





当前,大多数机器学习模型都被部署在独立于数据库的环境中,数据库仅作为数据存储的容器使用。这种架构虽然在过去的实践中广泛应用,但却存在不少缺点。例如,模型和数据的分离增加了系统的复杂性,导致数据传输的延迟以及模型推理过程中的性能瓶颈。此外,许多数据处理任务在Python中执行起来相当复杂,而这些任务若在数据库中完成,则能够简化流程并提升效率。
在这种背景下,将机器学习模型直接引入数据库内执行的需求愈发迫切。通过将模型直接部署在数据库中,不仅可以提升系统的整体性能和架构简化度,还能利用数据库的内置功能快速完成许多数据操作。特别是当需要进行向量相似度搜索、分类和预测等任务时,拥有一个能够直接运行AI和机器学习模型的数据库可以极大地简化开发流程。
Oracle Database 23ai正是为了解决这一需求而推出的新型数据库解决方案。它支持导入来自Hugging Face等平台的预构建嵌入模型,或者是用户在TensorFlow、PyTorch等主流框架中训练的自定义模型。同时,通过Oracle AI向量搜索和数据库内的Oracle机器学习,用户能够更加高效地管理和使用这些模型。

Oracle Database 23ai 提供了强大的支持,能够轻松集成多种机器学习模型来源,帮助用户在数据库内高效地完成模型推理和分析任务。它的核心优势在于其多样化的模型兼容性,无论是数据库原生的机器学习模型,还是外部框架开发的模型,都可以无缝集成并充分利用。首先,Oracle Database 23ai 支持原生OML(Oracle Machine Learning)数据库内模型,这些模型直接在数据库内部通过Oracle的机器学习功能构建和运行。这种集成方式不仅简化了数据流动,还确保了模型推理的高效性与数据安全性。
其次,Oracle Database 23ai兼容ONNX格式的模型,这一开放的神经网络交换格式使得用户可以将来自不同框架的模型(如TensorFlow、PyTorch等)直接导入到数据库中使用,充分实现了模型跨平台、跨框架的迁移和应用。ONNX的标准化格式让用户能够充分地利用其已有的机器学习开发资源,不必因平台差异而进行额外的模型转换或开发工作。
除此之外,Oracle Database 23ai也支持通过原生Python和R包创建的机器学习模型。这对很多数据科学家和开发人员来说非常有利,因为Python和R是目前广泛使用的数据科学和机器学习编程语言。通过这种支持,开发人员无需更改他们习惯的开发环境,即可将模型集成到数据库中,实现无缝的开发和部署。
同时,Oracle Database 23ai还支持Transformer和嵌入模型,这是现代AI应用中的核心模型架构,尤其在自然语言处理(NLP)、图像识别以及向量相似性搜索等任务中广泛应用。通过支持这些先进的深度学习模型,Oracle Database 23ai 能够让用户在数据库内完成更复杂的AI任务,而无需额外的外部平台支持。
Oracle Database 23ai 通过其对多种模型类型的广泛支持,为企业和开发者提供了极高的灵活性和可扩展性。不仅简化了AI和机器学习项目的开发与部署流程,还大大提高了系统的整体效率和性能表现,为实现更快、更安全的机器学习推理提供了强大的技术基础。

什么是ONNX及其运行时(Runtime )?
在当今复杂多变的AI和机器学习领域,模型的开发和部署往往依赖于多个不同的框架和工具。这为AI开发者带来了极大的便利,但同时也增加了不同平台间模型兼容和迁移的挑战。为了解决这一问题,ONNX(Open Neural Network Exchange,开放神经网络交换格式)应运而生。
ONNX 是一种开放的格式,专为表示机器学习和深度学习模型而设计。它通过定义一套通用的操作符(模型的基本构建块)和文件格式,使得开发者可以在不同的框架、工具、运行时和编译器中无缝地使用这些模型。换句话说,ONNX打破了模型在不同工具和平台间迁移的壁垒,极大地提高了模型的可移植性和通用性。
