




导读
上一篇文章我们介绍了mysql压缩页的存储格式以及解析方法. 但只考虑了zlib的情况. 对于lz4压缩的就没管它的死活了. 现在来补充下lz4格式的解析.

LZ4
LZ4是YC大佬写的类LZ77压缩算法, 压缩速度嘎嘎快. 压缩中使用的hash算法的是xxhash(还是他写的)
所谓的压缩算法, 就是找规律, 用最简单的字符表示出现最多的字符. 但每次都找规律就比较麻烦, 所以有些算法会使用已经找到的’规律’(dict)来使用, 这样压缩速度就会快很多. 对于重复出现越多的数据, 压缩率往往越好(比如图片里面一大片空白这种). 但对于数据重复度相对低的数据(比如mp4)压缩就不那么明显了. 对于业务是否使用压缩, 还得看数据类型, 有些数据压缩就是存粹浪费时间. 又扯远了.
官方给的数据是: i7-9700K 环境下, 压缩780MB/s, 解压4970MB/s
| Compressor | Ratio | Compression | Decompression |
|---|---|---|---|
| memcpy | 1.000 | 13700 MB/s | 13700 MB/s |
| LZ4 default (v1.9.0) | 2.101 | 780 MB/s | 4970 MB/s |
| LZO 2.09 | 2.108 | 670 MB/s | 860 MB/s |
| QuickLZ 1.5.0 | 2.238 | 575 MB/s | 780 MB/s |
| Snappy 1.1.4 | 2.091 | 565 MB/s | 1950 MB/s |
| [Zstandard] 1.4.0 -1 | 2.883 | 515 MB/s | 1380 MB/s |
| LZF v3.6 | 2.073 | 415 MB/s | 910 MB/s |
| [zlib] deflate 1.2.11 -1 | 2.730 | 100 MB/s | 415 MB/s |
| LZ4 HC -9 (v1.9.0) | 2.721 | 41 MB/s | 4900 MB/s |
| [zlib] deflate 1.2.11 -6 | 3.099 | 36 MB/s | 445 MB/s |
虽然速度这么快, 但是python之类的不内置啊, 引入第三方包又太麻烦了, 那就只能自己简单的解析下了.
lz4的格式, 分为frame和block两种. mysqlpump之类的看起来比较偏向frame,但mysql的page很明显偏向于block.

那我们就只看block格式的了.
LZ4 block 格式
我们通过查询官方介绍, 得到lz4的格式如下:
lz4由 一堆 sequences 构成. 每个sequences 由token+literals+match构成.
token: 固定1字节.
- 前4bit表示literals的长度, 若值为上限(15),则往后再读1字节大小,再加上前面的大小. (若新读的数据也为上限(255),则再往后读1字节, 依次内推)
- 后4bit表示match部分的大小. 格式同上.
不好理解, 官方给了几个例子:
48: literals 15:value for the 4-bits High field 33: (=48-15) remaining length to reach 48 280 literals 15 : value for the 4-bits High field 255 : following byte is maxed, since 280-15 >= 255 10 : (=280 - 15 - 255) remaining length to reach 280 15 literals 15 : value for the 4-bits High field 0 : (=15-15) yes, the zero must be output
意思就是达到上限(15/255)就再来1字节表示大小. 其实这种存储方式空间使用并不是最优(比如15,就还得额外使用1字节来表示), 但lz4算法本身主打的是速度.
literals: 不可压缩的部分, 即部分原始数据, 类似于dict的角色. 若token部分记录的大小为15, 则literals前面还有literals length部分.
match: 匹配压缩的部分, 即压缩后的数据位置(相对于原始数据). 格式为offset+match
- offset : 小端字节序, 表示这部分数据和原始数据中的位置. 2字节只能表示最大65535, 所以对于block的大小要求为64KB.
- match: 若token部分不够,则使用此部分来存储剩余长度.
token部分记录的长度加上match部分的长度之后还得+4(minmatch). 因为最少是4个字节. 我们这里就不细看算法了.
看起来云里雾里的, 这种时候就得画图来解释了.
