




ClickHouse 作为开源的列式存储数据库,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。而阿里云 EMR ClickHouse 则提供了开源 OLAP 分析引擎 ClickHouse 的云上托管服务。
本系列文章将从以下几个方面详细介绍 EMR ClickHouse 的操作指南:
ClickHouse 运维 (本文)
数据导入
常见问题
EMR ClickHouse 操作指南 — ClickHouse 运维

一、日志配置说明
EMR 支持在控制台查看或配置日志参数,也支持在命令行中设置参数。
前提条件
已创建集群,详情请参见创建集群:
https://help.aliyun.com/document_detail/208809.htm
Clickhouse 控制台日志配置
您可以在 ClickHouse 服务配置页面的服务配置区域,在 server-config 页签中查看或修改配置,或者在 ClickHouse 服务的配置页面,在搜索区域搜索 logger.,即可查看或修改所有的日志配置项。
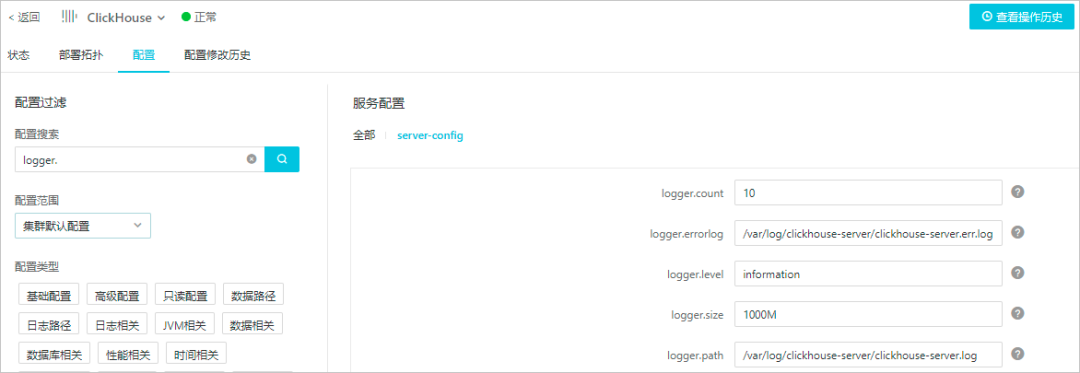
| 参数 | 描述 |
| logger.level | 日志的等级,默认等级为 information 可以配置的等级从严格到宽松依次为
|
| logger.path | ClickHouse Server 正常输出的日志文件,默认为/var/log/clickhouse-server/clickhouse-server.log,会输出符合 logger.level 所指定的日志等级的日志。 |
| logger.errorlog | ClickHouse Server 中错误日志的输出路径。默认值为/var/log/clickhouse-server/clickhouse-server.err.log。 |
| logger.size | 日志文件的大小。当文件达到该参数设置的值时,ClickHouse 会将其存档并重命名,并创建一个新的日志文件。默认值为1000M。 |
| logger.count | 存档的 ClickHouse 日志文件个数。当存档的日志文件个数达到该参数设置的值时,ClickHouse 会将最早的存档删除。默认值为10。 |
ClickHouse 客户端日志配置
您可以通过配置客户端日志,来接收来自服务端的日志,默认接收 fatal 级别的日志。
1. 通过 SSH 方式登录集群:
https://help.aliyun.com/document_detail/169150.htm
2. 基本操作示例。
查看每次执行的日志。
执行以下命令, 启动 clickhouse-client。
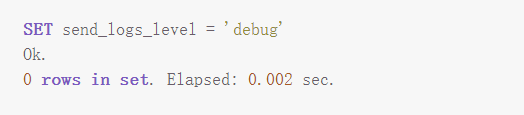
clickhouse-client您可以执行以下命令,设置参数 send_logs_level 查看每次执行的日志。
set send_logs_level='debug';
在 clickhouse-client 启动时,您可以执行以下命令,将日志保存到指定的文件中。
clickhouse-client --send_logs_level=trace --log-level=trace --server_logs_file='/tmp/query.log'
二、系统表说明
系统表存储于 System 数据库中,仅提供数据读取功能,不能被删除或更改,但可以对其进行分离(detach)操作。大多数系统表将其数据存储在 RAM 中,一个 ClickHouse 服务在刚启动时便会创建此类系统表。
背景信息
常用系统表如下:
system.clusters
system.query_log
system.zookeeper
system.replicas
system.storage_policies
system.disks
更多系统表信息,请参见ClickHouse官方文档:
https://clickhouse.tech/docs/zh/operations/system-tables/
system.clusters
该表包含了配置文件中可用的集群及其服务器的信息。
| 参数 | 数据类型 | 描述 |
cluster | String | 集群名。 |
shard_num | UInt32 | 集群中的分片数,从1开始。 |
shard_weight | UInt32 | 写数据时该分片的相对权重。 |
replica_num | UInt32 | 分片的副本数量,从1开始。 |
host_name | String | 配置中指定的主机名 |
host_address | String | 从 DNS 获取的主机 IP 地址。 |
port | UInt16 | 连接到服务器的端口 |
user | String | 连接到服务器的用户名。 |
errors_count | UInt32 | 此主机无法访问副本的次数。 |
slowdowns_count | UInt32 | 在与对端请求建立连接时导致副本更改的 slowdown 的次数。 |
estimated_recovery_time | UInt32 | 在复制副本错误计数归零并被视为恢复正常之前剩余的秒数。 |
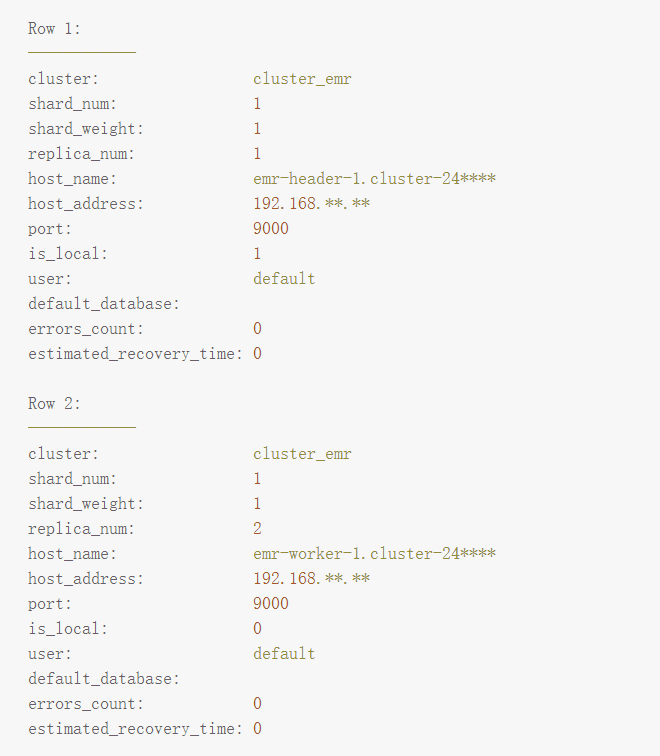
示例:您可以执行以下命令,查看表信息。
SELECT * FROM system.clusters LIMIT 2 FORMAT Vertical;
返回信息如下。
system.query_log
