




点击上方蓝字关注我们

为促进团队内外的沟通联系,我们Klustron团队的bbs论坛开始上线,欢迎各位同学使用!(链接:https://forum.klustron.com/,或者点击文末“阅读原文”,即可跳转)
点击上方蓝字关注我们
为促进团队内外的沟通联系,我们Klustron团队的bbs论坛开始上线,欢迎各位同学使用!(链接:https://forum.klustron.com/,或者点击文末“阅读原文”,即可跳转)



主节点事务组提交的性能瓶颈。 所有同时并发提交的事务的线程阻塞; 由一个线程依次append每个事务的私有缓存中已写好的Binlog事件到Binlog文件; 实测表明:如果关掉Binlog,性能可以翻倍。 主备延迟:使得主节点宕机后无主可用。 典型成因:表无主键和唯一索引,后来hash机制略改进; 典型成因:同一个事务中大批量插入、更新、删除; 典型成因:主节点上并发度不够且备机后期加入;大事务(2次IO,写完才发)。 恢复时耗大:存储引擎恢复,然后MySQL server层Binlog recovery

表必须有主键或者唯一索引,用于hash后作为id来标识行; 事务运行期间收集增删改的行id的集合; 事务提交前先发送增删改的id集合到其他节点,并且检查冲突; 如有并发提交的冲突事务,则回滚事务,浪费计算开销。 