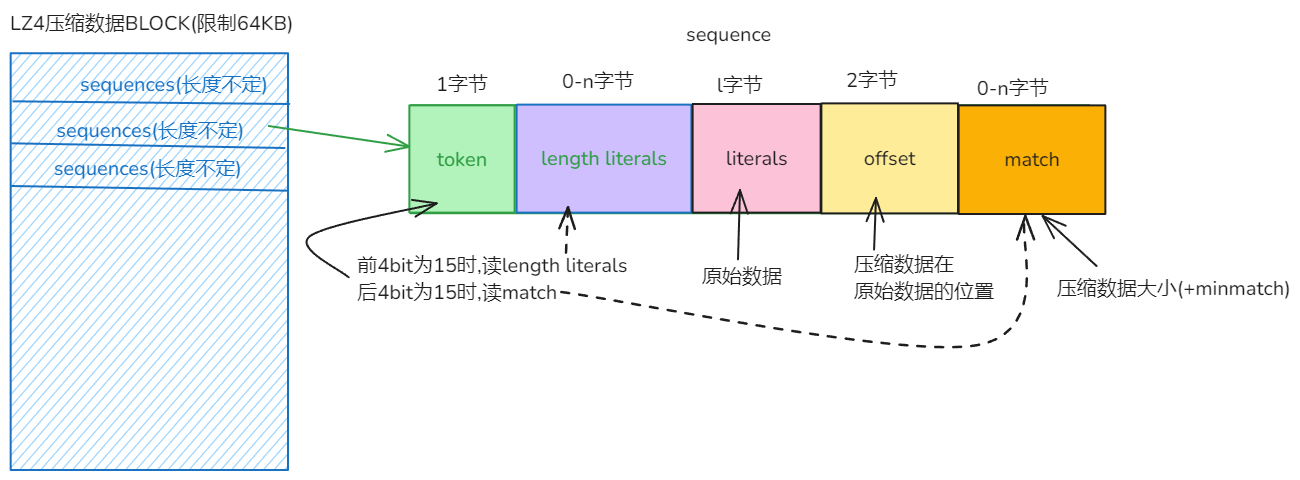
好像看起来更复杂了.
那我们再来看下关于block结束的判断.
- 最后一个seq只包含literals. (后面没得offset了)
- 最后5字节始终是literals. (如果输入只有5字节的数据,就只有1个seq)
- 最后一个match必须在block的倒数12的偏移量开始, 所以要压缩block要求大于12字节.
LZ4压缩
压缩相对于解压复杂太多了.(还得考虑性能). 用ai(gpt-o1)写了个简单的, 但压缩的结果不符合预期(和python库的lz4结果不一致, 和mysql使用的lz4压缩的结果也不一致. 压缩算法还是太TM复杂了.)
这里就不介绍了. 感兴趣的可以自己去实现.

LZ4解压
解压就简单多了, 我们只需要按照格式读就行.
逻辑很简单, 就是初始化一个bytearray作为原始数据, 然后while循环一个个seq的解析并填充回去即可.
注意: ml值得加4. offset是相对于原始数据的位置. 即这个seq里面的match并不是match的literals. literals只是不可压缩的数据.

直接上代码吧.
def decompress(bdata,decompress_size):
"""
input:
bdata: 压缩数据
decompress_size : 解压之后的大小
return: data 解压之后的数据
不考虑dict和prefix_size了
"""
def read_to_less255(tdata,ip):
length = 0
while True:
#t = struct.unpack('<B',aa[ip:ip+1])[0]
t = tdata[ip]
ip += 1
length += t
if t != 255: # 小于255时,就读完了
break
return length,ip
ip = 0 # input pointer (bdata的指针)
op = 0 # output pointer (data的指针)
data = bytearray(decompress_size) # 要返回的数据有这么大
while True:
token = bdata[ip]
ip += 1
ll = token >> 4 # literals length
if ll == 15:
tll,ip = read_to_less255(bdata,ip)
ll += tll
data[op:op+ll] = bdata[ip:ip+ll] # literals 不可压缩的部分
op += ll
ip += ll
if decompress_size-op < 12:
if op == decompress_size: # 解压完了, 因为可能没得后面的match部分
break
else:
raise ValueError('Invalid lz4 compress data.')
