




题目:Proprietary Interconnects and CXL
演讲者:Larrie Carr, VP of Engineering, Rambus Inc.
会议:SNIA Compute, Memory, and Storage Summit
日期:2024年5月22日
感谢大家参加我的演讲《专有互连技术与CXL》。我是Larrie Carr,目前担任Rambus的工程副总裁,同时也是CXL联盟的主席。
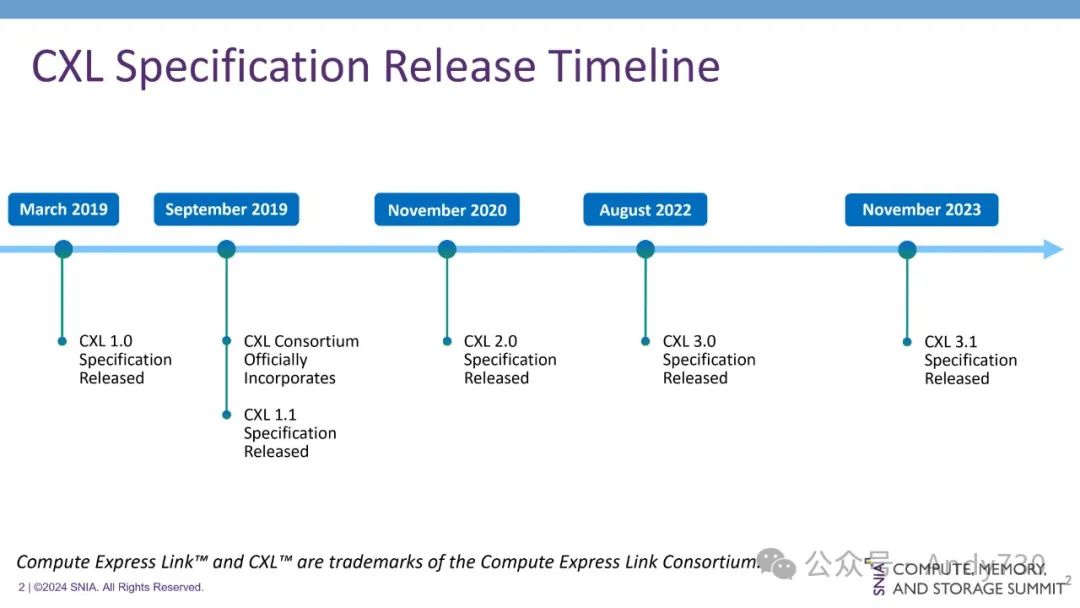
接下来,我们来回顾CXL的发展历程,并展望未来架构的变革,将有助于大家理解我们对CXL的预期。
CXL技术已经历经了约五年的发展历程。从最初针对加速器连接和内存扩展的小规模直接连接解决方案,CXL逐渐演变为一个功能完善的互连架构,支持加速器和内存之间的切换和可组合性,其复杂性也随之显著提升。对于不熟悉负载/存储架构的人士而言,CXL或许是解决相关问题的首个方案。然而事实并非如此,CXL所致力解决的诸多问题早已存在于CXL出现之前,并曾有其他互连协议试图在更大规模的系统中加以解决。

让我们回溯约十年前的历史,看看CXL是如何发展到今天的。
首先,PCI Express是一个非常优秀的接口,它在上世纪20年代初经历了重要的序列化演变,当时其他并行接口也经历了类似的转变。在有了串行接口之后,业界开始寻求新的方式来实现切换、网络和互连的复杂性。而PCI Express本身只是协议的序列化,该协议可以追溯到1991年。PCIe最初设计用于外设,本质上是一个负载/存储接口,但并不适用于内存连接。它旨在连接外设,这并不意味着它速度慢,例如如今的Gen 5 SSD的速度就非常快。然而,从内存连接的角度来看,PCIe与处理器的连接方式并非针对负载/存储设计,因此在仅讨论负载/存储时,其性能表现并不佳。
当然,业界希望改进这一点。
第一家这样做的公司是IBM,他们创建了CAPI(Coherent Accelerator Processor Interface),试图引入新的加速器与PowerPC进行通信,以加速某些HPC工作负载。他们扩展了PCIe Gen 3和 Gen 4,但这是一个专有接口。2016年,他们通过创建OpenCAPI联盟将其开放,支持所有这些功能。通过OpenCAPI构建了一些非常有意思的东西,我们可以看到它是如何随着时间演变的。
