





文章链接: https://arxiv.org/pdf/2312.10302
代码链接: https://github.com/pldlgb/nuggets
摘要
主要方法
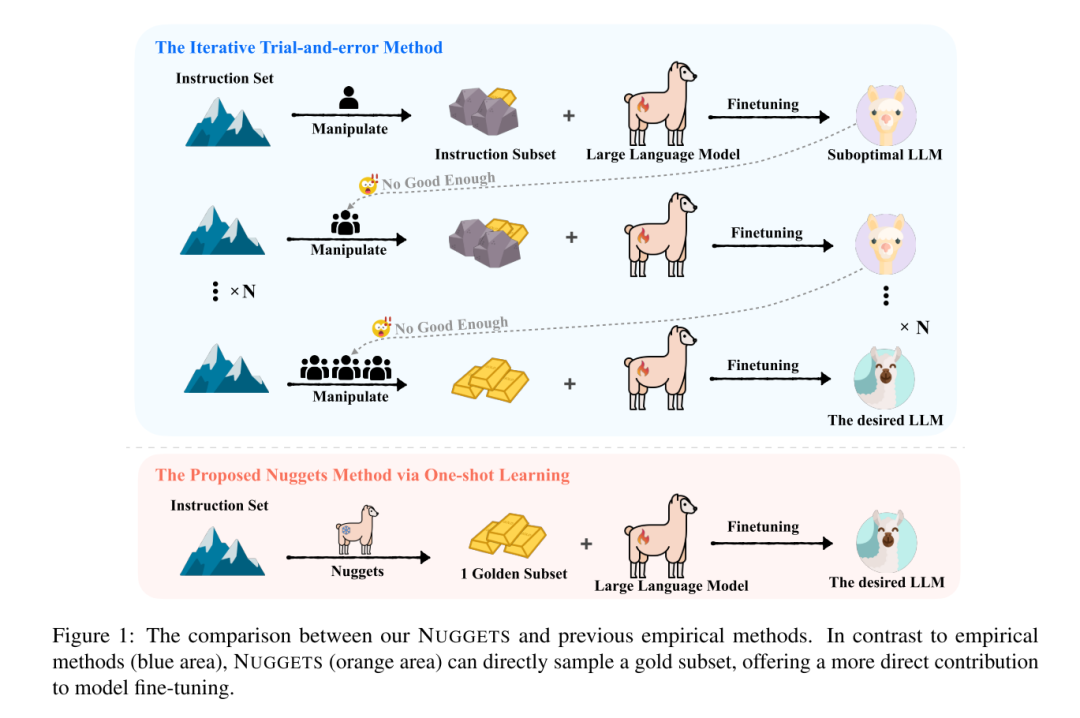
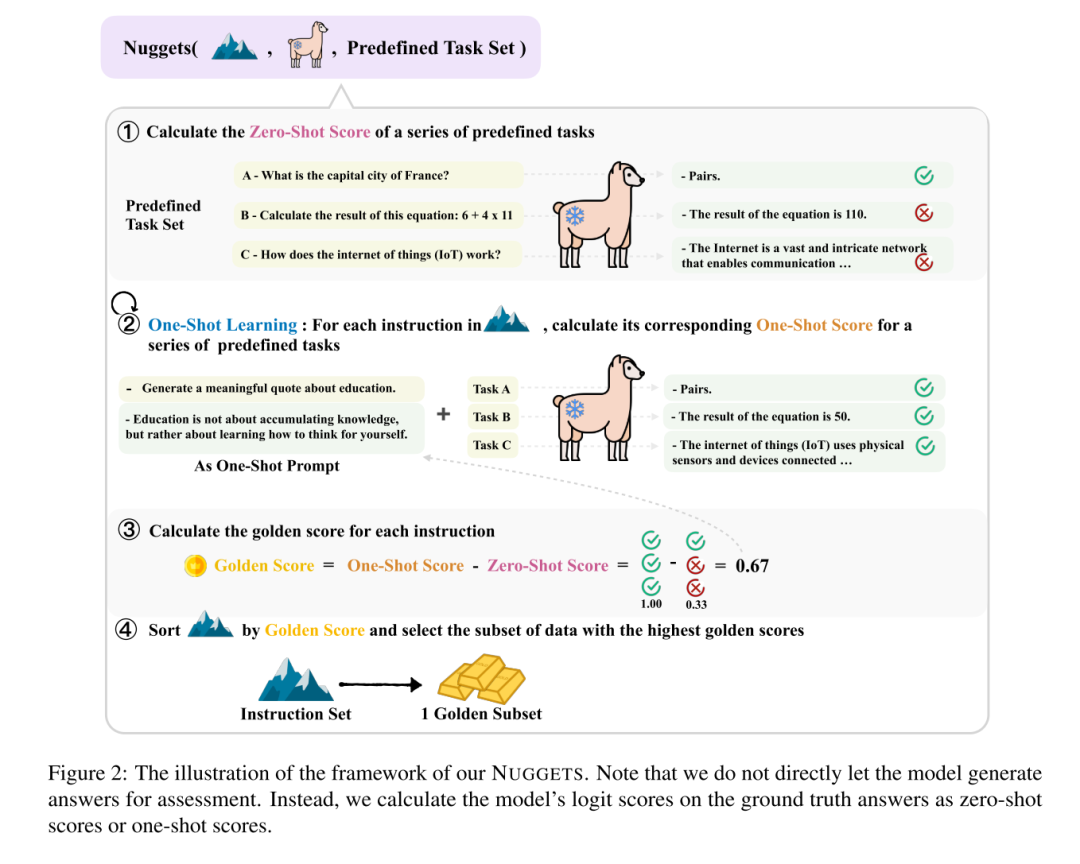
计算零样本评分(Zero-Shot Score)这里有三个预定义的任务(A、B、C),并给出了模型在没有额外提示词指令下的表现。例如: 任务A:法国首都是哪里(可以正确回答) 任务B:计算数学方程(解方程错误) 任务C:解释物联网的工作原理(解释错误) 一次性学习(One-Shot Learning):针对每个指令,计算其对应的One-Shot评分 选择两个个指令示例(Education is not about accumulating knowledge, but rather about learning how to think for yourself、Generate a meaningful quote about education)给到任务ABC。三个任务都得到了正确的答案。 计算每个指令的黄金得分(Golden Score) 黄金得分是通过比较One-Shot和零样本之间的差异得出的。在这个例子中,我们看到模型在添加了指令后,表现有了显著的提高。Golden Score的计算公式如下:
按黄金得分排序并选择最高得分的指令子集 最后,我们根据黄金得分对所有的指令示例进行排序,并选择得分最高的那个子集。这个子集就是所谓的“黄金子集”。使用黄金子集的指令和数据集中的所有输入组合作为指令微调的数据集即可。
总结
编者简介

文章转载自AI 搜索引擎,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
