




概述 分析师观点 Kioxia光互连SSD技术及其在数据中心的潜在影响 Kioxia BiCS 8: 218层3D NAND如何重塑闪存制造工艺 演讲《KIOXIA:先进闪存技术释放AI潜力的新篇章》(PPT) 从芯片到系统:SK hynix的技术布局 对象计算型存储(OCS):SK hynix引领HPC存储技术新突破 NEO半导体3D X-AI技术:颠覆HBM,重塑AI芯片未来 MSI携手Samsung与MemVerge:CXL技术驱动下一代内存扩展服务器 Samsung突破128TB大关:BM1743 QLC SSD引领企业存储新纪元 Western Digital展示全方位创新闪存解决方案 Microchip发布Flashtec NVMe 5016 SSD控制器系列 Micron突破26GB/s:PCIe Gen6 SSD引领存储新纪元 Silicon Motion推出PCIe Gen5 NVMe 2.0 SSD控制器SM2508 突破100 DWPD:Phison的aiDAPTIVE+如何改变AI训练格局 突破内存瓶颈:Kove:SDM引领软件定义内存新时代 MaxLinear推出Panther III存储加速解决方案 Nimbus Data与Tesla联手打造:全球首个移动全闪存数据中心BatArray 参考资料
-----
概述
Fadu推出SSD控制器和基于CXL的解决方案。
Kioxia展示SSD光学接口、SSD RAID卸载技术和2Tb QLC闪存。
Kove展示Kove:SDM软件定义内存系统,该公司近期在与AWS的诉讼中胜诉。
MaxLinear重点推广Panther III存储加速卡。
Microchip发布新一代Flashtec PCIe Gen 5 SSD控制器。
Micron展示9550 NVMe SSD。
Nimbus Data推出多款产品,包括FlashRack Turbo、ExaDrive DC和EN(一款创新的以太网原生SSD,提供NFS接口的NVMe),以及HALO软件的最新版本。
Phison展示aiDAPTIV+技术和Pascari产品线。
Pliops展示XDP LightningAI平台。
Samsung展示多款CXL解决方案、新型HBM内存,以及128TB容量的BM1743 SSD。
Silicon Motion展示SM2508,一款高能效的PCIe Gen5 NVMe 2.0客户端SSD控制器。
SK hynix重点展示计算对象存储系统,同时展出321层NAND和HBM解决方案。
西部数据展示多款产品,包括各类SSD、OpenFlex Data24 4200 NVMe-oF和RapidFlex适配器。
ZeroPoint Technologies发布zstd解压缩硬件IP。
厂商参会情况:
缺席厂商:Atto、Bittware/Molex、Kalray、Lightelligence、Montage、Panmnesia、Seagate、Solidigm、Swissbit和Tuxera。 降低赞助级别:Marvell。 重返展会:Micron、Phison。 首次参展:Kove、UnifabriX和ZeroPoint Technologies。 值得注意的是,Kalray与Pliops预期中的合并未能达成,这也是Kalray缺席的原因之一。然而,Pliops在这种交易中接受80%的价值缩水令人费解。 本次会议议程新增了冷数据流主题,并邀请了Cerabyte或Biomemory参与讨论。 分析师观点
Coughlin Associates总裁Thomas Coughlin:
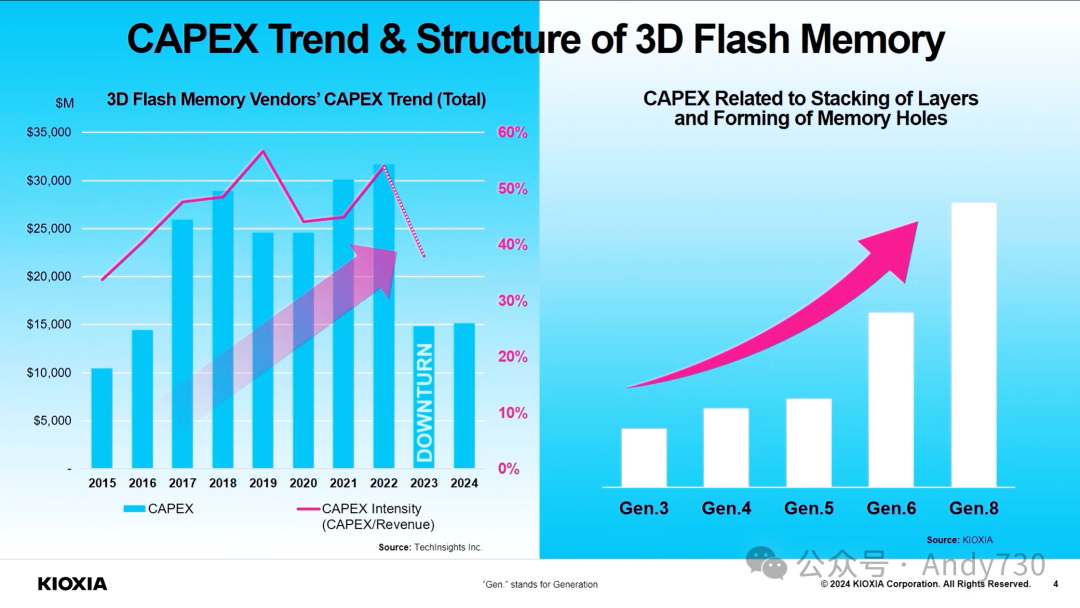
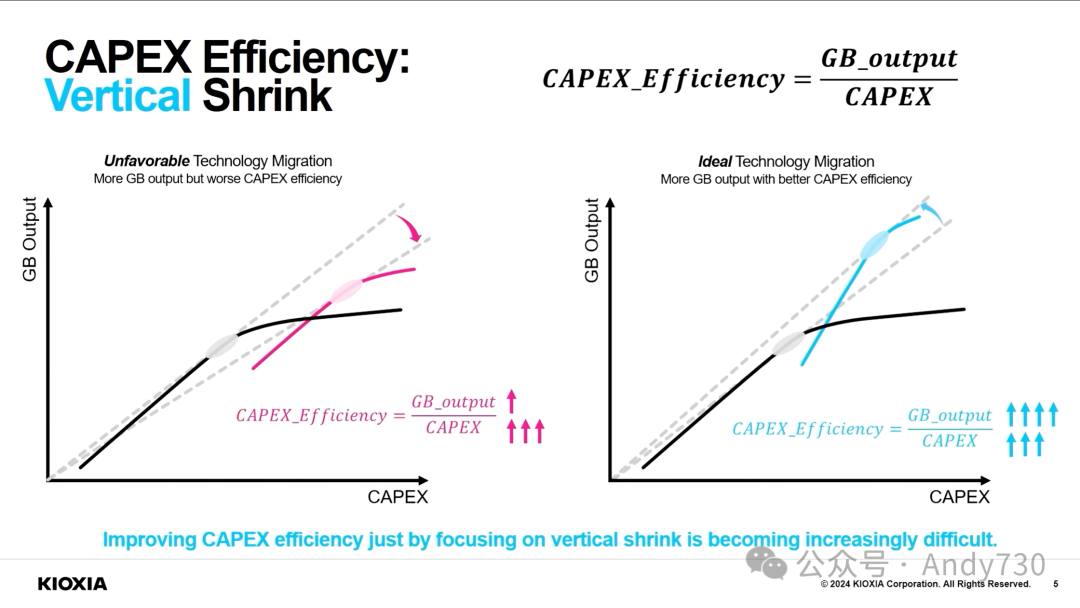
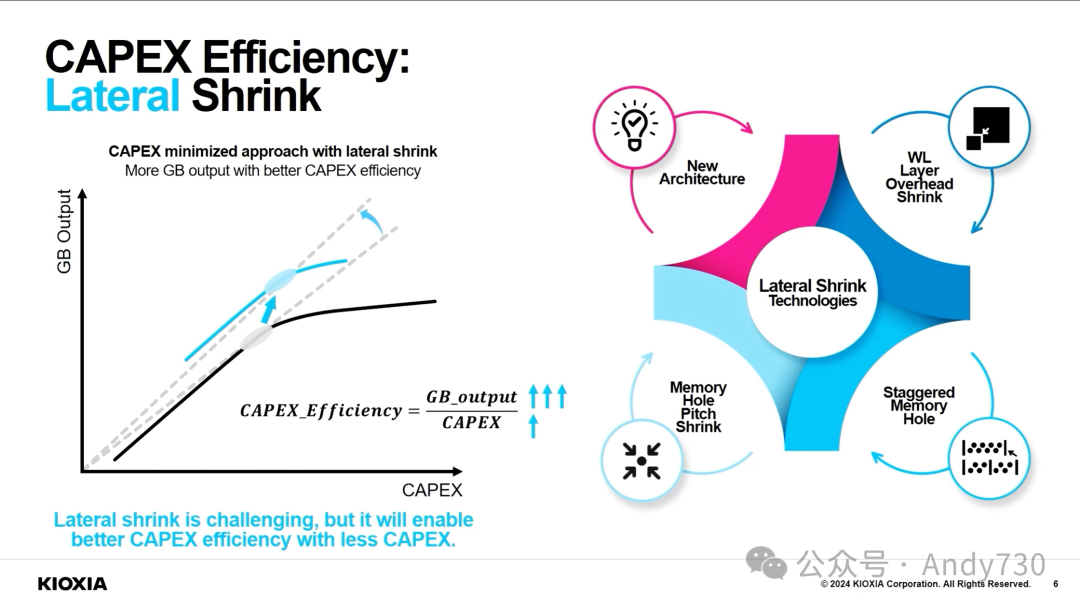
FMS展会规模扩大,除了磁记录产品,还涵盖了NAND闪存。NAND闪存层数增长明显放缓,主要是因为单纯增加层数带来的成本下降效果已经减弱。今年主要厂商更关注通过减小单元间距、增大单元直径、提高单元存储密度等方法来提升闪存容量。
ChannelScience首席科学家兼FMS大会主席Chuck Sobey:
AI成为贯穿整个展会的核心主题,涉及AI在系统设计、存储基础设施影响以及推动更多内存和存储需求等方面的应用。能效仍是重要话题,有演讲者指出,用AI从文本生成一张图像消耗的能量相当于为一部手机每天充电一年半。
Cloud Architects总裁Jean S. Bozman:
今年最大变化是对内存关注度的提升,讨论涵盖了内存的多个方面。鉴于AI和HPC等领域对性能的需求,充足且高效的内存成为客户未来工作负载的关键。存储中的AI是另一热门话题,AI及生成式AI的快速发展使其重回焦点。随着AI在企业和中小企业中广泛应用,人们对AI应用扩展的兴趣增加。客户正利用AI深入了解业务动态,提高收入和利润。
Objective Analysis总经理兼半导体分析师Jim Handy:
AI和CXL是今年展会的两大主题。AI的重要性源于Nvidia过去四个季度的持续增长。CXL涉及多个方面,其重点已从两年前的解决孤立内存问题,转变为支持AI所需的大容量内存。随着CXL市场发展,其应用可能会进一步演变。
Futurum Group首席技术顾问Camberley Bates:
内存和数据存储技术在AI处理中的融合尤为突出。这些数据元素的整合日益紧密,以满足CPU和GPU的功耗和速度需求。这一趋势在两个技术领域都得到认可。虽然它们不会完全合并,但将继续在数据存储层级中演进。
Wedbush分析师Matt Bryson总结了Phison CEO潘健成对当前市场的看法:
企业级市场表现强劲(Phison企业解决方案销售额从第一季度的5%增至第二季度的14%),但相关存储位元相对紧缺。OEM需求(PC和智能手机)目前疲软。预计智能手机需求将在第四季度反弹,但PC OEM库存能否在年内消化完毕仍不确定。零售市场几乎停滞。虽然预计下半年会有季节性反弹,但幅度将取决于更广泛的经济因素(如利率、美元走势等)。长期来看,随着PC更换市场萎缩,零售市场也将逐渐缩小。
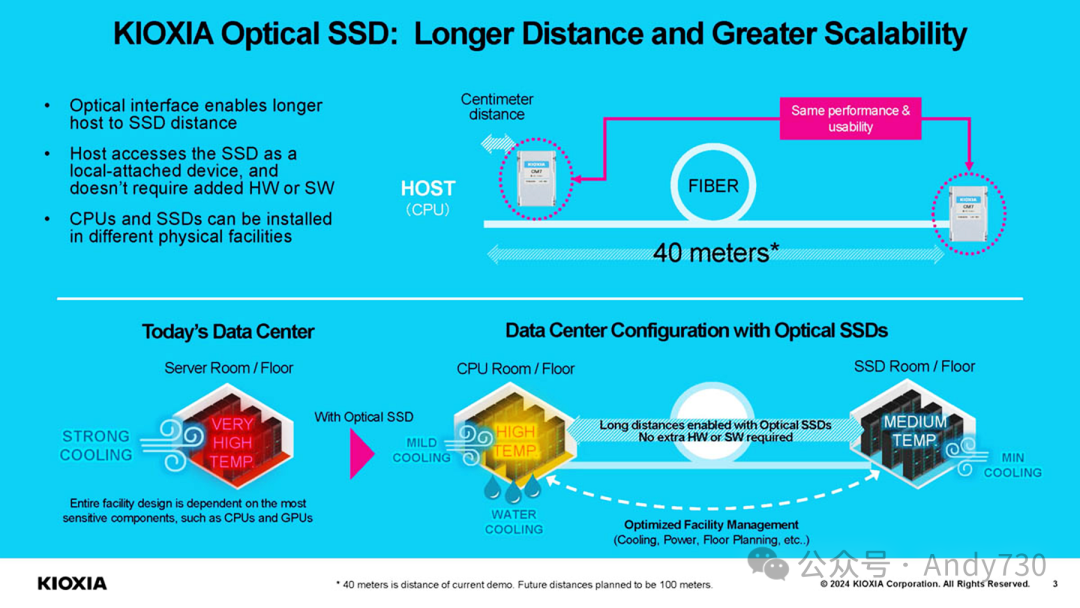
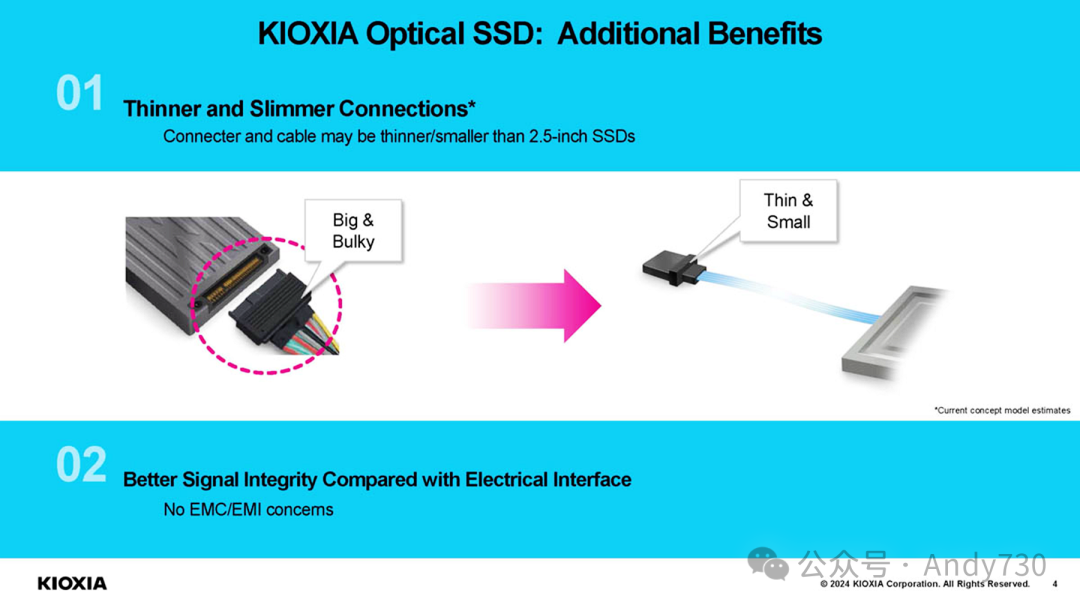
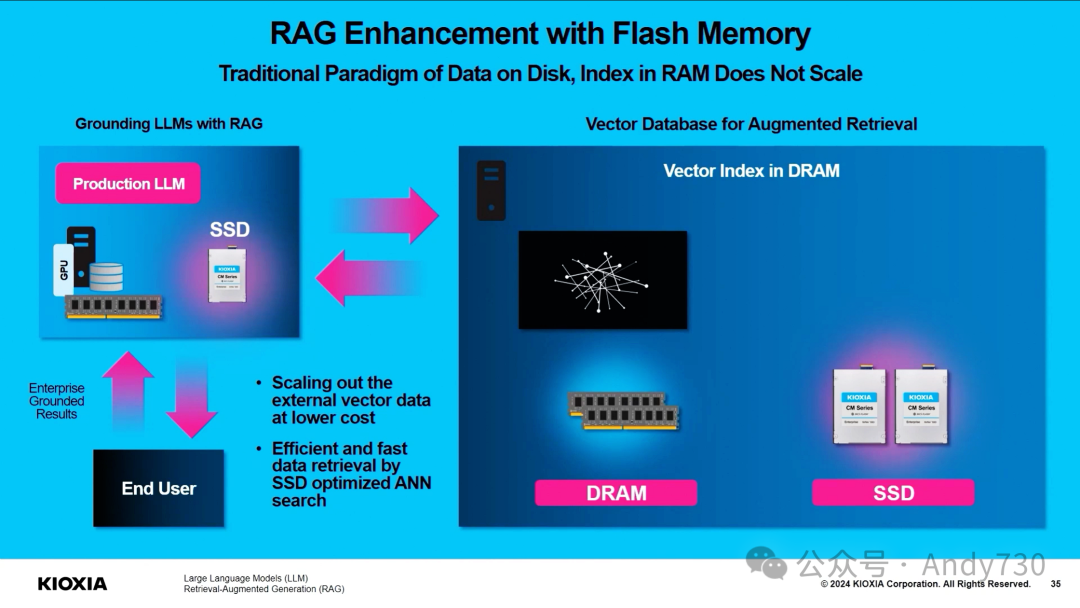
Kioxia正在开发适用于PCIe Gen8或更高版本的光互连SSD,目前已开始展示这项技术。当前演示采用约40米的短距离光连接,但Kioxia计划未来将其扩展至100米。这项技术的一个设想是,可以将SSD远离需要液冷的高热CPU和GPU,而将NAND放置在温度更适宜的环境中,以发挥最佳性能。另一个构想是采用更小的光接口连接器,但这一点尚未确定。标准MTP/MPO连接器虽然更小(尽管不确定演示中使用的是否为此类型,因其外观略有不同),但无法供电。
该SSD连接到一个将PCIe信号转换为光信号的板卡上。理论上,这种技术也可应用于GPU等设备。本次演示更像是光传输的PCIe(不含电气部分),而非将其转换为以太网等其他协议。
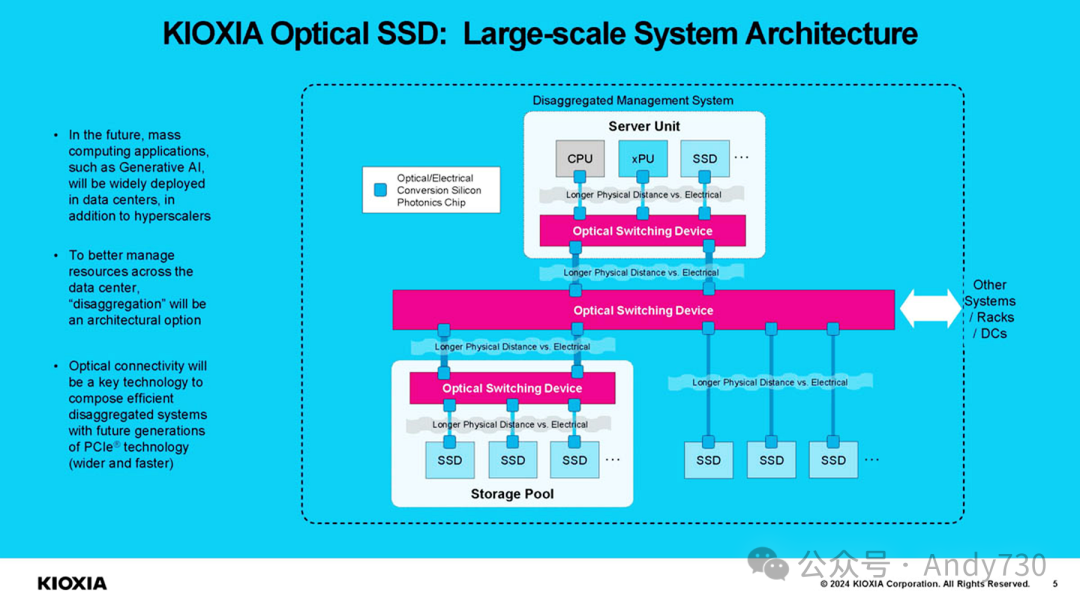
另一大优势在于可通过光学方式进行切换。这是一个重要亮点,但也存在一些限制。理论上,即使使用100米的短距离光连接,仍可通过交换机聚合带宽、共享设备,并扩展SSD与主机服务器之间的距离。
关键问题在于如何实现这一技术。目前,光网络速度远超SSD且增长更快,因此可能的选择是使用交换机将SSD接入网络,无论是基于PCIe、CXL还是以太网。作为参考,主要SSD供应商刚推出PCIe Gen5 NVMe SSD(Kioxia较早推出)。同时,我们刚测试的Marvell Teralynx 10 51.2T交换机上,一个800GbE端口需要约16块高端PCIe Gen5 x4 SSD才能充分利用带宽。
随着网络技术发展,最终需要权衡是直接使用光互连连接SSD,还是将SSD连接到通过光纤相连的交换机上。
这似乎是以太网SSD的下一个发展方向,类似早期的Kioxia EM6 NVMeoF SSD。虽然Kioxia尚未披露光学接口SSD将基于以太网、PCIe还是CXL,但未来的主要挑战是如何合理地在系统间共享足够的存储空间。另一个机遇是在更大的集群中共享SSD池,特别是在进入CXL 2.0、CXL 3.1及更高版本交换机时代后。



