




系列文章第七期对“文档型数据库建模视角--关系、维度、查询”进行了初步的介绍。考虑到在实际应用中维度视角更倾向于处理BI及数据分析的统计场景,而关系、查询视角最能展示在数据模型设计思路的不同。本期我们通过一个综合的案例,应用这两个不同的视角分别设计“物理数据模型PDM”,并通过「关系型数据库」和「文档型数据库」进行实施落地的讲解。
这里,先通过 “业务术语模型(Business Terms Model,BTM)” 来描述一个最基本的 “销售业务系统” 需求。
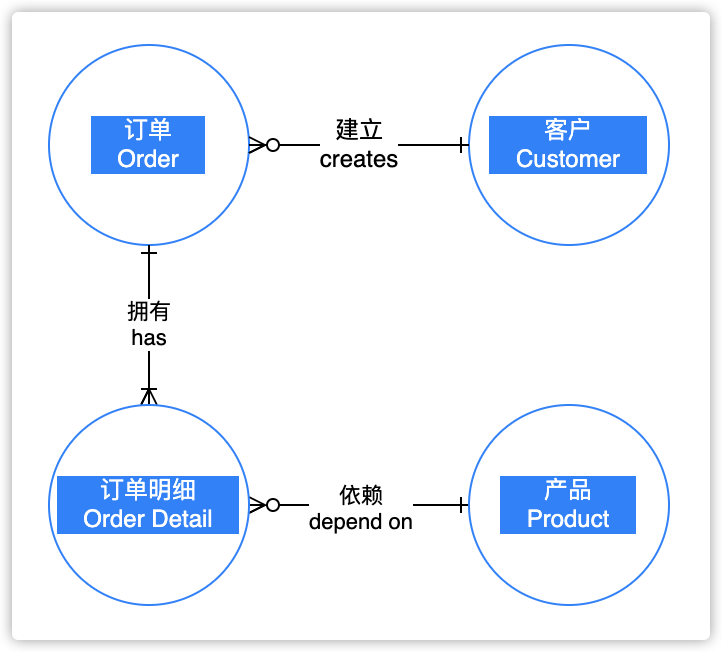
图1:销售业务系统的业务术语模型BTM
图1中可以看到:
「客户」和「订单」是 1:N 的关系,每个「订单」必须由某个「客户」建立,而「客户」可以没有「订单」,例如:刚刚注册的新客户;
「订单」和「订单明细」是 1:N 的关系,每个「订单明细」必须由某个「订单」拥有,而且每个「订单」必须拥有1个以上的「订单明细」;
「订单明细」和「产品」是 N:1 的关系,每个「订单明细」必须依赖于某个「产品」,而「产品」可以没有「订单明细」,例如:新上架的产品。
基于以上信息,我们先展示应该如何从 “关系、查询” 视角进行最终的 “物理数据模型PDM” 建立,以应用到「关系型数据库」和「文档型数据库」中。
查询视角:数据冗余,提升查询性能避免不必要的JOIN
在“查询视角”下,数据建模过程中需要考虑的是业务将如何使用数据,而不会仅仅是僵硬地复刻 “业务术语模型BTM” 的描述信息。
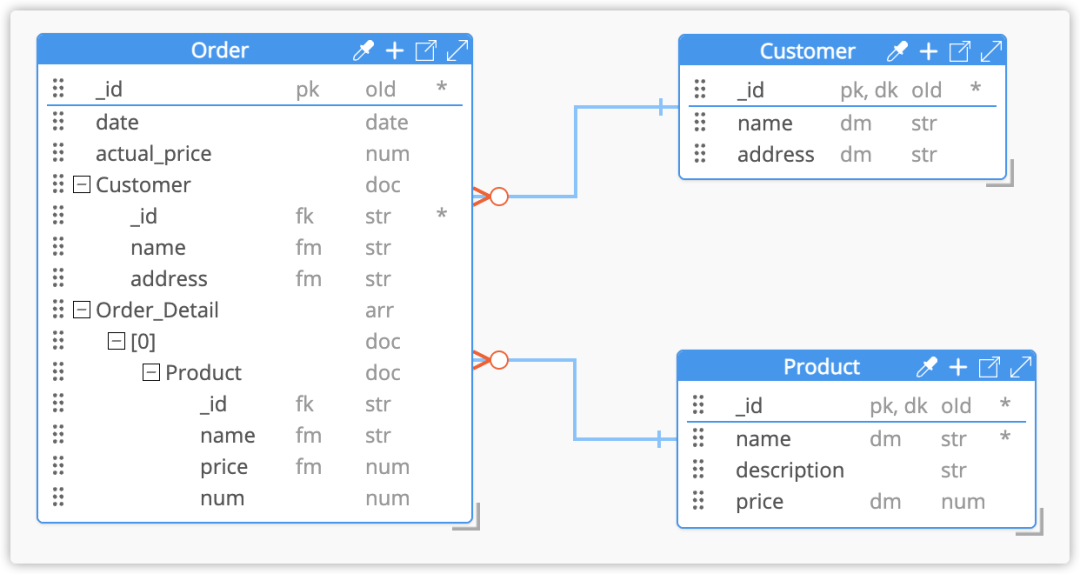
图2:查询视角,文档型数据库JSON集合结构的物理数据模型PDM
以上图2是基于图1建立的“查询视角PDM模型”,“销售业务系统” 被最大量使用的将是订单的处理信息,每次生成「订单」时,都必须连同「订单明细」、「客户信息」、「产品」信息一并进行使用,作为业务的一个整体原子性处理。而查询时,这些实体的部分必要信息也需要同时进行展示。
因此,「订单」数据集合通过嵌套的方式包含了「订单详情」的全部信息。同时,在「订单」中通过子集引用的方式更引入了「客户」、「产品」的部分关键信息。不同于关系视角的模型,这里并没有将「订单详情」单独建立一个集合,这是因为业务操作中往往不会对某条「订单详情」的信息进行单独处理。
文档型数据库的JSON集合结构,可以表达为以下具体内容:
db.Order.insertOne({"_id": ObjectId("ffceb6eecdd4f81cd6e10900"),"date": ISODate("2024-07-10T15:06:21.595Z"),"actual_price": 8300,"Customer": {"_id": "dd87a0fbebc96c54a2b93ff6","name": "张三","address": "广州市南沙区1街1号"},"Order_Detail": [{"Product": {"_id": "d0b8b77b1cde75b1f4273cd0","name": "xx手机","price": 