与此同时,ONNX Runtime 是一个高性能的引擎,专为部署ONNX格式的模型而设计。无论是神经网络模型还是其他类型的机器学习模型,ONNX Runtime都能够高效地执行。这种高性能的推理引擎使得开发者可以在不牺牲性能的情况下,快速部署和运行ONNX模型。
对于企业和开发者来说,ONNX及其运行时的结合提供了一个标准化的解决方案,使得不同开发工具创建的模型可以方便地集成到生产环境中,并实现跨平台的推理与部署。通过利用Oracle Database 23ai对ONNX的支持,用户可以轻松导入并在数据库中执行这些模型,进一步简化了AI项目的开发与部署流程。
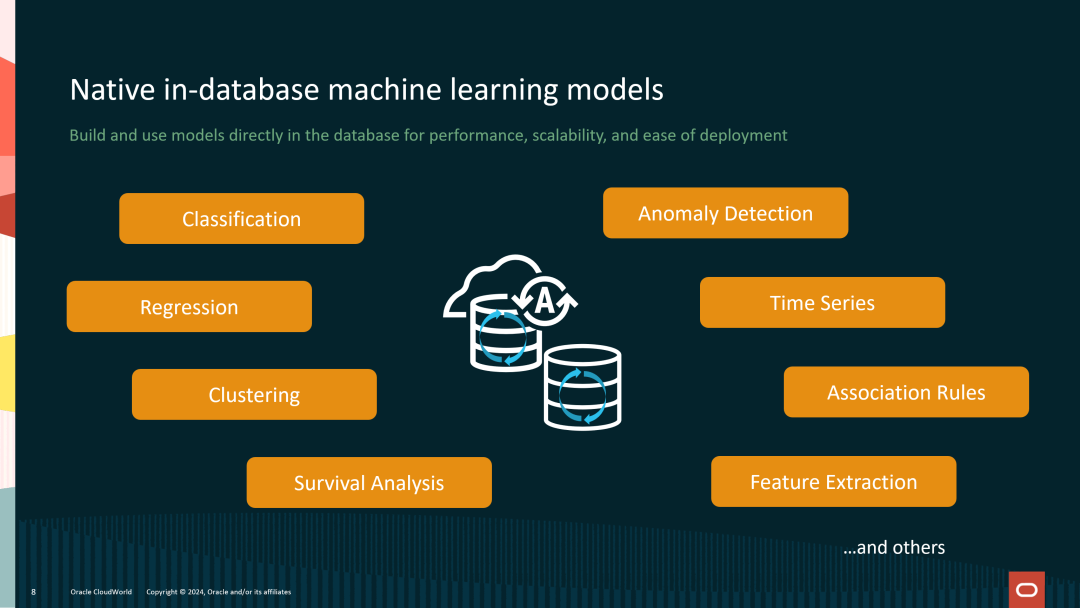
原生数据库机器学习模型:高效、可扩展的AI解决方案
在当今快速发展的数据驱动世界中,企业需要能够快速、高效地在数据中提取有用的信息,并实时做出决策。以往,机器学习模型的训练和部署需要将数据从数据库中提取到外部系统中进行处理,这不仅增加了复杂性,还会引发数据安全和性能问题。Oracle Database 23ai通过原生支持多种机器学习模型,提供了一种在数据库内部直接构建和使用模型的方式,从而大大简化了AI工作流,提高了性能和可扩展性。
以下是Oracle Database 23ai支持的几种常见机器学习模型类型和应用场景:
分类(Classification):用于将数据分类到预定义的类别中,广泛应用于客户细分、欺诈检测等领域。
回归(Regression):通过预测连续值输出,如销售预测、市场趋势分析等场景。
聚类(Clustering):通过发现数据中的自然分组,应用于客户分类、市场细分等。
异常检测(Anomaly Detection):用于识别数据中的异常模式,常见于信用卡欺诈检测、设备故障预测等。
时间序列分析(Time Series Analysis):用于分析和预测基于时间的数据,如股票价格预测、气象数据分析等。
关联规则(Association Rules):用于发现数据中的频繁项集和关联关系,常用于购物篮分析等领域。
生存分析(Survival Analysis):用于预测事件发生的时间,适用于医疗保健和设备维护等领域。
特征提取(Feature Extraction):帮助从数据中提取有用的特征,以提高模型的预测性能。
通过支持这些内置的机器学习模型,Oracle Database 23ai不仅提升了AI任务的执行效率,还降低了数据移动和外部系统集成的复杂性。这种在数据库内部直接运行的机器学习模型能够提供更好的性能、可扩展性和安全性,使企业能够更轻松地将AI模型集成到业务流程中。

通过REST端点实现数据库内和ONNX格式模型的高效部署与推理
Oracle Database 23ai通过REST端点的支持,为企业提供了灵活且高效的机器学习模型部署和推理解决方案。无论是数据库内的原生模型,还是来自第三方平台的ONNX格式模型,都可以通过这一方式轻松集成,确保AI应用能够快速上线并稳定运行。
支持的模型类型:Oracle Database 23ai能够支持包括分类、回归、聚类、特征提取等多种机器学习模型类型。这使得企业能够根据具体的业务需求,选合适的模型应用于不同的场景。
灵活的模型部署:通过REST端点,用户不仅可以部署数据库内的原生模型,还可以部署第三方(如ONNX格式)的模型。这种灵活的支持,打破了工具和平台之间的界限,使得模型的管理和部署更加简便。
轻量级实时推理:Oracle Database 23ai提供了轻量级的实时数据推理功能,能够支持流数据和其他应用场景。无论是实时推理(Real-time Scoring)还是批量推理(Batch Scoring),都可以根据需求灵活选择。
多种推理模式:Oracle Database 23ai支持单例、小批量和全批量推理方式,确保从小规模实验到大规模生产环境的需求都能得到满足。
