




❤️ 点击上方蓝字关注我 👆 解锁更多 AI 干货知识 😎

本文正文字数约 4000 字,阅读时间 12 分钟。
你知道 ChatGPT 中的 GPT 全称是什么吗?
Generative Pre-training Transformer,翻译成中文就是生成式预训练 Transformer,是一种基于 Transformer 架构的 LLM。
当然,除了 GPT 之外,还有不少的 LLM 也是基于 Transformer 架构,可参考我的上一篇文章:2024 年最值得尝试的 8 个 AI 开源大模型。
Transformer 架构最早在 2017 年的论文《Attention is All You Need》中被提出,随后便成为了深度学习模型的首选架构。
它支撑了诸如 OpenAI 的 GPT、Meta 的 Llama 以及 Google 的 Gemini 等文本生成模型。同时,Transformer 还被广泛应用于音频、图像、甚至是游戏领域。
作为一种神经网络架构,Transformer 彻底改变了 AI 的研究方法。
那么,什么是 Transformer,它的工作原理又是怎么样的?本文将为你详细介绍。
Transformer 简介
想象这样一个场景,我们正在手机上编写文本。在每个单词之后,手机都有可能会给我们提供多个建议的词组。
比如,如果输入 “今天天气”,那手机可能会建议诸如“好”、“很”、“不错”这样的词。
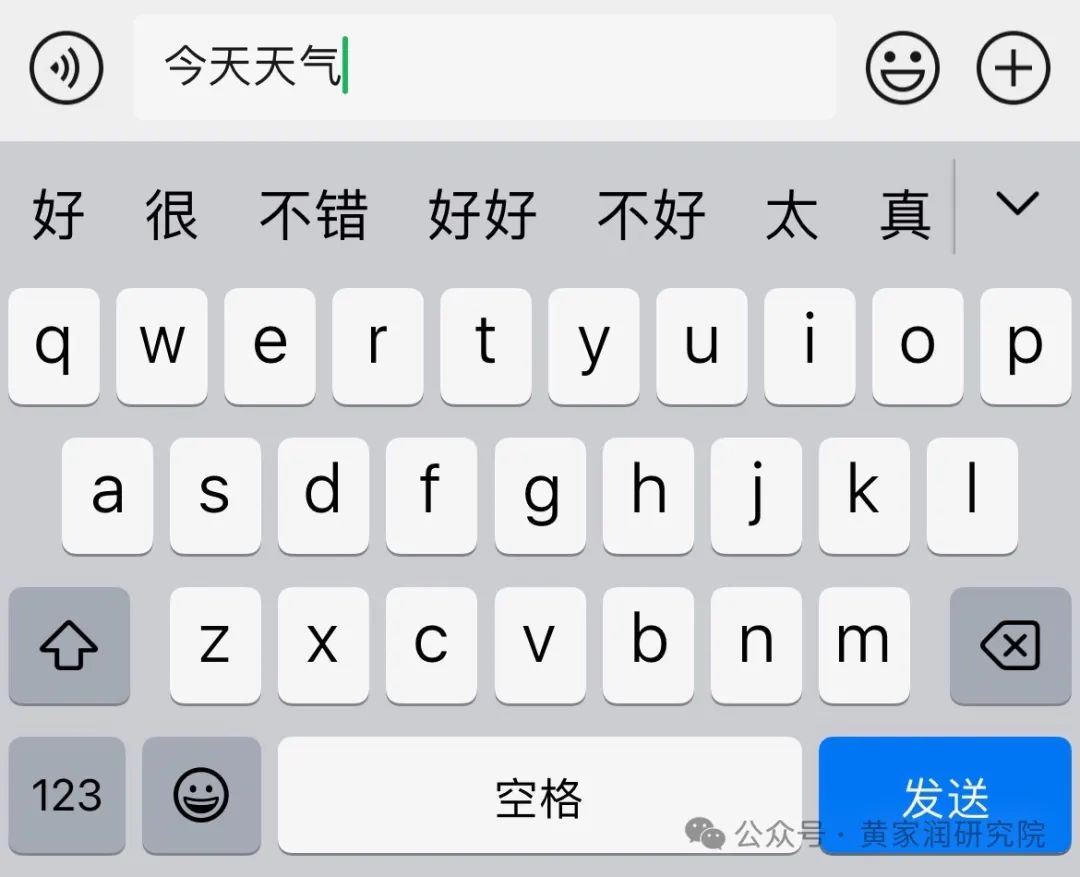