该表包含了已执行查询的相关信息。例如,开始时间、处理持续时间和错误消息。
system.query_log 表中记录了两种查询:
客户端直接运行的初始查询。
由其它查询启动的子查询(用于分布式查询执行)。对于这些类型的查询,有关父查询的信息显示在
initial_*
列。
根据查询的状态(请参见type
列),每个查询在查询日志表中创建一行或两行记录:
如果查询执行成功,则会创建
type
为QueryStart
和QueryFinish
的两行记录信息。如果在查询处理期间发生错误,则会创建
type
为QueryStart
和ExceptionWhileProcessing
的两行记录信息。如果在启动查询之前发生错误,则会创建
type
为ExceptionBeforeStart
的一行记录信息。
| 参数 | 数据类型 | 描述 |
type | Enum8 | 执行查询时的事件类型。取值如下:
|
event_date | Date | 查询开始日期。 |
event_time | DateTime | 查询开始时间。 |
event_time_microseconds | DateTime64 | 以微秒精度查询开始时间。 |
query_start_time | DateTime | 查询执行的开始时间。 |
query_start_time_microseconds | DateTime64 | 以微秒精度查询执行的开始时间。 |
query_duration_ms | UInt64 | 查询消耗的时间。单位为毫秒。 |
read_rows | UInt64 | 从参与了查询的所有表和表函数读取的字节总数。包括常用的子查询,IN和JOIN的子查询。对于分布式查询read_rows包括在所有副本上读取的字节总数。每个副本发送它的 read_rows值,并且查询的发起方将所有接收到的和本地的值汇总。缓存卷不会影响此值。 |
read_bytes | UInt64 | 从参与了查询的所有表和表函数读取的总字节数。包括常用的子查询,IN和JOIN的子查询。对于分布式查询read_bytes包括在所有副本上读取的字节总数。每个副本发送它的 read_bytes值,并且查询的发起方将所有接收到的值和本地的值汇总。缓存卷不会影响此值。 |
written_rows | UInt64 | 对于INSERT查询,为写入的行数。对于其它查询,值为0。 |
written_bytes | UInt64 | 对于INSERT查询时,为写入的字节数。对于其它查询,值为0 |
result_rows | UInt64 | SELECT查询结果的行数,或INSERT的行数。 |
result_bytes | UInt64 | 存储查询结果的RAM量。 |
memory_usage | UInt64 | 查询使用的内存。 |
query | String | 查询语句。 |
exception | String | 异常信息。 |
exception_code | Int32 | 异常码。 |
stack_trace | String | 如果查询成功完成,则为空字符串。 |
is_initial_query | UInt8 | 查询类型。取值如下:
|
user | String | 发起查询的用户。 |
query_id | String | 查询ID。 |
address | Ipv6 | 发起查询的客户端IP地址。 |
port | UInt16 | 发起查询的客户端端口。 |
initial_user | String | 初始查询的用户名(用于分布式查询执行)。 |
initial_query_id | String | 初始查询的ID(用于分布式查询执行)。 |
initial_address | Ipv6 | 运行父查询的IP地址。 |
initial_port | UInt16 | 进行父查询的客户端端口。 |
interface | UInt8 | 发起查询的接口。取值如下:
|
os_user | String | 运行clickhouse-client的操作系统的用户名。 |
client_hostname | String | 运行clickhouse-client或其他TCP客户端的机器的主机名。 |
client_name | String | clickhouse-client或其他TCP客户端的名称。 |
client_revision | UInt32 | clickhouse-client或其他TCP客户端的Revision。 |
client_version_major | UInt32 | clickhouse-client或其他TCP客户端的Major Version。 |
client_version_minor | UInt32 | clickhouse-client或其他TCP客户端的Minor Version。 |
client_version_patch | UInt32 | clickhouse-client或其他TCP客户端的Patch component。 |
http_method | UInt8 | 发起查询的HTTP方法。取值如下:
|
http_user_agent | String | HTTP查询中传递的HTTP请求头UserAgent。 |
quota_key | String | 在quotas配置里设置的quota key. 详细信息可以参见配额: |
revision | UInt32 | ClickHouse revision。 |
