




计算资源 GPU型号:Nvidia H100 GPU数量:目标是10万个,但预计到2024年12月可能只有2.5万个GPU到位,整个集群预计在2025年才能完全扩展。 服务器和节点 服务器架构:基于八路HGX GPU板卡的Supermicro机架级系统,总共1.25万个节点,每个节点配置8个GPU。 网络架构 后端网络:使用Nvidia的Spectrum-X以太网解决方案,包括Spectrum-4交换机、BlueField-3 DPU和新的软件技术,优化AI处理,提供1.6倍于传统以太网的网络性能。 前端网络:由Juniper Networks提供,负责数据访问和节点管理。 存储系统 存储类型:尚未确定,但可能包括Supermicro的混合闪存和磁盘存储阵列,或来自VAST Data或Pure Storage的全闪存阵列。 电力需求 电力分配:目前工厂有8兆瓦的电力分配,计划在未来几个月内增加到50兆瓦,目标是150兆瓦。 数据中心位置 地点:田纳西州孟菲斯市,改造自旧Electrolux工厂。
-----
埃隆·马斯克旗下的多家公司,包括SpaceX、Tesla、xAI和X(原Twitter),都对GPU有着巨大需求,各自都有特定的AI或HPC项目要求。然而,现有的GPU数量远不能满足这些公司的宏伟计划。因此,马斯克必须慎重考虑如何分配有限的GPU资源。
马斯克曾于2015年参与创立OpenAI。2018年,一场围绕AI模型大规模投资及其治理问题的权力斗争爆发,导致马斯克离开了OpenAI。这一变故为Microsoft带着雄厚资金进入该领域提供了契机。眼看OpenAI迅速成长为生产级生成式AI的领头羊,马斯克当机立断,于2023年3月创立了xAI。自成立以来,这家新兴公司一直在积极争取资金和GPU配额,力图建立具有竞争力的基础设施,以与OpenAI/Microsoft、Google、AWS、Anthropic等行业巨头一较高下。
筹集资金反而是相对容易的部分。
五月底,Andreessen Horowitz、Sequoia Capital、Fidelity Management、Lightspeed Venture Partners、Tribe Capital、Valor Equity Partners、Vy Capital和沙特王室旗下的Kingdom Holding联手为xAI提供了60亿美元的B轮融资,使其总融资额达到64亿美元。这无疑是一个良好的开端。更为有利的是,马斯克从Tesla获得了一份高达450亿美元的薪酬方案,这使他能够随时为xAI追加GPU采购资金。(当然,他可能会明智地预留一部分资金,用于Tesla、X和SpaceX的GPU配额。)
从某种角度来看,特斯拉将一次性支付给马斯克440亿美元的薪酬,这与他在2022年4月收购X所耗资金额相当,甚至还多出10亿美元。这笔钱足够购买2.4万个GPU的集群,可谓是一笔惊人的"零花钱"。诚然,特斯拉确实颠覆了汽车行业,2023年实现了968亿美元的销售额,其中150亿美元为净收入,现金储备高达291亿美元。但即便在当今这个新的富足时代,如此巨额的薪酬方案仍显得格外离谱。然而,马斯克有其宏伟蓝图,而且他拥有一个愿意牺牲特斯拉现金流以讨好他的董事会。
