




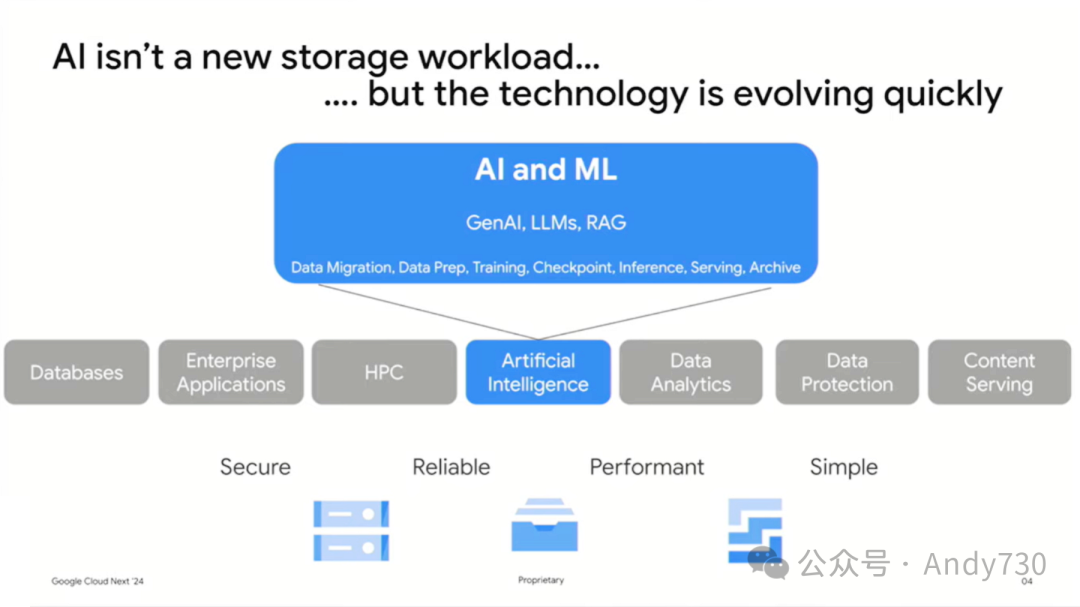
我们一直在探索如何改进客户运行AI/ML工作负载的体验。虽然无论是文件存储还是块存储等都存在共性问题和通用方案,但AI/ML应用程序与数据库和GKE中的传统工作负载相比有着独特需求。

在过去的一年半里,我们一直在增强我们的存储解决方案,以支持AI/ML工作负载,助力客户实现目标。以下是一些关键优势:
随处访问:支持客户在任何大陆的任何区域获取和存储数据,并将数据尽可能降低延迟地访问GPU/TPU资源。
性能扩展:支持客户根据需求将性能从每秒数GB的吞吐量扩展到每秒数TB的吞吐量,并支持多种数据访问方式,满足不同用户的需求。
任意规模:支持客户从GB级别扩展到PB甚至EB级别,使他们能够自主选择训练模式和资源。
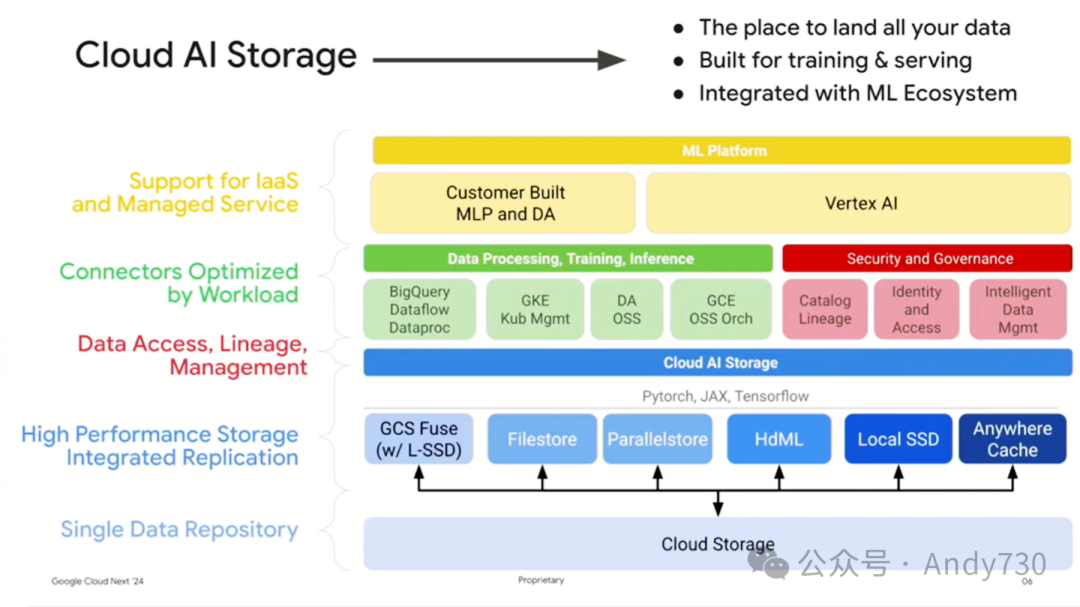
这些就构成了AI Hypercomputer基础设施的核心。
我们提供多元化存储解决方案,包括块存储、文件存储、对象存储等,并提供不同性能等级和数据访问方式,满足不同用户的多样化需求。
