




运行大型语言模型(LLM)是一项复杂而富有挑战性的任务。主要挑战在于模型规模巨大,对计算资源和存储空间提出了极高的要求。为了解决这一问题,模型分片技术至关重要,它可以将模型分割到多个服务器上,有效分散计算负载。此外,精心设计和优化模型服务和推理流程对于处理高并发请求和数据至关重要。
构建和维护支持所有这些的基础设施还需要深厚的技术知识,涵盖分布式计算、数据管理和机器学习等多个领域。基础设施建设本身就是一个复杂的过程,需要在硬件和软件层面进行大量投资。
大型语言模型的成本考量
1. 编译成本高昂
大型语言模型的编译过程不仅耗时费力,还需大量计算资源和专业知识支持,往往需要在硬件和软件方面进行双重投资。
2. 托管成本不菲
托管这类模型需要构建庞大的基础设施系统,包括服务器、存储系统和网络设备,成本因模型的大小和复杂度以及所选择的托管服务提供商而异。
3. 运营开销持续
模型的长期运营需要持续的维护和支持,包括软件更新、数据备份和安全措施,这些费用会随着时间的推移而累积,需要由专业团队进行管理。
4. 多模型部署挑战
在某些情况下,可能需要部署和管理多个模型。每个模型都有自己的资源需求和成本考虑因素,这将增加对资源和专业知识的需求。
综上所述,托管大型语言模型的成本可能很高。但是,在许多情况下,这些模型在自然语言处理领域提供的价值足以抵消成本。
大型语言模型性能考量
1. 模型编译
大型语言模型的编译需要大量的计算资源和专业技术,耗时较长,且可能对模型整体性能造成影响。
2. 模型压缩
压缩大型语言模型可以减小模型体积,并在某些任务上提升性能,但压缩也可能会降低模型的准确性和质量。
3. 延迟
延迟是指模型处理请求并生成响应所需要的时间。对于实时应用而言,降低延迟至关重要,可以通过模型优化和缓存等技术来实现。
4. 吞吐量
吞吐量是指模型在规定时间内所能处理的请求数量。提高吞吐量可以提升模型效率,减少用户等待时间。