无冲突则 通过raft协议分发事务的Binlog; 性能开销显著:大量同时提交的事务排队等待; 持锁完成上述操作,导致大量并发运行中的冲突事务阻塞。

两个存储节点都有其buffer pool 和redo log,共享存储,类似Oracle RAC架构; 并发控制; 页上事务行锁做增删改的并发控制; 基于MVCC做select并发控制; 避免了事务提交时冲突检测的巨大性能损失; 事务运行期写redo log, 并行提交,无需排队; 解决了MySQL innodb在同一个事务中 select -> update 的一致性问题。 按页hash分配到参天节点,两节点都可更新; crash recovery: 两节点同时并行恢复; 对表无PK,UK要求,避免提交时的事务排队的性能瓶颈和长时间持锁阻塞大量冲突事务; 可以合并连接点的更新操作产生Binlog,供MySQL Binlog生态工具使用。

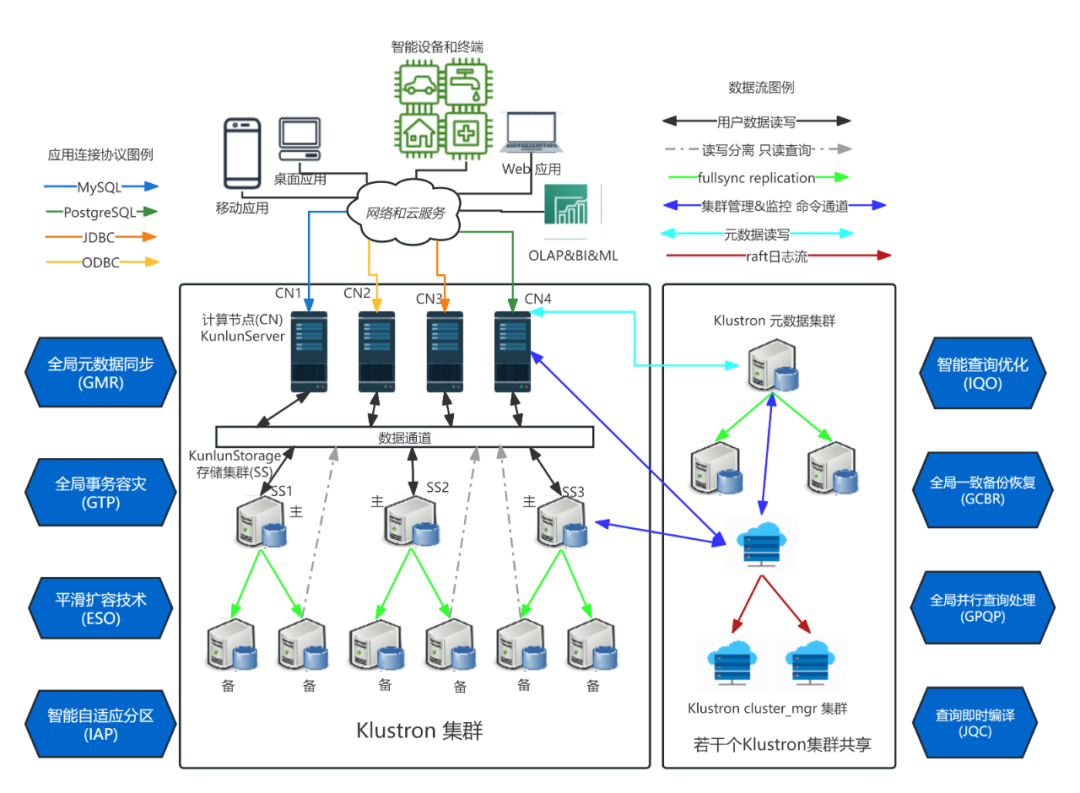
计算层(Klustron-server):多个PostgreSQL实例构成的计算节点负责接受验证应用软件端的连接请求,以及从已经建立的连接中接受SQL查询请求,执行请求,然后返回查询结果; 存储层(Klustron-storage): 