存储引擎
OceanBase 数据库的存储引擎采用了基于 LSM-Tree 的架构,把基线数据和增量数据分别保存在磁盘(SSTable)和内存(MemTable)中,具备读写分离的特点。对数据的修改都是增量数据,只写内存。所以 DML 是完全的内存操作,性能非常高。读的时候,数据可能会在内存里有更新过的版本,在持久化存储里有基线版本,需要把两个版本进行合并,获得一个最新版本。
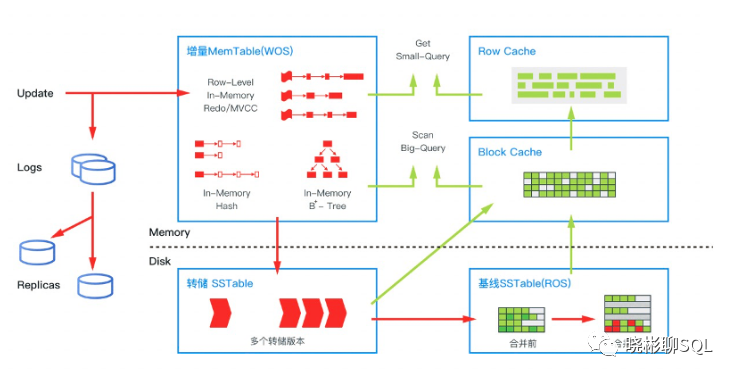
如上图所示,在内存中针对不同的数据访问行为,OceanBase 数据库设计了多种缓存结构。除了常见的数据块缓存之外,也会对行进行缓存,行缓存会极大加速对单行的查询性能。为了避免对不存在行的“空查”,OceanBase 数据库对行缓存构建了布隆过滤器,并对布隆过滤器进行缓存。OLTP 业务大部分操作为小查询,通过小查询优化,OceanBase 数据库避免了传统数据库解析整个数据块的开销,达到了接近内存数据库的性能。当内存的增量数据达到一定规模的时候,会触发增量数据和基线数据的合并,把增量数据落盘。同时每天晚上的空闲时刻,系统也会启动每日合并。另外,由于基线是只读数据,而且内部采用连续存储的方式,OceanBase 数据库可以根据不同特点的数据采用不同的压缩算法,既能做到高压缩比,又不影响查询性能,大大降低了成本。
SQL 引擎
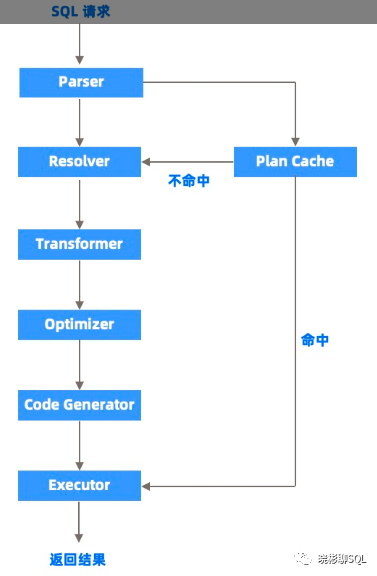
OceanBase 数据库的 SQL 引擎是整个数据库的数据计算中枢,和传统数据库类似,整个引擎分为解析器、优化器、执行器三部分。当 SQL 引擎接受到了 SQL 请求后,经过语法解析、语义分析、查询重写、查询优化等一系列过程后,再由执行器来负责执行。所不同的是,在分布式数据库里,查询优化器会依据数据的分布信息生成分布式的执行计划。如果查询涉及的数据在多台服务器,需要走分布式计划,这是分布式数据库 SQL 引擎的一个重要特点,也是十分考验查询优化器能力的场景。OceanBase 数据库的查询优化器做了很多优化,诸如算子下推、智能连接、分区裁剪等。如果 SQL 语句涉及的数据量很大,OceanBase 数据库的查询执行引擎也做了并行处理、任务拆分、动态分区、流水调度、任务裁剪、子任务结果合并、并发限制等优化技术。
下图描述了一条 SQL 语句的执行过程,并列出了 SQL 引擎中各个模块之间的关系。