




❤️ 点击上方蓝字关注我 👆 解锁更多 AI 干货知识 😎
本文正文字数约 3200 字,阅读时间 12 分钟。
在上一篇关于 RAG 入门的文章中,我们从零开始构建了一个简易版本的 RAG 系统,这个系统包含了文档集合、用户输入、相似性度量以及本地 LLM 等功能。
其中,我们选择了一个非常简单的相似性度量方法:杰卡德相似度(Jaccard Similarity)。
杰卡德相似度(Jaccard Similarity)是一种衡量两个集合相似程度的简单方法。它计算两个集合的交集和并集的比例,用于比较两个文本之间的相似性。简而言之就是,杰卡德相似度看两个集合中共同元素的数量占所有元素的总数量的比例。
然而使用这种方法的缺点就在于,它只关注了用户输入与文档之间的词汇重叠的情况,并不会去考虑每一个词语的含义以及这些词语所处的语境,也就是语义 (semantics)。
作为 RAG 入门指南的第二篇,本文将着重关注如何利用语义来改进我们的 RAG 系统。
RAG 入门指南第一篇:RAG 入门指南:从零开始构建一个 RAG 系统
如何获得语义?
在文章一开始就提到,当前所使用的杰卡德相似度这种度量方法过于简单,我们需要将其提升到更高的层次。这时候就需要用到 Sentence Transformers 这个 Python 库,它能够将文本转化为数值。
Sentence Transformers 官网:https://www.sbert.net/
关于 Transformer 的工作机制介绍,可以参考:你知道 GPT 代表什么意思吗?Transformer 架构深度解析
嵌入(Embedding)
在使用 Sentence Transformer 之前,我们需要先了解一下嵌入的原理。
嵌入是一种将一种表示形式转换为另一种表示形式的方法。文本是一种表示形式,整数是另一种表示形式,浮点数也是一种表示形式。嵌入通过生成一组数值序列来表示我们输入的文本。
这些嵌入捕捉了输入文本的语义含义,让我们能够衡量不同文本之间的相似性。
简单来说,嵌入的过程其实就是将词汇转换为数值向量的过程。这些向量捕捉了词汇的语法和语义信息,让相似的词汇在数值空间中具有相似的数学表示,这样可以方便模型来处理和学习。
比如,我们看这两个句子:
• Take the leisurely walk in the woods(在树林里悠闲散步)
• Enjoy a stroll outside(享受户外漫步)
这两个句子就可以直接展现出杰卡德相似度的局限性。
它们虽然在词汇上没有任何重叠,但是这两句话的语义是近似的。由于这两句话并没有相同的单词,所以这时候如果使用杰卡德相似度来衡量的话,得分会非常低。
而将句子通过嵌入转换为数值向量之后,就能够捕捉到这些句子背后的相似含义。
也就是说,含义相近的单词、短语或者句子,它们的嵌入也会相似。当然,我们依然需要使用一种方法来衡量相似度,那就是余弦相似度(Cosine Similarity)。我将在下面的内容中详细介绍这个衡量方法。
在本文中我们使用的模型是 all-MiniLM-L6-v2,这是一个 Sentence Transformer 模型,它可以将句子和段落映射到一个 384 维的稠密向量空间,可以用在聚类或者语义搜索这样的任务上。
稠密向量是一种在向量空间中,所有元素都包含实际数值的向量。与稀疏向量不同,稠密向量的每个维度都有数值(通常为浮点数),没有零值或非常少的零值。它通常用于机器学习和深度学习任务,用来表示文本、图像等复杂数据的特征。
构建 RAG 系统
本章节包含 Python 代码编写,请确保你已经在电脑上配置好了 Python 环境。
关于如何使用 all-MiniLM-L6-v2 这个模型,可以直接参考 HuggingFace 上关于此模型的介绍:https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2。
关于如何安装 Sentence Transformer,可以参考 https://www.sbert.net/docs/installation.html。
获取文档集合
本文所使用的语料库与上一篇文章中的语料库相同,都是 10 条关于不同的休闲活动的简短描述。
corpus_of_documents = [
"Take a leisurely walk in the park and enjoy the fresh air.",
"Visit a local museum and discover something new.",
"Attend a live music concert and feel the rhythm.",
"Go for a hike and admire the natural scenery.",
"Have a picnic with friends and share some laughs.",
"Explore a new cuisine by dining at an ethnic restaurant.",
"Take a yoga class and stretch your body and mind.",
"Join a local sports league and enjoy some friendly competition.",
"Attend a workshop or lecture on a topic you're interested in.",
"Visit an amusement park and ride the roller coasters."