三个或者更多个MySQL8.0实例构成的存储节点组成一个存储集群(storage shard,简称shard),每个shard 存储着一部分用户表或者表分区; 元数据集群存储着Klustron 集群的元数据包括拓扑结构、节点连接信息、DDL日志,commit log,和其他集群管理日志等; cluster_mgr集群负责维护正确的集群和节点状态,实现集群管理、集群逻辑备份和恢复, 集群物理备份和恢复、水平弹性伸缩等功能。
采用全局分布式缓存技术保证跨节点数据一致性,实现多读多写集群; 分布式MVCC技术,极大提升MVCC事务提交性能; 采用多活集群高可用技术,实现节点故障快速切换。
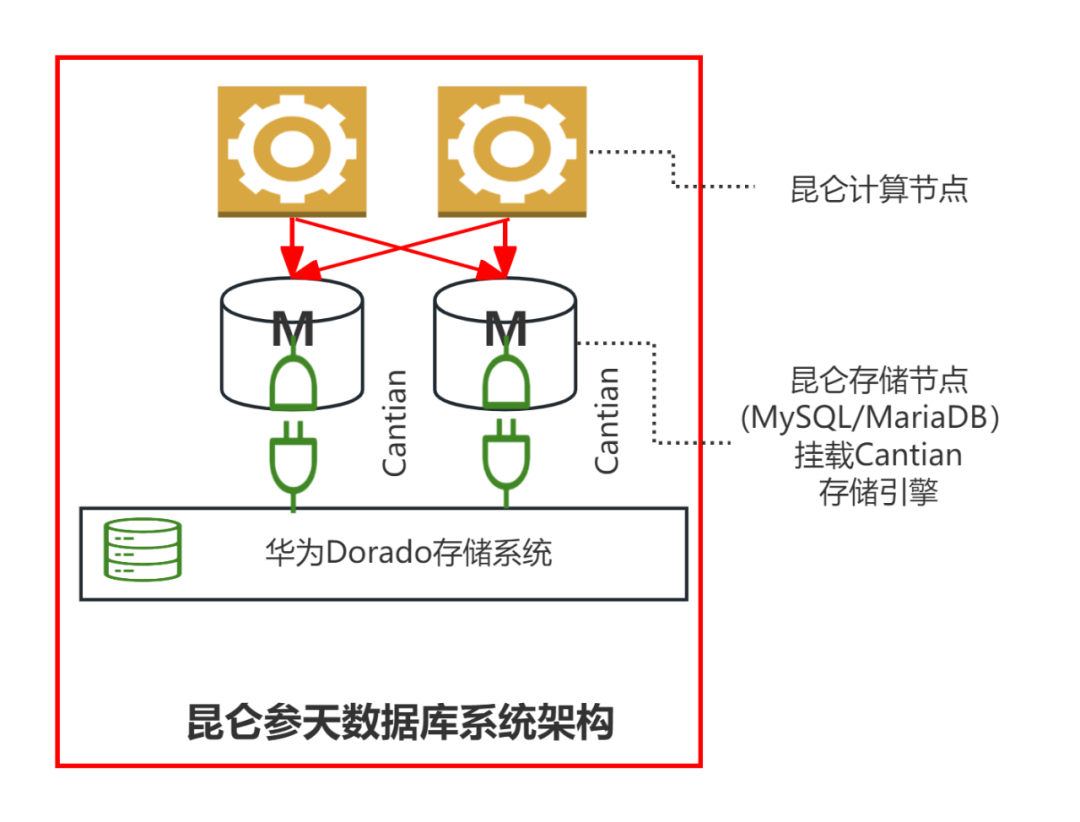
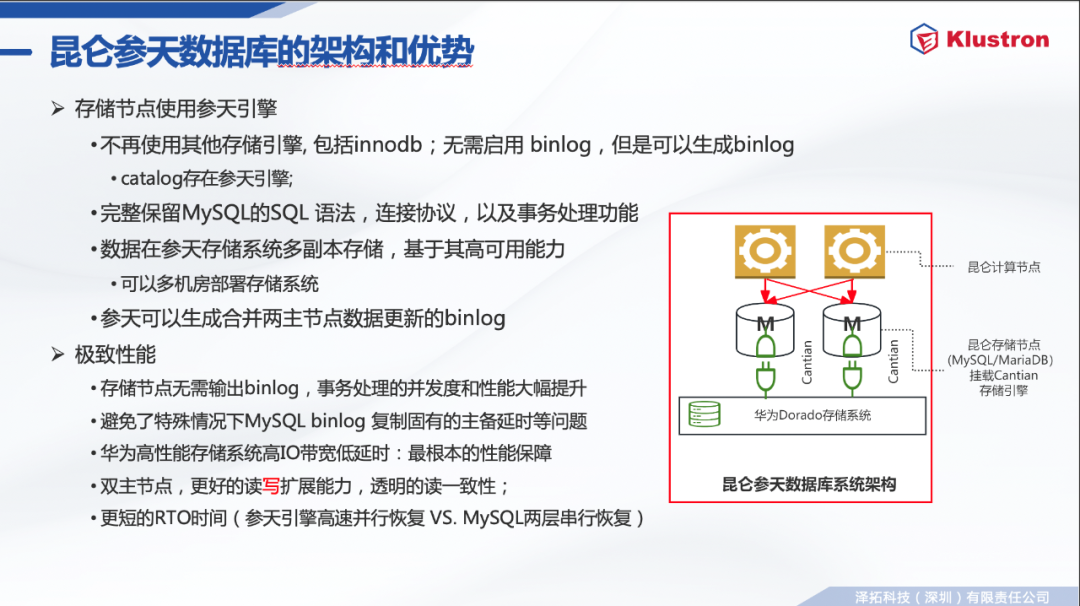
昆仑参天数据库的存储节点使用参天引擎。 不再使用其他存储引擎, 包括innodb;无需启用Binlog,但是可以生成Binlog; catalog存在参天引擎; 完整保留MySQL的SQL 语法,连接协议,以及事务处理功能; 数据在参天存储系统多副本存储,基于其高可用能力,可以多机房部署存储系统; 参天可以生成合并两主节点数据更新的Binlog。 极致性能。 