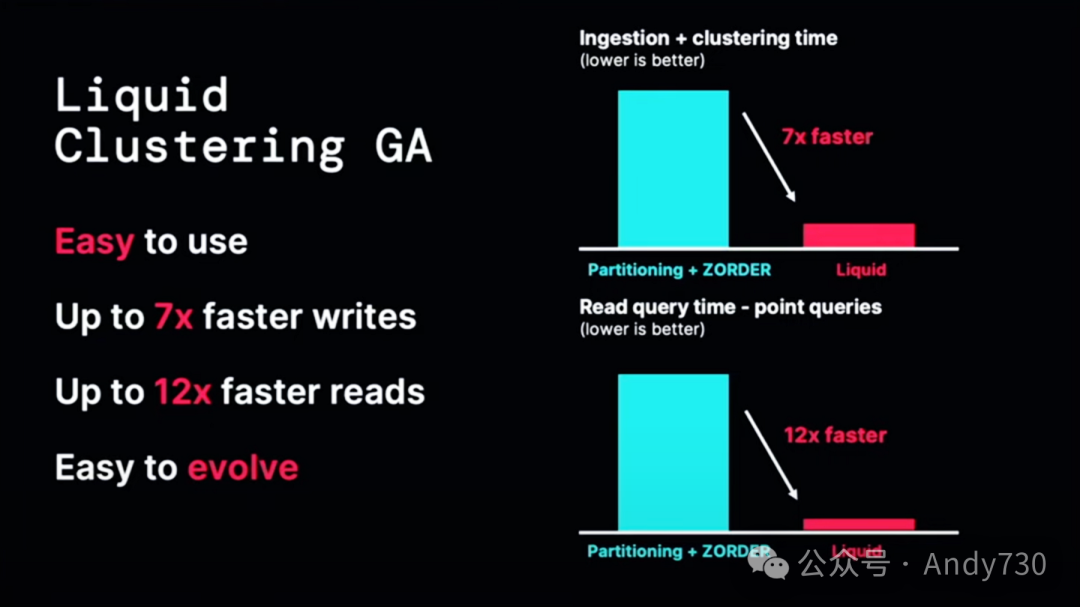
Liquid Clustering通过一种新颖的数据布局策略解决了这个问题,这种策略使用起来非常简单,我们希望所有人在定义表时都能轻松告别“partitioned by”。它不仅易于使用,而且写入速度最高可提升七倍,读取速度最高可提升12倍。这些性能优势令人惊叹。此外,你可以轻松地演化模式、进行更改,并定义任何东西,而不必担心所有数据都被重新写入。

目前已有大约1500家客户正在积极使用这个功能,其采用情况令人难以置信。已经处理了超过1.2ZB的数据。即使是Shell在开始将其用于时间序列工作负载时,也看到了性能提升一个数量级以上。而且使用起来非常简单。
接下来,让我们深入了解开放变体(Open Variant)数据类型。这一点尤为重要。术语“开放”确实令人兴奋。在AI领域,我们正见证半结构化文本数据和其他替代数据源在Lakehouse中的增长。我们的目标是设计一种方法,简化这些数据类型在Delta内的存储和处理。
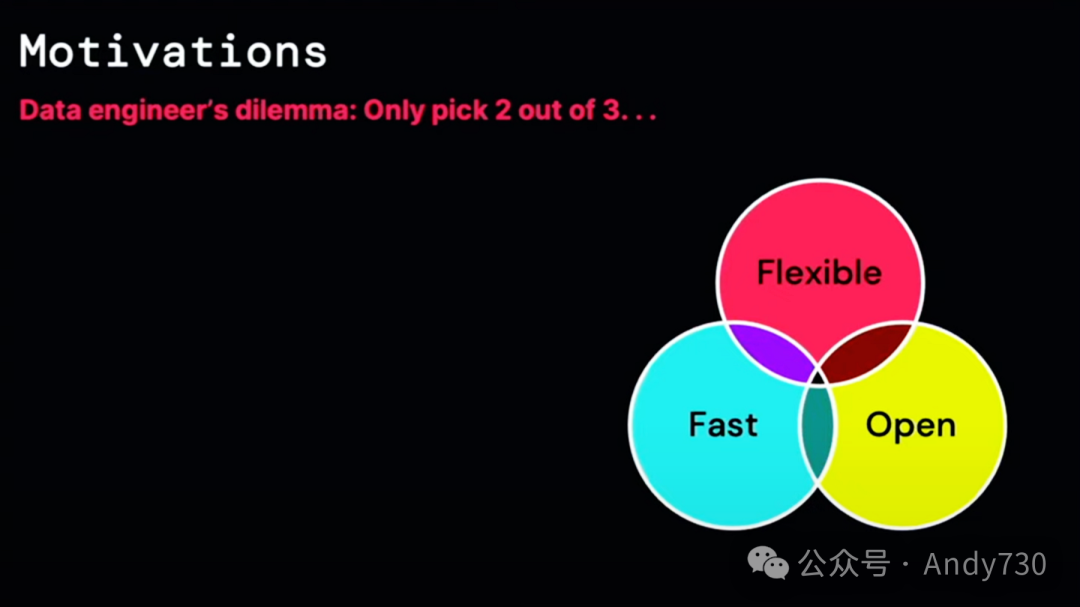
通常,在处理半结构化数据时,大多数数据工程师发现自己不得不做出妥协。我们都不喜欢妥协,但通常只能在开放性、灵活性或速度之间做出选择。通常,他们只能优先考虑这三个方面中的两个。

例如,在处理半结构化数据时,一种方法是将所有内容都存储为字符串。这虽然提供了开放性和灵活性,但解析字符串的速度很慢。为什么要将数字存储为字符串,并在每次需要时都重新解析呢?

另一种选择是从半结构化数据中选择字段,将其转换为具体类型,以实现出色的性能,这种方法提供了开放性和快速访问。

但如果利用专有格式数据,你可能会牺牲修改模式的灵活性。
关系数据库长期以来一直拥有专门的枚举或变体数据类型,但这些类型往往是专有的。如果你想在使用它们时不必将所有内容都存储为字符串,或者不必将每个列都进行分片而做出妥协,那么你可能会被限制在某个特定的系统中。
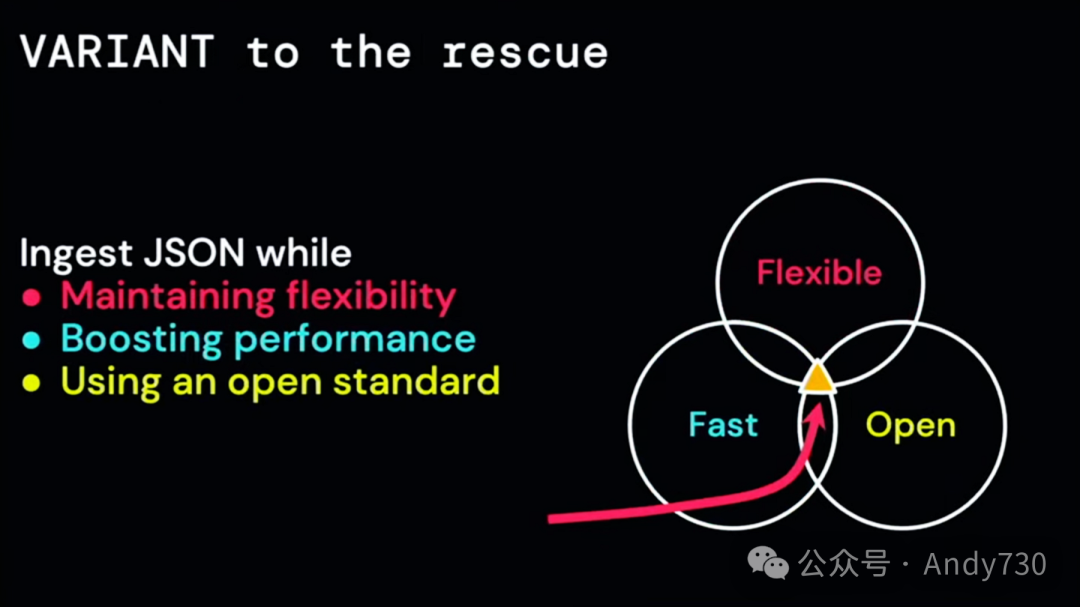
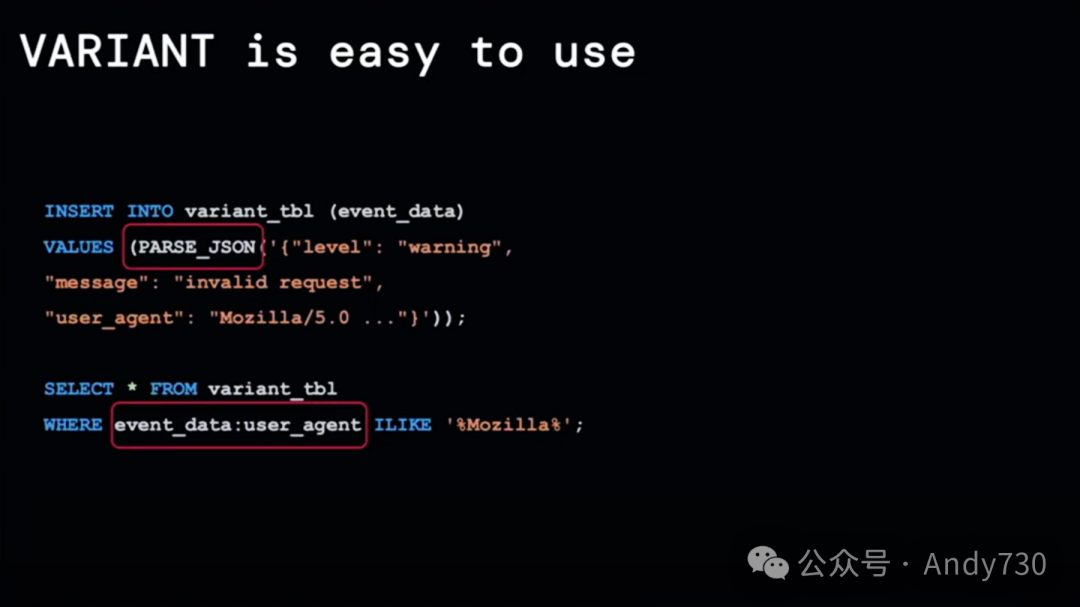
这就是我们对变体数据类型感到兴奋的原因。它为我们提供了一个完美的中间方案。你能够以灵活、完全开放且性能卓越的方式存储JSON数据。这种数据类型非常用户友好,甚至可以与复杂的JSON结构无缝兼容。
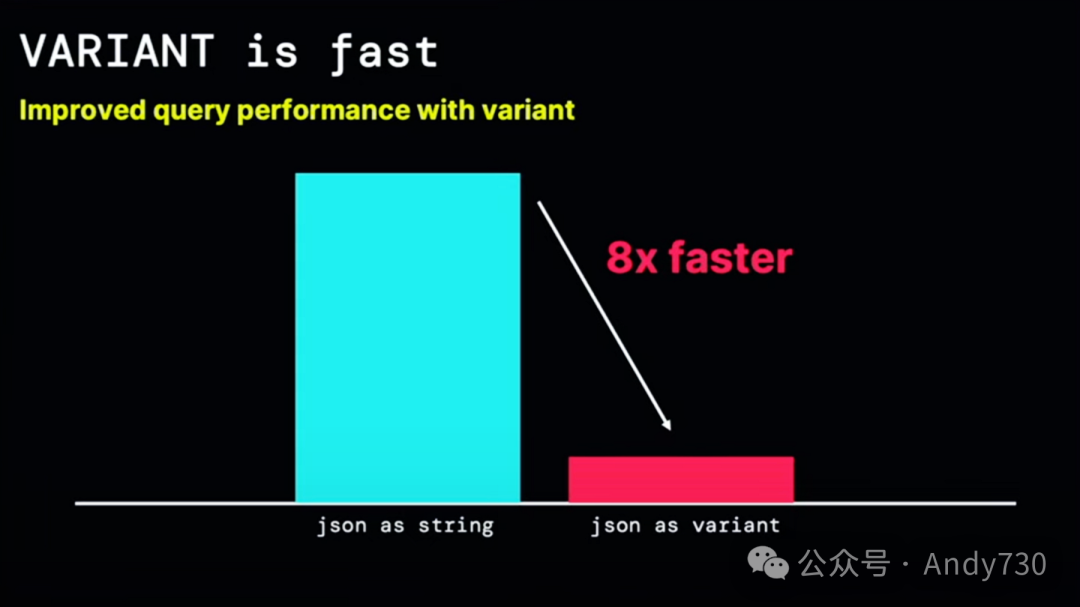
举例来说,它比将JSON数据存储为原始字符串要快8倍。如果你目前将JSON存储在字符串字段中,我们强烈建议你过渡到变体存储。这种存储方式已在DBR 153中提供。

值得一提的是,所有关于变体的代码已经并入Apache Spark中。在4.0分支中,有一个公共子目录,包含了所有实现细节和运算符。此外,我们还开源了二进制格式的代码定义和库,允许其他数据引擎也使用这种变体。我们的目标是将它推广为每个人都可以采用的官方开放格式。这将最终为可靠地存储半结构化数据提供一种非专有方法。

最后,我想对Delta Lake 4.0做一个简要的总结。它支持互操作,拥有令人惊叹的生态系统,其中包括像Hanis这样的贡献者,他们共同努力增强了其功能。其性能优势十分显著,且该平台现在变得更加用户友好。
Matei Zaharia

今天我为大家准备了一个稍长的会议,因为我将深入讲述关于开源Unity Catalog的治理和数据共享方面的内容。我们还发布了另一个名为Delta Sharing的开源项目,它在开放数据协作领域引起了广泛关注。关于这方面,我们有很多令人兴奋的公告要分享。所以,我将从介绍Unity Catalog的新功能开始,解释我们为什么要将其开源,以及它包含了哪些内容。
Ali昨天已经宣布我们正在开源它,但他让我保留了一个今天要宣布的消息,我将会谈到Unity Catalog的下一个重要发展方向。最后,我将转向数据分享和协作,并展示这些功能。

让我们从Unity Catalog开始。我相信每个从事数据和AI工作的人都清楚,治理在安全性、质量和合规性方面对许多应用来说仍然是一个巨大的挑战。随着生成式AI的兴起,这个问题变得更加复杂。关于它的新法规正在不断制定中。我听说仅在加利福尼亚州就提出了80项关于AI的法案。如果你要创建模型、部署它们并运行这些应用程序,那么你需要真正了解数据的来源。
我们时常听到客户说,他们很想使用AI,但现有的框架无法满足他们的管理需求。即使在数据领域,情况也足够复杂;所有的规则都在变化,人们担心如何最好地管理数据。

因此,我们想要退一步思考,现在是2024年,如果你必须从零开始设计一个理想的治理解决方案,你会希望它具备哪些功能?我们咨询了一些CIO,他们认为,你确实希望这个方案具备三个方面的内容。
第一点是我们称之为的“开放连接性”。你应该能够将组织内的任何数据、任何来源连接到治理解决方案中,因为没有人会将所有数据迁移到一个数据系统中。随着时间的推移,大多数组织都有数百或数千个数据源,所以用户真的希望一个治理解决方案能够覆盖所有这些数据,无论它们存放在哪里,以任何格式存在,甚至在其他平台上也是如此。
然后,我们还认为需要在数据和AI之间实现统一的治理。通过生成式AI,我们越来越清楚地知道必须同时管理数据和AI。无法在不了解输入数据的情况下管理AI,而且由于AI的所有输出都会成为关于应用程序运行情况的数据,因此也需要管理AI的输出。这些问题涉及到数据的质量和安全性。因此,我们真的需要实现统一治理。
最后,我们听到每个人都在要求来自任何计算引擎或客户端的开放访问,因为有这么多优秀的解决方案不断涌现。将会有下一个数据处理引擎,下一个机器学习库。你希望它们能与数据一起工作。
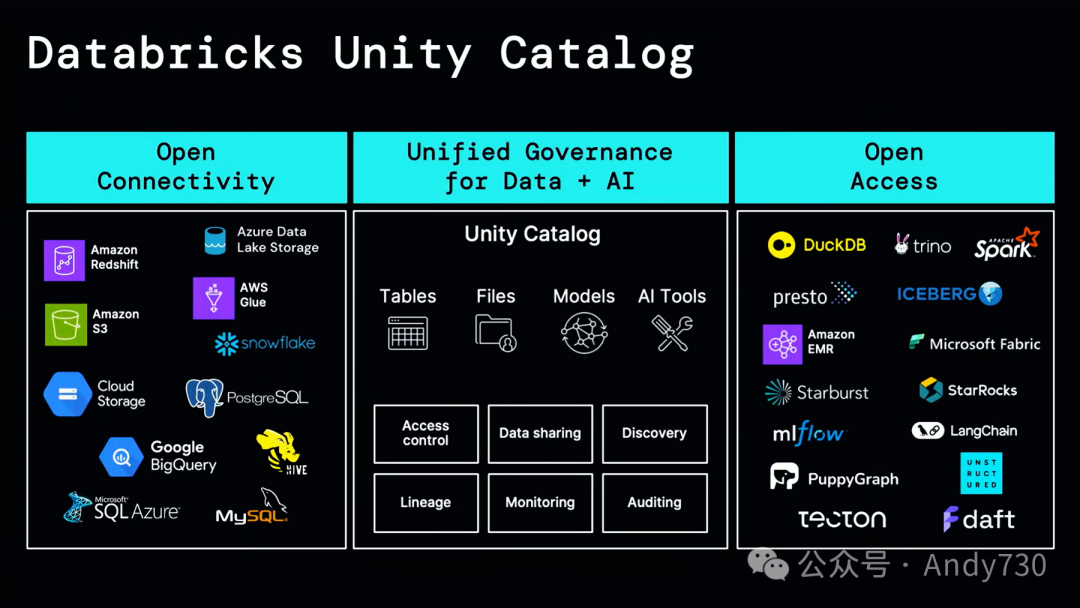
这就是我们正在构建的Unity Catalog,特别是今天的开源发布。
首先是开放连接性。作为Databricks平台上的Unity Catalog,它能够在其他系统中连接数据,并通过我们称之为Lakehouse Federation的功能,以极为高效的方式联合处理数据。因此,可以真正整合所有数据,并为用户提供一个统一的位置,用于设置安全策略、管理数据质量并使其可用。它也是业内首个统一的数据和AI治理系统。自推出以来,我们就支持表格、模型、文件,并随着AI世界的新发展,我们不断添加新内容,比如昨天我们与生成代理讨论了工具目录的概念。
对于所有这些功能,可以获得一系列能力,从访问控制到数据谱系,再到监控和发现。最后,通过我们最新推出的开放API和开源项目,可以通过各种应用程序轻松访问所有表格。稍后我会详细讨论这一点,但这里的重点是,这不仅仅适用于像Databricks这样的数据系统,许多领先的机器学习系统,如LangChain,也可以与Unity Catalog集成。

