




下本文是《PolarDB-X 致数据库行内人》专栏系列的第三篇
本系列其他文章:
缘起
2023年10月份的杭州云栖大会,围绕PolarDB-X分布式数据库,面向大型金融机构核心系统数据库改造实践做了一次技术分享,介绍了PolarDB-X分布式数据库在大型银行、股份制银行、证券系统、保险业务等场景落地的总结。
本篇文章是对云栖大会所分享内容的一个技术补充,期望从数据库架构设计的视角,分享下在大型银行落地PolarDB-X的经验,介绍Paxos多副本 + 传统两地三中心上的技术思考。
金融行业的容灾需求
在金融行业中,容灾是非常重要的,因为金融交易和金融数据的安全性和连续性对于银行和金融机构来说至关重要。金融行业一般有4级和5级容灾需求,分别代表了不同的容灾级别和要求,参考《分布式数据库技术金融应用规范 灾难恢复要求》、《信息系统灾难恢复规范 GB/T 20988—2007》:
- 4级容灾:较低级别的容灾需求,通常同城容灾,确保同城网络的冗余性和故障切换能力
- 5级和6级容灾:更高级别的容灾需求,要求多地容灾,需要建立多个数据中心,在主要数据中心不可用时能够快速切换到备用系统,针对6级在异地副本数、备份周期频率、恢复RTO上会有更明确的要求
容灾等级 | RTO(恢复时间目标) | RPO(恢复点目标) | 灾备部署 |
4级 | <= 30分钟 | 0 | 同城灾备或异地灾备 |
5级 | <= 15分钟 | 0 | 异地灾备,异地单副本 |
6级 | <= 1分钟 | 0 | 异地灾备,异地双副本 |
一般银行的核心业务普遍要求5级容灾,考虑多数据中心的建设成本,当前金融行业普遍的5级容灾形态为两地三中心架构,典型的网络拓扑架构: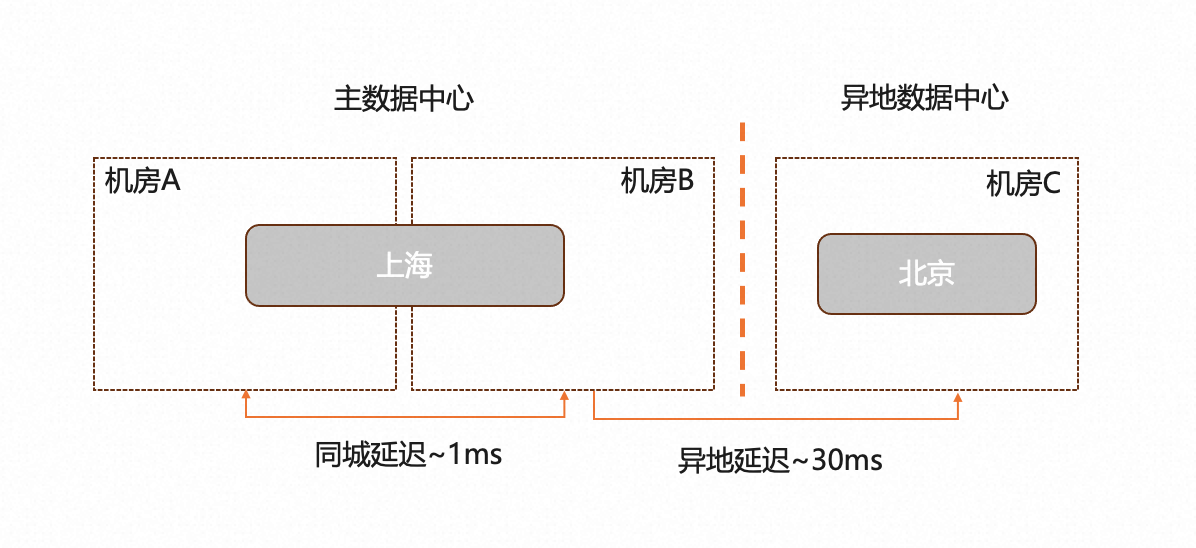
两地三中心对于数据库的需求
跨机房容灾,推荐Paxos/Raft多数派共识算法
在上一篇文章中《PolarDB-X:分布式数据库,挂掉两台机器会发生什么》,我们简单论证过对于数据有一定的重要性场景,都不应该选择主备架构的产品(包含mysql semi-sync半同步,也有网络降级为异步丢数的风险),而金融行业尤其重视机房级别的容灾(比如主机故障、断网脑裂等),推荐使用Paxos/Raft多数派协议的数据库,从多数派共识算法的原理层面可以很好的满足一致性要求。
目前主流分布式数据库基本都选择Paxos\Raft(包括其他变种协议),其共通点是,每份数据会存在多个副本,并且能够保证在一个副本挂掉的情况下,不影响可用性,并且不会出现任何一致性问题(脑裂、丢数据、丢更新等)。
本文同样无意去解析Paxos\Raft协议,我们需要思考结合两地三中心架构,进一步思考新一代基于Paxos多副本的数据库,如何满足金融的严苛要求。
我们将进一步探讨几个问题:
- 一个业务的两地三中心,同城和异地,数据库是一个实例还是多个实例,以及如何满足RPO和RTO?