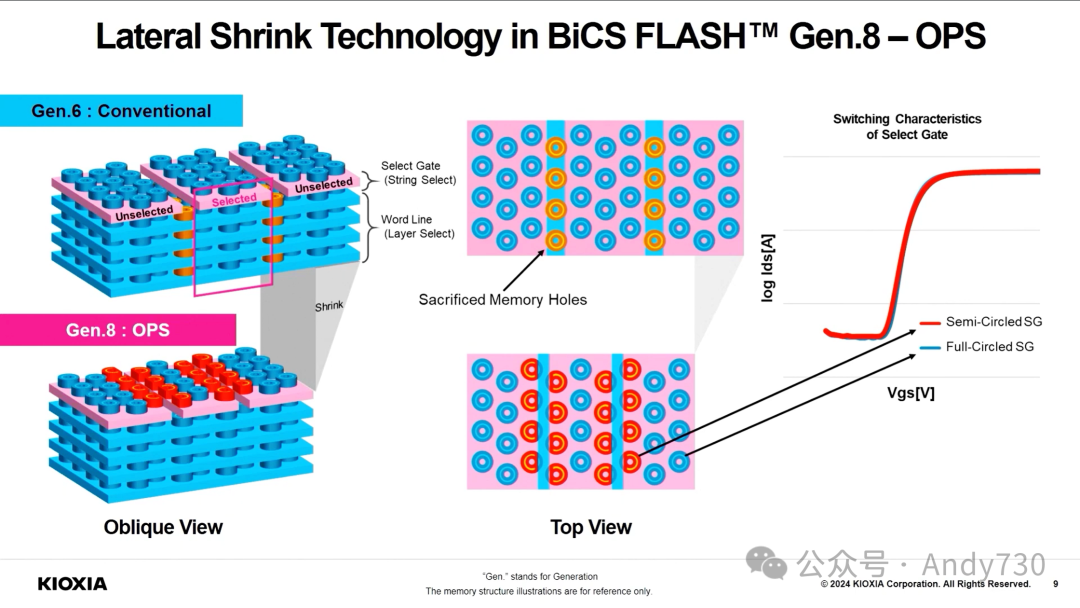
Kioxia BiCS 8: 218层3D NAND如何重塑闪存制造工艺
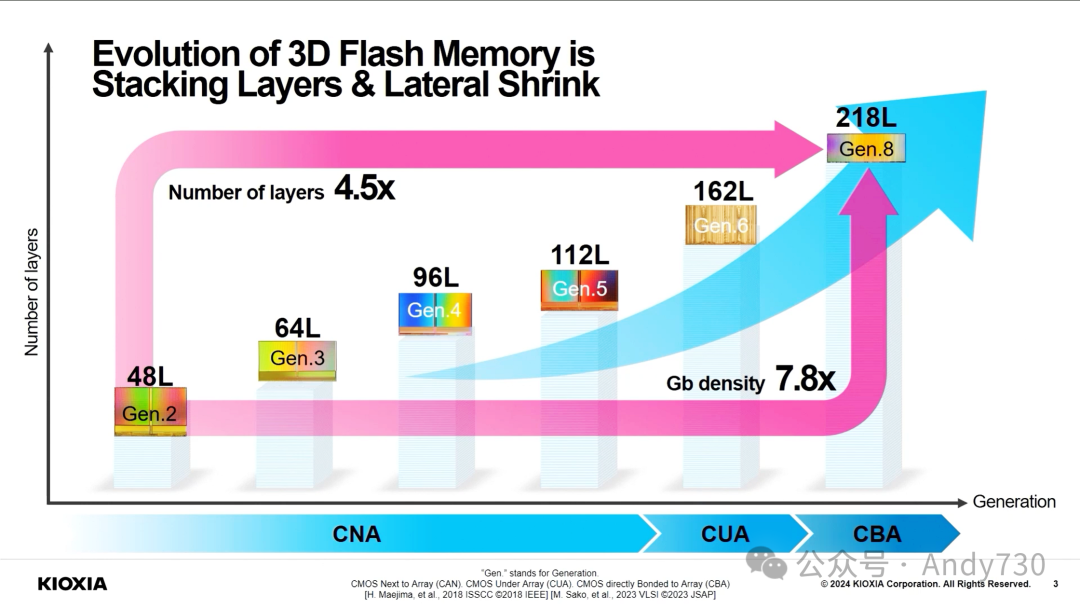
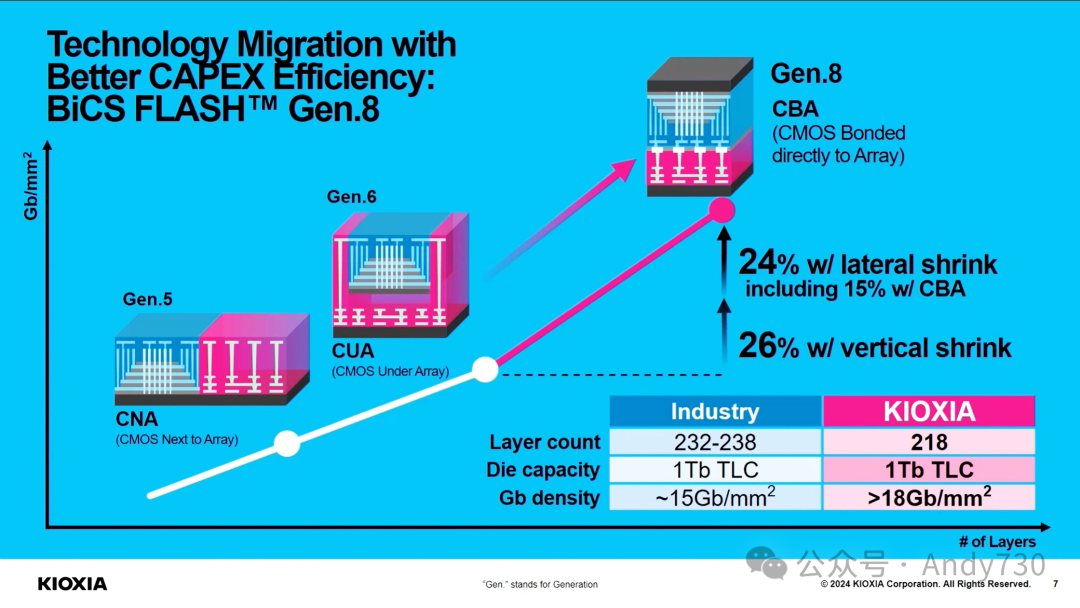
传统闪存芯片制造将逻辑电路(CMOS工艺)布置在闪存阵列周边。随后,工艺演变为将CMOS电路置于存储单元阵列下方,但仍采用串行开发流程:先制造CMOS逻辑电路,再在其上构建存储单元阵列。这种方法面临挑战,因为存储单元阵列所需的高温处理可能损害CMOS逻辑电路性能。
得益于晶圆键合技术的进步,新型CBA工艺应运而生。它允许CMOS晶圆和存储单元阵列晶圆独立并行加工,然后组合在一起,如模型所示。
集成218层结构,相比BiCS 5的112层和BiCS 6的162层有显著提升。 跳过了BiCS 7(可能仅作内部测试用),保留了BiCS 6的四平面电荷陷阱结构。 TLC模式下为1 Tbit容量,QLC版本提供1 Tbit和2 Tbit两种选择。
Kioxia强调,尽管218层数量不及某些竞争对手,但通过横向缩放和单元优化,在比特密度和运行速度(3200 MT/s)方面仍具竞争力。相比之下,Micron最新G9 NAND拥有276层,TLC模式下比特密度达21 Gbit/mm²,速度高达3600 MT/s。但其232层NAND速度仅为2400 MT/s,比特密度为14.6 Gbit/mm²。
CBA混合键合工艺优势:相较于其他供应商目前使用的工艺,如Micron的"阵列下CMOS"(CuA)和SK hynix的"4D PUC"(芯片下周边电路)工艺,CBA混合键合工艺展现出明显优势。预计其他NAND供应商最终也会采用类似Kioxia的混合键合方案。



