





Doris 数据表模型上分为三类:
DUPLICATE KEY, UNIQUE KEY, AGGREGATE KEY
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)
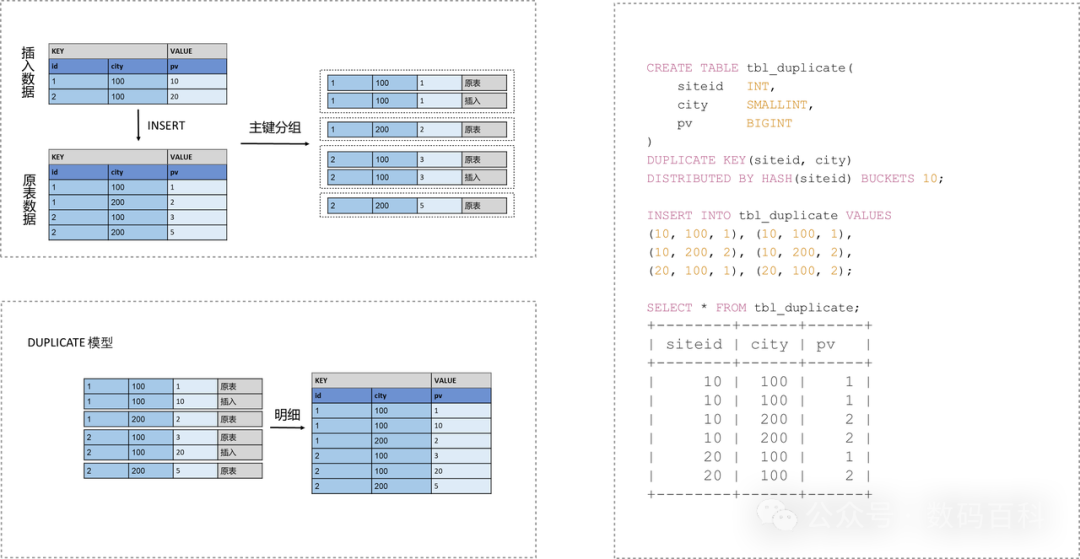
只指定排序列,相同的 KEY 行不会合并。
适用于数据无需提前聚合的分析业务:
原始数据分析
仅追加新数据的日志或时序数据分析
Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
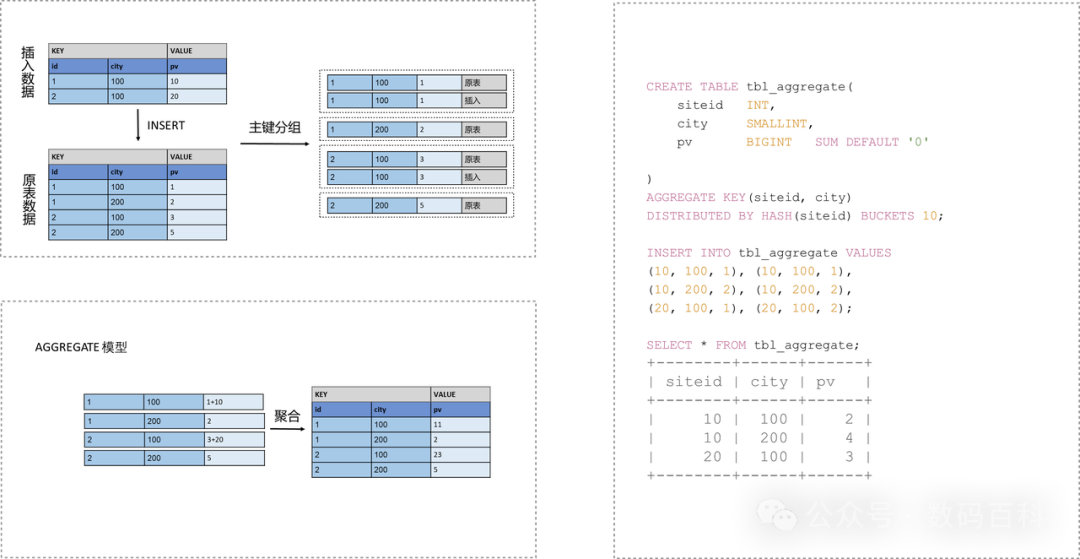
AGGREGATE KEY 相同时,新旧记录进行聚合,目前支持的聚合方式:
SUM:求和,多行的 Value 进行累加。
REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
MAX:保留最大值。
MIN:保留最小值。
REPLACE_IF_NOT_NULL:非空值替换。和 REPLACE 的区别在于对于 null 值,不做替换。
HLL_UNION:HLL 类型的列的聚合方式,通过 HyperLogLog 算法聚合。
BITMAP_UNION:BIMTAP 类型的列的聚合方式,进行位图的并集聚合。
适合报表和多维分析业务:
网站流量分析
数据报表多维分析
Unique 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用物化等预聚合带来的查询优势。对于聚合查询有较高性能需求的用户,推荐加入的写时合并实现。
UNIQUE KEY 相同时,新记录覆盖旧记录。UNIQUE KEY 实现上和 AGGREGATE KEY 的 REPLACE 聚合方法一样,二者本质上相同, UNIQUE KEY 引入了 merge on write 实现,该实现有更好的聚合查询性能。
适用于有更新需求的分析业务:
订单去重分析
实时增删改同步
如果有部分列更新的需求,可以选择:
a. Unique 模型的 Merge-on-Write 模式
b. Aggregate 模型的 REPLACE_IF_NOT_NULL 聚合方式
