




CVPR 2024核心亮点回顾:具身AI、生成式AI、基础模型与视频理解 CVPR 2024:基础模型与视觉提示即将重塑计算机视觉领域 我在CVPR 2024的笔记:扩散模型、多模态学习、3D技术以及基础模型方面的突破
CVPR 2024核心亮点:具身AI、生成式AI、基础模型与视频理解
具身AI(Embodied AI)
生成式AI(Generative AI)
基础模型(Foundation Models)
视频理解(Video Understanding)
1. 具身AI(Embodied AI)
 图1. Chris Paxton指出,在处理任何物体的长时间操控任务上,LLM优于传统和复杂方法(如模仿学习)
图1. Chris Paxton指出,在处理任何物体的长时间操控任务上,LLM优于传统和复杂方法(如模仿学习)
主要内容
具身AI是一种前沿的AI技术,旨在构建能够直接与环境交互,从而学习并解决复杂任务的智能实体(包括机器人、智能家居系统等)。
正如主旨演讲者Joshua Bongard所言:“具身AI的含义因人而异,且多年来不断演变”,但其核心特性在于,这些系统能够感知外界环境(利用视觉等多种感官)、使用自然语言进行沟通、理解音频输入、在环境中导航并执行操作以达成目标,同时还能够进行长时间的规划和逻辑推理。
关键洞察
1.现有的AI系统由于缺乏真正的具身化,易受对抗性攻击影响。
Bongard在其主旨演讲中强调,仅将深度学习技术应用于机器人是不够的;具身性需要兼顾系统内部与外部的动态变化。为了构建更安全的AI,我们需要技术能够显著适应内部物理变化。“形态预训练”便是一种通过内部调整来提升AI系统应对新任务和对抗性攻击能力的策略。
2.实现真正“通用型机器人”的路径是通过扩展模拟(scale simulation)。
西雅图艾伦AI研究所(AI2)的计算机视觉高级总监Aniruddha Kembhavi认为,通过广泛扩展模拟数据,智能体可以在无需额外适应或微调的情况下,在现实世界中实现高效的导航和操控。他的Robothor项目正是针对这一问题进行的研究,探索了模型在模拟环境中训练后能否有效泛化至现实世界的可能性。
3.LLMs在长时间跨度物体操作中表现更好,优于之前的方法如模仿学习或更传统的任务和运动规划。
Hello Robot具身AI部门负责人Chris Paxton认为,相比传统的任务与运动规划方法以及模仿学习等复杂策略,LLM在处理需要长时间操控物体的任务时表现更为出色。他提出,通过训练Transformer模型预测物体运动轨迹,结合GPT-4等LLM进行常识推理和用户意图解读,再将这些信息与规划器结合以确保满足约束条件,同时使用空间抽象表示来训练低级运动技能,可以显著提升AI系统在复杂环境中的操控能力。
Joshua Bongard:佛蒙特大学形态学、进化与认知实验室主任
Aniruddha Kembhavi:AI2计算机视觉高级总监,华盛顿大学计算机科学教授
Chris Paxton:Hello Robot具身AI部门负责人
Eric Jang:1X Technologies AI副总裁
Brian Ichter:Physical Intelligence (π)创始人
2. 生成式AI(Generative AI)
 图2. OpenAI研究员Tim Brooks在GenAI主题演讲Sora中
图2. OpenAI研究员Tim Brooks在GenAI主题演讲Sora中
主要内容
如果你在过去24个月里没有完全与世隔绝,那么现在很可能每天都在与生成式AI打交道。生成式AI,顾名思义,是指那些能够创造出全新内容(如文本、图像、音频或视频)的人工智能系统,Google的Imagen便是其中的佼佼者。
