




前言
子图匹配(Subgraph Matching)是图模式挖掘算法中的一个热点研究问题,其旨在一个数据图中挖掘出所有与给定查询图同构(或同态)的子图。目前大多数的子图匹配工作都是在顶点带标签的无向图上对子图同构进行研究。由于子图匹配问题是一个NP-hard的问题,因此当数据图的规模很大或查询图的顶点数目很多时,子图匹配算法的效率会大打折扣。为了提高子图匹配算法的效率,现存的子图匹配算法从过滤候选、生成有效的匹配顺序和加速枚举过程等多个角度对子图匹配进行优化设计,提出了许多行之有效的优化方法。在这里,我们将介绍复旦大学张志杰等人在SIGMOD 2024会议上发表的最新子图匹配综述文章”A Comprehensive Survey and Experimental Study of Subgraph Matching: Trends, Unbiasedness, and Interaction“[1]。笔者在此做翻译和总结。该文章主要从过滤策略、匹配顺序和枚举优化三个方面调研了近年来的许多子图匹配工作,并总结了它们在处理不同workload时的优势和不足。
研究目标
子图匹配算法发展的主流趋势是什么?大多数的子图匹配算法都遵循过滤-排序-枚举这个计算框架。早期子图匹配算法的主要重点是过滤策略和匹配顺序的优化,但是尽管有精心设计的候选过滤和匹配顺序,回溯算法仍然面临着大量无效递归的问题。因此,最近越来越多的算法努力加强回溯框架,以尽量减少回溯的次数,如:DPiso[2],RM[3],VEQ[4],GuP[5]和CaLiG[6]。这些方法都对回溯框架进行了不同程度的修改,已成为当前的研究趋势。
如何在没有任何偏见的情况下严格评估不同子图匹配算法的性能?之前的工作在实验评估中遵循一个“通用设置”:算法在产生个匹配后或达到300秒超时时终止。这可能会对评估子图匹配算法产生偏见,最理想的解决办法是不加限制地进行实验,直至获得全部匹配。然而,这种做法是不现实的,因为子图匹配是NP-hard的。因此,该工作引入了每秒嵌入数(Embeddings per seconds,缩写为EPS)这一指标,该指标被定义为每秒返回的嵌入数的平均值。这一衡量指标可以通过考虑时间成本和报告嵌入的数量提供一个全面的度量。
