




译者
韩宗泽(棕泽),阿里云计算平台事业部技术专家,负责开源大数据生态企业团队的研发工作
前言
本文翻译自大数据技术公司 Databricks 针对数据湖 Delta Lake 系列技术文章。众所周知,Databricks 主导着开源大数据社区 Apache Spark、Delta Lake 以及 ML Flow 等众多热门技术,而 Delta Lake 作为数据湖核心存储引擎方案给企业带来诸多的优势。
此外,阿里云和 Apache Spark 及 Delta Lake 的原厂 Databricks 引擎团队合作,推出了基于阿里云的企业版全托管 Spark 产品——Databricks 数据洞察,该产品原生集成企业版 Delta Engine 引擎,无需额外配置,提供高性能计算能力。有兴趣的同学可以搜索` Databricks 数据洞察`或`阿里云 Databricks`进入官网,或者直接访问以下链接进行了解:
https://www.aliyun.com/product/bigdata/spark
本系列还包括其他内容,欢迎持续关注:
第一章:基础和性能
01、Delta Lake基础:为什么可靠性和性能很重要?>>
02、深入理解事务日志 / 如何使用Schema约束和演变>>
03、(本文)Delta Lake DML语法 / 在Delta Lake中使用 Data Skipping和Z-Ordering来快速处理PB级数据
第二章:特性
第三章:Lakehouse
第四章:Streaming
第五章:客户用例

Delta Lake技术系列 - 基础和性能
(Fundamentals and Performance)
——使用 Delta Lake 为机器学习和商业智能提供可靠的数据保障

Chapter-04 Delta Lake DML(数据操作语言)

Delta Lake 支持数据操作语言(DML)命令,包括更新(UPDATE)、删除(DELETE)和合并(MERGE)。这些命令简化了数据变更(CDC)、审计和治理,以及GDPR/CCPA 等工作流程。
在本章中,我们将演示如何使用这些 DML 命令,来描述 Delta Lake 在幕后所做的工作,并为每一个命令提供一些性能调优技巧。
Delta Lake DML:UPDATE
可以使用 UPDATE 操作来有选择地更新与过滤条件匹配(也称为谓词)的任何行。下面的代码演示了如何将每种类型的谓词用作来 UPDATE。请注意,Delta Lake 提供了 Python、Scala 和 SQL 的 API,但在本电子书中,我们只包含 SQL 代码。
-- Update eventsUPDATE events SET eventType=‘click’ WHERE buttonPress = 1
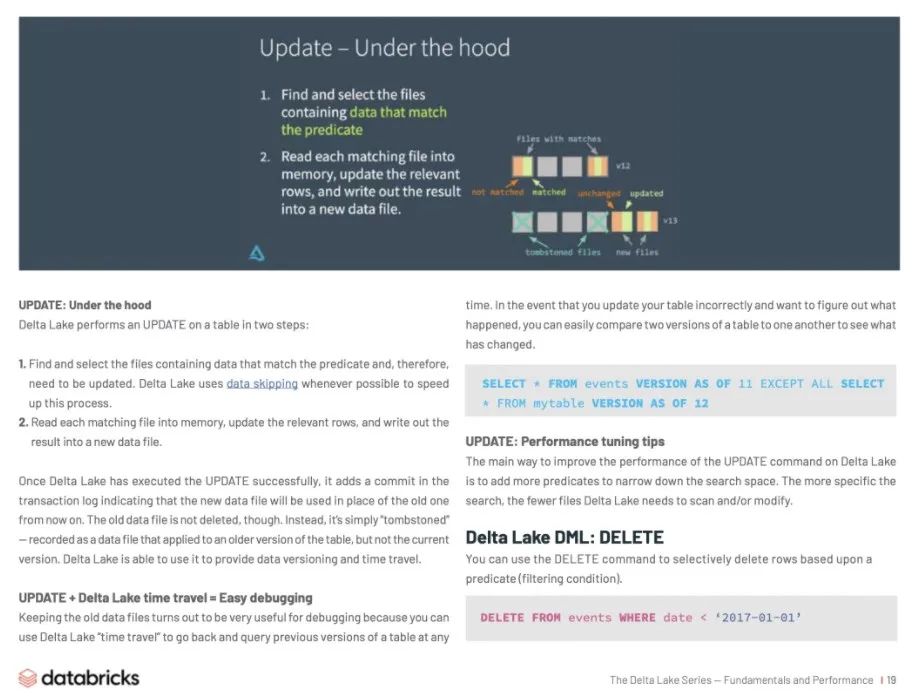
更新(UPDATE):底层原理
Delta Lake 分两步对表执行 UPDATE:
查找并选择包含与谓词匹配的数据的文件,这些文件是需要更新的。Delta Lake 尽可能使用 Data Skipping 来加速这个过程。
将每个匹配文件读入内存,更新相关行,并将结果写入新的数据文件。
一旦 Delta Lake 成功地执行了 UPDATE 操作,它就会在事务日志中添加一个 commit,表示从现在起将使用新的数据文件代替旧的数据文件。不过,旧数据文件并不会被删除。相反,它只是简单的“逻辑删除”——会记录为应用于表的旧版本的数据文件,而不是当前版本的数据文件。Delta Lake 能够使用这个逻辑来提供数据版本控制(Version control)和时间旅行(Time travel)。
UPDATE + Delta Lake Time Travel = 易于Debugging
保留旧数据文件对于调试 debug 非常有用,因为您可以使用 Delta Lake “时间旅行”随时返回并查询表的早期版本。如果您错误地更新了表,并且想知道发生了什么,您可以很容易地将一个表的两个版本相互比较,以查看发生了什么变化。
SELECT * FROM events VERSION AS OF 11 EXCEPT ALL SELECT* FROM mytable VERSION AS OF 12
UPDATE:性能优化 tips
优化 Delta Lake 中 UPDATE 命令性能的主要方法是,添加更多谓词以缩小搜索空间(精确更新数据的范围)。搜索越具体,Delta Lake 需要扫描或修改的文件就越少。
Delta Lake DML:DELETE
可以使用 DELETE 命令根据谓词(过滤条件)有选择地删除行。
DELETE FROM events WHERE date < ‘2017-01-01’
如果要还原意外的删除操作,可以使用时间旅行将表回滚到原来的状态。

