




1、介绍
网格计算的概念及其相关技术已经被引入到越来越多需要高性能计算能力的领域。网格计算技术不仅可以集成地理上分布的资源,形成一个超级虚拟计算系统,而且可以使许多人协同处理许多科学和工程领域中的一些大规模问题。实现这些应用程序的主要方法是将大任务划分为小部分并并行处理。通常有两种划分的任务:有依赖关系的任务和没有依赖关系的工作。具有相关性的划分任务将具有任务间通信,并且它们需要按特定顺序执行。另一方面,没有依赖性的划分任务可以按任意顺序执行,并且它们只需要在应用程序结束时进行任务同步处理。这种应用模型也称为任务包(BoT)/参数扫描。在该模型中工作的应用程序包括MCell,SET@home, Folding@home、VizGrid、Earth System Grid等。如何将划分的任务调度到网格中的候选机器是即将到来的问题。由于任务调度问题的NP完全性,启发式方法通常是一种受欢迎的解决方案。典型的启发式任务调度算法有Min-Min算法、Max-Min算法和苦难算法。这些算法通常研究任务最小完成时间(MCT),它是数据传输时间和任务执行时间的总和。它们是在一个相当通用的模型中研究的,而没有特别考虑到不同的任务可能部分具有相同的输入文件。如果任务之间存在数据共享,那么尽可能多次地重用已经传输的数据将大大缩短任务的完成时间。XSufferage作为苦难的延伸,就是这样一种考虑到数据共享的努力。它使用集群/站点级后缀值而不是主机级后缀值,以尽可能多次地重用已存储在站点上的数据。这种算法需要副本目录的指导,该目录记录了数据源副本的位置。如果任务提交频率很高,以至于等待调度的任务无法获得副本信息,除非前一个任务完成,那么调度队列将不断增加,直到没有任务进入或调度系统崩溃。此外,如果不记录复制品,XSufferge将退化为苦难。存储亲和性(SA)算法和SIL(基于共享输入数据的列表)是不需要副本目录的调度算法。SA根据之前提交的任务为每个主机计算任务的数据传输量。将选择具有最小存储相关性的主机。SIL对一组任务进行排序,以形成一个新的提交顺序,即每个任务与前一个任务共享的数据最多。一个问题是,如果主机的存储空间不足,一些已经传输的数据将被删除,以获得用于即将到来的任务的输入数据的可用空间,但网格调度器不知道这种文件替换,并将向主机提交任务,假设删除的数据仍然存在。这有时可能会导致以下某些任务的完成时间比预期的要长。
针对上述问题,本文提出了一种新的调度算法,用于在大多数站点在副本目录上没有记录的特定网格中进行高频繁提交任务的调度。
该文件的提醒整理如下。第二节简要介绍了我们开发的合作医疗可视化网格以及该网格用于任务调度的模型。第3节介绍了所提出的算法和其他用于同情的算法。第4节显示并解释了评估结果。结论见第5节。
2、研究网格和模型
A.研究网格和网格模型
该模型的动机是我们在基于PC的协同医疗可视化网格平台上的初步应用。我们实验室最终建立了一个网格,可以充分利用医院分散的计算资源对大数据集进行快速图像可视化。网格平台是使用Globus Toolkit 4.0(GT4)构建的,这是一个用于构建网格系统和应用程序的开源软件工具包。为网页访问服务开发了一个网格门户。不同的用户可以以不同的方式对同一大图像数据集进行协作。对于可视化操作,将大型图像数据集划分为多个部分以形成子任务,而不相互依赖。同步过程中每个子任务的输出文件都很小(几十KB),在下面的分析中会忽略此同步过程的时间。任务处理时间的主要部分是每个子任务开始时的数据传输。尤其是每台PC机上的可视化功能都被部署为Web服务,其链接建立时间相当长。因此,重复使用数据将显著提高任务执行的效率。此外,许多用户的可视化请求会在岸上时间间隔内形成许多子任务。如何调度这些子任务并使其尽快完成,是保持系统满足用户协同操作需求的关键。