演讲《KIOXIA:先进闪存技术释放AI潜力的新篇章》(PPT)



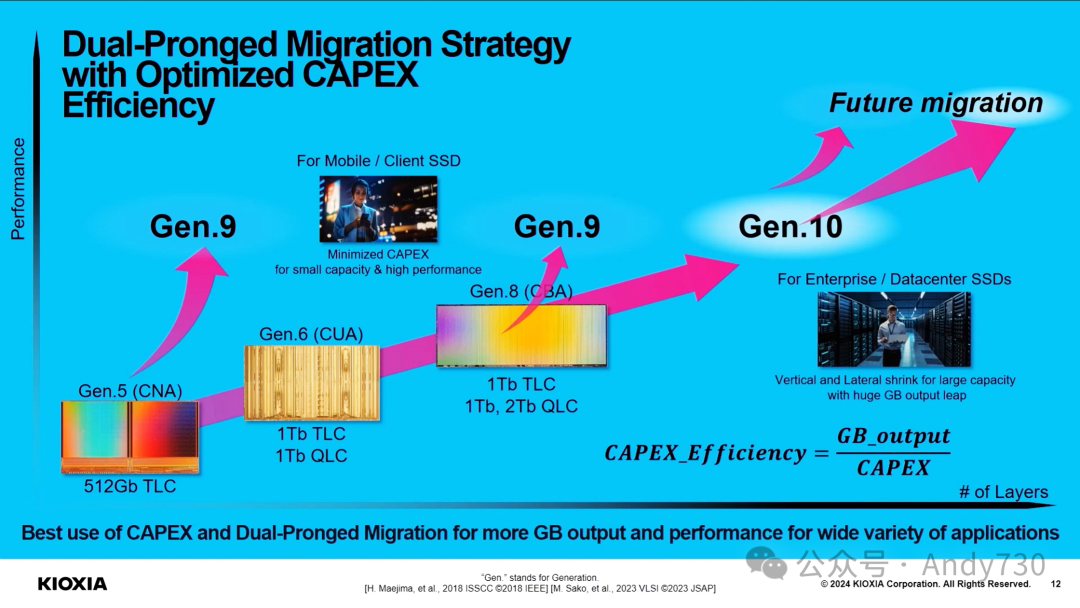
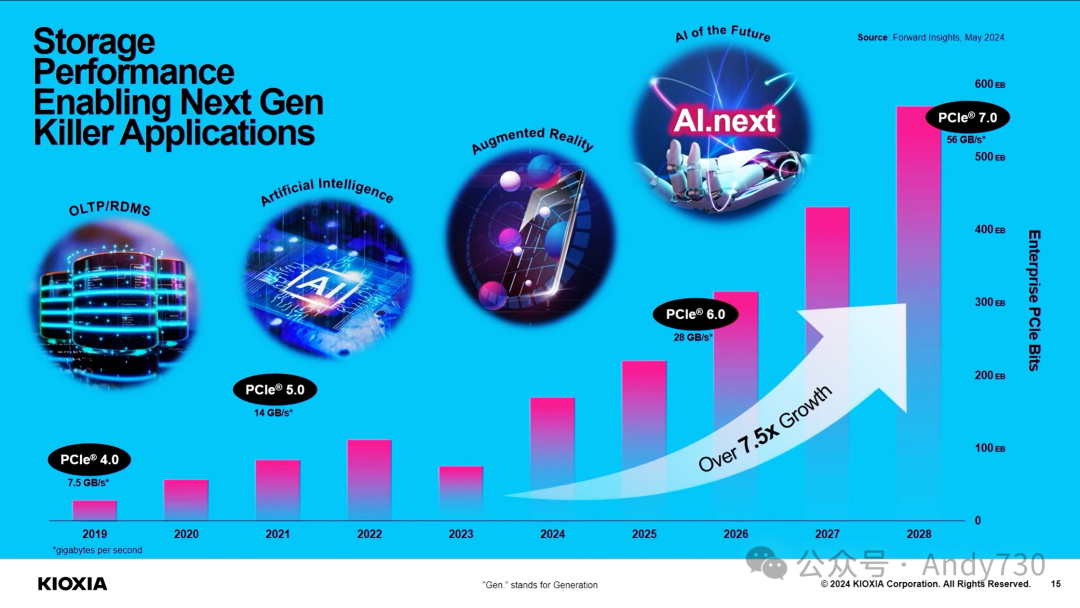
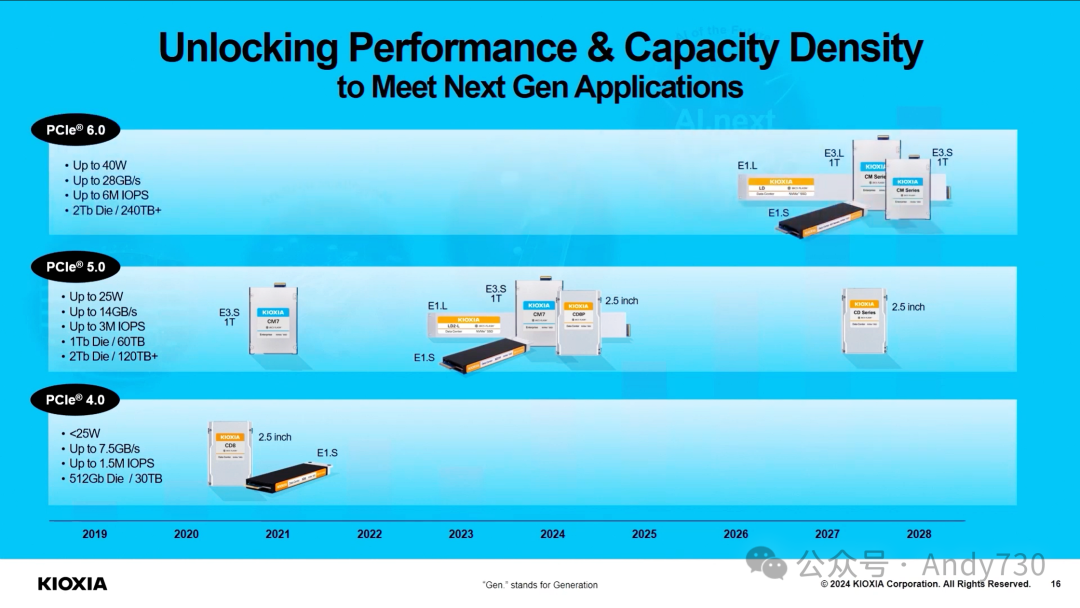