SyntaGen:探讨生成模型在合成视觉数据集中的应用
生成视觉艺术的未来:展望生成式AI在艺术创作中的潜力
负责任的生成式AI研讨会:讨论如何确保生成式AI的伦理与责任
计算机视觉的生成模型:研究生成模型在计算机视觉领域的应用
生成基础模型的评估:评估并提升生成基础模型的性能
关键洞察
1.通过执行严格的数据集开发流程,可以揭示创建多模态数据集(包含配对的图像-文本实例)的过程。
在生成基础模型评估研讨会上,AI2的研究员Ludwig Schmidt指出,采用数据中心化的方法能够加速多模态学习的进程。他介绍了一种名为DATACOMP的基准测试集,该基准由38个分类和检索任务组成,旨在通过保持训练代码和GPU预算不变的前提下,比较不同训练集的效果。
2.在丰富且详细的生成图像标题上训练文本到图像模型,显著增强了它们的提示遵循性(prompt-following abilities)。
OpenAI的Tim Brooks揭示,生成式AI模型在处理复杂或详细的图像描述时常常遇到挑战,容易忽略某些词汇或误解提示。为解决这一问题,他们通过训练一个专门的图像描述器来重新标注数据,从而构建了一个更加准确和详尽的数据集。这一创新成果直接促成了DALL-E 3的开发,显著提升了模型对提示的理解和遵循能力。
3.学习视觉而无需视觉数据是可能的。
麻省理工学院的Phillip Isola在其题为“无视觉数据学习视觉”的演讲中提出了一个引人入胜的观点:即便没有直接的视觉数据,我们也可以利用噪声、语言或代码等非视觉信息来训练视觉模型。他特别指出,像GPT-4这样的语言模型虽然能够准确分类人类绘制的图像,但在识别那些本应能准确表达的概念类别时却显得力不从心。
Ludwig Schmidt:华盛顿大学和AI2的计算机科学教授
Phillip Isola:麻省理工学院计算机视觉领域的杰出教授
Tali Dekel:Google高级研究科学家及魏茨曼科学研究所计算机科学教授
Gianluca Corrado:Wayve公司的研究科学家
3. 基础模型(Foundation Models)
 图3. Wayve公司的Alex Kendall展示了自动驾驶车辆所依赖的基础模型架构。
图3. Wayve公司的Alex Kendall展示了自动驾驶车辆所依赖的基础模型架构。
主要内容
基础模型是基于海量且多样化的数据集训练而成的大规模AI系统,它们构成了众多AI应用的核心基石。这些模型以其庞大的规模、广泛的训练数据覆盖以及强大的跨任务适应能力而著称。
关键洞察
1.基础模型可以作为真实世界的模拟环境运行。
Google研究员Sherry Yang在自主系统研讨会上,于其主题演讲中阐述了基础模型的一个潜在应用领域——作为真实世界的模拟器。她指出,要让基础模型成功扮演这一角色,必须达成两大条件:
互联网上的数据,包括文本和视频,需为“世界模型”构建起统一的表达形式与任务接入接口。
强化学习技术在决策制定层面需达到足够高的成熟度,以在该“世界模型”内进行有效的策略规划与执行。
然而,要实现这一目标,尚存两大挑战:
这些模型目前仍频繁出现“幻觉”现象。
亟需构建更为完善的评估体系与反馈机制。
2.基础模型在机器人领域的真正优势在于它们能够作为优秀的决策通用化模型。
在题为《通用型机器人导航模型》的演讲中,加州大学伯克利分校的人工智能研究员及计算机科学教授Sergey Levin指出,在计算机视觉等领域,现有的基础模型并非专为直接决策而预先训练的,它们与决策任务之间的联系相对松散。然而,他强调,如果能够开发出能预先训练来直接作出关键且实用决策的基础模型,这将对机器人学乃至更广泛的领域产生巨大价值,因为下游的机器学习应用最终都绕不开决策制定的核心环节。