ProfileEvents | Map(String,UInt64) | 其它事件的指标,可以在表system.events中找到相关的描述:https://clickhouse.tech/docs/en/operations/system-tables/events/ |
Settings | Map(String,String) | 客户端运行查询时更改的设置。要启用对设置的日志记录更改,请将log_query_settings参数设置为1。 |
thread_ids | Array(UInt64) | 参与查询的线程数 |
Settings.Names | Array(String) | 客户端运行查询时更改的设置的名称。要启用对设置的日志记录更改,请将log_query_settings参数设置为1。 |
Settings.Values | Array(String) | Settings.Names列中列出的设置的值 |
示例:您可以执行以下命令,查看表信息。
SELECT * FROM system.query_log LIMIT 1 FORMAT Vertical;
返回信息如下。

system.zookeeper
该表可以查到 ZooKeeper 中的节点信息。
如果未配置 ZooKeeper,则该表不存在。允许从配置中定义的 ZooKeeper 集群读取数据。查询必须具有path=
条件,或使用 WHERE 子句设置了 path IN 条件,这对应于 ZooKeeper 中要获取数据的子对象的路径。
查询语句SELECT * FROM system.zookeeper WHERE path = '/clickhouse'
,输出/clickhouse
节点的对所有子路径的数据。如果需要输出所有根节点的数据,请写入路径为‘/’
。如果path
中指定的路径不存在,则将提示异常。
SELECT * FROM system.zookeeper WHERE path IN ('/', '/clickhouse'),输出
/和
/clickhouse节点上所有子节点的数据。如果
path中指定的路径不存在,则将提示异常。它可以用于一批 ZooKeeper 路径的查询。
| 参数 | 数据类型 | 描述 |
name | String | 节点的名字。 |
path | String | 节点的路径。 |
value | String | 节点的值。 |
dataLength | Int32 | 节点的值长度。 |
numChildren | Int32 | 子节点的个数。 |
czxid | Int64 | 创建该节点的事务ID。 |
mzxid | Int64 | 最后修改该节点的事务ID。 |
pzxid | Int64 | 最后删除或者增加子节点的事务ID。 |
ctime | DateTime | 节点的创建时间。 |
mtime | DateTime | 节点的最后修改时间。 |
version | Int32 | 节点版本和节点被修改的次数。 |
cversion | Int32 | 最后删除或者增加子节点的事务ID。 |
aversion | Int32 | ACL的修改次数。 |
ephemeralOwner | Int64 | 针对临时节点,拥有该节点的事务ID。 |
示例:您可以执行以下命令,查看表信息。
SELECT *FROM system.zookeeperWHERE path = '/clickhouse/tables/01-08/visits/replicas'FORMAT Vertical
返回信息如下。

system.replicas
该表包含本地服务所有复制表的信息和状态,可以用于监控。
| 参数 | 数据类型 | 描述 |
database | String | 数据库名称。 |
table | String | 表名。 |
engine | String | 表引擎名称。 |
is_leader | UInt8 | 副本是否是领导者。 一次只有一个副本可以成为领导者。领导者负责选择要执行的后台合并。 注意 可以对任何可用且在Zookeeper中具有会话的副本执行写操作,不管该副本是否为leader。 |
can_become_leader | UInt8 | 副本是否可以当选为领导者。 |
is_readonly | UInt8 | 副本是否处于只读模式。 如果配置中没有ZooKeeper的部分,在ZooKeeper中重新初始化会话时发生未知错误,以及在ZooKeeper中重新初始化会话时发生未知错误,则会打开此模式。 |
is_session_expired | UInt8 | 与ZooKeeper的会话已经过期。用法基本上与is_readonly相同。 |
future_parts | UInt32 | 由于尚未完成的插入或合并而显示的数据部分的数量。 |
parts_to_check | UInt32 | 队列中用于验证的part的数量。如果怀疑part可能损坏了,则将其放入验证队列。 |
zookeeper_path | String | 在ZooKeeper中的表数据路径。 |
replica_name | String | ZooKeeper中的副本名称。同一表的不同副本具有不同的名称。 |
replica_path | String | ZooKeeper中副本数据的路径。与 zookeeper_path/replicas/replica_path下的内容相同。 |
columns_version | Int32 | 表结构的版本号。表示执行ALTER的次数。如果副本有不同的版本,则意味着部分副本还没有进行所有的更改。 |