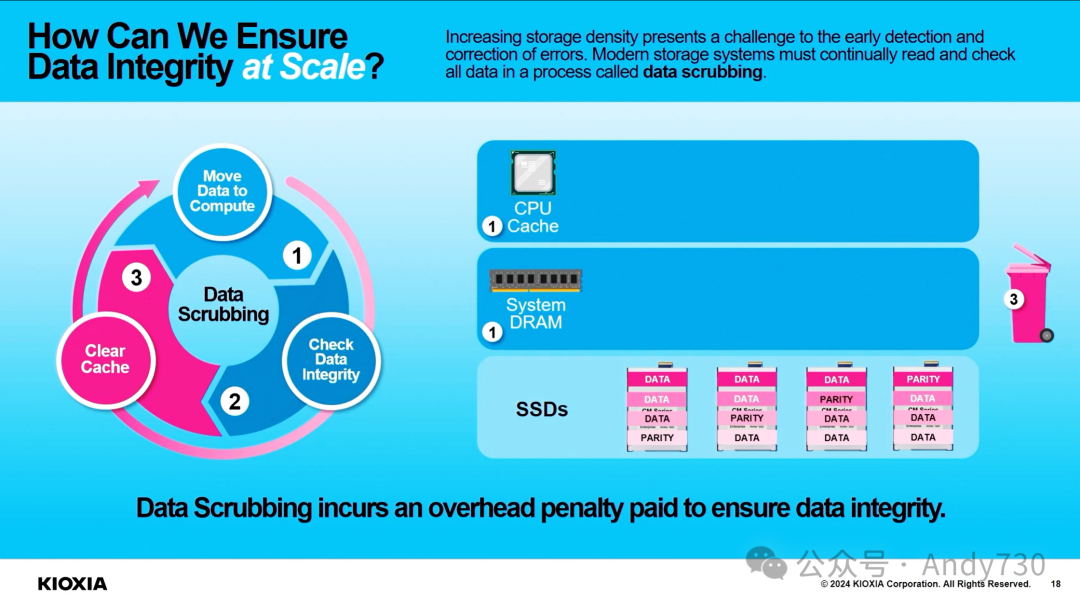

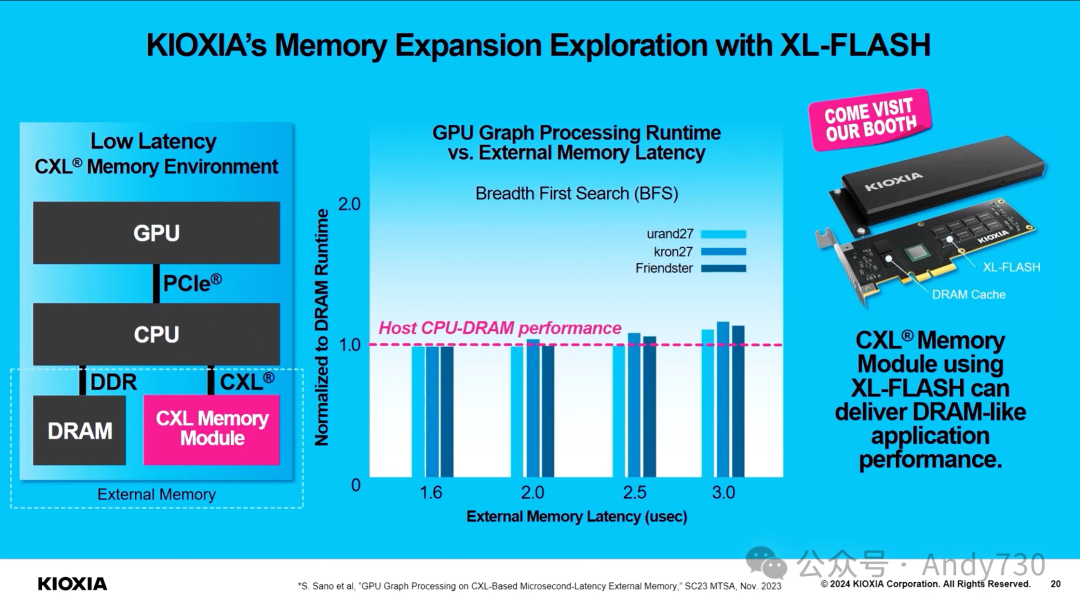
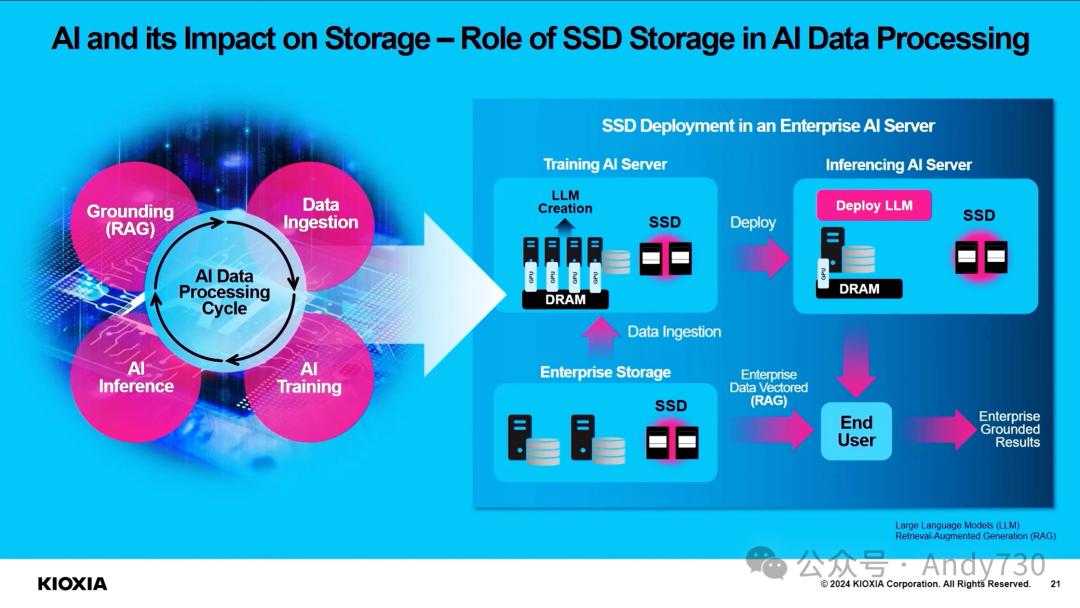
从芯片到系统:SK hynix的技术布局
SK hynix发表了题为“AI时代下的存储器与存储解决方案:领导力与未来展望”的主题演讲。分享了针对生成式AI量身定制的DRAM与NAND闪存解决方案,这些创新方案旨在直击AI领域的关键挑战。其核心目标在于,通过技术革新最大化AI训练与推理的效率,同时大幅度降低数据存储对空间及能耗的需求。
介绍了两大类别的存储器产品:首先是专为AI系统优化设计的DRAM产品线,包括高性能的HBM2、前沿的CXL技术,以及高效节能的LPDDR5T等,它们共同为AI应用提供了强大的数据处理能力;其次是高端NAND闪存存储设备,涵盖了SSD固态硬盘及UFS移动存储解决方案。
SK hynix的展位分为四个部分,展示了多款在主题演讲和技术会议中提到的产品。展位亮点之一是12层HBM3E样品,这是一种下一代AI存储解决方案,预计2024年第三季度开始量产。
- CMM演示(与仅配备DDR5的系统相比,CMM-DDR5可将系统带宽扩展50%,容量增加最多100%)














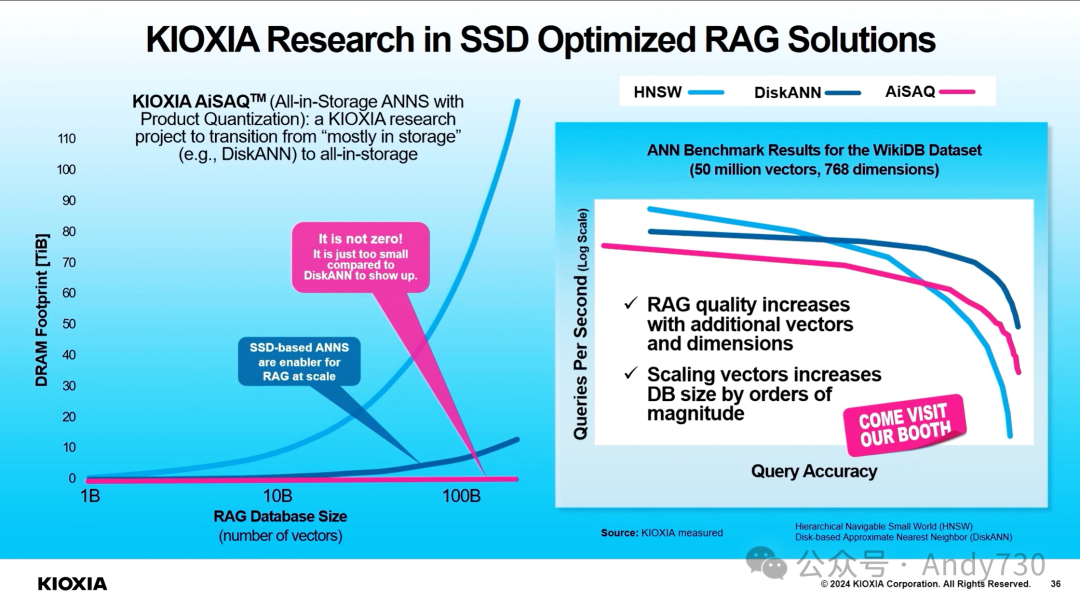
对象计算型存储(OCS):SK hynix引领HPC存储技术新突破
在此应用场景中,目标数据以Parquet文件形式存储在NVMe SSD上。当洛斯阿拉莫斯国家实验室(LANL)需要进行大规模模拟运行时,OCS(对象计算型存储)对SSD上的数据进行预处理,以减少传输到分析服务器的数据集规模。
在高性能计算(HPC)环境中,物理模拟数据的分析需要将存储节点中的大量数据传输到计算节点进行处理。这要求网络带宽和计算节点中足够的内存来存储处理数据集。
然而,SK hynix指出,“实际需要进行分析的数据仅占总数据的一小部分。”计算型存储可以通过选择仅用于处理的数据来减少数据传输量,并对其进行所谓的预处理。
这一技术旨在缩短物理模拟数据的分析时间。SK hynix在2023年丹佛举行的超级计算大会(Supercomputing 2023)上展示了其OCS原型系统与LANL合作的成果,显示出超过6.5倍的速度提升。OCS“可以独立完成数据分析,而无需计算节点的帮助”,并强调了其作为HPC中计算型存储未来潜力的技术。
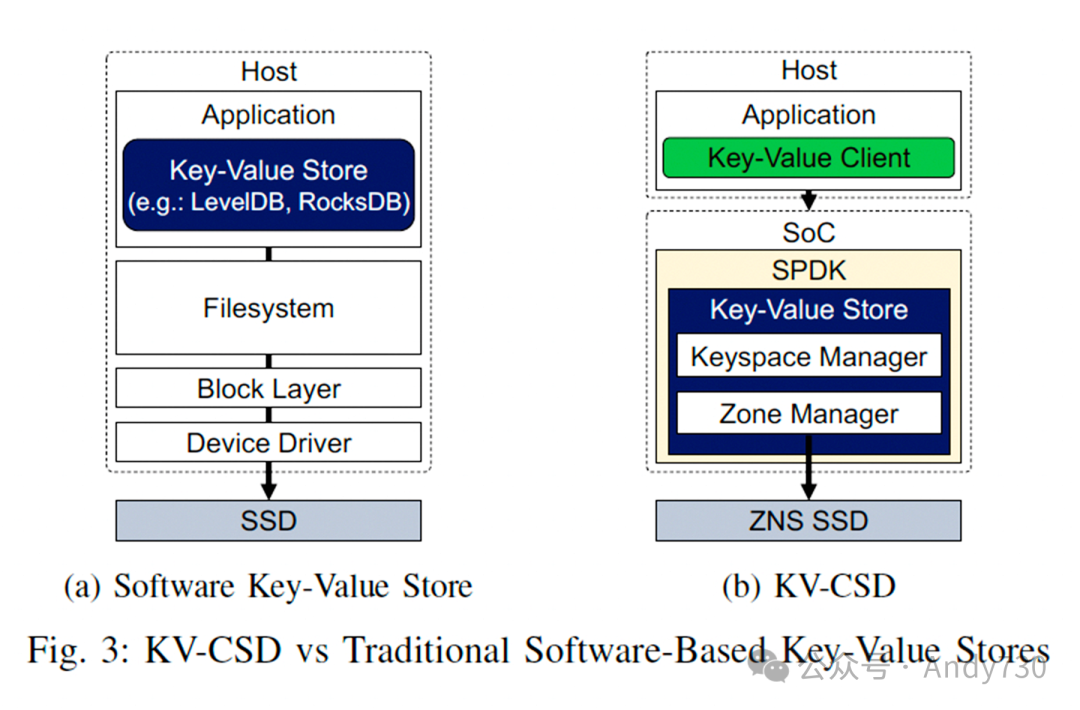
OCS被认为是数据感知的。这是因为基于块的存储系统除了知道逻辑块地址(LBA)和范围之外,对其数据内容一无所知。而对象存储系统则存储元数据,其中可以包含数据内容标识符,如ID、键、名称等。本地处理可以在键值计算型存储驱动器(KVCSD)上使用这些索引元数据来选择所需的数据项。
KVCSD是一种硬件加速的键值存储,可以基于现有的键值存储,如RocksDB和LevelDB。根据SK hynix、LANL和NVIDIA联合发布的研究论文《KV-CSD:面向数据密集型应用的硬件加速键值存储》的描述,KV-CSD由NVMe SSD和“一个在SSD上实现有序键值存储的片上系统(SoC)”组成。该SoC配备4个ARM Cortex A53 CPU核心、8GB DDR4内存和Ubuntu操作系统,采用基于LSM树的键值存储实现。
宣称的结果是:“通过卸载处理,KV-CSD简化了数据插入,减少了主机与设备之间的数据移动,无论是后台数据重组还是查询处理,并且在实际科学数据集上,与当前最先进的软件键值存储相比,写入时间降低了多达10.6倍,查询速度提高了多达7.4倍。”
论文指出:“通过直接在设备中实现键值存储管理,KV-CSD提供了利用低级存储接口(如分区命名空间)的机会,以优化性能,而软件键值存储则必须依赖底层文件系统和操作系统来采用这些优化。”事实上,KV-CSD使用了一块15TB的NVMe分区命名空间SSD,采用PCIe 3.0接口。
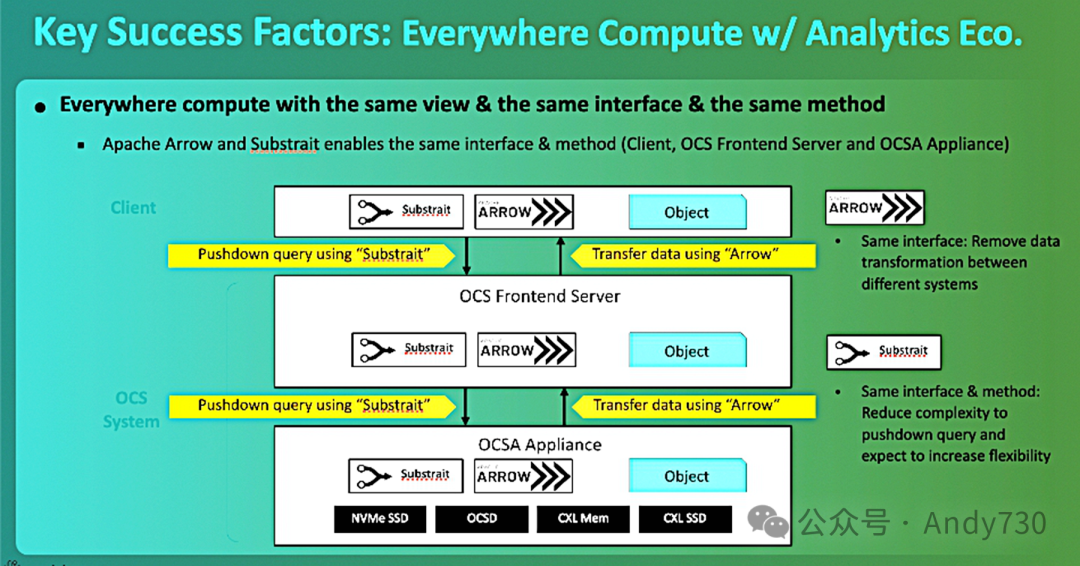
OCS项目涉及使用Apache分析生态系统的分析软件栈,包括Substrait和Arrow。Substrait提供了分析查询计划的标准化开放表示,允许将查询的一部分从基于S3的存储服务器推送到OCS计算型存储,具体而言,是作为后端存储的对象计算型存储阵列(OCSA)。
在这里,使用索引技术对存储的Parquet文件数据集进行筛选,仅选择查询所需的数据。Apache Arrow软件具有语言无关的列式内存格式,适用于平面和层次数据,并具有通用传输格式。它可以用来将查询结果——减少的数据集——以更少的网络带宽传输回分析服务器,这样这些服务器所需的内存比以前少。
SK hynix和洛斯阿拉莫斯国家实验室表示:“通过将这种索引能力更接近存储设备,可以节省数量级的数据移动。”
在FMS 2024上的OCS演示使用了Paraview/VTK(可视化工具包),Substrait将部分分析查询计划发送到OCS系统。
SK hynix存储系统研究负责人柳胜洙表示:“这种新颖的数据处理方法最小化了分析应用程序与存储之间的冗余数据传输,并减轻了存储软件栈的负担。这加速了大数据分析、人工智能等数据密集型应用的性能。SK hynix致力于与行业合作伙伴共同开发分析生态系统。”
洛斯阿拉莫斯高性能计算部门负责人Gary Grider表示:“我们的大规模索引工作,得益于如Apache列式分析这样的行业标准生态系统,正在取得良好的结果。”