存储节点无需输出Binlog,事务处理的并发度和性能大幅提升; 避免了特殊情况下MySQL Binlog复制固有的主备延时等问题; 华为高性能存储系统高IO带宽低延时:最根本的性能保障; 双主节点,更好的读写扩展能力,透明的读一致性; 更短的RTO时间(参天引擎高速并行恢复 VS. MySQL两层串行恢复)
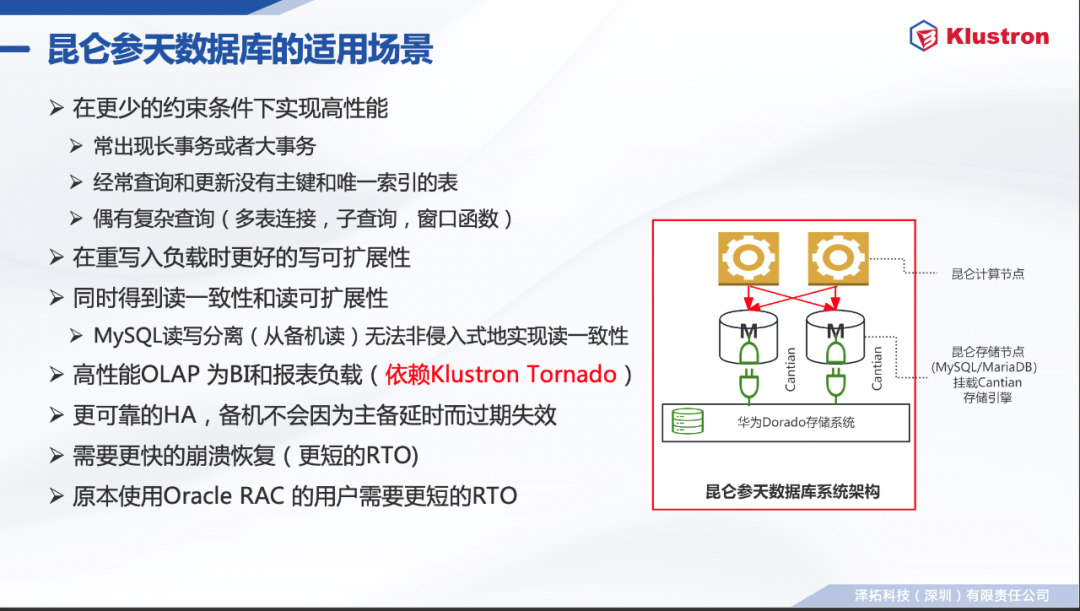
在更少的约束条件下实现高性能。
常出现长事务或者大事务;
经常查询和更新没有主键和唯一索引的表;
偶有复杂查询(多表连接,子查询,窗口函数)。
在重写入负载时更好的写可扩展性。
同时得到读一致性和读可扩展性。
MySQL读写分离(从备机读)无法非侵入式地实现读一致性。
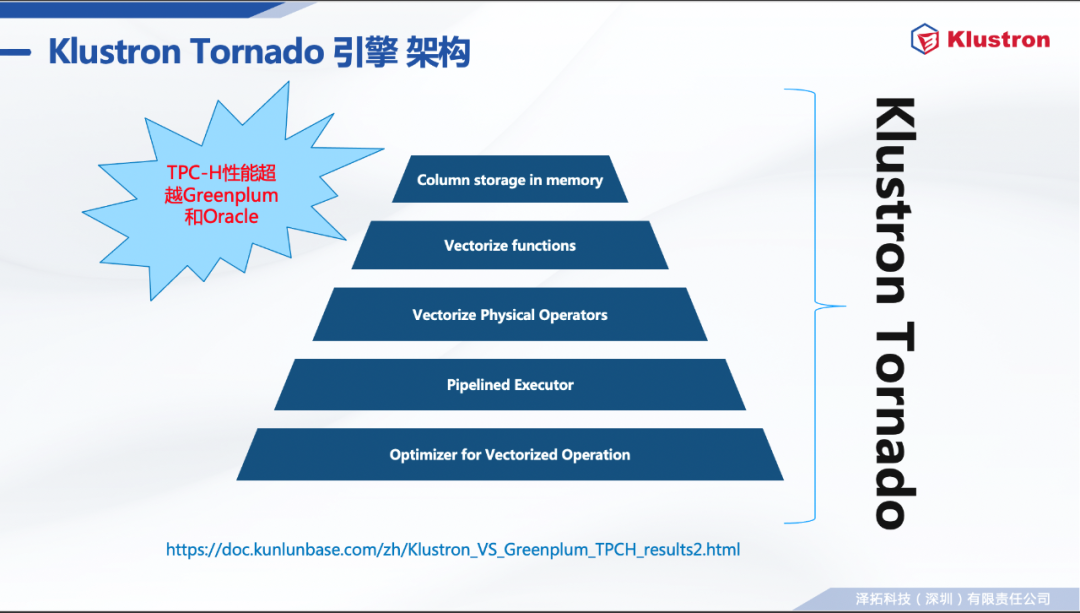
高性能OLAP 为BI和报表负载(依赖Klustron Tornado)。
更可靠的HA,备机不会因为主备延时而过期失效。
需要更快的崩溃恢复(更短的RTO)。
原本使用Oracle RAC 的用户需要更短的RTO。
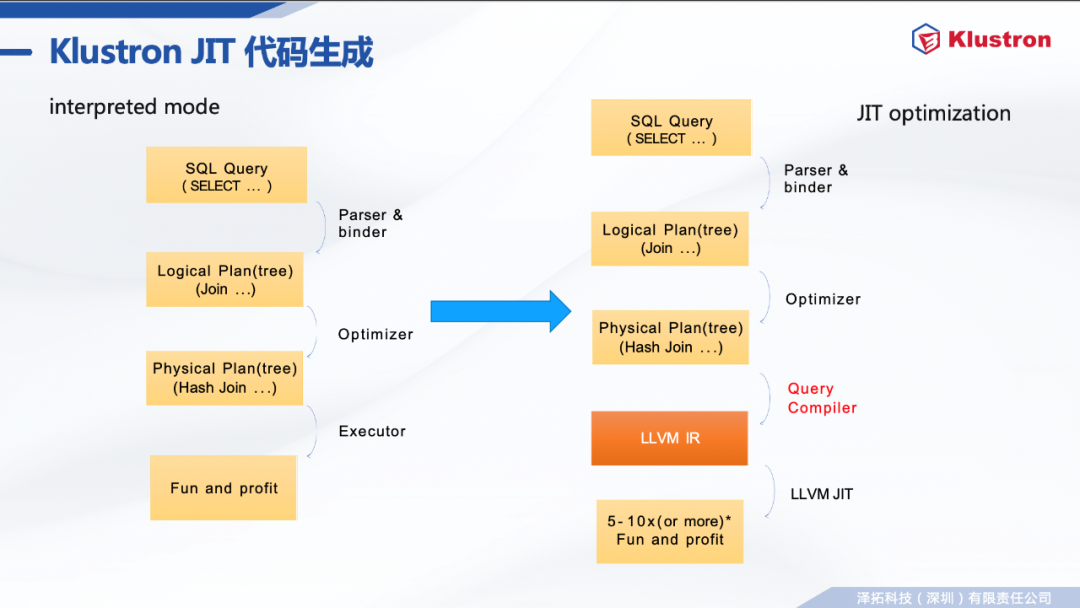