如果我们一直点选建议的词组,也许在前几次会形成有效的信息,但是很快就能发现最终组成的信息其实并不连贯,甚至毫无意义。
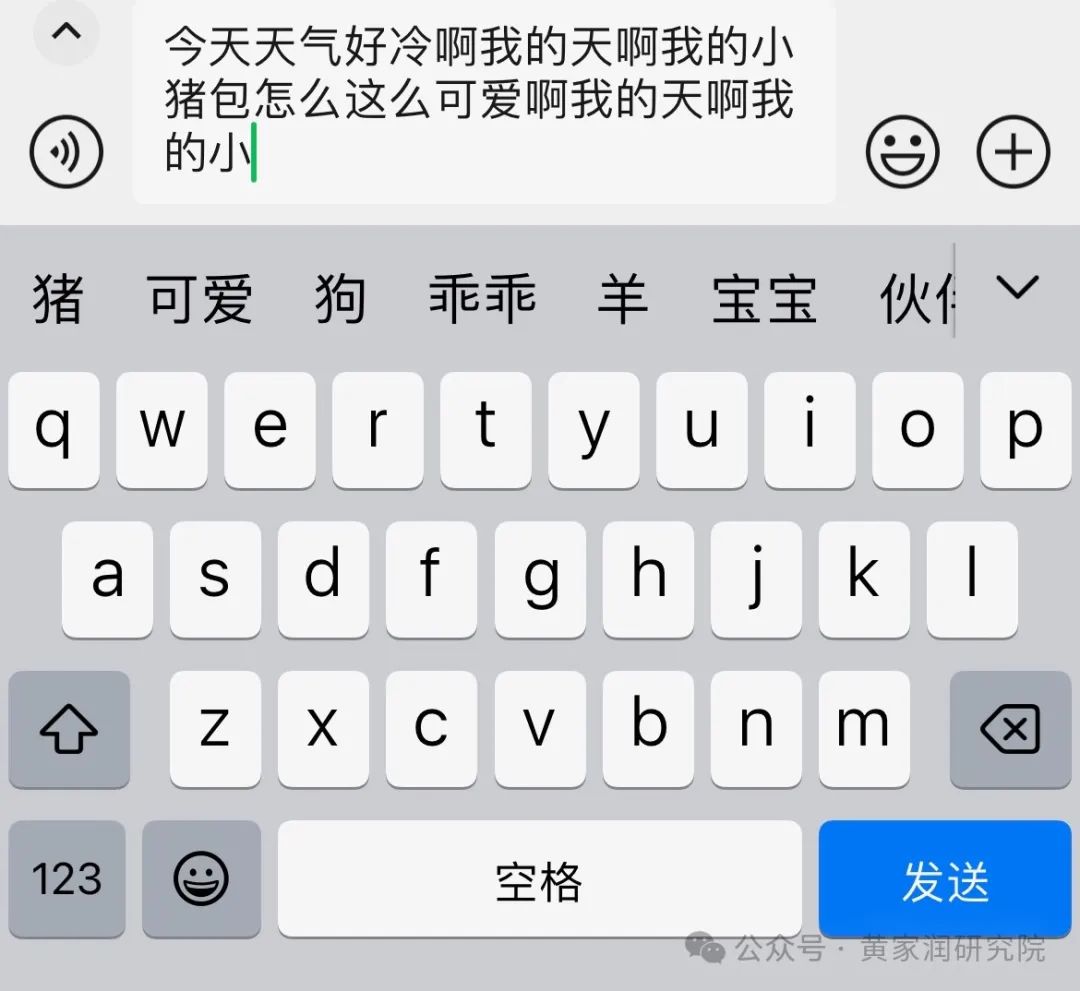
这是因为手机中使用的模型并没有考虑整个信息的上下文,它只是简单地预测在最后几个词之后最可能出现的词。
而 Transformer 则不同,它会跟踪当前内容的上下文,所以使用 Transformer 生成的文本是连贯且有意义的。
Transformer 是一种用于将输入序列转换为输出序列的神经网络架构。它可以通过学习上下文并追踪序列组件之间的关系来实现输入输出的转换。
从根本上来说,Transformer 的原理就是基于下一个词来预测。也就是说,在用户给定的提示语的上下文中,预测最有可能跟随输入的下一个词是什么。
但是其核心创新和强大之处就在于它的注意力机制。基于这个机制,Transformer 能够处理整个序列,并且比以往的架构能够更加有效地捕捉长距离的依赖关系。
注意力机制使得模型在处理每个输入时,能够同时关注整个序列,从而更好地理解和生成上下文相关的输出。
Transformer 架构
Transformer 主要由以下四个部分组成:
1. 分词(Tokenization)
2. 嵌入(Embedding)
3. 位置编码(Positional Encoding)
4. Transformer Block
5. Softmax
