




核心内容
推理性能:MI300X在Llama 2 70B参数模型的推理任务中表现接近NVIDIA H100,但H200由于更大的内存容量和带宽,在推理性能上有56%的显著提升。 理论浮点性能:MI300X的FP16理论峰值性能为1.31 petaflops,高于H100和H200的989.5 teraflops,但在Llama 2推理任务上,单个MI300X只比H100高7%,比H200低40%。 扩展能力:8个MI300X的推理性能比单个提高2.01-2.11倍;4个H100的推理性能比单个提高2.6-2.73倍。
内存容量:MI300X配置了192GB HBM3内存,MI325X将提供288GB HBM3E,相比H100的80GB和H200的141GB有所优势,但H200在内存容量和带宽方面表现更为突出。 内存带宽:H200的HBM3E带宽达到4.8 TB/s,MI300X的带宽为5.3 TB/s。MI325X预计将提升到6 TB/s。
GPU互连:AMD使用Infinity Fabric互连技术,带宽为128 GB/s,而NVIDIA的NVSwitch提供高达900 GB/s的互连带宽,互连带宽差异达7倍,但对Llama 2推理影响不大。
软件栈优化:NVIDIA的CUDA和TensorRT栈在推理任务中的优化显著提升了H100和H200的性能。AMD则通过收购Silo AI来提升其软件优化能力。
GPU价格:H100的价格约为2.25万美元,H200接近3万美元,B200预计在3.5万至4万美元之间(可能会上升至5万美元)。相比之下,MI300X的价格在2万美元左右。 推理任务的单位成本:MI300X在推理任务中的性价比优于H100,但与H200相比略显逊色,B200的推理成本可能大幅下降。
未来GPU发展:MI350系列将采用CDNA 4架构,支持FP6和FP4,而NVIDIA可能在2025年将Blackwell B200的内存扩展至272GB。 市场定价策略:在供给短缺的情况下,NVIDIA可能提高B200的价格,并通过调整定价策略对AMD的MI325X形成价格压力,而未来市场价格将取决于内存供应和需求的紧迫程度。
-----
计算引擎的理论性能虽然颇具学术价值,但其实际应用表现才是关键。近日,由厂商主导的AI基准测试组织MLCommons发布了首批MLPerf AI训练和推理基准测试结果。这次测试对比了AMD Instinct MI300X "Antares" GPU与NVIDIA的H100、H200 "Hopper"以及B200 "Blackwell" GPU,结果令人鼓舞。
具体而言,测试结果显示,在某些AI推理基准中,MI300X确实能与NVIDIA的H100 GPU一较高下。根据我们对GPU及整体系统成本的估算,MI300X在价格和性能方面有望与NVIDIA的H100和H200 GPU展开竞争。然而,需要指出的是,本次测试仅评估了Meta Platforms的70B参数Llama 2模型,尽管这为我们提供了有价值的参考,但我们本期待看到更全面的测试,涵盖多种AI模型。毕竟,MLPerf不仅允许,还鼓励进行多模型评估。
对于MI300X及其未来平台而言,这无疑是一个良好的开端,也为当前数据中心GPU市场提供了一个有意义的快照。然而,展望未来,市场竞争的态势或将发生变化。到今年年底,考虑到NVIDIA Blackwell B100和B200 GPU的预期定价,NVIDIA可能通过提升性价比对AMD的MI300X加速器,甚至可能包括年底推出的MI325X GPU形成价格压制。当然,鉴于Blackwell GPU的重新设计和延迟出货,加上需求远超供应的现状,NVIDIA目前可能并不急于采取这种策略。我们预计,Blackwell GPU的价格将会上涨,其性价比可能不会显著优于H100、H200、MI300X和未来的MI325X。最终,市场价格可能趋于一致,具体定价压力将取决于实际需求的紧迫程度。