不同的优化技术之间的相互作用可以如何影响不同算法的性能评估?丰富的子图匹配算法可以分解为单独的技术(过滤、排序和枚举)并相互组合,这些不同的组合为这些技术的效果提供了更大的研究空间。
过滤策略
过滤策略用于判别每个查询顶点的候选顶点集,目的是可以提前过滤掉无效的候选顶点。在实践中,使用有效的过滤策略可以大大减少匹配数据顶点的数量。本文综述了10种具有代表性的过滤方法,具体如下表所示。
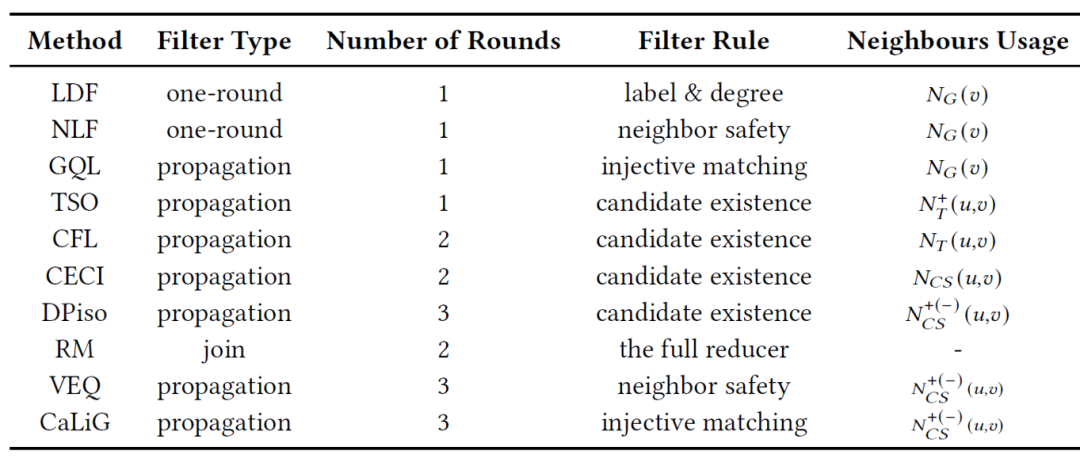
1. 过滤方式
LDF[7]和NLF[8]是早期提出的比较简单的过滤方法,它们采用一轮过滤方式,仅利用数据图每个数据顶点的局部特征进行过滤。为了提高过滤的效果,后续的基于预处理-枚举框架的算法通常采用传播过滤方式来获得更加准确的候选顶点集。传播过滤的想法是:在一个顶点被过滤掉之后,这个结果会影响到这个顶点周围的邻居,可以利用这个信息继续去修正邻居顶点的过滤结果。在实践中,传播过滤方法还需指定遍历和优化候选对象的轮数以及遍历顺序。RM是基于连接的算法,因此它采用关系过滤,利用join操作来实现过滤。
2. 过滤规则
过滤规则通常是根据子图匹配的必要条件设计的。对于全局过滤,给定一个查询顶点,LDF会收集所有与标签相同且度数不小于的数据顶点作为的候选顶点。对于每一个标签,NLF会检查一个候选顶点关于的邻居数是否不小于的标签为的邻居数。对于传播过滤,过滤规则本质上是相似的,但应用于已经得到的候选顶点集而不再是原始数据图。
过滤规则1(Candidate Existence):对于一个候选顶点集中的候选点,如果存在的邻居,的候选集与的邻居集没有公共元素,那么可以从中过滤掉。
这个规则表明该候选点在匹配过程中无法到达,因此是一个无效的候选点。实际上,RM提出的利用join的Full Reducer过滤就等价于规则1的过滤效力。
过滤规则2(Neighbor Safety):对于一个候选顶点集中的每个候选点,如果存在一个标签,使得关于标签的邻居数目大于在候选空间中关于标签的邻居邻居数,那么可以从中过滤掉。
Neighbor Safety过滤是由VEQ算法提出的。不难看出,其本质上是NLF在传播过滤情况下的扩展。它不再是基于原始数据图进行邻居标签频度过滤,而是在候选空间上进行邻居标签频度过滤。