queue_size | UInt32 | 等待执行的操作的队列大小。操作包括插入数据块、合并和某些其它操作。它通常与future_parts一致。 |
inserts_in_queue | UInt32 | 需要插入的数据块的数量。 数据的插入通常很快。如果该数值很大,则说明有问题。 |
merges_in_queue | UInt32 | 等待进行合并的数量。 有时合并时间很长,因此此值可能长时间大于零。 |
part_mutations_in_queue | UInt32 | 等待进行的突变的数量。 |
queue_oldest_time | DateTime | 如果queue_size大于0,则显示何时将最早的操作添加到队列。 |
inserts_oldest_time | DateTime | |
merges_oldest_time | DateTime | |
part_mutations_oldest_time | DateTime | |
log_max_index | UInt64 | 一般活动日志中的最大条目数。 注意 存在与ZooKeeper的活动会话时才具有非零值。 |
log_pointer | UInt64 | 副本复制到其执行队列的常规活动日志中的最大条目数,再加一。如果log_pointer比log_max_index小,则说明有问题。 注意 存在与ZooKeeper的活动会话时才具有非零值。 |
last_queue_update | DateTime | 上次更新队列的时间。 注意 存在与ZooKeeper的活动会话时才具有非零值。 |
absolute_delay | UInt64 | 当前副本最大延迟时间。单位为秒。 注意 存在与ZooKeeper的活动会话时才具有非零值。 |
total_replicas | UInt8 | 此表的已知副本总数。 |
active_replicas | UInt8 | 在ZooKeeper中具有会话的此表的副本的数量(即正常运行的副本的数量)。 |
示例:您可以执行以下命令,查看表信息。
SELECT * FROM system.replicas WHERE table = 'visits' FORMAT Vertical
返回信息如下。

system.storage_policies
该表包含了有关存储策略和卷的优先级相关的信息。
| 参数 | 数据类型 | 描述 |
policy_name | String | 存储策略的名称。 |
volume_name | String | 存储策略中定义的卷的名称。 |
volume_priority | UInt64 | 配置中定义的卷的优先级。 |
disks | String | 存储策略中定义的磁盘名称。 |
max_data_part_size | UInt64 | 可以存储在磁盘卷上的数据part的最大值。 |
move_factor | Float64 | 可用磁盘空间的比率。当比率超过配置参数的值时,数据将会被移动到下一个卷。 |
示例:您可以执行以下命令,查看表信息。
SELECT * FROM system.storage_policies
返回信息如下。

system.disks
该表包含了配置中定义的磁盘信息。
| 参数 | 数据类型 | 描述 |
name | String | 配置的磁盘名称。 |
path | String | 文件系统中挂载的磁盘路径。 |
free_space | UInt64 | 磁盘上的可用空间(Bytes)。 |
total_space | UInt64 | 磁盘的总空间(Bytes)。 |
keep_free_space | UInt64 | 磁盘上需要保持空闲的空间。定义在磁盘配置的keep_free_space_bytes 参数中。 |
示例:您可以执行以下命令,查看表信息。
SELECT * FROM system.disks;
返回信息如下。

三、监控
EMR 上的 ClickHouse 集群提供了完善的监控体系,分为服务监控和节点监控两个维度。
背景信息
ClickHouse 集群服务监控只有 ClickHouse 和 Zookeeper 服务。在集群监控大盘的集群指标页面,可以查看不同组件的监控数据,可以根据需求选择时间粒度。
前提条件
已创建 ClickHouse 集群,详情请参见操作指南02期--快速入门
查看服务监控
1. 进入监控大盘页面
a. 登录阿里云E-MapReduce控制台:
https://emr.console.aliyun.com/
b. 在顶部菜单栏处,根据实际情况选择地域和资源组。
c. 单击上方的监控大盘页签。
2. 单击上方的集群指标页签。
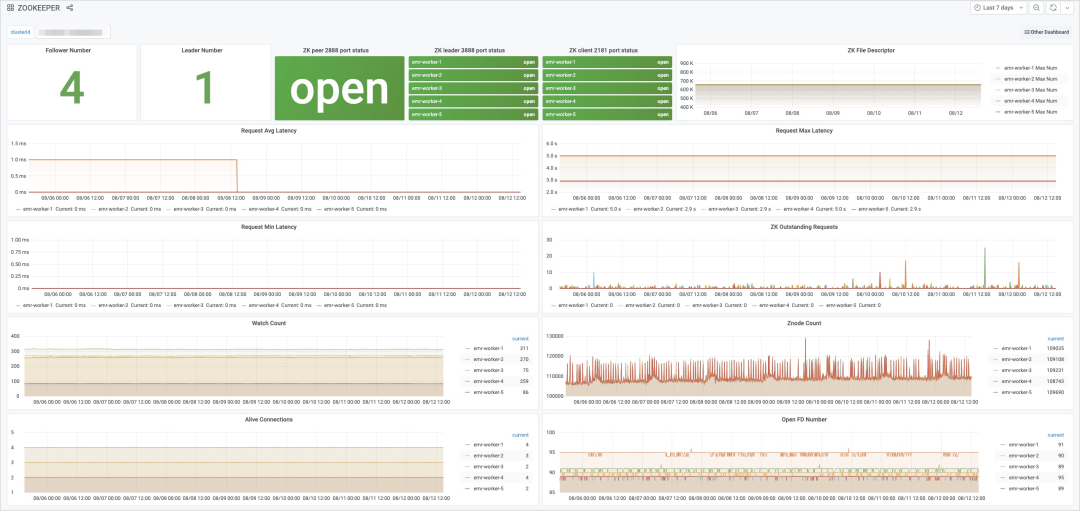
单击 HOST,选择 ZOOKEEPER 服务。
单击 HOST,选择 CLICKHOUSE 服务。
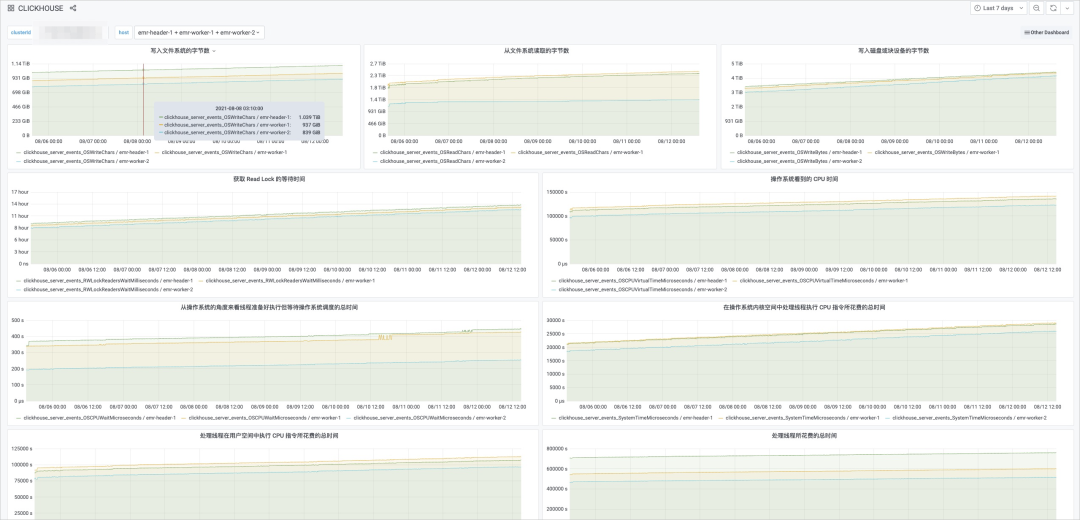
ClickHouse 的监控指标分为3组,分别来自 ClickHouse 的三个系统表metrics、events 和
asynchronous_metrics。
查看节点监控
查看节点监控又分为节点部署状态和查看节点详细监控指标。
查看部署状态
1. 进入集群详情页面
a. 登录阿里云 E-MapReduce 控制台。
b. 在顶部菜单栏处,根据实际情况选择地域和资源组。
c. 单击上方的集群管理页签。
d. 在集群管理页面,单击相应集群所在行的详情。
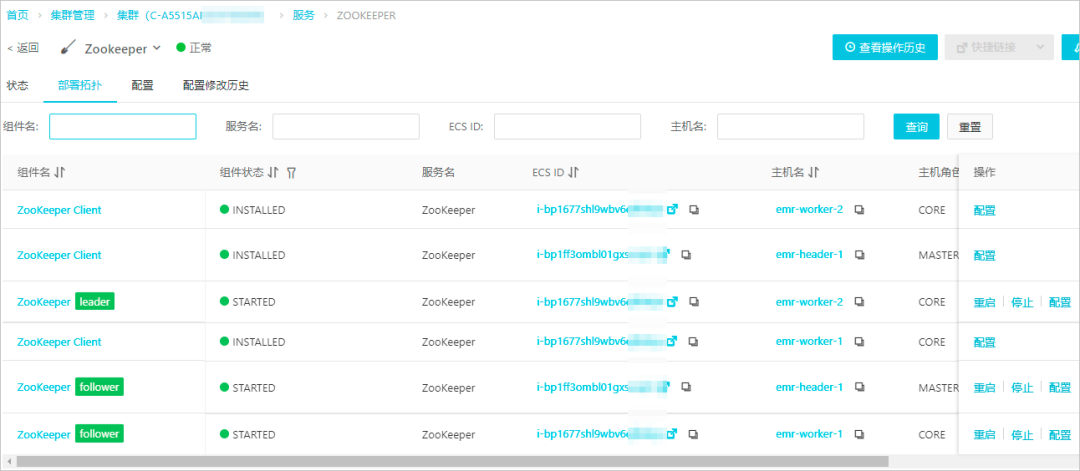
2. 查看 Zookeeper 服务或 ClickHouse 服务的监控数据。