参考:
此外,值得注意的是,本次测试结果并未包括Meta Platforms最新的、更先进的Llama 3.1 70B参数模型。而在进行概念验证并推进AI应用生产化过程中,企业更可能选择后者。这一信息对于理解当前AI硬件市场的趋势和未来发展具有重要意义。
另一个引人关注的点是,AMD尚未公布AI训练任务的MLPerf测试结果。这一领域恰恰是业界最为关注的,因为它直接关系到AI硬件在实际应用中的性能和效率。我们预计,MLPerf Training v4.1的测试结果将于第四季度发布,很可能在SC24超级计算大会前夕揭晓。值得一提的是,MLPerf Training v4.0的测试结果已于6月份公布,但当时AMD并未提交任何结果。这一空白无疑增加了业界对于AMD在AI训练领域表现的期待和关注。
聚焦推理性能
近期有传闻称,AMD凭借MI300X在AI推理任务中赢得了超大规模数据中心和云服务提供商的重大订单。这或许解释了AMD为何选择在MLPerf推理v4.1基准测试结果发布后才采取行动。
我们对最新MLPerf推理结果的分析表明,MI300X在性能和性价比方面,尤其是在Llama 2 70B参数模型的推理任务中,确实可与NVIDIA的H100相媲美。然而,与配备141GB HBM内存和更高带宽的H200相比,MI300X的竞争优势略显不足。如果NVIDIA Blackwell系列的定价符合我们的预期,那么AMD的MI325X在今年晚些时候发布时,将需要配备更大容量的内存、更高的带宽,并且定价必须更具竞争力,以应对AI工作负载的需求。
以下是我们从近期发布的MLPerf推理v4.1中提取的关键基准测试结果:
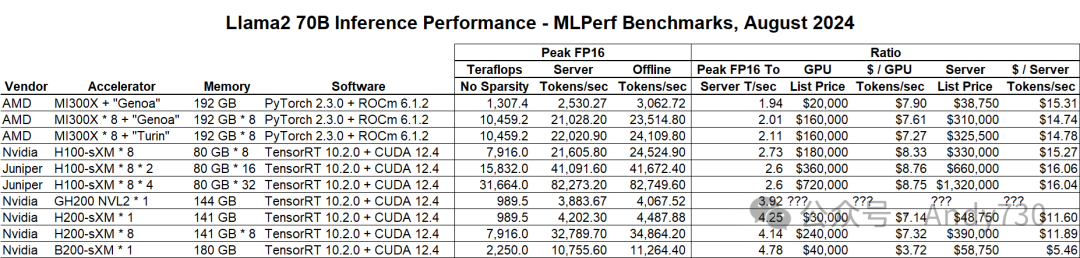
尽管多家服务器制造商对各种NVIDIA GPU进行了测试,我们仅选取了NVIDIA自身的测试结果,包括其近期在博客中讨论的单个Blackwell B200 SXM处理器上运行Llama 2 70B参数模型的测试。我们提取了所有NVIDIA的测试结果,同时纳入了即将被HPE收购的Juniper Networks在HGX H100集群上进行的两项测试结果,分别涉及双节点和四节点配置,共使用8颗和16颗H100。AMD则测试了一款配备当前"Genoa"霄龙9004系列处理器和8颗Antares MI300X GPU的标准通用基板(UBB)服务器节点,以及一台搭载即将发布的"Turin"霄龙9005系列处理器的机器,预计该处理器将在一个月内推出。

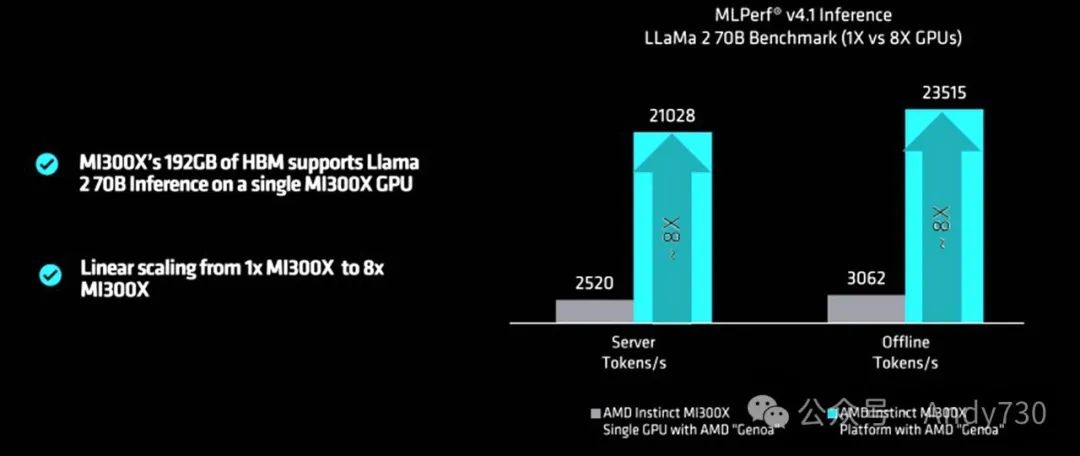
AMD展示了一张图表,展示了其中一台Genoa服务器上MI300X GPU的性能,凸显了GPU在单个节点内的扩展能力。
接下来,我们先讨论性能,然后再分析性价比。
在性能方面,我们关注的是AMD和NVIDIA设备在Llama 2推理任务中实际生成的token数量与其理论峰值浮点性能的关系。尽管基准测试中未包含GPU和内存的利用率数据,但我们可以做出一些合理推测。
AMD GPU配置使用Meta Platforms的PyTorch 2.3.0框架以及AMD的ROCm 6.1.2库和运行时(ROCm是AMD对标NVIDIA CUDA的技术)。MI300X的张量核心在FP16精度下的理论峰值性能为1307.4 teraflops,但在服务器模式下(模拟现实世界中随机查询的环境),单个MI300X运行Llama 2 70B参数模型时每秒生成2530.7个token。这意味着Llama 2推理性能与理论峰值浮点性能之比为1.94。随着系统扩展至8颗MI300X,并切换到更快的CPU,该比值略微上升至2.01和2.11。