3.在解决数据规模化问题、可操作性和可提示性、以及可扩展性评估这三个关键组成部分之前,我们不会实现面向机器人的基础模型。
数据扩展:虽然LLMs和视觉语言模型(VLMs)的数据集已经扩展到很大规模,但机器人领域缺乏类似规模的数据集。如果将机器人动作视为一种新的数据模式,并提高数据互操作性,或许能够解决这一问题。
可提示性:与LLMs不同,目前还没有可通过提示完成各种任务的通用机器人。这部分原因是机器人需要处理更大的上下文信息,并且缺乏机器人数据也阻碍了通用机器人的开发。
评估:能够执行各种任务的通用模型需要全面的评估。LLMs可以直接由人类评估,因为它们针对的是人类数据分布。然而,机器人需要在物理环境中运行,因此可能需要目前无法实现的真实世界评估方法。
Sergey Levin:加州大学伯克利分校计算机科学领域的知名教授
Alex Kendall:Wayve公司的联合创始人
Sanja Fidler:NVIDIA AI研究员,同时担任多伦多大学计算机科学教授
Ted Xiao:谷歌高级研究科学家
4. 视频理解(Video Understanding)
 图4. 一个多模态模型被应用于将长篇视频内容转化为音频描述
图4. 一个多模态模型被应用于将长篇视频内容转化为音频描述
主要内容
视频理解是AI领域的一个重要分支,它专注于开发能够深入理解和分析视频序列中内容、上下文及事件的系统。这一过程超越了简单的物体识别和场景分类,要求系统能够解析视频数据中错综复杂的时间和空间关系、动作以及叙事结构。
关键洞察
1.多模态上下文学习引领音频描述任务新纪元。
AMD的AI研究员Zicheng Liu介绍了如何利用多模态模型,特别是结合少样本上下文学习(MM-ICL)的GPT-4,将长视频的视觉信息转化为生动的音频描述。他断言,这种方法在生成长视频音频描述方面的表现超越了基于微调的传统方法和单纯依赖大语言模型(LLM/LMM)的策略【14】。
2.大语言模型(LLMs)成为长视频字幕生成的核心驱动力。
在给定短期视频片段字幕的基础上,LLMs能够成功生成连贯的描述和长视频内容的精炼摘要。
LLMs还能有效扩充训练数据集,通过自动生成内容来弥补人工标注数据的不足,从而进一步提升字幕生成的准确性和效率。
Chunyuan Li:微软研究院首席研究员
Dima Damen:布里斯托大学计算机视觉教授及谷歌研究科学家
Fei Xia:谷歌高级研究员
Long Chen:Wayve的AI研究员
Zicheng Liu:AMD生成式AI部门高级总监
Lorenzo Torresani:FAIR的AI研究员
References
[1] Josh Bongard talk, DAY 2 EI’23 Conference
[2] RoboTHOR: An Open Simulation-to-Real Embodied AI Platform
[3] A Survey of Imitation Learning: Algorithms, Recent Developments, and Challenges
[4] Language Models are Few-Shot Learners
[5] Attention is all you need
[6] Generative AI in Vision: A Survey on Models, Metrics and Applications
[7] Imagen
