




摘要
Azure Blob存储专为高效管理海量非结构化数据而设计。尽管Blob存储在HPC任务中展现出可扩展性和成本效益的优势,但数据访问延迟以及计算密集型或实时应用访问Blob数据时可能导致的性能下降,仍是亟待解决的挑战。本文深入探讨了WEKA的专有文件系统WekaFS及其并行处理算法如何显著提升Blob存储的性能表现。
关于WEKA
WEKA数据平台是为现代企业和研究机构量身打造的解决方案,旨在无缝且可持续地提供速度、简洁性和可扩展性,满足客户需求而不妥协。其先进的软件定义架构支持下一代工作负载,可在任何位置部署,兼具云端简洁性和本地性能优势。
WEKA 数据平台的核心是一个现代化的全分布式并行文件系统 WekaFS。它能够跨越数千个分布在多个主机上的 NVMe SSD,并无缝扩展到兼容的对象存储之上。
WEKA在Azure中的实践
众多组织借助Microsoft Azure平台,大规模运行其HPC应用。随着云计算基础设施的快速普及,用户对云上性能的要求已逼近本地部署水平。WEKA以其卓越的性能,为Azure上运行的最严苛应用提供了强有力的支持,保障高I/O吞吐量、低延迟响应、小文件处理效率以及混合工作负载的顺畅运行,同时实现自动存储均衡,无需繁琐的手动调优。
WEKA软件可部署于Microsoft Azure LSv3虚拟机(VM)集群上,这些VM配备有高性能的本地NVMe SSD,共同构建起一个高效能的存储底层。此外,WEKA还能充分利用Azure Blob存储的成本优势,实现命名空间的经济扩展。借助HashiCorp Terraform模板,用户可轻松实现WEKA的自动化部署,享受快速便捷的部署体验。在WEKA环境中存储的数据,支持通过NFS、SMB、POSIX及S3兼容等多种协议进行访问,满足多样化的数据交互需求。