过滤规则3(Injective Matching):对于一个候选顶点集中的每个候选点,构造一个关于的邻居集和的邻居集的一个二部图。其中,对于和,如果,那么和之间就存在一条边。如果在这个二部图中没有单射匹配,那么可以从中过滤掉。
GraphQL[9]和CaLiG都采用了这种过滤方式,很明显,这种过滤规则的剪枝能力很强。但也不难发现,这比上述两种过滤规则复杂度要高的多,因为需要不断地进行二部图匹配。单射匹配的示例如下:
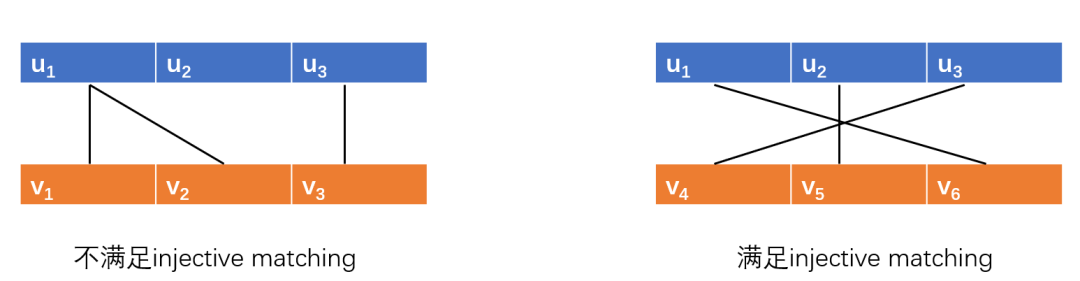
3. 邻域使用率
不同过滤策略对于邻域的使用(即考虑到的邻居)是多种多样的,这是因为不同的子图匹配算法会设计不同的辅助数据结构。例如,CFL[8]和TurboISO[10]只会维护BFS生成树的树边信息,而CECI[11]和DPiso[2]会同时维护树边和非树边信息。当然,也有一些算法为了过滤的效率考虑,它们只会使用前向邻居和后向邻居来进行过滤。
匹配顺序
匹配顺序是一个生成的用来探索搜索空间的查询顶点的排列。匹配顺序的生成方式大致可以分为三类:与数据无关的匹配顺序,依赖于数据的匹配顺序和动态匹配顺序。
与数据无关的匹配顺序
与数据无关的匹配顺序仅利用查询图的信息来生成顺序,例如优先选择度数大的查询顶点。其中如下图所示,RM算法通过核分解为查询图构造了一棵密度树,并从最密集部分到最稀疏部分排列匹配顺序。与数据无关的顺序通常是经验有效的。
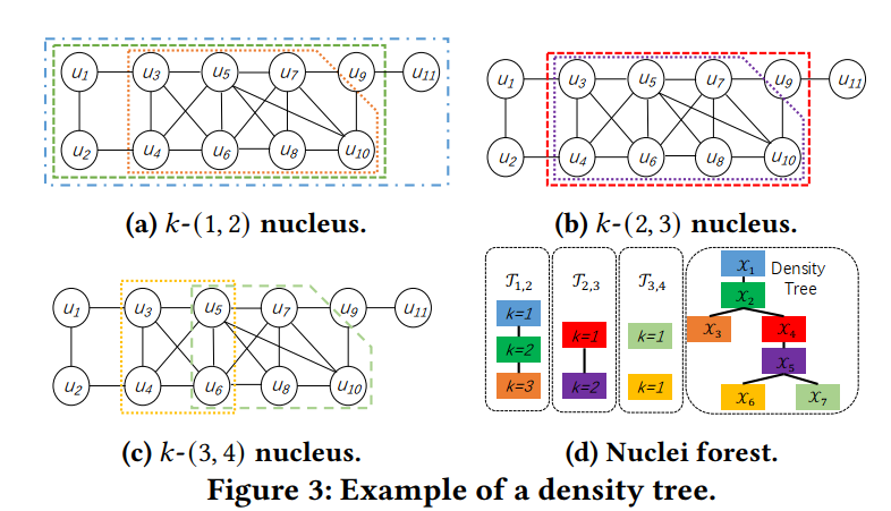
依赖于数据的匹配顺序
依赖于数据的匹配顺序会同时利用查询图和数据图来生成有效的匹配顺序。此时经常会用到基数估计的方法,如GraphQL会迭代地选择最小的查询顶点,CECI会迭代地选择最小的查询顶点。而CFL会对core结构构造BFS生成树,然后枚举所有根到叶子的路径,迭代地选择基数估计最小的路径。
动态匹配顺序
在大型数据图中,单个图中不同区域的顶点标签分布可能是不平衡的。因此,固定的匹配顺序可能是次优的。这就为使用动态的匹配顺序带来了契机。TurboISO将搜索空间划分为候选子区域,候选子区域为以不同的为根的搜索子树。对于每个子区域,TurboISO为其选择性地生成匹配顺序。DPiso则提出了一种自适应的排序方式,可以在回溯过程中动态地调整匹配顺序。