3500,"num": 1}},{"Product": {"_id": "d0b8b77b1cde75b1f4273cd1","name": "xx平板电脑","price": 4800,"num": 1}}]});db.Customer.insertOne({"_id": ObjectId("dd87a0fbebc96c54a2b93ff6"),"name": "张三","address": "广州市南沙区1街1号"});db.Product.insertMany([{"_id": ObjectId("d0b8b77b1cde75b1f4273cd0"),"name": "xx手机","description": "5G,黑色,256GB","price": 3500},{"_id": ObjectId("d0b8b77b1cde75b1f4273cd1"),"name": "xx平板电脑","description": "10寸,银色,512GB","price": 4800}]);
如上述需求描述,业务运行中往往需要获得通过「客户」或「产品」查询出相关的「订单」信息。基于查询视角配合文档型数据库的物理数据模型,可以极为简洁的方式获得特定条件订单的详情信息。
/* 按客户ID查询订单 */db.Order.find( {"Customer._id": "dd87a0fbebc96c54a2b93ff6"} );/* 按产品ID查询订单 */db.Order.find( {"Order_Detail.Product._id": "d0b8b77b1cde75b1f4273cd1"} );
关系视角:精简存储,JOIN影响查询时性能表现
关系视角:更注重于如何通过关系数学模型,精确表示如何接收和访问数据。从以下“图1”中,可以看到 “物理数据模型PDM” 中精确地表现了各个业务实体,每个实体通过独立的二维数据表格进行表示。
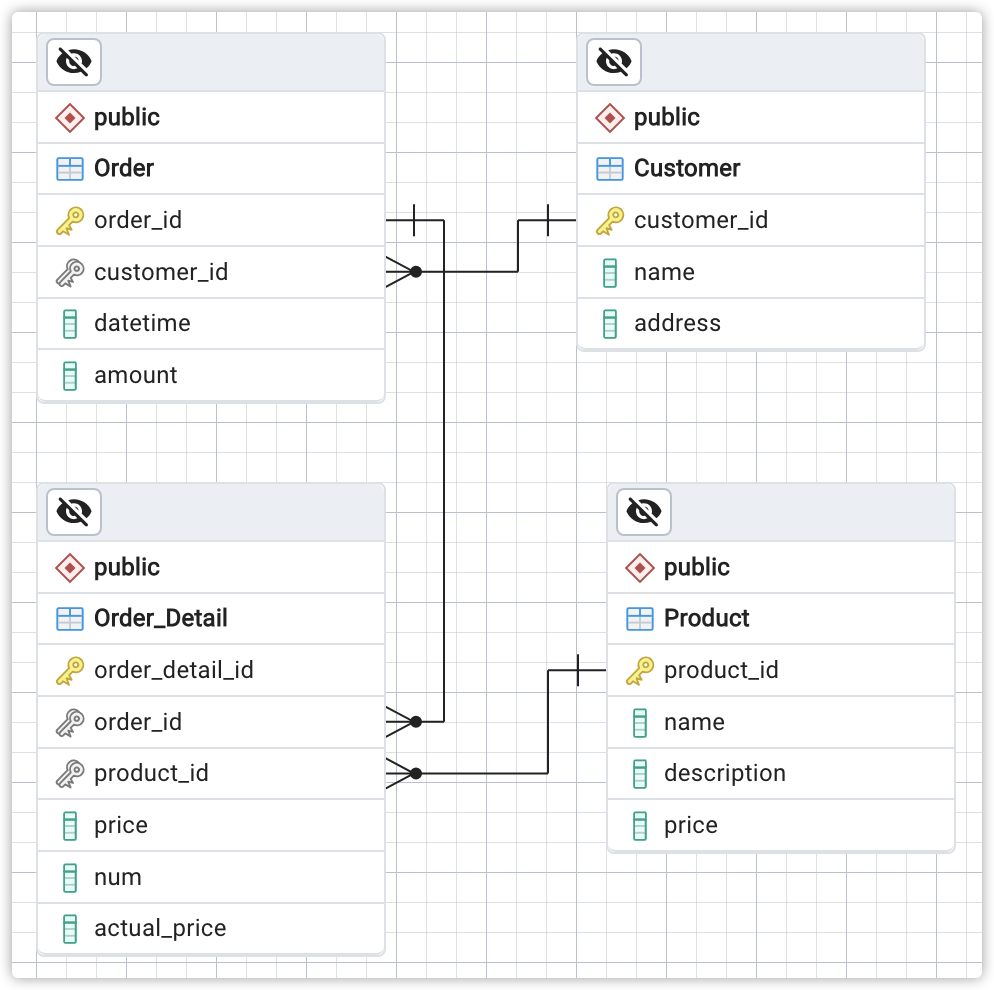
图3:关系视角,关系型数据库SQL表格结构物理数据模型PDM
以上图3是基于图1建立的“关系视角PDM模型”,关系视角的基本思想是使用规范化的方法,将数据分解成一系列表,并通过关系建立这些表之间的联系。因此,设计中注重的是每个数据表格和实体的一一对应,和每个实体间的主键和外键依赖关系。而不会直接考虑业务应用过程可能出现的复杂关联JOIN,以及是否可以通过数据冗余让未来业务运行时间可以避免跨表查询的开销。
具体的关系型数据库SQL表格结构,本文不提供具体DEMO。通过关系视角进行模型设计时,由于每个数据表都保存自己的实例信息,因此不会出现查询视图中Order集合中冗余存放Customer、Product集合部分子集信息的情况,数据存储空间更为节省。但在进行常规业务,需要获得通过「客户」或「产品」查询出相关的「订单」信息时,可以明显看到SQL的SELECT操作需要进行更多的JOIN关联,消耗运行时的计算资源。
