




01
元数据管理发展阶段
02
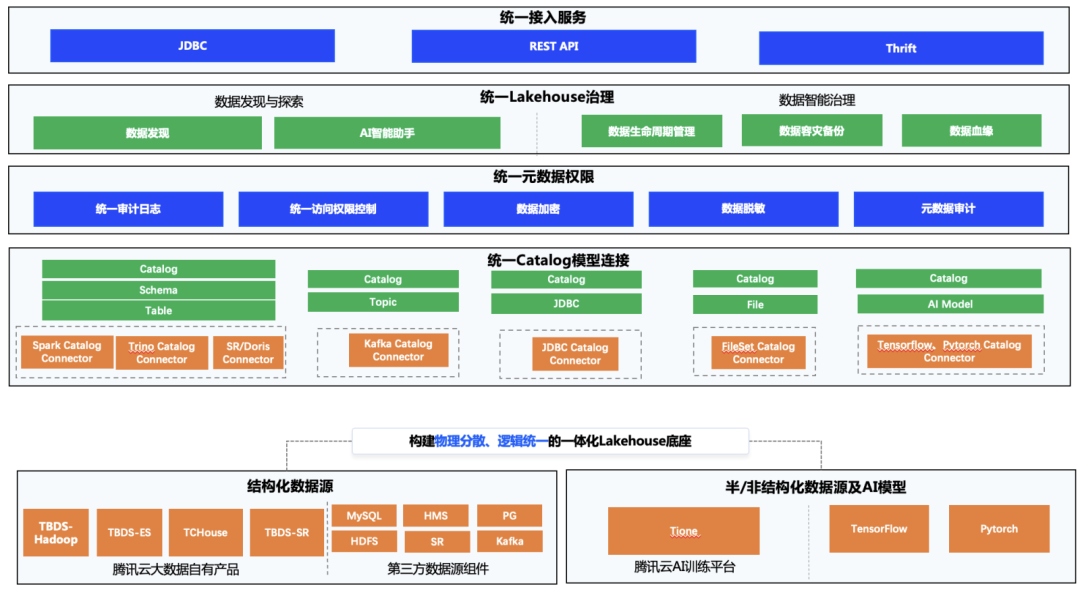
新一代元数据湖管理方案
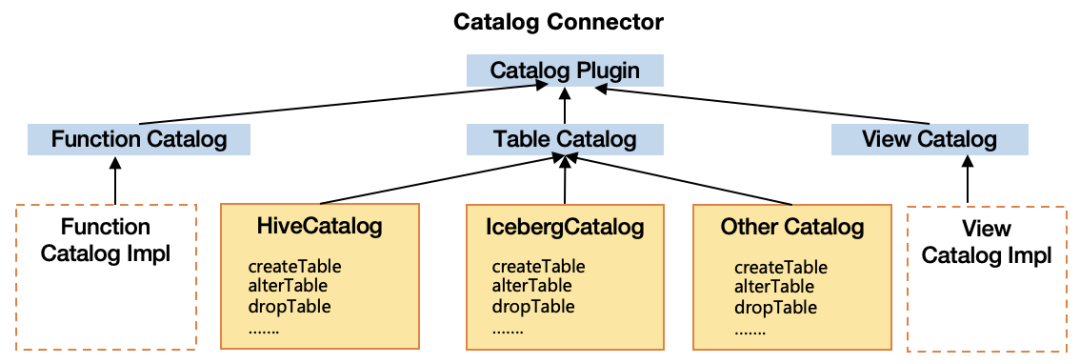
03
统一元数据权限
在Hadoop体系的优化
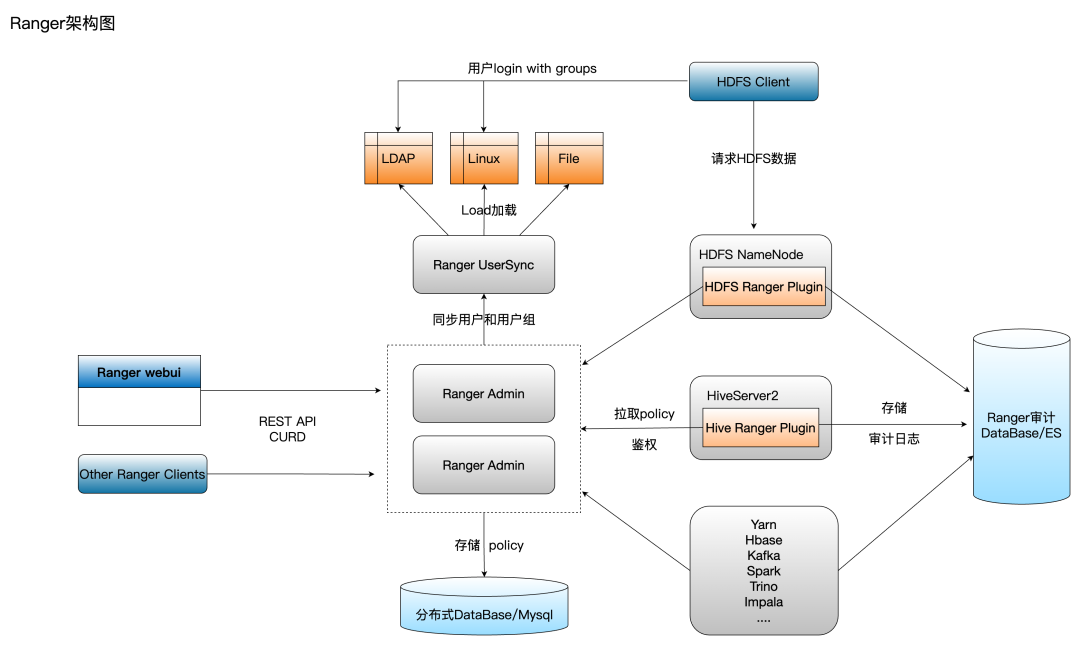
【1】用户会基于不同的细分场景选择不同计算引擎,TBDS版本里基于Hive库表的计算引擎就有Hive、Spark、Trino、Impala等,不同计算引擎上用到相同的Hive表需要在Ranger上为每个组件创建相同的库表权限,增加了用户在权限配置成本和理解,增加了复杂性且难以管理。
【2】随着库表及策略数持续增加,Ranger Plugin占用本地内存也持续增加,TBDS的生产经验值是100万策略情况下消耗的内存在10~20G左右。对于Spark Cluster模式来说每个Spark作业都会起一个Spark Driver,每个Spark Driver都会有一个Spark Ranger Plugin。大集群大量Spark批作业并行运算情况下仅仅Spark Driver上对集群的内存消耗都非常大,不仅造成大量集群内存计算资源的浪费,而且Spark Driver还容易OOM,导致任务不稳定。