关于WEKA在HPC Windows Grid集成中的SMB性能表现,Kent已撰写了详尽的文章进行深入剖析,敬请参考:云端扩展新高度:WEKA数据平台与Azure HPC的强强联合(https://techcommunity.microsoft.com/t5/azure-high-performance-computing/scaling-up-in-the-cloud-the-weka-data-platform-and-azure-hpc/ba-p/3997491)
WEKA架构
WEKA是一个完全分布式、并行文件系统,从底层开始设计,旨在提供专为NVMe SSD设计的最高性能文件服务。与传统的并行文件系统不同,后者通常需要深厚的文件系统知识才能部署和管理,而WEKA采用零调优的存储方法,使得从数十TB到数百PB级别的存储管理变得简单易行。
如图1所示,WEKA在Microsoft Azure中的独特架构通过POSIX、NFS、SMB和AKS提供并行文件访问。它提供丰富的企业级功能,包括但不限于:本地和远程快照、快照克隆、自动数据分层、动态集群重平衡、备份、加密以及配额管理(建议、软和硬)。
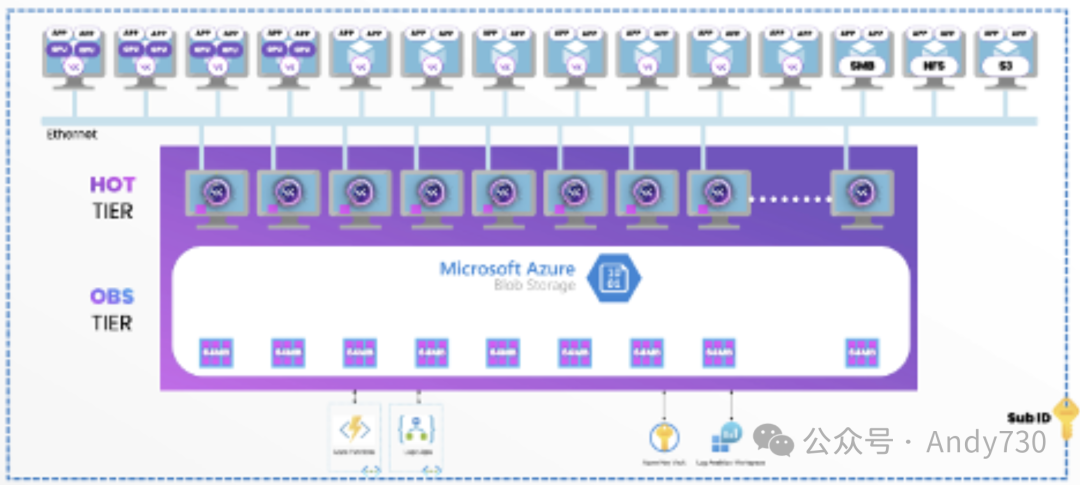 图1.WekaFS将NVMe闪存与云对象存储融合于统一的全球命名空间中
图1.WekaFS将NVMe闪存与云对象存储融合于统一的全球命名空间中
Azure中WEKA数据平台的核心组件包括:
WEKA软件高效部署于6个或更多Azure LSv3虚拟机之上,这些虚拟机经集群化处理,作为一个统一的高性能设备运行。 WekaFS命名空间无缝扩展至Azure热Blob存储,实现存储容量与经济性的双重优化。 借助Azure Logic Apps与Function Apps的强大功能,WekaFS能够灵活地进行扩展与缩减操作,满足动态变化的存储需求。 所有敏感的客户端信息均安全存放于Azure Key Vault中,确保数据安全性与合规性。 部署流程全面自动化,依托Terraform WEKA模板,简化部署流程,提升部署效率。
WEKA与数据分层
