





01
—
分桶与分区的区别
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区,特别是要确定合适的划分大小这个疑虑。分桶是将数据集分解成更容易管理的若干部分的另一个技术。

02
—
分桶及抽样查询
(1)分桶规则
分桶规则:对分桶字段值进行哈希,哈希值除以桶的个数求余,余数决定了该条记录在哪个桶中,也就是余数相同的在一个桶中。
类似于MR中的HashPartitioner的分区规则:
MR中:按照key的hash值去模除以reductTask的个数
Hive中:按照分桶字段的hash值去模除以分桶的个数
(2)分桶的优势
优点:1)提高join查询效率
2)提高抽样效率.
提高join的查询效率
桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
提高 抽样效率
使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
(3) 建表
通过 clustered by(字段名) into bucket_num buckets 分桶,意思是根据字段名分成bucket_num个桶。drop table test_bucket;create table test_bucket (id int comment 'ID',name string comment '名字')comment '测试分桶'clustered by(id) into 4 bucketsROW FORMAT DELIMITED FIELDS TERMINATED BY ','location '/apps/hive/warehouse/dan_test.db/test_bucket';
① 数据准备
1,name12,name23,name34,name45,name56,name67,name78,name89,name9
load data local inpath '/root/dkl/data/buckt_data.txt' into table test_bucket;
需要借助中间表
drop table test;create table test (id int comment 'ID',name string comment '名字')comment '测试分桶中间表'ROW FORMAT DELIMITED FIELDS TERMINATED BY ','location '/apps/hive/warehouse/dan_test.db/test';
先将数据load到中间表
load data local inpath '/home/centos/dan_test/buckt_data.txt' into table dan_test.test;
然后通过下面的语句,将中间表的数据插入到分桶表中,这样会产生四个文件。
insert into test_bucket select * from test;
HDFS:桶是以文件的形式存在的,而不是像分区那样以文件夹的形式存在。
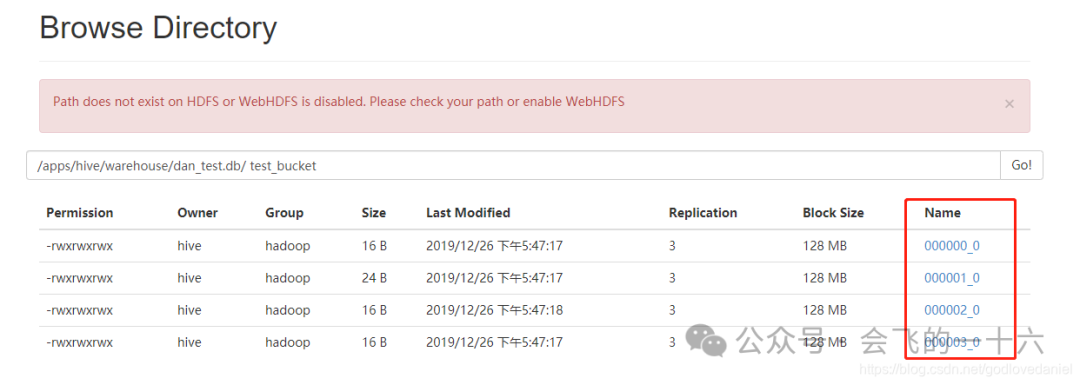
⑤ 看一下每个文件下存放的都是什么数据
hadoop fs -ls apps/hive/warehouse/dan_test.db/


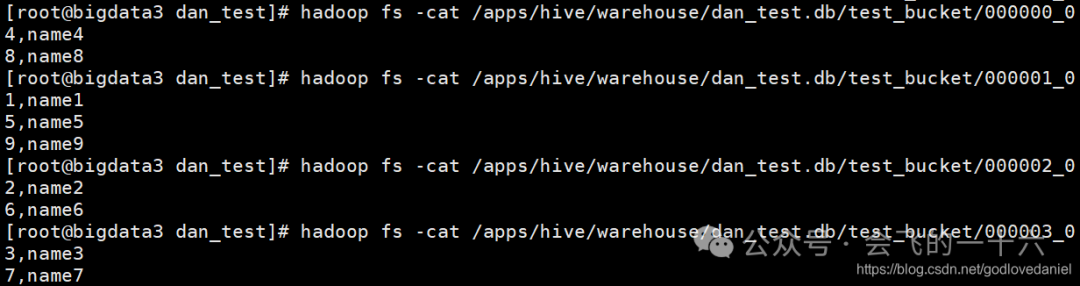
可以看到除以4余数相同的确实在一个文件里,也就是在一个桶中。
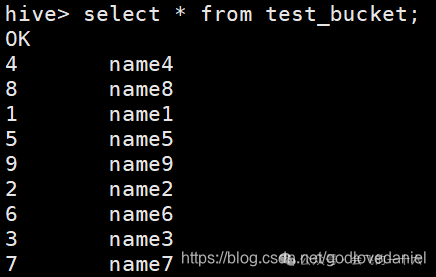
注意:我们用sql语句查出来的顺序和文件存放的顺序是一致的。偶数在前为什么?