[8] DATACOMP: In search of the next generation of multimodal datasets
[9] Improving Image Generation with Better Captions
[10] Learning to See by Looking at Noise
[11] Sora at CVPR 2024
[12] UniSim: Learning Interactive Real-World Simulators
[13] PRISM-1 by Wayve
[14] MM-Narrator: Narrating Long-form Videos with Multimodal In-Context Learning
[15] Video ReCap: Recursive Captioning of Hour-Long Videos
Source: Jose Gabriel Islas Montero, Dmitry Kazhdan; CVPR 2024: Top Highlights You Must Know— Embodied AI, GenAI, Foundation Models, and Video Understanding
CVPR 2024:基础模型与视觉提示即将重塑计算机视觉领域
 视觉提示的创新应用:以预测为驱动的视觉系统新视角
视觉提示的创新应用:以预测为驱动的视觉系统新视角
深化图像理解:简约的视觉线索助力基础模型精准把握图像的精髓细节。
赋能多模态大语言模型:借助场景图,多模态大语言模型(MLLMs)无需额外训练数据,即可生动描绘图像内容。
优化基础模型:通过精心设计的视觉提示策略,提升视觉基础模型(如SAM)的性能表现。
增强泛化能力:训练AI快速识别全新对象的同时,巩固其既有的知识基础。
融合主动学习:视觉提示助力AI高效学习新视觉任务,减少示例需求且不忘旧知。
本文深入探讨了视觉提示技术,揭示其如何赋能大型视觉模型快速适应新任务。
什么是视觉提示
视觉提示:系统视角 CVPR 2024上引起轰动的视觉提示进展 未来展望
1. 什么是视觉提示(Visual Prompting)
1.1 视觉提示的起源追溯
视觉提示的起源可回溯至2001年问世的“图像类比”(Image Analogies)一文[2],在该研究中,科研人员开创性地设计了一种利用示例处理图像的策略,此策略要求同时呈现提示与查询以检索相应结果。
进入生成AI时代,视觉提示领域迎来了哪些新兴发展?
视觉提示意指赋予模型以能力,使其能够执行超越其原始训练目标范畴的任务。从技术维度解读,这表示视觉提示能够使预训练模型灵活适应并处理那些在其训练过程中未曾遭遇的数据分布。
视觉提示的概念已在语言模型中广泛应用[3],即通过将诸如GPT-4等大型预训练模型调整至新任务上,实现其功能的拓展与深化。
视觉提示[1]可被定义为一种过程,该过程旨在将大规模视觉模型的能力引导至执行那些先前未曾接触过的视觉任务之上。
1.2 深入理解视觉领域中的提示
为了深入理解视觉领域中的提示概念,我们首先需要明确视觉提示与微调(这一标准的适应技术)之间的本质区别。

图1直观展示了在计算机视觉基础模型框架下,视觉提示与微调之间的主要差异。视觉提示巧妙地利用视觉线索或示例来引导模型行为,这一过程无需对模型参数进行任何修改,从而赋予了高度的灵活性和较低的计算成本。相反,微调则要求我们在特定的数据集上重新训练模型,通过调整其参数来优化针对特定任务的表现,但这往往伴随着更高的计算资源消耗。
值得注意的是,这两种方法并非相互排斥的选择。实际上,它们共同构成了基础模型适应策略中一个多元化、可选择的方案集合,如图2所示。