这种网格G由用于图像可视化处理的PC和用于存储大型图像数据集的数据服务器组成。PC被进一步划分为作为CPU的计算元件和作为磁盘空间的存储元件。在这里,我们将每个PC和数据服务器分别视为一个站点。更正式地说,其中i S是G的第i个站点,i S中的RNSEi是代表PC的硬盘的复制无记录存储元件,RRSEj是作为数据服务器的复制记录存储元件。可以发现,本文中使用的模型是,表示为PC的每个站点被建模为CE-RNSE对,并且数据服务器被独立地建模为另一个站点。将站点中的带宽视为无穷大的值,以模拟磁盘访问速度远快于站点之间的网络传输速度。
B.应用模型
由于用户协同工作,系统将不断产生许多异构的独立子任务。在一个时间间隔内,有一个任务队列{,,…,}TQ=T1-T2-Tn。子任务Ti具有属于数据源D的部分的一组输入数据{,,…}i1i2-ik D=D。
在可视化过程中,子任务所需的数据会下载到PC的指定工作目录上。该工作目录的磁盘空间是预定义的,通常不是很大。当工作目录的硬盘空间达到有限的数量时,应该删除一些本地副本。文件替换策略可以使用随机、LFU(最不频繁使用)、LRU(最近最少使用)等。副本类别不是建立在这样的PC上的,因为频繁的任务处理会导致大量的副本类别更新,这将消耗许多带宽和计算资源。由于工作目录的空间限制较小,数据删除操作(或文件替换)也会使副本类别更新更频繁。此外,与子任务执行时间相比,数据传输时间往往占据了主要部分,可以视为数据密集型任务。
如果没有副本目录的指导,许多基于数据共享的调度算法就无法减少数据传输量。有限的工作目录导致的数据删除使情况变得更糟。
3、基于副本预测的调度
在本节中,提出了一种副本预测指南(RPG)算法。为了进行比较,还简要描述了一种典型的基于副本的调度算法和一种不依赖于副本信息的算法。
A.两种比较算法
队列访问成本(QAC)是OptorSim中使用的一种基于副本信息的算法,OptorSim是一种具有良好结构的数据网格模拟器,用于副本目录维护。QAC算法计算每个主机的当前任务访问成本和排队任务访问成本之和,然后将当前任务与具有最小值的站点相关联。
第1节中介绍的存储亲和性是一种不依赖于副本信息的算法。存储相关性定义为已存储在主机上的任务所需的数据量。信息不是从副本目录中获得的,而是从以前提交给主机的任务中获得的。通过计算等待调度的任务与主机之间的存储相关性以形成SA度量,可以选择具有最大相关性的主机来运行任务。如果存在具有相同亲和性值的主机,则会随机选择这些主机。它试图使数据尽可能多次地被重新利用,以提高应用程序的性能。
B.副本预测指南算法(RPG)
