




最近一直在研究国产数据库, 虚机上安装了yashan,达梦,oceanbase(以下简称OB)和TiDB等多个测试环境, 主要是想看看这些国产数据库的SQL优化器表现, 为国产数据库的发展也做点贡献.
在从oracle向国产数据库迁移时,很多时候会遇到某些SQL性能下降, 其实这很正常, 即便是同种数据库做升级, 升级后都会遇到部分SQL性能下降(当然这个数量会比较少), 更何况是从一个发展了将近50年的oracle数据库到国产库的迁移.
那么问题来了, 如果是从OB迁移到oracle, 是不是也会遇到很多SQL性能问题呢? 看了下面的对比, 可能你自己就能得出结论.
下面通过几个典型场景来比较一下.
OB使用的是4.3.1 (兼容oracle租户); oracle使用的是19c.
场景1: count(*)
SQL:
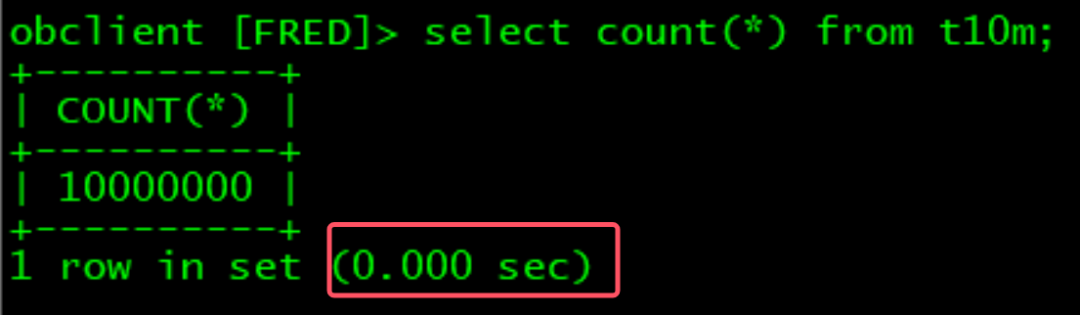
select count(*) from t10m;
其中t10m是一个1000万记录的表
在oracle里面, 需要全表扫描(或索引全扫描), 表越大,消耗的时间越长;
在OB里面是瞬出(0.001秒), 这个技术挺神奇!
场景2: 索引与null
SQL:
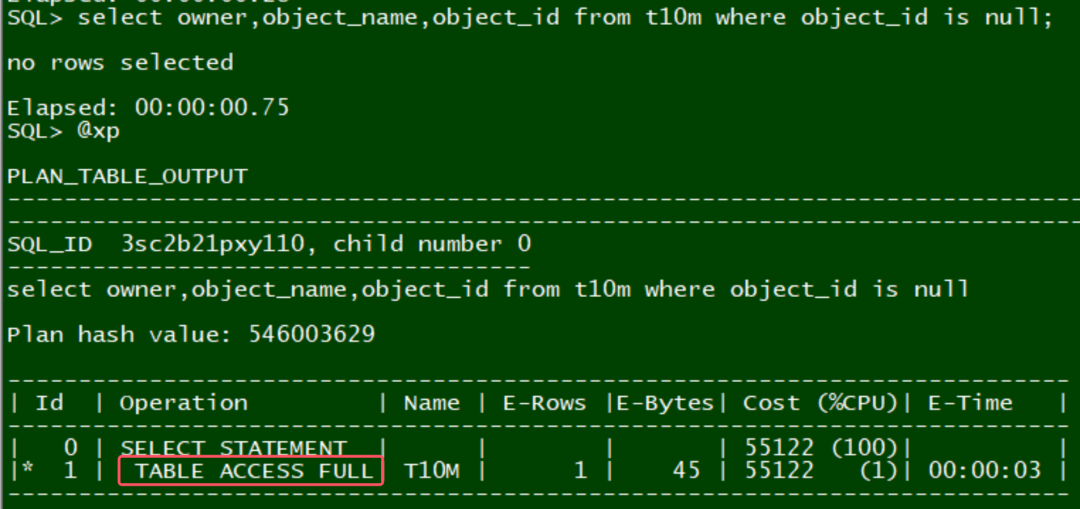
select owner,object_name,object_id from t10m where object_id is null;
object_id 字段上存在索引,满足条件的记录数很少.
