




 点击上方蓝字关注我 ⬆️ 解锁更多 AI 干货知识
点击上方蓝字关注我 ⬆️ 解锁更多 AI 干货知识 
本文正文字数约 3600 字,阅读时间 8 分钟。
在 RAG 入门指南:从零开始构建一个 RAG 系统中我们就有提到,真实环境下的 RAG 应用会涉及到使用向量数据库来存储向量嵌入。
同时,在 谈一谈向量嵌入(Vector Embeddings)中,我也为你详细介绍了有关于向量嵌入这个概念。
那么现在,我们就需要来详细了解一下向量数据库了:向量数据库是什么?它与普通的数据库有什么区别,它有哪些应用场景...
这些问题,在本文中我将会为你一一解答。
本文将会为你详细介绍向量数据库,我们会涵盖以下这些话题:
• 向量数据库简介
• 向量数据库的工作机制
• 向量数据库的应用
• 主流向量数据库
向量数据库简介
向量数据库(Vector Database)是一种专门用于存储和检索向量嵌入的数据库。
关于什么是向量嵌入(Vector Embeddings),可以参考阅读:谈一谈向量嵌入(Vector Embeddings)
向量数据库用于存储非结构化数据,它通过向量嵌入的方式来表示数据,通过向量相似性搜索等算法来进行索引和查询。
向量数据库提供的搜索功能可以应用于多种场景,比如推荐系统、为 AI 模型提供长期记忆、视频摘要、股票市场分析等。
与传统数据库的区别
向量数据库与传统的数据库在处理向量嵌入的复杂性和规模方面有明显差异。
与传统的关系型数据库或者 NoSQL 数据库不同,传统数据库可能难以提取深层见解并进行实时分析,而向量数据库则专为处理这类数据设计,也就是我们一直在提到的向量嵌入,它能够确保更高的性能、可扩展性和灵活性。
这种独特的设计让向量数据库在处理此类数据的时候有明显的优势,比如能够进行相似性搜索,在用户的提示语与特定向量嵌入之间找到最佳匹配。
这个功能在部署模型的时候非常有用,向量数据库可以存储几十亿个代表广泛训练数据的向量嵌入。
所谓关系型数据库(Relational Database),其实就是一种以表格形式组织数据的数据库,数据通过行和列的方式存储。它依赖于结构化查询语言(SQL)来管理和查询数据,强调数据的结构化和一致性,通常使用主键和外键来建立表与表之间的关系。常见的关系型数据库有 MySQL、PostgreSQL 和 Oracle。
而 NoSQL 数据库则是一类非关系型数据库,用于处理大量的非结构化或半结构化数据。它不使用固定的表格结构,适合分布式数据存储和高并发场景。NoSQL 数据库类型多样,包括键值存储(如 Redis)、文档存储(如 MongoDB)、列存储(如 Cassandra)和图数据库(如 Neo4j)。
向量数据库的工作机制
为了能够更好地理解向量数据库,我们需要了解它的工作机制。
向量数据库专门处理高维向量数据,特别适合管理和搜索大量的非结构化数据,这些数据通过向量嵌入转化为结构化格式。
向量数据库中包含三个核心元素:
• 非结构化数据(Unstructured Data)
• 向量嵌入(Vector Embeddings)
• 向量索引(Vector Indexing)
非结构化数据
非结构化数据是指不符合特定预定义的数据模型的信息,比如大量的文本类数据、电子邮件、视频等。
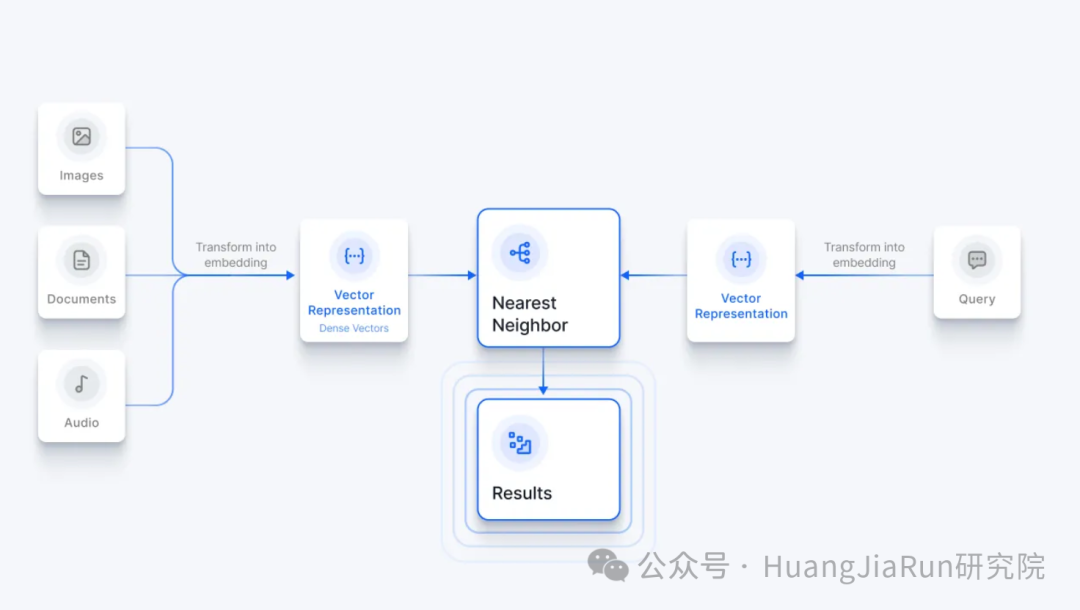
向量数据库通过使用向量嵌入将这些非结构化数据转换为结构化格式。
在转换过程中,使用 AI 模型来生成携带语义信息的嵌入,这些嵌入包含了多个维度,代表了不同的特征和属性。