NEO半导体3D X-AI技术:颠覆HBM,重塑AI芯片未来
NEO半导体公司成功研发出3D X-AI芯片,旨在革新市场,取代现有的HBM芯片,并从根本上解决数据总线瓶颈问题。
该公司正式宣布了其3D X-AI芯片技术的诞生,其核心目标在于替换当前高带宽内存(HBM)体系中的DRAM芯片。通过在这一3D DRAM结构中融入AI处理能力,该技术直击数据总线瓶颈的痛点。
3D X-AI芯片以其独特设计,有效缩减了在AI运算过程中HBM与GPU之间频繁传输的海量数据。这一创新举措预示着AI芯片在诸如生成式AI等前沿应用领域的性能、功耗及成本将迎来颠覆性变革。
具体而言,3D X-AI芯片巧妙利用3D内存架构直接执行AI操作,显著降低了HBM与GPU间不必要的数据传输负担。这一变革不仅有望重塑AI芯片的性能表现,还将在功耗控制和成本效益上带来显著提升。
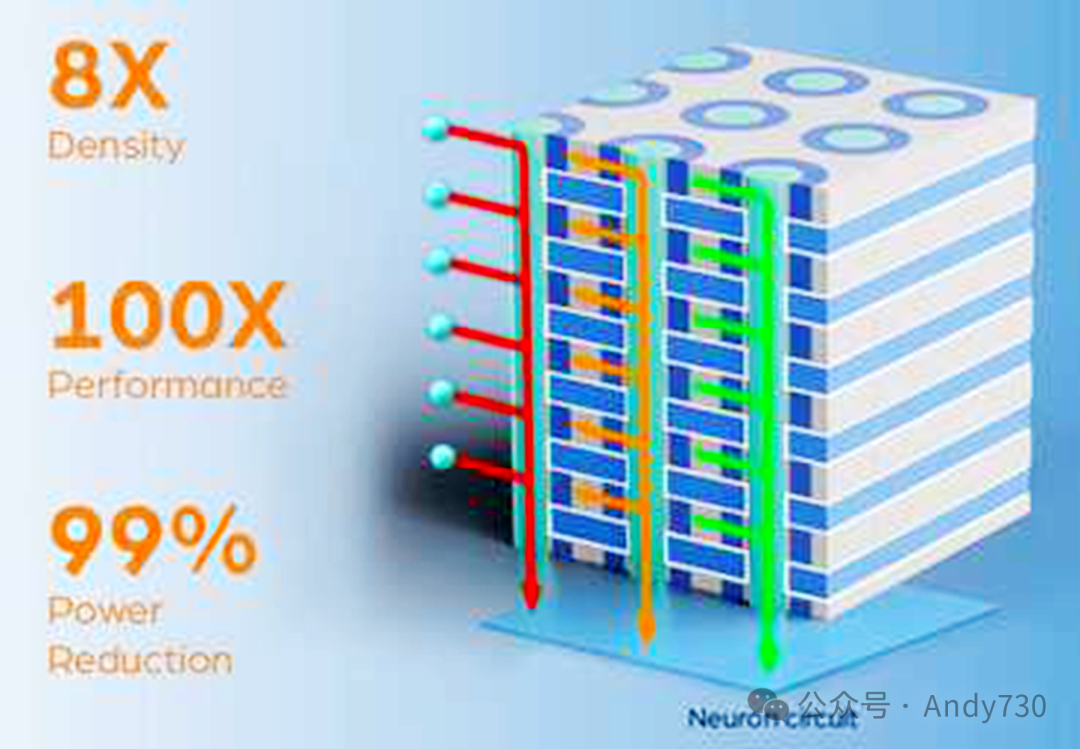
搭载NEO 3D X-AI技术的AI芯片,其优势显而易见:
性能飞跃:实现100倍的性能加速,得益于芯片内置的8000个神经元电路,在3D内存环境中高效执行AI任务。
功耗大减:减少高达99%的功耗,通过最小化数据向GPU传输的需求,大幅降低数据总线的能耗与热量产生。
内存扩容:提供8倍的内存密度提升,依托其包含的300层内存结构,使得HBM能够存储更为庞大的AI模型。
NEO半导体公司的创始人兼首席执行官Andy Hsu先生对此表示:“当前的AI芯片架构因技术与设计上的不足,导致了性能与功耗的严重浪费。传统架构将数据存储在HBM中,却依赖GPU进行全部计算,这种分离模式不可避免地造成了数据总线成为性能提升的瓶颈。而3D X-AI芯片则能在每个HBM芯片内部直接执行AI处理,极大减少了HBM与GPU间的数据传输量,从而实现了性能的飞跃与功耗的大幅降低。”
单个3D X-AI芯片集成了300层3D DRAM单元,总容量达到128Gb,并配备了一层包含8000个神经元的神经电路。据NEO估算,该芯片能支持高达10TB/s的AI处理吞吐量。若将12个这样的芯片堆叠于HBM封装内,则可实现惊人的120TB/s处理吞吐量,性能提升百倍。
网络存储领域的资深顾问Jay Kramer先生也对3D X-AI技术寄予厚望:“此技术的应用无疑将加速新兴AI场景的发展,并催生出一系列创新应用。通过打造基于3D X-AI技术的下一代优化AI芯片,我们正步入一个AI应用创新的新时代。”


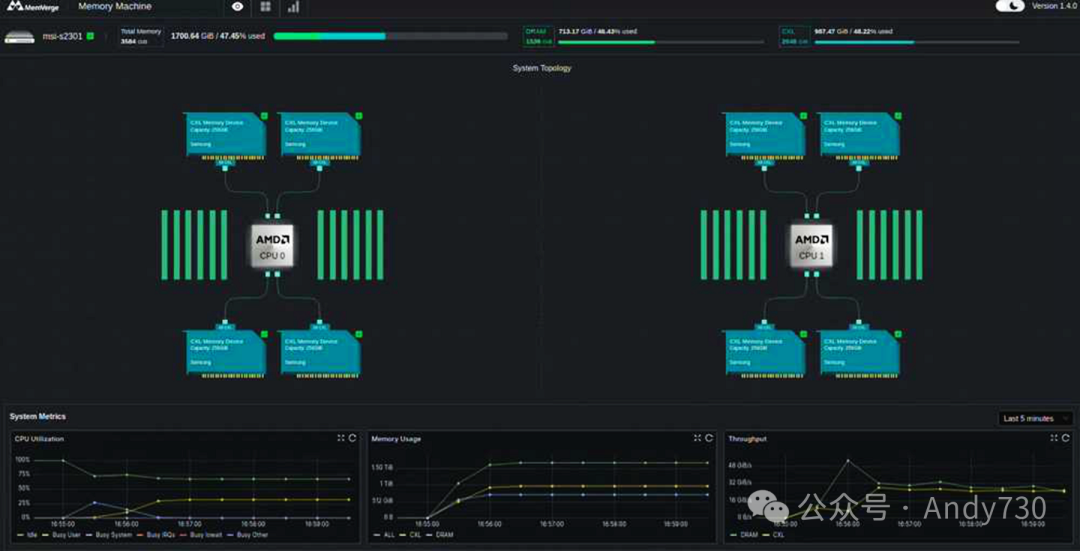
MSI携手Samsung与MemVerge:CXL技术驱动下一代内存扩展服务器
MSI推出CXL内存扩展服务器,携手SamsungCXL内存模块与MemVerge Memory Machine X软件
MSI的CXL内存扩展服务器专为提升内存数据库、EDA以及HPC应用的性能而设计。企业平台解决方案总经理Danny Hsu指出:“MSI的这款服务器通过融合创新的CXL技术,极大地扩展了内存容量与带宽,集成了AMD EPYC处理器、CXL内存模块及先进管理软件的尖端技术。我们与AMD、Samsung、MemVerge等CXL生态系统中的关键玩家紧密合作,共同推动CXL技术革新,以满足高性能数据中心计算的严苛需求。”
CXL内存扩展技术致力于提升现代计算环境的内存带宽与容量。CXL 2.0标准引入了一种革命性的内存访问机制,使得扩展设备能够无缝对接CPU的内存体系,将外部内存模块视为系统原生内存的一部分。MSI S2301服务器已率先支持第五代AMD EPYC处理器,并通过CXL 2.0与PCIe 5.0 x8链路的集成,允许用户灵活添加CXL标准内存扩展设备,从而突破传统DRAM配置的内存限制。这一突破不仅大幅提升了系统内存的总量与HPC任务的性能,还通过CPU与额外内存模块的直接一致访问,显著优化了内存带宽,为应用性能带来质的飞跃。
Samsung推出的基于CXL 2.0标准的256GB内存模块,预示着下一代内存解决方案商业化进程的加速。Samsung电子内存新业务规划团队副总裁Jangseok Choi表示:“我们非常荣幸能与MSI和AMD携手,共同构建强大的CXL生态系统,并优化我们CXL 2.0 256GB CMM-D内存模块的性能。这款新型CXL DRAM解决方案预计将在MSI S2301服务器上展现出卓越的工作负载处理能力。”
同时,MemVerge的Memory Machine X软件以其智能的内存层次结构管理能力,为AI及其他内存密集型工作负载带来了成本与性能的双重优化。该软件能够智能判断CXL内存的适用场景,并运用带宽与延迟的QoS策略,自动将数据分配到最合适的内存层级,确保最佳性能表现。MemVerge首席执行官兼联合创始人Charles Fan强调:“合格CXL外设与软件的融合应用,是行业的一大突破,标志着我们已具备满足IT组织对CXL技术额外内存容量与带宽需求的强大能力。”
此次联合演示,不仅展示了下一代CXL接口的无限潜力,还通过CXL内存扩展设备的加入,实现了系统内存总量与带宽的显著扩展。随着主DRAM可扩展性的提升,这一技术革新无疑将对未来计算市场产生深远影响。

Samsung突破128TB大关:BM1743 QLC SSD引领企业存储新纪元
Samsung在上个月低调发布了其BM1743企业级QLC SSD,其中一款型号更是达到了惊人的61.44TB容量。而在最近的FMS 2024展会上,Samsung更是展示了容量翻倍的122.88TB版本,并进行了多项基准测试。与前一代产品相比,BM1743在I/O性能上实现了4.1倍的提升,数据持久性有所增强,同时在顺序写入能效上也提高了45%。
这款128TB级别的QLC SSD,其顺序读取速率高达7.5GB/s,顺序写入速率则为3GB/s。在随机读写方面,随机读取速率可达1.6百万IOPS,而针对16KB大小的随机写入,速率也能达到45K IOPS。值得注意的是,Samsung似乎在闪存管理方面采用了优化策略,以16KB为间接单位(IU)进行操作,这与Solidigm在其大容量SSD中采用的大于4K IU的策略不谋而合。
此外,Samsung还公开了PM9D3a 8通道第五代SSD的基准测试结果。该系列SSD被定位为数据中心的主力军,顺序读写速度分别高达12GB/s和6.8GB/s,随机读写速度则分别达到了2百万IOPS和40万IOPS。
PM9D3a系列提供了多种尺寸的规格,最大容量可达32TB(M.2接口最大为2TB),并内置了可选的灵活数据放置(FDP)功能,以有效缓解写放大问题。
而Samsung当前的企业级SSD旗舰产品——PM1753,则是一款支持16个NAND通道的U.2/E3.S SSD,最大容量同样可达32TB。其顺序读写速度分别飙升至14.8GB/s和11GB/s,对于4KB访问的随机读写,速度也分别达到了惊人的3.4百万IOPS和60万IOPS。
Samsung宣称,与上一代PM1743相比,PM1753在性能上实现了1.7倍的提升,能效也提高了1.7倍,使其作为TLC SSD在AI服务器应用中展现出巨大的潜力。
值得一提的是,Samsung的第九代V-NAND晶圆也在展会中亮相,尽管禁止拍照,但这款闪存的量产已于2024年4月正式启动。