oracle不可以走索引. 因为oracle的Btree索引不保存null值. 要想走索引,还需要做一些特殊处理才行:
OB(包括几乎除了oracle数据库之外的其他所有数据库)是可以走索引的, 走索引就都可以瞬出:

下面SQL也是一样的:
select * from (select owner,object_name,object_id from t10m order by object_id desc) where rownum<=10;
场景3: union all+exists
SQL:
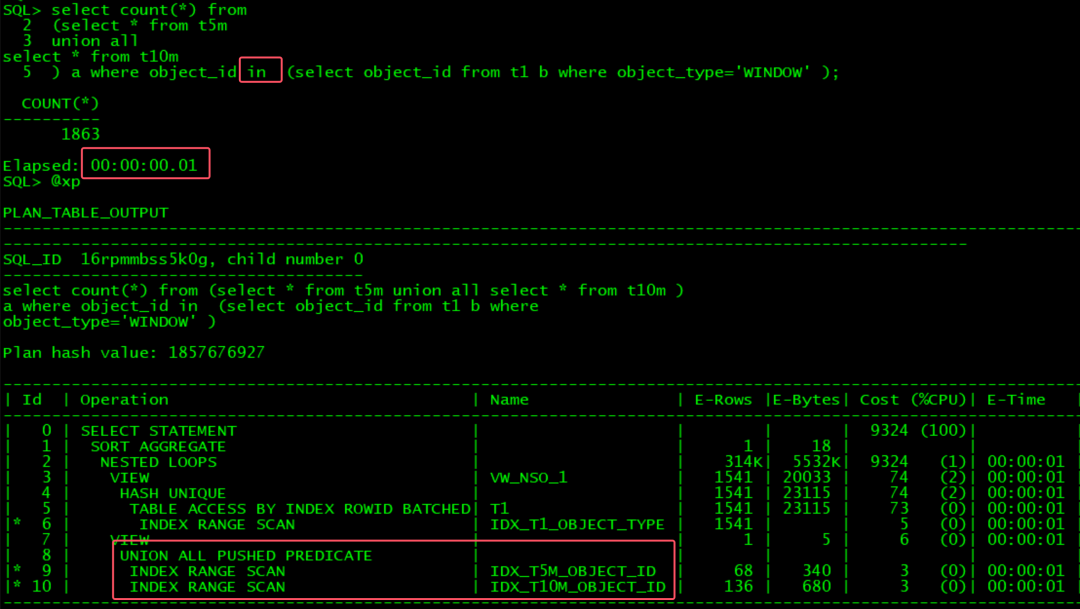