5. 可用性
可用性是指模型能够不间断运行的百分比时间。确保高可用性需要对基础设施进行投入,并进行持续的维护和支持。
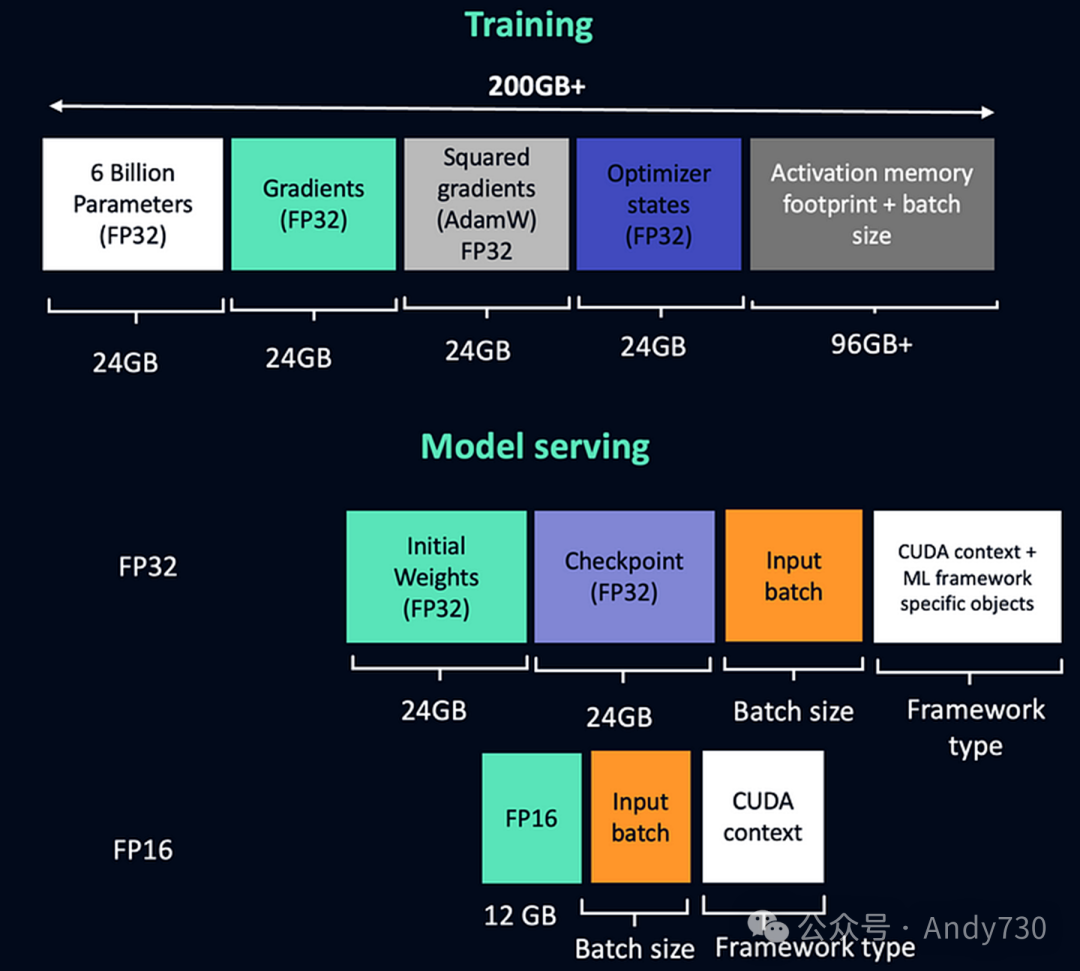
让我们快速了解加载GPT-J模型所需的内存大小。该需求取决于是进行模型训练还是提供模型服务。接下来,我们将简要估算训练GPT-J模型所需的内存。
在FP32精度下,仅加载模型参数就需要24GB内存,同时还需要相同量的内存来存储梯度。此外,Adam优化器会占用额外空间来存储平方梯度,这同样需要24GB内存。再加上存储优化器状态所需的24GB,仅一个GPT-J模型实例的加载就需要消耗高达96GB的内存。然而,这还未计入训练过程中所需的批次数据和激活内存,它们往往会使总内存需求轻松超过200GB。幸运的是,如果采用FP16模型,内存需求几乎能够减半。
那么,部署Llama 70B模型需要多少块GPU呢?为了回答这个问题,我们首先需要明确LLM运行所需的GPU内存容量。这里,我们可以借助一个简单的公式来进行估算。
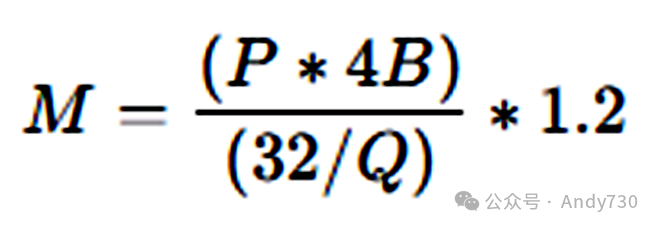
M: GPU内存,单位为GB P: 模型参数数量。例如,7B模型代表有70亿个参数 4B: 4字节,表示每个参数占用的存储空间 32: 强调4字节包含32位信息 Q: 加载模型时使用的位数。如16位、8位或4位量化 1.2: 加载额外元素至GPU内存时产生的约20%开销的系数
接下来,我们通过具体实例进行说明:Llama 70B模型的GPU内存需求。我们计算一下在16位精度下部署Llama 70B模型所需的GPU内存量。该模型拥有700亿个参数。计算公式如下:
70 * 4 bytes 32 16 * 1.2 = 168 GB
由此可见,所需内存量相当庞大。单个80GB的A100 GPU无法满足此需求,但使用两个80GB的A100 GPU则足以在16位量化模式下部署Llama 70B模型。