分词(Tokenization)
Transformer 中最基本的步骤就是分词。
这一步会将输入的内容转换为由大量 token 组成的数据集,其中包含所有的单词、标点符号等。这个阶段会将每个单词、前缀、后缀和标点符号等与库中的已知 token 进行匹配。
比如,如果一个句子是:Write a story。那么,将会生成四个对应的 token:<Write>
,<a>
,<story>
和 \<.>
。

嵌入(Embedding)
在对输入数据完成分词之后,下一步就是将单词转换为数字,这时候就需要用到嵌入。
简单来说,嵌入的过程其实就是将单词转换为数值向量的过程。这些向量捕捉了单词的语法和语义信息,让相似的单词在数值空间中具有相似的数学表示,这样可以方便模型来处理和学习。
我们依然使用上一个小节中的例子。
我们已经得到了 <Write>
,<a>
,<story>
和 \<.>
这样的四个 token,那么每个 token 将会被转换为一个长向量,最终我们会得到四个向量。
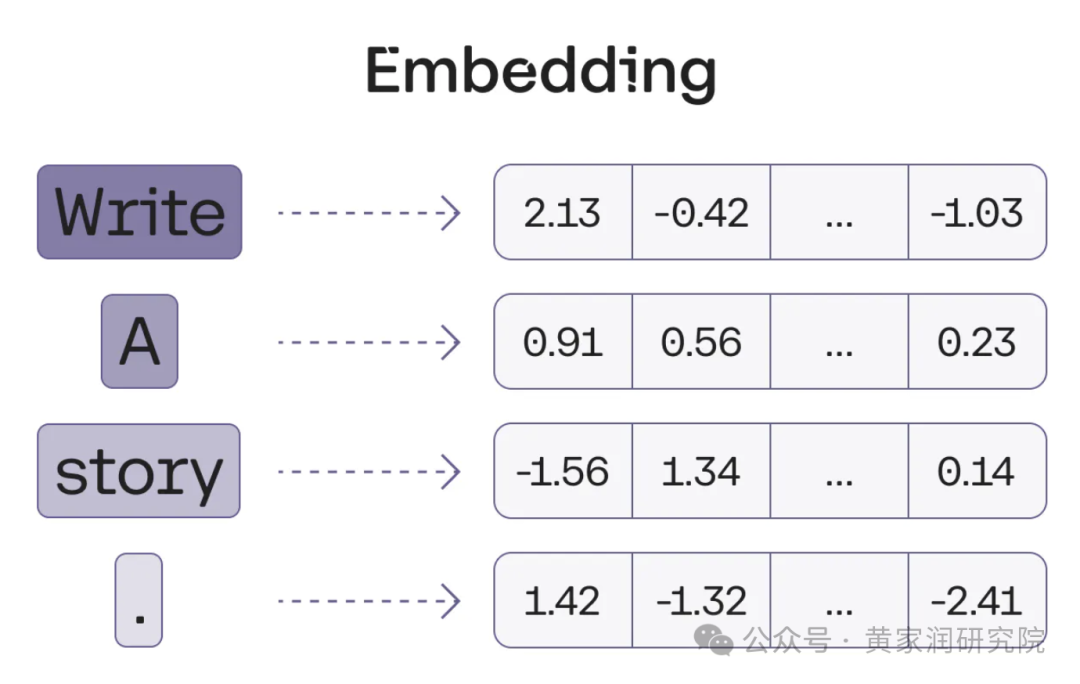
这里提到了一个新概念:长向量。长向量和普通向量的主要区别在于维度的数量,即向量中包含的元素数量。简单来说就是,长向量比普通向量能描述更加细致和复杂的特征。
在 Transformer 中,将文本转换为长向量的原因是,长向量能够捕捉到更多维度的信息,包括单词的语义、语法以及上下文关系。由于文本数据通常非常复杂,需要考虑多个层次的含义和关系,而长向量提供了更丰富的表达能力,可以让模型能够更准确地理解和生成文本。