select count(*) from (select * from t5m union all select * from t10m ) a
where exists (select 1 from t1 b where object_type='WINDOW' and a.object_id=b.object_id);
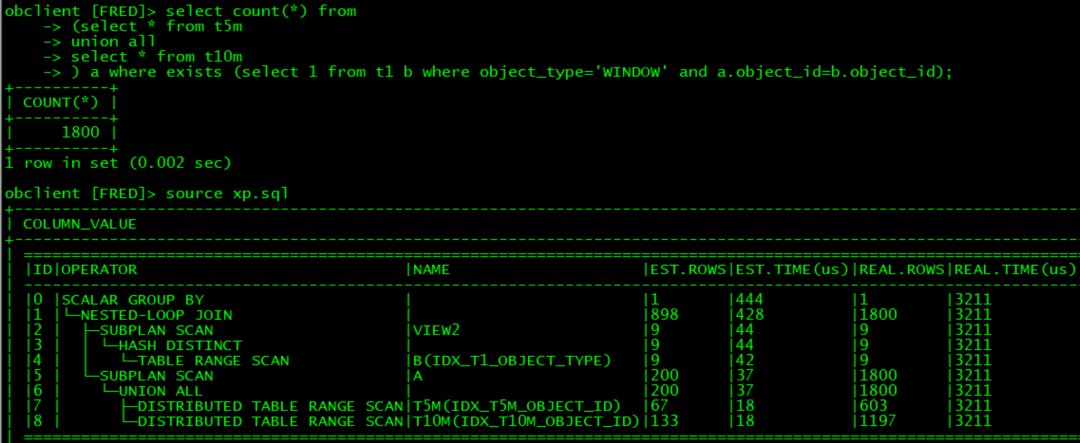
oracle的表现一般, 两个大表都使用了全表扫描:
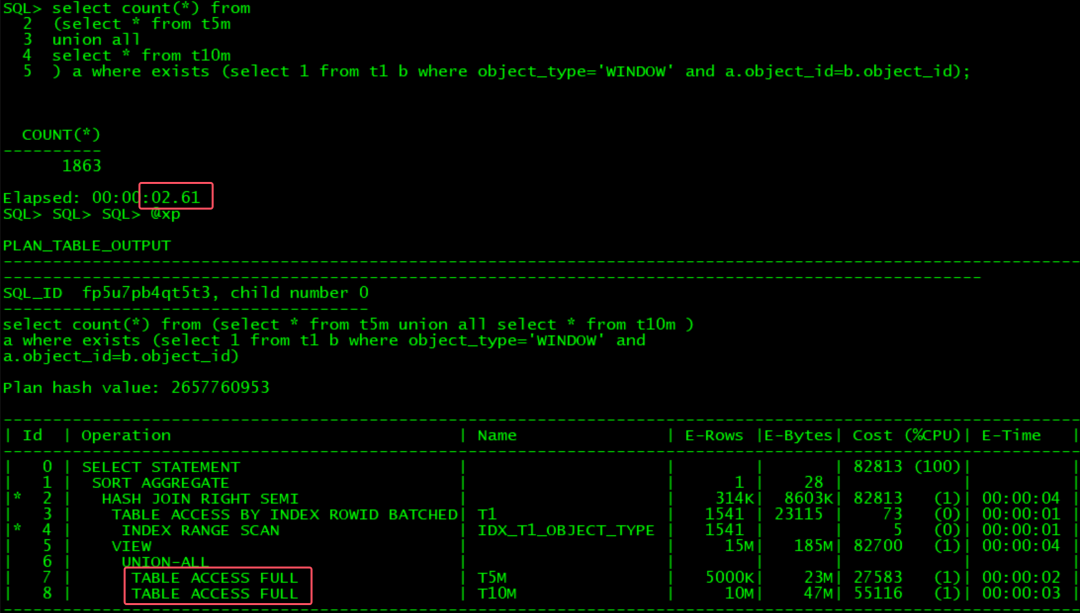