#offset = struct.unpack('<H',bdata[ip:ip+2])[0]
offset = (bdata[ip+1]<<8) | bdata[ip] # 位移真TM好用
ip += 2
ml = token & 15 # 后4bit是match length
if ml == 15:
tml,ip = read_to_less255(bdata,ip)
ml += tml
ml += 4 # 还得加4(minmatch)
match = op - offset
data[op:op+ml] = data[match:match+ml] # match实际上是指的原始数据位置的数据,而不是压缩之后的数据位置
op += ml # 重复的数据只需要移动op就行,ip那没得要移动的.(match部分已经mv了)
return bytes(data)
注释还是写得很清楚的. 就不多介绍了.
测试
那我们来测试下吧. 我们这是针对mysql中使用的lz4算法做的解析, 所以对于其它使用lz4压缩的不一定有用. 最好还是使用mysql的压缩页来做.
先准备数据吧.
create table t20240924_compress_lz4(id int primary key, name varchar(200)) COMPRESSION='lz4';
insert into t20240924_compress_lz4 values(1,'ddcw');
insert into t20240924_compress_lz4 values(2,'https://github.com/ddcw');
insert into t20240924_compress_lz4 values(3,'https://github.com/ddcw/ibd2sql');
我们数据量很少, 所以数据是放在root page里的, 且root page是使用的第一个’未使用页’. 那么基本上可以猜到pageno=4 (0:fsp, 1:insert buffer, 2:inode 3:sdi page). 那我就直接开整了.
# 导入包的代码是重复的, 我就不再写了.
import struct
filename = '/data/mysql_3314/mysqldata/db1/t20240924_compress_lz4.ibd'
f = open(filename,'rb')
f.seek(4*16384,0)
data = f.read(16384)
# 压缩信息
FIL_PAGE_VERSION,FIL_PAGE_ALGORITHM_V1,FIL_PAGE_ORIGINAL_TYPE_V1,FIL_PAGE_ORIGINAL_SIZE_V1,FIL_PAGE_COMPRESS_SIZE_V1 = struct.unpack('>BBHHH',data[26:34])
# lz4解压
data = data[:24] + struct.pack('>H',FIL_PAGE_ORIGINAL_TYPE_V1) + b'\x00'*8 + data[34:38] + lz4.decompress(data[38:38+FIL_PAGE_COMPRESS_SIZE_V1],FIL_PAGE_ORIGINAL_SIZE_V1)
# 验证解压后的数据.
......
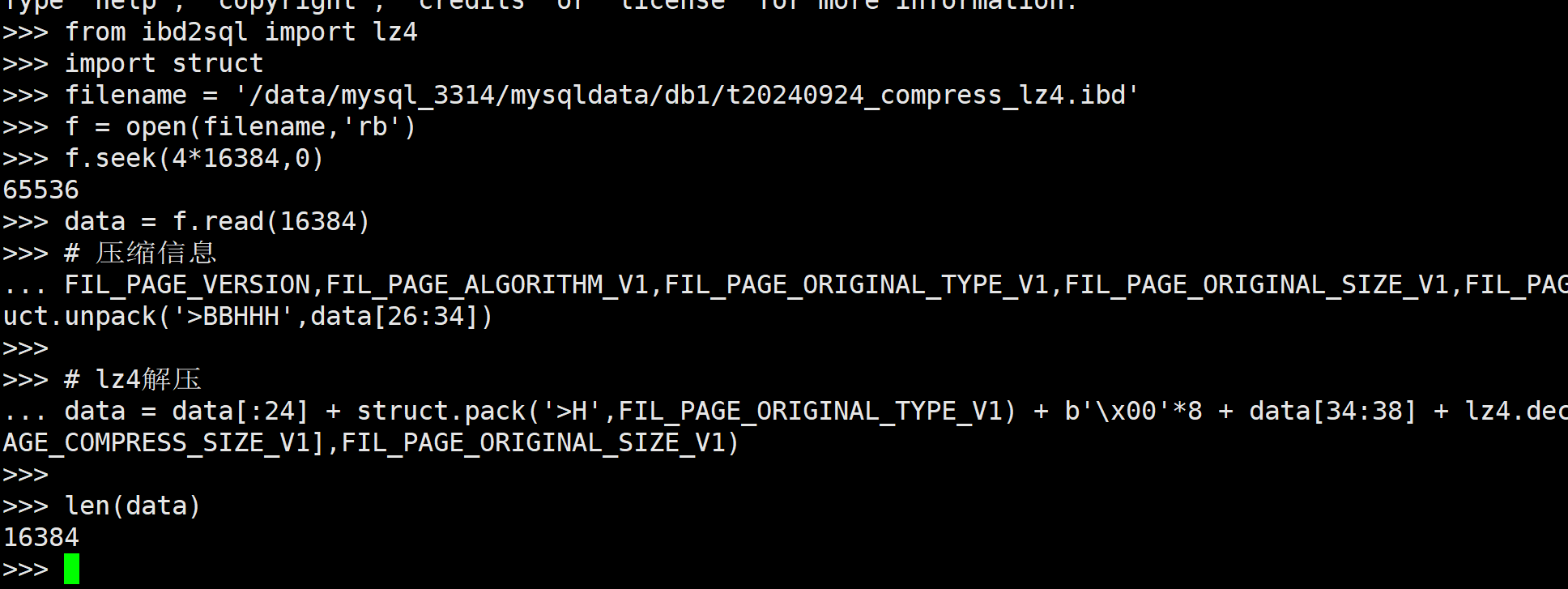
由于是innodb的数据页, 所以不方便直接查看, 那我们就使用ibd2sql来验证吧.