自推出以来,这一功能得到了广泛的采用。现在,大多数客户都使用Unity Catalog,其中一些客户正在管理数十PB的数据,如GM,或者拥有数千名活跃用户。
接下来,我将简要介绍一些新特性以及一些快速公告,然后我们将看到一个演示,展示所有这些内容如何结合,包括开源项目。
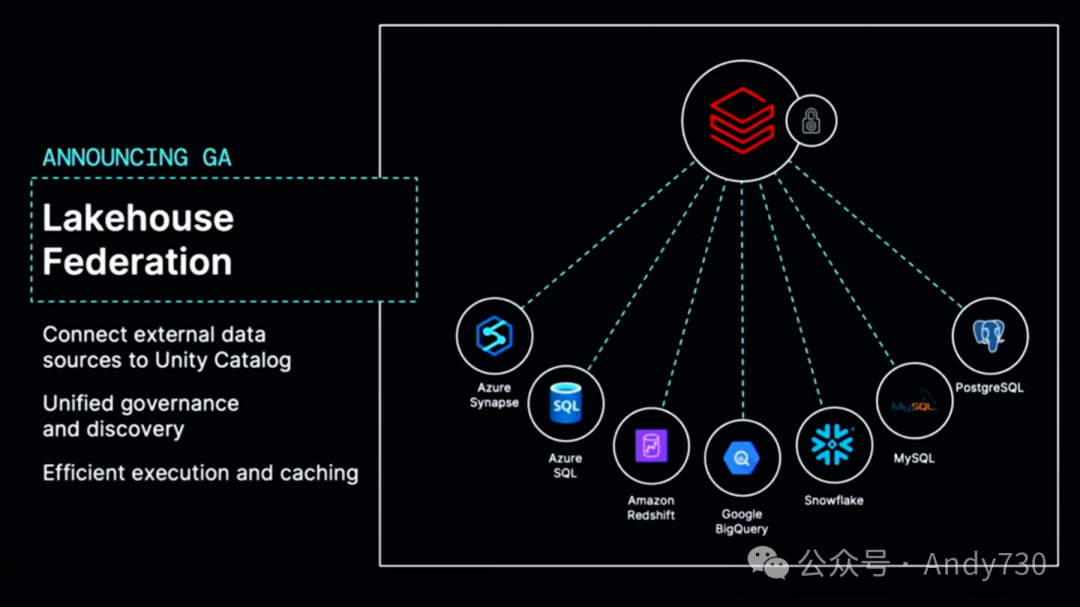
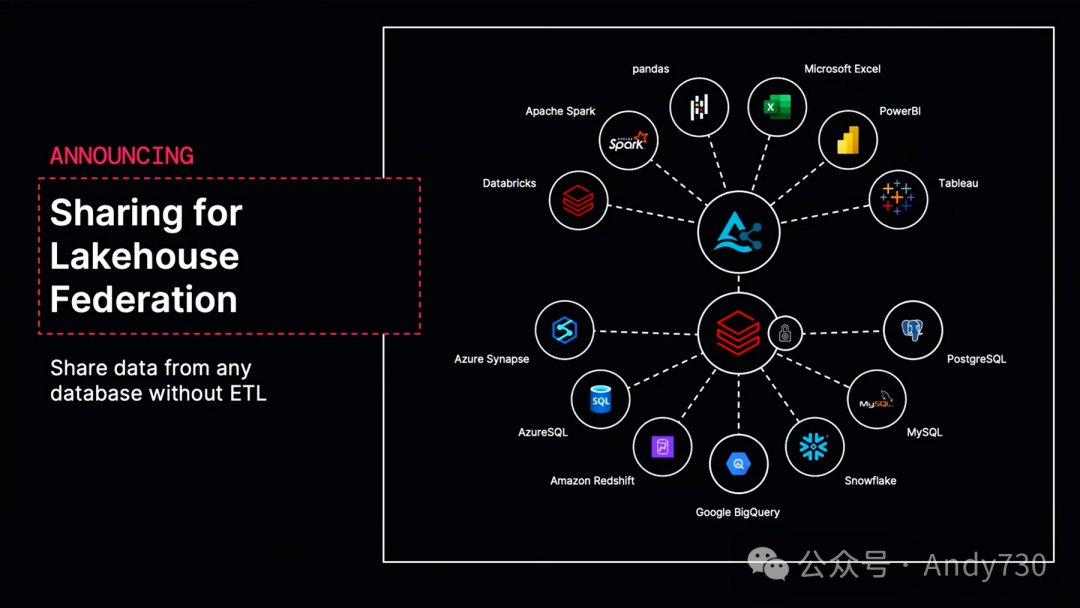
让我从开放连接性开始。今天我非常高兴地宣布Lakehouse Federation的正式发布,这是Unity Catalog中连接和管理外部数据源的能力。感谢大家的支持。这是我们去年推出的一个功能,一年前在峰会上与大家分享过。它建立在Apache Spark独特的能力之上,可以高效地组合多个数据源,让你可以将这些数据源挂载到Databricks中,设置统一的治理规则,并享受与Delta表相同的体验,包括在使用时管理数据质量、追踪数据谱系等。
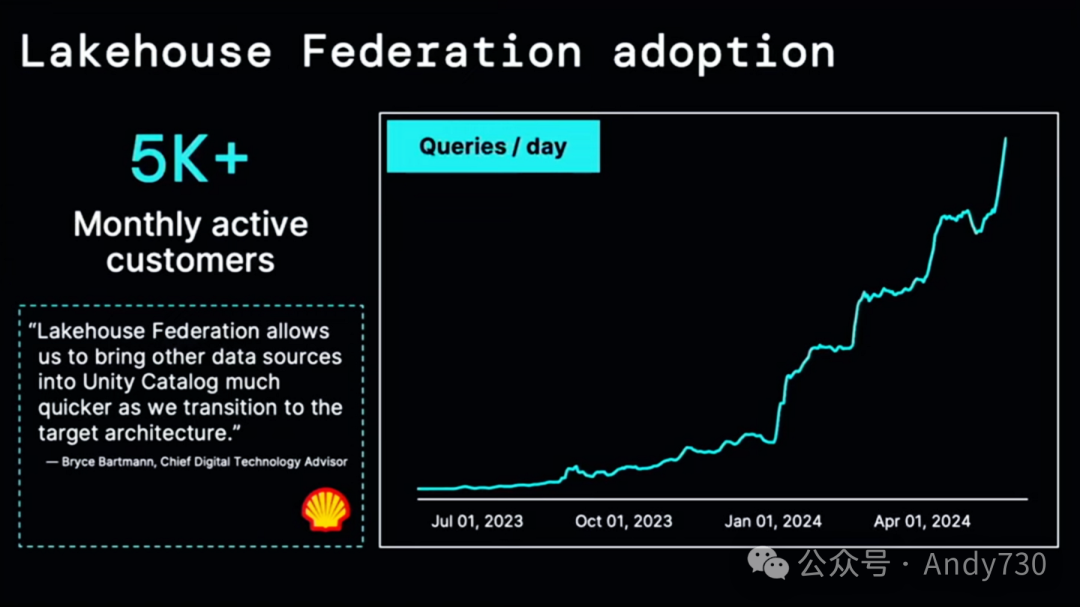
这一功能发展迅速。目前,我们有超过5000个活跃用户,从Lakehouse Federation的增长图表来看,它仍在持续高速增长。因此,我们看到许多客户终于能够将所有分散的数据整合在一起,这在每家公司都是现实情况,尽管每个数据供应商都希望你将所有数据放入一个系统中,但实际上,这些系统是可以共同使用的。
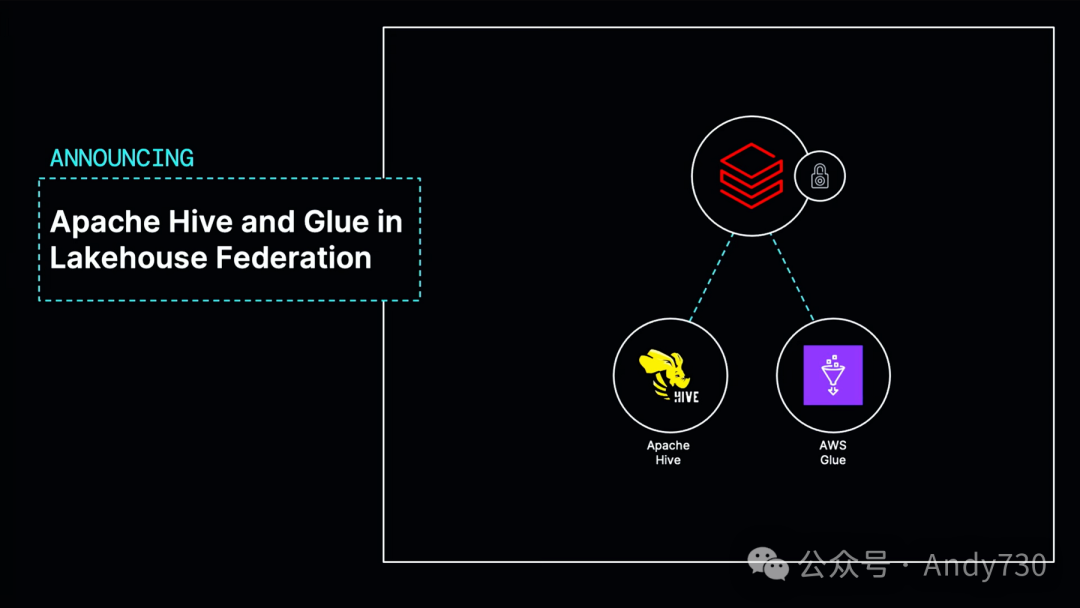
我要宣布的另一项激动人心的功能是,Lakehouse Federation将支持Apache Hive和Glue。因此,如果你拥有现有的Hive Metastore或Glue,并在其中存储了大量表格,你现在可以将它们有效地连接到Unity Catalog中并管理其中的数据,这一功能将在今年晚些时候推出。我认为这是Databricks作为数据平台的一个标志性功能。

那么,关于数据和AI的统一治理呢?在这个领域,我们团队一直在努力推出一系列新功能。尽管我无法逐一介绍所有功能,但在过去的一年里,我们推出了从AI辅助文档和token到许多改进的谱系共享、监控等功能。
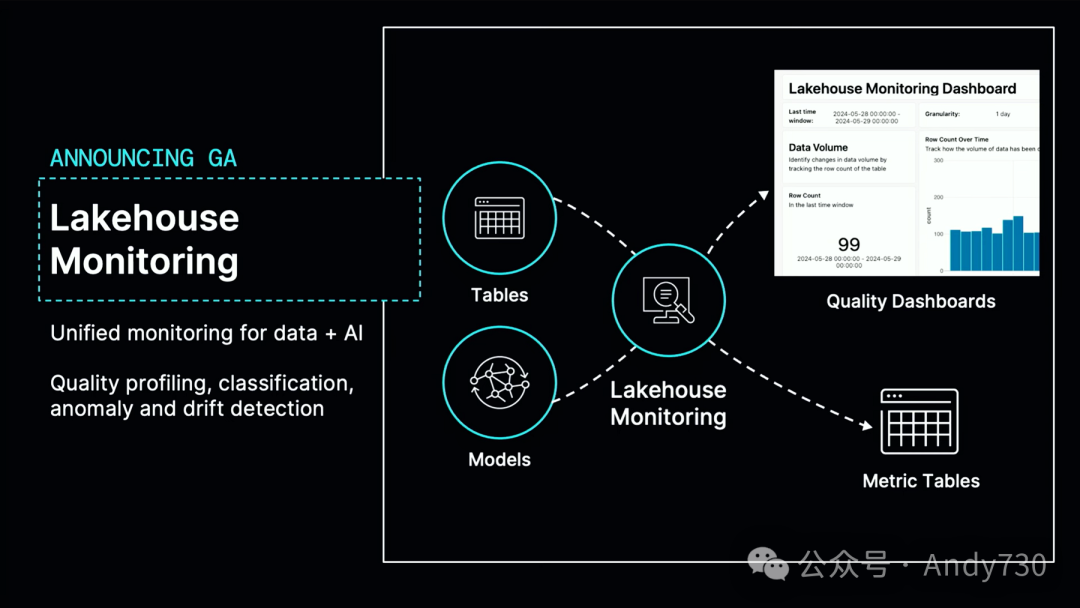
在这里,我只想强调两个重要公告,一个是关于ABAC(基于属性的访问控制),另一个是关于Lakehouse监控。首先,Lakehouse监控功能将正式发布。因此,Lakehouse监控是Unity Catalog中任何表格或机器学习模型自动检查数据质量的能力。它内置了许多质量检查,比如空值数量、是否已停止更新等。此外,你还可以进行自定义检查。这一功能之所以优秀,是因为它集成在数据平台中,我们知道数据何时发生变化或模型何时被调用,因此它非常高效,并且所有计算都是增量进行的。它为你提供了关于数据质量、数据发现、分类等的丰富仪表板。此外,所有这些报告都会自动关联到这些表格,因此你可以通过编程方式全面监控整个数据和AI的质量。该功能现已正式发布,并在成千上万的客户中得到了广泛应用。

接下来我要介绍的预览功能是基于属性的访问控制(ABAC)。我们开发了这个策略构建器和token系统,支持在目录的任何层级上为数据设置token。还可以根据数据模式自动填充token。然后,可以在所有token上应用这些访问控制策略。而且,这些操作都可以通过用户界面或SQL轻松实现。这只是其中的两个新特性。

最后但同样重要的是,我最为兴奋的是推出开源Unity Catalog和开放访问。
昨天很多人问我为什么要开源Unity Catalog?实际上,这是因为客户有这样的需求。客户正在为未来几十年的数据平台架构设计寻找基础,他们希望这个基础是开放的。今天,即使你看到许多声称支持开放性的云数据平台,但深入研究后,你会发现它们并未真正贯彻这一点。
有很多云数据仓库,比如那些可以读取Delta Lake或Iceberg中的表格的,但它们大多也有自己更高效、更优化的本地表格,这些表格会诱导你使用它们,从而将你的数据锁定在特定平台中。还有一些平台,甚至是某些湖平台,表面上似乎一切都是开放格式的,但如果你从外部读取到它们的引擎内部,你必须支付高昂的始终开启的计算费用。客户不希望这样。大家都希望能拥有一个开放的数据湖,数据由自己掌控,没有供应商锁定,未来可以自由选择任何计算引擎。

我们早已是这种理念的坚定拥护者。我们认为这是未来的趋势,因此我们所做的一切都是为了支持这一理念。在Databricks中,所有数据都是以开放格式存在的,没有本地表的概念。去年,我们还与Uniform一起推动了跨格式兼容性,使得那些仅支持Apache Iceberg或Hoodie的客户端生态系统也能读取你的表格。
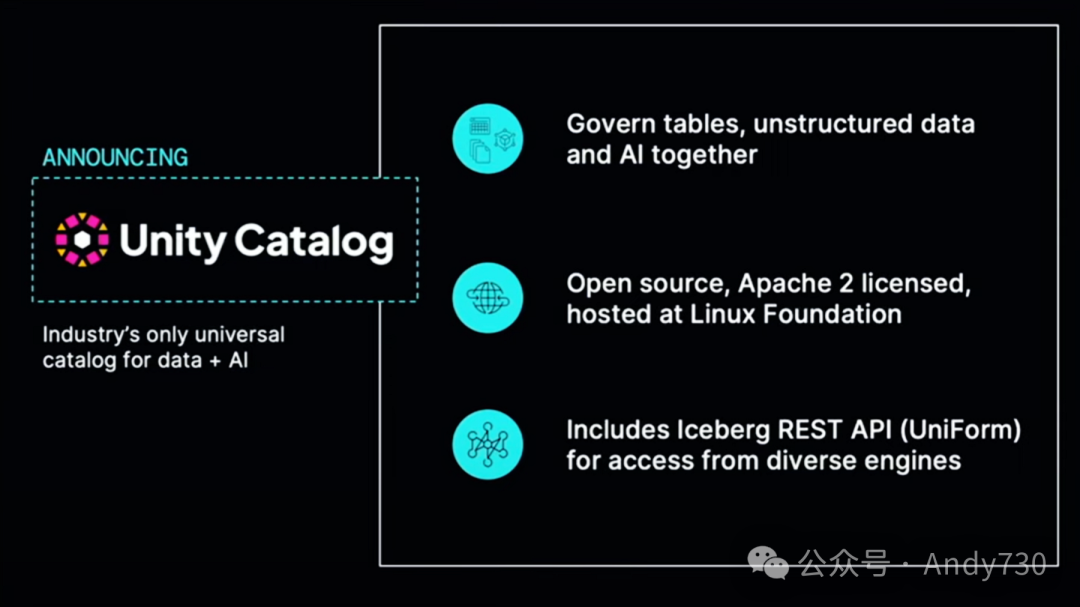
下一个重要步骤是提供开源目录。这就是我们在Unity Catalog的第一个版本中所做的。我们将逐步发布我们在平台上构建的功能,并去除所有对Databricks代码的依赖,将它们放入开源项目中。即使在第一个版本中,你也可以管理表格、非结构化数据和AI模型。我们对此感到非常兴奋。我们已经将这个项目提交给Linux基金会,并且已经得到接受,所以它将在那里持续发展。
Unity Catalog的另一个基石是我们正努力实现的跨格式兼容性。因此,即使是第一个版本也支持了Iceberg REST API。这是第一个实现这种格式的开源目录,意味着你可以从任何支持该格式的引擎连接到它。我们希望这意味着外部生态系统中的许多工具都可以与其配合使用。
你可能会问,这是真的吗?什么时候正式发布?现在我就到Notebook电脑旁进行操作。Unity Catalog已经在GitHub上公开了。看起来很不错,团队正在努力工作。我现在就来设置一下,将这个功能公之于众。好的,它已经公开了。所以,请大家去看看吧。访问github.com/Unity-Catalog即可。

我们刚刚发布了版本0.1。这个版本支持表格、非结构化数据和AI工具和函数的卷。因此,它实现了我们昨天讨论的工具目录概念,并提供了对Iceberg的支持。如果你访问我们的网站,会发现开源服务器API和客户端,它们与你在Databricks上的Unity Catalog实例一样有效。因此,你可以连接到你当前的数据。

