





01
—
问题描述
假设表A 为事件流水表,客户当天有一条记录则视为当天活跃。
表A:
time_id user_id2018-01-01 10:00:00 0012018-01-01 11:03:00 0022018-01-01 13:18:00 0012018-01-02 08:34:00 0042018-01-02 10:08:00 0022018-01-02 10:40:00 0032018-01-02 14:21:00 0022018-01-02 15:39:00 0042018-01-03 08:34:00 0052018-01-03 10:08:00 0032018-01-03 10:40:00 0012018-01-03 14:21:00 005
假设客户活跃非常,一天产生的事件记录平均达千条。
问题:累计去重
输出结果如下所示:
日期当日活跃人数,月累计活跃人数_截至当日
date_id user_cnt_act user_cnt_act_month2018-01-01 2 22018-01-02 3 42018-01-03 3 5
02
—
数据准备
create table t3 asselect '2018-01-01 10:00:00' as time_id,'001' as user_idUNION ALLselect '2018-01-01 11:03:00' as time_id,'002' as user_idUNION ALLselect '2018-01-01 13:18:00' as time_id,'001' as user_idUNION ALLselect '2018-01-02 08:34:00' as time_id,'004' as user_idUNION ALLselect '2018-01-02 10:08:00' as time_id,'002' as user_idUNION ALLselect '2018-01-02 10:40:00' as time_id,'003' as user_idUNION ALLselect '2018-01-02 14:21:00' as time_id,'002' as user_idUNION ALLselect '2018-01-02 15:39:00' as time_id,'004' as user_idUNION ALLselect '2018-01-03 08:34:00' as time_id,'005' as user_idUNION ALLselect '2018-01-03 10:08:00' as time_id,'003' as user_idUNION ALLselect '2018-01-03 10:40:00' as time_id,'001' as user_idUNION ALLselect '2018-01-03 14:21:00' as time_id,'005' as user_id

03
—
问题分析
select substr(time_id,1,10) as date_id,user_idfrom t3group by substr(time_id,1,10),user_id
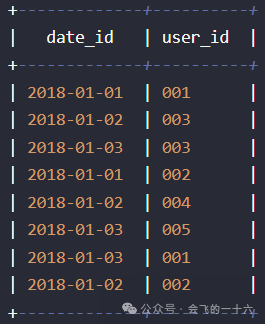
第二步:基于上述表利用开窗求出对应的指标
select date_id,user_id,count(user_id) over(partition by date_id) as user_cnt_act--注意求月的累计值时需要对用户去重,count(distinct user_id) over(partition by substr(date_id,1,7) order by date_id) as user_cnt_act_monthfrom(select substr(time_id,1,10) as date_id,user_idfrom t3group by substr(time_id,1,10),user_id) t
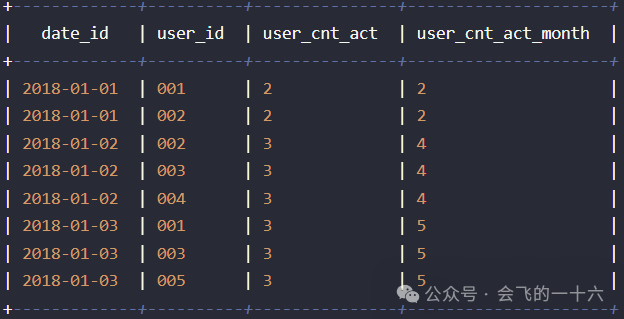
第三步:按天进行聚合去重。由于开窗会按照窗口内每条数据都会生成一个标签值,会根据窗口内数据进行膨胀,因此需要去重。最终SQL如下
select date_id,max(user_cnt_act),max(user_cnt_act_month)from(select date_id,user_id,count(user_id) over(partition by date_id) as user_cnt_act,count(distinct user_id) over(partition by substr(date_id,1,7) order by date_id) as user_cnt_act_monthfrom(select substr(time_id,1,10) as date_id,user_idfrom t3group by substr(time_id,1,10),user_id) t) tgroup by date_id
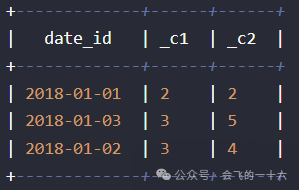
或SQL如下:
select date_id,max(user_cnt_act),max(user_cnt_act_month)from(select substr(time_id,1,10) as date_id,user_id,count(distinct user_id) over(partition by substr(time_id,1,10)) as user_cnt_act,count(distinct user_id) over(partition by substr(time_id,1,7) order by substr(time_id,1,10)) as user_cnt_act_monthfrom t3) tgroup by date_id
关于hive 低版本不支持count(distinct XX) over()的说明,官网说法如下:
Distinct support in Hive 2.1.0 and later (see HIVE-9534)Distinct is supported for aggregation functions including SUM, COUNT and AVG, which aggregate over the distinct values within each partition. Current implementation has the limitation that no ORDER BY or window specification can be supported in the partitioning clause for performance reason. The supported syntax is as follows.COUNT(DISTINCT a) OVER (PARTITION BY c)ORDER BY and window specification is supported for distinct in Hive 2.2.0 (see HIVE-13453). An example is as follows.COUNT(DISTINCT a) OVER (PARTITION BY c ORDER BY d ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
hive2.1之后支持partition by语句
COUNT(DISTINCT a) OVER (PARTITION BY c)
hive2.2之后支持order by 语句
COUNT(DISTINCT a) OVER (PARTITION BY c ORDER BY d ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
如果目前hive版本不支持这样的语法,尝试用collect_set()函数去重,利用size()函数求其个数,具体SQL如下:
select dt, s1, s2from (select dt,size(collect_set(user_id) over (partition by dt)) as s1,size(collect_set(user_id) over (partition by date_format(dt, 'yyyy-MM') order by dt)) as s2from (select to_date(time_id) as dt, user_idfrom t3group by to_date(time_id), user_id) t1) t2group by dt, s1, s2
04
—
小结
本文介绍如何使用HiveSQL处理多指标累计去重问题,通过实例展示了利用窗口函数解决此类需求的步骤,包括按天去重、开窗计算累计值,并讨论了不同Hive版本对window函数的支持情况。

往期精彩
SQL进阶技巧:如何查询最近一笔有效订单?| 近距离有效匹配问题
解锁SQL无限可能 | 如何利用SQL求解力扣难题接雨水问题?
文章转载自会飞的一十六,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