WEKA在Azure环境下的数据分层策略与Azure Blob存储实现了无缝对接。该策略充分利用了WekaFS分布式并行文件系统的优势,将高频访问的数据存储在LSv3虚拟机上的本地NVMe SSD(性能层),而低频访问的数据则迁移至成本更低的Azure Blob存储(容量层)。数据以4K块为单位进行写入,并与NVMe SSD块大小保持对齐,随后被打包成1MB的区段,并分散存储于集群内的多个存储节点(即Azure中的LSv3虚拟机)。进而,这些1MB区段被组合成64MB的对象,以优化存储效率。小文件会被合并至单一对象,而大文件则会被分割存储于多个对象中。
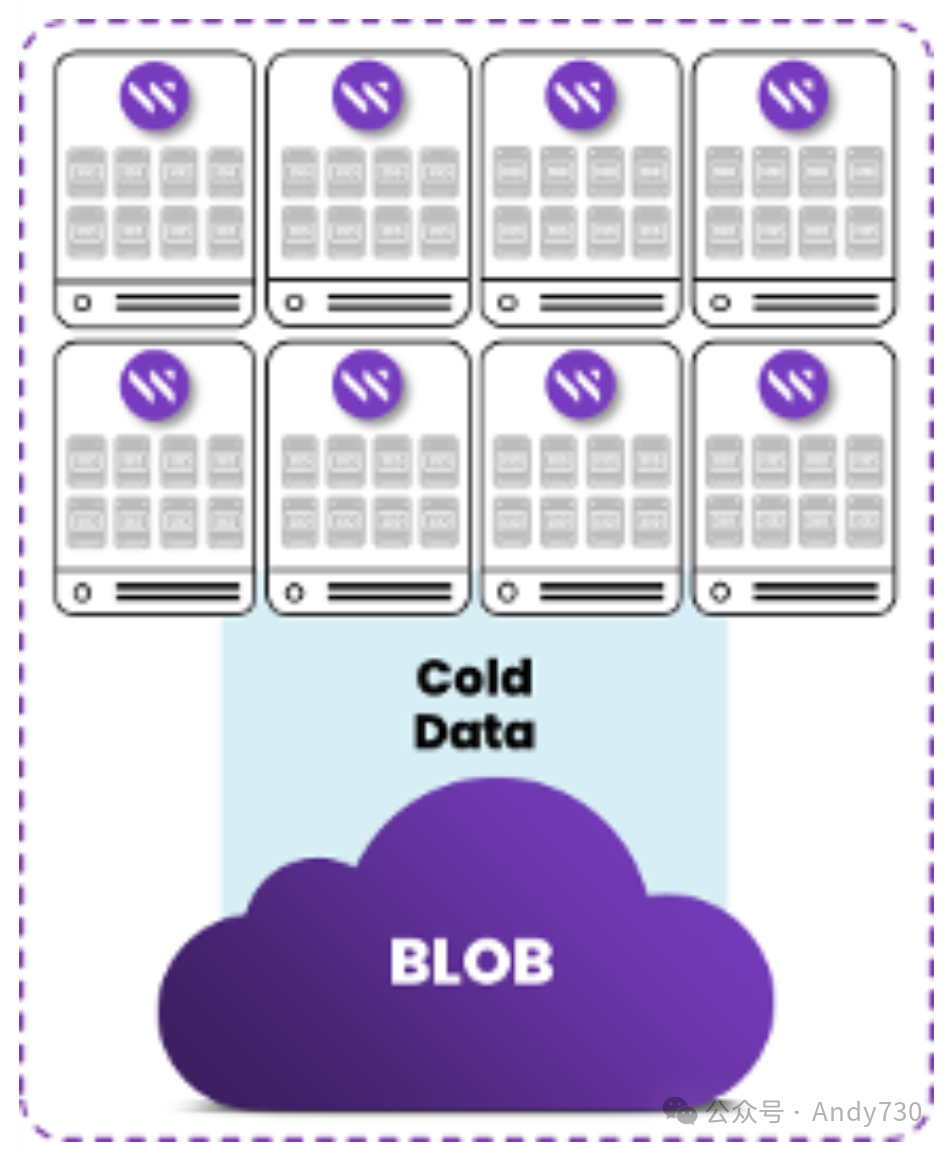
图2.WekaFS向热Blob存储分层
如何检索冷数据?有哪些可选方案?
分层存储的数据始终保持可访问性,就如同它仍是主文件系统的一部分。更为关键的是,尽管数据可能经历了分层存储,但元数据始终被保存在SSD上。这一特性使得用户能够在不牺牲性能的前提下,轻松遍历文件和目录。
缓存层:利用WEKA内置的缓存机制,当文件数据从Blob存储重新检索时,会被暂存于NVMe SSD的“读取缓存”中,以加速后续读取操作。 预取:通过WEKA提供的预取API,用户可主动触发数据从Blob存储至NVMe SSD的迁移过程,确保关键数据在需要时能够迅速访问。 直接冷读:客户端亦可直接从WEKA挂载点访问Blob存储中的数据,虽然此时数据不会经过WEKA FS缓存,但WEKA声称其能够并行化读取操作,提升数据访问速度。
性能测试方法
为了验证WEKA从Blob存储直接读取数据的性能,我们设计了以下测试方案:
测试环境包括6台Standard_D64_v5 Azure虚拟机作为客户端,以及20台L8s_v3虚拟机实例用于构建NVME WEKA层。
启用了热区冗余存储(ZRS)的Blob用于数据存储。
在测试中,NVME层配置了一个2TB的文件系统用于存储元数据,而HOT BLOB层则配置了20TB的存储空间。
通过特定挂载选项(参考obs_direct),我们使WEKA能够直接访问Blob存储中的数据。
pdsh mount -t wekafs -o net=eth1,obs_direct [weka backend IP]/archive mnt/archive