既然我们已讨论了内存消耗的问题,接下来就谈谈如何利用模型压缩技术来降低内存需求。
以下是用于获取模型大小的Python代码示例:
from accelerate.utils import calculate_maximum_sizes, convert_bytesfrom accelerate.commands.estimate import check_has_model, create_empty_modelimport torchDTYPE_MODIFIER = {"float32": 1, "float16/bfloat16": 2, "int8": 4, "int4": 8}def calculate_memory(model: torch.nn.Module, options: list):"Calculates the memory usage for a model init on `meta` device"total_size, largest_layer = calculate_maximum_sizes(model)data = []for dtype in options:dtype_total_size = total_sizedtype_largest_layer = largest_layer[0]modifier = DTYPE_MODIFIER[dtype]dtype_total_size = modifierdtype_largest_layer = modifierdtype_training_size = convert_bytes(dtype_total_size * 4)dtype_total_size = convert_bytes(dtype_total_size)dtype_largest_layer = convert_bytes(dtype_largest_layer)data.append({"dtype": dtype,"Largest Layer or Residual Group": dtype_largest_layer,"Total Size": dtype_total_size,"Training using Adam": dtype_training_size,})return datamodel_name = 'microsoft/phi-2'model = create_empty_model(model_name, library_name=None, trust_remote_code=True, access_token=None)results = calculate_memory(model, ["float32"])for result in results:print(f"Total size of the Model with dtype {result['dtype']} is {result['Total Size']}")
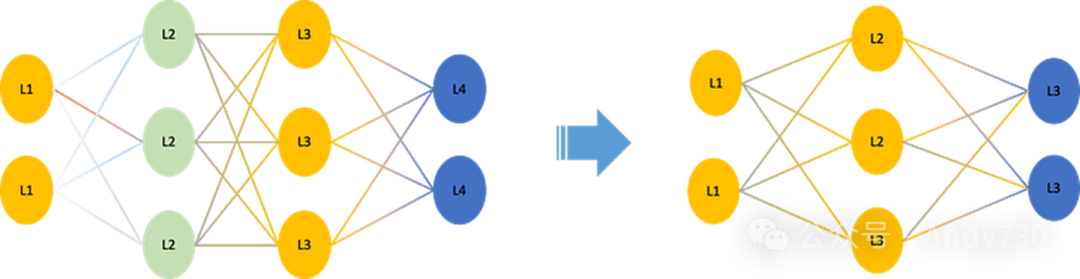
1. 剪枝(Pruning)
剪枝技术旨在从神经网络中剔除冗余或不重要的参数,以此缩减模型规模和计算量。这一过程通过识别并将低值权重参数置为零来实现。其中,结构化剪枝直接移除整个神经元或滤波器,而非结构化剪枝则针对个别权重进行零化。剪枝技术能够在保持模型精度损失最小的前提下,将模型大小缩减超过90%。
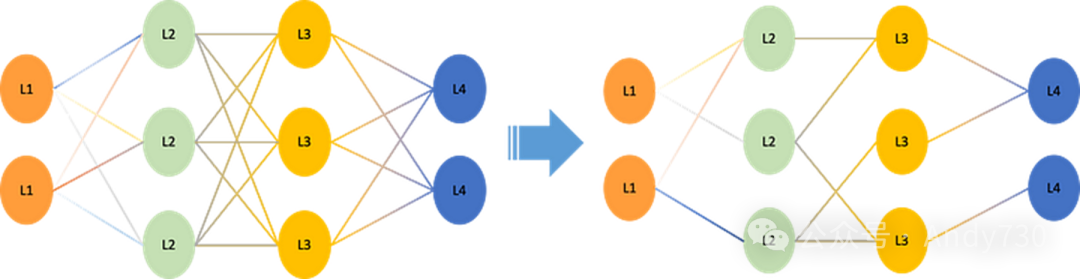
2. 蒸馏(Distillation)
知识蒸馏是一种训练技术,通过一个小型“学生”模型来学习并模仿一个大型“教师”模型的输出分布(软目标),从而捕获到超越简单类别标签的深层知识。这种方法允许学生模型高效地学习到教师模型所掌握的复杂函数关系,同时能在保持精度损失可控的情况下,将计算量减少超过90%。