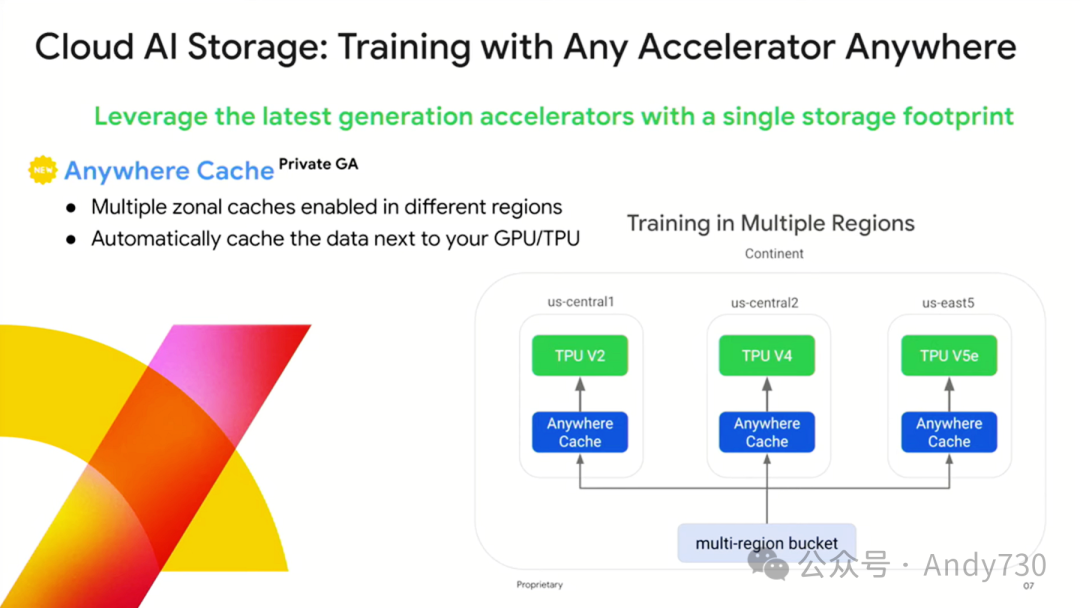
接下来,着重介绍一下Anywhere Cache。
Anywhere Cache与Cloud Storage紧密协作,共同为用户提供了一种前所未有的存储体验。这一功能的核心亮点在于支持多区域存储桶的灵活应用。客户无需再为数据具体存放在哪里而烦恼,因为他们获得的是一个大陆级别的存储桶,可以无缝地访问存储于其中的所有数据。这些数据被智能地分布在不同的区域,由Google在后台自动优化存储位置,而客户只需简单地通过一个统一的存储桶接口即可轻松访问。
但我们的目标远不止于此。我们追求的愿景是:让数据无处不在,确保数据能够紧密贴近GPU和TPU等高性能计算资源。正是基于这样的愿景,Anywhere Cache应运而生。它赋予客户能力,在本地计算资源上,特别是在接近GPU和TPU的位置设置缓存,从而实现在特定区域内的数据高速缓存。这一举措极大地加速了跨多个区域的训练过程,使工作流更加流畅,效率显著提升。
如此一来,GPU和TPU等宝贵资源能够持续高效地运行,不再受限于数据加载的时间瓶颈,真正实现了计算与数据的无缝对接。
观众:你的意思是它支持多区域的训练会话吗?