a. 在左侧导航栏中,选择集群服务 > Zookeeper。ClickHouse服务,需要选择集群服务 > ClickHouse。
b. 单击部署拓扑页签。该页面展示了部署服务的进程的实时状态,方便您监控组件的情况。
查看节点详细监控指标
1. 进入监控大盘页面
a. 登录阿里云 E-MapReduce 控制台。
b. 在顶部菜单栏处,根据实际情况选择地域和资源组。
c. 单击上方的监控大盘页签。
2. 单击上方的集群指标页签。
3. 从 clusterid 下拉列表中,选择您创建的集群 ID,hostname 下拉列表中,选择节点名称。该页面展示了节点具体的监控指标的情况,包括 Load、Disk、内存、网络和 TCP 等信息。

四、配置项说明
EMR 的 ClickHouse 集群中,主要提供了四种服务配置项以配置 ClickHouse 集群,包括客户端配置、服务端配置、用户权限配置和拓展配置。
背景信息
ClickHouse 集群提供的四种服务配置项信息如下表。
| 配置项 | 详细 |
| 客户端配置 | client-config |
| 服务端配置 | server-config |
| 拓展配置 | server-metrika |
| 用户权限配置 | 访问权限控制 |
前提条件
https://help.aliyun.com/document_detail/28088.htm
注意事项
如果配置可以直接填写在 yandex 标签下,则可以直接新增。 如果配置包含多层嵌套,每层需要直接使用半角句号(.)进行连接。例如,在 server-users 页签中,添加新的用户 aliyun,可以设置参数为 users.aliyun.password,参数值为密码,您可以自定义。
自定义配置中,请勿使用 XML 类型作为参数或者参数值。
client-config
该服务配置项用于生成 clickhouse-client 所使用的 config.xml 文件。您可以在 EMR 控制台 ClickHouse 服务的配置页面,单击 client-config 页签,查看以下参数。
| 配置项 | 描述 |
| user | 设置clickhouse-client使用的用户。默认值为default。 |
| password | 设置clickhouse-client进程使用的用户密码。默认值为空。 |
| prompt_by_server_display_name.production | 在使用clickhouse-client的时候,允许自定义提示符。设置这个选项以配置在不同的display_name情况下的提示符,例如在server-config选项中设置display_name为default时,所展示的提示符为prompt_by_server_display_name.default中所设置的值。设置提示符允许使用的颜色,请参见 |
prompt_by_server_display_name.default | |
prompt_by_server_display_name.test |
server-config
该服务配置项用来生成 clickhouse-server 进程所使用的 config.xml 文件。您可以在 EMR 控制台 ClickHouse 服务的配置页面,单击 server-config 页签,查看以下参数。
| 配置项 | 描述 |
| tcp_port | 通过TCP协议与客户端通信的端口。默认值为9000。 |
| logger.count | 存档的ClickHouse日志文件个数。当存档的日志文件个数达到该参数设置的值时,ClickHouse会将最早的存档删除。默认值为10。 |
| logger.errorlog | ClickHouse Server中错误日志的输出路径。默认值为/var/log/clickhouse-server/clickhouse-server.err.log。 |
| logger.level | 日志的等级,默认等级为information。可以配置的等级从严格到宽松依次为none(关闭日志)、fatal、critical、error、warning、notice、information、debug和trace。 |
| logger.size | 日志文件的大小。当文件达到该参数设置的值时,ClickHouse会将其存档并重命名,并创建一个新的日志文件。默认值为1000M。 |
| logger.path | ClickHouse Server正常输出的日志文件,默认为/var/log/clickhouse-server/clickhouse-server.log,会输出符合logger.level所指定的日志等级的日志。 |
| access_control_path | ClickHouse Server用于存储SQL命令创建的用户和角色配置的文件夹的路径。默认值为/var/lib/clickhouse/access/。 |
| user_files_path | 用户文件的目录。会在表的函数file()中被使用。默认值为/var/lib/clickhouse/user_files/。 |
| path_to_regions_hierarchy_file | 用于ClickHouse内部字典,包含区域层次结构的文件的路径。默认值为空。 |
| path_to_regions_names_files | 用于ClickHouse内部字典,包含区域名称的文件的路径。默认值为空。 |