]
计算相似度
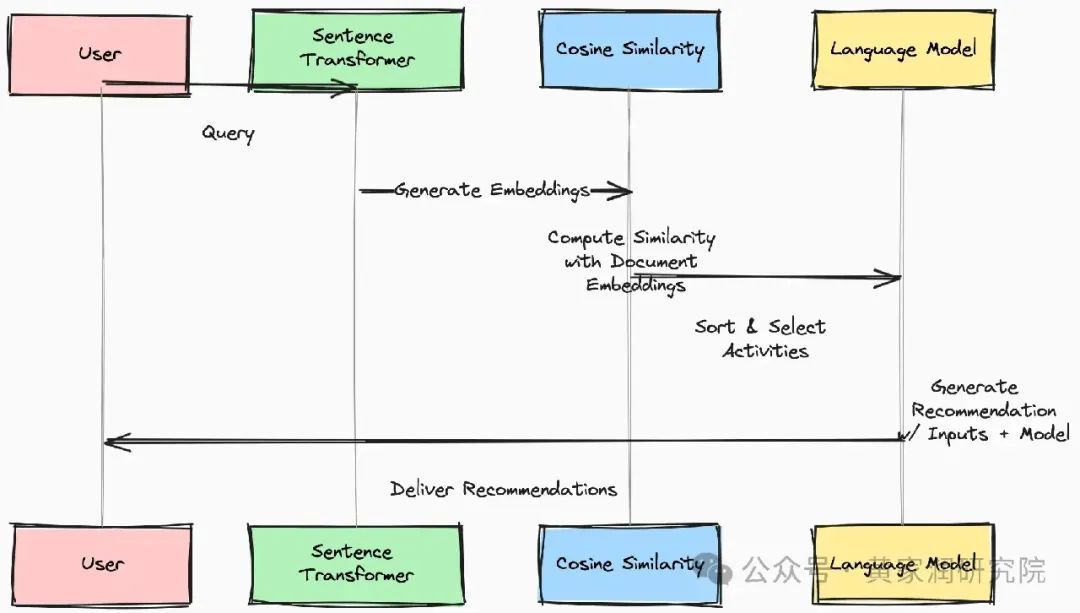
下图包含了 RAG 系统的处理步骤。
编码
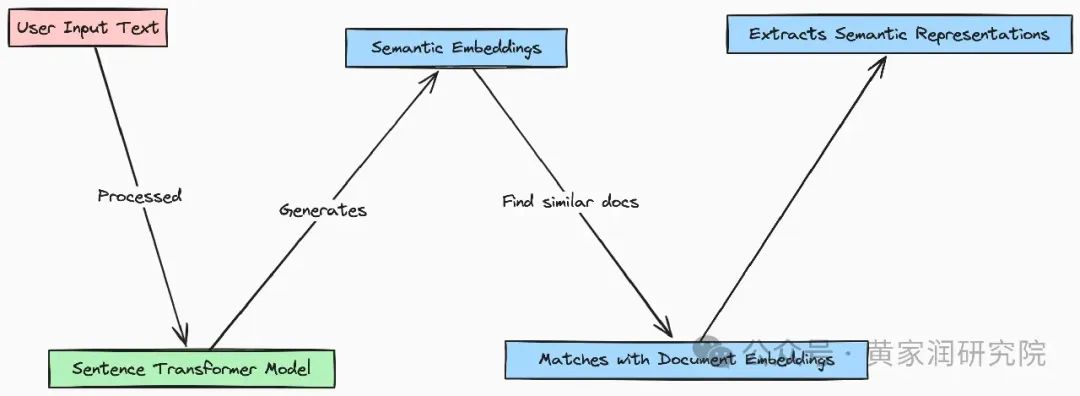
首先,使用 Sentence Transformer 模型将整个语料库编码为一组嵌入向量。
Sentence Transformer 模型将 corpus_of_documents
作为输入,然后返回一个嵌入向量矩阵,其中,数组中的每一个子数组代表了对应文档的向量编码。
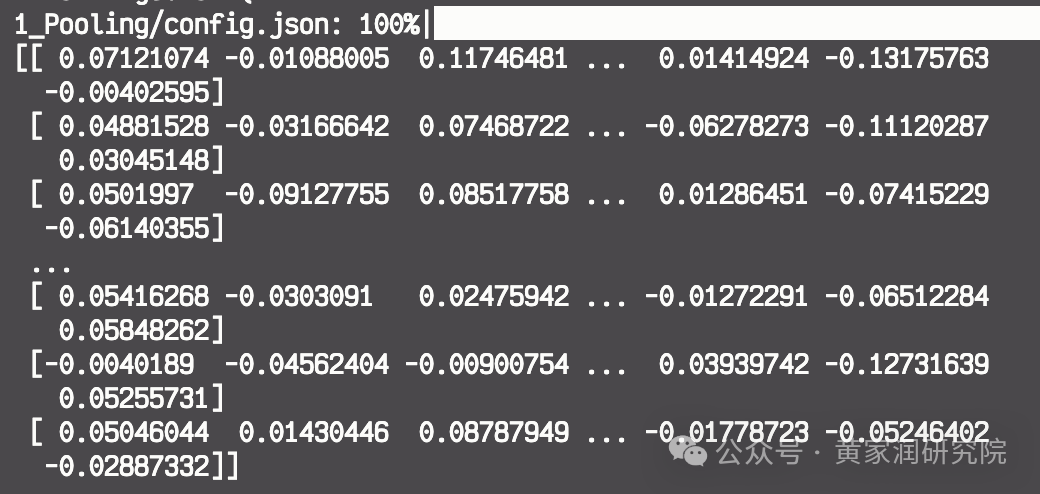
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
doc_embeddings = model.encode(corpus_of_documents)
# 可以直接使用 print 函数将编码后的嵌入向量打印出来查看
print(doc_embeddings)
计算
我们已经得到了文档的嵌入向量,接下来就可以开始计算用户输入的文本与语料库中每个文档之间的语义相似度了。
上文中有提到,我们会选择余弦相似度这个方法来对相似度进行衡量,这是一种常见且广泛使用的相似度衡量方法。
余弦相似度(Cosine Similarity) 是一种衡量两个向量之间相似程度的指标,计算的是它们夹角的余弦值。它通过判断两个向量方向的相似性来确定它们的相似度,而不考虑向量的长度。余弦相似度的取值范围是 -1 到 1,其中 1 表示两个向量方向完全相同,0 表示它们互相垂直,没有相似性,-1 表示它们方向完全相反。在文本处理中,余弦相似度常用于比较两个文本的语义相似度,特别适合在高维向量空间中比较嵌入向量。
from sklearn.metrics.pairwise import cosine_similarity
query = "What's the best outside activity?"
query_embedding = model.encode([query])
similarities = cosine_similarity(query_embedding, doc_embeddings)
print("\n-----------similartities------------\n")
print(similarities)
cosine_similarity
函数将用户输入的文本嵌入和文档嵌入作为输入,并返回一个相似度的得分向量。每个得分代表查询文本与对应文档之间的语义相似性。
代码中所使用的
cosine_similarity
函数来自于 scikit-learn,详情可参考:https://scikit-learn.org/stable/modules/generated/sklearn.metrics.pairwise.cosine_similarity.html