- 业务对接分布式数据库有单元化诉求,单元化要求数据库切主同机房优先,如何满足单元化?
- Paxos/Raft多数派共识算法,如何优化跨机房数据复制、以及如何满足机房故障场景?
- 分布式事务遇到两地三中心,是否会有数据一致性问题?
- 数据库日常的容灾演练能力,如何构建面向不同故障场景下的模拟演练?
1. 中心主实例 + 异地灾备实例
按照两地三中心的5级容灾,同城每个机房至少需要2副本 + 异地至少需要1个副本,因此基于Paxos多数派的需求,两地三中心比较合理的架构是采用5副本。
针对第一个问题,一个业务的两地三中心,PolarDB-分布式数据库的设计上是:中心主实例(5副本)+ 异地灾备实例(2副本),基于可以满足RPO/RTO以及故障演练场景的诉求,文章后续通过架构逐步演进的思路来介绍两地三中心的方案。
中心主实例
初始的架构设计
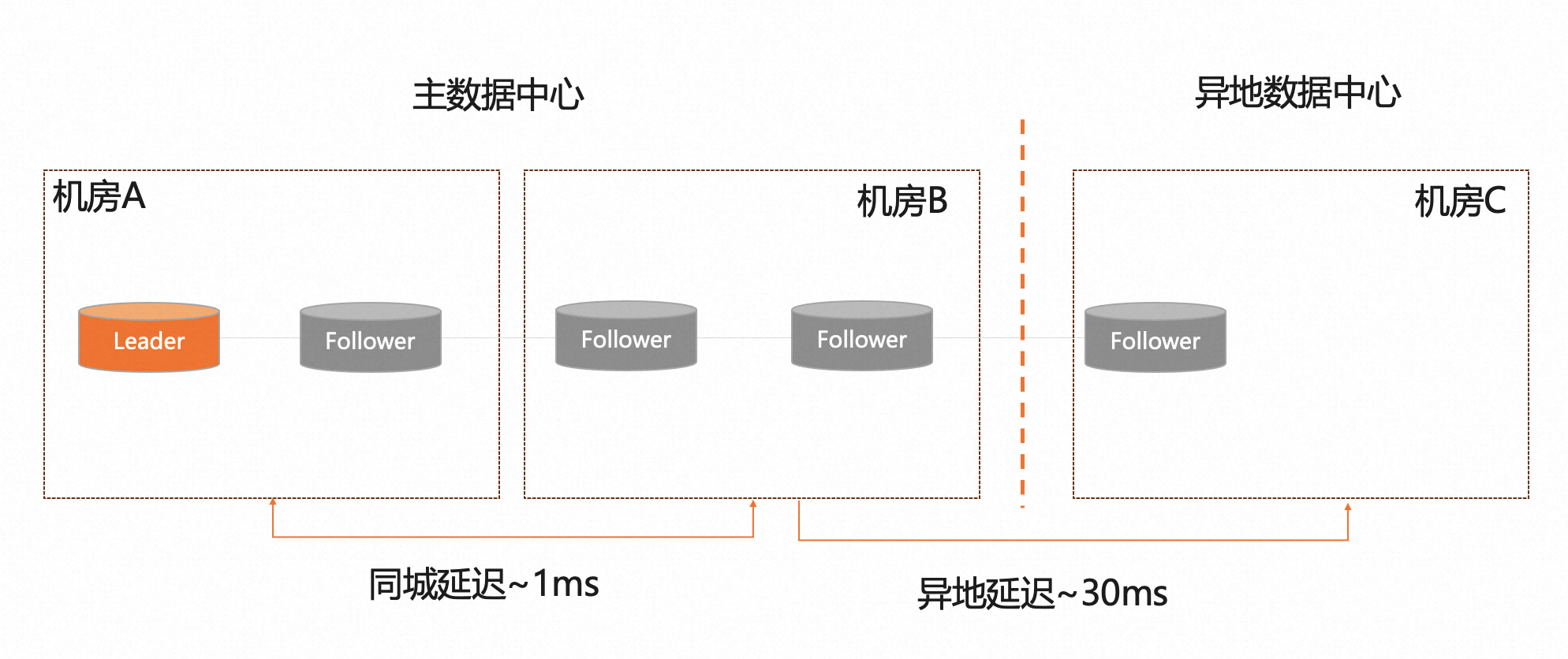
基于Paxos协议经常被咨询的一个问题:如果机房容灾,多数派副本挂了,异地容灾能否提供服务?