由于人们可能需要动用数千乃至数万个GPU和TPU,因此多区域、跨区域的训练会话显得尤为重要。你会将这些计算资源部署在最适合的地方。
观众:那么,是不是会优先考虑成本最低的区域呢?
理想情况下,确实会优先考虑成本最低的区域。
这里的核心思路是:让用户拥有一个覆盖大陆多个区域的存储桶,无论需要数据时身处何地,都可以快速启动计算资源,如GCE或GKE,确保数据能够存放在靠近GPU的位置。
观众:多区域训练面临的一个挑战就是需要管理不同GPU之间的接口同步问题。因此,在数据处理或训练过程中,必须确保多个区域、多个GPU之间的数据同步。
这正是客户使用如Slurm等工具的原因,它们能够高效地为GCE资源调度数千乃至数万个资源,并通过启用缓存来优化操作。当然,这取决于具体的规模,因为并非所有用户都需要处理如此庞大的数据量。
观众:这个缓存功能是专门为Cloud Storage数据设计的,而不涉及其他服务吗?
是的,这个缓存功能仅针对Cloud Storage数据进行优化。

去年,我们推出了ParallelStore,这是我们的首款并行文件系统产品,它构建在Intel DAOS之上。鉴于训练过程中多样化的存储需求,我们时常需要系统能提供超低延迟、超高吞吐量以及高效处理小文件的能力。ParallelStore与我们传统的基于Filestore的NFS系统有所不同,但两者可以相辅相成,共同使用。ParallelStore还实现了与Cloud Storage的集成。设想一下,当你希望从云端任何位置获取数据,比如在Cloud Storage中选取一部分数据开始训练时,我们的目标是将缓存功能从ParallelStore拓展至Cloud Storage,从而让你能轻松、快速地提取所需数据。
我们还推出了HyperDisk ML这一全新的块存储产品。它允许数据卷在数千台主机上实现只读访问,极大地加速了数据加载过程。其核心理念在于,训练过程中的每个Epoch都需要耗费一定时间,而我们的目标是尽可能缩短这些周期,无论是大规模还是小规模的训练任务,都能更快地完成。
值得一提的是,通过ParallelStore,我们实际上已经将基于Cloud Storage的基准性能提升了近4倍。
观众:Anywhere Cache是否适用于ParallelStore、Filestore以及HyperDisk吗?