执行代码,可以得到以下这样的输入内容。

排序与推荐
计算完成了用户输入与语料库中的文档的语义相似性之后,接下来,我们需要对文档进行排序,然后选择最相关的文档推荐给用户。
首先是将相似度得分按照降序排列,找出与用户输入的文本的语义最相似的文档。
indexed = list(enumerate(similarities[0]))
sorted_index = sorted(indexed, key=lambda x: x[1], reverse=True)
然后,选择排名靠前的文档推荐给用户。这里我们可以应用一个相似度阈值(比如设置为 0.3)来过滤掉不太相关的文档,只保留最相关的文档来进行推荐。
recommended_documents = []
print("\n-----------formatted scores------------\n")
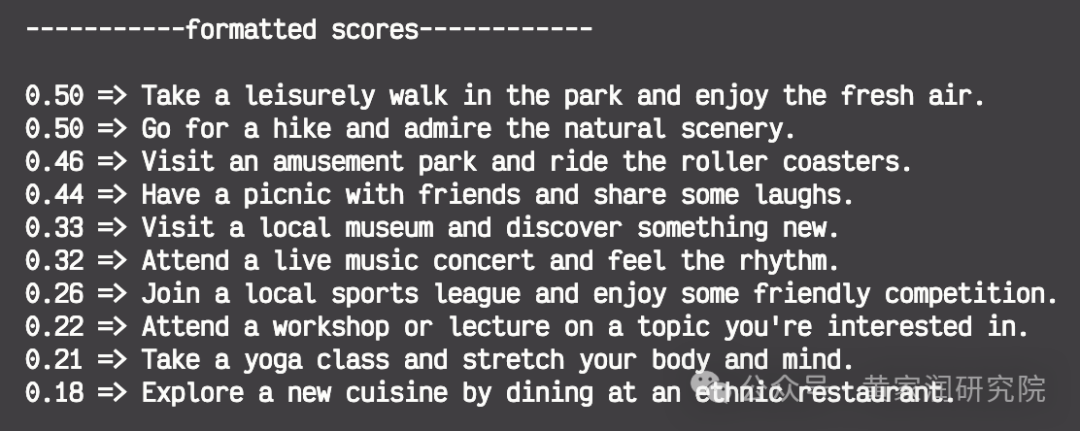
for value, score in sorted_index:
formatted_score = "{:.2f}".format(score)
print(f"{formatted_score} => {corpus_of_documents[value]}")
# 只推荐相似度大于 0.3 的文档
if score > 0.3:
recommended_documents.append(corpus_of_documents[value])
结果如下图所示。
相似度阈值的选择需要仔细的考量,因为它决定了推荐的精确性和召回率之间的平衡。
较高的阈值会导致推荐的数量较少,但相关性更高;而较低的阈值则可能提供更多的推荐,但相关性可能较低。
集成 LLM 来生成回答
在本文中,我将依然使用 Ollama 的 Llama 3.1 模型。当然,你也可以使用 OpenAI 的 GPT-4 或 Anthropic 的 Claude 或者其他 LLM。
我们需要创建一个提示语模板,将用户的输入与推荐的活动结合起来。然后将组装好的模板作为提示语输入给 LLM,这样,LLM 就会为我们生成连贯且自然的推荐内容了。
集成 LLM 部分的代码与入门指南的第一篇的中的代码基本一致,具体可参考:https://github.com/Huangjiarun/ai-application-demos/blob/main/create-rag-from-scratch.py
import requests
import json
recommended_activities = "\n".join(recommended_documents)
user_input = "I like to go to museum"
full_response = []
prompt = """