3. 量化(Quantization)
量化技术通过降低模型权重和激活的数值精度(如从float32降至int8或int4),来减小模型体积并加速在支持整数运算的硬件上的处理速度。这一过程中,会运用剪裁、舍入和重新缩放等手段将连续值离散化,同时尽量保持模型的预测精度。常见的量化策略包括训练后量化、量化感知训练和量化感知微调。

综上所述,剪枝、蒸馏和量化是优化大型AI模型的三大关键策略,它们分别通过精简模型结构、知识传递和降低数值精度来实现模型的高效运行。当这些技术协同作用时,能在几乎不牺牲精度的前提下,大幅度减少模型的规模和计算负担。
张量并行(Tensor Parallelism)
张量并行一种用于大型神经网络模型的并行技术,可以将大规模神经网络层的计算分布到多个设备上。其核心思想是将层划分为称为张量的较小块,并在不同设备上并行计算每个张量。
权重拆分: 将大型层的权重划分到多个设备上,每个设备持有部分权重。 并行计算: 在训练或推理过程中,将输入激活划分并传递给每个设备,设备并行计算其持有的权重和激活。 输出拼接: 收集每个设备的输出并连接起来,形成完整的层输出。 与数据并行对比: 与数据并行不同,后者在每个设备上复制整个模型权重,而张量并行则是将模型本身进行拆分。 支持超大模型: 能够在多个GPU或TPU核心上训练无法在单个设备上容纳的超大模型。 通信需求: 设备之间需要进行通信以收集部分输出,因此高速互联至关重要。 优化挑战: 如何有效地将张量分布到各设备上以最小化通信和负载平衡是活跃的研究课题。
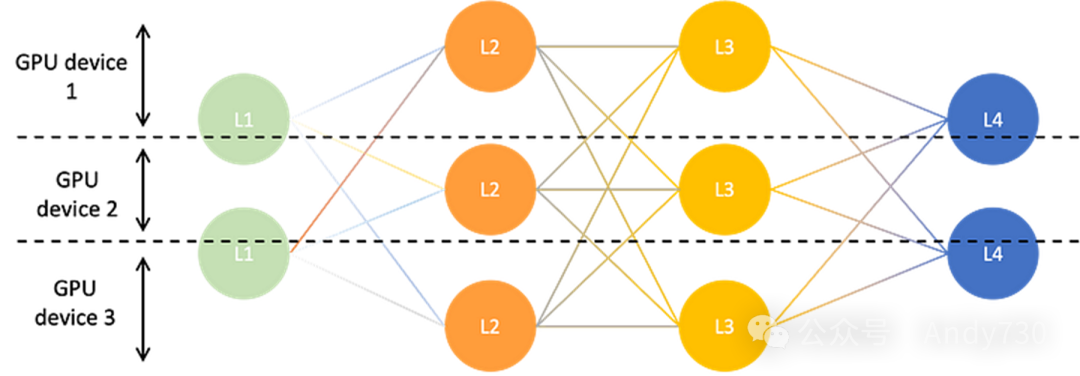
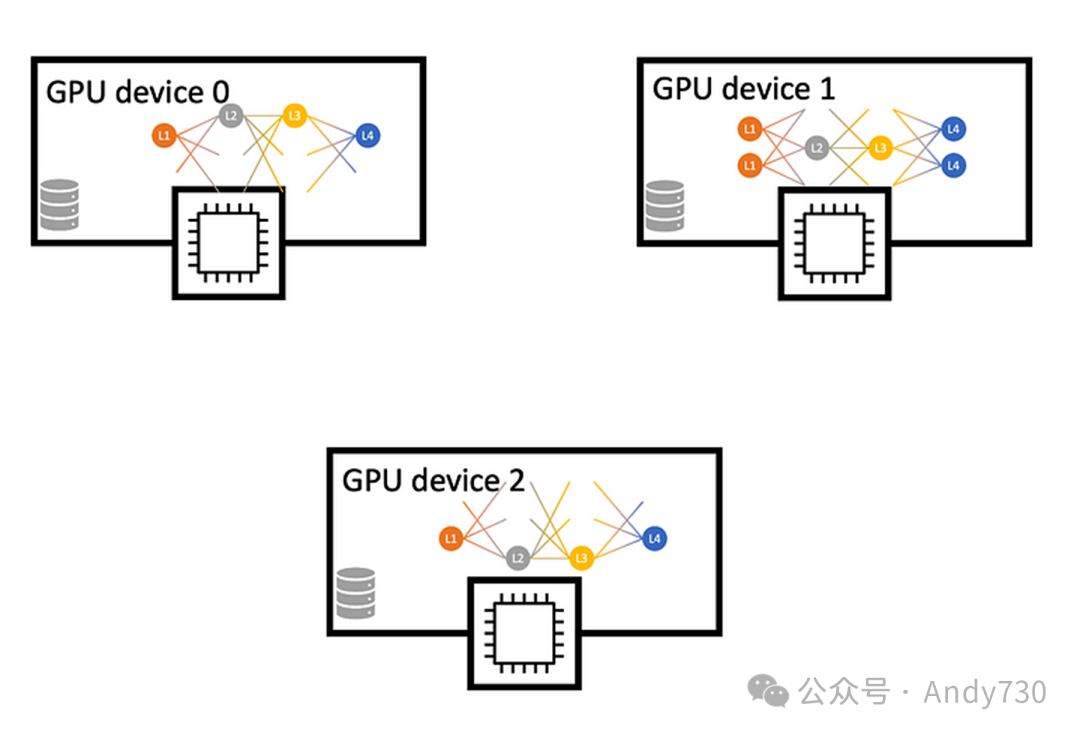