CCIX也大约在同一时间出现,试图引入缓存一致性以及内存扩展。他们利用了Gen 4,但也希望以更快的非标准速率运行。这是由一些公司共同创建了这个协议。它已经被军事领域采用,我知道它在一些导弹中使用。
因此,连接、加速和内存扩展到处理器的问题至少已经有十年的历史了。业界在专有标准和开放标准上投入了大量时间和精力,试图解决这一问题。
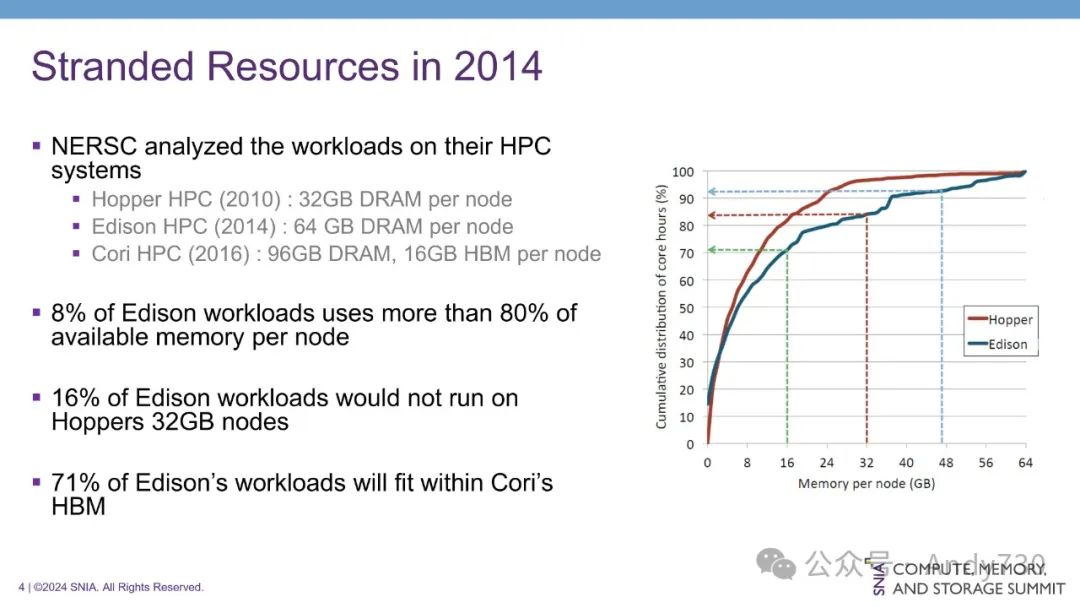
从标准的角度来看,资源浪费问题,尤其是在内存方面,首次公开讨论是在2014年。当时,英特尔正在研究其HPC系统的工作负载。他们注意到,尽管某些工作负载可以扩展并充分利用内存资源,但大多数工作负载却并未能有效利用。
例如,在Edison系统上,每个节点配备了64GB的DRAM内存,但研究发现,高达71%的工作负载实际上只需要16GB的HBM内存即可满足需求。这导致了大量的DRAM内存资源浪费。对于拥有数万个节点的大型HPC系统而言,这种资源浪费问题尤为严重。
与超大规模数据中心不同,HPC系统中的每个节点通常运行相同的程序,无法通过将不同工作负载打包在一起的方式来提高资源利用率。因此,十年前,我们面临着严峻的挑战:内存资源在某些地方过剩,而在其他地方却严重不足。
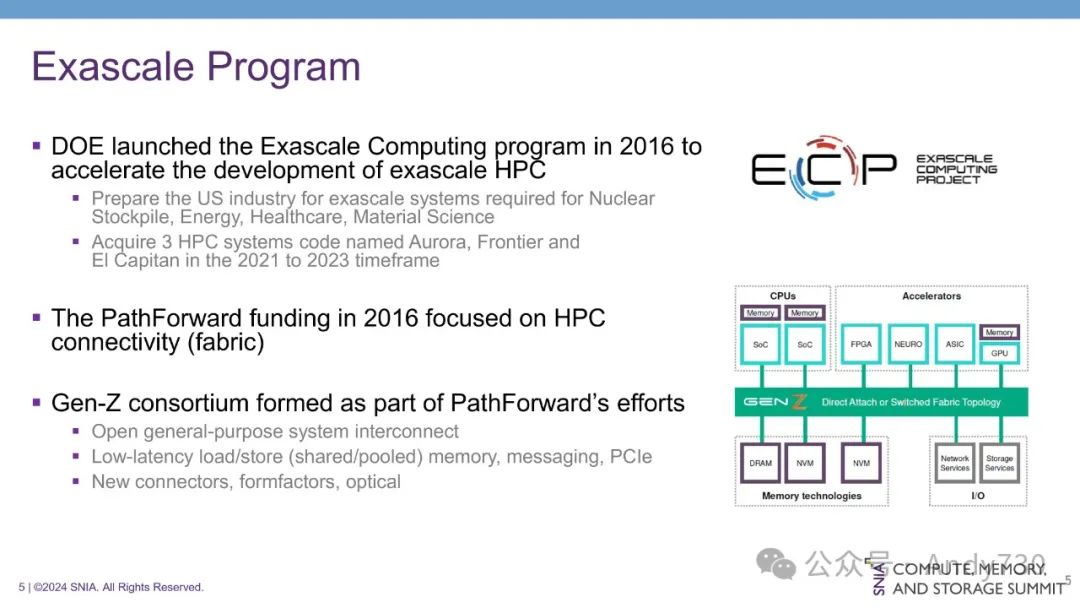
2016年,美国能源部启动了“百亿亿次计算计划”(Exascale Compute Program),旨在加速HPC的性能,特别是在维护美国核武库方面。该计划具有重要战略意义,因为百亿亿次计算能力(即每秒进行百亿亿次浮点运算)被认为是保持世界科技领先地位的关键。
能源部负责管理核武库并确保其整个生命周期的安全,而国防部则负责核武库的部署。该计划的目标是采购三套拥有百亿亿次浮点运算能力的高性能计算系统,性能将比当时的10到100 petaflops范围提升10到50倍。