完整保留Klustron的强大功能和生态兼容能力。 Klustron-server的生态兼容能力,充分利用PostgreSQL社区技术资源; 支持JSON,向量(pgvector) 数据管理; 支持PostgreSQL和MySQL双协议双语法; 支持机器学习(PostgresML, python 存储过程 with ML libs); 各类FDW访问各类外部数据源(对象存储,数据库); 高级SQL功能(MySQL不具备第2,3条); 存储过程,触发器,[物化]视图,CTE; 多层级细粒度的访问控制,数据validation&约束; OLAP相关查询功能(window function, grouping-sets, cube, roll-up, etc)。 Klustron-server的高性能分布式查询处理技术体系。 充分发挥硬件性能。

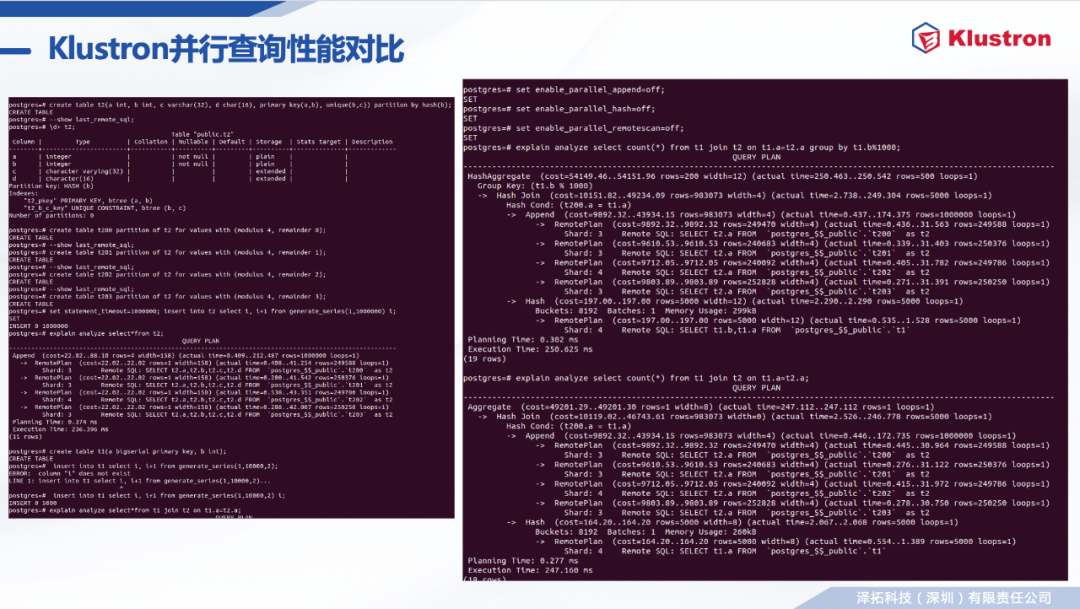
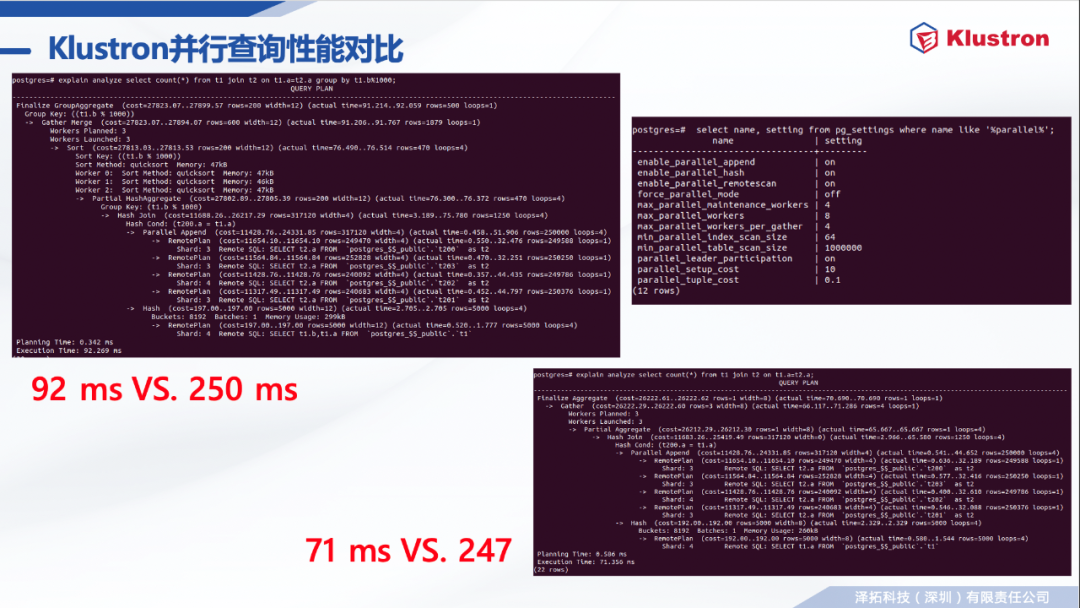
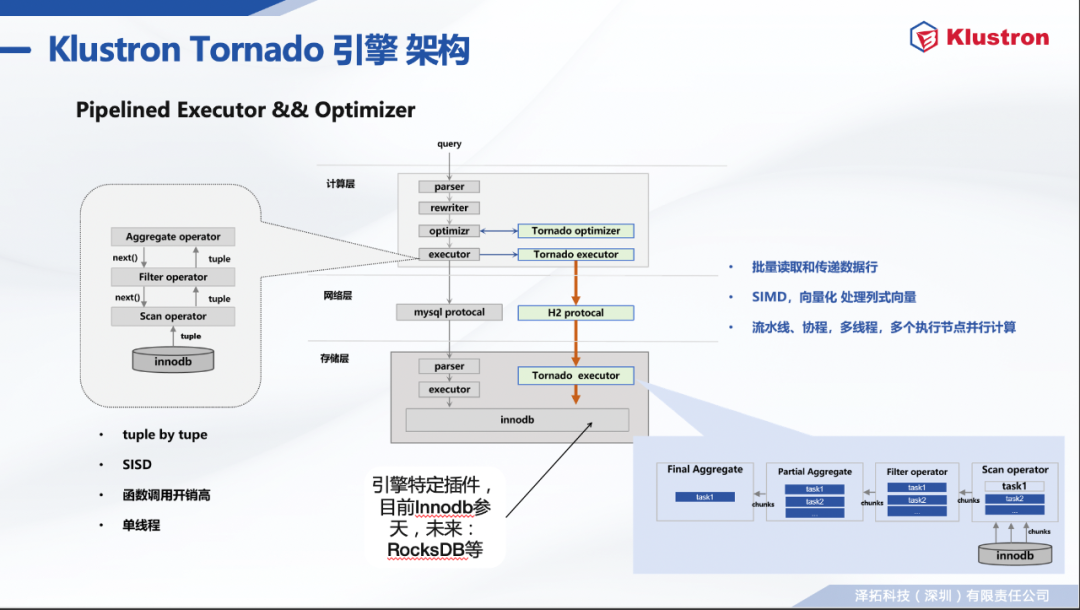
计算节点内 --- 继承自PostgreSQL 并行查询架构。 多进程架构(leader,worker)和 Gather机制; Parallel Append, Parallel Aggregate, Parallel Join; Remote Plan; 计算节点内的并行完全使用原有并行查询框架。