位置编码(Positional Encoding)
通过嵌入获得了每个 token 的向量之后,就需要将这些向量组合成为一个可以处理的向量。
也就是说,需要将每个 token 对应的向量进行合并,这样可以将整个句子或者序列表示为一个整体的向量。这样模型才能够对整个句子进行处理,而不是只是对单个单词进行处理。
最常见的方法就是将这些向量按照元素相加,也就是说,按照每个坐标来分别相加。
比如,如果两个长度为 2 的向量分别是 [1,2]
和 [3,4]
,它们相加的结果就是 [1+3, 2+4]
,即 [4,6]
。
尽管这样计算是可以的,但是这其中存在有一个问题。
我们都知道加法有交换律,加号左右两边的数字交换之后并不影响计算结果。换句话说就是,如果用不同的顺序来将向量的坐标相加,最终结果是一样的。
那么在这种情况下,句子 I'm not sad,I'm happy
和 I'm not happy, I'm sad
将会得到相同的向量。因为它们包含的单词是一样的,只是顺序不同。
所以,需要一种方法来让两个句子生成不同的向量,也就是位置编码。
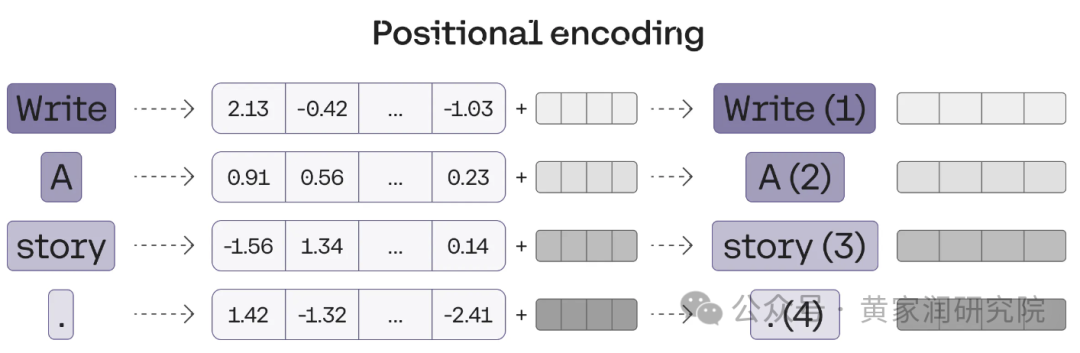
位置编码是指将一系列预定义的向量添加到单词的嵌入向量中,确保为每个句子生成唯一的向量,而顺序不同但单词相同的句子将被分配不同的向量。
在以上的例子中,单词 Write
,a
,story
,.