VEQ在DPiso的动态顺序的基础上提出了一个新的自适应匹配顺序。由于DPiso遵循CFL分解的叶子分解原则,因此叶子节点的扩展会推迟到匹配顺序最后。但如果叶子节点的匹配失败就可能产生回溯的浪费。因此,VEQ的动态顺序考虑检查一度可扩展顶点的剩余候选点的大小是否小于或等于所需的大小,从而提前检测到失败。
枚举优化
对枚举阶段的优化可以分为两类:枚举时的剪枝和一次枚举多个嵌入。
枚举时的剪枝
枚举时的剪枝操作主要分为两种:一种是记录过去的失败路径,以防止其再次发生;另一种是再次利用先前成功的结果以避免重复地回溯。
DPiso提出了失败集剪枝(Failing Set Pruning)策略,失败分为两种:conflict-class和emptyset-class,前者是同一个数据顶点被分配给多个查询顶点导致的,后者是一个查询顶点的局部候选集为空。DPiso通过BFS构建一个有根的有向无环图(DAG),用于捕获查询顶点之间的依赖关系。然后对于不存在依赖关系的顶点,它映射的顶点如果有一个是失败子树,那么它的兄弟顶点都将可以被剪枝。如下图最左侧的搜索子树所示:
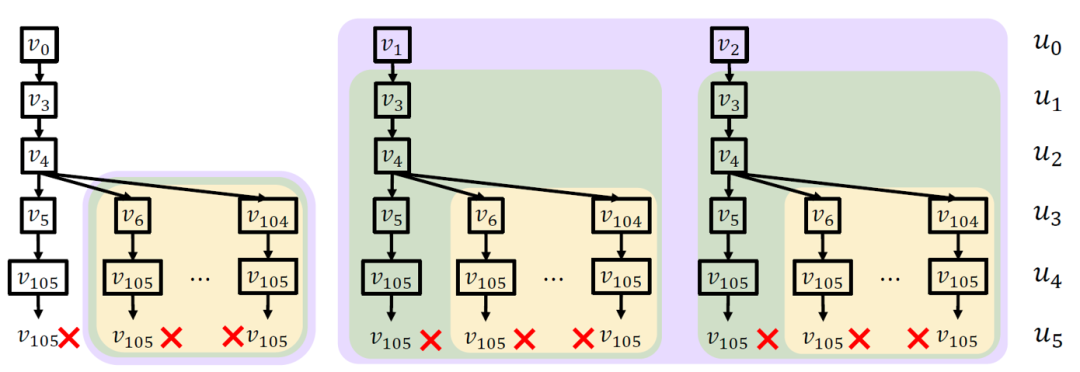
然而,由于DPiso的失败集在完成回跳后被丢弃,因此对于部分嵌入和仍然需要相同的剪枝过程。作为扩展,GuP提出了基于守卫(Guard-based)的剪枝方法,以额外的内存消耗为代价,将已经发现的nogood重新用于多次剪枝。nogood表示一个不会出现在任何结果中的部分嵌入。此外,Gup还提出了Reservation-guard pruning用于提前剪枝由于顶点映射冲突而导致的失败。对于GuP,上图黄色区域都可以被剪枝掉。
上述两种方式都只是对失败路径的剪枝,VEQ利用等价类的思想剪枝等价子树,不仅可以剪枝失败子树,也可以剪枝成功子树。VEQ会在候选集中定义动态等价类,如果中的两个数据顶点和在的所有邻居的候选集中都有公共邻居,那么它们是等价的。对于等价的数据顶点,它们的搜索子树具有相同的扩展过程。
一次枚举多个嵌入
不用等到回溯直到所有的查询顶点分配结束,有方法可以提前终止搜索并且一次产生多个嵌入。
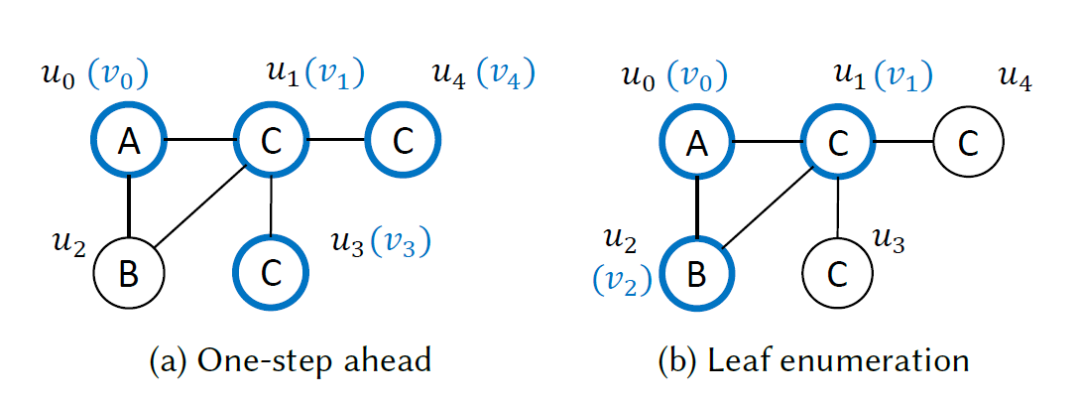