| distributed_ddl.path | 该参数指定了ZooKeeper中用于存储DDL查询队列的路径。默认值为/clickhouse/task_queue/ddl。默认情况下,ClickHouse的操作CREATE、DROP、ALTER和RENAME等都只会影响正在处理查询的这一台机器。设置distributed_ddl相关参数,允许ClickHouse的查询运行在集群中(当且仅当ZooKeeper被使用时)。 |
| tmp_policy | 用于存放处理大型查询时产生的临时数据。默认值为空。 从server-metrika服务配置项中的storage_configuration选项中设置的磁盘策略选择一个来设置。 说明 如果此项为空,则使用tmp_path,否则tmp_path会被忽略。 |
| path | 包含数据的目录的路径,末尾必须加上正斜线(/)。默认值为/var/lib/clickhouse/。 |
| https_port | 通过HTTPS连接到服务器的端口。指定此参数时,必须配置OpenSSL相关参数。如果指定了http_port,此参数会被忽略。默认值为空。 |
| query_log.flush_interval_milliseconds | 如果在使用的profile中设置了log_queries=1,则会记录下参与了查询操作的线程信息,这些信息会被记录在表中。query_log系列参数可以来配置此行为,支持的系列参数如下:
|
| query_log.engine | |
| query_log.partition_by | |
| query_log.database | |
| query_log.table | |
| interserver_http_credentials.user | 如果表使用的引擎是Replicated*类型的,通常情况下,复制是不需要进行身份验证的,但可以通过设置这些参数开启身份验证。这个凭据仅用于副本之间的通信,与ClickHouse客户端的凭据无关。
|
| interserver_http_credentials.password | |
| mlock_executable | 当ClickHouse启动后执行mlockall可以降低首个查询延迟,并防止在高IO负载下调出ClickHouse可执行文件。默认值为false。 说明 建议启用此选项,尽管启用此选项会导致启动时间增加几秒钟。 |
| trace_log.table | 如果在使用的profile中query_profiler_real_time_period_ns和query_profiler_cpu_time_period_ns其中任意一个值非0,则会将query profiler记录的stack trace存放到表中。trace_log支持的系列参数如下:
|
| trace_log.database | |
| trace_log.partition_by | |
| trace_log.engine | |
| trace_log.flush_interval_milliseconds | |
| disable_internal_dns_cache | 值非0时禁用内部DNS缓存。默认值为0。 说明 推荐在环境经常变化的系统中使用。例如,Kubernetes。 |
| listen_reuse_port | 是否允许Socket间复用相同的Port。取值如下:
|
| query_thread_log.table | 如果在使用的profile中设置log_query_threads=1,则会记录下参与了查询操作的线程信息,这些信息会被记录在表中。
|
| query_thread_log.database | |
| query_thread_log.partition_by | |
| query_thread_log.engine | |
| query_thread_log.flush_interval_milliseconds | |
| default_database | 默认数据库。默认值为default。 |
| http_server_default_response | 访问ClickHouse的HTTP Server时,默认返回的页面。 |
| display_name | ClickHouse Server端设置的客户端默认提示信息。默认值为空。 |
| builtin_dictionaries_reload_interval | 重新加载内置字典的间隔时间,单位为秒。默认值为3600。 |
| umask | 文件权限掩码。默认值为027,表示其他用户(操作系统用户)无法读取日志和数据等文件,相同组的用户仅可以读取。 |
| uncompressed_cache_size | 表引擎使用MergeTree时,为解压后的block所建立的Cache大小。默认值为0。 如果设置为0,则表示不启用Cache。 |
| timezone | 设置服务器的时区。默认值为Asia/Shanghai。 |
| max_session_timeout | Session最大超时时间,单位为秒。默认值为3600。 |
| default_session_timeout | Session默认超时时间,单位为秒。默认值为60。 |
| max_open_files | 打开文件的最大数量。默认值为262144。 说明 该参数与操作系统有关联关系,当此值设置为空时,ClickHouse会使用操作系统设定的max_open_files。 |
| tmp_path | 用于处理大型查询的临时数据的路径,末尾必须带上正斜杠(/)。默认值为/var/lib/clickhouse/tmp/。 |
| max_concurrent_queries | 可以同时处理查询的最大数量。默认值为100。 |