此外,Oracle Database 23ai还提供了完善的监控和模型管理功能。通过对数据和模型的监控(Data Monitoring 和 Model Monitoring),用户能够实时掌握模型的运行状态和数据的变化趋势,确保系统的稳定性和性能。对于模型的管理,系统支持存储、组织、版本管理以及模型比较等操作,帮助企业更加高效地管理其机器学习资产。通过这些强大的功能,Oracle Database 23ai为企业提供了一个完整且灵活的机器学习解决方案,极大简化了AI模型的部署和维护过程,使得企业能够更加专注于业务创新和发展。
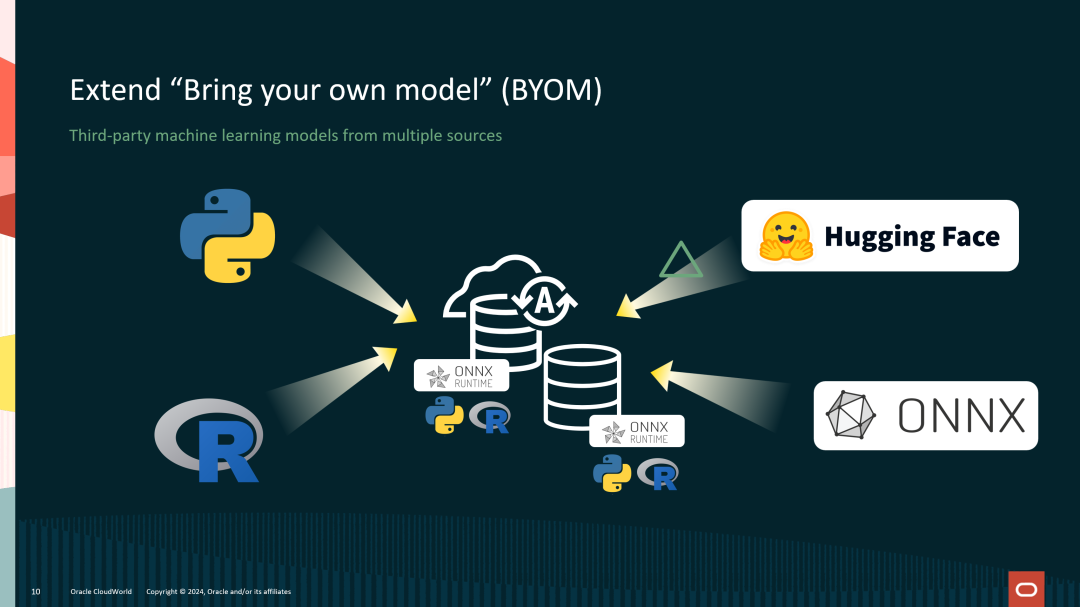
Oracle Database 23ai的“Bring Your Own Model (BYOM)”功能支持用户从多个第三方平台(如Hugging Face、ONNX等)导入机器学习模型,并通过ONNX Runtime进行高效推理。无论是Python或R等开发环境中的模型,还是不同框架创建的模型,Oracle Database 23ai都能实现跨平台兼容性,提供统一的执行环境。这一功能大大简化了AI模型的部署和管理,帮助企业充分利用现有资源,快速满足业务需求。

导入文本嵌入模型 (Import Text Embedding Models)
Oracle通过OML4Py EmbeddingModel2OML包,支持用户将文本转换模型作为数据库对象导入,并在数据库中使用AI向量搜索。这种方式使得我们可以直接从像Hugging Face这样的模型仓库中生成ONNX格式的模型,并将其无缝集成到数据库中进行存储和使用。这个过程涵盖了模型的预处理和后处理,使整个数据管道得以顺利运行。使用OML4Py包,用户可以轻松地导入文本嵌入模型到数据库中。以下是一个Python代码的示例:
import omlfrom oml.utils import EmbeddingModelem = EmbeddingModel(model_name="sentence-transformers/all-MiniLM-L6-v2")em.export2db("sentence-transformer")# 或者em.export2file("sentence-transformer")
通过该代码,我们可以看到用户如何快速将预训练的文本嵌入模型转换为可在数据库中使用的ONNX格式,并存储到Oracle数据库中。
具体而言,Oracle提供了OML4SQL DBMS_DATA_MINING包,它允许用户从对象存储中获取ONNX格式的模型包,并将这些模型导入到数据库中,随后在数据库内使用ONNX运行时进行处理。以下是使用DBMS_DATA_MINING包将ONNX格式的文本嵌入模型导入数据库的示例代码:
DECLAREmodel_source BLOB := NULL;BEGINmodel_source := DBMS_CLOUD.get_object(credential_name => 'OBJ_STORE_CRED',object_uri => 'https://objectstorage_bucketname/o/sentence-transformer-bundle.onnx');DBMS_DATA_MINING.import_onnx_model(model_name => 'sentence-transformer',model_data => model_source,metadata => JSON('{"function" : "embedding"}'));END;
通过这个流程,用户可以直接从对象存储中获取已准备好的ONNX模型,并将其加载到Oracle数据库中供AI向量搜索等功能使用。该方法不仅减少了部署AI/ML模型的复杂性,还确保了模型可以在数据库内无缝运行。
使用嵌入模型进行AI向量搜索 (Using Your Embedding Model with AI Vector Search)
在成功将文本嵌入模型导入到Oracle数据库后,用户可以利用AI向量搜索功能来进行实际的应用。例如,在招聘场景中,企业可以使用嵌入模型快速查找与特定求职者简历相匹配的职位。在这个案例中,系统通过嵌入模型为每个职位创建向量表示(vector embedding),然后根据简历内容计算这些职位与简历的相似度,帮助招聘者快速找到符合条件的职位。下面是一个实现的SQL示例,展示了如何创建一个职位信息表并生成对应的嵌入向量:
CREATE TABLE job_post_vector_table ASSELECT id, job_title, location, job_post,VECTOR_EMBEDDING(sentence_transformer)USING job_post AS embedding;
通过此命令,用户可以将职位描述转换为嵌入向量,并将这些向量存储在数据库的表中。接着,可以创建向量索引来加速搜索和查询:
CREATE VECTOR INDEX vector_idx ONjob_post_vector_table (embedding)ORGANIZATION INMEMORY NEIGHBOR GRAPH;
此向量索引将帮助系统通过语义相似度来快速检索与输入简历相似的职位信息。一旦索引创建完成,用户可以使用以下查询语句来获取匹配的工作岗位,例如查找“纽约的软件工程师”职位:
SELECT id, job_post FROM job_post_vector_table tWHERE t.job_title = 'Software Engineer'AND t.location = 'New York'ORDER BY VECTOR_DISTANCE(embedding, VECTOR_EMBEDDING(sentence_transformer)USING :resume) ASCFETCH APPROXIMATE FIRST 10 ROWS ONLY;
此查询通过计算嵌入向量的相似度,按照与简历的匹配程度排序,返回前10个相关的工作岗位。
实际应用示例:在招聘系统中,求职者提交简历后,系统会通过嵌入模型将简历内容转换为向量表示。数据库中的职位信息也已经预先通过相同的嵌入模型转换为向量。当系统接收到简历后,它会使用向量距离计算求职者与各职位的匹配度,并返回符合条件的工作列表。这种基于AI向量搜索的方式不仅提升了招聘的效率,还改善了职位匹配的精准度。
导入ONNX格式的机器学习模型 (Import ONNX-format ML Models)
Oracle通过OML4SQL DBMS_DATA_MINING包,支持将传统的机器学习模型作为数据库中的对象进行管理和预测。这个包可以支持多种机器学习技术,包括分类、回归和聚类。用户可以将ONNX格式的模型导入到Oracle数据库中,这些模型的行为与原生的数据库模型相同,能够使用与其他数据库模型一致的预测操作符。以下是一个SQL示例,展示了如何将ONNX格式的分类模型导入数据库:
DECLAREmodel_source BLOB := NULL;BEGINmodel_source := DBMS_CLOUD.get_object(credential_name => 'OBJ_STORE_CRED',object_uri => 'https://objectstorage_bucketname/o/classification-churn-bundle.onnx');DBMS_DATA_MINING.import_onnx_model(model_name => 'churn_model',model_data => model_source,metadata => JSON('{"function" : "classification"}'));END;
该示例展示了如何从云对象存储中获取一个分类模型(用于客户流失预测),并将其加载到数据库中。导入完成后,模型可以像数据库中的其他模型一样,使用标准的预测操作符进行应用,例如以下查询用于根据客户数据进行流失预测:
SELECT case_id, PREDICTION(churn_model USING *) FROM CUSTOMERS;
这种方式为开发人员和数据科学家提供了一种简洁的解决方案,可以快速将预训练的ONNX模型集成到数据库中,并且直接进行预测,而无需在应用层重新构建复杂的模型处理逻辑。
这种做法的优势在于:
原生支持多种机器学习技术:通过DBMS_DATA_MINING包,Oracle数据库支持分类、回归和聚类等多种ML任务的执行。
简化模型集成流程:ONNX格式的模型可以轻松导入到数据库中,并且行为和预测操作与原生模型一致,大大减少了模型集成的复杂度。
增强的预测功能:通过标准的SQL预测操作符,用户可以快速对存储在数据库中的数据进行预测,从而提升系统的性能和响应速度。

接下来让我们看一个实际的例子。
全面球员发展 (Wholistic Player Development)
在现代体育中,球员的发展不仅仅依赖于技术和战术层面的提升,还需要从心理、身体、社交和战术多个维度进行全面考虑。纽卡斯尔联队女子U21队采用了全面的球员发展方法,帮助球员在各个方面得到充分的成长和进步。
心理 (Psychological)
心理健康对于球员的长期表现至关重要。球队通过以下方式支持球员的心理发展:
睡眠质量与幸福感测量:了解球员的生活习惯和情绪状态,确保她们能够以较好的状态投入比赛。
赛后分析:鼓励球员分享她们对比赛的感受和想法,帮助她们反思表现。
教练与球员的观点对比:帮助球员理解教练的意图和训练计划,以改进训练和比赛中的表现。
身体 (Physical)
在身体层面,球队通过多种指标来确保球员的身体素质和健康状态:
测试:例如垂直/水平距离和加速度的测量,用于评估球员的爆发力和速度。
伤病恢复:专门的计划帮助球员在伤病后快速恢复,并尽量减少复发风险。
距离覆盖:在训练和比赛中,跟踪球员的跑动距离,以评估她们的体能状况。
社交 (Social)
球员的发展同样需要考虑她们的社交能力和团队协作能力:
社交网络的捕捉与理解:通过了解球员之间的社交关系,帮助球队建立更紧密的团队合作。
领导力培养计划:通过教育计划,提升球员的领导能力,帮助她们在场上和场外都能成为团队的核心。
战术 (Tactical)
战术能力是每个成功球员必备的素质,球队在这方面提供了详细的数据分析:
传球组合分析:研究球员在比赛中的传球路线,帮助她们优化战术执行。
平均位置分析:跟踪球员在场上的位置,尤其是在控球和无球时的移动。
进攻分析:通过成功或未成功的射门分析,帮助球员提高进攻效率。

理解所有数据:发展阶段 (Understanding All Data: Development Phase)
为了更好地管理球员的健康和表现,纽卡斯尔联队女子U21队采用了数据驱动的方法来跟踪球员的日常状态。这一过程不仅包括球员的身体数据,还包括她们的心理状态、疲劳水平等信息。这种全面的数据收集为球队提供了一个更深入的理解,帮助他们在训练和比赛中做出更明智的决策。
数据收集方法
每日更新:球员每天都会通过表单输入她们的状态信息,如睡眠时长、睡眠质量、情绪状态等。这些日常数据帮助教练团队及时了解球员的身心状况。
长期分析:随着时间的推移,表单中的数据将形成完整的历史记录,通过分析这些数据,教练可以发现球员疲劳的来源,以及一些潜在的健康问题或影响表现的因素。
文本输入:鼓励球员使用自由文本框输入她们的额外信息或更新内容。这种方式让球员可以表达她们的主观感受,如训练中的压力、对比赛的期望或任何身体不适的反馈。
数据的用途
这些数据不仅仅用于监测球员的健康状态,还是球队决策的重要依据。通过数据的积累和分析,球队能够:
了解球员的目标:球员可以通过表单分享她们的长期职业目标或对某场比赛的感想。
评估训练和比赛:球队可以使用这些数据回顾训练和比赛的情况,进一步优化战术和训练计划。
个性化反馈:通过这些信息,教练能够针对球员的具体需求提供个性化的指导,帮助球员在训练和比赛中更好地发挥。

理解所有数据:非结构化数据分析 (Understanding All Data: Unstructured Data Analysis)
在现代足球数据分析中,不仅结构化的数据(如跑动距离、传球次数等)非常重要,非结构化数据(如球员的自由文本反馈)也同样关键。为了更好地理解这些非结构化数据,纽卡斯尔联队女子U21队开发了一种基于Python的分析方法,通过Hugging Face上的情感分析模型来挖掘球员输入的文本信息。
分析方法