使用fio工具模拟写入负载,以1MB的块大小向对象存储写入随机数据,以评估系统的写入性能。
pdsh ‘fio --name=$HOSTNAME-fio --directory=/mnt/archive --numjobs=200 --size=500M --direct=1 --verify=0 --iodepth=1 --rw=write --bs=1M’
测试结果显示,在写入工作负载完成后,仅有2.46GB的元数据驻留在SSD层,而大部分数据(631.6GB)则成功迁移至Blob存储中,验证了WEKA数据分层策略的有效性。
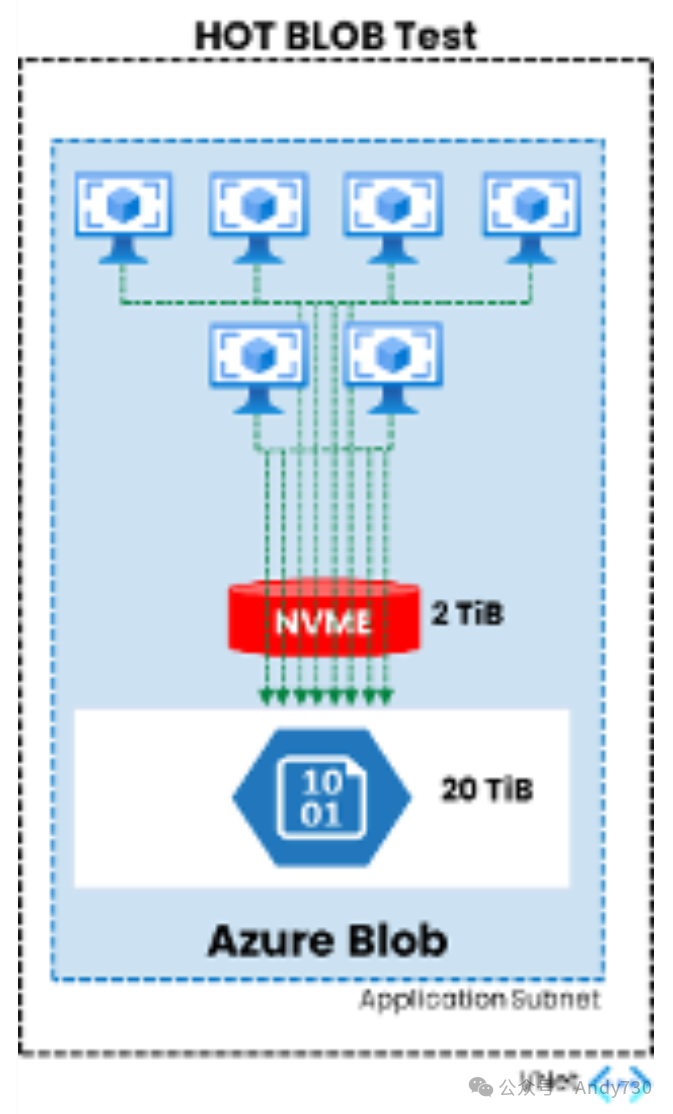
图3.WekaFS测试设计
使用Weka fs命令再次确认文件系统状态,发现SSD的使用量维持在2.46 GB,这正是我们元数据所占用的空间。
现在,所有数据都已转移至BLOB存储,接下来我们将测试其访问速度。
我们将采用FIO基准测试来评估性能。测试将在所有六个客户端上并发执行,每个客户端以1MB的块大小进行读取操作。
pdsh ‘fio --name=$HOSTNAME-fio --directory=/mnt/archive --numjobs=200 --size=500M --direct=1 --verify=0 --iodepth=1 --rw=read --bs=1M --time_based --runtime=90’’
该命令设置为运行90秒,旨在捕获WEKA数据平台在热BLOB层上的持续带宽性能。
从以下截图可以看出,我们从Azure Blob中读取数据的速度高达20 GB/s。
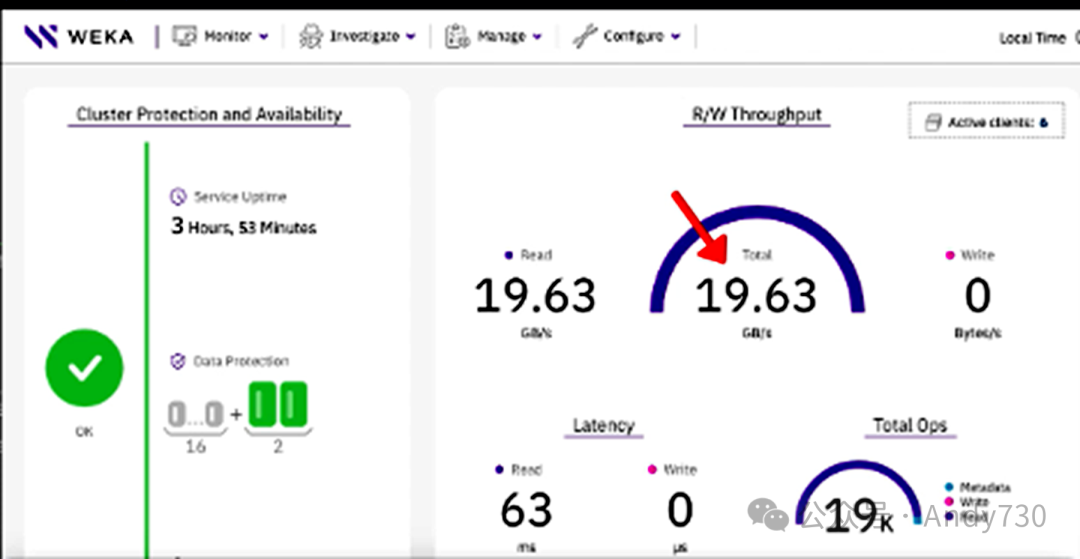 直接从BLOB以19.63 GB/s的速度读取100%数据
直接从BLOB以19.63 GB/s的速度读取100%数据
WEKA如何实现的?
简而言之,WEKA通过在集群的所有节点上均匀分配负载来实现。每个WEKA计算进程都会创建64个线程来执行从Blob容器的GET操作。每个WEKA后端负责管理命名空间的一个等量部分,并执行相应的Azure Blob API操作。