参考:突破CUDA局限:ROCm、oneAPI、Chapel和Julia助力开放跨平台GPU编程
我们一直认为,H100 GPU由于仅有80GB的HBM容量和相对较低的带宽,在内存方面表现不足,主要原因是HBM3和HBM3E内存的供应短缺。MI300X似乎也面临类似的挑战。正如美国前国防部长Donald Rumsfeld所言,"你只能用手头的资源应战"。所有GPU厂商在内存配置上都有所不足,这不仅是因为他们希望销售更多设备,还因为在保持封装制造工艺良率的同时,很难将足够多的HBM堆栈安装在足够靠近GPU芯片(或芯粒)的位置。
观察NVIDIA测试的H100系统,我们发现服务器每秒生成的token与FP16理论峰值flops之比为2.6或2.73,优于AMD的表现。这可能归因于软件优化。CUDA栈和TensorRT推理引擎在H100上经过了大量调优,这也解释了AMD为何急于收购AI咨询公司Silo AI,该交易几周前刚刚完成。
随着H200切换到HBM3E堆栈,内存容量提升至141GB,带宽从3.35 TB/秒增加至4.8 TB/秒,该比值上升至4.25。NVIDIA的内部基准测试表明,仅通过增加内存容量和带宽,AI工作负载在相同的Hopper GH100 GPU上性能提升了1.6至1.9倍。
虽然难以准确预测MI300X在推理(以及训练)工作负载中需要多大的内存容量和带宽才能与其浮点性能相匹配,但我们推测即将发布的MI325X将在这方面取得重大进展。MI325X的带宽预计将达到6 TB/秒(相比MI300X的5.3 TB/秒),HBM3E内存容量将达到288GB(相比MI300X的192GB)。值得注意的是,根据我们6月的报道,MI325X的FP16浮点性能仍保持在1.31 petaflops。MI325X并未在峰值flops方面直接推动性能极限,现在我们理解了其中的原因。
我们预计明年发布的MI350系列将带来浮点性能的显著提升。该系列将采用与MI300A、MI300X和MI325X不同的CDNA 4架构,而非CDNA 3架构。MI350将采用台积电的3纳米工艺,并增加FP6和FP4数据类型支持。我们推测可能会有一个纯GPU的MI350X版本,以及一个集成Turin CPU内核的MI350A版本。
需要特别说明的是,AMD MI300X和NVIDIA H100之间的性能差异可能部分源于它们在各自UBB和HGX板上的GPU共享内存复杂体的互连技术。AMD使用的是Infinity Fabric,这是一种在PCIe 5.0传输上添加了HyperTransport内存原子操作的技术;而NVIDIA使用的是NVSwitch。每颗GPU的双向带宽为128 GB/秒,而NVLink 4端口和NVSwitch 3开关则为900 GB/秒,NVIDIA的内存一致节点互连带宽高出7倍。
这可能部分解释了Llama 2工作负载的性能差异,但我们认为并非全部原因,理由如下:
单颗MI300X在FP16精度下的峰值性能为1.31 petaflops,比H100或H200的989.5 teraflops高出32.1%。MI300X拥有2.4倍的内存容量,但在Llama 2推理工作负载上仅比H100高出约7%,而H200的推理负载却达到了MI300X的60%。根据NVIDIA的测试数据,MI300X大约完成了Blackwell B200(配备180GB内存)23.5%的推理工作量。
据我们所知,B200同样面临内存瓶颈。根据NVIDIA今年6月发布的路线图,B200和可能的B100将在2025年进行内存升级,预计容量将达到272GB左右。H200在内存平衡方面领先于MI300X,而MI300X将通过今年晚些时候发布的MI325X实现内存平衡,预计将领先B200"Blackwell Ultra"六至九个月。