Python和Hugging Face模型:通过使用Hugging Face的情感分析模型,球队能够深入分析球员提交的非结构化文本数据。例如,球员可能会提交她们对比赛或训练的主观感受,而这些感受可以通过情感分析来量化,从而为教练提供额外的洞察。
情感分类和冲突识别:分析过程中,模型能够识别出球员的情感状态,如紧张、焦虑或情绪波动。这帮助教练团队更好地理解球员在某段时间内的情感变化。通过这种方法,球队还可以发现结构化数据与非结构化数据之间的冲突。例如,某位球员在体能测试中的表现可能良好,但她的情感反馈却显示出极大的压力或焦虑。
实际应用和收益
促进球员和教练之间的对话:这些情感分析结果为球员与教练之间的沟通提供了依据。当教练了解球员的内心感受后,能够更好地为她们提供心理支持或个性化的训练建议。
决策依据:基于这些额外的洞察,球队可以在日常管理中更加主动,及时发现球员的心理和情感变化,做出相应调整。例如,情感分析结果可能显示一名球员正在经历紧张或不安情绪,这时教练可以提前与她进行一对一的沟通。
通过对非结构化数据的深入研究,教练团队意识到这种分析对球员管理的极大帮助,因此决定将这一功能纳入日常数据收集流程中。未来,球员的自由文本反馈将会与结构化数据一起提供给教练,帮助他们更加全面地了解球员的状态。
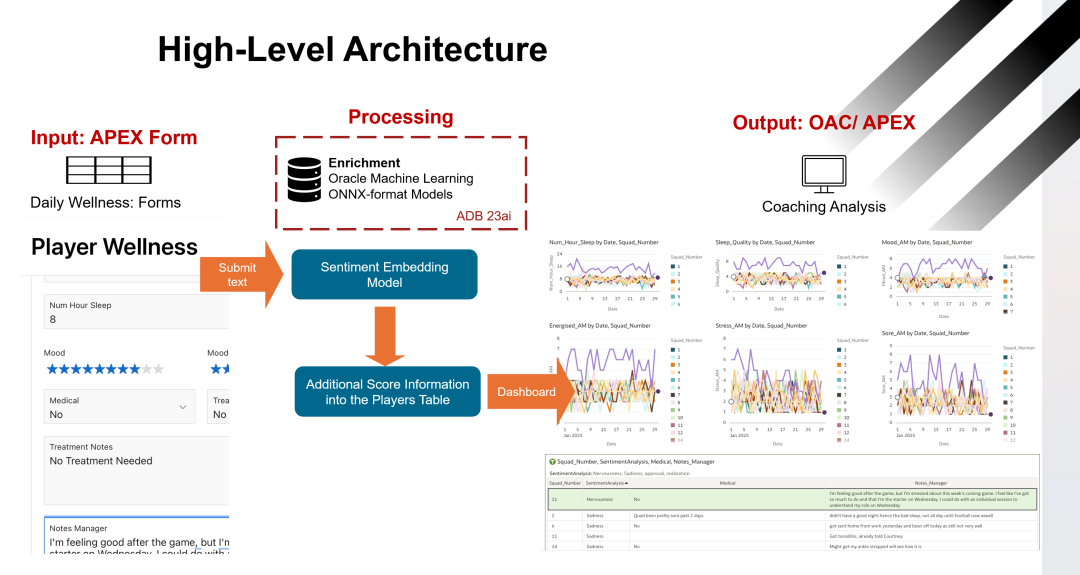
架构概述 (High-Level Architecture)
为了全面跟踪和分析球员的健康状态,纽卡斯尔联队女子U21队采用了一个集成的架构,通过Oracle APEX、Oracle Machine Learning(OML)和情感嵌入模型来实现从数据收集到教练分析的全流程。
输入阶段:APEX表单 (Input: APEX Form)
球员通过每日填写健康表单(Player Wellness),将她们的睡眠时长、情绪状态、压力感等信息提交到系统中。这些信息通过APEX表单进行结构化收集,便于后续的数据处理和分析。
处理阶段:情感嵌入模型和机器学习 (Processing: Sentiment Embedding Model and Machine Learning)
当球员提交信息后,系统会使用情感嵌入模型对非结构化的文本数据(例如自由文本输入的感受或评论)进行处理。Oracle的机器学习平台结合ONNX格式的模型,对这些文本数据进行情感分析和量化。接下来,这些额外得分信息会被整合到球员的健康表中,帮助教练获取更全面的球员状态信息。这一阶段的处理是在Oracle Autonomous Database(ADB 23ai)中完成,利用强大的数据处理和机器学习能力,使得情感分析能够快速且精准地完成。
输出阶段:OAC/APEX仪表板 (Output: OAC/APEX Dashboard)
处理后的数据将通过Oracle Analytics Cloud(OAC)和APEX仪表板呈现给教练团队。教练可以在仪表板上查看球员的详细状态数据,包括:
睡眠时长:每天、每周的睡眠数据。
情绪变化:球员在训练或比赛前后的情绪状态。
压力水平:通过情感分析量化的压力感受。
疲劳状况:球员在训练或比赛中的身体疲劳情况。
这些数据通过图表和时间线展示,帮助教练更直观地了解球员的身体和心理状况。同时,系统还提供自由文本分析的结果和相应的情感得分,帮助教练做出更全面的分析和决策。
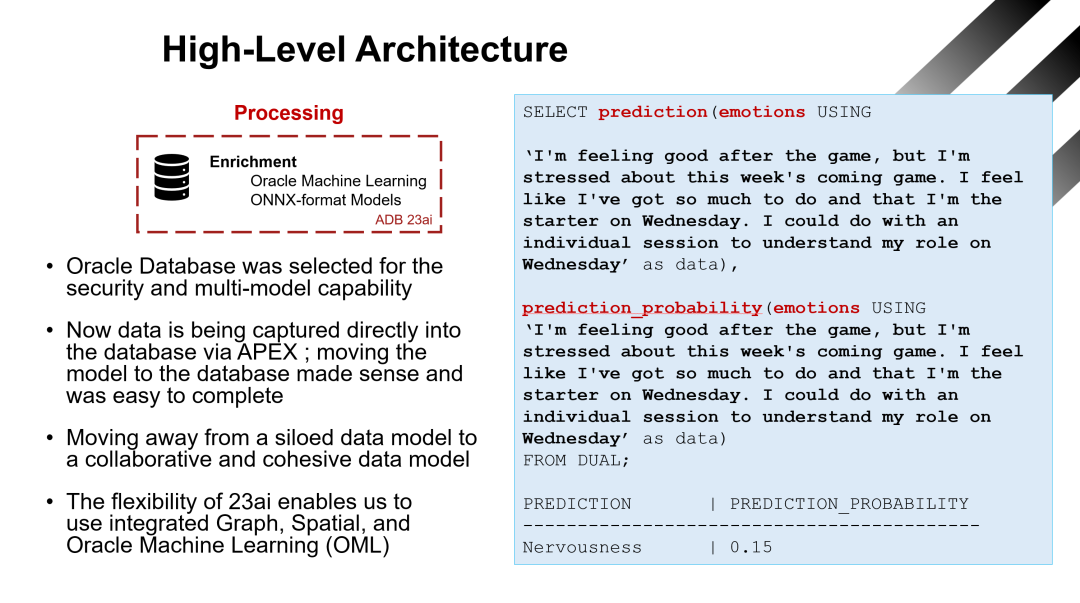
在球员数据的管理中,Oracle数据库成为了关键的技术基础,它提供了安全性和多模型处理能力,使得数据的存储、处理和预测分析更加高效和便捷。
数据捕捉与处理
Oracle数据库的选择:Oracle数据库因其卓越的安全性和多模型处理能力被选为存储和分析平台。它的多模型功能使得结构化与非结构化数据能够无缝集成,提供了一体化的解决方案。
APEX 数据输入:球员数据通过APEX表单直接输入到数据库中,这种方式简化了数据的捕获流程。将模型迁移到数据库的过程中也显得非常自然和顺畅。