为了实现这一目标,能源部资助了诸如PathForward等关键项目,以改进HPC的互连技术。当时市场上最成功的互连架构是Cray公司开发的Slingshot,但能源部希望能够创建一种开放的架构和标准,以支持行业所需的新特性、功能和性能。
PathForward项目的一部分成果是Gen-Z标准的创建,旨在为高性能计算、企业和云环境建立一个开放的互连标准,用于内存传输和加速器连接。从功能集来看,Gen-Z与CXL 3.1非常相似。该项目还定义了一些连接器,这些连接器至今仍被业界广泛使用,并率先探索了光学技术,在许多方面都超前于时代。
尽管Gen-Z标准引起了广泛的行业兴趣,但在处理器端却未能获得足够的支持,这阻碍了其普及。

2018年,CPU-GPU混合HPC系统Summit的上线标志着HPC发展历程中的一个重要里程碑。在此之前,HPC系统主要由CPU组成。而Summit的出现,将大规模GPU引入HPC领域,开启了全新的时代。
Summit系统包含9000个处理器和30000个NVIDIA处理器,通过NVLink(一种专有网络)和InfiniBand进行连接。与传统CPU系统相比,Summit的性能实现了大幅提升。如今,主流的HPC架构与六年前的Summit系统仍然十分相似。
为了进一步提升内存带宽,Summit的后续系统Sierra采用了全新的内存架构。与传统的并行DDR接口不同,Sierra使用16个OpenCAPI串行接口,将内存带宽提升至并行接口的两倍。这是因为在相同的物理空间内,可以容纳16倍数量的串行链接,可提供25Gbps的带宽。同时,通过内存控制器,Sierra的读延迟控制在5纳秒以内。
OpenCAPI内存标准OMI的发布,使之成为一种通用标准。尽管Sierra是唯一充分利用该标准的系统,但它通过OMI接口成功实现了高带宽内存处理器的生产。JEDEC组织对OMI标准进行了标准化,并将其命名为DIMM OMI。Microchip公司参与了处理器制造,我本人也参与其中。这种方法与CXL类似,代表了一种将专有标准开放化的尝试。

在2016年至2018年间,HPC领域涌现出大量新的互连标准,约有10种之多,其中包括几家RISC-V公司提出的标准。这些标准旨在解决内存扩展、内存移动和共享、加速器以及处理器内存带宽等问题,并在不同公司中得到了不同程度的采用。