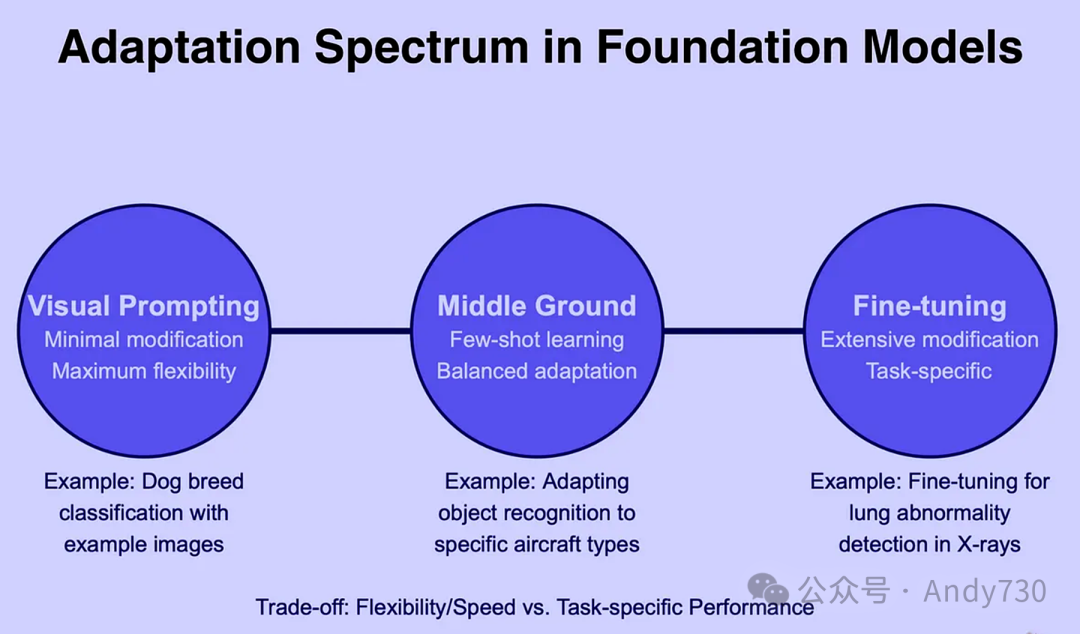
在图2中,我们进一步强调了视觉提示在追求灵活性和快速响应方面的独特优势。当面对需要迅速适应和灵活调整的场景,如视觉搜索与检索、快速原型设计以及实验性探索等应用时,视觉提示无疑成为了利用大规模视觉模型进行这些任务的最佳途径。
2. 视觉提示:系统视角
从系统整体架构的层面来审视视觉提示的强大功能,或许是洞察其核心价值的关键所在,特别是在复杂多阶段视觉系统的内部运作中。
一个可提示的模型能够无缝融入其他系统之中,作为庞大AI生态系统中的一个关键组件,在推理过程中精准执行分配给它的具体任务。
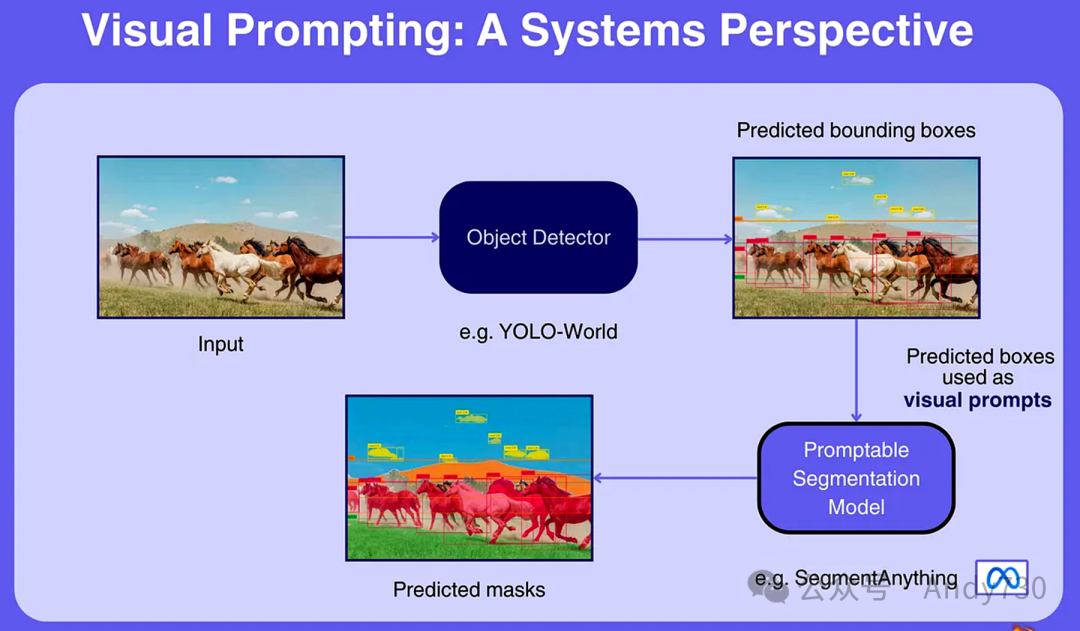
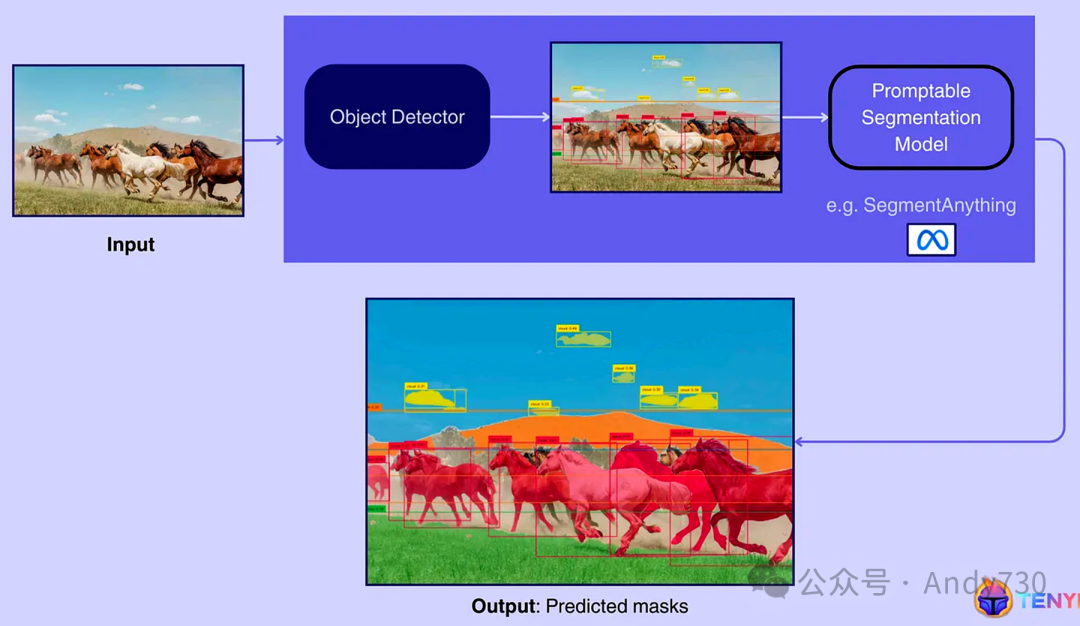
图3展示了如何在多阶段视觉系统中集成视觉提示的实例:以SegmentAnything这一基础模型为例,它能够利用前置对象检测模型(如YOLO-World)生成的视觉提示,来实现高精度的图像分割。
输入图像:系统处理的起点是一张输入图像,本例中展示的是一群在广袤田野上驰骋的马匹。 对象检测:该步骤通过对象检测器(如YOLO-World)对输入图像进行处理,识别并定位图像中的各个物体,随后生成围绕这些物体的边界框。输出结果清晰地展示了每匹马周围的边界框,以及天空中云朵的小框。 分割:接下来,这些检测到的边界框作为视觉提示被传递给可提示的分割模型(如SegmentAnything)。该模型基于这些提示,为每个检测到的对象生成精确的掩膜,从而实现对图像的细致分割。
3. CVPR 2024上引起轰动的视觉提示进展
3.1 大型多模态模型的直观视觉提示
 图4:CVPR 2024 ViP-LLaVA海报
图4:CVPR 2024 ViP-LLaVA海报
论文链接:https://openaccess.thecvf.com/content/CVPR2024/papers/Cai_ViP-LLaVA_Making_Large_Multimodal_Models_Understand_Arbitrary_Visual_Prompts_CVPR_2024_paper.pdf
演示链接:https://vip-llava.github.io/
主要创新:本研究引入了一种多模态模型,该模型能够解析任意(自由格式)的视觉提示,使用户能够简单地通过标记图像(如使用“红色边界框”或“指向箭头”等自然提示),无需复杂的区域编码,即可直观地与模型进行互动。
医疗影像:帮助医疗专家在X光片、MRI等医学图像中标出特定区域,促进更精准的诊断与分析。 电子商务产品搜索:让消费者能够标记产品图片的特定部分(如鞋跟),以便快速找到相似商品或获取详细产品信息。
3.2 零样本视觉提示增强AI图像理解
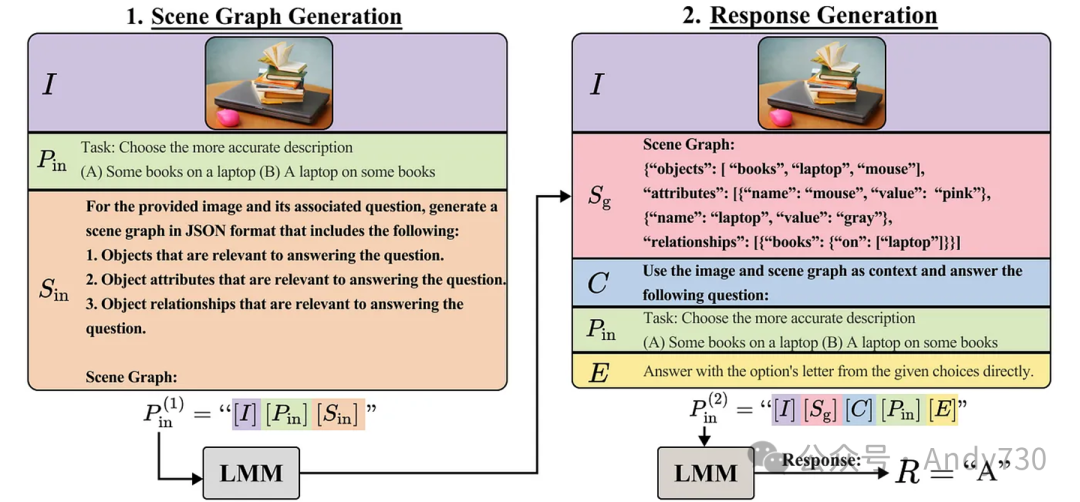 图5:CCoT完整提示示例说明:首先,结合图像和任务提示生成场景图。随后,利用图像、场景图及问题提示引导大型多模态模型(LMM)提取答案。
图5:CCoT完整提示示例说明:首先,结合图像和任务提示生成场景图。随后,利用图像、场景图及问题提示引导大型多模态模型(LMM)提取答案。
论文链接:https://arxiv.org/pdf/2311.17076
代码仓库:https://github.com/chancharikmitra/CCoT