基于同样的逻辑,我们不妨设想一下:通过从美国银行、阿布扎比主权财富基金和其他任何可能的资金来源借款,我们进行一笔6500亿美元的收购,买下摩根大通。然后在来年领取一份略高于收购成本的薪酬,比如6750亿美元。之后我们可以将其更名为"TPMorgan Caught",并在偿还贷款后还能剩下250亿美元任意支配。这样的设想虽然荒谬,却恰恰反映了当前情况的不合理性。
不过,我们似乎偏离了主题。而且这种跑题似乎总是充满热情地频繁发生。
这就引出了xAI对计算、存储和网络资源的巨大需求。xAI成立后不久,即2023年8月,就训练出了拥有330亿参数的Grok-0大语言模型。紧接着在2023年11月,xAI推出了Grok-1模型,这是一个具备对话功能的AI,其参数规模扩大到了3140亿。该模型于2024年3月开源。随后不久,xAI又发布了Grok-1.5模型,这一版本具有更大的上下文窗口,在认知测试中的平均表现还超越了Grok-1。
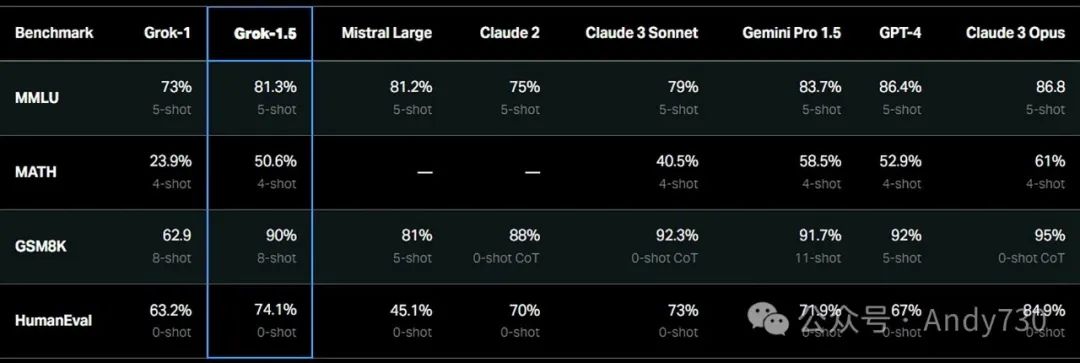
由此可见,Grok-1.5的性能仍略逊于谷歌、OpenAI和Anthropic的同类产品。
即将面世的Grok-2模型计划使用2.4万个Nvidia H100 GPU进行训练。据报道,该模型将在Oracle的云基础设施上训练,预计8月发布。(Oracle已与OpenAI达成协议,吸收xAI未用完的GPU算力。)
马斯克在多条推文中表示,Grok-3将于年底前推出,训练需要一个拥有10万个Nvidia H100 GPU的集群,其性能将与OpenAI和Microsoft正在研发的未来GPT-5模型不相上下。Oracle和xAI正就GPU算力达成协议。三周前,与Oracle的100亿美元GPU集群协议传闻破裂后,马斯克迅速转变策略,决定在田纳西州孟菲斯南部的一家废弃Electrolux工厂建立"计算超级工厂",以容纳自己的10万个GPU集群。如果你住在孟菲斯,情况可能会变得有些疯狂,因为xAI希望为其分配150兆瓦的电力。
据彭博社报道,目前工厂分配了8兆瓦电力,未来几个月内可增至50兆瓦。要超过这个限额,田纳西河谷管理局需要处理大量文书工作。
顺便提一下,如果你在孟菲斯拥有一台大规模超级计算机,绝对不能给它起一个与“猫王”埃尔维斯·普雷斯利无关的昵称。你可以在未来几年为后续机器命名时,依次使用猫王不同时期的名号。例如,你可能会想称这台机器为“Hound Dog”(猎犬),代表猫王早期的摇滚乐时期。然而,如果马斯克无法在12月前获得全部10万个H100配额,除非Nvidia愿意出手相助(这似乎不太可能),那么它可能会被称为“Heartbreak Hotel”(心碎旅馆)。