我们还很高兴地宣布与多个合作伙伴进行了广泛的发布,包括一些为Iceberg REST API做出了很大贡献的云供应商,以及领先的AI和治理公司。微软、AWS、Google等都对这一进展感到兴奋,我们期待与他们紧密合作,为Apache Iceberg做出贡献,并帮助定义这些标准,以便客户能够获得他们想要的互操作性。
接下来会有更多新功能推出。我们正在努力将你在Databricks和Unity中拥有的许多优秀功能带到这里,包括Delta共享、MLflow集成、视图等。这是对Unity的一个概述,其中一些我们即将推出的功能。
Zeashan Pappa
接下来,我将带你深入了解每个功能。
首先,我们从左侧的目录资源管理器开始。这是一个统一的界面,用于浏览、设置访问控制和查询表格。你可以通过它来浏览和组织目录、表格、函数、模型、卷和其他数据系统,无论它们是在Databricks内部还是外部。
在某些情况下,你的部分数据可能只存储在数据湖中。为了解决这个问题,我们简化了对诸如BigQuery、Glue和Hive、MySQL、Postgres、Redshift、Snowflake和Azure SQL等系统的访问控制,并提供了保护。所有这些都得到了Lakehouse Federation的支持。
在SQL编辑器中,我将演示如何通过执行SQL查询来访问外部数据系统。这个SQL查询将结合Snowflake中联合的商店报告表和包含零售店退货数据的湖本地源表。一旦创建了这个表,这个商店报告表就将成为Unity Catalog管理的对象,这意味着平台将为你处理所有表格管理方面的挑战,包括自动数据布局、性能优化和预测性分析。
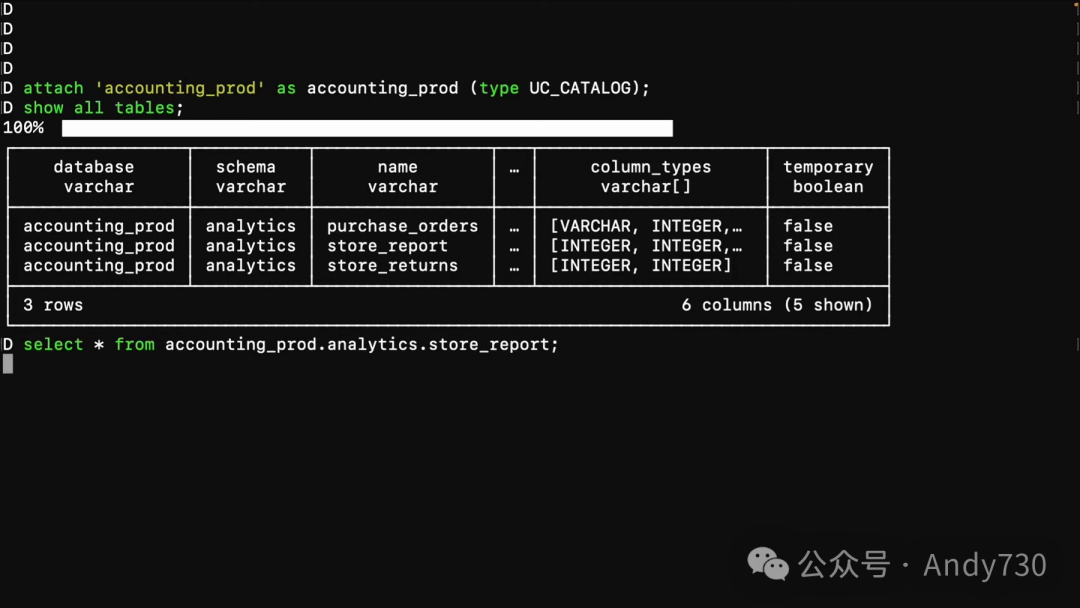
但管理并不意味着数据被锁定。你可以通过Unity Catalog的开放API在Databricks之外访问此表格或任何Unity Catalog对象。下面,我将展示如何轻松使用DuckDB查询这个新创建的对象。首先,我将此表格设置为外部可访问,就像我处理目录中其他表格一样。接下来,我将切换到DuckDB,使用你现在可以访问的相同夜间构建版本。我将这个目录连接到DuckDB的catalog accounting prod。现在,我将运行一个快速查询,以查看这个目录中的所有表格。
正如你所见,我刚刚创建的商店报告表就在其中。接下来,我将从这个表格中选择数据进行查询。我可以使用相同的方法处理Unity Catalog中创建的表格,并利用DuckDB的本地Delta读取器快速查询它们。这正是Databricks对开源和开放互操作性的承诺。就在这里,就在现在。
到目前为止,我已经介绍了Unity Catalog的资源管理器、Lakehouse Federation和我们的新开放API。然而,对于许多组织来说,一个主要挑战是确保在各种数据和AI资产上实施一致且可扩展的策略执行。接下来,我将展示如何使用标签、ABAC策略以及主动PII监控来轻松扩展你的治理。
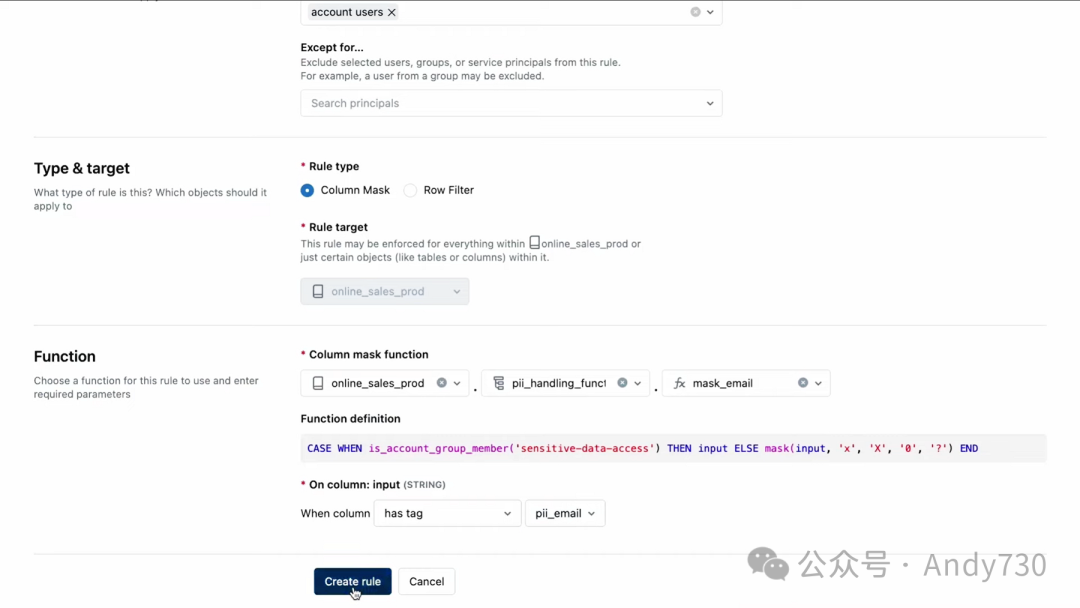
我们切换到在线销售产品目录。让我们看看这个名为Web Logs的表格。Unity Catalog中的一项强大功能是Lakehouse Monitoring,它允许简化数据和模型的异常检测,并进行主动的PII检测。在左侧的仪表板中,你可以浏览列和行,并看到PII已经在用户输入列中被检测到。显然,这是一个需要解决的问题。在实际使用这个数据集之前,必须掩盖这些数据并应用适当的策略。
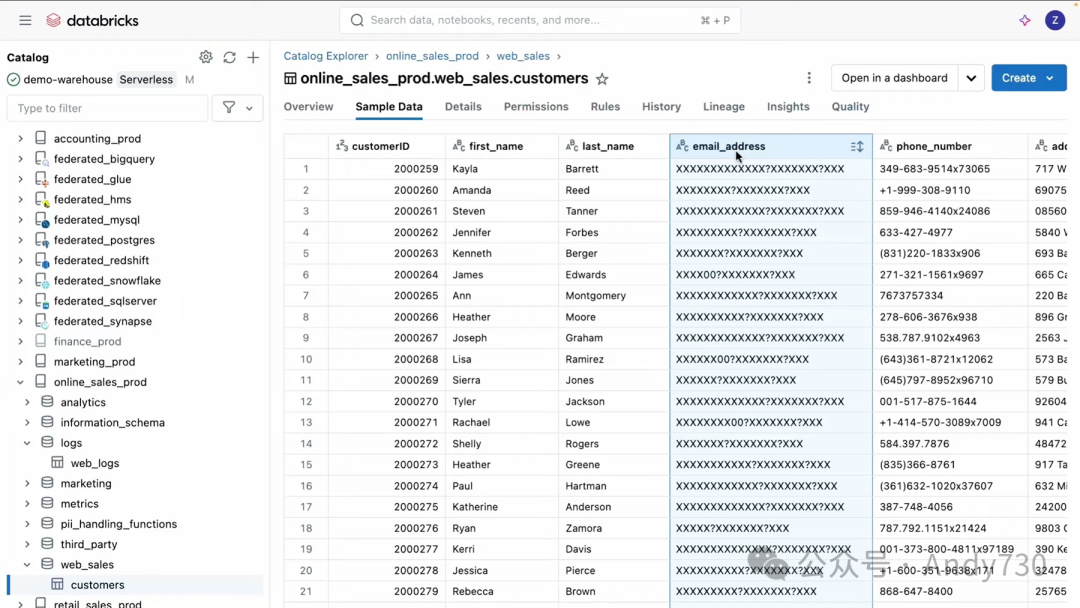
现在,我们回到目录资源管理器。在资源管理器中的“规则”选项卡下,可以创建一个新规则,以在所有数据上表达政策。现在,通过一个规则,我们可以更轻松地掩盖所有表格中的所有电子邮件列。让我们为这个规则命名,叫做“Mask Email”。给它一个简短的描述,比如“掩盖电子邮件”。我们将这个规则应用于所有账户用户。好的,这是一个列掩盖类型的规则。我们将选择一个之前创建的列掩盖函数,称为“Mask Email”。当检测到一个带有PII电子邮件标签值的列时,我们将匹配一个条件。好的,现在创建这个规则。
为了验证掩盖效果,我们再次查看Web Logs Sales表。在这个表格中,我们可以看到用户输入列中的样本数据现在已经被掩盖了。由于这个规则适用于整个目录,让我们转到另一个表格验证一下。在这里的某个地方。找到了。正如你在这里看到的,这个表格中的电子邮件地址列也被该规则掩盖了。
我展示了Unity Catalog如何使组织能够轻松访问其数据,无论数据位于何处,同时应用统一的治理来确保其完整性和安全性。
Matei Zaharia
刚才你看到,你可以建立一个目录,它是开放的,具有访问控制和监控功能,你可以从任何引擎访问它,你可以将内容联合到其中。
你可能会说,“这听起来不错。” 作为工程师,你是否已经完成了工作?

但不幸的是,接下来可能会有人提出商业问题。例如,“我的EMEA地区的应收账款趋势如何?” 要回答这种问题,仅仅知道目录、表格模式和类似内容是不够的。你还需要了解“应收账款”是如何定义的,这可能与你业务的某种特定计算有关。可能有很多表格都提到了应收账款,但哪个是正确的表格来获取这些信息?“EMEA”是如何定义的?哪些国家实际上属于这个区域?

所以,问题是,你如何弥合这个差距?
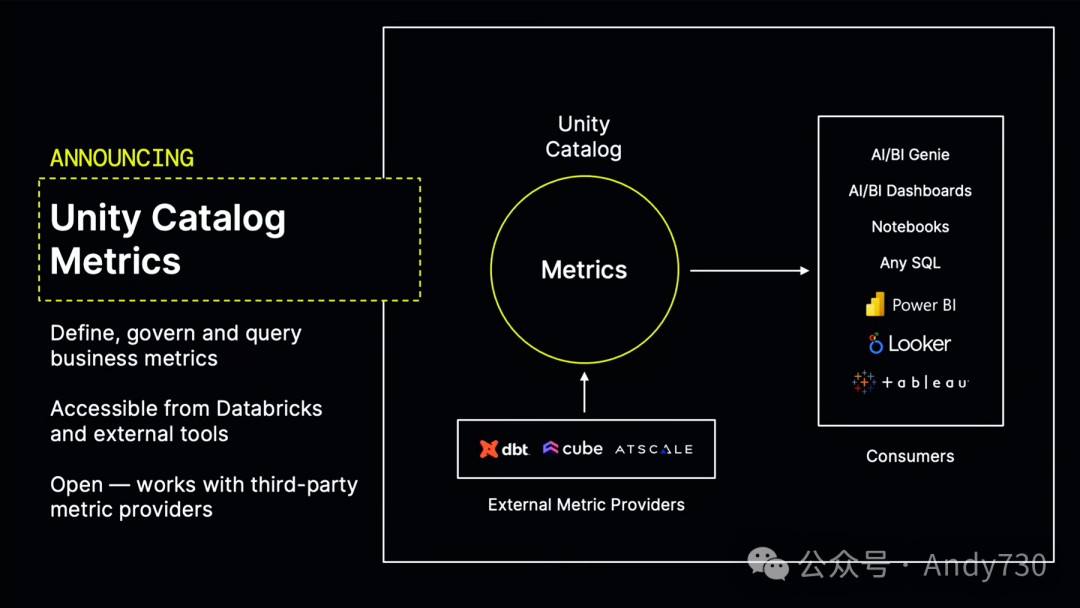
通常,这些工作会在某种度量层中完成。我很高兴地宣布,我们正在为Unity Catalog添加对度量的一流支持,作为一个新的概念。非常感谢。这是我们计划在今年晚些时候推出的一项功能。
Unity Catalog Metrics的理念是,你可以在Unity Catalog中定义度量,并与所有其他资产一同管理。因此,你可以为它们设置治理规则,在搜索中快速找到它们,获取审计事件和它们的血统等信息。与Unity Catalog的其他部分一样,我们采取了一种开放的方法。我们期望你能在任何下游工具中使用这些指标。为此,我们将它们暴露给多个BI工具,让你能选择自己喜爱的BI工具。当然,我们还将它们与AI/BI工具进行了集成。让我们激动的是,从一开始我们就精心设计了这一功能,以确保AI/BI等工具能够真正利用这些度量,并为你提供出色的结果。你只需通过SQL或在其上计算的表格函数即可轻松使用它们。此外,我们还与DBT Cube和AD scale等外部度量提供者合作,以便轻松地在Unity Catalog中引入、管理和维护这些度量。
Zeashan Pappa
正如刚才提到的,度量增强了业务用户提问、理解组织数据并最终做出更好决策的能力。通过Unity Catalog,用户可以高效地管理、发现和查询经过认证的业务度量,而无需筛选所有数据。
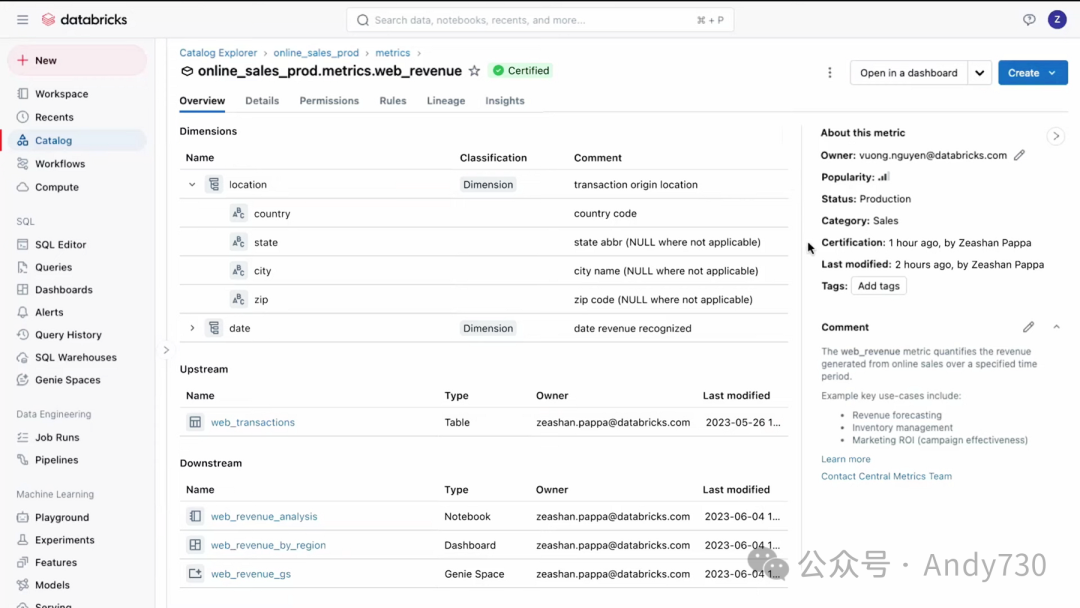
既然我们已经讨论了目录资源管理器,接下来让我们深入了解一下概述选项卡中的业务度量。在这里,你将看到所有可用销售度量的列表。其中一些度量被token为认证,这代表了更高的可信度。我们将选择“Web Revenue”度量。正如你所见,下方也token为认证。点击进入后,你可以查看与此度量相关的元数据以及“Web Revenue”的预定义维度。这些维度在查询度量时使用,例如日期或位置。这就像在你的数据中内置了一本说明书。
在右侧,你可以看到度量概述部分。这里展示了度量的描述、谁编辑了它以及谁认证了它等信息。你还可以查看度量来自何处以及度量在何处被使用,例如Notebook、仪表板和Genie空间。
现在,让我们点击进入这个仪表板。如你所见,在右侧的X轴列中,我列出了所有有趣的维度,如国家、城市、州等。这使得你可以在不完全了解数据模型的情况下对数据进行切片和切块操作。
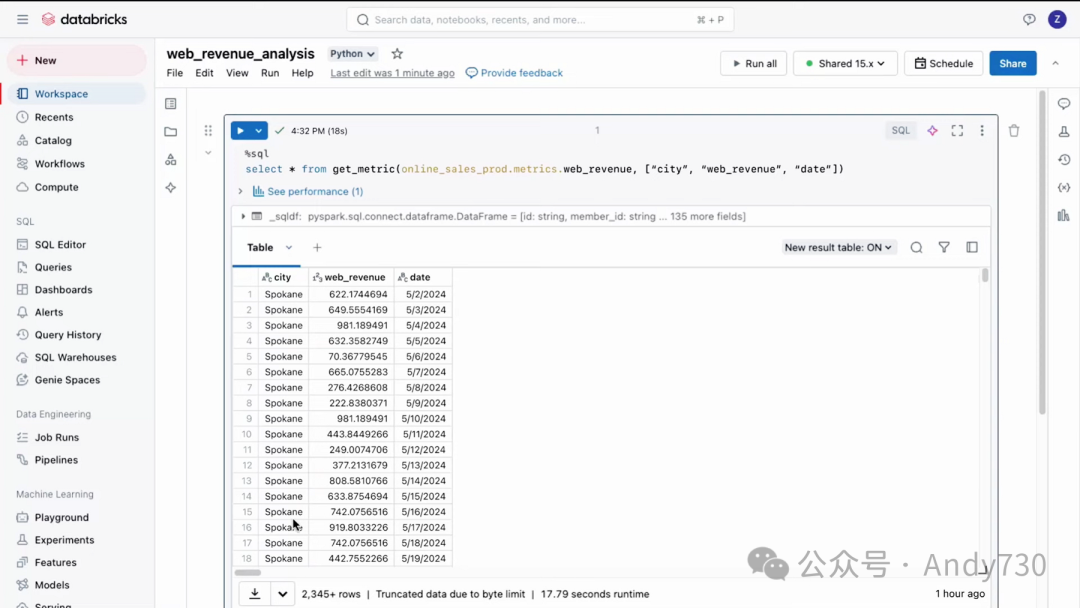
接下来,我们进入一个Notebook。这个度量不仅可以在仪表板中使用,还可以在外部工具和Notebook中进行查询。在这个Notebook中,我们使用GetMetric函数来提取所有聚合数据。操作非常简单。
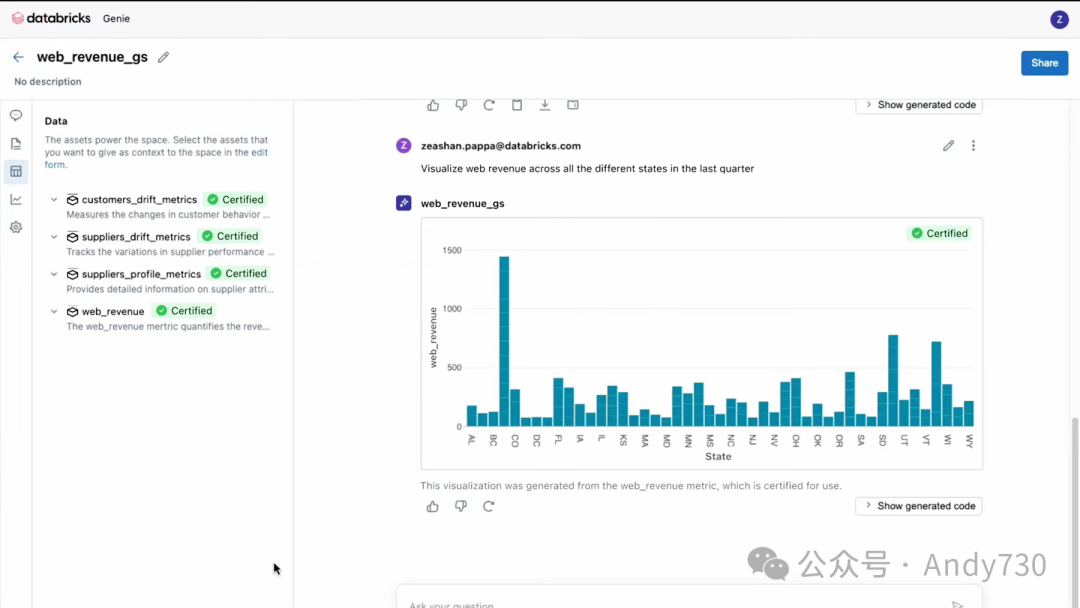
最后,让我们回到Genie空间。在这里,“Web Revenue”度量可用于回答自然语言问题。在这个空间中,你还会看到,通过询问关于使用此度量生成的收入的各个州的情况,我们创建了这个可视化效果。这种方法扩大了这些度量在整个组织中的影响力,使其对业务用户更加可用。
如你所见,Unity Catalog Metrics使任何用户都能够发现和使用可信数据,从而做出更好的决策。
Matei Zaharia
在最后部分,我想谈谈我们在数据共享和协作方面所做的工作。根据你所在的行业,你可能已经注意到,数据共享和组织之间的协作正在成为现代数据领域的一个关键部分。它可以帮助供应商之间更好地协调,简化许多业务流程。就在昨天,我遇到了一位客户,他认为通过实施这些技术,新药的推出速度可以提高一倍。因此,对于许多行业来说,这是向前迈进的一大步。

