




现代数据湖,有时也被称为数据湖仓(data lakehouse),是数据湖与基于开放表格式规范(OTF,Open Table Format)的数据仓库各占一半的结合体。两者均建立在现代对象存储之上。
如何构建全面支持AI/ML需求的AI数据基础设施,不仅要包含存储训练集、验证集和测试集的原始数据,还应涵盖训练大型语言模型所需的计算资源、MLOps工具链以及分布式训练等功能。
本文探讨如何利用现代数据湖参考架构来满足AI/ML需求。下图展示了现代数据湖参考架构,并重点标出了支持生成式AI所需的能力。
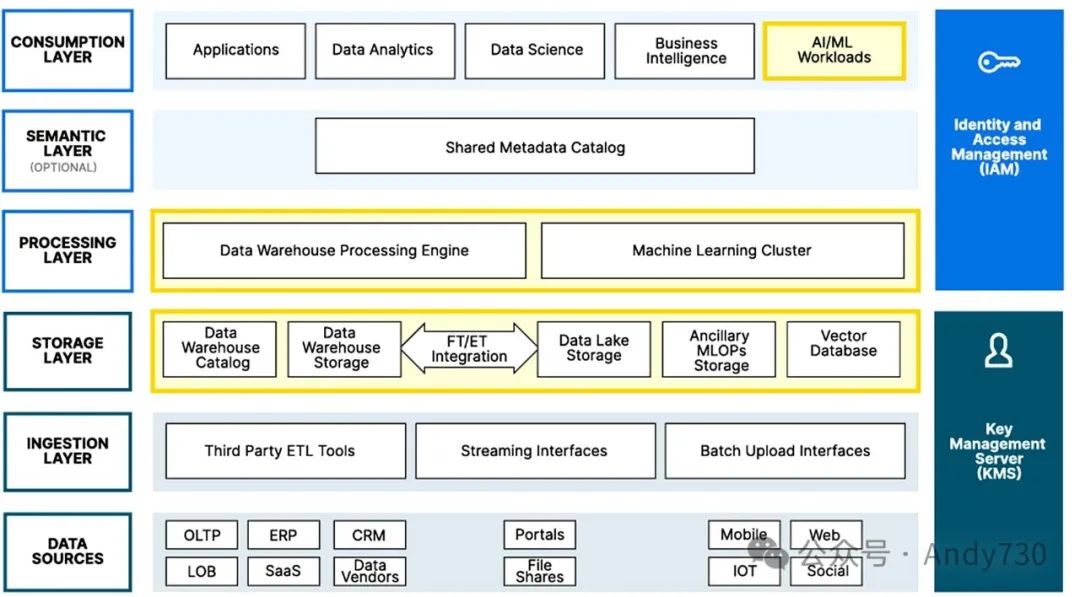
1. 数据湖
企业级数据湖以对象存储为基础。这里所指的并非传统的、以设备为基础的对象存储(主要用于大规模低成本归档),而是现代的、高性能的、软件定义的、Kubernetes原生的对象存储,它是现代生成式AI技术栈的基石。这类存储可作为服务提供(如AWS、Google Cloud Platform(GCP)、Microsoft Azure),也可在本地部署或采用混合模式,例如MinIO。
这些数据湖必须支持流处理工作负载,具备高效的加密和纠删码能力,能够将元数据与对象原子性地存储,并支持Lambda计算等技术。由于这些现代对象存储是云原生的,它们能与其他云原生技术栈(从防火墙到可观测性再到用户和访问管理)无缝集成。
2. 基于OTF的数据仓库
对象存储同样是基于OTF的数据仓库的底层存储方案。虽然用对象存储构建数据仓库听起来有些反常,但这种方式代表了新一代数据仓库。Netflix、Uber和Databricks制定的OTF规范使得在数据仓库中使用对象存储变得简单可行。
这些OTF包括Apache Iceberg、Apache Hudi和Delta Lake,是因为市场上缺乏能够满足创建者数据需求的产品而开发的。它们的核心功能(尽管实现方式不同)是定义一个可以构建在对象存储之上的数据仓库。对象存储提供了其他存储方案无法比拟的可扩展容量和高性能的结合。
作为现代规范,它们具备传统数据仓库所不具备的高级功能,如分区演进、模式演进和零拷贝分支。
- 开放数据湖仓 | Starburst(目录和处理引擎)
3. 机器学习运维(MLOps)
MLOps之于机器学习,犹如DevOps之于传统软件开发。两者都是一套旨在提升工程团队(开发或机器学习团队)与IT运维团队之间协作的实践和原则。其目标是通过自动化来简化开发生命周期,涵盖从规划、开发到部署和运维的各个阶段。其中一个主要优势是实现持续改进。
- Kubeflow(Google)
4. 机器学习框架
机器学习框架是用于创建模型和编写训练代码的库(通常是Python库)。这些库功能丰富,提供多种损失函数、优化器、数据转换工具和神经网络的预构建层。其中最重要的功能之一是张量(Tensor)。张量是可以被移至GPU上的多维数组,在模型训练过程中具有自动微分功能。
- TensorFlow
5. 分布式训练
分布式模型训练是指在多个计算设备或节点上同时训练机器学习模型的过程。这种方法能够加速训练过程,尤其在使用大型数据集训练复杂模型时效果显著。
- Spark TensorFlow Distributor(来自Databricks)
6. 模型中心
虽然模型中心并非严格属于现代数据湖参考架构的一部分,但由于其对快速启动生成式AI至关重要,仍将其纳入其中。Hugging Face已成为大型语言模型的首选平台。它托管了一个模型中心,工程师可以在此下载预训练模型并分享自己创建的模型。Hugging Face还开发了Transformers和Datasets库,这些库与大型语言模型(LLM)以及用于训练和微调它们的数据协同工作。
- Hugging Face
7. 应用框架