机器学习模型的集成:数据进入数据库后,通过Oracle Machine Learning(OML)和ONNX格式的模型对这些数据进行处理。数据库的集成能力允许模型直接在数据上运行,实现实时的预测与分析。
通过这种架构,球队从原本分离的数据模型过渡到一个协作、统一的数据模型。以前,数据可能散布在多个系统中,难以进行有效的整合和分析;而现在,所有数据被集成在一个系统中,不仅提高了数据的透明度,还使得各部门能够更好地协作。
实时情感预测
下方的SQL代码展示了如何通过Oracle数据库直接进行情感分析与预测:
SELECT prediction(emotions USING'I'm feeling good after the game, but I'm stressed about this week's coming game. I feel like I've got so much to do and that I'm the starter on Wednesday. I could do with an individual session to understand my role on Wednesday' as data),prediction_probability(emotions USING'I'm feeling good after the game, but I'm stressed about this week's coming game. I feel like I've got so much to do and that I'm the starter on Wednesday. I could do with an individual session to understand my role on Wednesday' as data)FROM DUAL;
该查询结果表明了系统对文本的情感分析,例如识别出球员的情绪状态“紧张”并给出相应的概率(例如0.15)。通过这种情感分析,教练能够更好地了解球员在比赛和训练中的情绪变化,并采取相应的行动。

在球员的全面发展中,团队不仅关注技术和战术的提高,还利用数据分析手段来评估球员的健康、心理状态和整体表现。以下是目前在球员发展方面的进展、主要目标和可行的行动方案。
当前状况
健康评估:球员的身心健康正在通过情感分析进行评估,尤其是利用情感模型捕捉和理解她们的情绪变化。
数据捕捉:通过APEX系统,球队已经开始全面捕捉球员的结构化数据,包括表现指标和日常健康数据。这为后续的分析和决策提供了数据基础。
关键目标
克服数据孤岛:一个关键目标是解决分散的数据环境问题,确保所有相关数据能够集中并实现无缝的整合和共享。
鼓励数据捕捉:鼓励所有相关人员,特别是球员和教练,持续捕捉数据,为每个球员的表现和发展提供更全面的背景信息。
及时共享数据:确保所有教练能够及时获取这些数据,从而在训练和比赛中做出更有效的决策。
情感与技术数据结合分析:引入新的数据分析方式,不仅关注技术和战术数据,还要理解球员的情感数据,这对于全面了解球员状态至关重要。
增强数据安全:随着数据的重要性提升,保护数据的安全性是另一项重要目标,确保球员的隐私和敏感信息不会被泄露。
提升在比赛日和训练日的容量:尤其是在比赛日和训练日,确保数据的采集、分析和处理能力能够应对高峰期需求,确保所有信息能够被高效利用。
可行的见解
建立对数据的理解:教练和球员必须逐渐构建对数据的深刻理解,确保数据能够真正指导日常的训练和比赛管理。
数据的可用性:确保这些数据在教练团队中可以在线上实时获取,同时也可以在需要时离线访问,确保灵活性。
赋能多方人员:通过数据的整合和分析,不仅赋能教练和球员,还能够为理疗师和体能教练提供有价值的见解,帮助他们制定更有效的康复和训练计划。

利用GPU提升性能
Oracle正在扩展其数据库功能,特别是针对需要高性能计算的AI/ML应用,推出ADB Serverless支持GPU的OML Notebooks。这一更新将为用户提供更多的计算能力,尤其是在处理大型数据集和复杂的机器学习模型时,可以大幅提高处理速度和效率。
即将推出