这个SQL, oracle如果要达到OB同等效率, 必须要改写. 有3种方法,可以将exists改成in,或者改成inner join, 或者将小union 拆分成大union :
场景4:识别inner join的能力
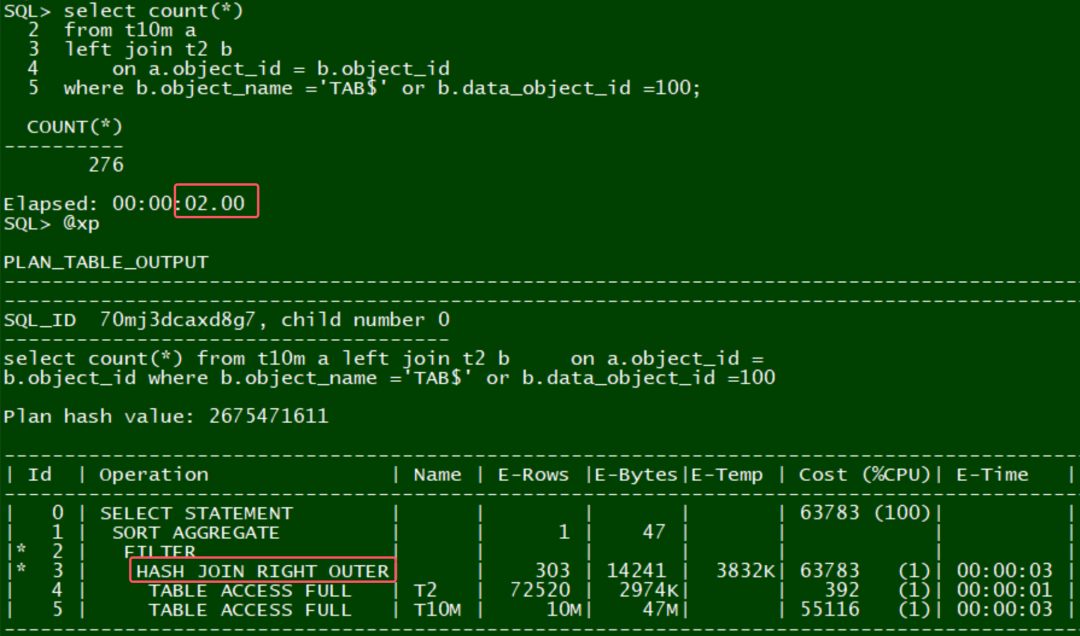
上面SQL实际上是一个inner join, 因为有个or条件, oracle没能识别出来:
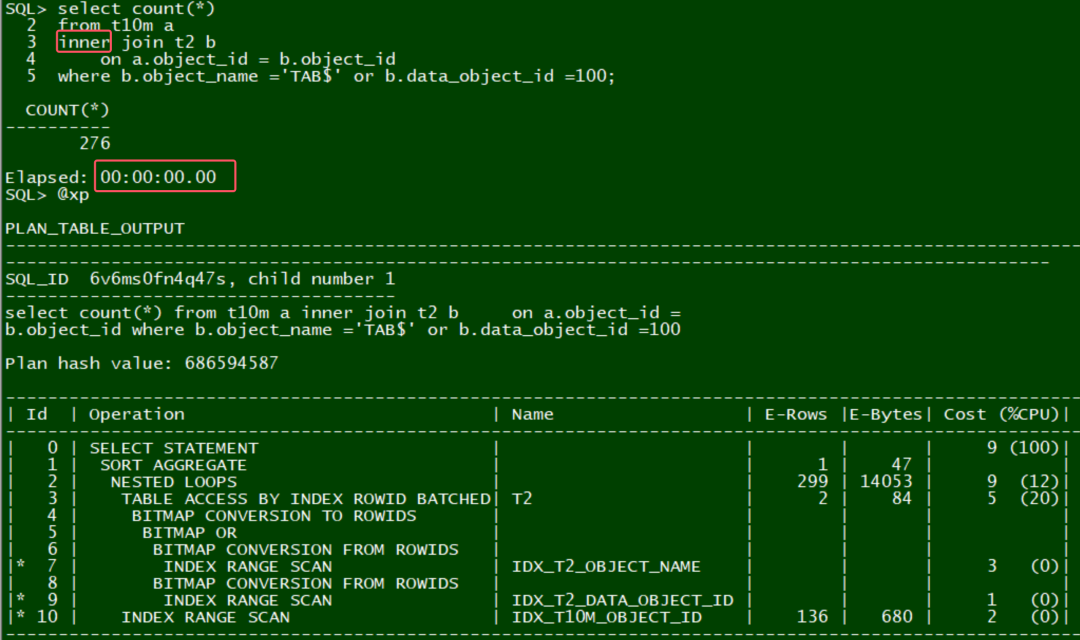
oracle如果人工将left join改成inner join,效率也是非常高的:
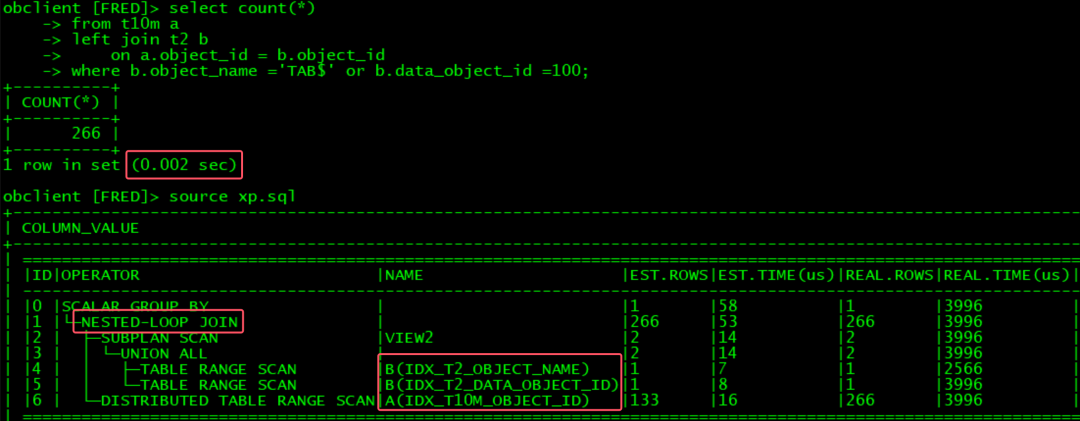