主要创新:提出了组合思维链(CCoT)方法,包含两步零样本提示机制。首先,多模态大语言模型(MLLM)根据任务提示从图像中自动生成场景图。随后,利用此场景图提供详尽准确的响应,整个过程无需标注数据或微调模型。
视觉问答:通过深入理解视觉内容及其构成,为图像相关问题提供精确答案。 监控系统:识别图像中的对象并理解它们之间的关系,对提升监控应用效能至关重要。
3.3 基础模型中的成本效益分割技术
 图6:CVPR 2024 Semantic-aware SAM for Point-Prompted Instance Segmentation 海报
图6:CVPR 2024 Semantic-aware SAM for Point-Prompted Instance Segmentation 海报
论文链接:https://arxiv.org/abs/2312.15895
项目查看:https://github.com/zhaoyangwei123/SAPNet
主要创新:该研究开发了语义感知实例分割网络(SAPNet),将多实例学习(MIL)与如SAM等视觉基础模型融合,通过点提示强化类别特定的分割能力。SAPNet通过精选代表性掩膜提案,结合点距离引导和框挖掘策略,有效解决分割难题。
自动驾驶:提升自动驾驶系统中对象检测与分类的精度,增强决策能力和行车安全。 农业监测:精确分割航空或卫星图像中的特定作物或植物,优化农业管理,预测作物产量。
3.4 利用视觉提示优化基础模型中的图像分割性能
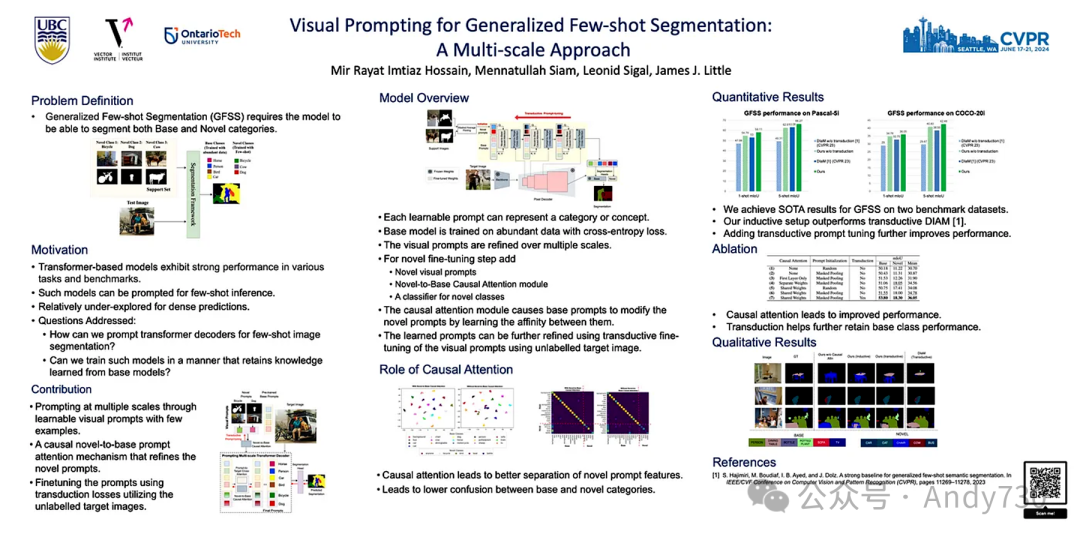 图7. CVPR 2024 视觉提示在广义少样本分割中的应用 海报
图7. CVPR 2024 视觉提示在广义少样本分割中的应用 海报
论文链接:https://arxiv.org/pdf/2404.11732
项目查看:https://github.com/rayat137/VisualPromptGFSS
主要创新:该研究将学习的视觉提示与变压器解码器技术相结合,应用于广义少样本分割(GFSS)任务中。其亮点在于引入了一种创新的单向因果注意力机制,该机制有效融合了从有限样本中学习的特定提示与从大量数据中学习的基础提示。
自动驾驶技术:能够在仅提供少量样本的情况下,迅速适应并准确识别和分割新出现的物体或道路条件,同时保持对常见道路元素的稳定识别能力。 卫星图像解析:在少量样本的支持下,有效识别和分割新的土地利用类型或环境变化,同时确保对已知地理特征的准确识别。
3.5 主动学习与视觉语言模型中的提示技术融合
 图8. CVPR 2024 视觉语言模型中的主动提示技术 海报
图8. CVPR 2024 视觉语言模型中的主动提示技术 海报
论文链接:https://arxiv.org/pdf/2311.11178
项目查看:https://github.com/kaist-dmlab/pcb
主要创新:本研究提出了一种创新的主动学习框架——PCB,该框架专为预训练的视觉语言模型(VLMs)设计。PCB框架有效解决了将VLMs应用于新任务时面临的适应性挑战,同时极大地减少了高成本的人工标注需求。
医学影像分析:通过快速适应VLMs,使其能够识别新的疾病模式或异常现象,显著降低对医学专家进行大量标注的依赖。 电子商务领域:利用PCB框架将VLMs快速适应到新的产品线,提升产品分类和搜索的准确性与效率,大幅减少人工输入的负担。
4. 未来展望
正如本文所深入探讨的,视觉提示技术为在输入空间中灵活调整基础模型提供了强大工具,这一特性至关重要,因为它构建了人类与模型之间的通用沟通桥梁。
随着可提示模型在视觉领域的不断发展,它们正逐步重塑传统计算机视觉流水线的面貌。这些模型可以被视为替代传统流程中某些关键阶段(如标注)的高效构建块。