CXL的诞生离不开英特尔的推动。当时,英特尔拥有自己的内部规范,旨在扩展PCIe以支持内存共享和加速器连接。基于这一规范,CXL 1.0标准应运而生。该标准得到了多家公司的支持,并约定进行后续扩展。
CXL取得成功的关键因素在于,到2019年CXL 1.1发布时,所有主要处理器厂商都已在其路线图中承诺支持该标准。这一承诺使CXL区别于以往的开放标准和专有方案。开放标准的成功不仅取决于其技术本身,更取决于其被广泛采纳的程度,特别是关键处理器厂商的支持,这能够确保标准在不同处理器之间的一致性和可移植性。

在百亿亿次计算领域,我们取得了令人瞩目的进展。2022年,Frontier系统成功实现了1.6 exaflops(FP64)高精度算力,这是迄今为止最高的计算性能记录。紧随其后,Aurora系统也达到了同样的里程碑。Aurora系统采用了约1万个AMD处理器和3.7万个AMD GPU,并通过专有网络Infinity Fabric和HPE的Slingshot进行连接。值得一提的是,HPE收购了Cray公司,并继续使用Slingshot进行处理器连接。
Frontier系统不仅性能强劲,而且能效出众,达到了63 gigaflops/W,是目前最节能的HPC系统。然而,尽管如此,Frontier系统仍需要20兆瓦的电力才能运行,这已接近现有的电力基础设施极限。
许多HPC系统都部署在数据中心内,而现有的电力基础设施通常只能提供约20兆瓦的电力。为了更直观地理解这一限制,我们可以举一个例子:三座温哥华摩天大楼的总电力消耗约为20兆瓦,每座大楼约消耗7兆瓦。由此可见,在一个小区域内,运行HPC系统所需的电力需求是巨大的。
目前,多个百亿亿次计算计划正致力于再次将性能提升10倍,而功耗成为主要关注点,因为现有电力基础设施难以支撑超过20兆瓦的电力需求。
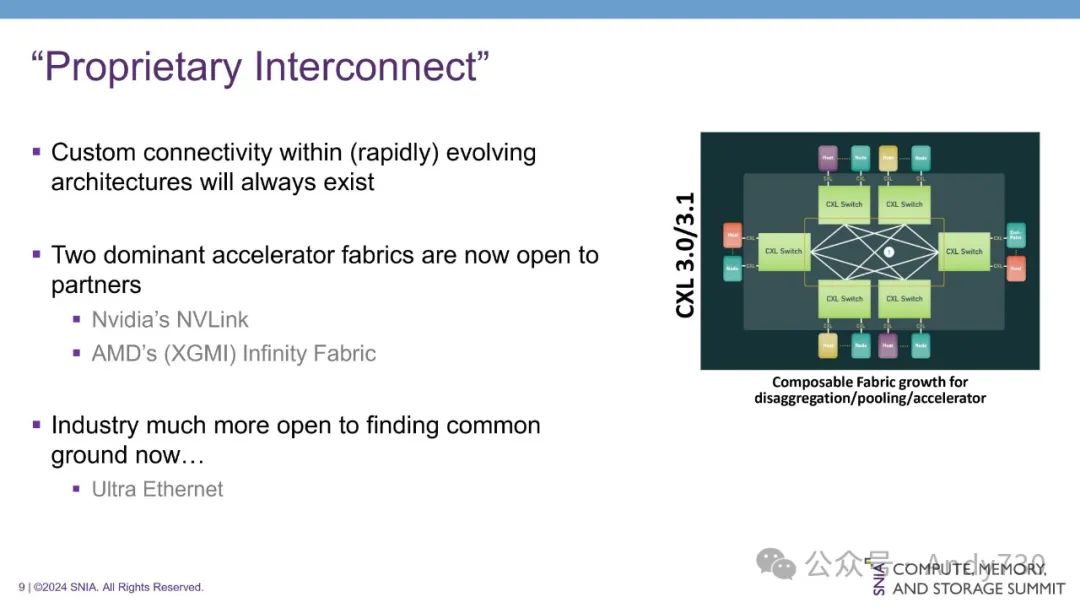