它目前仅适用于Cloud Storage。这是指仅限于对象云存储。

ParallelStore是一种先进的并行文件系统,用户可以在任何区域启动它。当从存储中提取数据时,由于ParallelStore的即时可用性,数据会迅速被访问到,因为它是作为一个文件系统来运作的。GPU和TPU可以直接挂载到这个文件系统上,从而实现高效的数据访问。
观众:那么,是否可以将ParallelStore视为Cloud Storage的一个前端呢?
用户通常会从Cloud Storage中提取他们想要用于训练的数据,这涉及到数据的迁移过程。对于Filestore来说,情况也是类似的;用户会进行类似的数据迁移操作。

分享一个案例。丰田旗下的Woven团队在Google Cloud及其他大型云服务平台上进行训练时,采用了包括Lustre在内的多种系统。他们发现,在将数据从Cloud Storage转移到并行文件系统的过程中,由于需要创建数据副本,导致存储成本显著增加。尽管这一做法在某些工作负载下或许可以接受,但无疑加重了他们的成本负担。
为此,他们选用了Cloud Storage FUSE,这项技术支持将存储桶直接挂载为文件系统使用。尽管Cloud Storage FUSE并非严格意义上的POSIX兼容文件系统,但它确实为那些需要文件系统访问权限的训练应用程序提供了利用存储桶的便利。
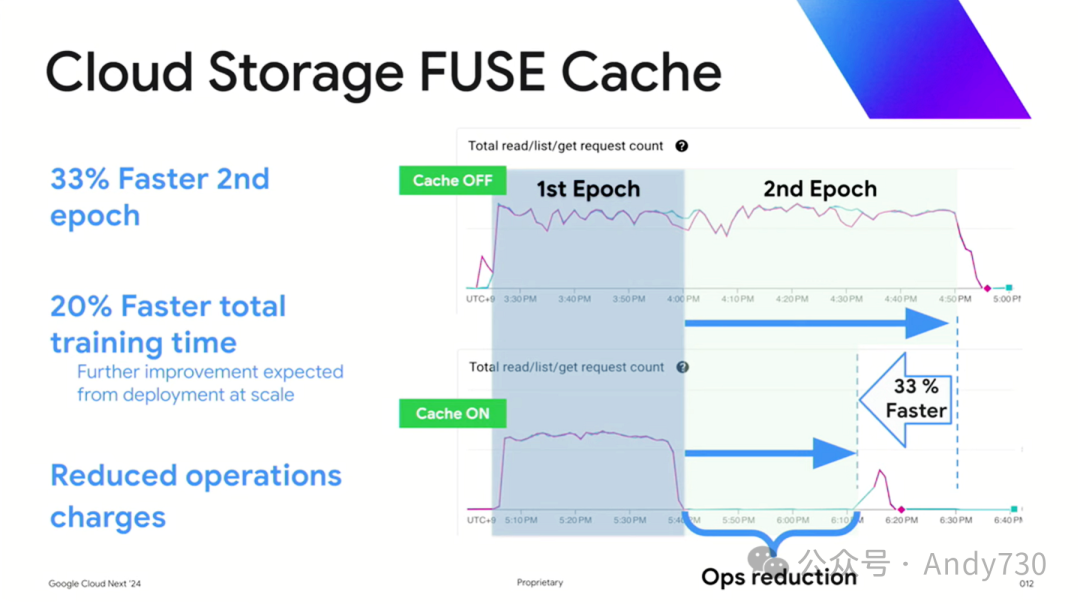
通过摒弃为Lustre并行文件系统创建额外数据副本的做法,Woven团队成功降低了训练成本,这是他们内部基准测试得出的结论。其中,传统的Cloud Storage FUSE(已存在多年)在首个Epoch到第二个Epoch之间,由于需要反复从存储桶中检索数据,时间消耗保持相对稳定。而就在几个月前,我们推出了带缓存功能的Cloud Storage FUSE,该功能现已全面开放。其运作机制与Anywhere Cache相似,允许客户在每个节点的GPU和TPU上设定缓存大小。这样,在启动第二个Epoch时,所需数据大多已预存于缓存中,从而显著提升了数据访问速度。这项可调的缓存技术使得第二个Epoch的运行速度提升了33%,而后续周期则更快。这不仅缩短了训练时间,还使得更频繁的训练成为可能。