这样会再产生新的四个文件
insert into test_bucket select * from test;
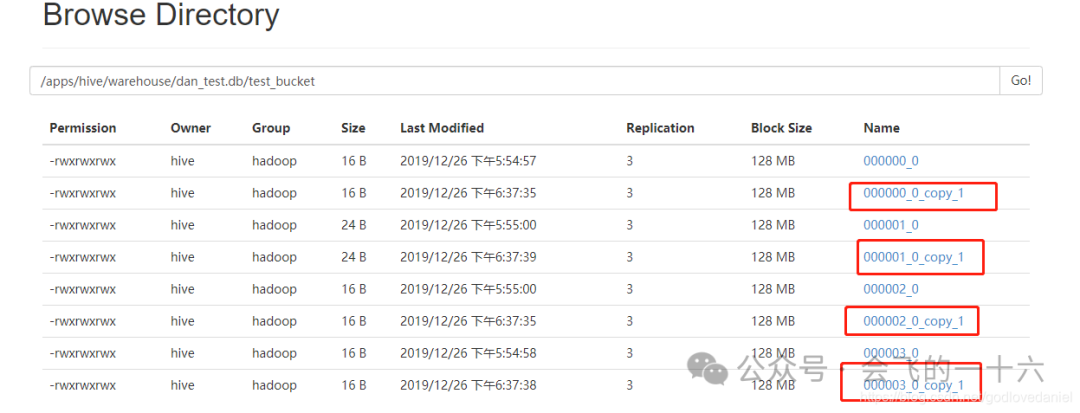
(3) 分桶排序
5,name52,name27,name73,name38,name84,name46,name61,name19,name9
删除表数据
truncate table test_bucket;truncate table test;
重新按上面讲的,导入打乱的数据。
load data local inpath '/home/centos/dan_test/buckt_data2.txt' into table test;insert into test_bucket select * from test;
确实没有排序(默认按文件里的顺序)
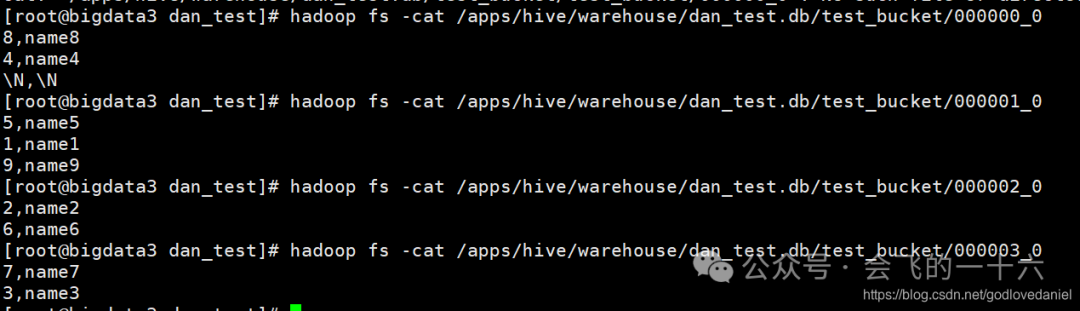
① 建表
create table test_bucket_sorted (id int comment 'ID',name string comment '名字')comment '测试分桶'clustered by(id) sorted by (id) into 4 bucketsROW FORMAT DELIMITED FIELDS TERMINATED BY ','location '/apps/hive/warehouse/dan_test.db/test_bucket_sorted';
②插入数据
insert into test_bucket_sorted select * from test;
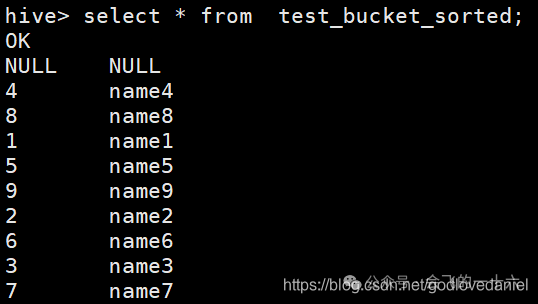
用sql看和用hadoop命令看每个文件,结果每个桶内都是按id升序排序的,也就是和最开始的截图是一样的。
(4)提高join查询效率
假设表A和表B进行join,join的字段为id
条件:
1、两个表为大表
2、两个表都为分桶表
3、A表的桶数是B表桶数的倍数或因子
这样join查询时候,表A的每个桶就可以和表B对应的桶直接join,而不用全表join,提高查询效率
比如A表桶数为4,B表桶数为8,那么桶数对应关系为