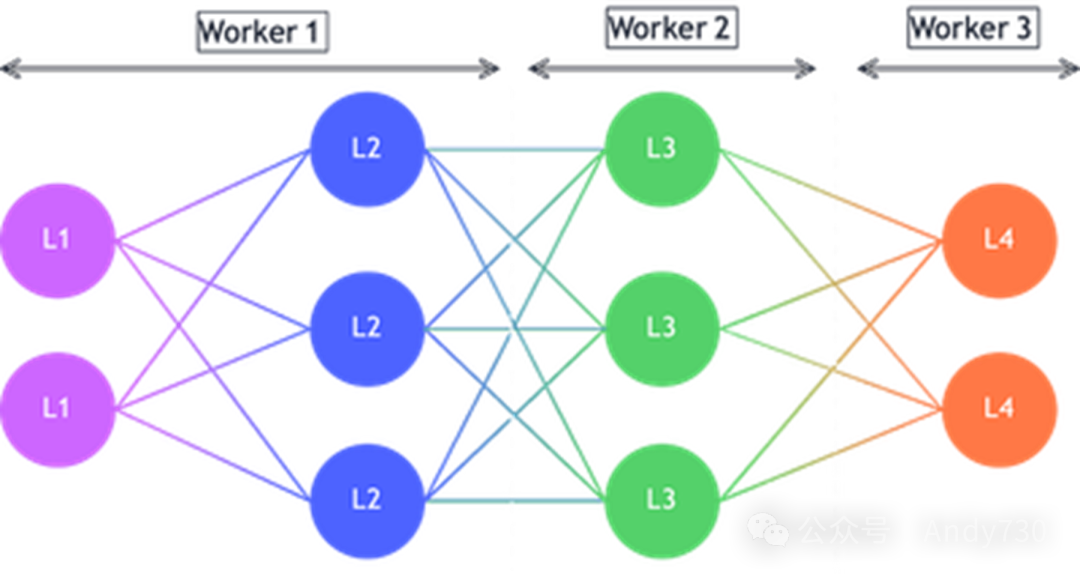
管道并行(Pipeline Parallelism)
管道并行是一种用于大型神经网络模型分布式训练的技术,它跨越多个设备或节点进行。在此模式下,模型被分割成多个连续的部分或阶段,每个阶段被分配给不同的设备进行处理。输入数据以微批次的形式在管道中流动,每个设备独立且异步地在接收到的微批次上执行计算,随后将结果输出传递给管道的下一个阶段。这种方式不仅实现了设备间的并行处理,还允许计算和通信过程相互重叠,从而提高了效率。
与张量并行相比,后者通过沿隐藏维度等内部维度划分张量来将模型分布到不同设备上。例如,大型权重矩阵的不同部分可以分配给不同的设备,这些设备协同工作以计算层的结果,并在每一步骤后同步梯度信息。
管道并行侧重于将模型划分为一系列连续的处理阶段,而张量并行则侧重于对模型内部的张量维度(如隐藏层状态)进行划分。 在管道并行中,设备可以独立且异步地处理微批次数据,而张量并行则要求所有设备在每一步计算后同步梯度,之后才能继续下一步。 管道并行通过优化计算和通信的重叠,实现了更高的硬件利用率。相反,张量并行虽然有助于减少激活内存的使用,但因其需要更多的同步操作,可能会引入额外的开销。 管道并行本质上是对训练样本的划分处理,而张量并行则是对张量本身的划分。这种不同的划分方式可能导致模型在训练过程中的收敛行为有所差异。
巨大的内存占用:GPT-J模型拥有庞大的参数数量,并在解码过程中产生大量的中间状态,导致整个模型及其运行时数据所需的内存空间远超单个加速器芯片的内存容量。尤其是在注意力机制中,键值缓存也消耗了大量的内存资源。 低并行性带来的延迟升高:由于巨大的内存占用,频繁的数据传输成为了瓶颈,尤其是在将参数和缓存加载到计算核心时。这导致了对总内存带宽的极高需求,进而显著增加了延迟。 注意力机制计算的二次方增长:注意力机制的计算复杂度会随着序列长度的增加而呈二次方增长,这使得模型在处理长文本时面临着更加严峻的延迟和计算资源挑战。