观众:Epoch之所以运行得更快,是因为缓存中已经预存了所有数据,无需再从存储中实时获取,从而减少了数据读取的时间。
这一改进使得整体的训练时间缩短了20%,特别是在第二个Epochs中,时间减少了33%。

我们拥有众多客户,在企业环境及GKE工作负载中运行着各式各样的应用。起初,多数客户在GKE上运行无状态工作负载,这类负载即便集群遇挫,也能通过简单重建恢复,数据备份需求不大。但如今,我们已推出GKE备份功能,旨在保护Pod、集群配置乃至数据本身。值得注意的是,GKE中有状态工作负载的数量显著增长,为此,我们不断推出存储解决方案,以支撑这些有状态应用。
比如,借助Filestore,用户可轻松访问数以万计的Pod。任何集群故障转移都实现了透明化,因为所有节点均挂载了具备一致访问权限的NFS卷。

现在,客户可根据价格、性能、容量及可用性等因素,在Zonal、Regional和Basic三种实例类型中做出灵活选择。每种类型各具特色,比如Zonal实例提供每秒26GB的吞吐量,并能与多达8万个GKE集群或Pod无缝连接。这些持久卷均具备持久性,考虑到减少人为错误,我们推荐使用Terraform进行管理,客户现在也可选择这一方式。
对于Filestore Regional实例,我们尤为注重数据的可用性,会在指定区域内的所有三个子区域实现数据的同步复制。因此,如果追求高可用性并需要区域级的故障容忍能力,Filestore Regional将是理想之选。所有Filestore实例均集成了CSI驱动程序,便于持久卷的配置。此外,还可以针对单个共享进行数据备份,确保重要数据的万无一失。
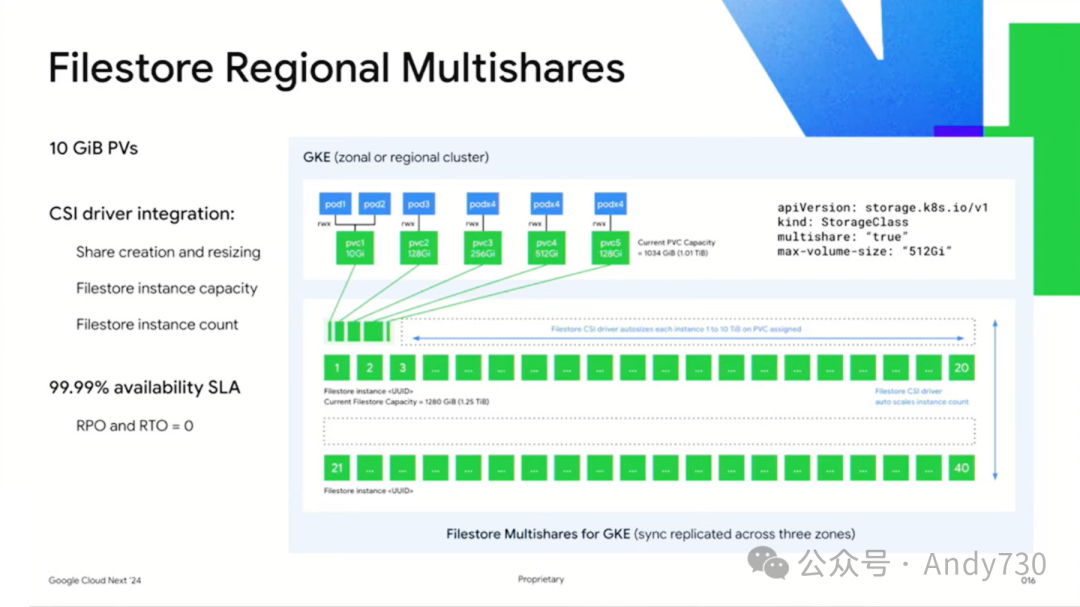
从容量扩展性来看,Filestore支持从1TB至100TB的灵活扩容。但考虑到GKE集群的实际需求,并非总是需要配置完整的1TB存储,因此我们推出了Filestore Multishares选项,允许客户按需配置小至10GB的持久卷,或在任意中间容量进行选择。随着需求增长,它会自动扩容,持续满足客户对存储空间的增加需求。这样,在配置Pod时,客户不仅能明确Pod的特性,还能精准设定用于存储的持久卷规格。