对于第2节中提出的网格模型,有两种信息与副本间接相关:任务之间的数据共享和工作目录的磁盘空间。这些信息用于帮助网格调度程序跟踪每个站点上发生的数据复制。RPG主要分为两个阶段:副本预测列表(RPL)管理和任务调度。网格调度程序为每个站点维护一个RPL、一个任务队列等待时间队列(TQWTQ)和工作目录的总大小(TS)。算法如图1所示。RPL中的每个元素都有一个数据名称、数据大小和数据的再利用计数器。TQWTQ中的每个元素都保存某个任务的预测访问时间。TQWTQ是一个FIFO队列。步骤9-20是任务调度。对于一组任务中的每个选定任务T的第一个,计算每个站点的访问成本和任务队列等待时间,并计算总和
其中与每个站点相关联的按升序排序。总和值最小的站点将被提交任务。如果有多个站点具有相同的最小值,则会随机选择这些站点。在步骤30中,将其提交站点的任务的访问成本插入到该站点的TQWTQ中,用于接下来的任务等待时间计算。
在步骤21-29中示出了副本预测列表管理。其主要思想是使用RPLk和TSk来跟踪第k个站点复制操作模式。Dfirst的信息将被存储到RPLk中,而没有数据重叠。如果不能将总输入数据添加到列表中,则RPLk中的所有元素
将找出不具有Dfirst中存在的数据信息的数据。然后,具有最少再利用次数的元素将被删除,直到Dfirst可以被添加到RPLk中。步骤3-7实际上是在维护TQWTQ的其他线程中执行的。当网格调度器检测到任务已完成时,TQWTQ将删除此任务的预测访问成本。对于任务调度,在RPL的指导下计算Tfirst的访问成本。将预测每个站点上任务的完成时间值,并按升序排序。然后选择具有最小值的站点来提交任务。
图2显示了一个站点的RPL和TQWTQ管理示例。有三个任务T1、T2和T3。假设这三项任务将被安排到同一个站点/PC,为了简单起见,该站点/PC的总存储大小为4。在第一调度周期中,T1被调度到该站点,因此该站点的RPL的内容是D1(D1,d2,d3)的对应信息,并且该站点的TQWTQ具有T1访问成本为3的一个元素。

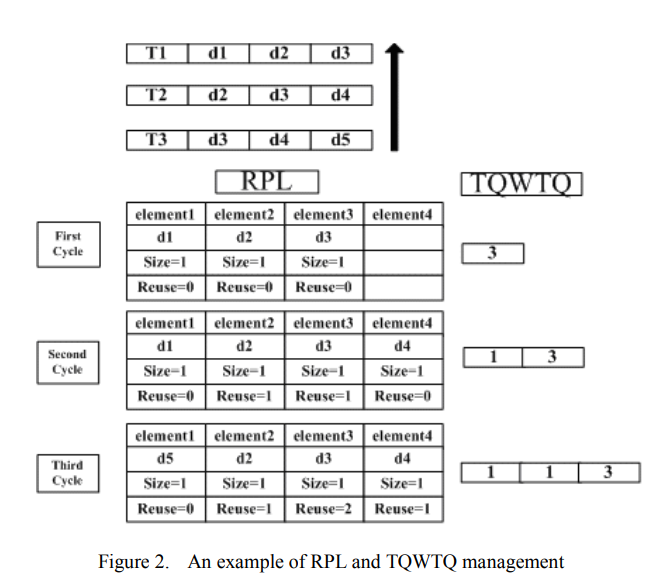
对于第二个周期,因为T2和RPL之间的两个数据(d2,d3)相同,所以TQWTQ的第二个元素是1。在这个周期中,总数据大小仍然小于4,因此没有文件替换,但d2和d3的重用计数器增加了一。对于T3,输入数据d5的信息不能直接存储到RPL中,因此进行文件替换。存在重复使用次数最少的两个数据(d1和d4),但T3需要d4,因此d1被d5代替。TQWTQ现在有三个要素。如果检测到T1完成,则具有值3的元素将从TQWTQ中移除。可以发现,即使先前的任务没有完成,也可以立即调度任务,因为在给定站点的RPL中预测了数据存储和文件替换的操作模式。
可以发现,网格调度器为每个站点维护两种数据结构,即RPL和TQWTQ。与其他算法相比,这将占用网格调度器的一些额外内存。RPL将占用的内存大小取决于每个任务的数据大小。对于定义的站点总存储大小,提交给站点的每个任务的数据大小越小,RPL的内存占用就越大。实际上,任务的数据集中每个数据的大小不会太小,从而导致RPL创建许多数据槽来存储数据信息。对于TQWTQ,它占用的内存与任务处理速度有关。对于某个站点,如果任务处理速度较慢,并且任务提交频率较高,则会增加TQWTQ的内存占用。值得注意的是,TQWTQ中每个等待任务只存储一个数字(见图2),因此当站点上等待任务的数量增加时,内存占用不会迅速增加。总之,在我们建模的网格中,用于维护RPL和TQWTQ的内存不会严重增加。