计算节点和存储节点之间的并行查询能力 -- Klustron 全新设计和开发。 可独立于计算节点的并行查询框架工作,也可与之协作; Parallel Remote Scan: 多进程划分和并行执行Remote Scan子任务; 利用多个备机提升只读查询的扩展性; 降低查询开销; 存储节点的支持功能 -- Klustron 全新设计和开发; 多个后端连接(线程)中执行同一个客户端连接的查询子任务; 事务快照共享技术 。

计算节点与存储节点之间异步通信。 在多个连接异步发送SQL语句,不阻塞等待查询结果; 可以用于驱动多个shard并行执行写入命令(update, delete, insert); 可用于单个或者多个节点并行执行只读查询(select)。 异步发出remote plan SQL语句。 支持的plan节点: MergeAppend,Append,ModifyTable; 都发出后再统一等待收集remote plan查询结果; Parallel Remote Scan: 只读查询任务分解和多线程执行; 把remote scan任务划分为多个子任务,每个子任务返回一个子结果集 使用主键或者唯一索引的做range切分; 在多个连接中分别异步发送,以便存储节点并行执行; 多个worker进程可以各自独立分解任务、发送任务、收集和汇总子结果; Klustron 1.2 及以上版本支持。

读写分离,多个备机执行SELECT。 避免影响主节点性能; 在同一个shard的多个备机中实现并行。
计算节点和存储节点之间使用Prepared statements。 适用于客户端发送prepared statements 或者plain text statements; 避免存储节点重复解析和优化查询子任务; 优化 LIMIT ... OFFSET 性能:使用fetch(N)增量流式拉取查询结果。 中途停止避免无谓的查询执行和结果传输; 避免读写临时表引起IO负载暴增。
Kunlun-storage的支持功能。 多个后端连接共用同一个快照(snapshot); 多个线程并行执行多个查询子任务,确保查询结果在同一个节点内的一致性。 使用服务器端只读游标来获取结果; 避免计算节点物化(materialize) 查询结果到临时表; 避免缓存查询结果到存储节点的临时表; fetch之间可以执行其他查询或者其他prepared statement的fetch。


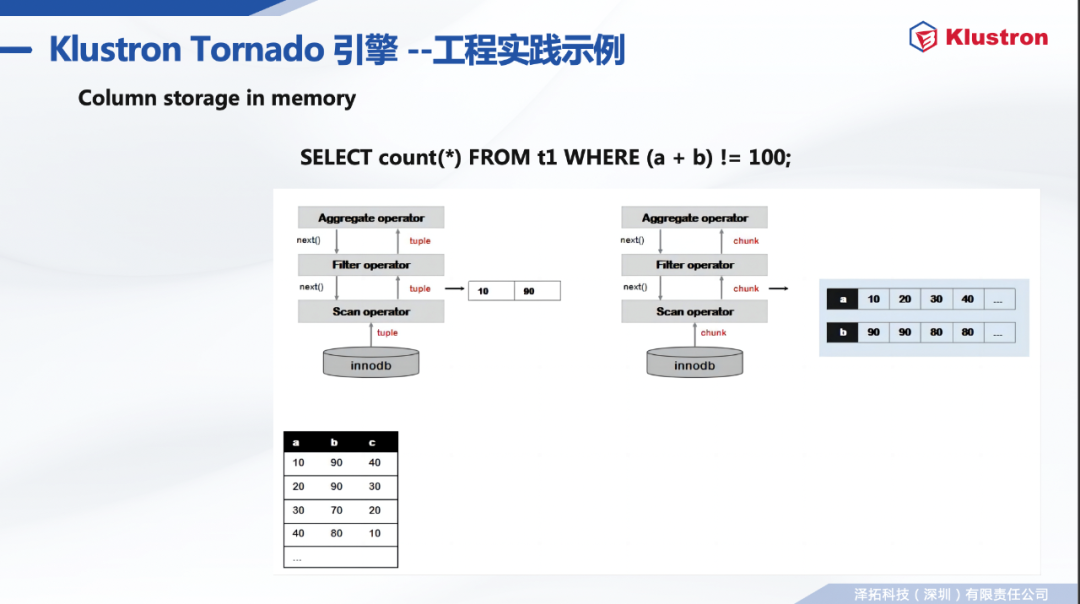
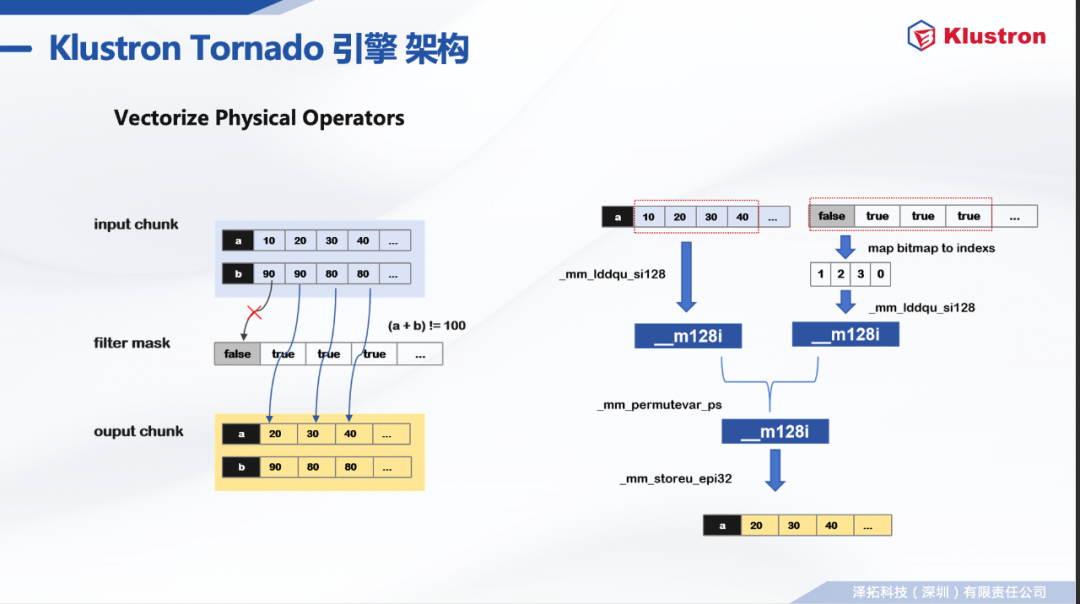