TBDS基于元数据的统一权限
【1】实现Ranger Service Def的定义描述:里面包括Service有哪些资源的定义(如catalog、database/schema、table、column、udf等)、多个资源之间依赖关系的定义、对资源的访问动作(如select、insert、delete、use等)、访问资源的连接信息定义、还有脱敏、行过滤等一些配置信息。前面提到了Ranger的权限在最初架构设计上是以Service(组件)做区分,我们沿用Ranger这种设计,只是在理念上把统一元数据当作一种特别的Service来承载,在资源定义这里我们基于统一元数据定义的Hive Catalog通用元数据的entity模型来定义共用的资源,这些有了后,多种计算引擎常见的资源的权限都可以描述表示。但是还有一些资源是不属于统一元数据定义的,比如Trino引擎有自己特有的sessionproperty、trinouser资源,如果不定义这些资源,在Trino执行和这些资源有关的sql语句时权限就会管控不住。最终我们再融入各个引擎独有的资源(较少),形成一个统一的ranger-servicedef.json定义描述。
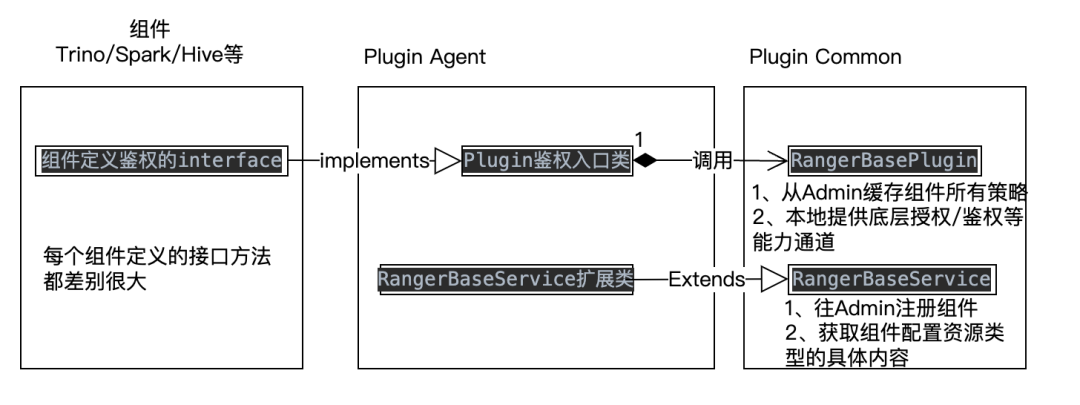
【2】实现Ranger Plugin Agent的代码实现。下图是Ranger在Plugin在代码设计上的关系图,可以看到每个组件自己定义了组件做权限控制ACL的接口和抽象授权/鉴权方法,Ranger实现了Plugin的底层Common通用鉴权通道(实现从Ranger Admin定时同步所有策略到本地内存构建内存策略树结构,并且提供了通用的RangerAccessRequest请求体到策略树鉴权和授权的方法),Plugin Agent这部分就起到了承上启下的作用,需要在Agent里按组件定义接口和抽象方法实现具体逻辑,具体逻辑概括起来就是把不同组件定义的不同资源访问结构转换成Plugin Common提供的RangerAccessRequest的过程。
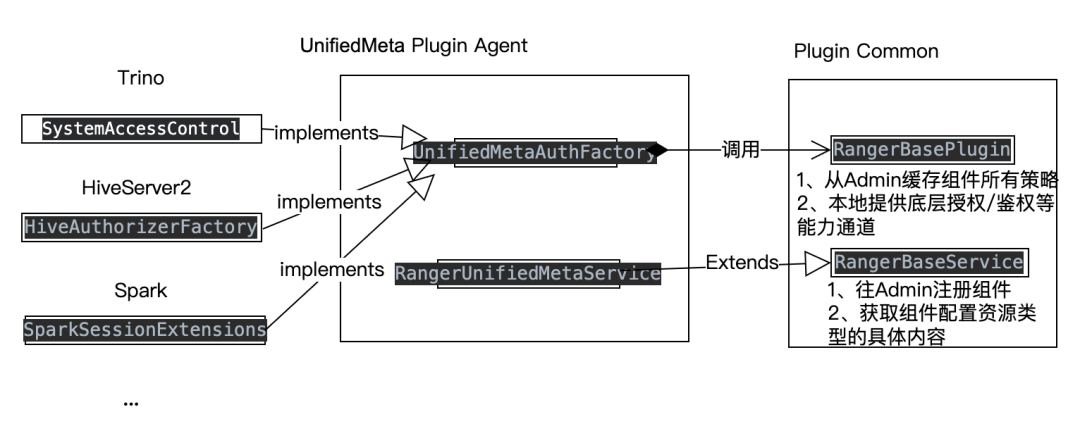
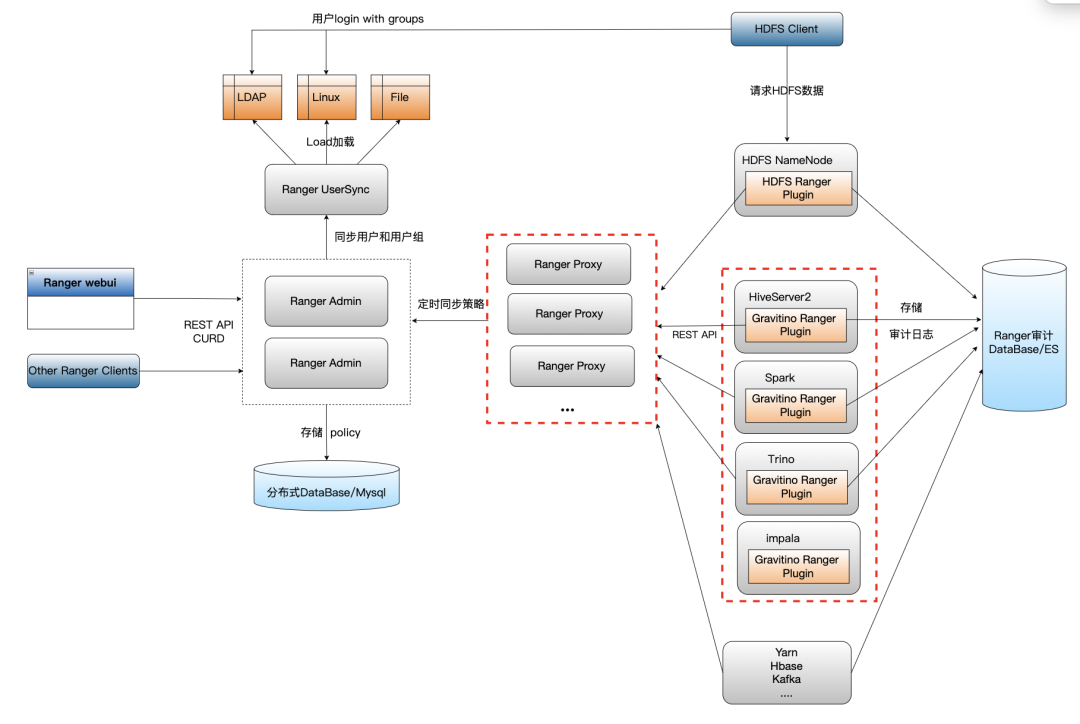
TBDS轻量级Ranger Plugin Proxy代理
04
总结
关注腾讯云大数据公众号
邀您探索数据的无限可能

点击阅读原文,了解更多相关产品详情
↓↓↓