我们坚信这一变革的浪潮比预期来得更快、更猛烈。在《计算机视觉流水线2.0》一文中,我们已深入剖析了这场变革的必然性与深远影响,揭示了其背后的深刻洞察。
[1] Exploring Visual Prompts for Adapting Large-Scale Models
[2] Image Analogies
[3] Language Models are Unsupervised Multitask Learners
[4] Visual Prompting
[5] Segment Anything
[6] YOLO-World: Real-Time Open-Vocabulary Object Detection
-----
我在CVPR 2024的笔记:扩散模型、多模态学习、3D技术以及基础模型方面的突破
什么是CVPR?
CVPR 2024是计算机视觉领域顶尖的盛会,聚焦于该领域的最新进展。此次会议汇聚了行业内的杰出专家,就图像处理、视频处理、机器学习及AI应用的前沿研究展开深入交流。作为该领域规模最大的会议,CVPR 2024吸引了超过万名研究人员的参与,并收录了超过2000篇研究论文。随着计算机视觉技术的迅猛发展,CVPR对于渴望保持行业前沿的AI专家而言,无疑是一场不可或缺的盛会。
最新动态与趋势
在CVPR 2024上,我见证了计算机视觉领域的几大激动人心的趋势,特别是扩散模型、多模态学习、3D技术以及基础模型方面的突破。以下是对这些趋势的简要概述,以及它们的重要性与潜在应用分析,并特别推荐了几篇引起我高度关注的优秀论文。
扩散模型与内容生成
扩散模型已成为图像、视频及3D内容生成领域的领先技术。它们通过逐步细化过程,将随机噪声转化为细致入微且逼真的输出结果,展现了极高的生成质量。正因如此,扩散模型正受到研究界的广泛追捧,成为CVPR关注的焦点。
Instruct-Imagen:利用多模态指令进行高效图像创作(Instruct-Imagen: Image Generation with Multi-modal Instruction)
重构扩散模型以优化单目深度估计性能(Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation)
多模态学习
多模态学习(Multimodal Learning)致力于训练能够处理并识别图像、视频、音频及文本等多种数据类型间关系的AI模型。通过整合多种模态信息,模型能够更全面地理解其所在环境。例如,在情感识别中,结合面部表情的视觉信息与声音语调的音频信息,可显著提升识别精度。尽管单模态模型在各自领域内已取得显著成就,但多模态模型通过跨模态融合,提供了更为丰富和深入的洞察,正逐渐成为研究热点。
EGTR:从Transformer中抽取图结构以优化场景图生成(EGTR: Extracting Graph from Transformer for Scene Graph Generation)
利用自然语言描述图像集间的微妙差异(Describing Differences in Image Sets with Natural Language)
MMMU:构建面向专家级通用AI的大规模多学科多模态理解与推理基准(MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI)
3D计算机视觉