为了提升请求处理能力,我们可以考虑以下策略:
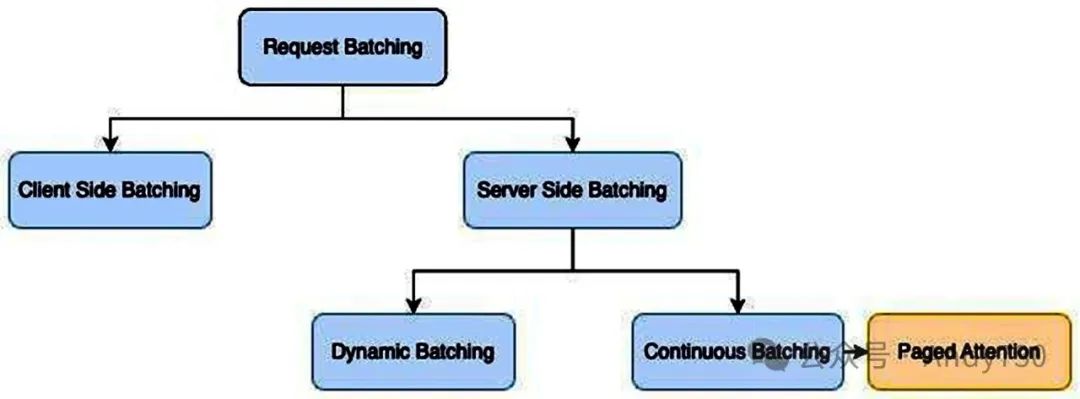
连续批处理(Continuous Batching)
鉴于传统方法的效率瓶颈,业界已探索出更为高效的解决方案。在OSDI '22会议上发表的论文《Orca: A Distributed Serving System for Transformer-Based Generative Models》中,首次提出了一个针对此问题的系统。Orca采用了迭代级调度(iteration-level scheduling)机制,每次迭代时动态确定批次大小。这种方式使得一旦批次中的某个序列完成生成,就能立即被新序列替换,从而相比静态批处理显著提高了GPU的利用率。
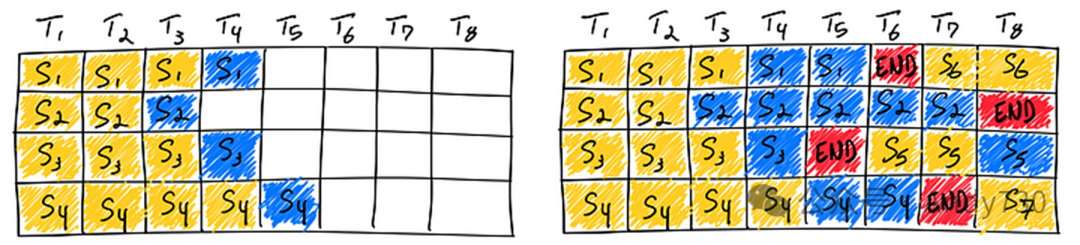
KV缓存(KV Cache)
占用大:以LLaMA-13B模型为例,单个序列的KV缓存占用可高达1.7GB。 动态性强:其大小随序列长度变化,这种高度可变且不可预测的特性使得高效管理KV缓存成为一大挑战。现有系统常因内存碎片和过度预留而浪费60%至80%的内存资源。
PagedAttention机制
受传统操作系统中分页和虚拟内存概念的启发,PagedAttention作为一种新型注意力机制在vLLM(GitHub项目)中得以实现。它允许KV缓存(在“预填充”阶段计算得出)以非连续方式存储,通过分配固定大小的“页面”或块来实现。随后,注意力机制被重新设计以在块对齐的输入上操作,从而支持在非连续内存范围内执行注意力计算。