映射到两地三中心5副本的初始架构,思考RPO/RTO的相关问题:
- 中心机房A挂了,剩余3副本,可以满足多数派。此时,RPO=0且RTO<30,可以满足paxos多数派协议的自动切换
- 中心机房B挂了,如同上一条的A机房挂了的场景
- 中心地域挂了,机房A和机房B不可用,此时仅剩异地的1个副本,不满足多数派且异地RPO>0,这种场景下数据库比较难以自动恢复,需要结合RTO场景思考数据库的能力。
异地单副本启动
在中心地域挂了,异地仅剩单副本时,PolarDB-X提供了一种单副本启动的方式(一键需改元数据+强制重启),重新提供服务。
# 强制单节点,剔除所有follower
call dbms_consensus.force_single_mode();这种故障恢复模式下,可以作为一种应急能力,但RTO的时间取决于运维同学介入 + 手工操作恢复的总时间(登录一堆数据库主机挨个重启节点),RTO比较难有严格时效性的保障。
同时,异地单副本启动模式对于故障演练场景的需求来看,即使有预期也会对当前业务有损(需要重建数据库),不太具备故障演练的能力。
异地灾备实例
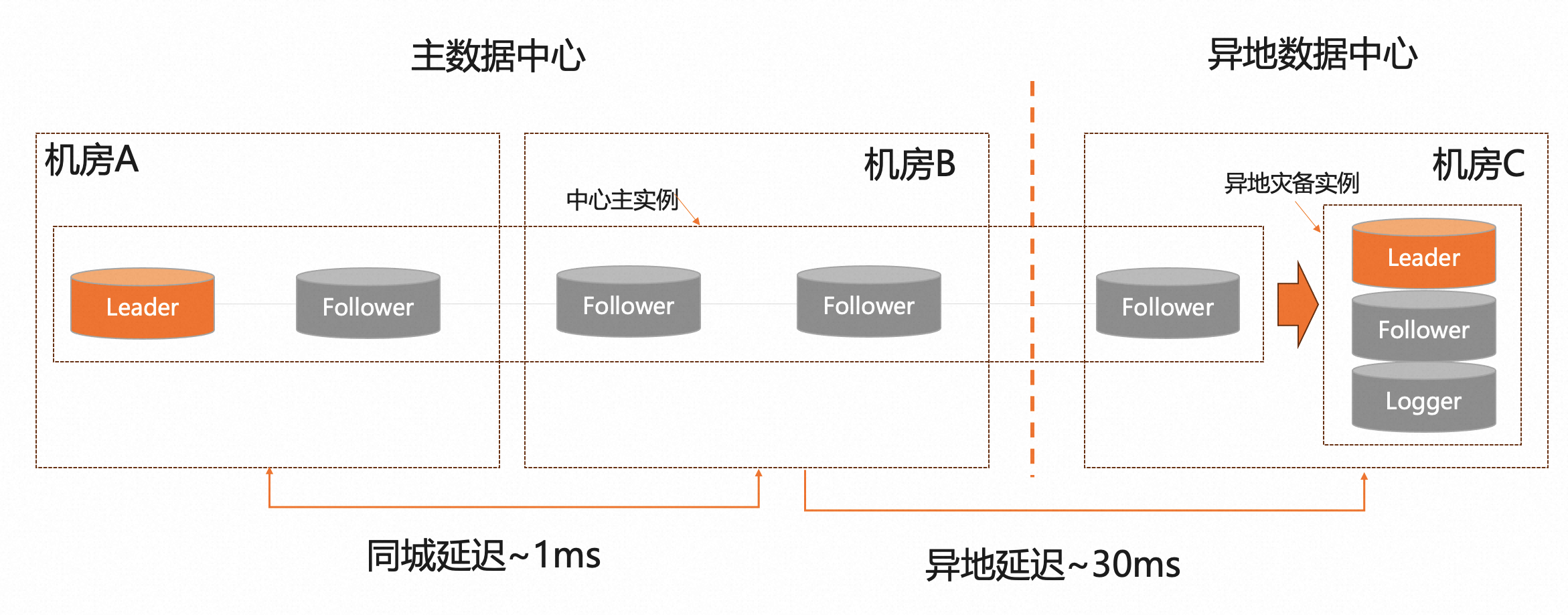
架构形态:
- 中心主实例 + 异地灾备实例,采用数据异步复制 + 双向同步。
- 异地灾备实例,推荐选择为一个独立的Paxos 3副本实例,结合PolarDB-X的Logger副本类型,最后等价于2副本模式
PolarDB-X支持的副本类型:
副本角色 | 角色类型 | 角色说明 |
Leader | Normal | 领导者,负责处理客户端的请求并进行决策,Leader需要维护日志,保证数据的一致性和可恢复性。 |
Follower | Normal | 跟随者,接受Leader的指令并进行执行,当Leader宕机或无法被访问时,通过竞选成为新的Leader。 |
Logger | Log | 日志者,与Follower角色类似,仅提供多数派协议服务,但不提供数据服务。当Leader宕机或无法被访问时,会参与Leader的竞选投票,短时间内有可能会被选举为Leader,但不会提供数据服务,等待其余多数派Follower角色完成协议日志追平后,Logger会主动让出Leader |