大约三年前,我们开始关注这个领域。我们想要为此提供强大的支持,于是开始与许多合作的数据提供商交谈。他们告诉我们,许多现有的数据平台支持不同实例之间的某种共享,但这种共享往往是封闭的。你只能在同一个数据平台内、在该数据仓库的客户之间共享数据。作为希望与众多合作伙伴合作的提供商,这种限制是非常不利的。例如,作为CDP的Empyr表示,他们更愿意投资于能够设置一次数据协作,然后能够接触任何平台的任何人的开放解决方案。因此,我们采用了基于开放标准的开放协作生态系统来处理所有的数据共享和协作基础设施。其核心是Delta Sharing,这是Delta Lake的一个功能,允许你在云端和数据平台之间安全地共享表格。此外,我们还通过Databricks Marketplace和Databricks Clean Rooms来构建这一生态系统。
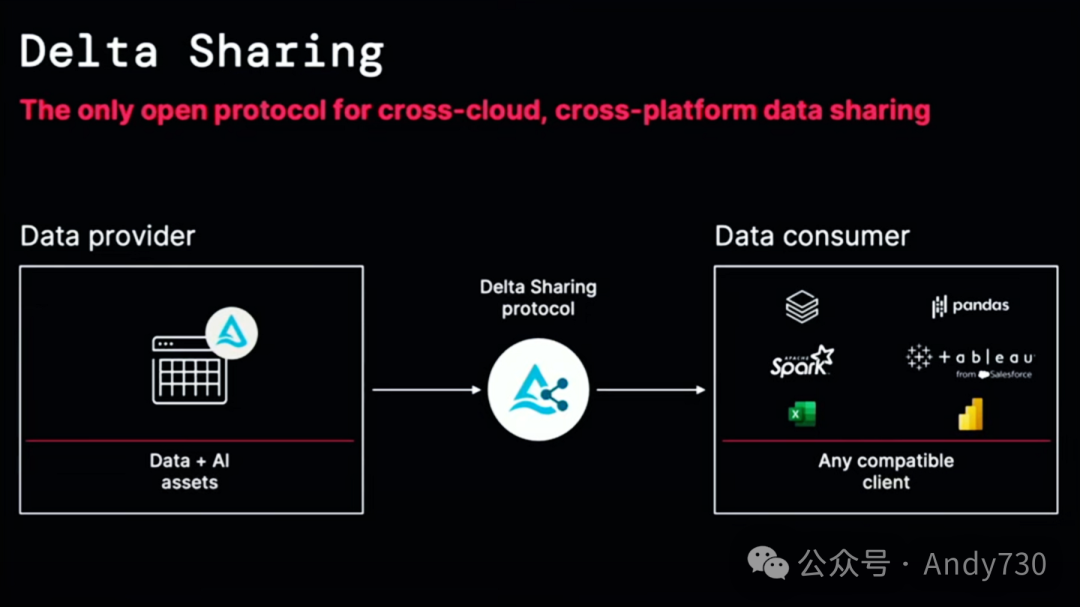
如果你对Delta Sharing还不太了解,简单来说,这是Delta Lake项目的核心组件。如果你有一个表格,甚至越来越多的其他类型资产,你可以运行这个服务器,它采用开放协议,并向其他授权方提供你表格的部分内容。由于协议是开放的,基于Parquet文件,因此非常易于实现,对于许多使用者来说,都是轻车熟路。当然,你可以使用Databricks来访问这些内容,但同样,你也可以直接使用Pandas、Apache Spark,甚至像Tableau和Power BI这样的BI产品来直接加载数据。这样做有很多好处。
如果你是一个数据提供商,想要发布一些数据,为什么另一方需要首先安装数据仓库呢?为什么不直接将数据交付给Tableau或Excel之类的工具呢?这就是Delta Sharing的魅力所在。

它从两年前开始正式发布,并且持续快速发展。就在今年,我们已经有超过1.6万个接收者通过Delta Sharing从Databricks平台上的客户那里接收数据,这比去年增长了四倍。这些接收者中有40%并不在Databricks平台上。这证明了跨平台协作的理念是切实可行的,我们的客户能够交付数据,并与任何使用不同数据平台的人进行实时数据交换。
我们还在继续扩展Delta Sharing的功能。我们正在将平台的两个最佳功能——Lakehouse联合和共享——结合在一起,让你也能够自动共享来自其他数据源的数据。我们已经与许多在数据仓库中拥有数据或拥有合作伙伴(不在Databricks上)的公司进行了对话。由于我们建立了这种可以高效查询数据、推送过滤器、获取数据并传递数据的联合技术,我们只需将其与Delta Sharing连接,你就可以轻松地实现数据共享。现在,只要应用程序支持Delta Sharing协议,你就可以真正地从任何数据仓库、任何数据库共享数据。

现在我来谈谈Delta Sharing的一个衍生产品——Databricks Marketplace。这是我们大约两年前推出的一项服务,也一直在快速发展。Databricks Marketplace现在已经有超过2000个列表,每年增长超过4倍。看到这一点,我感到非常兴奋。Databricks Marketplace已经成为云端任何平台上最大的数据市场之一。我们的团队一直在为市场添加一系列新功能,以满足提供商的需求,如私人交换、共享非数据资产(如模型和卷)、使用分析,甚至支持非Databricks客户。如果你将数据放在那里,你也可以接触到这些其他平台。

此外,我们还非常高兴地欢迎12个新合作伙伴加入这个共享和市场生态系统。其中一些公告上周已经发布,但包括Axium、Amperity、Atlassian等各个领域的行业领导者,他们现在都在连接这个生态系统,并向Databricks上的用户或任何实施开放共享协议的平台上的用户提供数据。他们加入了我们现有的合作伙伴生态系统。在此,我要感谢所有参与其中的合作伙伴。
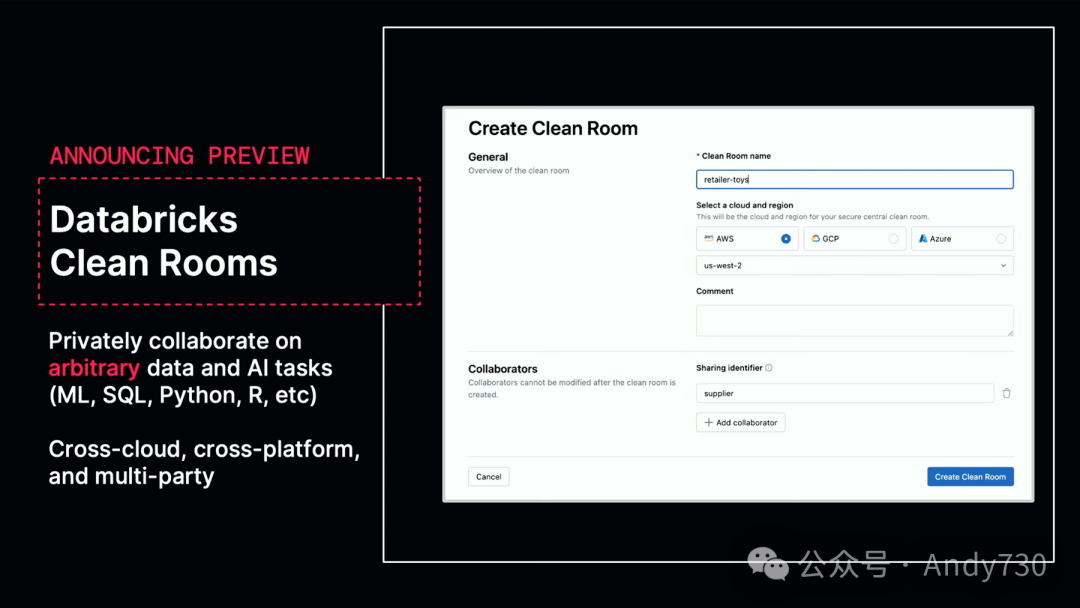
最后,我想分享的是,我们即将推出Databricks Clean Rooms的公共预览版。Clean Rooms是一种与另一方进行私人计算的方式,你可以各自带入自己的资产。你可以带入表格、代码、非结构化数据、AI模型等任何在Databricks平台上可以拥有的资产,然后与其他人就一项计算达成一致,并发送给接收者。例如,这可能涉及到你双方都拥有一些表格,想要弄清楚共同拥有多少记录;或者某人有一个他们想要保密的机器学习模型,而另一个人有一个数据集也想保密,但他们想要将这两者结合使用以获取预测或比较两个模型之间的差异。
Databricks Clean Rooms与其他类似解决方案相比,具有两个明显的优势。首先,由于拥有完整的数据和AI平台,可以选择任何计算方式,无论是机器学习、SQL、Python、R等,而不仅限于许多其他解决方案中的SQL。此外,Databricks Clean Rooms是基于Delta Sharing构建的,集成了Lakehouse Federation,因此非常容易实现跨云甚至跨平台的协作。即使某人的主要数据存储不在Databricks上,他们仍然可以无缝地将其连接到Clean Room并进行处理。这个产品将在今年夏天稍晚时发布公开预览,我们已经看到一些非常出色的应用案例。我们与Mastercard等公司紧密合作,他们有许多令人兴奋的用例,涵盖了各种合作伙伴。你可以想象他们如何利用他们的数据,以及哪些合作伙伴正在寻找最佳方式,来运用最新算法和技术的私有版本来处理这些数据。
为了向你展示这些协作工作的实际效果,接下来我们有第三个演示。
Darshana Sivakumar
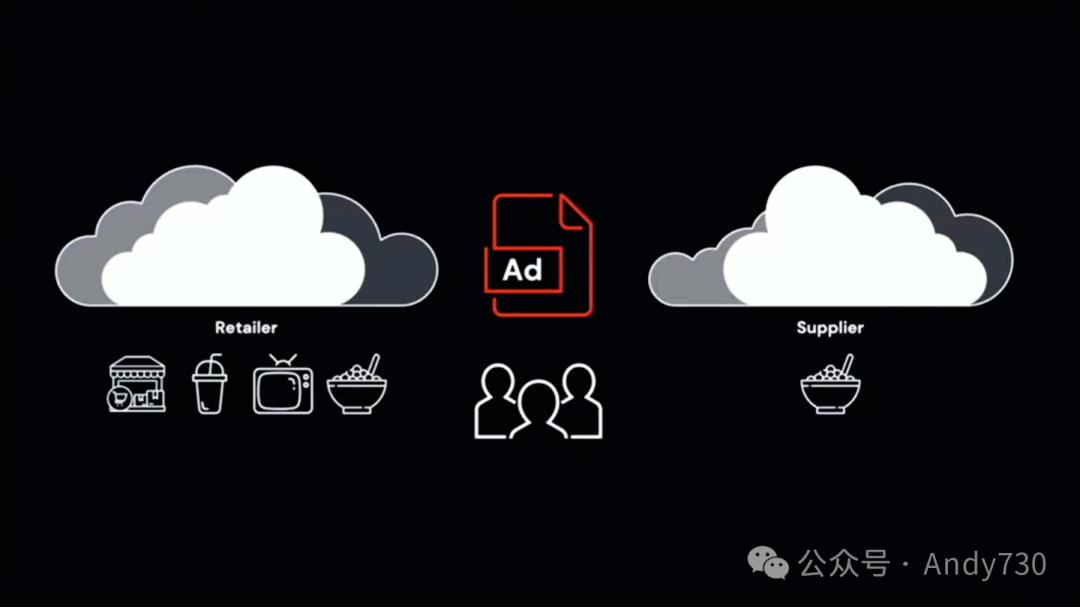
请设想这样一个场景:我是一家大型零售商的媒体团队成员。我们正在与供应商合作开展联合广告活动,以增加销售额。为了实现这一目标,我们需要确定目标受众。我们需要就联合客户数据进行协作。
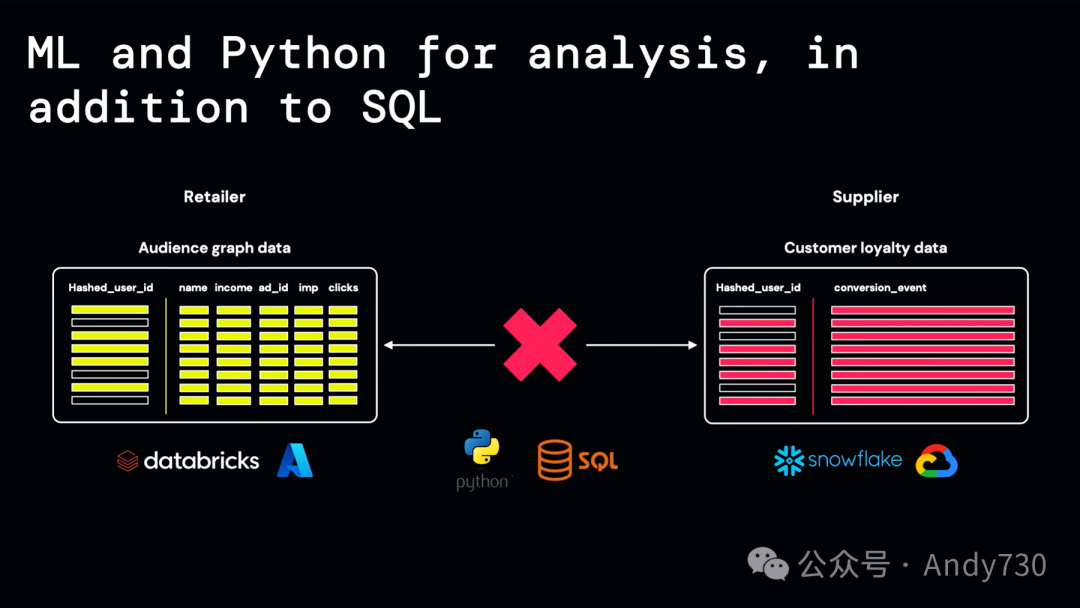
作为零售商,我拥有关于我的客户及其购物行为的数据。我的供应商则拥有他们的客户忠诚度数据。但是,我们面临一些挑战。首先,我们不能向彼此透露关于我们客户的任何敏感信息。其次,我们的数据存储在不同的云、区域和数据平台上。最后,我们希望利用机器学习和Python进行分析,而不仅仅是SQL。
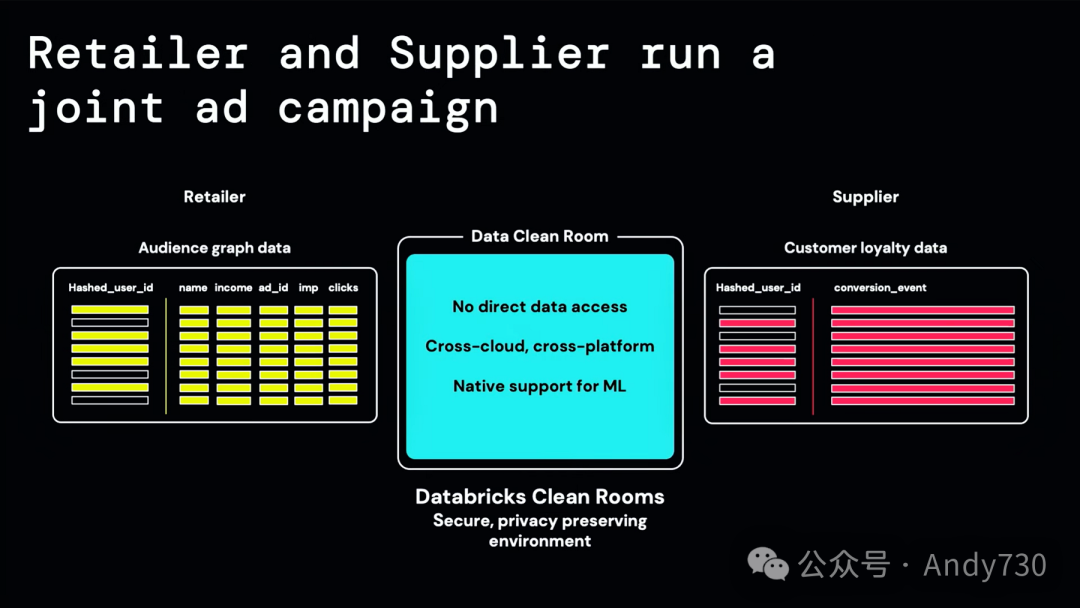
Databricks Clean Rooms可以在一个隐私安全的环境中帮助我们解决所有这些问题。让我们看看它是如何做到的。
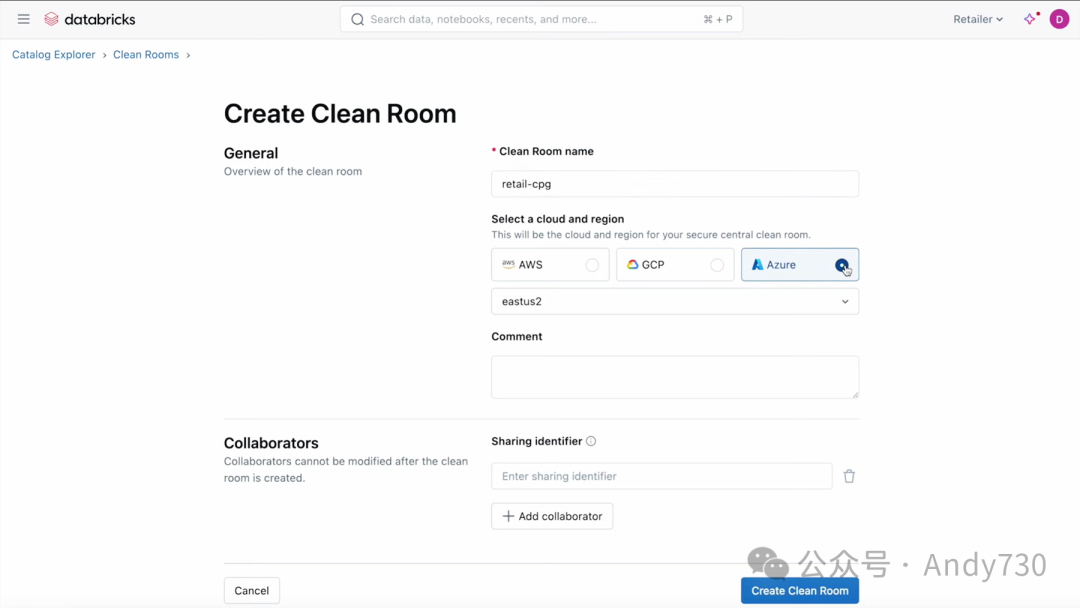
在这里,我作为零售商在Databricks Clean Room控制台上,只需几个简单的步骤就创建了一个Clean Room。我选择了Azure和East US2作为我的云和区域。令人惊讶的是,我的供应商和我在不同的区域和云上并不重要。接下来,我指定了我的供应商作为合作伙伴。一旦Clean Room创建完毕,我就开始引入数据。我添加了我的Audience CFT表,更令人惊喜的是,我还可以引入非结构化数据和AI模型来进行协作。在此基础上,我添加了一个广告科学私有库,这个库中包含我创建的用于调用AI函数的库,以帮助我完成受众细分任务。
现在是添加Notebook的时候了,我添加了一个预先创建的用于受众细分的Notebook,该Notebook已预先配置为使用我的私有库。而这个Notebook最出色的部分是什么?我可以使用Python进行机器学习。
我的Clean Room已经准备好让我的供应商加入。现在,我切换到供应商的角色,选择了暗色模式,并加入了我的零售合作伙伴创建的Clean Room。我看到了他们带入Clean Room的所有资产,当我点击进入Audience Graph表时,我看到了与表相关的元数据,但没有看到实际的数据。这为良好的协作提供了完美的背景,同时确保我不会获取任何敏感信息。
现在轮到我带入我的客户数据了。但我的客户数据存储在Databricks之外的Snowflake Warehouse上,我不想为此创建一个自定义的ETL管道。幸运的是,我可以直接指定Lakehouse Federated表作为这个Clean Room的数据源,无需复制,无需ETL。这些Clean Rooms确实为跨平台协作提供了规模化的解决方案。
我检查了Notebook中的代码,看起来不错,于是我运行了它。作业已成功启动并在几秒钟内完成。我得到了令人满意的视觉结果,这些结果帮助我理解,我们可以基于客户的年龄、收入水平和家庭规模等因素,将广告活动定位给120万户家庭。