近年来,3D计算机视觉领域取得了显著进展,涵盖3D重建、3D生成与3D理解三大核心方向。3D重建技术能够从2D图像或传感器数据中创建逼真的数字3D模型,对于虚拟现实等领域至关重要;3D生成技术则允许用户创建或修改3D内容,在游戏与动画制作中发挥着关键作用;而3D理解技术则进一步解读复杂的3D场景信息,助力自动驾驶与医学影像分析等领域的发展。深度学习与传感器技术的不断进步正推动3D计算机视觉迈向新的高度。
pixelSplat:基于图像对的3D高斯斑点技术,实现高效可扩展的通用3D重建(pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction)
基础模型
基础模型正通过提供适应多种下游任务的强大框架来重塑计算机视觉领域。这些模型在海量数据集上进行训练,能够捕捉丰富的特征与模式信息,并可针对图像分类、目标检测及语义分割等具体任务进行微调。基础模型具备强大的泛化能力,对特定数据类型(如图像或文本)有着广泛而深入的理解。其他研究人员可基于这些模型进行定制化开发以满足特定应用需求,并取得了卓越的表现。例如GPT-3作为典型的基础模型已衍生出Chat-GPT等杰出应用。
Florence-2: 引领多种视觉任务向统一表示迈进(Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks)
InternVL: 拓展视觉基础模型,促进视觉与语言任务的精准对齐(InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks)
生成型AI在视觉领域的应用
过去十年间,生成建模技术受到了广泛研究。特别是近年来,随着扩散模型的兴起,图像生成技术取得了显著突破,如今,研究人员正致力于攻克更具挑战性的3D和4D内容生成任务。下图直观展示了多样化的生成任务及用户如何灵活指定所需生成的内容。
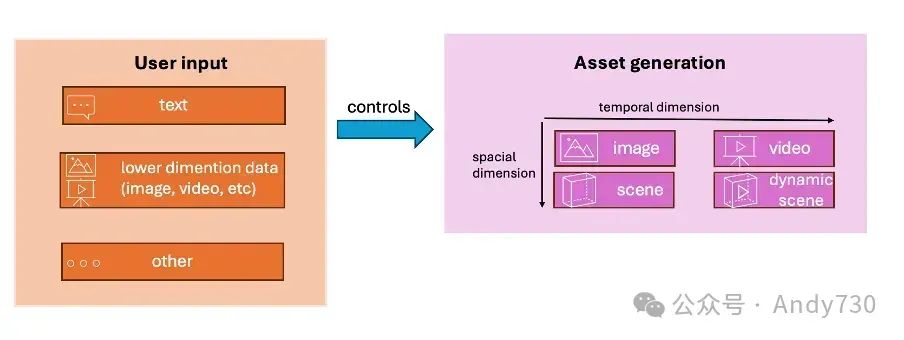 各类生成任务概览图
各类生成任务概览图
科学亮点
我的研究兴趣聚焦于3D计算机视觉领域,特别是生成模型与3D神经表示相融合的交叉地带。以下是我最为关注的几项研究成果:
PI3D: 基于伪图像扩散的高效文本到3D生成。该论文创新性地调整了现有的文本到图像模型StableDiffusion,使其能够直接生成3D资产。作者巧妙构建了一个包含文本标注的轻量级三平面数据集,这种3D表示方式可视为多通道图像,从而实现了与图像生成模型的兼容。
MVD-Fusion: 基于深度一致性的单视图多视图3D生成。此论文进一步拓展了StableDiffusion的能力,实现了从单视图到多视图的图像生成。通过融入图像的深度信息,并应用极点几何原理,该方法能够基于输入图像的关键特征生成高度一致的多视图图像。
4D-fy: 利用混合分数蒸馏采样的文本到4D生成。该论文提出了一种革命性的技术,通过文本描述即可生成动态场景。它结合了现有的文本到图像和文本到视频扩散模型作为监督,训练出4D神经表示。作者还成功将文本到3D的Score Distillation Sampling方法拓展至4D领域。
学习网络中的3D生物形态。此论文提出了一种新颖的方法,能够从单张图像中提取四足动物的3D模型。其训练数据全部来源于互联网上的单视图图像,这无疑增加了任务的难度,因为仅依赖2D数据(缺乏多视图数据和相机信息)。作者设计了一个包含两个模块的系统:一个用于生成通用的四足动物形状,另一个则负责估算特定实例的形状变形和着色。这两个模块最终通过对抗性训练实现了端到端的优化。
Source:Antoine Schnepf; My notes from CVPR 2024
--【本文完】---
近期受欢迎的文章:
更多交流,可添加本人微信
(请附姓名/单位/关注领域)