Learner | Normal | 学习者,只能被动接收系统状态信息,不能参与投票和决策,可以避免对系统的影响(一般用于只读节点) |
基于异地灾备实例,继续考虑中心地域故障的场景:
- 中心主实例仅剩异地1副本,不满足多数派,此时中心主实例不可服务,可以快速切流量到异地灾备实例,可以满足RTO<1分钟
- 故障演练场景,可以切流量到异地灾备实例,此时基于双向同步的机制,异地灾备实例数据可以同步会中心主实例,演练过程对于数据没有太大的影响
2. 分布式 + 单元化
金融行业随着业务的发展,普遍都会有单元化的诉求,业务对于单元化的诉求:
- 业务单元化,将原本一个业务拆分为N个单元,每个单元承担部分流量,个别单元故障时可以隔离故障爆炸半径,避免影响业务整体。
- 分布式扩展性,将不同单元调度到不同资源上,实现业务的线性扩展性
业务对于单元化的诉求,通过分布式数据库的分布式拆分机制,有比较好的技术契合度,这也是金融行业对于分布式数据库比较热衷的一个原因。
单元化分片
PolarDB-X 分布式数据库,考虑单元化适配后,此时的架构设计: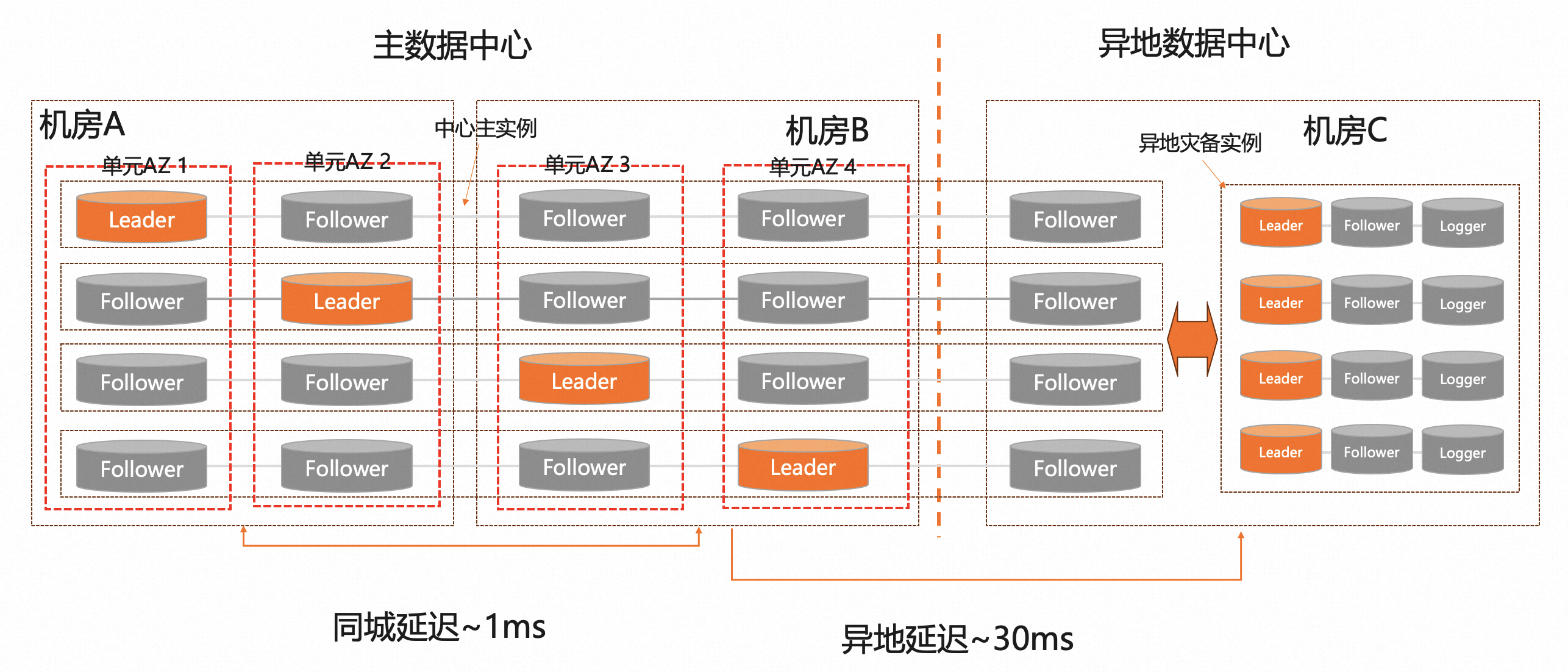
如上图所示:
- 业务单元划分:中心地域2机房4单元,相当于每个机房有2个单元,每个单元有自己独立的主机硬件和交换机。
- 分布式适配:PolarDB-X数据库的数据节点DN的数量,推荐是单元数量的整数倍,比如4、8、12、16等。每个DN的多个副本,确保每个单元都有1个副本,同时需要调度不同分片DN的leader到对应的单元,最后的效果:每个单元内都有数据库全量数据,分片Leader各自均匀分布。
- 数据库和表,适配单元化的分片 和 对应的DN。比如总计4个DN(DN1~DN4),数据分片128份,单元化的数据分片规则就是:分片0~31(DN1)、分片32~63(DN2)、分片64~95(DN3)、分片96~127(DN4)。
- 单元化分片算法,适配业务单元调度。比如按照用户id进行单元化,按照hash算法进行适配,业务流量和数据库的分片单元进行对齐,最后达到业务流量访问同机房DB的效果。
这里基于单元化的结构设计,针对数据库有隐形的需求:
- 中心主实例,异地副本不能选为Leader,否则单元会有跨地域访问的场景,导致RT异常。