让我们回到幻灯片,总结我们刚刚看到的内容。我们的零售商和供应商能够将各自的客户数据带入一个隐私安全的环境,即Clean Room,并在不向对方透露任何敏感信息的情况下进行协作。无论他们身处不同的云、区域或数据平台,这都不重要。他们可以就不仅仅是结构化数据进行协作,还可以使用Python进行机器学习。
Matei Zaharia

我对Clean Rooms,特别是跨平台的Clean Rooms感到十分激动。我认为这将彻底颠覆许多行业的运作模式。能够在安全的环境下实时协作处理数据和AI是非常明智的举措。因此,我相信我已经让你对我们的方法有了全面的了解。我们坚信,为你的公司选择正确的治理和共享基础是未来成功的关键,而我们认为这需要一种开放和跨平台的方法。我们对Unity Catalog和Delta Sharing能够在短短几年内从一个想法变为几乎所有客户都在使用的工具感到无比兴奋。我们对它们的开放性同样感到兴奋。我们对合作伙伴充满期待,并邀请你加入这个开放的生态系统。尽管技术本身很重要,但真正令人激动的是技术能够做什么。
Alexander Booth
今天,我将与大家分享我们如何利用数据智能来获取竞争优势,并改变现代棒球的游戏规则。
你们大多数人可能都知道,棒球一直是一项数据驱动的运动,无论是比较棒球卡背面的统计数据,还是现代Moneyball时代。然而,在AI时代,数据如何被用于决策已经发生了翻天覆地的变化。过去,数据主要用于描述过去的表现;而现在,数据则用于预测,优化我们对未来球员表现的理解。
一个例子是我们如何利用数据和AI进行生物测量洞察。我们建立了预测模型,研究身体动作如何影响球的运动轨迹,从而制作出由AI指导的定制球,为每个独特的投手量身打造。此外,通过更深入地了解球员在挥棒时的移动方式,我们可以提供生物力学建议,以优化特定类型的击球。基于这些洞察,我们可以为我们的球员提供建议。如果你想打出力量,那就用力挥棒,尝试将球击出球场外。如果你只想击中球,那就打准。在小联盟时,我的教练总是告诉我要用力挥棒并弯曲膝盖。现在我们使用每秒300帧的高帧率来测量这一动作。这种姿势跟踪为我们提供了对受伤和工作量管理的进一步洞察。
姿势跟踪并不是我们唯一的新数据来源。我们还以每秒30帧的速率连续跟踪每场大联盟比赛中每个球员的位置。这为我们提供了前所未有的方式来衡量防守能力。通过了解球员的倾向、反应时间以及外野手在试图接住飞球时的移动方式,我们可以利用AI优化防守位置,以最大限度地增加球员完成出局的可能性。是的,也许我们在这方面过于出色了,几年前美国职棒大联盟因此改变了规则。但我们至今仍在使用这项技术。这助力我们在季后赛中取得了客场11胜0负的战绩,其中包括了精彩的主动防守表现,如抢本垒打和关键的双杀。

我们是如何改变这个数据和AI的游戏规则的?我想说,这并非一蹴而就。实现这些成功并不容易。在我们开始数据现代化之旅的几年前,我们面临了许多挑战。
如果下面任何一点听起来似曾相识,请告诉我。我们的本地堆栈无法满足这些新数据来源的规模。这些本地服务器的维护成本上升,导致AI投资的回报率不可持续。此外,随着我们的数据团队不断壮大,支持遍布全国的小联盟运营以及全球范围内的侦察工作,治理和权限管理变得难以掌控。我们缺乏统一的治理,陷入了碎片化的孤立状态。
我们的数据团队被分为小联盟球员发展、业余分析、国际和高级侦察等多个团队。这种孤立的处理方式导致了球员和教练所需的报告延迟。在某些情况下,我们甚至要等到次日才能提交报告,而比赛已经结束了。虽然我们没有与球场连线的直播链接(可能是由几年前某个垃圾桶敲击事件引起的),但我们的球员仍然需要在比赛结束后尽快收到信息,以准备应对接下来的比赛,并在明天取得胜利。
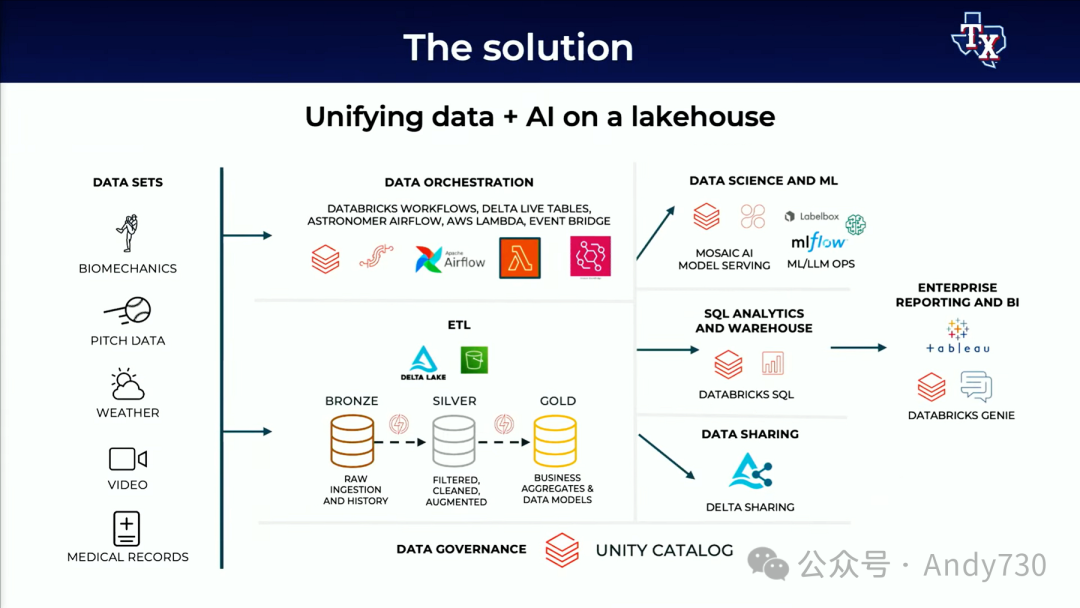
为了解决这些问题,我们在Lakehouse上统一和简化了我们的数据和AI堆栈。Unity Catalog将我们分散的数据整合到一个平台下。我们拥有各种包含敏感信息的数据,如球员地址和财务合同信息。此外,生物力学和医疗记录也不应广泛地在整个组织中共享。Unity Catalog使我们能够拥有一个单一的共享平台,并制定适当的权限设置,以符合内部和外部法规,如FERPA和HIPAA。
Unity Catalog还协助我们在JSON元数据中管理集群ETL管道。一旦数据加载完成,我们的数据智能平台还能对数据进行评论,并生成关于数据实际内容的AI摘要,这极大地方便了我们的分析师找到正确的数据源。
最后,我们在这些数据基础上构建了数百个ML和AI模型。Unity Catalog管理的ML注册表为我们提供了一个绝佳的平台来组织和搜索这些模型。此外,Unity Catalog还让我们能够管理哪些数据团队有权访问来自特征存储库的模型和功能,以支持他们自己的项目。这些详尽的数据谱系让我们能够清晰地看到数据从源头流向建模,并最终形成球员所需的最终BI报告的过程。透明度建立了信任,数据共享则使我们能够与部门内的其他数据垂直领域和供应商建立紧密的联系,包括球场、餐饮业务,以及分享球迷与球队互动的实时数据。这一切都在严格的权限管理下进行。

最终结果是:我们现在拥有比以前多四倍的数据,而成本却与传统系统相同,用于AI。我们有数百名用户分布在全国和全球各地,他们安全、受管理地访问这些数据和ML KPI。比赛和训练结束后,我们的数据洞察速度提高了10倍,能迅速将球员所需的报告交到他们手中,让他们能充分发挥出最佳状态。当然,所有这些都为我们首次赢得世界系列冠军做出了贡献。我试图让我的戒指一直闪耀着光芒,但它并没有拒绝。但Databricks确实在帮助我们的组织通过赋予团队数据智能而取得了胜利。然而,这只是开始。
随着生成式AI的兴起,我们已经投入时间和精力在这个新领域寻找创新。接下来,我将为大家做一个快速演示,使用Databricks AI/BI Genie为我们的数据提供自然语言界面。由于交易截止日期即将到来,且我们身在旧金山,我想看看旧金山巨人队是否有任何可能具有未来交易价值的球员。在这个应用程序中,我们使用了来自Baseball Savant的公共数据。请注意,这些表格以及应用程序都在Unity Catalog中受到严格管理。用户需要具有正确的权限才能访问。评论和摘要描述了并帮助Genie应用程序了解我关心的这些内部KPI,尽管它们对你可能并不重要,但对我来说却至关重要。当然,所有这些都需要在工作空间内共享和管理。
分析师可以针对这些数据提出广泛的问题。接下来,你们将看到我们将只寻找在巨人队中具有交易价值的球员。我知道我打字很慢。我猜你们可能会想:“你要做什么,电脑?”而我会说:“没关系,你可以假装我在打字。”Genie并不知道如何直接回答“交易价值”这个问题,它只会提供关于巨人队球员的统计数据。所以,我们现在可以告诉Genie我们更关心的是交易价值。我想看一下预期表现和观察表现之间的差异,以寻找被低估的球员。请注意,我们很快就看到Genie应用程序识别出路易斯·马托斯和马特·查普曼本赛季在巨人队表现不佳。但也许如果他们把路易斯·马托斯从三A级联盟召回,剩下的赛季表现会更好。但这只是个小插曲。
我们可以将此保存为一个token,并提供指示,以便日后轻松访问。我们还可以将这些数据可视化,以便快速理解。由于我们已经将其保存为token,现在对其他棒球俱乐部进行相同分析就变得轻而易举了。在这里,我要求它对芝加哥白袜队进行同样的分析。经过短暂的等待,结果就出现了。我们看到马丁·马尔多纳多和安德鲁·本顿迪在芝加哥白袜队表现不佳。
这使我们能够打破壁垒,让我们的分析师、SQL开发人员和不太技术的利益相关者前所未有地访问我们数据库中的原始数据。这使他们能够提出他们需要的问题,并为即将到来的交易截止日期设定目标和进一步决策的高效起点。
最后,我们始终致力于继续推动体育数据和AI的前沿发展。
Ali Ghodsi
接下来,我要向大家介绍我的联合创始人。他们说他曾是Apache Spark的头号贡献者,但经过核实,他现在位列第三。不过,在过去的七年里,他确实是Apache Spark项目的头号贡献者。接下来,他将为我们详细介绍Spark。令人惊讶的是,这个项目已经走过了超过10年的历程,所以你们可能会认为我们对Spark已经非常熟悉了,但实际上在过去的两三年里,它发生了巨大的变化。这个项目已经焕然一新,他将为我们揭示这一变化的背后故事,以及社区是如何推动这一变革的。
Reynold Xin
实际上,这次会议的内容在很大程度上源自之前被称为Spark Summit或Spark NII Summit的系列会议,而在此演讲中,我们将回归Apache Spark会议的初心。

三年前,在这个会议上,我们向在座的百位听众做了一个调查,询问他们在使用Apache Spark时面临的最大挑战是什么。迄今为止,最大的挑战在于,虽然有一群Scala用户深爱着Spark,这是很棒的,但他们同样拥有一大群Python用户。事实上,Python用户的数量更多,但他们并不真正了解Spark。Spark在Python中的使用相对笨重且困难,对他们来说不是一个理想的工具。其次,其他人则提到,虽然他们喜欢Spark并一直在使用它,包括使用Scala,但Spark应用的依赖管理简直是一场噩梦,版本升级可能需要花费6个月、一年甚至3年的时间,这完全取决于具体情况。
在语言框架开发者中,尽管他们的数量不多,但他们是Apache Spark社区中非常重要的部分。他们向我们反映,由于Spark紧密的JVM语言本质,作为框架开发者与Spark交互变得异常困难,而不仅仅是作为终端用户。因此,我们开始采取行动。首先,让我们来谈谈第一个问题,即Spark与Scala的紧密联系,但很多用户通常只使用Python。
如果你之前参加过这个会议,那么关于Python的讨论并不是第一次了。但我在前几天准备演讲时找到了一段视频,大约三年前的,是由Airbnb的数据工程师Zach Wilson分享的。Zach在视频中说:“另一个问题是,Spark实际上是基于Scala的,所以用Scala编写Spark作业是最自然的方式,因此Spark最有可能理解你的作业,并且出现问题的机会较少。”Zach认为,Scala是编写Spark作业的最佳选择,且更不容易出错。不仅是在这次会议上,我们听到了这样的声音,而且我们也开始付诸行动。
三年前,在这个会议上(那时可能还叫做Spark Summit),所有幻灯片的背景都是白色而不是黑色。我们讨论了Apache Spark社区的“项目Zen”倡议,它旨在全面提升Python的地位,使其成为一流公民。这包括API的改进、更好的错误消息、调试性能的增强,几乎涵盖了开发体验的每一个方面。
两年后,我们进行了项目报告,并讨论了在这两个Spark版本中所做的各种改进。去年,我们展示了一个具体的例子,说明了从Spark 2到Spark 3.4,自动完成功能有了多大的提升。

这张幻灯片总结了Spark 3和Spark 4中PySpark的许多关键功能,如果你仔细观察,它确实表明Python在Spark中不再只是附属品,而是一种一流的语言。实际上,PySpark提供了许多Python特有的功能甚至是习惯用法,这些在Scala中都是不可用的。例如,你可以定义Python表函数,用它来连接任意的数据源,这在Scala中要困难得多。
仅在今年这次会议上,我们就有超过八次的演讲专门讨论了PySpark的各种功能。我们付出了很多努力。但用户真正感受到了多少好处呢?我可以不停地解释,但最好的方式还是让你们亲自体验。实际上,它就像是一种全新的语言。仅在过去的12个月里,根据Pie Stats的数据,PySpark已经被世界上200多个国家和地区的用户下载。
我前几天进行了一些数据分析,当我看到这个数字时,真的感到非常惊讶。仅在Databricks平台上,针对Spark版本3.3及以上(不包括早期版本),我们的客户每天运行超过50亿个PySpark查询。为了让你们感受到这个规模,领先的云数据仓库每天大约运行50亿个SQL查询,这个数字与PySpark的查询量相匹敌。而这只是PySpark整体工作负载的一小部分。
最酷的是,当我找到Zach之前发布的视频时,他在视频中说:“嘿,Scala是原生的方式。”但最近我找到了他大约三个月前发布的另一个视频。直到上周我才与Zach见面,当时我联系他询问:“嘿,你介意我展示你的视频吗?”现在,请允许我播放一下Zach今年的这段视频。数据工程领域已经发生了变化。Spark社区在支持Python方面取得了显著进步。因此,如果你正在使用Spark,你会发现PySpark和Scala Spark在Spark 3中的区别实际上已经非常小了。
如果你对Spark的印象还停留在“Spark是用Scala原生编写的”,那也没错。我们确实很喜欢Scala。但如果你有这样的印象:“如果我使用Python,会遇到疯狂的JVM堆栈跟踪,收到糟糕的错误消息,API也不符合使用习惯”,那么请再试试看。现在的Spark与三年前已大不相同。当然,我们的工作永无止境,我们会继续提升Python对Spark的支持。但我认为,现在说“Python已成为Spark的一流语言”是合情合理的。
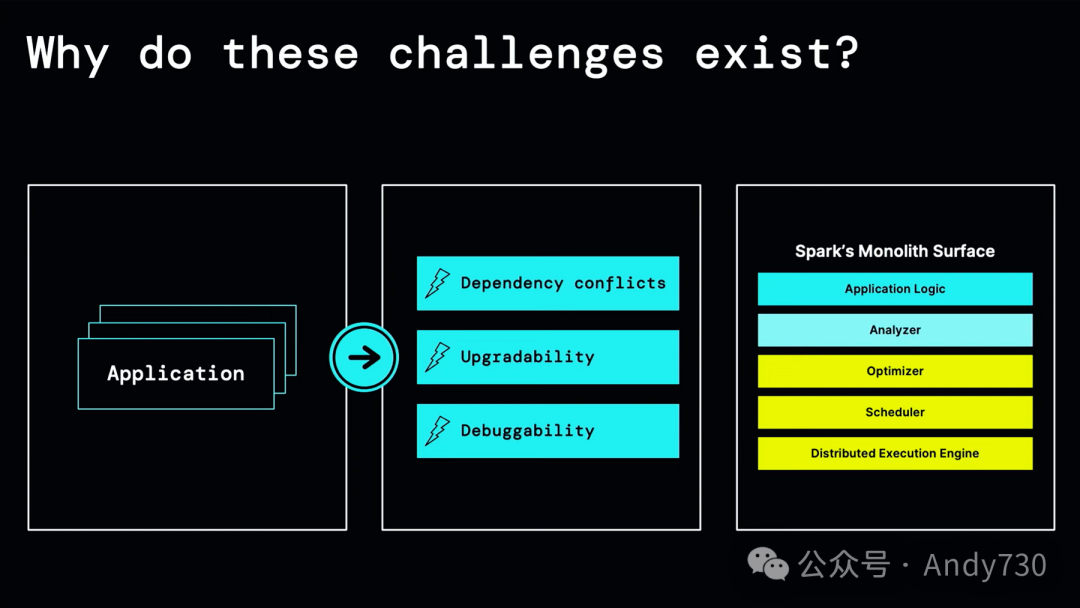
接下来,我们聊聊版本升级、依赖管理以及JVM语言的问题。Spark的设计方式是,所有编写的Spark应用程序——包括ETL管道、数据科学分析工具、Notebook逻辑——都在一个名为驱动程序的单体进程中运行。这还包括Spark的所有核心服务器端组件。因此,实际上,所有应用程序并不在客户端或服务器上运行,而是独立地在同一个运行着相同单体服务器集群的进程中运行。这就是问题的核心所在。首先,因为它们都运行在同一个进程中,所以应用程序必须共享相同的依赖关系。它们不仅彼此共享相同的依赖关系,还要与Spark本身共享相同的依赖关系。这使得调试变得困难,因为为了附加调试器,你需要附加运行所有这些内容的进程。最后,如果你想要升级Spark,你必须升级整个服务器,并在一个步骤中升级服务器上的每个应用程序。这是一项非常艰巨的任务,因为它们都紧密耦合在一起。
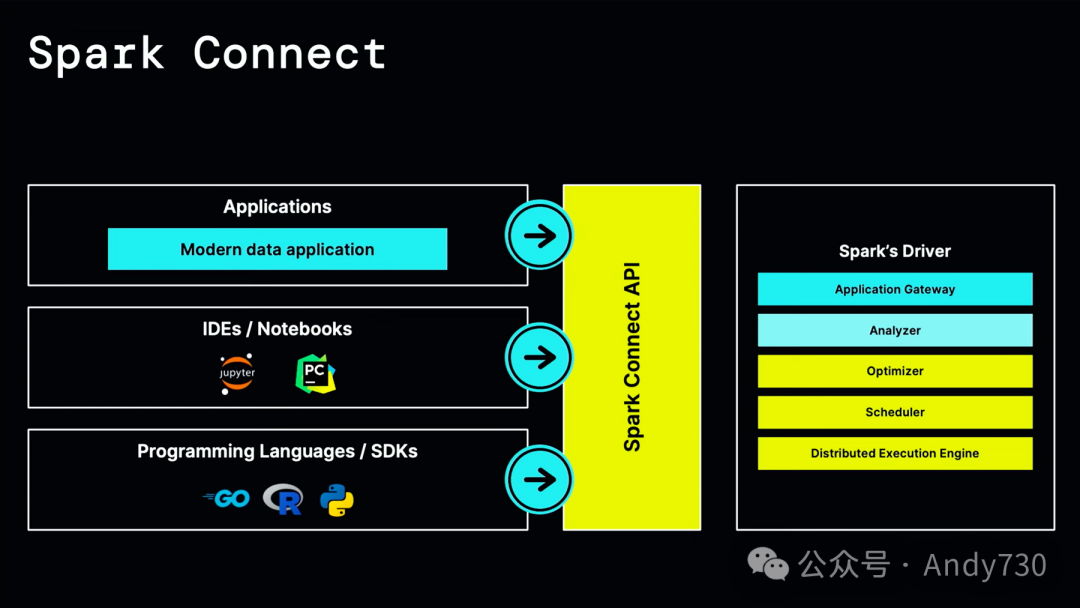
两年前,在这个会议上,Martin和我向大家介绍了Spark Connect。Spark Connect的概念其实非常简单:利用gRPC和Apache Arrow,基于Spark的DataFrame和SQL API(无论是Python还是Scala)创建一个与语言无关的绑定。从API的角度看,这似乎只是一个小改动,因为它只是引入了一个新的语言绑定和一个新的与语言无关的API。但实际上,这是自DataFrame API引入以来,Spark最大的架构变革。
有了这个与语言无关的API,现在所有其他内容都作为连接到这个API的客户端运行。因此,我们把这个单体系统拆分成了可以想象为在各自环境中运行的微服务。这对端到端应用程序有何影响呢?现在,不同的应用程序实际上将作为连接到服务器的客户端运行,但它们在自己的隔离环境中运行。
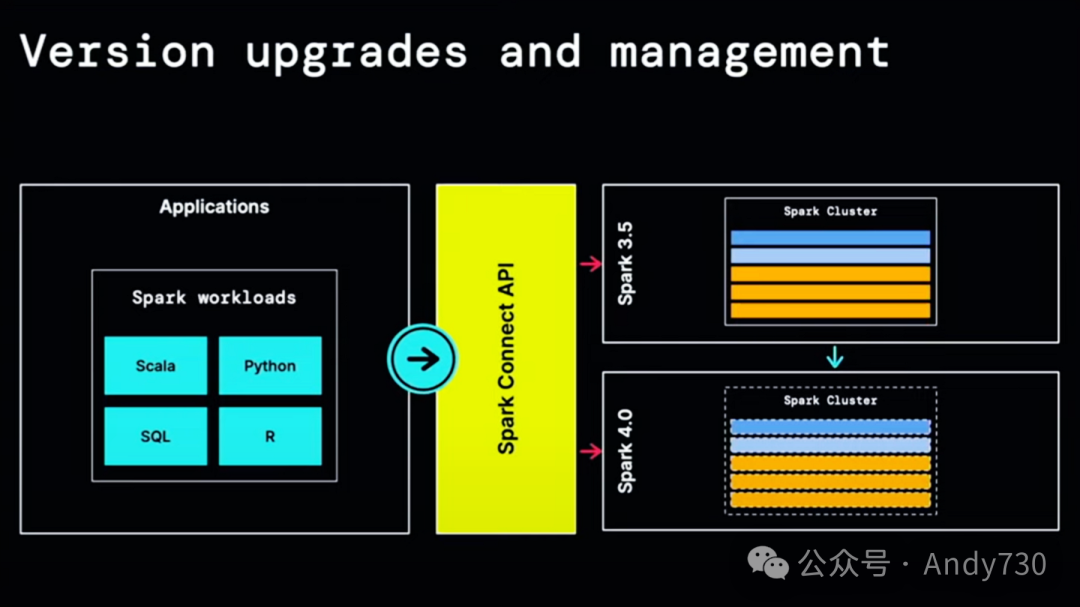
这使得升级变得轻而易举,因为语言绑定在API层面被设计为向后兼容。因此,你可以升级Spark服务器端,比如从Spark 3.5升级到Spark 4.0,而无需升级任何单独的应用程序本身。你可以按照自己的节奏逐个升级应用程序。
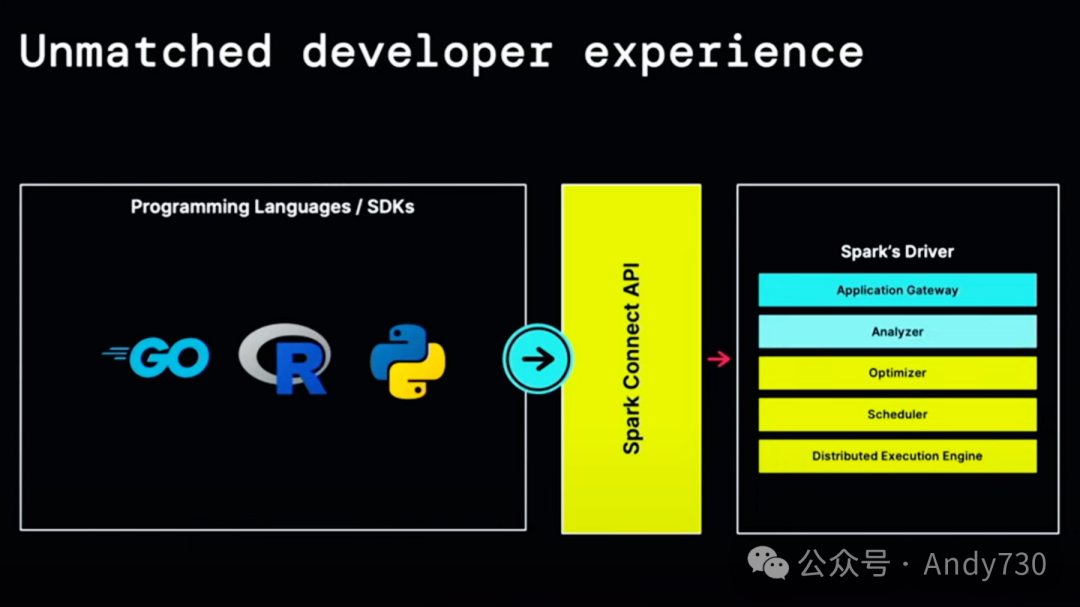
对于所有语言的开发者来说,这个与语言无关的API极大地简化了新语言的构建。仅在过去的几个月里,我们就看到了许多社区项目,构建了R绑定、Rust绑定和C#绑定。这些都可以完全在项目之外构建,拥有自己的发布节奏。