综上所述,Filestore的Basic、Regional和Zonal,均为客户提供了在价格、性能、容量及可用性方面的极致灵活性。而Filestore Multishares的推出,更是让客户能够以至少10GB的小容量起步,同时确保成千上万的Pod能够平等、高效地访问数据。
观众:Multishares支持Regional服务吗?
Filestore Multishares是基于Regional的,所以它是一种区域性服务。

我们在块存储领域持续复制并优化多年来在本地环境中积累的诸多功能,确保数据访问的流畅无阻。

我们赋予客户的一项重要能力,便是自由选择机器类型,无论是N2、C2,还是任何其他配置。回顾过去,使用持续性盘时,每个卷往往与特定类型的机器绑定,若需更大容量或更高性能,用户不得不更换机器类型,这并未实现计算与存储间的全面优化。
现在,借助Hyperdisk及我们提供的三种选项——平衡型、吞吐量优化型和极限性能型(现已全面上线),用户可根据初始工作负载需求及未来变化灵活调整。这意味着,可以按需选择配置的容量、吞吐量和IOPS,三者兼顾,既保留了选择机器类型的灵活性,又可根据SQL Server、Oracle等应用许可需求进行适当调整,同时还能针对存储进行精准调优。
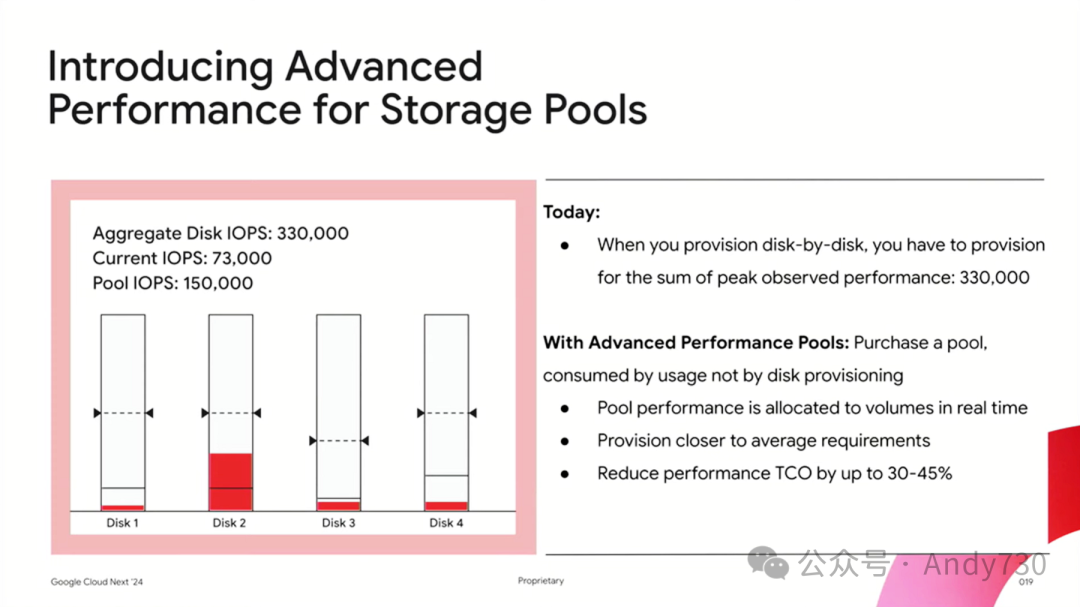
接下来,让我们谈谈存储池这一创新概念。我们将这一策略引入云端,让用户能以IOPS或容量为基准,实现存储资源的灵活调配。因此,存储池可视为云端版的本地灵活定价机制。用户可以有固定的IOPS配额(如10万IOPS),可跨多个卷灵活配置,这些卷共享这一IOPS资源。
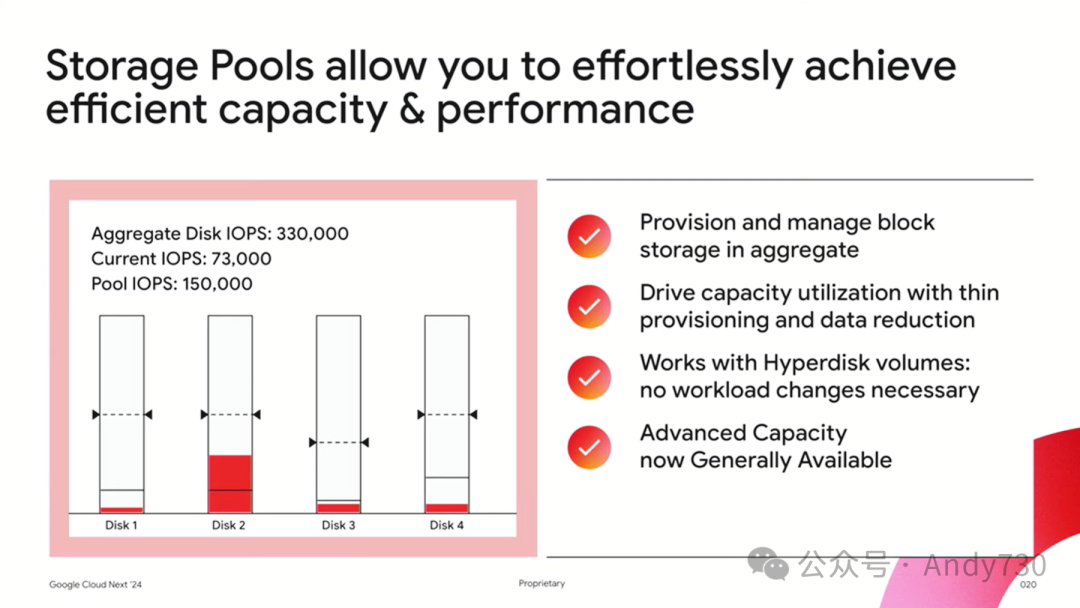
同样地,在容量和性能配置上,也无需再为峰值需求单独配置资源,而是可以基于跨多个VM的总体池概念进行规划。这一特性,目前仅在Google Cloud平台上提供。
观众:如果我没理解错的话,现在是否可以这样操作——我没想到能合并IOPS。比如,若我计划超额使用某个服务,无论是裸金属工作节点还是裸金属虚拟机管理程序,基础资源可能已超出,但我希望维持每秒15万 IOPS的稳定性能,那么,我是否能实现这一目标,而无需为每个节点都支付15万 IOPS的费用呢?