值得注意的是,定制互连仍然会存在。处理器之间的通信是创新的重要组成部分,随着硬件架构的不断发展,通信技术也将随之演进。目前,两种主要的专有互连是NVIDIA的NVLink和AMD的Infinity Fabric。尽管它们并非完全意义上的专有,但厂商可以允许合作伙伴访问其基本IP,从而连接到这些互连。然而,它们的采用范围仍较为有限。
业界已经意识到这一问题,并正在朝着更加开放合作的方向发展。例如,超以太网(Ultra Ethernet)标准的制定体现了业界对改进互连标准需要集体努力的共识。
随着规模经济效应的显现和投资的不断增加,企业在加速器互连方面的行为模式可能会发生转变。现有的加速器互连技术可以有效地连接GPU与内存、GPU与处理器以及GPU与GPU之间,但它们并不适用于内存扩展和内存一致性,这正是CXL所擅长的。CXL能够满足处理器的内存需求,因此在内存扩展和内存一致性方面仍然至关重要。
尽管在处理器之间或GPU之间连接中,公司特定的专有网络仍将存在,但随着技术的不断发展和成本的不断攀升,这种做法难以持续。未来,更加开放和标准化的互连技术将成为主流趋势,以降低成本并促进互操作性。

生成式AI拥有着颠覆性的潜力,这一点毋庸置疑。业界也涌现出与CXL绿色倡议一致的倡议,例如DDR4的再利用,这体现出对可持续发展的共同追求。
然而,我们也面临着巨大的挑战。随着AI模型规模的不断增长,对计算能力的需求也随之激增。现有的电力基础设施难以满足如此庞大的需求,以至于一些公司不得不购买核电厂为其系统供电。短期内,独立创新的趋势可能会继续主导行业发展。
但从长远来看,AI的准确性与处理能力密不可分,这意味着只有不断提升计算能力,AI才能变得更加智能。像Nvidia的Venado目前在93 exaflops浮点运算的水平上取得了突破,但仍受功耗限制。
因此,业界需要通过创新、研究投资和规模经济来提高功耗效率,以突破现有的技术瓶颈。JEDEC、SNIA、OCP和CXL等标准化组织的努力至关重要,它们能够促进基础设施的应用、架构的对齐和系统的稳定性,从而充分发挥这些网络的潜力。
CXL的采用尚处于起步阶段,而芯片开发成本高昂。如果没有现有的标准化工作,我们将无法加速发展并取得更大的突破。
--【本文完】---
近期受欢迎的文章:
更多交流,可添加本人微信
(请附姓名/单位/关注领域)