R和Python可能是数据科学中最流行的两种编程语言。Spark内置了对Python和R(SparkR)的支持。但实际上,最受欢迎的R编程库并不是内置的SparkR,而是一个名为sparklyr的独立项目。sparklyr是由RStudio公司制作的。我曾与RStudio背后的人员交谈过,并告诉他们:“我认为RStudio是你们从未听说过的最酷的开源公司。”你们可能没听过他们,因为他们最近才改名为RStudio。但RStudio的人员创建了诸如Dplyr(定义了今天我们所享受的数据框架的语法)、ggplot(可视化的视觉语法)和RStudio(最流行的R IDE)这样的基础开源项目。创建Pandas的Wes McKinney也在RStudio工作。还有Apache Arrow。
Tareef Kawaf

我们是一家公益性公司,成立已有大约15年。我们的核心关注点是以代码为先的数据科学。我们的治理结构使我们能够长期思考问题。因此,我们的目标实际上是长期存在,并继续投资于这些开源工具。

我们一直在支持数百个R包,并支持RStudio IDE。如果你们一直关注我们,可能已经注意到,在过去的五年里,我们为Python生态系统添加了许多功能。因此,在某些情况下,我们提供了多语言解决方案,如Quito Shiny for Python、Great Tables等,这些都是我们拥有的项目的示例,而且我们还将在未来几年推出更多的项目。

在2016年,我们推出了名为sparklyr的包。之所以发布它,是因为我们希望为R用户提供一个符合Tidyverse习惯的实现。对于不了解的人来说,Tidyverse是一种编写R包和相关模式的哲学。
Spark的原始设计使得企业中的用户要使用它,必须在服务器上运行RStudio和R本身。去年Spark Connect发布时,我们非常兴奋,因为它最终解决了我们面临的一个关键问题:如何让最终用户无需进入JVM,就能直接通过客户端访问Spark。
从去年开始到年底,我们得到了对Spark Connect的支持,包括Unity Catalog。我们与Databricks团队合作,共同确保sparklyr和IDE对此有顺畅的支持。其中,最令人兴奋的事情之一是我们增加了对R用户定义函数的支持,这对用户来说意义重大。现在,你组织中的R用户可以参与使用Spark解决真正棘手的问题,并与Spark生态系统中的其他成员合作。
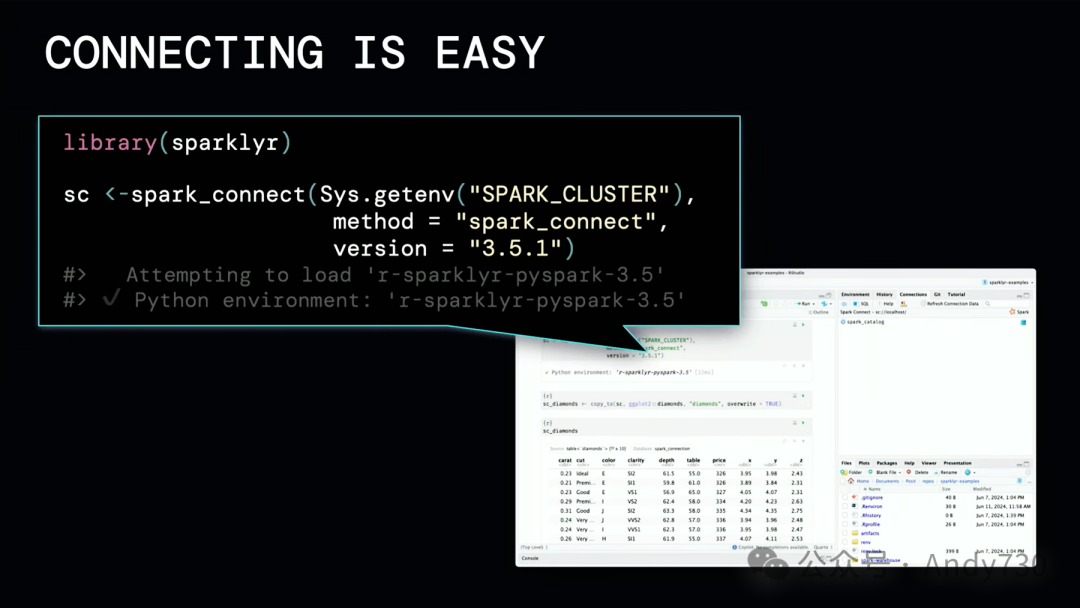
这是开源桌面IDE,你可以看到,只需一行更改即可连接到Spark Connect,现在桌面用户可以访问Spark集群,并利用其全部功能。我们认为这是一个关键因素,可以显著提高人们贡献和采用Spark的能力。
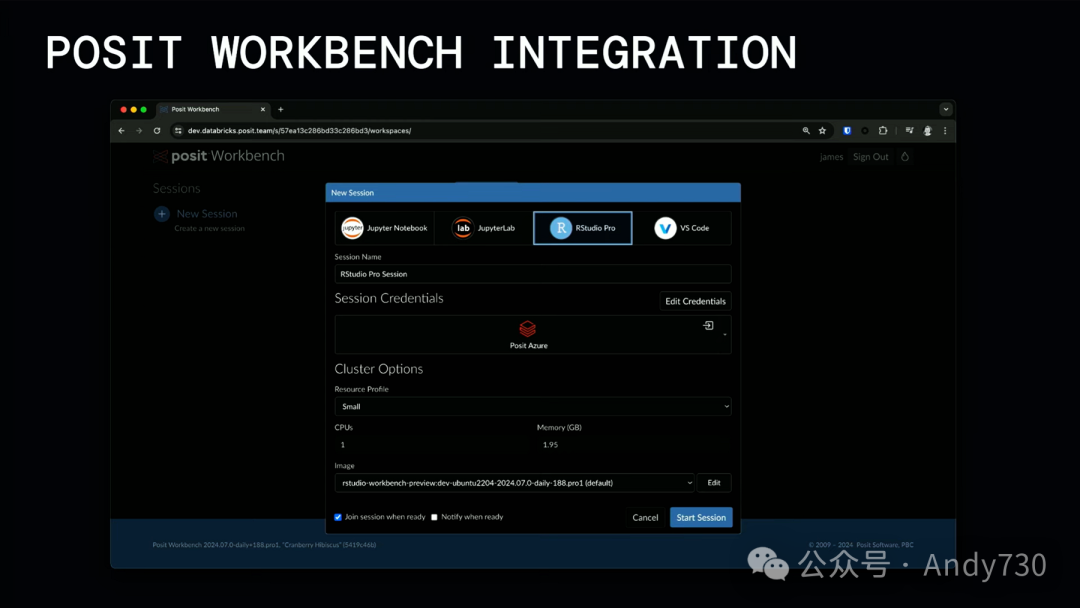
你可能已经注意到,在过去的一年里,我们一直在宣布与Databricks的各种合作。其中一个关键事项,显然是sparklyr、Spark Connect以及对其的支持,但我们也在商业产品上进行了一些调整。因此,我们支持的首个商业产品是RStudio Workbench,它提供了一个基于服务器的创作环境,支持我们的Studio、Jupyter Notebook、Jupyter Lab、VS Code,并与系统的认证和授权相结合。
因此,你基本上可以获得Databricks所拥有的所有治理能力,但将其呈现给他们的数据科学家。你可以期待,在未来一年中,我们将推出更多与Databricks堆栈紧密集成的商业产品和开源工具。如果你对此有任何好奇或兴趣,请随时查看相关链接,了解我们如何与Spark和Spark Connect更深入地合作,以及我们与Databricks的合作进展。
Reynold Xin
我对Spark Connect如此兴奋的原因是,它使得像sparklyr这样的框架成为可能。它简化了使用过程,易于采用、升级和构建。这实际上最终惠及了所有的开发人员、数据科学家和数据工程师,因为现在他们可以使用自己最熟悉的任何语言。这不需要将所有内容都构建到Spark中。现在,你可以在Spark上使用符合习惯的R。
通过Spark Connect,它真正试图解决升级Spark以及管理Spark的最后两个问题。它使得构建非JVM语言绑定变得更容易。随着这些发展,我们迎来了Spark 4.0。这实际上不是我们将宣布Spark 4.0的会议,但相关消息确实是今天发布的。这实际上是上游开源项目按照自己的节奏进行的工作。但Spark 4.0将在今年晚些时候发布。为了给你一些功能的预览,就像以前Apache Spark的其他主要版本发布一样,将会有成千上万的新功能。我今天无法一一列举。