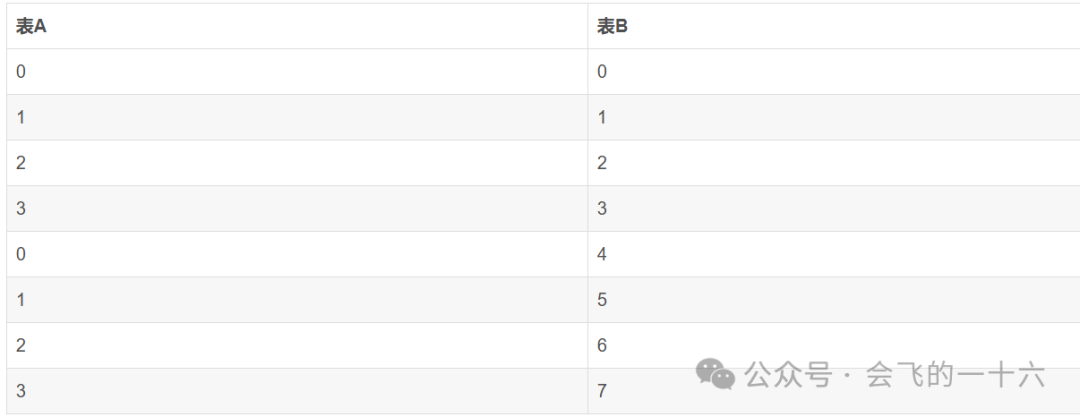
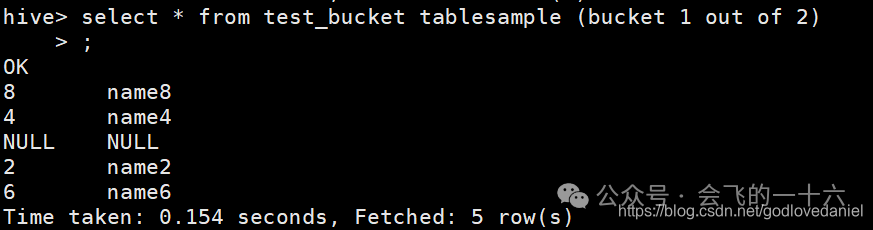
(5)提高抽样效率
hive> select * from test_bucket tablesample (bucket 1 out of 2);OK8 name84 name42 name26 name6
hive> select * from test tablesample (bucket 1 out of 2 on id);OK2 name28 name84 name46 name6
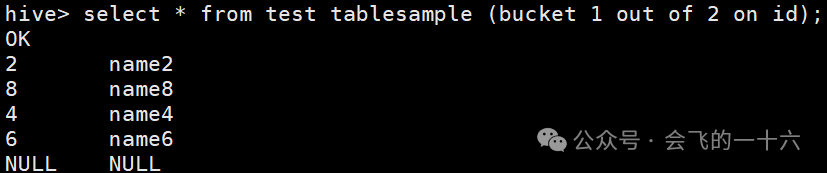
分桶表后面可以不带on 字段名,不带时默认的是按分桶字段,也可以带,而没有分桶的表则必须带。
tablesample (bucket x out of y on id);
x表示从哪个桶(x-1)开始,y代表分几个桶,也可以理解分x为分子,y为分母,及将表分为y份(桶),取第x份(桶)
所以这时对于分桶表是有要求的,y为桶数的倍数或因子,
x=1,y=2,取2(4/y)个bucket的数据,分别桶0(x-1)和桶2(0+y)
x=1,y=4, 取1(4/y)个bucket的数据,即桶0
x=2,y=8, 取1/2(4/y)个bucket的数据,即桶0的一半
x的范围:[1,y]
03
—
小结
本文围绕hive中分桶问题进行展开研究,分析了hive分桶与分区的区别,分桶的相关原理、分桶的优势,并对分桶的操作方法进行详细论述,给出了具体的操作步骤及案例,本文所有的操作案例均在机器上得到验证,读者可根据本文所提供的思路快速学习到hive分桶的相关知识。
(1)hive分桶与分区的区别
(2)hive分桶的相关规则及原理
(3)hive分桶的应用场景及优势
(4)hive分桶的相关操作
(5)hive分桶join案例及抽样查询案例
往期精彩
一种基于滑动平均的时间序列滤波方法 | Hive UDF 实现
Hive 利用Distribute by 解决动态分区小文件过多问题 | 小文件优化
万字详解Spark并行度 | 从spark.default.parallelism参数来看Spark并行度、并行计算任务概念