Western Digital展示全方位创新闪存解决方案
在2024年FMS大会上,Western Digital公司隆重推出了多项创新解决方案与技术演示,显著提升了变革性AI数据周期工作负载在性能、容量及效率方面的表现。这些创新成果广泛覆盖了从超大规模云计算到汽车、消费存储等多个细分市场。会上,Western Digital闪存业务部执行副总裁兼总经理Rob Soderbery的主题演讲为与会者提供了深刻见解,他深入剖析了推动NAND、AI及存储领域未来发展的战略蓝图,从数据中心一直延伸到边缘计算。
关于OpenFlex Data24 4200 NVMe-oF存储平台,Soderbery强调:“随着AI技术的飞速发展及其在日常生活中的日益普及,对存储的需求将持续攀升。Western Digital的产品与技术路线图与此战略高度契合,旨在为我们的客户提供最前沿、最可靠的解决方案,确保他们在瞬息万变的AI环境中保持领先地位。我们采取的这种全方位策略,旨在为客户提供最节能、高性能、高容量的定制化解决方案,以满足其独特需求。我们非常荣幸能够展示我们完整的产品线及新技术,并演示它们如何重塑现在与未来的AI世界。”
针对AI、机器学习(ML)及大语言模型(LLM)的迅猛崛起,Western Digital公司积极应对两大核心挑战:数据生成与消费的爆炸式增长,以及组织亟需快速从海量数据中挖掘价值的迫切需求。随着存储需求的激增,性能、可扩展性及效率成为了AI技术栈中不可或缺的关键因素。为此,Western Digital提供了一整套支持AI数据周期持续演进的存储技术组合。以下是展会期间的几大亮点:
数据中心领域:
展出了于6月发布的数据中心新品,包括专为计算密集型应用设计的PCIe Gen5企业级SSD(eSSD)、面向存储密集型应用的新款64TB eSSD,以及全球首款用于大规模数据存储的32TB ePMR SMR HDD。
进行了BiCS8 128TB高容量QLC eSSD技术演示,该技术专为快速AI数据湖及容量密集型性能应用而设计。
推出了RapidFlex中介板,该设备可将PCIe SSD信号转换为以太网信号,从而使PCIe eSSD能够无缝集成至增强的OpenFlex Data24 4200 NVMe-oF存储平台中,无论是以太网交换还是PCIe交换系统架构均可适用。分布式NVMe-oF存储是优化AI工作流程效率与可管理性的关键。特别值得一提的是,基于NVIDIA Spectrum以太网交换技术及NVIDIA GPUDirect Storage(GDS)的Ingrasys ES2100演示,展现了其实时可视化与分析大规模3D数据集的能力,凸显了NVMe-oF存储与GPU内存之间的直接数据通道,从而实现了存储与GPU资源的可扩展、高性能及高效利用,有力支撑了密集型AI应用的运行。RapidFlex中介板现已上市,由Ingrasys Technology, Inc.独家授权。
展示了BiCS8高性能与主流PCIe Gen5 NVMe SSD在AI PC、游戏设备、工作站、笔记本电脑及其他移动客户端PC中的应用。
汽车领域:
推出了AT EN610 NVMe SSD,这是一款专为汽车设计的高性能、宽温范围存储解决方案,能够满足下一代高性能集中计算(HPCC)架构的严苛要求。AT EN610提供高容量TLC选项,并支持全部或部分配置为高耐久性SLC模式,采用M.2 Type 1620 BGA封装形式,最大存储容量可达1TB。目前,AT EN610正处于样品测试阶段。
预览了iNAND AT EU752,该产品专为高级驾驶辅助系统(ADAS)、信息娱乐系统(IVI)及其他自动驾驶系统而设计。EU752作为最先进的汽车级存储解决方案之一,不仅具备UFS 4.0规范的所有功能,还额外提供了如自动设备刷新以防止数据损坏、100%内容预加载等特性,以进一步提升性能与可靠性。基于BiCS8 NAND技术,EU752提供高达1TB的存储容量及超快的数据传输速度,预计将于2025年第一季度开始样品测试。