删除(DELETE):底层原理
删除(DELETE)如更新(UPDATE)原理类似。Delta Lake 对数据进行两次扫描:第一次扫描是识别包含与谓词条件匹配的行的任何数据文件,第二次扫描将匹配的数据文件读入内存,此时 Delta Lake 会在将新的数据写入磁盘之前删除所选行。
Delta Lake 成功完成删除操作后,旧数据文件不会被完全删除——它们仍保留在磁盘上,但在 Delta Lake 事务日志中记录为“tombstoned”(不再是活动表的一部分)。
请记住,Delta Lake 不会立即删除这些旧文件,因为您可能仍然需要它们时间旅行回到表的早期版本。如果要删除超过某个时间段的文件,可以使用 VACUUM
命令。
删除(DELETE)+ VACUUM:清理旧的数据文件
运行 VACUUM 命令将永久删除以下所有数据文件:
已不再是当前表的部分数据,并且:
早于保留阈值,默认为7天
Delta Lake 不会自动清空旧文件——您必须自己运行命令清除,如下所示。如果要指定不同于默认七天的保留期,可以将其作为参数提供。
from delta.tables import * deltaTable.# vacuum files older than 30 days(720 hours)deltaTable.vacuum(720)

删除(DELETE):性能优化tips
与 UPDATE 命令一样,优化 Delta Lake 上 DELETE 操作性能的主要方法是,添加更多谓词以缩小搜索空间。Delta Lake 的 Databricks 管理版本(Databricks Runtime 企业版)还具有其他性能增强功能,如改进的 Data Skipping、bloom 过滤器和 Z-Order 优化(多维集群)。
Delta Lake DML: MERGE
Delta Lake MERGE 命令允许您执行 Upserts,这是更新(UPDATE)和插入(INSERT)的混合操作。要理解 Upserts,假设您有一个当前表(也称为目标表)和一个源表,其中包含新记录和对现有记录的更新。
下面是 upsert 的工作原理:
当源表中的记录与目标表中预先存在的记录匹配时,Delta Lake 会更新该记录。
如果没有这样的匹配,Delta Lake 将插入新记录。
Delta Lake MERGE 命令极大地简化了工作流程,这些工作流程与其他传统数据格式(如Parquet)相比可能非常复杂和繁琐。合并(MERGE)和升级(Upserts)带来便利的常见场景包括更改数据捕获、GDPR/CCPA 遵从性、会话化和记录的重复数据消除。