这种机制的优势在于,缓冲区分配可以按需进行,而非提前预留最大可能的上下文长度。每次迭代时,调度器可灵活决定是否需要为特定生成任务分配更多空间,并即时完成分配,且不影响PagedAttention的性能。尽管这种策略不能保证内存的完美利用(据其博客所述,浪费已控制在最后一个块的4%以内),但它显著改善了传统提前分配方案所带来的内存浪费问题。
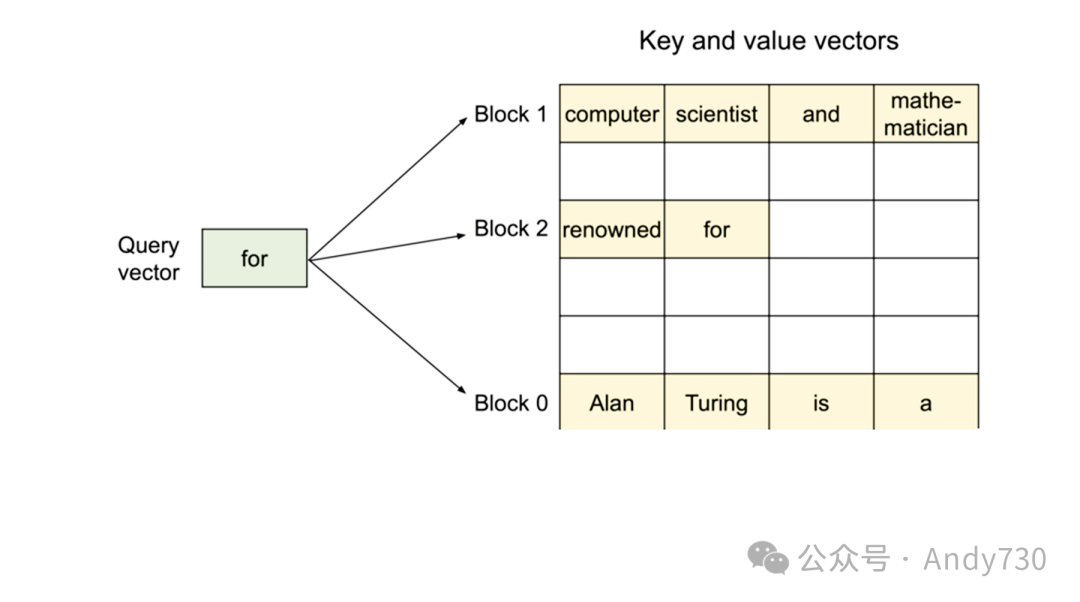
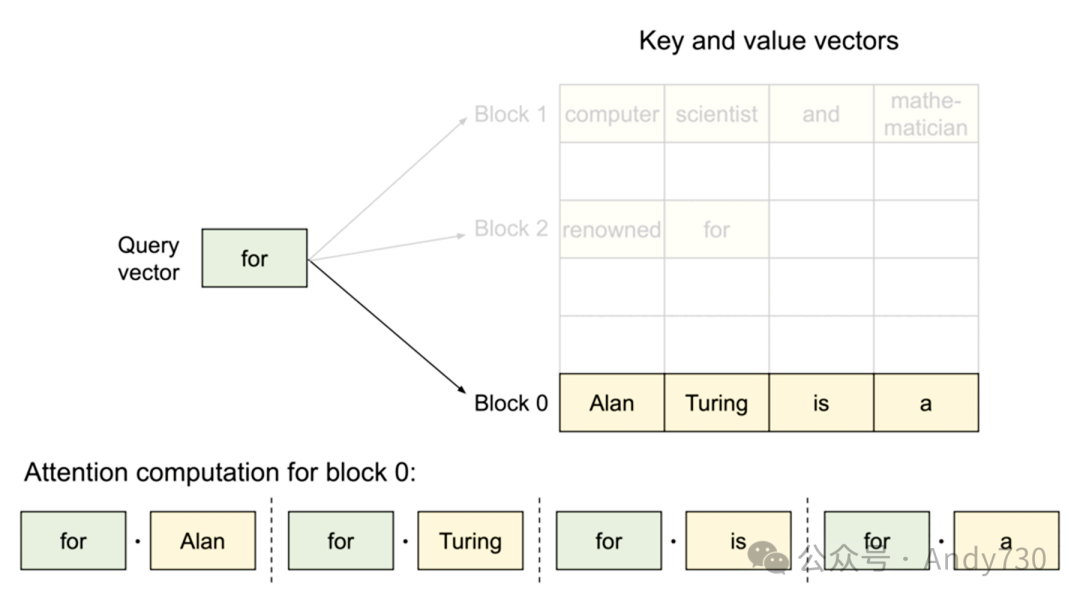
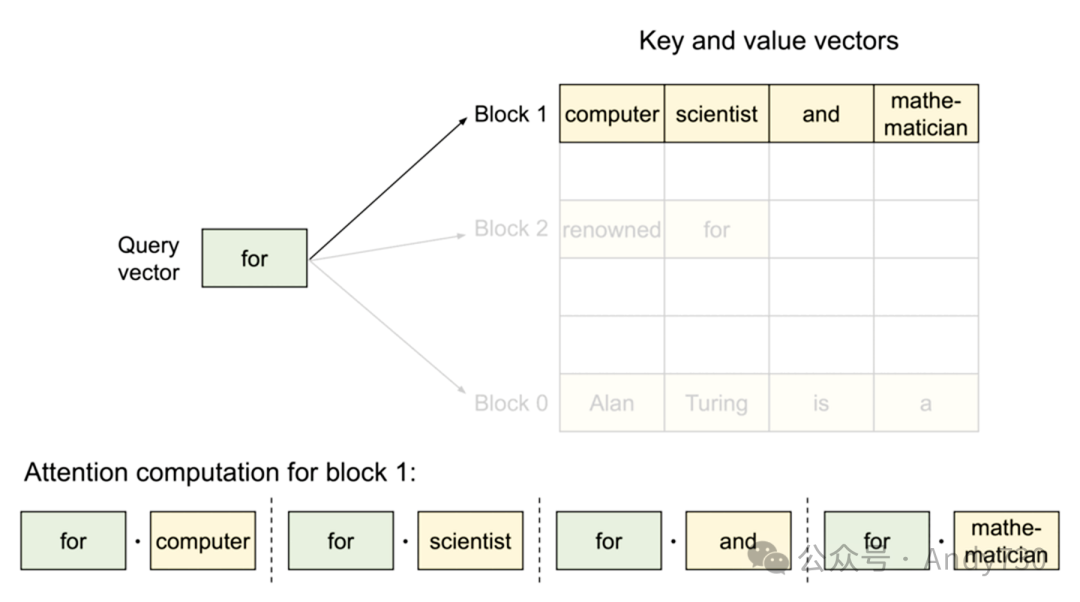
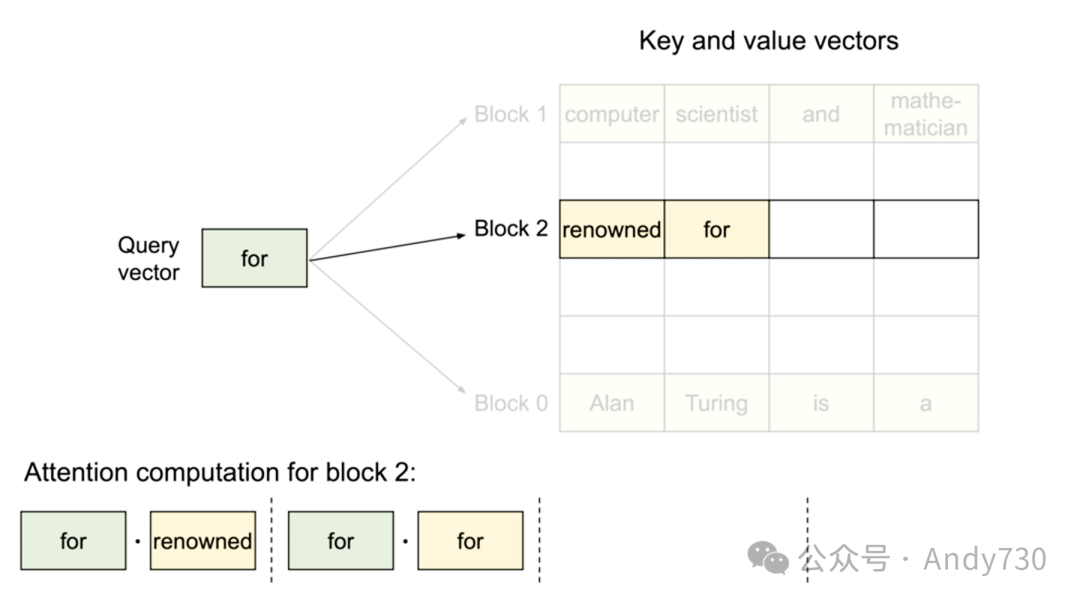
总体效益:PagedAttention与vLLM的结合大幅节省了内存资源,因为大多数序列并不需要占用整个上下文窗口。这些内存节省直接转化为更大的批处理能力和更高的吞吐量,进而降低了服务成本。
动态拆分融合(Dynamic SplitFuse)
长提示拆分:将长提示分解为较小的块,并在多个前向传递中逐步处理,仅在最后一次传递时执行生成操作。 短提示融合:将短提示组合起来,以精确填充目标标记预算。即便对于短提示,也可能进行拆分以确保预算的精确满足和前向传递大小的对齐。
提升响应性:由于长提示不再需要冗长的前向传递,模型能够提供更低的客户端延迟,并在同一时间窗口内执行更多前向传递。 增强效率:短提示的融合使得模型能够在高吞吐量模式下稳定运行。 降低方差,提升一致性:由于前向传递大小保持一致且成为性能的主要决定因素,每次前向传递的延迟相比其他系统更为稳定,从而保证了生成频率的一致性。同时,避免了因抢占或长时间运行的提示而导致的延迟增加问题。
Source:Manoranjan Rajguru; Fundamental of Deploying Large Language Model Inference; Mar 26 2024
--【本文完】---
近期受欢迎的文章:
更多交流,可添加本人微信
(请附姓名/单位/关注领域)