- 1个机房包含2个单元,如果遇到一个单元的DN副本故障时,优先切换到同机房的DN副本,尽可能保证业务和单元之间的同机房路由。
Paxos 选举权重
PolarDB-X分布式数据库,在Paxos协议部分引入了选举权重设计:
- 乐观权重机制,多数派共识算法Paxos在选举策略中优先发起选举容易成为Leader,引入权重后我们针对不同的节点引入随机延迟发起Leader选举的时间差,确保高权重的节点优先触发Leader选举。
- 强制权重机制,当某一新成为Leader的节点,发现自己不是所有节点中权重最高的节点的时候(当所有节点权重一致的时候,任意节点都是权重最高的点,所以此判定不生效),不会立刻放开写入,而是继续等待一个选举超时的时间段(称为禅让阶段),在禅让阶段会每隔一个心跳时间(比如1~2秒),向其它节点发送一次心跳探测。在选举时间段结束以后,如果收到其他权重比自己大的节点回包,即向回包节点中权重最大的节点发起一次Leader转移,确保高权重的节点成为Leader。
4个DN分片为例子:
机房 | 单元AZ | DN 1 权重 | DN 2 权重 | DN 2 权重 | DN 2 权重 |
主数据中心 机房A | AZ 1 | 9 (Leader) | 7 (Follower) | 5 (Leader) | 3 (Follower) |
AZ 2 | 7 (Follower) | 9 (Leader) | 3 (Follower) | 5 (Follower) | |
主数据中心 机房B | AZ 3 | 5 (Follower) | 3 (Follower) | 9 (Leader) | 7 (Follower) |
AZ 4 | 3 (Follower) | 5 (Follower) | 7 (Follower) | 9 (Leader) | |
异地数据中心 机房C | AZ 5 | 1 (Follower) | 1 (Follower) | 1 (Follower) | 1 (Follower) |
整体权重按照9/7/5/3/1,权重策略说明:
- 同机房的单元分配9和7的权重,确保权重为9的Leader故障时,优先选择同机房的权重为7的副本
- 异地数据中心,分配到的权重为1,权重为所有副本中最低,确保Leader不会调度到异地机房