OB可以自动识别出是inner join,执行效率非常高:
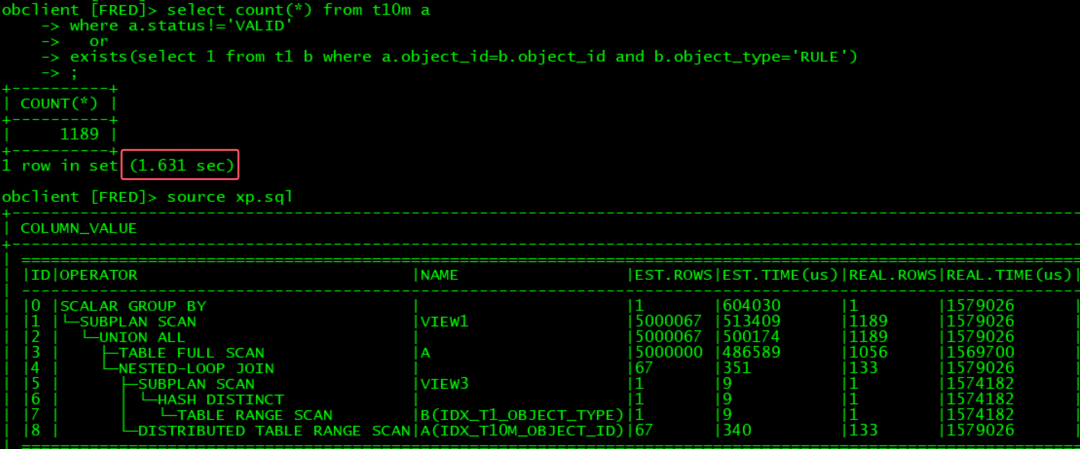
场景5:or exists
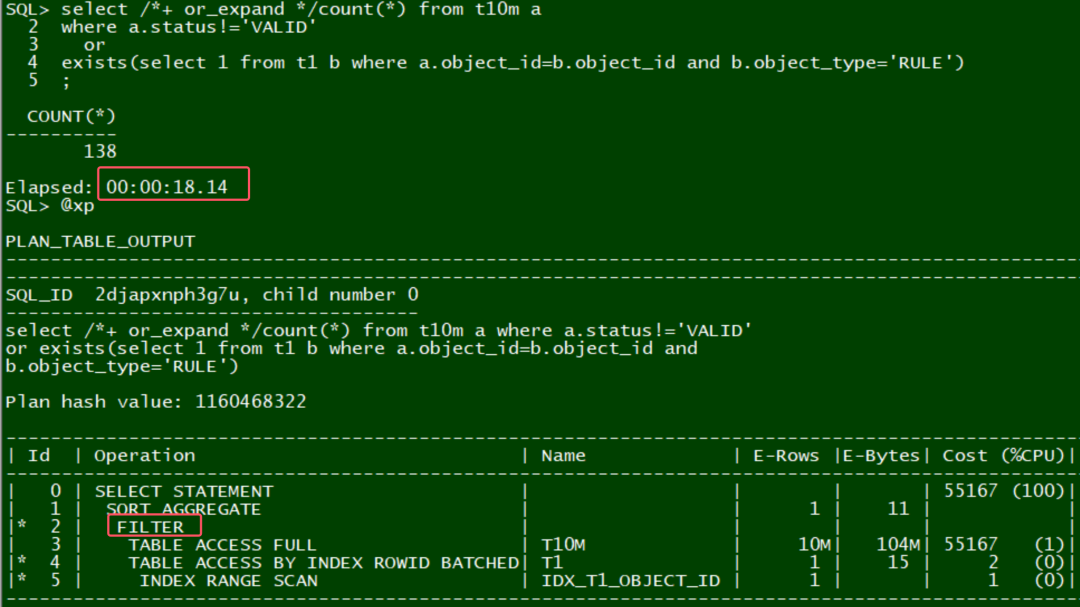
OB不加hint, 自动expand, 执行效率比较高:
声明:
上面列举的例子都是偏向OB的, 因为我搞oracle数据库20多年, 了解它的优点, 也非常了解它的缺点, 如果要找出oracle优化器好于OB的例子, 我相信也会有很多.
(未完待续)
封面照片来自我的老同事Cary Dong,感谢!