以文章检索为例。
要在多篇文章中进行检索,那么在向量数据库中处理这些文章的时候,就会通过模型来处理这些文章并生成对应的向量嵌入。
每一篇文章都会被转换为一个在高维空间中捕捉其语义含义的向量。随后,这些向量会被存储到向量数据库中,将非结构化数据转变为结构化的表示。
当接收到用户的查询关键词的时候,模型会为这个关键词生成一个向量嵌入,而这个用来查询的向量嵌入会被用来在数据库中搜索相似的向量嵌入。
通过这种方式,系统就可以检索到与用户查询的关键词在语义上相关的文章。
向量数据库采用多种存储技术来应对高维数据的复杂性和数据量:
• 分片(Sharding):将数据划分为较小的可管理部分,分布在多个服务器上,这样可以提高性能和可扩展性。
• 分区(Partitioning):根据特定标准将数据拆分为独立部分。
• 缓存(Caching):将频繁访问的数据存储在内存中,加快检索速度。
• 复制(Replication):在不同服务器上创建数据副本,确保数据的可用性和可靠性。
向量嵌入
向量嵌入是将复杂的非结构化的数据(如文本、图像、音频等)转化为机器可理解的数值向量形式,让数据库可以高效地存储、处理和检索这些数据。
通过向量嵌入,向量数据库能够在高维空间中捕捉数据对象之间的关系和模式,为机器学习任务提供了结构化的数据表示,有助于模型在推理阶段对新数据进行有效处理。
另外,向量数据库还可以利用向量嵌入进行高效的检索和分析。这种转换不仅提高了数据的可操作性,还为数据的相似性搜索、聚类分析和分类等任务提供了基础。
向量索引
非结构化数据转换为向量嵌入之后,问题就在于如何能够更高效的存储这些嵌入,才能够达到快速检索的目的,这也就是向量索引的作用所在。
向量索引是向量数据库中用于高效存储和检索向量嵌入的核心技术。它的目的是在高维空间中组织这些向量以便于在执行相似性搜索时,可以快速找到与查询向量最接近的结果。
由于向量嵌入通常位于高维空间中,直接对所有向量进行暴力搜索(即逐一计算与用户的查询向量的距离)在大规模数据集上是非常耗时的。向量索引通过构建特定的数据结构,减少计算量,从而提高检索效率。
可以简单地理解为,向量索引就是为大量数据打标签或者标记,这样就可以快速地找到相似的数据。
在向量数据库中,向量嵌入相当于给每个数据对象生成了一个独特的特征标签(其实也是一个向量),向量索引的作用就是把这些向量用一种高效的方式组织起来,让系统在需要找相似对象时,能够更快、更准确地比较这些特征,从而更快速找到相似的结果。
相似性搜索
向量数据库中的相似性搜索是其核心操作之一,这个过程指的是在数据库中找到与给定向量最相似的向量。
相似性度量通常来说是基于距离来度量,比如欧几里得距离或者余弦相似度。
• 欧几里得距离:计算两个向量在多维空间中的直线距离。距离越小,表示两个向量越相似。
• 余弦相似度:计算两个向量之间的夹角余弦值,夹角越小,向量越相似。余弦相似度尤其适合用于高维空间的相似性搜索。
关于余弦相似度算法的实现,可以参考往期有关于 RAG 入门的文章:RAG 入门指南:从零开始构建一个 RAG 系统(2)
除了相似性搜索之外,向量数据库还有下面这些搜索方法:
• 语义搜索(Semantic Search):理解搜索查询的含义和上下文,根据数据的语义内容进行匹配。
• 最近邻搜索(NNS):在高维空间中查找离给定查询最近的数据点。
• 近似最近邻搜索(ANNS):使用算法快速找到近似的最近邻,用速度来换取一定的准确性。
向量数据库的应用
向量数据库在多种 AI 和机器学习应用中发挥着重要作用,包括:
• 自然语言处理(NLP):通过快速和准确的文本相似性搜索,提升搜索引擎、聊天机器人和语言翻译的性能。
• 计算机视觉:支持图像识别、人脸识别和目标检测,通过高效对比高维图像嵌入实现精确结果。
• 推荐系统:分析用户行为和偏好,提供个性化推荐。
• 大语言模型(LLMs):为 LLM 提供长期记忆,支持语义搜索,助力基于检索的文本生成。
• 内容审核:将新数据与已知示例数据库进行比较,自动检测以及过滤不当内容。
主流向量数据库

本章节将会为你推荐几个 2024 年最受欢迎的主流向量数据库。
Pinecone
https://www.pinecone.io/
概述:Pinecone 提供一个全托管的向量数据库服务,优化用于快速且可扩展的相似性搜索。它支持多种 AI 和机器学习应用,拥有强大的基础设施。
关键功能:高性能、与现有工作流的轻松集成、无缝扩展。
用户:Microsoft、Accenture、Notion、Hubspot、Shopify 等。
费用:有 Starter、Standard 以及 Enterprise 三个订阅模式,其中 Starter 免费。
Milvus
https://milvus.io/
概述:Milvus 是一个开源向量数据库,专为处理大规模向量数据而设计。它支持 NNS(近邻搜索)和 ANNS(近似近邻搜索),并与多种机器学习框架无缝集成。
关键功能:高可扩展性、灵活的部署选项、强大的社区支持。
用户:Salesforce、Zomato、Grab、Ikea、Paypal、Shell、Walmart、Airbnb 等。
费用:免费。
Qdrant
https://qdrant.tech/
概述:Qdrant 是一个先进的向量搜索引擎,专为处理高维数据而设计。它为相似性搜索和机器学习模型集成提供了可扩展的解决方案。
关键功能:实时更新、精确的搜索能力、高效的向量存储。
用户:Discord、Johnson & Johnson、Perplexity、Mozilla、Bosch 等。
费用:提供 Qdrant Cloud、Hybrid Cloud 以及 Private Cloud 三个订阅模式,其中 Qdrant Cloud 免费。
Chroma
https://www.trychroma.com/
概述:Chroma 是一个开源多功能的向量数据库,擅长于管理和检索高维数据。它针对 AI 驱动的应用进行了优化,提供强大的开发者工具。
关键功能:高灵活性、强大的 API 支持、与 AI 管道的无缝集成。
费用:免费。
Weaviate
https://weaviate.io/
概述:Weaviate 是一个基于 GraphQL 的云原生向量数据库,专为大规模 AI 应用设计,提供强大的向量数据搜索和检索功能。
关键功能:易于使用的 GraphQL 接口、灵活的架构、与多种机器学习工具的原生集成。
用户:Red Hat、Stack Overflow、Mutiny、Red Bull、Writesonic。
费用:提供 Serverless Cloud、Enterprise Cloud 以及 Bring Your Own Cloud 三个订阅模式。
总结
随着向量嵌入在自然语言处理、计算机视觉等 AI 应用领域的快速增长,作为与向量嵌入高效交互的计算引擎,向量数据库在未来的需求也会越来越多。
在本文中,我们详细探讨了向量数据库的各个方面,包括其工作机制和相关应用等,希望这些内容对你有所帮助。
合作请联系:erichainzzzz(添加好友请注明来意)
感谢耐心阅读
您的在看和点赞是我前进的动力