应用框架帮助将LLM集成到应用程序中。使用LLM与使用标准API有所不同,需要进行大量工作将用户请求转换为LLM可以理解和处理的内容。例如,如果你构建一个聊天应用程序,并希望使用检索增强生成(RAG),你需要将请求标记化,将标记转换为向量,集成向量数据库(如下所述),创建提示,然后调用你的LLM。生成式AI的应用框架允许你将这些操作串联在一起。
- TensorFlow(Keras API)
8. 文档处理
大多数组织并没有一个统一的、包含清晰准确文档的存储中心,而是将文档散落在各个团队的门户中,且格式多样。在为生成式AI准备数据时,首要任务是建立一条管道,筛选出已获批用于生成式AI的文档,并将它们导入向量数据库。对于大型跨国企业而言,这通常是最具挑战性的环节。
- Open-Parse
9. 向量数据库
向量数据库支持语义搜索。理解其工作原理需要大量的数学背景,较为复杂。然而,语义搜索在概念上很容易理解。假设你想找到所有讨论“artificial intelligence”相关内容的文档。要在传统数据库中实现这一点,你需要搜索“artificial intelligence”的每一个可能的缩写、同义词和相关术语。你的查询可能会像这样:
SELECT snippetFROM MyCorpusTableWHERE (text like '%artificial intelligence%' ORtext like '%ai%' ORtext like '%machine learning%' ORtext like '%ml%' OR... and on and on ...
这种手动的相似性搜索既繁琐又容易出错,而且搜索本身也非常缓慢。向量数据库可以接收类似下面的请求,运行查询更快且更准确。如果你希望使用检索增强生成,快速而准确地运行语义查询至关重要。
{Get {MyCorpusTable(nearText: {concepts: ["artificial intelligence"]}){snippet}}}
- Weaviate
10. 数据探索与可视化
- Streamlit
结论
以上是现代数据湖参考架构中的十项关键能力,以及对应的具体供应商产品和库。
以下是这些工具的汇总表。
数据湖: MinIO、AWS、GCP、Azure 基于OTF的数据仓库: Dremio Dremio Sonar Dremio Arctic Starburst Open Data Lakehouse | Starburst 机器学习框架: PyTorch TensorFlow 机器学习运维(MLOps): MLRun(麦肯锡公司) MLflow(Databricks) Kubeflow(Google) 分布式训练: DeepSpeed(Microsoft) Horovod(Uber) Ray(Anyscale) Spark PyTorch Distributor(Databricks) Spark TensorFlow Distributor(Databricks) 模型中心: Hugging Face 应用框架: LangChain AgentGPT Auto-GPT BabyAGI Flowise GradientJ LlamaIndex Langdock TensorFlow(Keras API) 文档处理: Unstructured Open-Parse 向量数据库: Milvus Pgvector Pinecone Weaviate 数据探索与可视化: Pandas Matplotlib Seaborn Streamlit
Source:The Architect’s Guide to the GenAI Tech Stack — 10 Tools; Keith Pijanowski; Jun 3rd, 2024
---【本文完】---
近期受欢迎的文章:
更多交流,可添加本人微信
(请附姓名/单位/关注领域)