OML Notebooks将支持GPU加速的Python解释器:这是一个重要的功能扩展,能够极大提升Python代码的执行速度,尤其是在AI/ML工作流中。这一更新将支持在Oracle数据库23ai中进行AI向量搜索(AI Vector Search)的GPU加速计算。
路线图:GPU支持的未来发展
OML4Py嵌入式Python执行:未来将支持在OML4Py环境中嵌入Python代码并利用GPU进行加速执行。这对于数据科学家和开发者来说,意味着可以在数据库内执行更高效的机器学习任务。
OML4Py空间AI深度学习算法:Oracle计划扩展GPU支持至空间AI和深度学习算法,帮助用户加速处理与地理空间数据相关的复杂计算任务。
ONNX格式模型支持ONNX Runtime:随着ONNX模型的普及,Oracle将增加对ONNX格式模型的GPU加速支持,结合ONNX Runtime来提升模型推理速度。这将使得模型能够快速在数据库中运行并实时生成预测结果。
多种GPU芯片选项:Oracle的路线图还包括支持多个GPU芯片选项,以确保用户能够根据其特定的工作负载需求选合适的硬件配置。这种灵活性将帮助不同的企业和开发者根据项目需求灵活调整其计算资源。
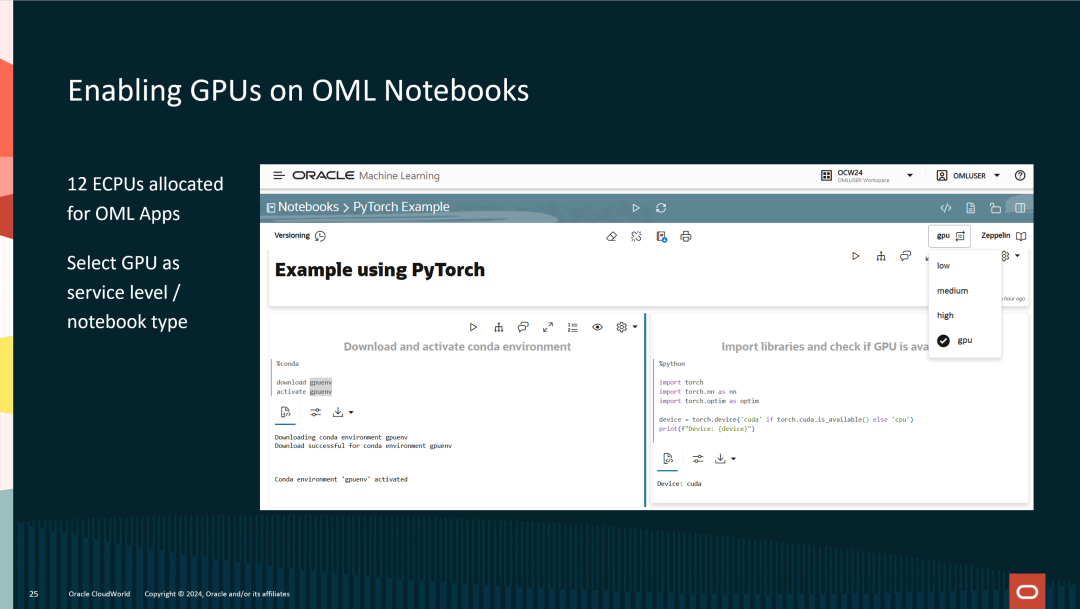
在OML Notebooks中启用GPU
为了满足更高的计算需求,Oracle现在支持在OML Notebooks中启用GPU,从而加速数据处理和机器学习模型的训练。使用GPU可以显著提高复杂计算任务的性能,例如深度学习模型的训练和推理。
关键功能:
分配12个ECPUs用于OML应用:系统为每个OML应用程序分配了12个ECPUs,以确保即使在未使用GPU的情况下也能高效运行。对于需要更高计算能力的任务,可以选择启用GPU。
选择GPU作为服务等级/Notebook类型:用户可以通过OML Notebook界面灵活选择计算资源。根据任务的需求,用户可以从“低”、“中”、“高”和“GPU”选项中进行选择。这种灵活性使得用户能够根据实际计算需求选择适合的硬件资源,既保证了性能,又避免了资源浪费。
PyTorch的GPU示例
页面展示了一个使用PyTorch在GPU上运行的示例。在Notebook中,用户首先下载并激活了一个带有GPU支持的conda环境:
%condadownload gpuenvactivate gpuenv
成功激活后,用户可以使用PyTorch库并检查是否已经启用了GPU:
import torchdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')print(f'Device: {device}')
代码中,torch.cuda.is_available()
会检查系统是否支持GPU加速,如果支持,模型会使用CUDA在GPU上运行。如果没有GPU可用,则自动回退到CPU。

通过Oracle提供的多种先进功能,企业可以在数据库中更加灵活、强大地集成AI和机器学习模型,为业务赋能。
“Bring Your Own Model” (BYOM):Oracle支持用户将外部的预训练模型带入数据库中,利用数据库内的计算能力进行AI推理。无论是文本嵌入模型还是传统机器学习模型,BYOM功能允许用户在Oracle数据库内轻松使用广泛的外部模型,增强模型的应用场景。
OML Notebooks支持GPU:随着OML Notebooks引入GPU支持,计算性能得到了显著提升,尤其是对于大规模数据和深度学习模型。GPU的支持扩展了OML的使用场景,使得用户能够在数据库中进行更复杂、更高效的AI模型训练和推理。
Oracle Autonomous Database:自主管理的Oracle数据库不仅提供了简化操作的便利性,还为基于AI的应用开发提供了强有力的支持。通过Oracle的强大计算和分析能力,开发者可以快速构建和部署智能应用程序,提升企业的业务决策和响应速度。
通过这些技术功能,Oracle为AI应用开发和部署提供了全新的可能性,使企业能够在快速发展的AI领域保持竞争优势。
编辑:殷海英