好家伙, 整半天, 还是得用ibd2sql…
wget https://github.com/ddcw/ibd2sql/archive/refs/heads/main.zip unzip main.zip cd ibd2sql-main python main.py /data/mysql_3314/mysqldata/db1/t20240924_compress_lz4.ibd --sql --ddl
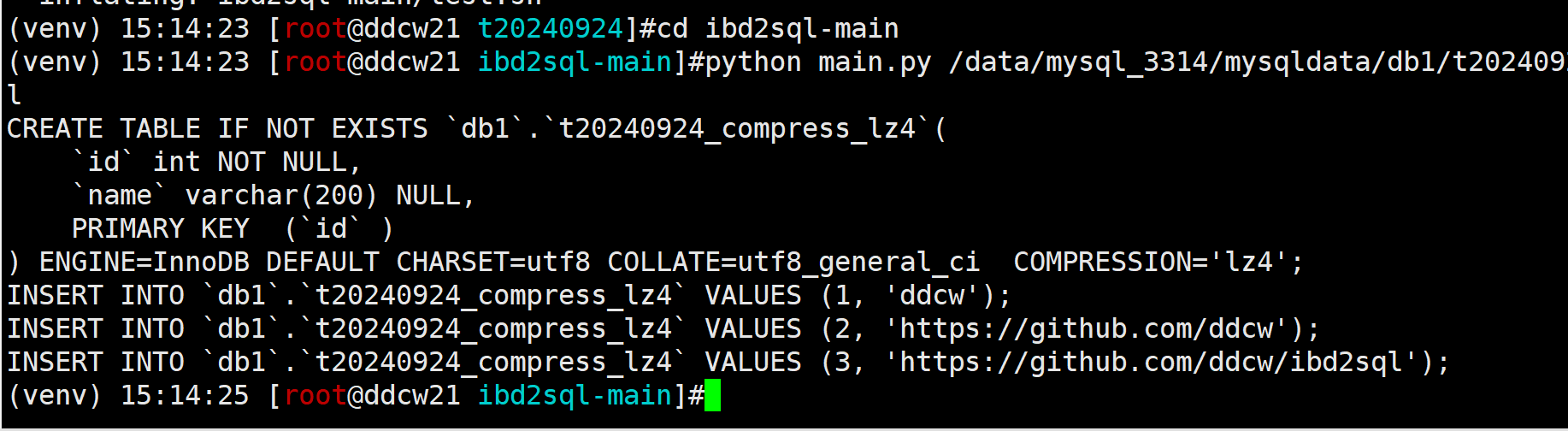
顺便把ddl中的压缩算法也加上去了.
看起来解析是正常的. 也就是说我们我们对于lz4压缩的数据解析没毛病.

总结
- 本文主要是讲lz4的压缩格式, 而非lz4压缩算法.
- lz4压缩算法优点是速度快. 但压缩率不一定好. (所以不适合存储数据, 倒是适合传输数据:要的是尽可能的快, 不然延迟就上去了. 比如x plugin). 所以不推荐在mysql中使用lz4压缩算法.
参考:
https://github.com/lz4/lz4/blob/dev/doc/lz4_Block_format.md
https://github.com/ddcw/ibd2sql