对应的向量就变成了包含位置信息的修正向量,即:Write(1)
,a(2)
,story(3)
和 .(4)
。
Transformer Block
这是 Transformer 最复杂的部分,也是 Transformer 处理的核心,它会对输入的数据进行多层的处理然后生成输出。我将会用大量篇幅来讲解这个部分。
可以把 Transformer Block 看做是信息处理单元,每个 Block 都会对输入的数据进行处理,然后将处理完成的信息传递给下一个 Block。
Transformer Block 是 Transformer 的基本构成单元。
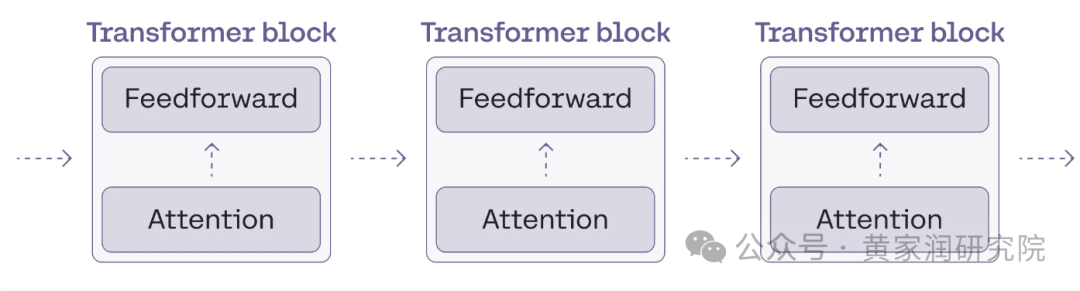
每个 Transformer Block 包含以下几个组件:
• 多头自注意力机制(Multi-Head Self-Attention)
• 前馈神经网络(Feedforward Neural Network)
• 层归一化(Layer Normalization)和残差连接(Residual Connection)
• 输出
这里依然使用上文中
Write a story.
的例子。
多头自注意力机制(Multi-Head Self-Attention)
这个机制可以让模型在处理某个单词的时候,不仅关注这个单词本身,还能够参考其他单词的信息。通过计算输入序列中每个单词与其他单词之间的关系来找到相关的重要信息。
• 计算 Query, Key, Value:每个单词的向量会被转换成三个不同的向量,称为 Query、Key 和 Value。这些向量用于计算每个词和其他单词之间的相关性。
• 计算注意力权重:通过计算 Query 和其他单词的 Key 之间的相似度(通常用点积计算),模型可以确定哪个单词与当前单词关系密切。对于
Write
,模型会计算它与a
、story
和.
的关系,得出一组权重值。• 加权求和:然后,用这些权重值对每个词的 Value 向量进行加权求和,生成一个新的向量。这一步使得每个词的表示不仅包含它自己的信息,还融合了来自其他词的信息。比如对于
story
,这个新向量可能会包含来自Write
和a
的部分信息,因为它们对理解story
有帮助。
前馈神经网络(Feedforward Neural Network)
经过多头自注意力机制处理后,得到的新向量会被送入一个前馈神经网络进行进一步的处理。
换句话说就是,模型需要进一步的处理这些信息,让其表示的更加抽象和复杂,这样才能更好地捕捉句子的深层含义。
这时候,前馈神经网络就发挥了作用。它通常由两个全连接层(Dense Layer)组成。这两个全连接层的工作过程如下:
• 第一个全连接层:这个层会先对输入的向量进行线性变换,将其映射到一个更高维度的空间中。简单来说就是,它是通过矩阵乘法和加上一个偏置(bias)来完成的。这个过程相当于给每个单词的表示增加更多维度,使单词的信息更加丰富。
• 非线性激活函数:在第一个全连接层之后,会通过一个非线性激活函数(例如 ReLU)。激活函数会引入非线性,这对模型来说至关重要,因为它能让模型学到更多复杂的模式和特征。
• 第二个全连接层:经过非线性激活函数后,输出会被送入第二个全连接层。这个层会将高维度的表示再次映射回到原始的维度。这一步的作用是进一步处理信息,并且通过之前的非线性激活函数,让输出具有更复杂的特征表示。
经过两层全连接层的处理之后,输入的向量会变得更加抽象和复杂。
这里的「抽象」,是指向量现在不仅仅是简单地代表一个单词的字面意思,而是包含了更多更深层次的、与上下文相关的特征,比如单词的寓意、单词与句子中其他单词的关系等。
残差连接和层归一化(Residual Connection & Layer Normalization)
为了保持模型的稳定性,Transformer Block 会将经过前馈神经网络处理后的输出与原始输入相加,也就是残差连接,然后进行层归一化。
层归一化会标准化每个词的表示,使其更适合下一步的处理。
输出
经过这一系列处理后,Transformer Block 会输出一个新的向量序列。这些向量比最初的嵌入向量包含了更多上下文信息。
比如,story
这个单词的最终表示可能包含了它与 Write
和 a
之间的关系,以及句子结束符号.