如果我们在采购GPU,我们会选择等待Hopper Ultra(H200)、Blackwell Ultra(B200+)以及Antares Ultra(MI325X)。数据中心GPU只有在配备更多HBM的情况下才能真正物有所值。
然而,在实际情况下,我们并不总能等待最优的GPU出现。在生成式AI的竞争中,我们只能利用现有的GPU资源。
尽管对于Llama 2 70B参数模型的推理任务,节点间的高速互连可能不那么重要,但这并不意味着对于更大规模的模型或AI训练任务也是如此。因此,我们不应过早下结论。我们还需要等到AMD在今年秋季进行AI训练基准测试时再做最终判断。
性价比与应用场景契合
这引发了我们对MI300X与NVIDIA Hopper和Blackwell设备性价比的深入分析。
NVIDIA联合创始人兼首席执行官Jensen Huang在今年早些时候宣布Blackwell系列时表示,这些高端设备的价格将落在3.5万至4万美元的区间内。而根据配置的不同,Hopper GPU的价格则约为2.25万美元,这与Jensen Huang在2023年公开披露的一块满配HGX H100系统板价格高达20万美元的说法相吻合。我们初步估算,H200 GPU的单独售价可能接近3万美元,而MI300X的价格则可能在2万美元左右,但请注意,这仅是我们的推测,实际价格会根据客户及具体情况有所变动。市场价格受多种因素影响,如客户采购量,正如Jensen Huang常言:“买得越多,省得越多”,这主要体现了规模经济效应,而非加速计算带来的额外网络效应。
进一步地,我们粗略估算,要将这些GPU构建成功能完备的服务器——包括两个CPU、大容量主内存、网络卡以及必要的闪存存储——大约需要15万美元的预算。这类服务器能够灵活插入NVIDIA的HGX板或AMD的UBB板,从而构建出强大的八路机器。在评估单个GPU性能时,我们将GPU的成本以及假设中GPU系统配置成本的八分之一进行了合理的分摊。
基于上述分析,我们将GPU成本及其所在完整系统的成本与从Llama 2 70B参数模型的MLPerf推理v4.1测试中提取的性能数据进行了全面对比。
分析结果显示,MI300X在内存方面与H100存在相似的不平衡情况,但在性价比上却略胜一筹。根据对八路H100系统的推测,我们认为在服务器模式下(非通过批处理生成式AI查询以提高效率的离线模式),单颗H100每秒可能处理约2,700个token,这一性能较MI300X在Llama 2 70B参数推理中的表现高出约7%。而H200凭借其高达141GB的内存容量(是H100的两倍多),在推理性能上实现了56%的显著提升,同时GPU价格仅增加了33%,因此在GPU和系统层面均展现出了更高的性价比。
若B200的价格真如Jensen Huang所言达到4万美元,那么在Llama 2 70B参数模型推理测试中,单次推理的成本在GPU层面几乎会减半,而在系统层面则略多于减半(因为我们维持了服务器的基础成本不变)。
鉴于Blackwell的供应短缺现状,以及在有限的空间和热功耗限制下对更高AI计算能力的迫切需求,我们预测NVIDIA可能会将每颗GPU的售价提升至5万美元,这一预期我们早已有所准备。
当然,未来的定价策略还将受到AMD今年晚些时候对MI325定价策略的影响,以及AMD能否成功推动其合作伙伴加速生产这些关键设备。
Source:The First AI Benchmarks Pitting AMD Against Nvidia; Timothy Prickett Morgan; September 3, 2024
---【本文完】---
近期受欢迎的文章:
更多交流,可加本人微信
(请附中文姓名/公司/关注领域)