用于本研究的网格模拟器是用OptorSim实现的,因为它善于维护每个存储元素的副本目录。这使得第3节中介绍的两种算法与所提出的算法之间的比较更加容易。评估使用两个值:平均完成时间(ACT)和完工时间。ACT定义为:
其中n是站点数量,i t是第i个任务完成时间。这里的Makespan定义为,对于一组任务,从第一次输入数据传输开始到最后一个任务完成执行。
本文的目的是研究所提出的算法是否比基于副本信息的QAC算法和不是基于副本信息算法的SA算法具有更好的性能。根据第2节中的模型,网格拓扑结构包括一个初始空存储容量为80GB的数据服务器(RRSE)和20个站点,这些站点是代表PC的CE-RNSE对。存储在数据服务器上的数据是网格调度器可以从副本目录中检查的唯一数据。数据服务器与每个CE-RNSE对之间的带宽为100Mbit/s。每个RNSE的初始空存储容量为500MB。该模拟以连续提交的500个任务为例,无时间延迟地运行,以模拟多个用户协同工作导致系统在短时间内产生大量任务的情况。中用作数据源的总数据大小为10GB,存储在数据服务器上。每个任务的输入数据是从数据源随机获得的,每个任务的大小保持在20MB到100MB的范围内。根据数据,每个CE都具有较高的处理能力,因此模拟侧重于数据密集型任务。由于RNSE的存储容量不是很大,因此在某些任务过程中会发生文件替换。OptorSim中实现的文件替换策略有四种:LRU、LFU、基于二项式预测函数的经济性策略和基于Zipf预测函数的基于经济性策略。
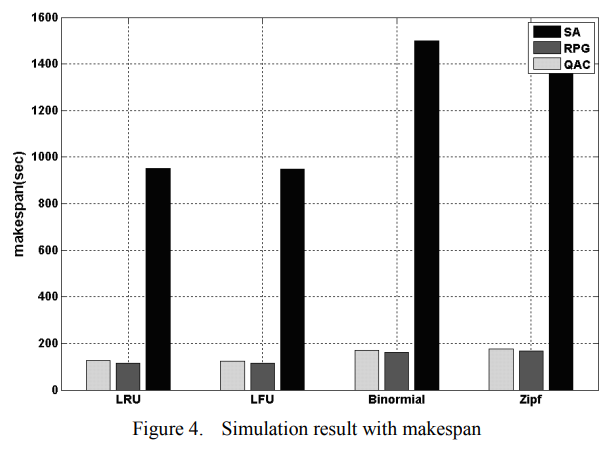
图3和图4显示了由具有上述四种不同文件替换策略的RNSE组成的网格中任务集的ACT和makespan的模拟结果。可以发现,RPG算法的ACT比QAC算法低,但略高于SA算法。另一方面,在图4中,SA的完成时间比其他的大得多。
对于SA来说,导致这些结果的原因有两个。一种是SA算法试图将具有最多数据共享的任务调度到尽可能多的同一站点,无论站点上的队列长度有多长。另一个原因是RNSE的存储容量有限。SA没有考虑文件替换,因此一些任务可能会因为空间不足而被删除,因为这些任务与站点共享的数据最多,但实际上这些数据可能会被删除。第二个原因更重要的是,即使ACT很小,也会导致大的制造跨度。
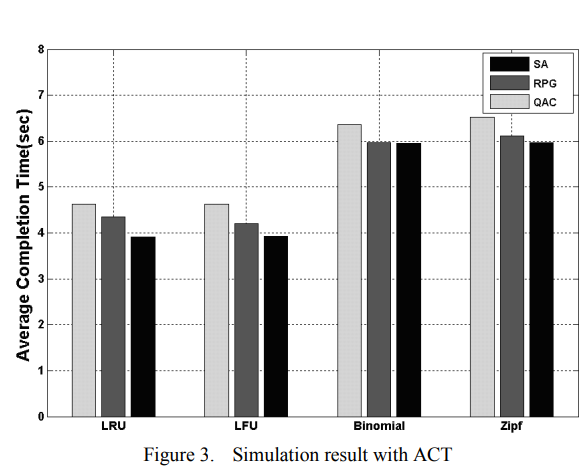
对于QAC,由于任务是以高频率提交的,因此访问成本的计算可能会有很大的误差。原因是先前计划的任务可能没有开始,并且其中的一些数据没有传输到站点,因此未计划任务的访问成本的计算无法获得一些副本信息,即使副本可能是在先前任务完成后找到的。
这两张图还表明,RPG算法可以很好地与实际在每个RNSE上运行的不同文件替换策略配合使用。
5、结论
针对协同医学图像可视化网格,提出了一种新的任务调度算法RPG。考虑到一些存储元素不会保存副本目录,并且在实践中任务之间的提交延迟很小,RPG为每个站点维护一个RPL来预测实际的副本内容。在RPL的帮助下,RPG可以在不等待先前任务完成的情况下,快速获得当前计划外任务与计划外任务的数据共享模式。另一方面,当某个站点的存储容量不足时,RPG可以通过RPL预测该站点的副本内容。仿真结果表明,即使RPG算法的平均完成时间略长于SA算法,但在高频率提交任务时,RPG算法可以在短时间内调度比QAC算法更多的任务,远远超过SA算法。