MERGE:底层原理
Delta Lake 分两步完成 MERGE 操作:
在目标表和源表之间执行内部联接,以选择所有匹配的文件。
在目标表和源表中的选定文件之间执行外部联接,并写出更新(UPDATE)/删除(DELETE)/插入(INSERT)的数据。
这与更新或删除不同的主要方式是,Delta Lake 使用连接(Join)来完成合并,这一事实允许我们在性能优化时使用一些独特的策略。
MERGE:性能优化 tips
为了提高 MERGE 命令的性能,您需要确定组成合并的两个连接中的哪一个限制了您的速度。如果内部连接是瓶颈(即,查找 Delta Lake 需要重写的文件花费的时间太长),请尝试以下策略:
添加更多谓词以缩小搜索空间。
调整随机分区。
调整广播连接阈值。
压缩表中的小文件(如果有很多),但不要压缩
因为 Delta Lake 必须复制整个文件才能重写它,所以将它们转换为太大的文件。
在 Databricks 版本的 Delta Engine(企业版 Databricks Runtime)中,使用 Z-Ordering 优化来利用更新的位置。
另一方面,如果外部连接是瓶颈(即重写实际文件本身花费的时间太长),请尝试以下策略。
调整随机分区。
通过在写入前启用自动重新分区来减少文件(在 Databricks Delta Lake 中优化写入)。
调整广播阈值。如果正在执行完全外部联接,Spark 无法执行广播联接,但是如果正在执行正确的外部联接,Spark 可以执行一个,并且可以根据需要调整广播阈值。
缓存源表 / DataFrame。
缓存源表可以加快第二次扫描,但请确保不要缓存目标表,因为这可能导致缓存一致性问题。
Delta Lake 支持 DML 命令,包括 UPDATE、DELETE 和 MERGE-INTO,这大大简化了许多常见大数据操作的工作流。在本章中,我们演示了如何在 Delta Lake 中使用这些命令,分享了关于每个命令的工作原理,并提供了一些性能调优技巧。

Chapter-05 Delta Lake如何使用Data Skipping和Z-Ording快速处理PB级别数据

Delta Lake 能够在几秒钟内筛选出数 PB 级数据。这种速度主要归功于两个特性:(1)Data Skipping和(2)Z-Ordering。
结合这些特性有助于 Databricks 运行时显著减少需要扫描的数据量,以针对大型 Delta表的选择性查询,这通常转化为运行时的显著改进和成本节约。
使用 Delta Lake 内置的 Data Skipping 过和 Z-Ordering 集群功能,通过跳过与查询无关的文件,可以在几秒钟内查询到大型云上数据湖数据。例如,在一个网络安全分析用例中,对于典型的查询,504TB数据集中93.2%的记录被跳过,从而将查询时间减少了两个数量级。换句话说,Delta Lake 可以将您的查询速度提高100倍之多。
想了解 Data Skipping 和 Z-Ordering 的实际应用吗?
Apple 的 Dominique Brezinski 和 Databricks 的 Michael Armbrust 演示了如何在网络安全监控和威胁应对的背景下,将 Delta Lake 作为数据工程和数据科学的统一解决方案。
了解他们的主题演讲:
「 Threat Detection and Response at Scale」
https://databricks.com/session/keynote-from-apple

使用 Data Skipping 和 Z-Ordering
Data Skipping 和 Z-Ordering 被用来提升对大规模数据集的查询性能。Data Skipping 过是 Delta Lake 的一项自动化功能,每当您的 SQL 查询或数据集操作包含“column op literal”形式的过滤器时,就会自动跳过,其中:
column 是一些 Delta Lake 表的一个属性,无论是顶级的还是嵌套的,其数据类型 为string/numeric/date/timestamp
op 是一个二进制比较运算符,StartsWith/LIKE pattern%',或 IN
literal 是与列具有相同数据类型的显式(列表)值
AND/OR/NOT 以及“literal op column”谓词也受支持。即使 Data Skipping 过在满足上述条件时起作用,它也未必总是有效的。但是,如果有一些列是您经常筛选的,并且希望确保快速筛选,则可以通过运行以下命令显式优化数据布局,以跳过有效性:
OPTIMIZE [WHERE ]
ZORDER BY ( [, ...])
探索细节
除了分区裁剪之外,数据仓库世界中使用的另一种常见技术( Spark 目前缺乏这种技术)是基于小型物化聚合的I/O裁剪。简言之,其思想是跟踪与I/O粒度相关的简单统计信息,例如特定粒度下的最小值和最大值。我们希望在查询规划时利用这些统计信息,以避免不必要的I/O。
这是 Delta Lake 的 Data Skipping 功能所涉及的内容。在将新数据插入 Delta Lake 表时,将收集受支持类型的所有列(包括嵌套列)的文件级最小/最大统计信息。然后,当对表进行查找查询时,Delta Lake 首先查询这些统计信息,以便确定哪些文件可以安全地跳过。
想了解更多关于 Data Skipping 和 Z-Ordering 的信息,包括如何在网络安全分析中应用它吗?
阅读我们的博客>
https://databricks.com/blog/2018/07/31/processing-petabytes-of-data-in-seconds-with-databricks-delta.html

后续
您已经了解了 Delta Lake 及其特性,以及如何进行性能优化,本系列还包括其他内容,欢迎持续关注:
第二章:特性
第三章:Lakehouse
第四章:Streaming
第五章:客户用例
也可点击文章下方阅读原文,查看所有本系列文章~
获取更详细的 Databricks 数据洞察 相关信息,可至产品详情页查看:
https://www.aliyun.com/product/bigdata/spark
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,技术专家直播,只为营造纯粹的 Spark 氛围,欢迎关注公众号!