int, bigint, float, double, decimal date, time, datetime, timestamp varchar
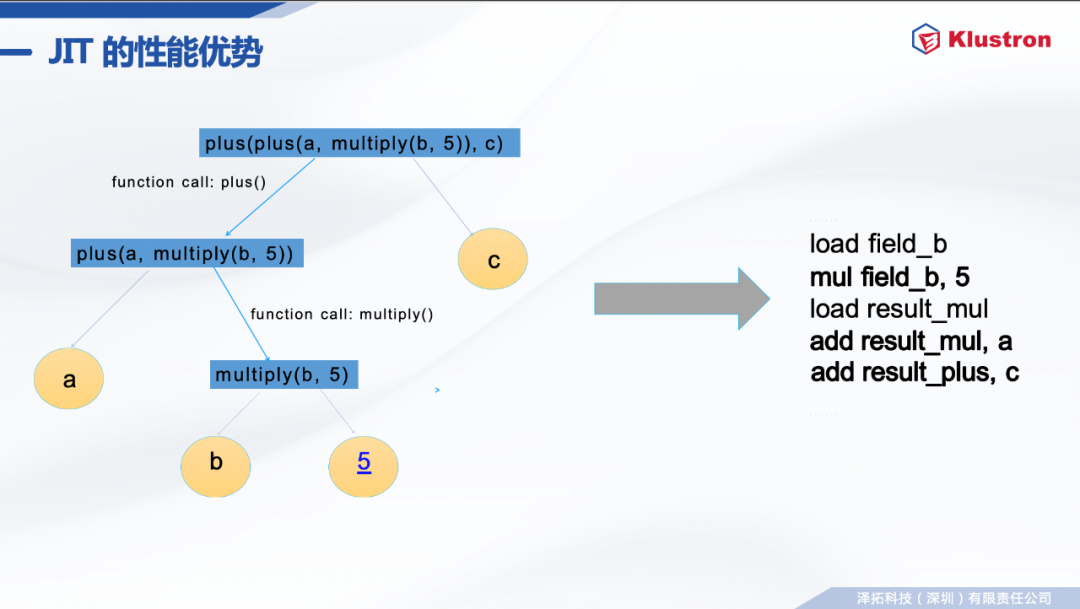
binary algebras:Plus , Minus , Multiply , Div binary comparators:GT , GE , LT , LE , EQ , NE, like logical operators:And , Or , Not unary operators:Abs others:Between . . .and , interval

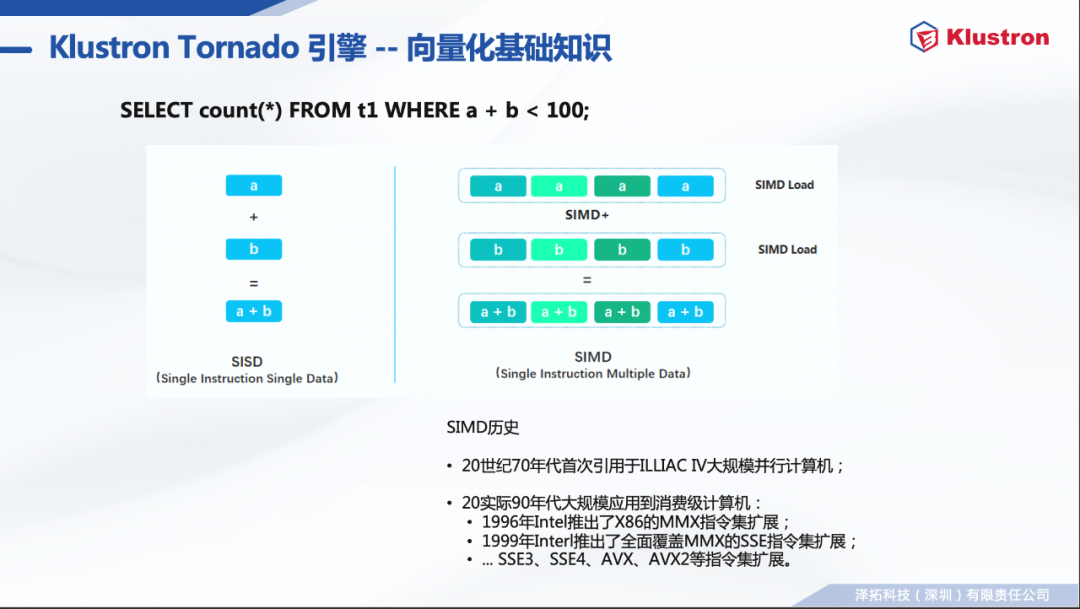
20世纪70年代首次引用于ILLIAC IV大规模并行计算机; 20实际90年代大规模应用到消费级计算机: 1996年Intel推出了X86的MMX指令集扩展; 1999年Interl推出了全面覆盖MMX的SSE指令集扩展; ... SSE3、SSE4、AVX、AVX2等指令集扩展。





文章转载自KunlunBase 昆仑数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