Spark Connect将成为GA版本,NC SQL也将成为Spark中的标准。我们期待许多其他功能。在这次会议上,不同的开源社区有机会相互合作,特别是在计算和存储方面。许多功能实际上需要共同设计计算堆栈,这正是Apache Spark的专长,以及存储堆栈,这是Delta Lake Foundation的Delta Lake和Apache Iceberg的专长。
事实上,在这次会议上听到的许多功能,以及Ken演讲中谈到的功能,不仅局限于Delta或Iceberg,而是Spark的功能。实际上,这些功能需要这三个项目共同思考才能发挥作用。这正是开源精神和开源合作精神的体现。
尽管Spark 4.0尚未正式发布,但上周Apache Spark社区已正式发布了Spark 4.0预览版。这不是最终版本,但它可以让你一窥Spark 4.0的样貌。
Ali Ghodsi
Spark如今的表现简直令人惊叹。此外,所有关于版本管理、安装以及管理Spark的事项都变得更加简单。我仅仅在一周前尝试了一下,你只需要打开任意终端,然后输入pip install pyspark,一切就搞定了。这与10年前截然不同,那时你需要设置服务器、守护进程等,并在本地模式下进行配置和使用。现在,只需pip install pyspark,一切就安装好了。
回到我们的数据智能平台路线图,现在我们已经接近尾声,但对我而言,接下来要介绍的内容最令人激动。
这个项目起源于几年前,我们向所有使用Databricks的顶级CIO们提问:“你最希望Databricks做的第一件事是什么?”得到的答案出乎我们的预料。从那时起,我们就一直努力解决这个问题。
Bilal Aslam
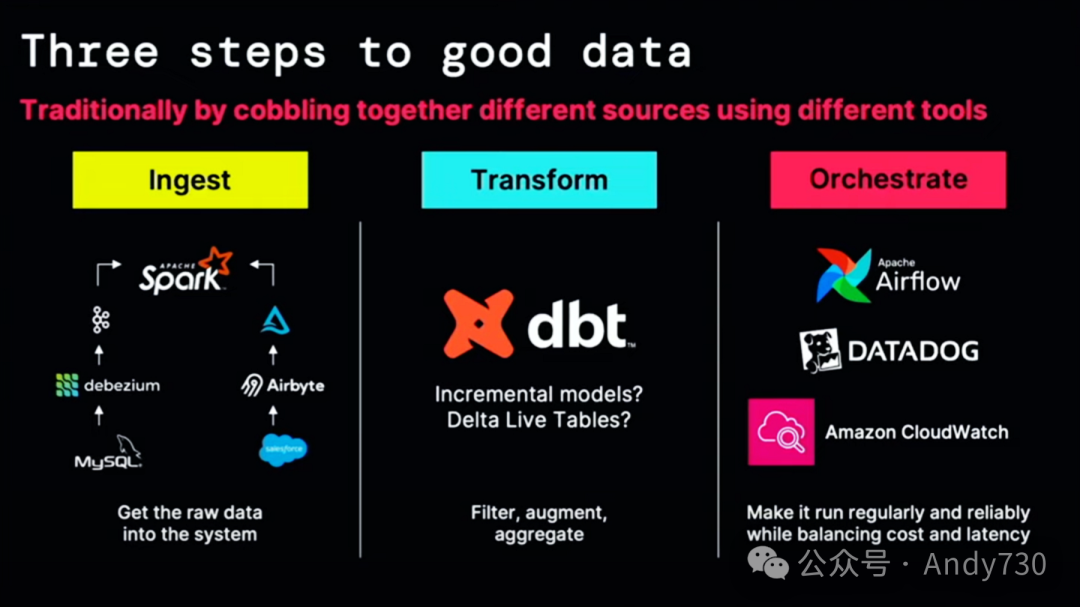
我们听说过机器学习、商业智能(BI)、分析以及这些令人惊叹的技术。但我要告诉大家,每一样技术都始于良好的数据。如何获取良好的数据?有三个步骤你必须遵循。我们每个人,包括我,传统上都在将许多不同的工具拼凑在一起,形成一个越来越昂贵、越来越复杂的工具链。让我为大家简要介绍一下。
Spark,特别是Databricks,在处理大数据方面已经非常出色。它是全球最大的大数据处理框架。但事实证明,许多真正有价值的数据有时可能是小数据。例如,你可能拥有MySQL、Oracle、Postgres等不同的数据库,它们都非常有价值。因此,你可能需要设置Debezium、Kafka以及监控堆栈和成本管理堆栈,仅仅是为了将这些系统的变更传输到Databricks中。
我敢肯定,每个人都在使用某种客户关系管理(CRM)系统。也许你在使用Salesforce、NetSuite,或者HRMS如Workday和NetSuite。这些系统中存储着大量有价值的数据,只需将它们导入Databricks,你就可以开始使用了。
一旦你的数据进入像Databricks这样的数据平台,接下来,下一步,就是对其进行转换。新收集的数据几乎永远不会立即被业务直接使用。你必须对其进行过滤、聚合、追加和清理。有很多技术选择——比如DBT,一个你可能听说过的优秀开源项目,或者PySpark中的Delta Lake表。Rold已经告诉你它有多受欢迎。你要选择哪一个?如何监控它?如何维护它?
一旦你的数据被转换,这实际上还只是战斗的一半。你需要通过在生产环境中运行你的生产管道来获取数据的价值。我不喜欢在凌晨两点被警报惊醒。因此,你现在必须进行编排。所以,你可能正在使用Airflow。很好。现在你的工具链又稍微扩展了一些。你需要负责管理Airflow及其认证堆栈等。然后,当然,你可能还必须在CloudWatch中监控所有这些事务。这既复杂又低效,实际上也非常昂贵。
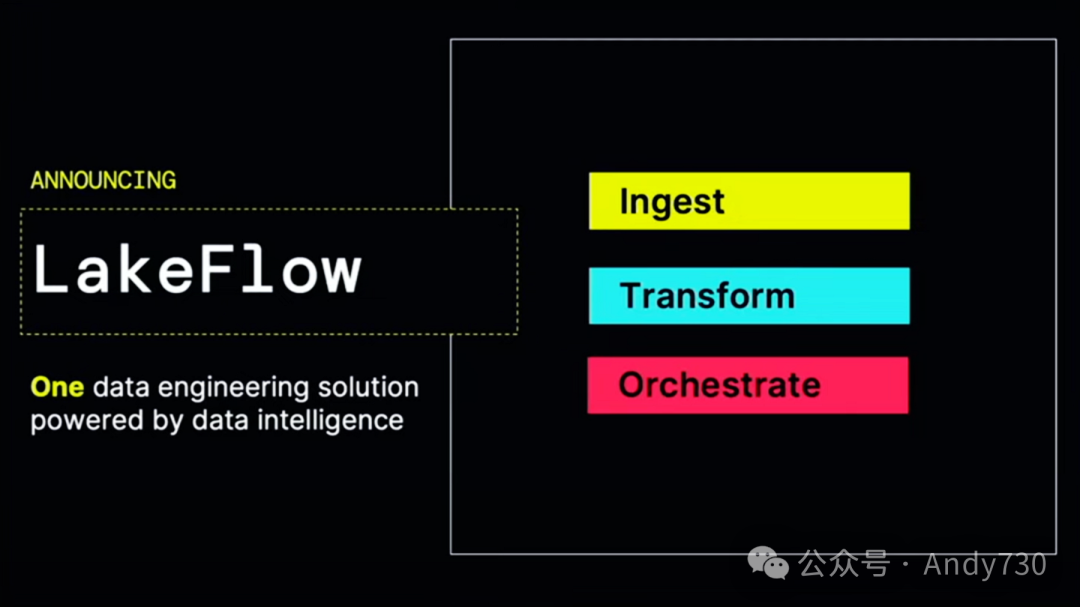
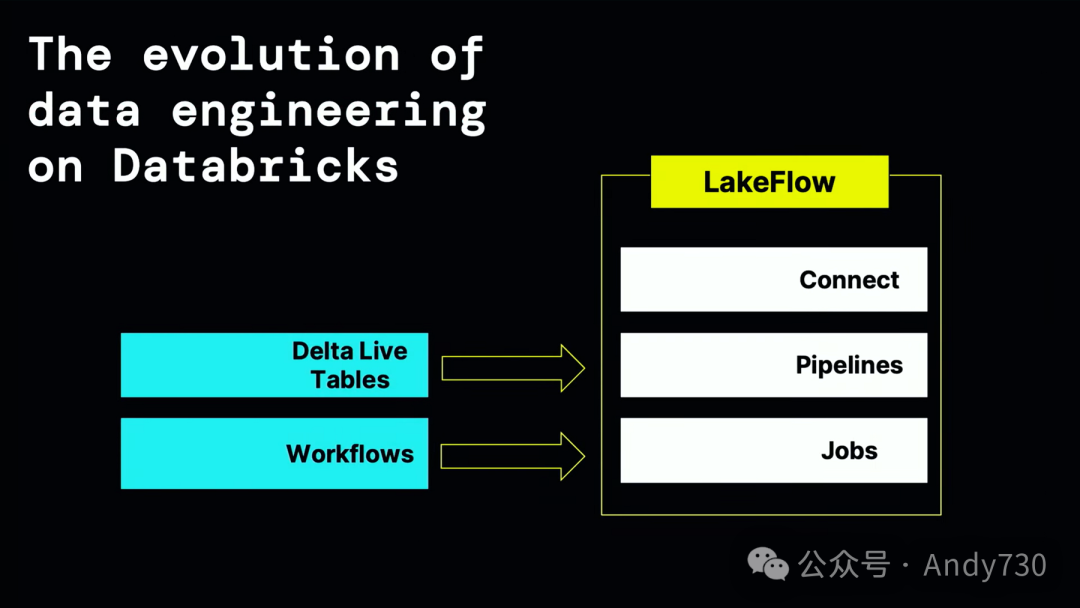
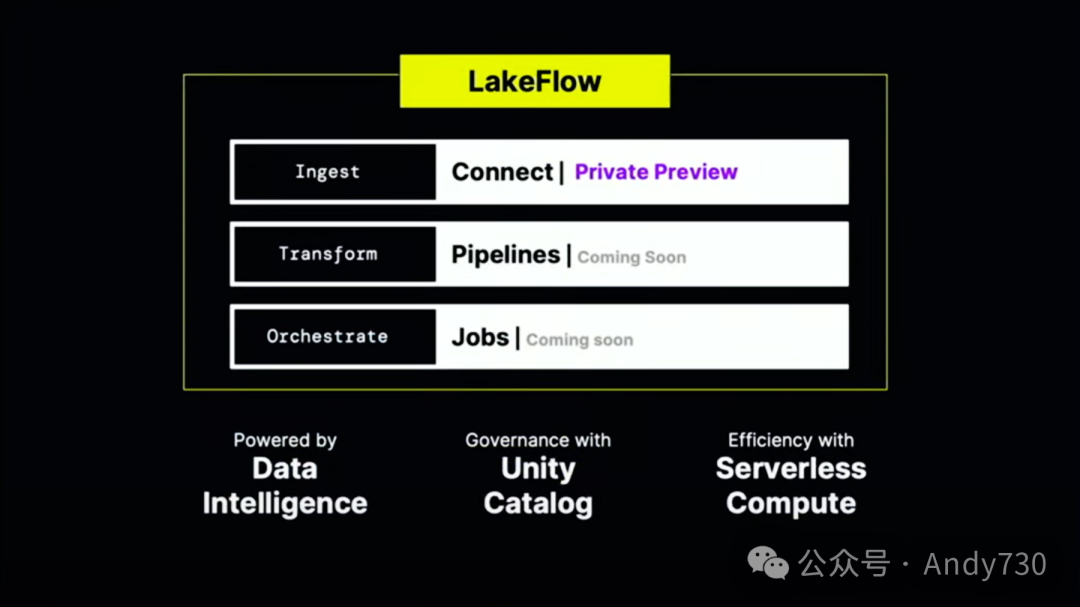
我非常自豪地推出我们称之为Databricks Lakeflow的新产品。它建立在Databricks工作流和Delta Lake表的基础上,再加上一些特别的创新。我想先从这个创新之处开始介绍。Lakeflow为你提供了一个简单而智能的产品,用于数据摄入、转换和编排。
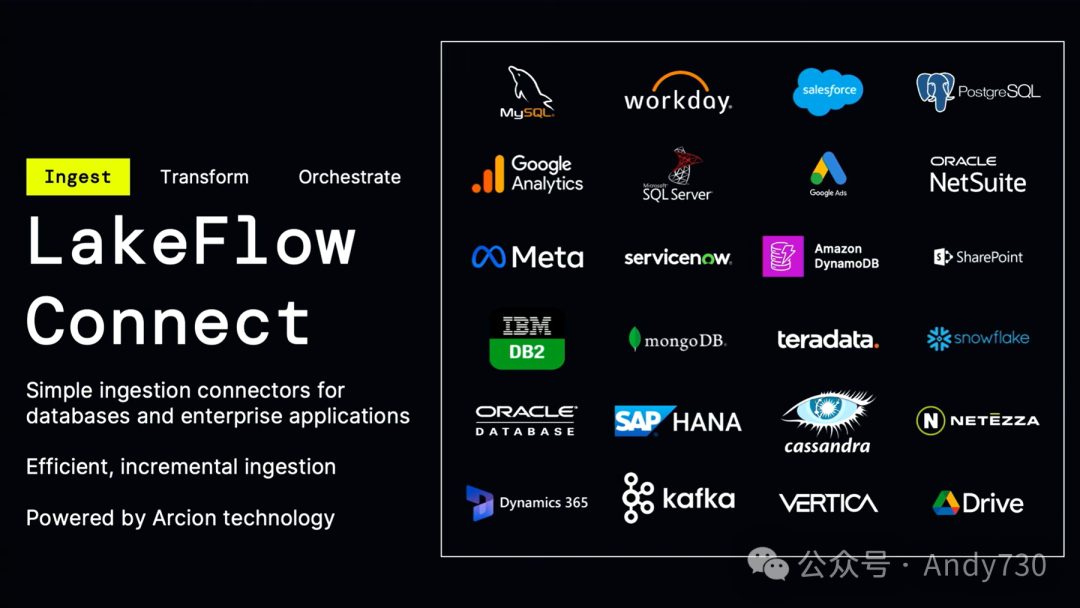
这三个组件中的第一个组件是我们称之为Lakeflow Connect的东西。Lakeflow Connect是专为数据湖设计的。这些原生连接器在性能方面非常出色,并且对于所有不同的企业应用程序和数据库都非常友好。如果在今天的听众中,你正在使用SQL Server、Postgres、传统数据仓库,或使用这些企业应用程序,我们的目标就是让所有这些数据都能简单地传输到Databricks中。这实际上是由我们去年收购的Arrikto提供支持的。我稍后会给大家做一个快速演示,但我现在想谈谈我们的一个客户,叫做Insulet。

Insulet制造了一种非常创新的胰岛素管理系统,叫做Omnipod,他们在Salesforce中存储了大量的客户支持数据。他们是我们的Lakeflow Connect的客户之一。通过这个产品,他们以前需要花费几天时间才能获得的数据洞察,现在只需要几分钟就能得到。这真是太令人激动了。
行动胜于空谈。让我们来看看具体操作。
现在,你已经在Lakeflow中了,我要做的是——好的,点击“摄入”选项。你看,这就是简单的点击操作,非常便捷,它是为每个人设计的。接下来,我点击“Salesforce”,我的朋友Eric Oren已经帮我设置了一个连接。顺便提一下,Lakeflow中的所有内容都由Unity Catalog管理,并由其提供安全保障,因此你可以非常轻松地管理和监控它。接下来是三个步骤——好的,非常顺利。
现在我看到了Salesforce中的这些对象,我选择“Orders”。实际上,我为Casey工作,如果你们还记得她的曲奇公司的话。我正在为她构建数据管道。作为CEO,她希望我能将一些订单信息导入到我们不断扩大的曲奇业务的数据目录和模式中。等等,好了。几秒钟内,数据应该会出现在我们的数据湖中。很好,完成了。就是这么简单,没有多余的步骤。
好的,我们回到幻灯片。

接下来,我想带你们了解一下背后的技术细节。作为工程师,我们都知道Lakeflow Connect背后其实发生了很多神奇的事情。你可能会想,“天啊,连接到这些API和数据库得多难?难道不能直接运行一个SQL查询吗?”

事实上,你真正想要的是获取这些源系统、数据库和企业应用程序中的新数据,也就是变更数据捕获(CDC)。这其实是一个非常复杂的问题。你不希望给源数据库带来过大压力,也不希望耗尽API的限制。数据必须按顺序到达,按顺序应用。事情难免出错,这是现实世界的常态,你正在将不同的系统耦合在一起。因此,你必须能够进行故障恢复。这些都是琐碎但重要的工作,我很高兴我们正在做这件事。借助Archon技术,CDC不再是一个复杂的难题。它变得简单、自动化,且一致可靠。这非常令人兴奋。
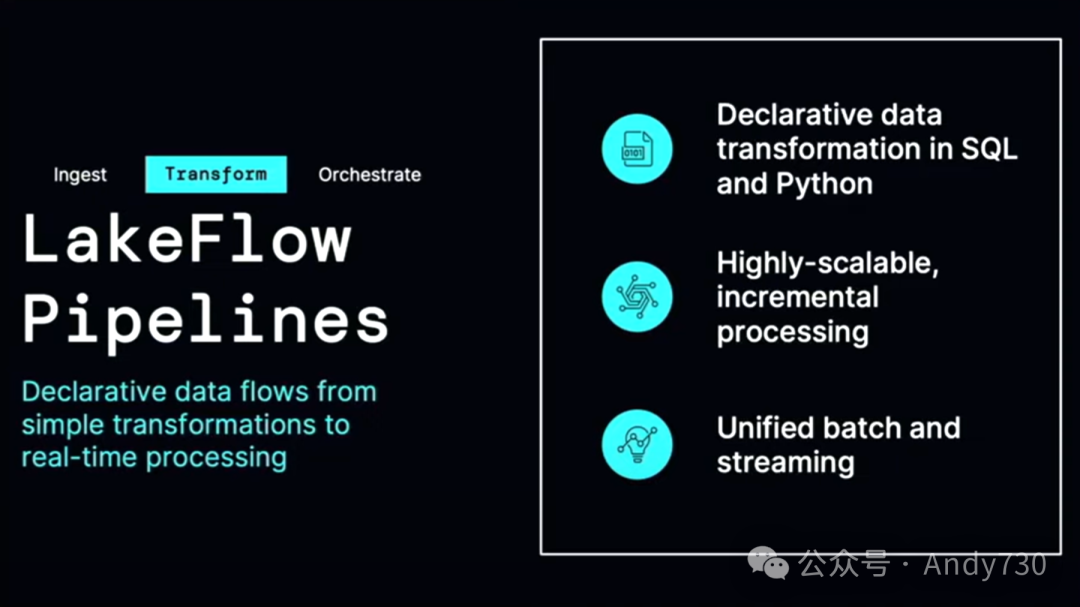
接下来,我们讨论这个产品的第二个组件。一旦你导入了数据,接下来会发生什么?你现在可以从这些数据库和企业应用程序中加载数据。接下来,你需要做的是转换数据,也就是进行预处理。请记住,你需要对数据进行过滤、聚合、连接和清理。这通常涉及编写复杂的程序,并处理许多错误条件。稍后我会为你展示这些。Lakeflow管道的神奇之处在于,它建立在Delta Live Tables的基础上,让你能够用简单的SQL来表达批处理和流处理。这种魔法技巧将你的工作转换为增量、高效且具有成本效益的管道。
回到刚才的话题。我刚刚进行了一些数据摄入操作。我还从SQL Server中拉取了数据,但这里不会展示那个流程。所以我现在有来自Salesforce和SQL Server的数据。
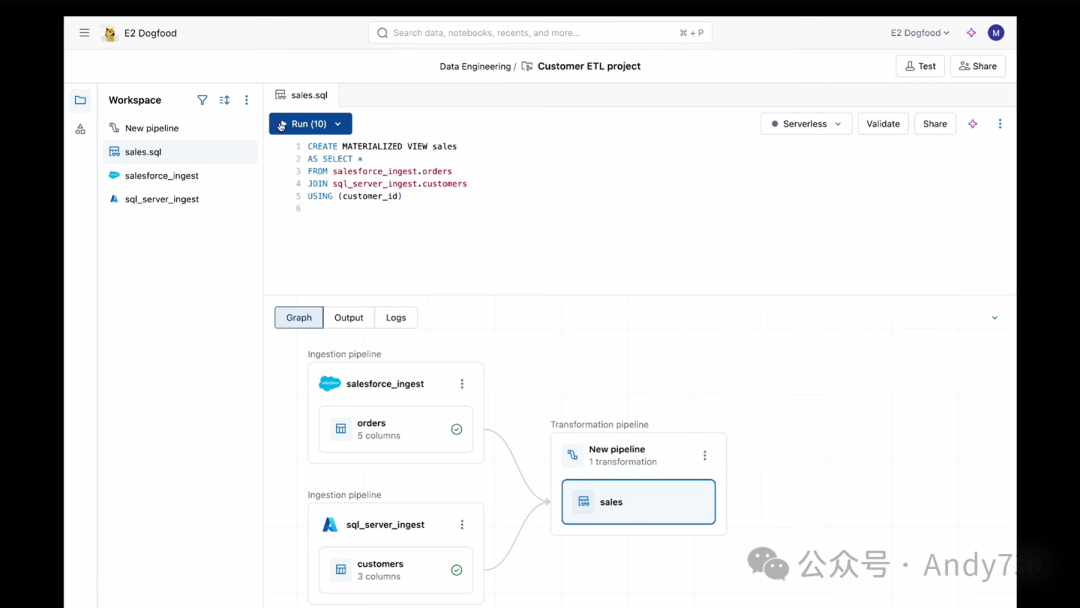
接下来,我需要对此进行一些汇总。
好的,让我向你展示在Lakeflow中进行这项操作是多么简单。这里有一个我非常喜欢的功能,那就是统一的画布。在底部,你可以看到一个小DAG(有向无环图),如果你想隐藏它也可以。但我现在要点击Salesforce并编写一个转换。
这是一个建立在智能数据智能平台上的智能应用。所以,我可能会继续询问助手它认为我应该如何连接。它给出了一个相当合理的连接建议。它说你可以连接这些表。我只是让它自动找出如何连接它们,找出关键字。
这真是太棒了。它找到了基于客户ID的关键字。我接受这个建议。让我快速运行这个转换。我不需要部署它,可以在开发环境中运行,这实际上让我能够快速调试它。
完美。我可以看到订单、日期、产品、客户等信息都已经很好地结合在一起。我得到了一个很好的数据样本。
好的,现在我们可以回到幻灯片了。

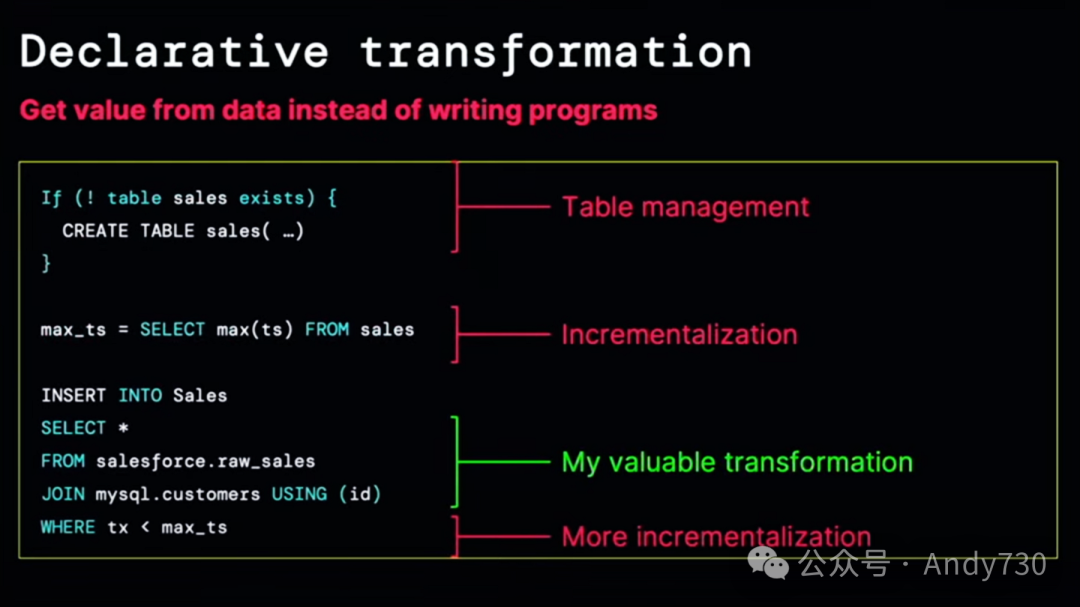


在这里,我想让你们了解一下背后的技术细节。为什么这令人惊奇?请注意,在这个过程中,没有复杂的集群设置,没有繁重的计算任务。我不需要设置基础设施或编写冗长的脚本。我只是写了一些SQL语句。这就是声明性转换的力量。如果没有Lakeflow管道,你将不得不多次进行表管理、增量更新,甚至处理模式演变。有些客户甚至编写了整个框架来处理模式演变和管理。再次强调,这些都是琐碎但重要的工作。为什么要在这上面花费时间呢?