上周,马斯克发布了一条推文:

因此,它可能会被命名为SuperCluster,这与Meta Platforms购买而非自建的AI训练机群所用的术语相同。
我们认为10万个GPU的数量只是一个理想目标。到12月份,xAI可能只会达到2.5万个GPU,但即便如此,它仍然足以训练一个规模相当可观的模型。根据我们看到的一些报道,孟菲斯的SuperCluster可能要到2025年下半年才能完全建成,我们认为这种说法是合理的。
从Supermicro创始人兼CEO梁见后(Charles Liang)在社交平台X上的发言可以推断,Supermicro正在为xAI的孟菲斯数据中心部署水冷服务器:
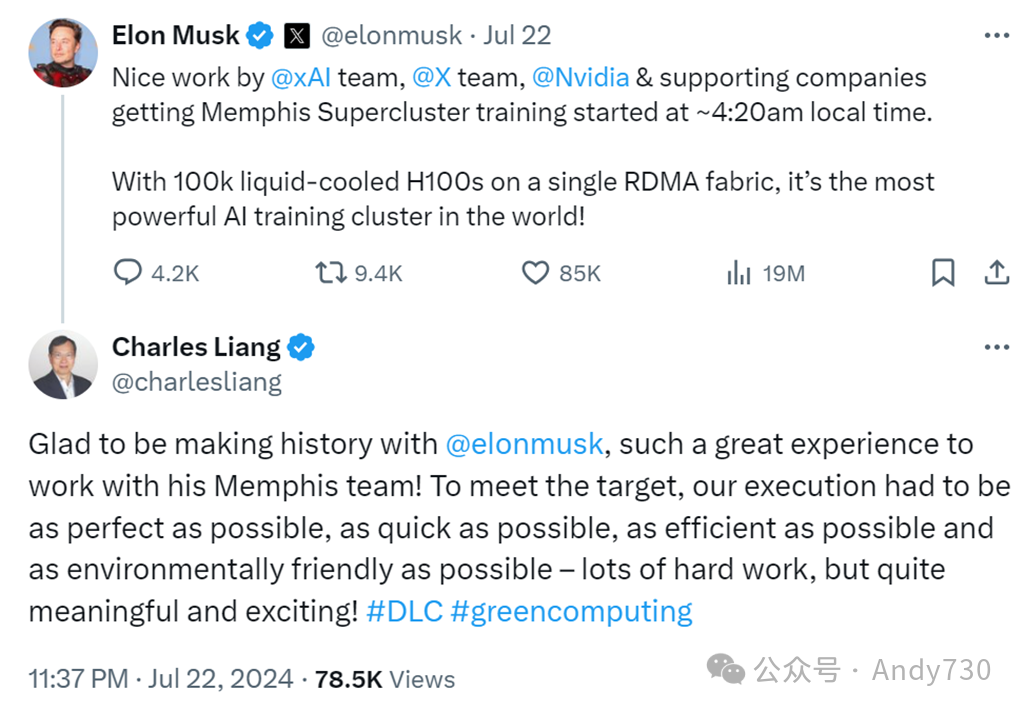
虽然没有关于服务器基础设施的具体细节,但我们有理由推测,这套系统很可能基于八路HGX GPU板,并采用Supermicro的机架级系统。这一设计灵感可能来自Nvidia的SuperPOD配置,但Supermicro可能进行了自己的工程优化,并提供更具竞争力的价格。如果使用八路HGX板,整个系统可能包括1.25万个节点,总计10万个GPU。此外,还需要10万个后端网络端点,以及1.25万个前端网络端点,用于访问集群中的数据和管理节点。
Juniper Networks的首席执行官Rami Rahim也参与了孟菲斯SuperCluster的相关讨论:
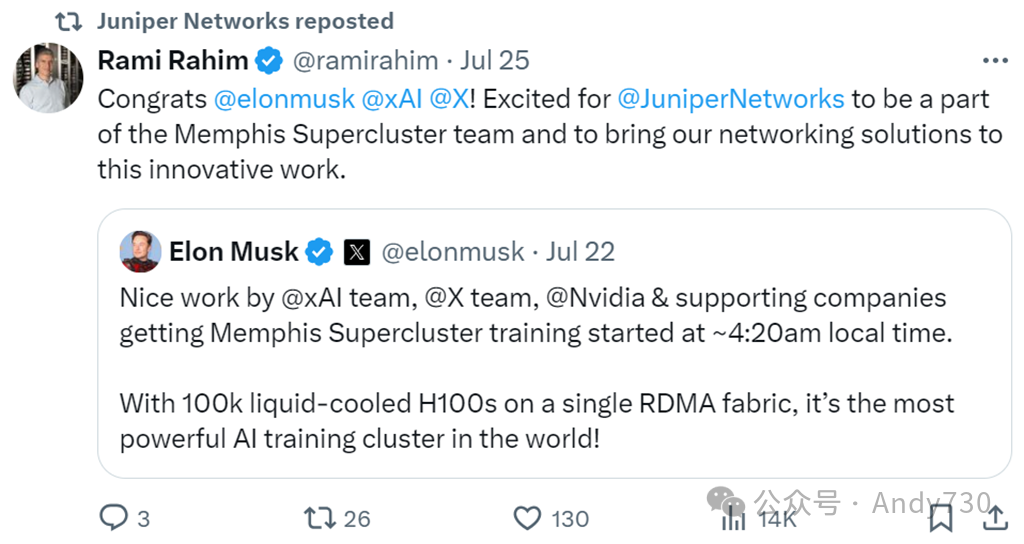
仅从这些社交媒体发言来看,可能会认为Juniper已经赢得了孟菲斯SuperCluster的网络合同。考虑到Arista Networks和Nvidia在AI集群网络方面的巨大影响力,这将是令人意外的结果。我们没有看到Arista或Cisco Systems关于这个系统的任何信息,但在5月22日,Nvidia公布2025财年第一季度财报时,首席财务官Colette Kress表示:
不得不承认,全球范围内10万GPU的交易并不常见。现在看到马斯克关于该系统的言论后,我们几乎可以确定Nvidia五月份声明中提到的就是孟菲斯SuperCluster。因此,我们推测Nvidia通过Spectrum-X设备获得了该项目的后端(或东西向)网络部分,而Juniper则负责前端(或南北向)网络部分。Arista对此似乎没有任何表态。
我们尚未看到任何关于孟菲斯SuperCluster将使用何种存储的信息。它可能是基于Supermicro提供的闪存和硬盘混合的原始存储阵列,运行各种文件系统;也可能是来自VAST Data或Pure Storage的全闪存阵列。如果非要我们做出猜测,我们倾向于认为VAST Data可能参与了这笔交易的大部分存储供应。不过,这仅仅是基于该公司在过去两年中在HPC和AI领域的大型存储阵列方面取得的进展而做出的推测。
---【本文完】---
近期受欢迎的文章:
更多交流,可添加本人微信
(请附姓名/单位/关注领域)

