




今天为大家分享一篇ICDE 2024年的向量检索论文:
Are There Fundamental Limitations in Supporting Vector Data Management in Relational Databases? A Case Study of PostgreSQL
在关系型数据库中支持向量数据管理是否存在根本上的局限性?基于PostgreSQL的案例分析

代码地址:https://github.com/YunanZzz/VecDB-ICDE24
论文概述
目前,工业级的向量管理有两种模式,一种是像Pinecone,Zilliz一类的向量数据库,一种是在传统数据库中支持向量类型,如PostgreSQL。一些传统数据库的向量支持的性能相比专用向量数据库仍有较大差距。本文通过分析两种数据库的代码实现,探究在关系型数据库中是否存在本质缺陷,使得无法高效支持向量管理。
实验观察
本文以PostgreSQL的插件PASE,和FAISS进行性能对比。
索引构建性能
1. IVF-FLAT
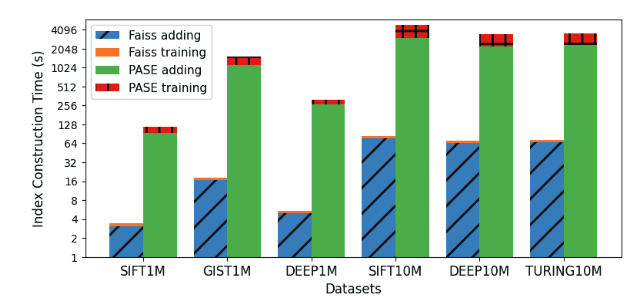
构建IVF-FLAT的性能上,FAISS是PASE的几十倍,作者通过火焰图手段分析到距离计算是核心差距:
FAISS将欧式距离拆分成向量内积和向量的模,内积则使用BLAS库中的高效矩阵计算函数SGEMM进行计算; PASE仅使用原始方法进行距离计算。
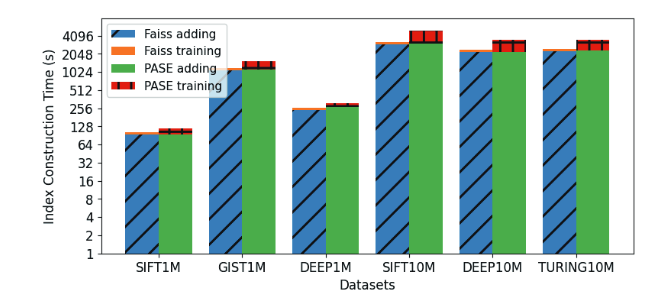
2. HNSW
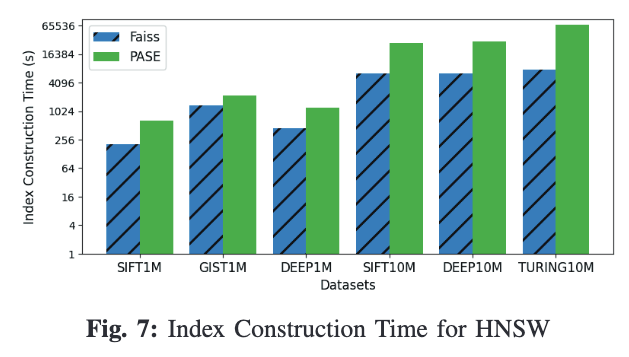
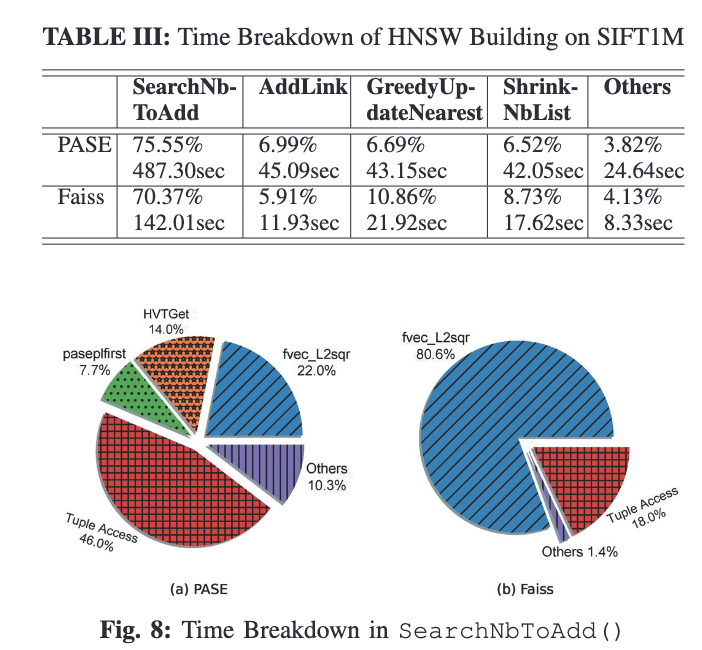
在构建HNSW索引上,PASE仍然比FAISS慢了数倍,然而其原因却不在距离计算上,因为HNSW没有批量距离计算的操作。
通过如下分析,可以看到PASE在内存访问上显著慢于FAISS。其原因在于PASE的内存管理方式仍然是基于磁盘页的缓存池。每次随机读取需要通过读整个页进行缓存,然后取出tuple。这对随机访问来说很不友好,造成了性能下降。
索引内存大小
在IVF-Flat和IVF-PQ方面,PASE和FAISS索引大小基本一致,但在HNSW上,又出现了数倍的差距。
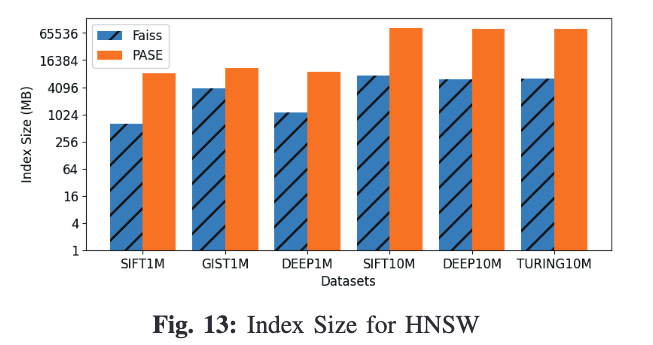
经过分析,原因为如下两点:
PASE要求每个邻接表对页对齐,一个页8KB,然而邻接表通常不到2KB,留下了大量的内存空白。 由于页结构,PASE中表示一个向量的位置,id,需要多个指针。在FAISS中一个4字节的id在PASE中需要24字节。
索引查询性能
1. IVF-FLAT
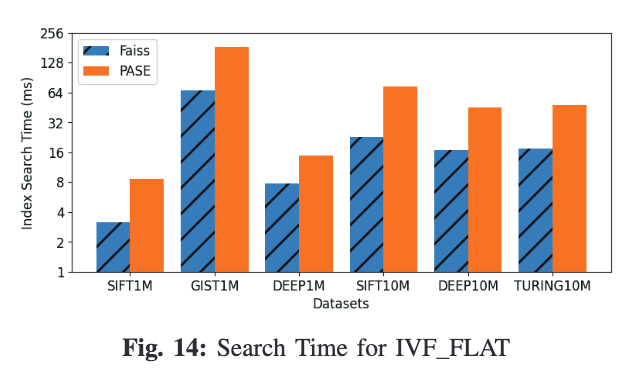
根据论文的检查,发现原因在于以下三点:
PASE的k-means算法质量比FAISS要差,聚类中心不一样; PASE的访存时延比FAISS要高。注意在查询时,不再会以顺序访问为主。 对于堆的使用,PASE的堆大小设置的远比k要大,在实现上有缺陷。
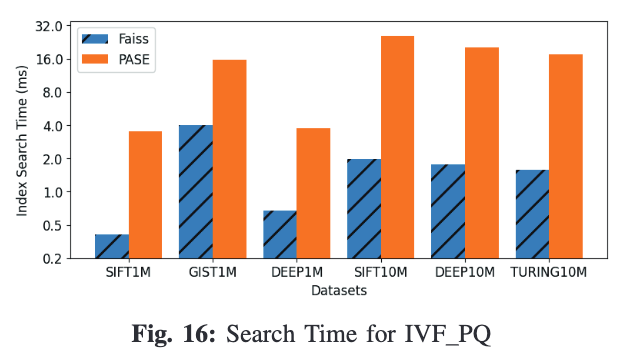
2. IVF_PQ
和IVF-Flat一样,PASE的IVF_PQ性能也要比FAISS慢几倍。主要原因除了以上三点以外,还有一个是关于查询时查找表的计算优化。PASE采用暴力算法,而FAISS再次使用了距离分裂的方法变欧氏距离为内积距离。
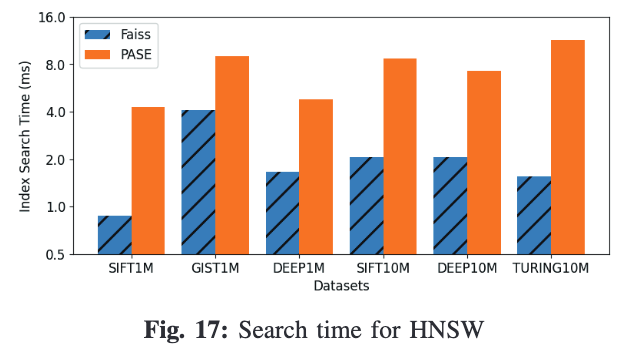
3. HNSW
在HNSW查询上,性能差距会更大。其主要原因仍然是内存排布与访存延迟的问题。
精彩段落


<<< 左右滑动见更多 >>>
总结与思考
本文通过细粒度的性能分析比较了关系型数据库和向量数据库对于向量搜索性能差距的原因。结果发现主要是工程实现导致了性能的差距,尤其是RDBMS中基于页的内存访问,给内存索引带来了不少障碍。这些结论意味着RDBMS的向量搜索性能将通过不断迭代优化逐步追上向量数据库。
延伸阅读
[1] VLDBJ'24:向量数据库技术综述 Survey of vector database management systems (https://arxiv.org/pdf/2310.14021)
[2] SIGMOD'20: PostgreSQL向量插件PASE PASE: PostgreSQL Ultra-High-Dimensional Approximate Nearest Neighbor Search Extension (https://dl.acm.org/doi/pdf/10.1145/3318464.3386131)
编者简介

个人主页:https://zeyuwang.top/
谷歌学术:https://scholar.google.com.hk/citations?hl=zh-CN&user=XXGhABIAAAAJ