是的,你的理解很准确。如果你的平均IOPS是5万,但峰值可能达到15万,你可以在四个主机上配置总共20万的IOPS,然后我们会根据你的平均使用量来配置,同时监控峰值。如果在六个月内频繁达到峰值,我们可以相应调高配置。
观众:那么,存储池这一功能仅适用于Hyperdisk,还是也支持Filestore呢?
存储池功能目前仅适用于Hyperdisk。因为Filestore的设计支持根据需要灵活地扩展或缩减容量。对于Filestore for NFS和Google Cloud NetApp卷,可以进行编程管理,包括配置、扩展和缩减操作。特别是在NetApp卷内,还可以动态且完全无中断地从高级层升级到极端层,实现性能从每秒4.5GB到每秒12GB的飞跃。
观众:在什么情况下,会推荐选择NetApp服务,而不是Google自己的服务呢?
Google Cloud NetApp卷是一个由Google管理的服务,它消除了在本地文件系统中可能遇到的缓存命中率等问题的担忧。SMB工作负载是首先被考虑的场景,因为这是我们之前一直没有提供的托管SMB服务,我们在八月已经推出了这项服务。对于NFS 4.1的支持,虽然Filestore NFS 4.1目前还处于预览模式,但NetApp已经提供了全面的支持。此外,如果你希望跨多个区域复制数据以实现区域可用性,这也是Google Cloud NetApp卷的一个优势,而Filestore目前还不具备这一功能。当然,如果你之前使用的是NetApp并且希望继续沿用这一方案,或者你的GKE工作负载更倾向于使用集成了CSI驱动的Filestore,那么这些也是选择时的考虑因素。但请注意,使用Google Cloud NetApp卷时,你可能无法访问所有ONTAP API的功能,但可以利用Terraform进行配置,并享受备份、快照等数据保护功能,这些功能是通过SnapMirror实现的。
观众:关于从本地到Google Cloud的ONTAP复制,以及迁移或灾难恢复的需求,目前我们可以支持一次性的SnapMirror迁移。而对于更频繁的混合持续模式,我们计划在明年提供更多支持。
观众:至于持续性盘、Hyperdisk等的备份,这是否自动进行,还是需要额外的解决方案呢?

这张幻灯片是关于NetApp和Filestore的,它展示了不同的保护能力,并对比了不同RPO(恢复点目标)和RTO(恢复时间目标)的成本与后果,帮助你做出选择并权衡利弊。

接下来,关于Hyperdisk的问题,对于Compute Engine,我们提供了多种选项来备份这些块存储卷。你可以对这些存储卷进行快照操作,稍后我会详细介绍快照功能。此外,我们还提供了高可用性解决方案,如果你担心某个区域内的区域性服务中断,可以选择使用区域硬盘,或者利用异步复制功能来增强数据的可用性。

现在,我想特别介绍一下我们的一个新功能:即时快照(Instant Snapshots)。传统上,快照被视为一种备份方式,但即时快照则更接近于大家所熟悉的快照概念,它具备空间优化、瞬时回滚等实用功能。现在,我们已经为Hyperdisk引入了即时快照功能,这意味着Hyperdisk用户也能享受到这些便捷和高效的保护能力。
与前面讨论的文件系统保护类似,Hyperdisk同样支持快照、克隆、复制、备份等多种功能。此外,我们还在不断优化这些功能的编排流程,以提供更加流畅和高效的用户体验。至于Google Cloud备份与SAP应用程序及数据库的灾难恢复,那属于更高级别的备份能力范畴,我们也在不断努力提升这些方面的服务能力。
但如果你当前关注的是存储保护能力,那么我上面提到的这些功能点就是你需要重点关注的。
--【本文完】---
近期受欢迎的文章:
更多交流,可添加本人微信
(请附姓名/单位/关注领域)