| tcp_port_secure | 用于与客户端安全通信的TCP端口。默认值为空。 说明 配置此参数时,需要设置OpenSSL相关参数。 |
| listen_try | 如果通过listen_host所指定的协议(IPv4或IPv6)不可用时,是否立刻退出:
|
| mysql_port | 通过MySQL协议与客户端通信的端口。 |
| keep_alive_timeout | ClickHouse在关闭连接之前等待传入请求的秒数,单位为秒。默认值为3。 |
| max_connections | 允许连接的最大数量。默认值为4096。 |
| dns_cache_update_period | 设置更新存储在ClickHouse内部DNS缓存中的IP地址的周期,单位为秒。默认值为15。 更新会在单独系统线程中异步进行。 |
| path_to_regions_names_files | 用于ClickHouse内部字典的,包含区域名称的文件的路径。默认为空。 |
| include_from | ClickHouse Server中的配置文件是利用XML编写的,其中有一些XML标签中包含了incl属性,这些标签的内容是可以被include_from配置所引用的文件中对应的配置所替换的。默认值为/etc/ecm/clickhouse-conf/clickhouse-server/metrika.xml。 |
| interserver_http_port | ClickHouse服务器之间交换数据的端口。默认值为9009。 |
| dictionaries_config | 外部字典的配置文件路径。路径可以包含通配符半角句号(.)、星号(*)和半角问号(?)。默认值为*_dictionary.xml。 |
| http_port | 通过HTTP连接到服务器的端口。默认值为8123。 ClickHouse官方JDBC也通过此端口访问ClickHouse,请参见 clickhouse-jdbc: |
| users_config | 包含用户配置、访问权限、设置配置文件和资源限制配置等配置的文件路径。默认值为users.xml。 |
| dictionaries_lazy_load | 延迟加载字典。取值如下:
|
| listen_host | ClickHouse服务器所监听的IP地址。可以指定IPv4和IPv6的地址,如果指定::则代表允许所有地址。可以设置多个IP地址,多个IP地址以逗号(,)分割。例如,127.0.0.1,localhost。默认值为0.0.0.0。 |
| default_profile | 默认会使用的profile。默认值为default。 |
| mark_cache_size | 表引擎使用MergeTree时,mark索引所使用的Cache大小的近似值。默认值为5368709120,单位为Byte。 |
| listen_backlog | 设置backlog的数量。默认值为64。 |
| format_schema_path | 存放输入数据Schema的目录。默认值为/var/lib/clickhouse/format_schemas/。 |
server-metrika
该服务配置项用于生成 metrika.xml 文件,其默认被 ClickHouse Server 的 config 所引用。您可以在 EMR 控制台 ClickHouse 服务的配置页面,在默认的 server-config 页签,查看以下参数。
| 配置项 | 描述 |
| clickhouse_compression | 为使用 MergeTree 相关引擎的表设置数据压缩,详细信息请参见 Server Settings: 如果需要使用 ClickHouse 的压缩,请自行添加配置。 |
| storage_configuration | 用来指定自定义的磁盘信息。阿里云 E-MapReduce 默认会自动为每块磁盘创建 ClickHouse 的数据目录,并且为这些磁盘创建一个 HDD in order 的磁盘策略。 |
| zookeeper_servers | 用来配置ClickHouse集群所使用的ZooKeeper信息。默认值为创建ClickHouse集群时同时创建的ZooKeeper的值。多个ZooKeeper节点时,请使用英文逗号(,)进行分隔,例如,emr-header-1.cluster-12345:2181,emr-worker-1.cluster-12345:2181,emr-worker-2.cluster-12345:2181。 |
| quotas_default | ClickHouse允许配置不同的quota以灵活的使用不同的资源限制。修改该配置项可以修改名为default的quota设置。如果需要添加新的quota设置,您可以添加自定义设置。 |
| clickhouse_remote_servers | 用来自定义集群的分片和副本信息。默认值为创建ClickHouse集群时设置的Shard和Replica数量所生成的拓扑。 |
例如,创建集群时设置2个 Shard 和2个 Replica,则 clickhouse_remote_servers 值如下所示:

例如,服务器上包含4块磁盘时,则 storage_configuration 值如下所示:

相关文档
ClickHouse 参数的详情信息,可以参见以下官方文档:
Server Settings:
https://clickhouse.tech/docs/en/operations/server-configuration-parameters/settings/Settings:
https://clickhouse.tech/docs/en/operations/settings/settings/?spm=a2c6h.12873639.0.0.459d1b48UXVzkEMergeTree tables settings:
https://clickhouse.tech/docs/en/operations/settings/merge-tree-settings/
后续步骤
如果需要修改或添加配置项,请参见管理组件参数:
https://help.aliyun.com/document_detail/106171.htm
五、访问权限控制
EMR 的 ClickHouse 集群中,主要提供了四种服务配置项以配置 ClickHouse 集群,包括客户端配置、服务端配置、用户权限配置和拓展配置。
背景信息
用户访问权限配置在 server-users 和 server-metrika 文件中,包含 users、profiles 和 quotas 三部分配置。详细配置信息:
users 配置
profiles 配置
quotas 配置
说明: ClickHouse 服务的客户端配置、服务端配置和拓展配置的详细信息,请参见前文配置项说明。
前提条件
已创建 E-MapReduce 的 ClickHouse 集群
users 配置
您可以在 ClickHouse 服务配置页面的服务配置区域,查看或修改配置。users 配置在 server-users 页签中。
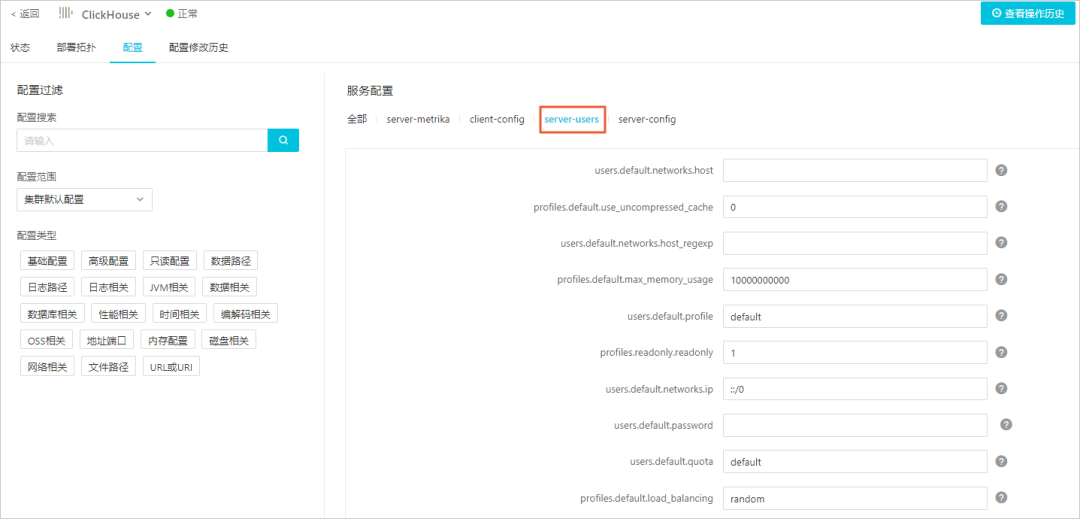
| 参数 | 描述 |
| users.default.networks.host | default用户允许访问的主机名,默认值为空。 多个主机名时,可以使用英文逗号(,)分隔。 |
| users.default.networks.host_regexp | default用户允许访问的主机名的正则表达式,默认值为空。 多个表达式时,可以使用英文逗号(,)分隔。 |
| users.default.networks.ip | default用户允许访问的IP地址。默认值为::/0, 表示允许所有IP地址访问。 多个IP地址时,可以使用英文逗号(,)分隔。 注意 请确保users.default.networks.ip、users.default.networks.host和users.default.networks.host_regexp三个参数中,至少有一个参数值不为空,否则可能会导致网络不通。 |
| users.default.profile | default用户默认使用的profile名称。默认值为default。 |
| users.default.password | ClickHouse Server中default用户的密码。默认值为空。 注意 不建议使用此配置。建议您添加自定义参数users.default.password_sha256_hex或users.default.password_double_sha1_hex以设置密码。
|
| users.default.quota | default用户默认使用的quota配置。默认值为default。 |
profiles 配置
您可以在 ClickHouse 服务配置页面的服务配置区域,查看或修改配置。profiles 配置在 server-users 页签中。
| 参数 | 描述 |
| profiles.default.max_memory_usage | 用于设置名为 default 的 profile 中 max_memory_usage 的值。修改该参数可以设置单个查询时所能够使用的最大内存。 默认为10,000,000,000,单位为byte。 |
| profiles.default.use_uncompressed_cache | 用于设置名为default的profile中use_uncompressed_cache的值。
|
| profiles.default.load_balancing | 用于设置名为default的profile中load_balancing的值。可以设置在分布式查询处理中选择副本的策略。 策略详细信息,请参见Settings。 |
| profiles.readonly.readonly | 用于设置名为readonly的profile中readonly的值。
|
quotas 配置
您可以在 ClickHouse 服务配置页面的服务配置区域,查看或修改配置。quotas 配置在 server-metrika 页签中。
quotas_default:ClickHouse 允许配置不同的 quota 以灵活的使用不同的资源限制。修改该配置项可以修改名为 default 的 quota 设置(users.default.quota)。
如果需要添加新的 quota 设置,你可以单击右上角的自定义配置,详细操作请参见添加组件参数:
https://help.aliyun.com/document_detail/106171.htm
后续
您已经学习了 ClickHouse 运维,本系列还包括其他内容:
数据导入
常见问题
获取更详细的信息,可至产品文档页查看:
EMR官网:
https://www.aliyun.com/product/emapreduce
EMR ClickHouse :
https://help.aliyun.com/document_detail/212195.html
扫描下方二维码加入阿里云 EMR 相关产品钉钉交流群一起参与讨论吧!