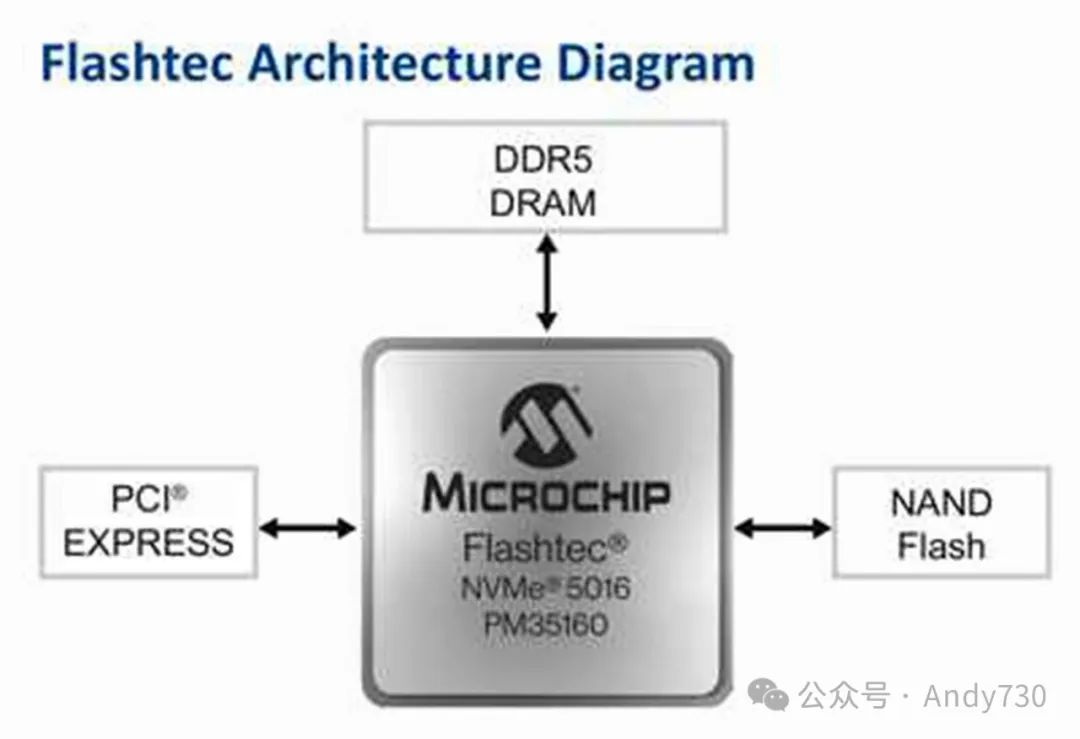
Microchip发布Flashtec NVMe 5016 SSD控制器系列
Microchip最新推出了Flashtec NVMe 5016 SSD控制器。这款控制器是一款集16通道、PCIe Gen 5标准于一身的NVMe控制器,专为提升带宽、增强安全性及灵活性而设计。
“随着AI与ML技术的飞速发展,数据中心技术也需与时俱进。我们的第五代Flashtec NVMe控制器正是为了引领市场,满足日益增长的高性能、低功耗SSD需求而精心打造。”Microchip数据中心解决方案业务部副总裁Pete Hazen表示,“Flashtec NVMe 5016 PCIe控制器能够完美融入数据中心环境,为云计算及业务关键型应用提供高效且安全的数据存储解决方案。”
Flashtec NVMe 5016控制器专为支持企业级应用而生,如一次性可编程(OTP)、金融数据处理、数据库挖掘等,以及对延迟和性能要求极高的应用场景。同时,它还积极响应AI领域的快速增长需求,提供卓越的读写吞吐量,助力模型训练和推理处理中大型数据集的快速处理,并凭借其高带宽特性,确保存储与计算资源间数据的高速流通。该控制器的顺序读取速度超过14GB/s,最大限度地提升了传统及AI加速服务器中的计算资源利用率,轻松应对严苛的工作负载挑战。
除了支持最新的NVMe主机接口标准外,Flashtec NVMe 5016控制器还展现出了惊人的随机读取性能,高达350万IOPS。其功耗设计紧密贴合数据中心对节能的严格要求,实现了超过2.5GB/W的数据传输效率。该控制器融合了先进的节点技术与电源管理功能,如自动空闲处理器核心关闭及自主功耗降低技术,进一步优化了能效表现。为支持QLC、TLC及MLC NAND等最新闪存技术,它配备了强大的错误纠正码(ECC)机制。所有闪存管理操作均在芯片内部完成,有效减轻了主机处理器及内存资源的负担。
Solidigm战略规划与营销高级副总裁Greg Matson对Microchip的这款新品给予了高度评价:“Microchip最新的Flashtec PCIe控制器采用了先进的6纳米工艺技术,完美满足了苛刻应用对于功耗优化的需求。其灵活的架构设计在紧凑的封装内实现了强大的处理能力,非常适合前沿的AI工作负载。”他还强调:“Flashtec PCIe控制器的卓越品质与可靠性,与Solidigm的QLC NAND技术相得益彰,共同满足数据密集型工作负载(如AI和ML)日益增长的需求。”
Longsys Electronics Co., Ltd.的董事长兼首席执行官蔡华博也对双方的紧密合作表示了肯定:“Longsys与Microchip之间的强大合作关系是推动企业SSD市场快速发展的关键力量。Microchip可靠且灵活的PCIe Flashtec产品架构为Longsys的企业解决方案奠定了坚实的基础,结合多种先进的NAND Flash技术,实现了高性能与可靠性的完美平衡,无论是标准还是定制化的高性能企业SSD需求,我们都能轻松应对。”
NVMe 5016控制器的灵活性和可扩展性特性,有效降低了总体拥有成本(TCO),这得益于其高级虚拟化功能,如单根I/O虚拟化(SR-IOV)、多物理功能及每物理功能下的多虚拟功能等,这些功能极大程度地优化了PCIe资源的利用。该平台的一致性和可编程性赋予了开发人员强大的灵活数据放置(FDP)能力,让他们能在SSD中充分发挥闪存资源的性能、效率和可靠性。此外,结合Microchip的动态资源分配信用引擎,NVMe 5016控制器为按需云服务提供了更加可靠的保障。
“我们热烈祝贺Microchip推出新一代Flashtec PCIe控制器,”Kioxia America, Inc.内存产品副总裁Maitry Dholakia表示,“Flashtec控制器在ECC技术上的不断创新,以及其灵活的架构设计,确保了与我们顶尖NAND闪存产品的完美兼容。”
随着数据存储量的不断攀升,安全威胁也日益严峻,这凸显了采取强大且可靠安全措施的紧迫性。Flashtec NVMe 5016控制器专为满足企业级数据完整性和可靠性需求而设计,确保数据保护、业务连续运行及机密信息安全无虞。
该控制器集成了全面的安全功能,以保障固件和数据从出厂到退役整个生命周期的完整性。这些功能涵盖基于硬件根信任的安全启动、双重签名认证以支持OEM或最终用户的系统验证、多种安全标准(通过各类认证算法支持)、用户数据保护(包括传输中和静态数据加密)以及严格遵循安全协议的复杂密钥管理实践,如符合联邦信息处理标准(FIPS)140-3第2级和可信计算组(TCG)Opal标准。
在数据完整性和可靠性方面,NVMe 5016控制器提供了NVMe保护信息(NVMe PI)的端到端数据保护、单错误校正和双错误检测(SECDED)ECC,并通过自适应LDPC实现高级错误校正。此外,它还集成了基于RAID技术的故障恢复机制,进一步增强了存储系统的韧性。
开发工具方面,Flashtec NVMe 5016 PCIe Gen 5 SSD控制器附带了一系列完善的支持工具,包括PM35160-KIT和PMT35161-KIT评估板(提供多样化的NAND选项)、具备PCIe兼容前端固件的SDK,以及专用的高级调试工具ChipLink等。
Micron突破26GB/s:PCIe Gen6 SSD引领存储新纪元
Micron科技正式揭晓了业内首款PCIe Gen6 SSD的研发成果,该SSD宣称能实现“超越26GB/s的顺序读取带宽”,目前正紧锣密鼓地为数据中心运营商的合作伙伴进行适配准备。
据Micron发布的新闻稿宣称,这款超高速PCIe Gen6数据中心SSD开创了行业先河,在当前计算技术迅猛发展的背景下,其加速存储技术被寄予厚望,认为能够有效应对AI处理需求的快速增长。
关于PCIe Gen6 SSD的具体性能细节,Micron尚未全面披露。尽管宣称新驱动器能够实现“超过26GB/s的顺序读取带宽”,但公众仍期待在Micron的主题演讲或圣克拉拉会议中心107号展位上,通过图片、视频等直观方式,亲眼见证这一速度的验证报告。
为了更直观地理解26GB/s数据传输速度的意义,我们可以参考我们定期更新的2024年最佳SSD推荐榜单中的佼佼者——Crucial T705。作为当前最快的消费级SSD之一,T705采用PCIe 5.0 x4接口,其顺序读取和写入速度分别达到了14.5GB/s和12.7GB/s。相比之下,Micron的新款PCIe Gen6 SSD在速度上大约快了80%,展现出了令人瞩目的性能飞跃。
Silicon Motion推出PCIe Gen5 NVMe 2.0 SSD控制器SM2508
Silicon Motion正式推出了SM2508,这是一款专为AI个人电脑和游戏主机量身打造的高效能PCIe Gen5 NVMe 2.0客户端SSD控制器。
作为业界首款采用台积电6纳米极紫外光(EUV)制程技术的PCIe Gen5客户端SSD控制器,SM2508相较于竞争对手的12纳米工艺,功耗降低了50%。其整体SSD功耗控制在7瓦以下,效能比PCIe Gen4 SSD高出1.7倍,更是领先市场上现有PCIe Gen5产品多达70%。计划于8月6日至8日在加州圣克拉拉举办的未来内存与存储峰会上,展示基于SM2508的SSD设计及其他创新技术成果。
SM2508是一款集高性能与低功耗于一身的PCIe Gen5 x4 NVMe 2.0 SSD控制器,专为支持AI功能的PC笔记本电脑设计。它配备了8个NAND通道,每个通道速度高达3600MT/s,提供了令人瞩目的顺序读写速度——分别可达14.5GB/s和13.6GB/s,随机性能也高达250万IOPS,性能较PCIe Gen4产品翻倍。尤为值得一提的是,SM2508在仅约3瓦的功耗下,即可充分发挥PCIe Gen5的性能潜力。此外,它还搭载了Silicon Motion自主研发的第八代NANDXtend技术,其中包括一种创新的磁盘训练算法,旨在减少ECC延迟,从而进一步提升性能并优化效能,同时确保与最新的3D TLC/QLC NAND技术完美兼容,支持更高的数据密度,以满足下一代AI个人电脑日益增长的需求。
Silicon Motion客户端及汽车存储业务高级副总裁Nelson Duann表示:“随着AI应用的不断发展,SSD存储解决方案正面临着前所未有的挑战,这些挑战要求数据的高效处理和高性能模型的支持。我们的PCIe Gen5 SSD控制器以最优的效能比设计,旨在满足当前AI功能个人电脑对高性能和高效能的独特需求,并为未来不断演进的AI PC标准奠定坚实基础。”
PCIe Gen5 x4, NVMe 2.0接口 8个NAND闪存通道,支持最高3600MT/s速度 采用台积电6纳米工艺制造 内置四核Arm Cortex-R8 CPU,支持4条PCIe通道,数据传输速率高达32Gb/s 顺序读写速度分别高达14.5GB/s和13.6GB/s,随机性能高达250万IOPS 兼容最新的3D TLC/QLC NAND技术
目前,多家主流SSD供应商及NAND供应商正基于SM2508进行设计开发工作,预计该控制器的量产将于2024年第四季度启动。
还将展示包括MonTitan PCIe Gen5企业级SSD开发平台在内的多项创新产品,该平台专为AI存储工作负载设计;SM8366企业级SSD控制器,提供高达14GB/s的顺序性能、350万IOPS的随机性能,并支持超过128TB的存储容量;以及基于多维QLC的MonTitan PCIe Gen5 SSD,通过FDP和PerformaShape技术最大化AI训练流程的性能。
此外,针对AI PC和AI智能手机,Silicon Motion还推出了UFS 4.0和USB存储解决方案,包括SM2756 UFS 4.0控制器(相比上一代UFS 3.1节能65%)和SM2322 USB SSD控制器(便携式SSD容量翻倍)。同时,还为汽车/物联网边缘应用提供了先进存储解决方案,如SM2264XT-AT汽车级SSD控制器(相比不支持SR-IOV的PCIe Gen4 SSD CPU功耗减少30%),以及FerriSSD PCIe Gen4 NVMe单芯片BGA SSD、Ferri-eMMC 5.0/5.1和Ferri-UFS 2.2/3.1等系列产品。
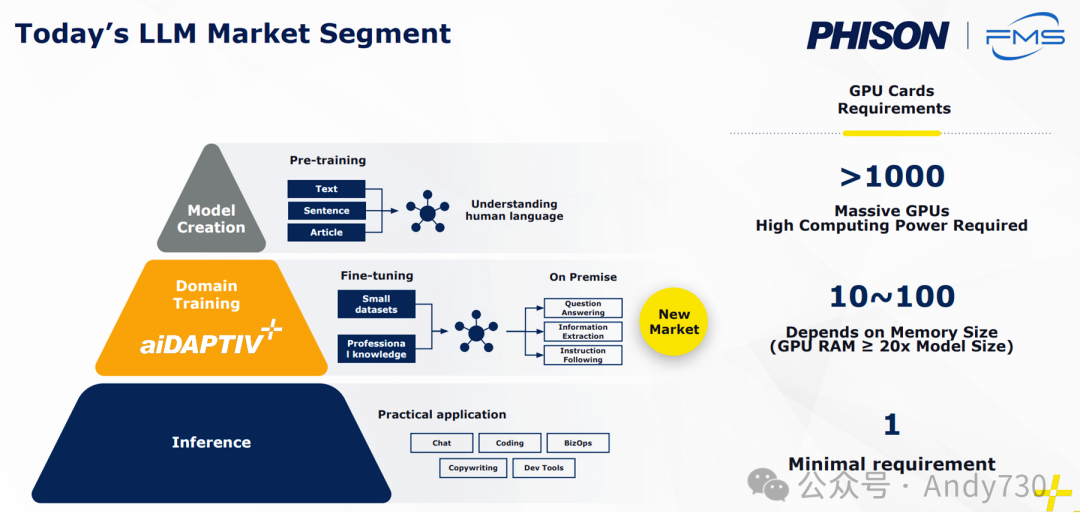
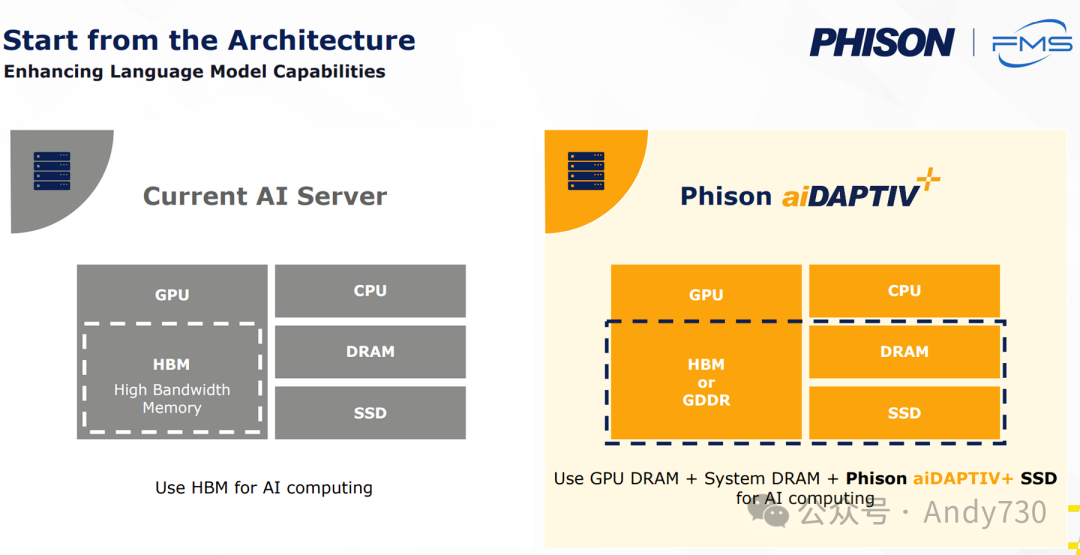
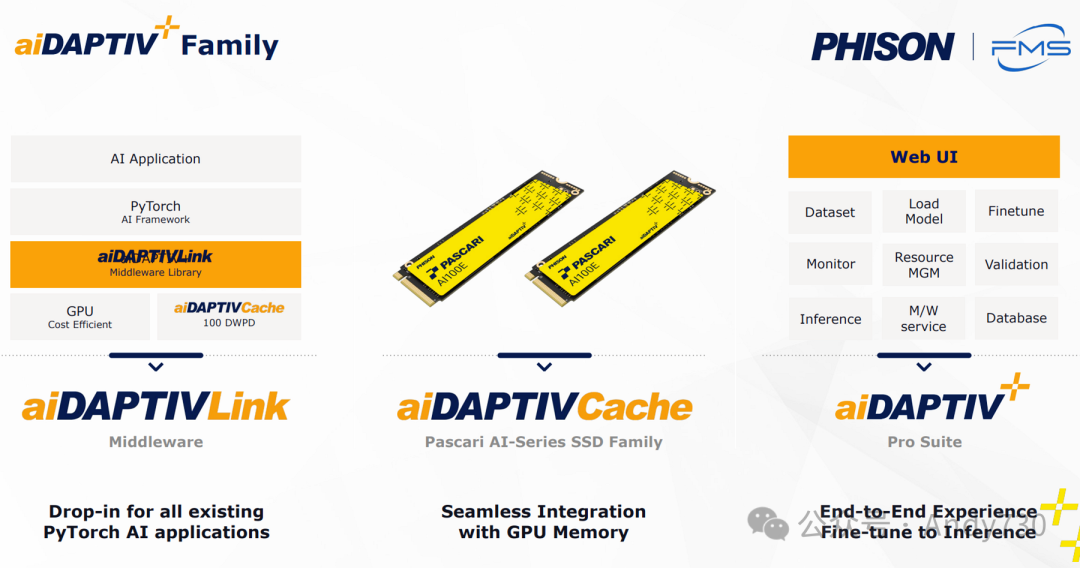
突破100 DWPD:Phison的aiDAPTIVE+如何改变AI训练格局
群联电子(Phison)在其展位上着重展示了其面向企业级/数据中心应用的SSD以及PCIe重新定时器解决方案。作为控制器/芯片领域的佼佼者,群联过去主要通过与硬盘制造商合作,将其创新解决方案推向市场。在企业级领域,与希捷(Seagate)携手推出的X1系列(及其后续的Nytro品牌企业级SSD)尤为知名。希捷不仅提供了详细的需求清单,还在最终固件的制定上拥有话语权,随后将认证后的硬盘提供给其数据中心客户。这一认证流程耗资巨大,仅大型公司能够承担(从而将众多二线消费级SSD供应商拒之门外)。
在去年的闪存记忆体展(FMS)上,群联展示了其Gen 5 X2平台,作为X1系列的延续之作。然而,鉴于希捷正全力推进HAMR技术,并在其他领域遭遇挑战,群联决定独立推动X2的认证流程。更宏观地看,群联也意识到,长期依赖白标策略推广企业级SSD并不可持续。因此,Pascari品牌应运而生,旨在使群联的企业级SSD更易于被终端市场接纳。
Pascari品牌下,群联精心打造了多条产品线,以满足不同应用场景的需求:从X系列的高性能企业级硬盘,到B系列的启动盘,再到AI系列,后者支持高达100 DWPD(详细见下文aiDAPTIVE+部分)的多种配置。
其中,D200V Gen 5硬盘以其领先的61.44 TB容量脱颖而出(同系列还规划有122.88 TB版本)。该系列采用QLC技术,虽导致持续顺序写入速度降至2.1 GB/s,但非常适用于读密集型工作负载。
相比之下,X200作为Gen 5 eTLC硬盘,提供了高达8.7 GB/s的顺序写入速度。它分为读密集型(1 DWPD)和混合工作负载(3 DWPD)两种版本,容量最高可达30.72 TB。而X100 eTLC硬盘则是X1/Seagate Nytro 5050平台的升级版,搭载了更新的NAND技术和更大的存储容量。
这些硬盘均配备了企业级硬盘的标配功能,如断电保护和FIPS认证。尽管群联并未大肆宣传,但预计未来的固件更新将引入更多先进的NVMe功能,如灵活数据放置。
值得一提的是,群联还展示了如何在普通桌面工作站上实现超过100 GB/s的顺序读写速度,尽管这并非纯粹的企业级演示。他们通过安装两块HighPoint Rocket 1608A扩展卡(每卡配备八个M.2插槽),并将16个M.2硬盘配置为RAID 0阵列,成功实现了这一目标。
HighPoint Technology与群联一直紧密合作,致力于将基于E26的硬盘认证应用于此类场景,未来评测中将有更多相关内容呈现。
在群联展位上,另一大亮点是aiDAPTIVE+ Pro套件。去年FMS上,群联曾展示了一款专为Chia挖矿设计的40 DWPD SSD(幸而该热潮已逐渐退去)。如今,群联在耐用性方面更进一步,提升至60 DWPD,甚至接近了Micron和Solidigm基于SLC缓存硬盘的标准。
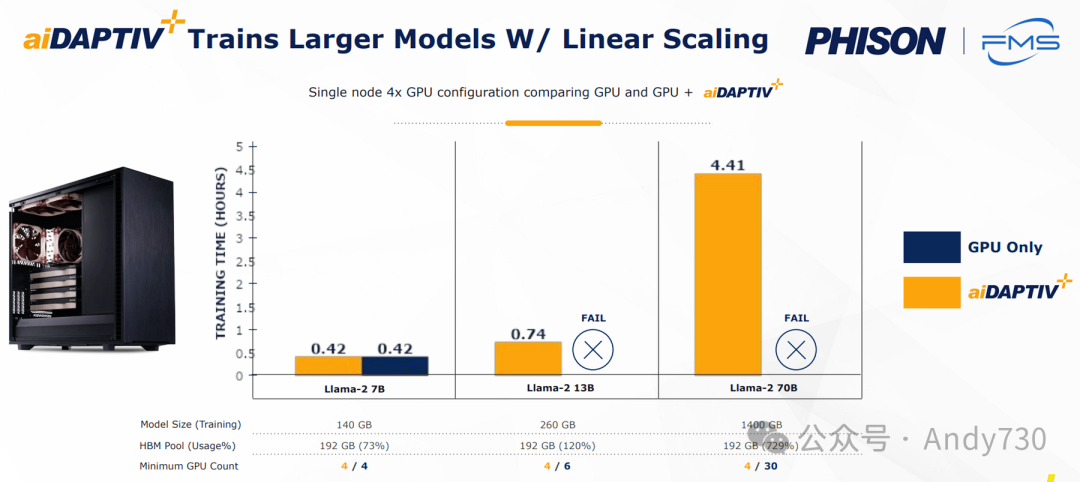
更重要的是,群联在这款SSD上集成了一个中间件层,以确保工作负载保持更高的顺序性,从而将耐用性评级提升至惊人的100 DWPD。这一中间件层现已成为其AI训练套件的一部分,专为那些无法承担全功能DGX工作站或本地微调成本的小型及中型企业量身定制。
通过将这些AI SSD用作GPU VRAM的扩展,企业可以在不依赖高成本AI训练专用GPU的情况下,利用一组相对经济的现成RTX GPU来重新训练模型,从而显著降低总拥有成本(TCO)。该中间件还包含了与AI系列SSD(目前支持Gen 4 x4接口,提供U.2或M.2规格尺寸)购买相关的许可服务。利用SSD作为缓存层,企业可以在使用最少GPU资源的情况下,对具有庞大参数的模型进行微调,无需过度依赖GPU的HBM容量。