Lakeflow管道是由物化视图驱动的。它们的神奇之处在于它们能够自动处理账务、模式演变、故障、重试和补充。它们能够选择正确的增量更新方式。
在我的工作环境中,我的CEO要求非常严格。随着我们电子商务网站的快速发展,现在我们需要实现网站上的实时操作。在这个看似批处理的流程中,我将引入一些流处理。我会将一些合并和丰富的记录写入Kafka。
让我演示一下这有多么简单,我们一起来看。
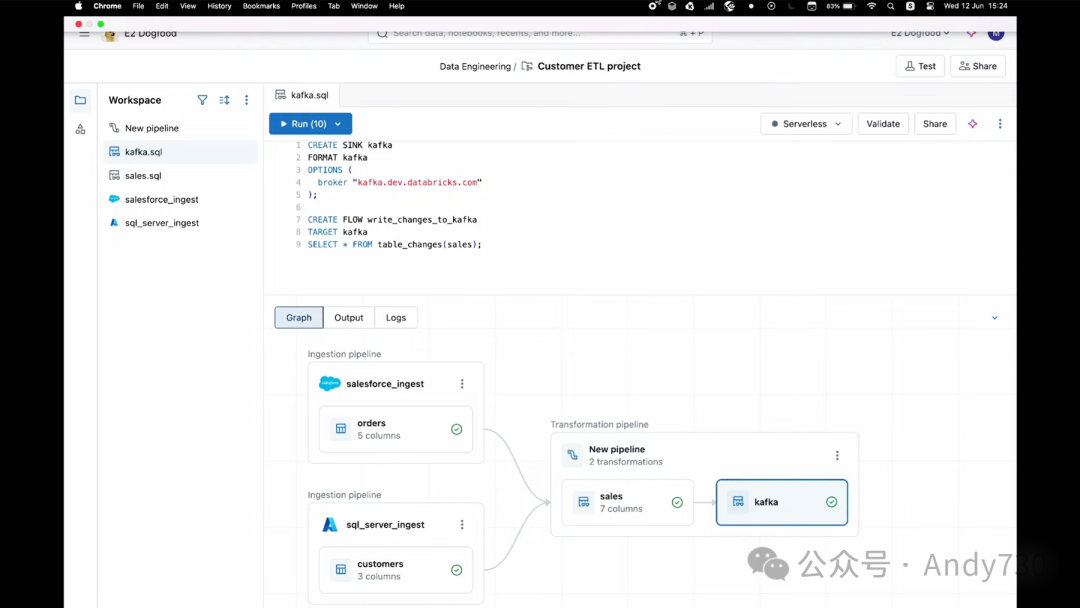
好的,这是工作流程。我进行了物化视图转换,因此再次从这个统一的界面中,我只需添加一个工作流步骤。接下来,我将进行实际操作。我要编写一些代码。我将创建一个名为“Sync”的组件。你可以将同步视为一个目的地。我只是将其命名为Kafka,因为我要将数据写入Kafka。我只需在这里编写SQL,并指向kafka.databricks.com,就可以创建一个同步了。所有的凭证都是通过Unity Catalog传递的,因此这是受管理的。
接下来,我要创建一个名为“flow”的组件。你可以将其视为将数据更改写入Kafka的边。我将设置目标Kafka,并从我刚刚创建的销售表中选择数据。我将使用表更改函数。请记住,这看起来像是一个批处理流程,但我会将其转变为流处理。就这样,我们的数据就已经在Kafka中了。
让我们回到幻灯片上。
这非常令人兴奋。这里不需要进行任何代码更改。我也不需要更改或选择另一个技术栈。所有东西都能协同工作。
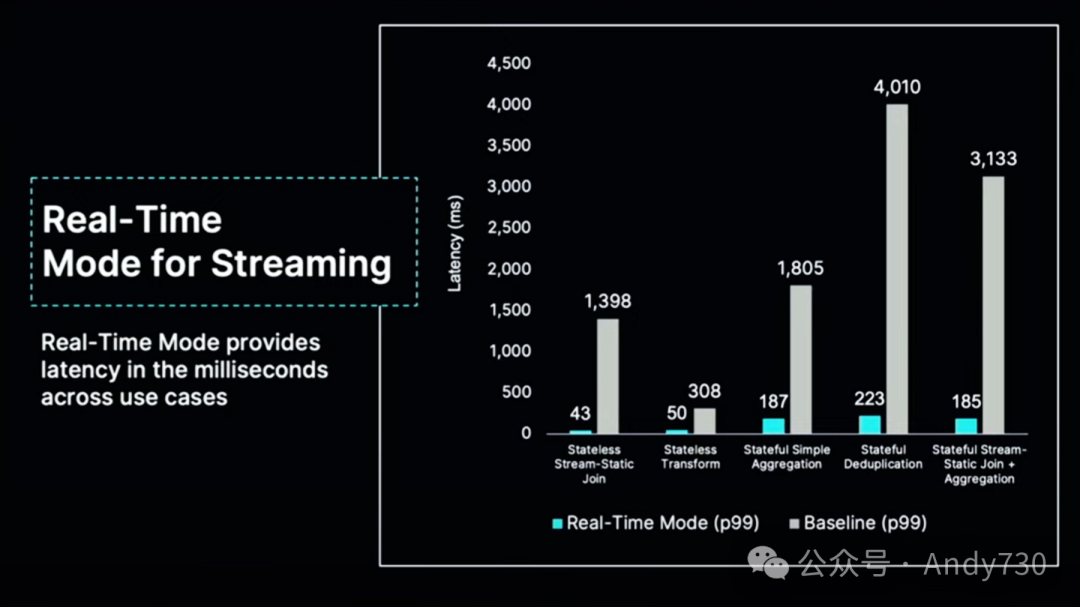
我们正在做的最酷的事情之一是称为流处理的实时模式。这种实时模式使流处理变得非常快,而且它的速度始终保持不变,而不仅仅是快一次或两次。因此,如果你有一个需要交付数据和洞察的操作性流处理用例,只需启用它,这个工作流将会非常迅速。
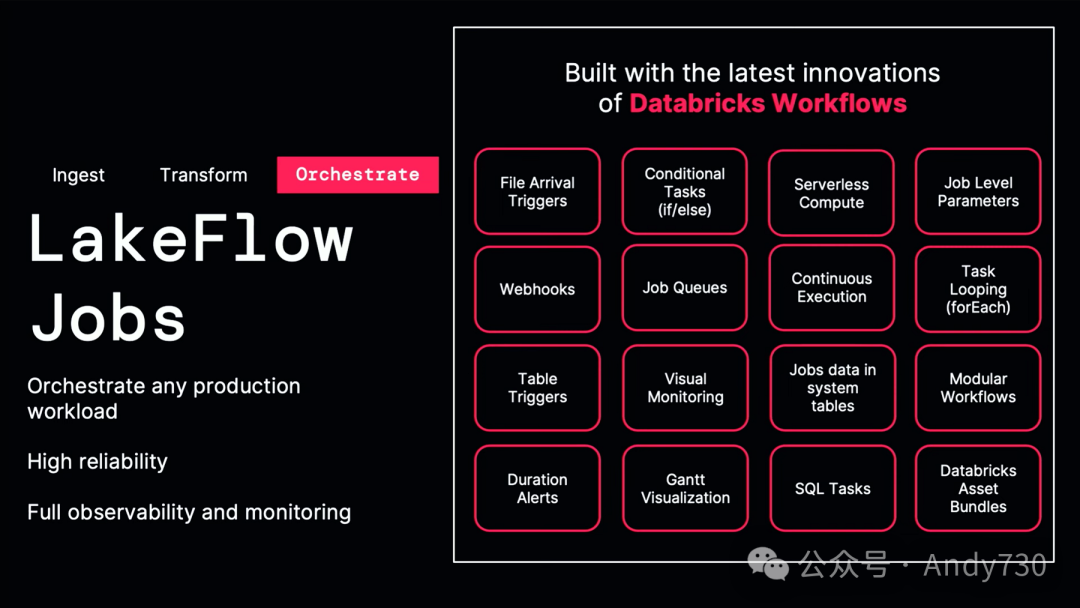
现在我从SQL Server和Salesforce中摄取了数据。我迅速构建了一个能够始终提供最新批处理和流处理结果的工作流。我不需要手动编排,但现在我的CEO要求很高。Cookie业务持续增长,Casey想要洞察,她想要一个可以了解业务状况的仪表盘。这就是编排的作用所在。编排实际上是关于如何做所有不涉及加载数据和转换数据的其他事情,比如构建仪表盘并运行或刷新它。
在Databricks中,我最喜欢的功能之一是名为Databricks Workflows的工具,它已经被我们发展到了下一代。Workflows是一个完整的编排器,不需要使用Airflow。Airflow虽然很好,但它已经完全集成在Databricks中了。这只是创新点的一部分列举。它具备许多传统编排器的功能。
现在我要做的是开始构建一个仪表盘,并在我的工作流完成后运行它。
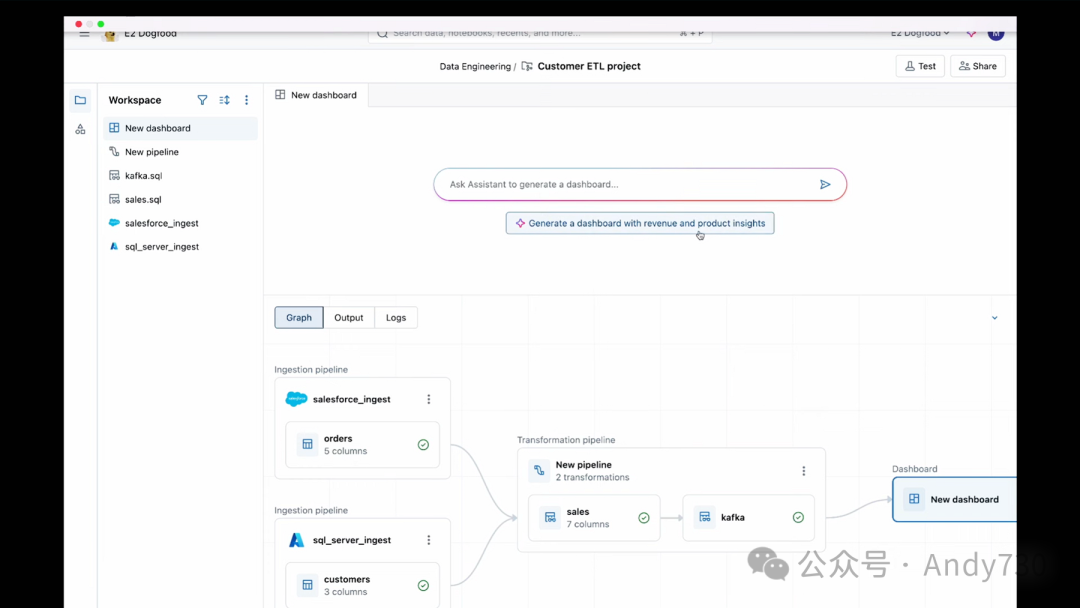
我们来看一下。请记住,我的数据正在进入Kafka。我将只添加一个步骤。我喜欢这个统一的界面,它很好地展示了我当前的上下文。这很酷。助手建议创建一个仪表盘。这很棒,实际上对收入和产品洞察非常有用。我很喜欢这一点。这正是我所期望的。让我稍微隐藏一下。就是它了,这是我们的仪表盘。好消息是,我们的Cookie业务持续增长。我们还没有完全完成业务,这很酷。我们实际上得到了一个很有趣的洞察,即糖饼干在十二月的销量通常很好。
就这样,你不需要做其他任何事情。
让我们回到幻灯片上。

我将快速总结一下。我对一个创新非常兴奋,我认为这将使我们的数据团队和数据工程师的工作变得更轻松。创建DAG(有向无环图)非常棒,运行一个接一个的任务很棒,为某些事情设置运行时间表也很棒。但是,随着组织的成长,你真正想要的是触发器。触发器是在新数据到达或数据更新时运行的任务。这使我们能够做另一个魔法,就是在需要时精确运行你的工作流。当上游表发生变化或上游文件准备就绪时,这非常酷。它完全包含在产品中,是LakeFlow任务的基础模块。
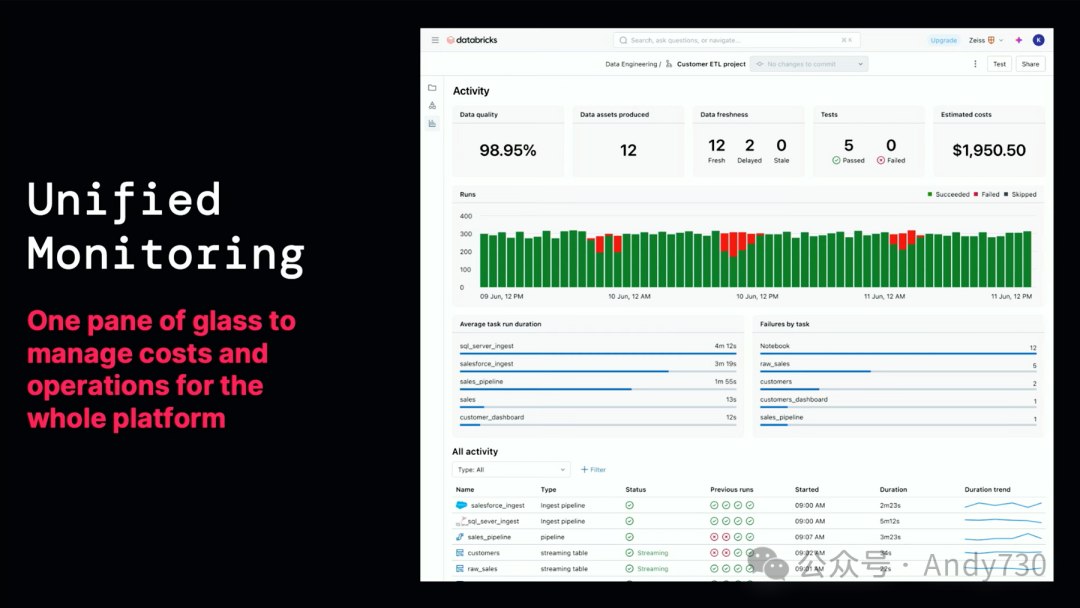
现在一切都在顺利运行。我已经成功摄取数据,进行了数据转换,并构建了一个仪表盘,同时我的工作流正在生产环境中稳定运行。正如我之前提到的,我讨厌在半夜醒来,通常我需要整合多个不同的工具来查看成本和性能。而LakeFlow提供了统一的监控功能,包括数据健康、数据新鲜度、成本和运行情况的全面覆盖。你可以随意进行调试,但即使没有调试需求,其单一的控制面板也能满足你的需求。

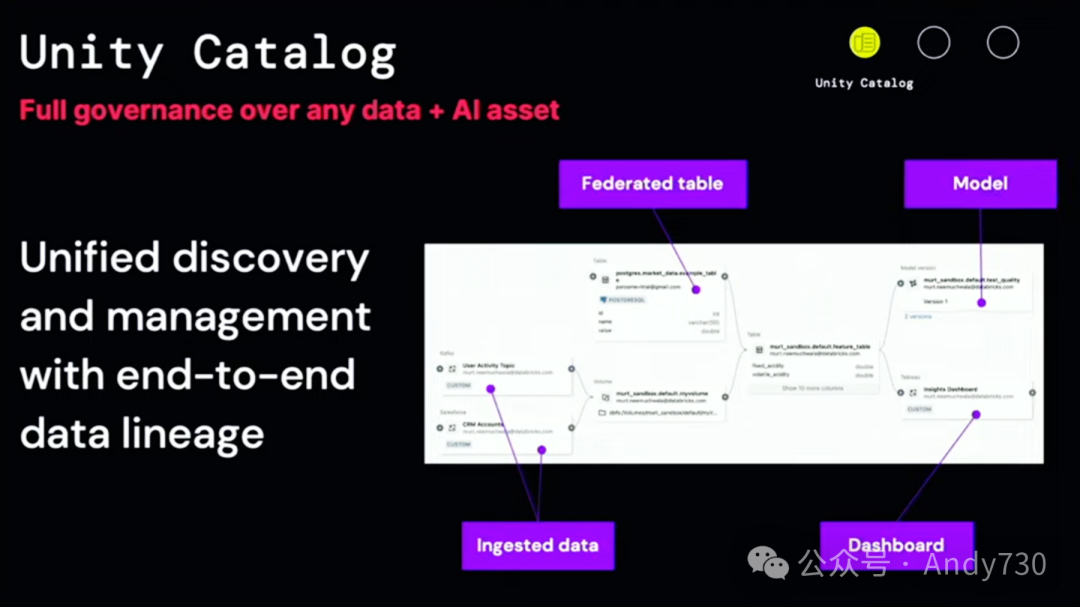
LakeFlow是基于Databricks Data Intelligence Platform构建的,与其原生集成,为我们带来了诸多强大的功能。通过Unity Catalog,我们可以获得完整的数据血缘追踪,覆盖所有已摄取的数据。来自Salesforce、Workday或MySQL的上游数据都已被成功捕获。数据血缘追踪还包括联合数据、仪表盘,甚至是ML模型,且这一切都不需要编写任何代码。
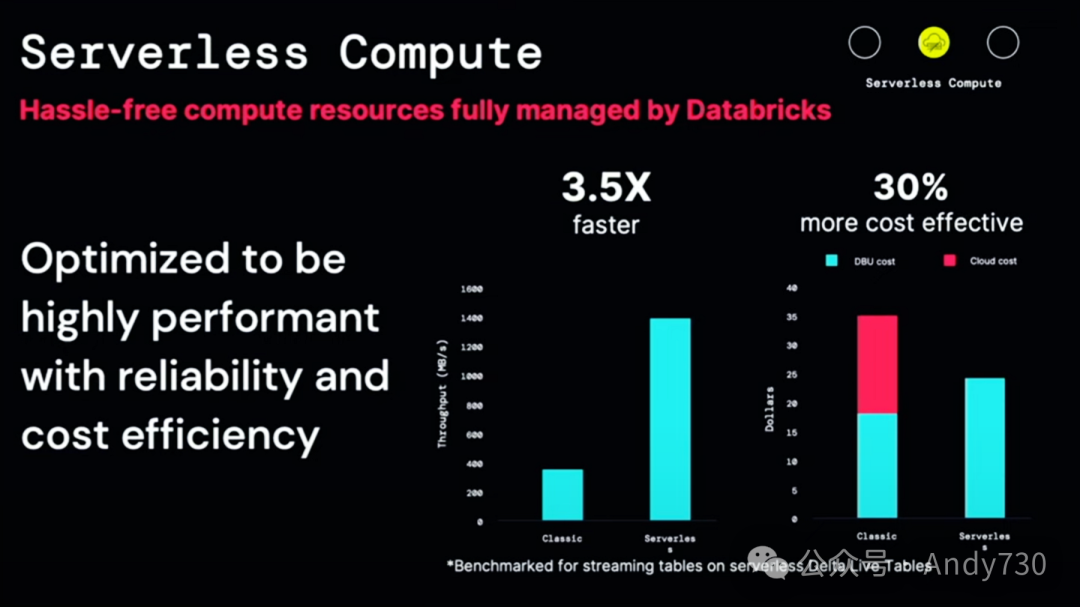
LakeFlow建立在无服务器计算之上,这大大减轻了你管理集群和实例的负担。它无服务器、安全,并与Unity Catalog完全连接,为你省去了许多麻烦。
真正令人兴奋的是,我们进行了一项基准测试。流摄入的实际数据速度达到了之前的3.5倍,同时成本效益也提高了30%。这真是鱼和熊掌兼得。这太令人激动了。

数据智能不仅仅是一个流行词。正如你在过去几天中所看到的,它实际上是Databricks的核心。
--【本文完】---
近期受欢迎的文章:
更多交流,可添加本人微信
(请附姓名/单位/关注领域)