因此,多个节点协同工作,每个节点处理64个线程,这就是“WEKA加速热BLOB层”的奥秘所在。
在测试运行期间,通过命令行上的统计数据(图8)可以看出,分层数据的服务在集群中的所有WEKA节点上实现了完美的负载均衡。这种均衡性有助于WEKA从Azure Blob中发挥出最佳性能。
图8.每个后端节点使用64个线程从BLOB执行GET操作,保持均衡
这种功能能解决哪些实际问题?
大规模数据导入:当需要一次性将大量数据导入WEKA Azure平台时,如果最终用户不确定哪些文件会成为“热点”,可以选择将所有数据直接存储在BLOB存储上,以避免将当前活跃数据从闪存层中移除。 低频顺序读取:对于需要不频繁顺序读取大量数据的工作负载(如每月或每季度仅使用一次数据的HPC作业),如果每个计算节点读取不同的数据子集,那么将数据重新加载到闪存层或替换重复使用的数据将变得没有意义。 读密集型工作负载:对于WEKA加速的BLOB冷读性能已能满足需求的读密集型工作负载,客户端可以在obs direct模式下挂载文件系统。
结论
通过融合并行处理、可扩展性、闪存优化、数据分层和缓存技术,WEKA在Azure中为数据密集型工作负载提供了卓越的性能表现。这使得组织能够为其最严苛的应用程序和使用案例实现高吞吐量、低延迟和最佳资源利用率。
还可以将直接从热BLOB存储进行低延迟、高吞吐量读取作为WEKA的又一重要应用场景。正如Kent所言:
“随着数字化趋势的不断深化,选择WEKA数据平台不仅是明智之举;它更是一种战略优势,能够让用户充分挖掘HPC网格的全部潜能。”
Source:Jerry Morey; Breaking the Speed Limit with WEKA: The World's Fastest File System on top of Azure Hot Blob; Jun 19 2024
--【本文完】---
近期受欢迎的文章:
更多交流,可添加本人微信
(请附姓名/单位/关注领域)