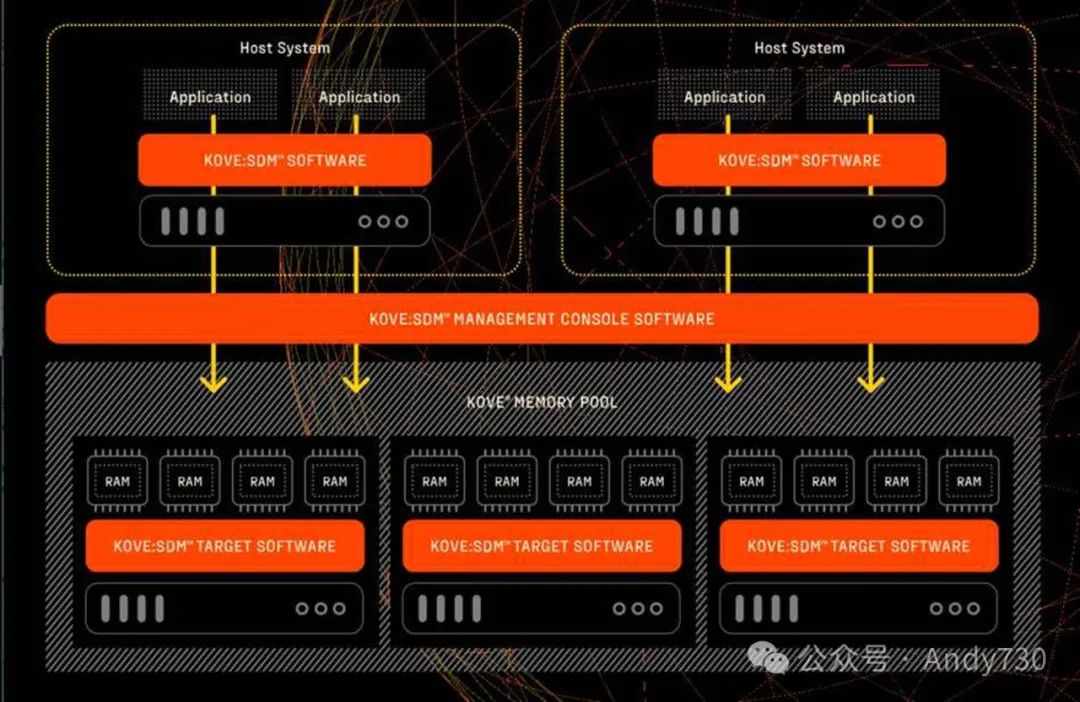
突破内存瓶颈:Kove:SDM引领软件定义内存新时代
Kove在FMS 2024盛会上隆重推出了其革命性的软件定义内存解决方案——Kove:SDM。
Kove的创始人兼首席执行官John Overton先生表示:“随着AI/ML技术的飞速发展以及对内存需求激增的应用不断涌现,敏捷企业已经成功跨越了内存瓶颈的障碍。我们非常荣幸能在FMS上展示Kove:SDM如何赋予任何服务器前所未有的灵活性,使其能够轻松应对大规模服务器需求,并即时将小型服务器转化为任意规模的服务器,以精准匹配实时需求。无论是AI密集型工作负载,如基于庞大数据集的模型训练、内存数据库操作,还是容器化部署,技术人员现在都能实现以往难以想象的目标。”
为了全面展现Kove:SDM的技术和操作优势,我们基于Red Hat OpenShift应用平台进行了深入的测试,测试工具包括StressNG、Intel P-States以及标准的Supermicro服务器硬件。测试结果显示,相较于传统本地内存,Kove:SDM能够在现有基础设施上节省高达54%的电力消耗,同时接近本地CPU的性能水平,并提供卓越的远程内存访问性能,而且这一切都不需要修改任何代码。
此外,Overton先生与Zschach还将共同探讨Kove与Swift如何携手推动金融犯罪预防的创新。他们将详细阐述Kove:SDM如何在风险极高的环境下保护客户交易安全,确保业务连续性和数据安全性。
值得强调的是,Kove:SDM是全球首个也是目前唯一成熟的商业化软件定义内存解决方案。在FMS的主题演讲中,Red Hat将分享实证测试结果,这些结果充分展示了Kove:SDM如何助力业务关键应用在节省时间和能源的同时,显著提升性能,降低成本和复杂性。Swift也将介绍Kove:SDM如何助力他们为全球客户构建坚不可摧的经济犯罪防线,并演示该集中内存解决方案如何在标准现有基础设施上无缝运行,无需任何代码改动。
从硬件资源中榨取更多价值,相比虚拟机,工作负载处理速度提升高达60倍;通过将所有作业直接在内存中处理,避免交换操作,处理速度更是提升了125倍。 集群上运行的容器数量显著增加,提升幅度高达100倍。 节省高达54%的电力消耗。 提供媲美本地内存的卓越远程内存访问性能。 通过内存池化和灵活配置,实现内存资源的最大化CPU利用。 无论数据规模或计算需求如何变化,都能显著提升内存的扩展性、易用性、效率和整体性能。
MaxLinear推出Panther III存储加速解决方案
MaxLinear公司自豪地展示了其创新的Panther III存储加速解决方案,该方案以其卓越的压缩、加密及安全性能脱颖而出。
Panther III在性能上实现了质的飞跃,吞吐量提升高达40倍,延迟改善多达190倍,CPU利用率更是大幅降低至千分之一。相较于纯软件解决方案,Panther III能够显著减少闪存使用量和所需的CPU核心数,从而为用户带来显著的成本节约。
Panther III开创了一个全新的“存储加速器”产品类别,它不仅仅是一款产品,而是一套完整的解决方案。与单一的加密或压缩解决方案不同,Panther III集压缩、去重、加密、数据保护及实时验证等存储加速功能于一身,全部集成在硬件之中。这一设计旨在分担并加速特定的数据处理任务,相较于传统的软件方案、FPGA及其他竞争对手,Panther III在性能提升、存储成本节省及能源效率方面均展现出显著优势。
MaxLinear公司以太网及存储加速器业务副总裁Vikas Choudhary表示:“Panther III精准满足了数据中心管理员和数据集所有者的迫切需求。在AI技术蓬勃发展的今天,他们既追求高效节能的存储方案,又渴望实现数据的快速、安全、准确存取。Panther III无疑是数据存储技术的一大飞跃,它为我们提供了一个无与伦比的解决方案,完美适应了数据管理和存储领域日新月异的发展态势。”
当前,数据存储市场正经历着前所未有的增长,AI技术的兴起成为主要推动力。据Fortune Business Insights 2024年报告预测,全球云存储市场已从2023年的1086.9亿美元规模,预计将在2032年增长至6650亿美元,年均增长率高达22.4%。然而,这一增长也伴随着电力需求的激增。国际能源署(IEA)报告指出,2022年数据中心消耗的电力已占全球电力使用的2%,其中大部分用于计算和冷却。而Uptime Institute更预测,到2025年,AI将占据数据中心行业全球电力使用的10%。
Panther III在降低存储系统总拥有成本方面展现出了两大突破:一是减少加密、压缩等常见存储操作对CPU核心的依赖;二是通过高达12:1的数据压缩比,显著降低每GB闪存驱动器的成本。
虽然基于软件的压缩和加密解决方案在灵活性上占有优势,但其对CPU核心的高度依赖却带来了不容忽视的隐性成本。在需要高数据吞吐量的场景中,所需CPU核心数量可能极其庞大。例如,为实现200Gb/s的数据吞吐率,传统软件方案需动用约3100个CPU核心,按每个核心50美元的成本计算,仅CPU核心费用就高达157,000美元。而Panther III仅需3个CPU核心便能轻松应对,展现出其非凡的性价比。
在闪存驱动器方面,Panther III同样带来了显著的成本节约。以一台配备8个1TB NVMe驱动器的1U AFA存储服务器为例,每个驱动器成本约为240美元,原始存储容量为8TB。然而,在实际应用中,由于存储开销和压缩不足等问题,有效存储容量往往大打折扣。而通过Panther III的12:1数据压缩比,该服务器的有效存储容量可提升至96TB,极大提升了存储效率并降低了成本。
在演示环节,首先展示了单个Panther III卡的强大卸载能力,实现了200Gb/s的吞吐率,并展示了其增强的内存带宽和显著的电力节省效果。参会者亲眼见证了Panther III硬件加速在处理密集型工作负载时的卓越性能与低能耗优势。
随后,演示了多个Panther III卡在单台服务器中的协同工作能力,进一步强调了其在可扩展性、性能及能源效率方面的卓越表现。这一演示不仅展示了数据中心客户可以实现的显著效益,还揭示了Panther III在扩展过程中如何保持高性能、低延迟及高效率,同时实现电力使用的最小化与效果的最大化。

Nimbus Data与Tesla联手打造:全球首个移动全闪存数据中心BatArray
Nimbus Data公司震撼发布了BatArray,这一创新之作将顶尖的FlashRack全闪存系统与Tesla的Cybertruck电动皮卡完美结合,共同打造出全球首屈一指的移动闪存存储数据中心。
BatArray不仅彰显了Nimbus Data全闪存系统的卓越能效,也体现了Tesla电动汽车电池技术的非凡实力,为应对AI时代的数据洪流提供了前所未有的解决方案。
Nimbus Data的首席执行官兼创始人Thomas Isakovich兴奋地表示:“虽然无法确认Elon Musk在设计Cybertruck时是否预见到它会成为一个防弹的移动数据中心,但Tesla确实打造出了一台具备这种潜力的非凡之作。我们非常荣幸能够展示,当Cybertruck与市场上最节能的闪存存储系统携手时,能够创造出怎样的奇迹。”
行业分析师预测,边缘数据的增长速度将迅速超越传统数据中心,由此带来了一系列新的挑战,包括如何高效地分析、归档或迁移这些数据。对于PB级的数据(如数字媒体、金融记录、卫星图像或科学数据)而言,即便是在最快速的网络环境下,通过互联网传输也可能需要数月乃至数年的时间,这主要受限于光纤网络的容量和物理定律。
BatArray巧妙地解决了这一问题,它搭载了6台FlashRack Turbo系统,每台系统提供1.5PB的存储容量,总计可达9PB的原始全闪存存储。考虑到冗余和高达3:1的数据压缩比,BatArray的理论有效容量更是惊人地达到了25PB。更令人赞叹的是,Cybertruck的货箱内配备了一个240V 40A的电源电路,原本设计用于为现场工作工具供电,但由于FlashRack Turbo的超高能效,这一电路足以支撑整个存储系统的运行。更令人称奇的是,Cybertruck的123kWh电池能够确保整个存储系统在没有外接电源的情况下持续运行24小时。
BatArray不仅外观酷炫,性能更是出类拔萃。凭借其独特的并行内存架构,BatArray实现了高达360GB/s的入站性能,接近3Tb/s的惊人速度,这一数据速率是亚马逊AWS Snowmobile(基于45英尺长的半挂车)的3倍之多。所有数据均通过硬件自动加密处理,采用AES-256加密标准并支持KMIP协议,确保数据传输的安全性。而出站速度更是达到了惊人的600GB/s,接近5Tb/s的极限。
在最大性能模式下,BatArray仅需约7小时即可达到满负荷状态,而此时Cybertruck的电池仍能保持超过200英里的续航能力,无需中途充电即可顺利到达目的地。借助400GbE FR4光纤电缆和收发器,BatArray能够在长达2公里的距离内保持高速数据传输,轻松连接源点或目的地。此外,BatArray还支持行业标准的NFS、SMB、S3和NVMe-oF协议,确保与各类系统的无缝兼容。


参考资料
https://blocksandfiles.com/2024/08/08/sk-hynix-computational-object-storage-accelerates-analytics/ https://news.skhynix.com/sk-hynix-presents-extensive-ai-memory-lineup-at-expanded-fms-2024/# https://www.anandtech.com/show/21519/kioxia-details-bics-8-at-fms-2024 https://www.anandtech.com/show/21526/samsungs-128-tbclass-bm1743-enterprise-ssd-displayed-at-fms-2024 https://www.anandtech.com/show/21527/phison-enterprise-ssds-at-fms-2024-pascari-branding-and-accelerating-ai https://www.servethehome.com/kioxia-optical-interface-ssd-demoed-at-fms-2024/ https://www.storagenewsletter.com/2024/08/07/fms-2024-kovesdm-software-defined-memory-solution/ https://www.storagenewsletter.com/2024/08/07/fms-2024-maxlinear-to-demo-panther-iii-storage-accelerator-solutions/ https://www.storagenewsletter.com/2024/08/07/fms-2024-microchip-pcie-gen-5-flashtec-nvme-5016-ssd-controller-family/ https://www.storagenewsletter.com/2024/08/07/fms-2024-msi-cxl-memory-expansion-server-with-samsung-cxl-memory-modules-and-memverge-memory-machine-x-software/ https://www.storagenewsletter.com/2024/08/07/fms-2024-silicon-motion-launches-best-performance-watt-sm2508-pcie-gen5-ssd-controller/ https://www.storagenewsletter.com/2024/08/07/fms-2024-western-digital-reveals-new-solutions/ https://www.storagenewsletter.com/2024/08/13/fms-2024-nimbus-data-batarray-mobile-data-center-powered-by-tesla-cybertruck/ https://www.storagenewsletter.com/2024/08/13/recap-of-fms-2024/ https://www.techtarget.com/searchstorage/news/366604876/Memory-and-storage-experts-share-highlights-from-FMS-2024 https://www.youtube.com/watch?v=t2s-V3V1_FA
---【本文完】---
近期受欢迎的文章:
更多交流,可添加本人微信
(请附姓名/单位/关注领域)