/* 按客户ID查询订单 *//* 需要分别按customer_id获取各个表格的信息,并且需要JOIN到Order、Order_Detail、Product获取对应数据 */SELECT *FROM "Customer", "Order"WHERE"Customer"."customer_id" = "Order"."customer_id" and"Customer"."customer_id" = 'dd87a0fbebc96c54a2b93ff6';SELECT "Order_Detail".*, "Product"."name", "Product"."description"FROM "Order", "Order_Detail", "Product"WHERE"Order_Detail"."order_id" = "Order"."order_id" and"Order_Detail"."product_id" = "Product"."product_id" and"Order"."customer_id" = 'dd87a0fbebc96c54a2b93ff6';/* 按产品ID查询订单,本文不再给出DEMO,可以参考以上进行调整 *//* Order_Detail的查询也可以通过在数据表中冗余添加customer_id作为FK减少1个表的JOIN进行数据结构的优化 */
文档型数据库基于查询视角下带来的卓越性能
现代硬件技术发展迅速,存储低成本持续降低,IO性能持续提升。查询视角通过冗余部分数据,在数据写入前规划最适合业务的数据结构,简化开发工作并提升高并发查询的总体性能。虽然基于关系视角进行建模,也可以面向业务需要灵活应用第1、2、3、4等范式,但不同范式也会出现数据冗余的问题,并没有那个范式可以符合所有业务需要,同时又兼顾最小化存储。
文档型数据库尤其是巨杉数据库SequoiaDB,在应用查询视角建模中凸显了多项优势:
1. 灵活性: SequoiaDB作为一种文档型数据库,为用户提供了高度灵活的数据模型。用户可以根据具体业务需求选择严格嵌入或更为灵活的逻辑模型,从而更好地适应多样化的查询场景。例如,在金融领域,可以灵活地建模客户信息和账户关系,适应各类查询需求。
2. 查询效率: 通过 SequoiaDB 的逆规范化和支持嵌套结构等设计模式,文档型数据库在查询操作中表现卓越。这一特性降低了数据检索的复杂性,提高了查询效率。在实际应用中,SequoiaDB的查询性能使其成为处理大规模数据的理想选择,尤其在需要快速响应复杂查询的情境下表现出色。
3. 易读性: SequoiaDB支持嵌套结构,这使得查询结果更易于理解。数据以自然的方式组织,降低了模型理解的难度。在具体案例中,例如零售行业中的订单和产品信息可以通过嵌套结构清晰地呈现,从而增强了用户对数据关系的直观感知,提高了整体的可读性。SequeoiaDB在这方面的设计使其成为高度直观和用户友好的文档型数据库选择。
总结
查询视角是构建应用程序时不可或缺的一部分,而文档型数据库在这一视角下展现了其独特的优势。通过灵活的数据模型、高效的查询操作和易读的查询结果,文档型数据库为应对不断变化的业务需求提供了理想的解决方案。在信息化时代,文档型数据库的维查询视角建模为企业更好地理解业务流程、发现新的洞察提供了强有力的支持。