You are a bot that makes recommendations for activities. You answer in very short sentences and do not include extra information.
These are potential activities:
{recommended_activities}
The user's query is: {user_input}
Provide the user with 2 recommended activities based on their query.
"""
full_prompt = prompt.format(user_input=user_input, recommended_activities=recommended_activities)
url = "http://localhost:11434/api/generate"
data = {
"model": "llama3.1",
"prompt": prompt.format(
user_input=user_input, recommended_activities=recommended_activities
),
}
headers = {"Content-Type": "application/json"}
response = requests.post(url, data=json.dumps(data), headers=headers, stream=True)
print(response)
try:
count = 0
for line in response.iter_lines():
if line:
decoded_line = json.loads(line.decode("utf-8"))
full_response.append(decoded_line["response"])
finally:
response.close()
print("\n-----------response------------\n")
print("".join(full_response))
运行代码就能看到 LLM 的输出回答了。

总结
至此我们从零开始构建了一个可以根据用户输入来提供个性化的休闲活动推荐的 RAG 系统。
在本文中通过整合语义分析和余弦相似度,我们将上一篇教程中的 RAG 系统提升到了一个新的水平。
希望这两篇 RAG 的入门指南可以让你对 RAG 的理解更加透彻。
如果有什么问题或者想要学习的其他教程,也欢迎留言。
RAG 入门指南第一篇:RAG 入门指南:从零开始构建一个 RAG 系统
你可以在我的 GitHub 上获取到这两篇 RAG 指南的所有代码:https://github.com/Huangjiarun/ai-application-demos/tree/main

合作请联系:erichainzzzz(添加好友请注明来意)
您的在看和点赞是我前进的动力 ❤️