的影响。
通过 Transformer Block 的处理,句子 Write a story.
中的每个词的表示向量都得到了丰富的上下文信息,模型可以更好地理解句子的含义。
在生成新文本时,模型可以利用这些信息来预测下一个词是什么,并生成连贯的语言。
比如,如果模型需要生成一个类似的句子,它可能会选择 Write a story about...
,因为它已经理解了 story
和 Write
之间的关系。
Softmax
Softmax 是一种常用的激活函数,特别是在神经网络的分类任务中。它的主要作用是将一个包含任意实数值的向量转换为一个概率分布,让每个输出值都在 0 到 1 之间,并且所有输出值的总和为 1。
在 Transformer 中,Softmax 主要应用于两个重要部分。
注意力机制中的 Softmax
上文中提到 Transformer 的核心组件之一就是多头自注意力机制,在这个机制中,Softmax 起着关键作用。
1、计算注意力权重:
在自注意力机制中,每个单词(或向量)与序列中其他单词之间的相关性通过点积计算得到一个分数。为了将这些分数转换为可以表示权重的概率值,就需要使用 Softmax 函数。
Softmax 将这些分数标准化,让它们的和为 1,从而表示当前单词在生成输出时如何参考其他单词的信息。
比如,模型正在处理句子中的单词 story
。它会计算 story
与其他单词(Write
, a
, .
)之间的相关性,得到一组分数,假设这一组分数为:[2.0, 0.5, 1.0]
。
2、应用 Softmax:
将这些分数输入 Softmax 函数之后,Softmax 会将分数转换为概率值,并保证这些概率值的总和为 1。
比如,经过 Softmax 之后,可能得到的概率值为 [0.67, 0.09, 0.24]
。也就是说,story
在生成它的表示时,67% 的注意力会放在 Write
上,9% 在 a
上,24% 在 .
上。
3、加权求和:
使用这些概率值,模型对每个单词的表示向量进行加权求和,从而得到 story
的最终表示。这个表示不仅仅依赖于 story
本身,还融合了来自 Write
、 a
和 .
的信息。
输出层中的 Softmax
在这个阶段,模型需要预测下一个单词是什么。
模型会为每一个可能的词生成一个得分。
比如,在处理完 Write a story.
这一句话之后,可能会生成这样的得分:"about" -> 2.5
,"on" -> 1.0
,"!" -> 0.5
。
然后,将这些得分通过 Softmax 函数得到每个词的概率,比如 [0.72, 0.18, 0.10]
。
最后,模型会根据这些概率来选择概率最高的一个词作为下一个单词输出,在这里下一个词就是 about
,所以就可能会产生 Write a story about...
这样的一个新句子。
总结
至此,本文已详细讲解了 Transformer 以及其工作机制,希望对你有所帮助。

合作请联系:erichainzzzz
您的在看和点赞是我前进的动力 ❤️