如上图所示,蓝色顶点表示已经匹配结束的顶点。对于One-step ahead方法,我们可以知道最后一个顶点不会再继续扩展下去,因此其得到的结果可以不展开,而是一次性作为多个嵌入一起枚举。对于Leaf enumeration方法,我们知道所有叶子节点都只有一个父节点,因此其得到的扩展结果也可以不继续展开,而是最后以笛卡尔积的方式计算最终的嵌入。
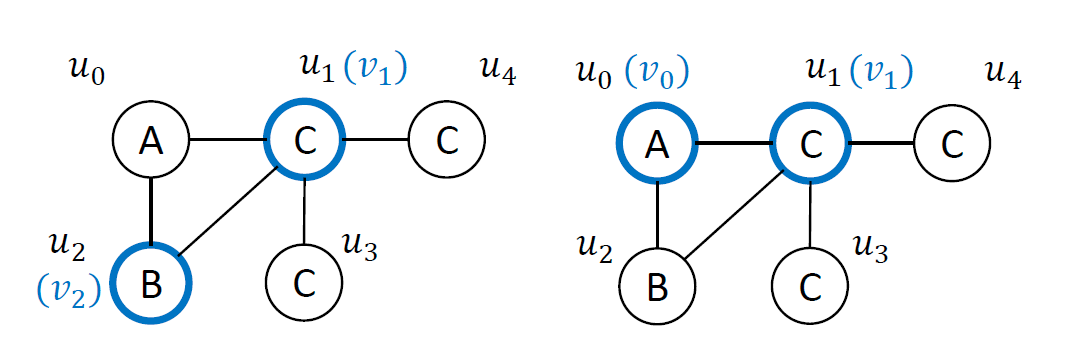
通过上述两种方式,不难发现,本质上当一个顶点不再有前向邻居时,其匹配得到的结果便不再需要继续扩展,因此可以用于一次性产生多个嵌入。基于此,CaLiG提出了Kerenl-and-Shell Search(KSS),Kernel顶点集是查询图的一个连通的顶点覆盖,Shell顶点集则是Kerenl顶点集的互补集,是一个独立集。因此,Shell顶点之间不存在邻接约束,它们可以单独进行匹配。例如,下图描述了两个Kerenl-and-Shell分解,其中蓝色部分是Kerenl集合。
实验评估
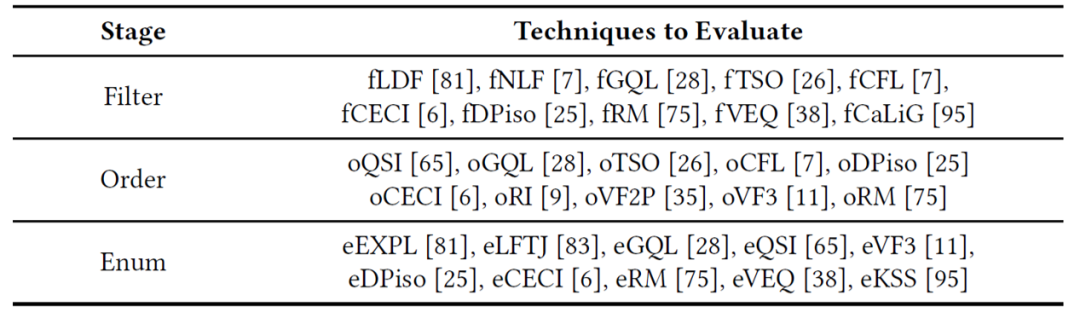
该综述将不同算法的不同优化方法分为了过滤策略、匹配顺序和枚举方法,如下表所示:
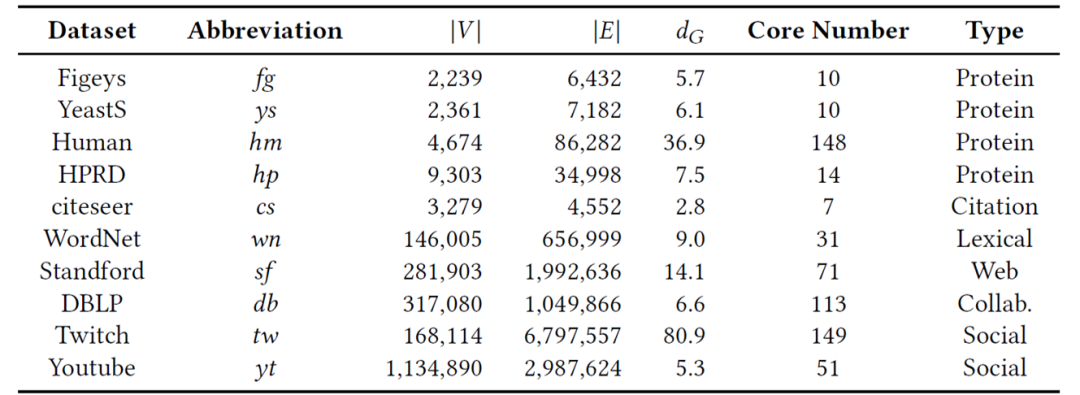
使用的数据集如下:
具体的实验结果图可以参考原文,我们在这里简要对一些实验现象进行了讨论:
对于所有算法的整体性能表现上,CaLiG只能完成3个数据集上的查询,这是因为它的二部图匹配过滤过于耗时。而从全局来看,RM和VEQ算法在大多数的数据图上性能表现最优。其中,VEQ会在等价类比较少的数据集上表现较差。 当增加了边标签之后,VEQ的表现变差了,因为它需要额外的边标签检查来过滤和生成等价类。CaLiG的效果变好了,由于标签约束使得二部图的检查变少了。 对于实际应用中的真实查询,由于查询顶点数目一般都比较少,因此基于连接的RM算法具有最好的性能。 至于过滤策略,除了NLF和LDF表现总体较差之外,其余大部分过滤策略的过滤效果相差不大,这是因为过滤顶点存在边界效应。 而与数据无关的匹配顺序总体效果竟好于依赖于数据的匹配顺序,这大概由于大多数的算法的基数估计其实并不十分准确。
总结
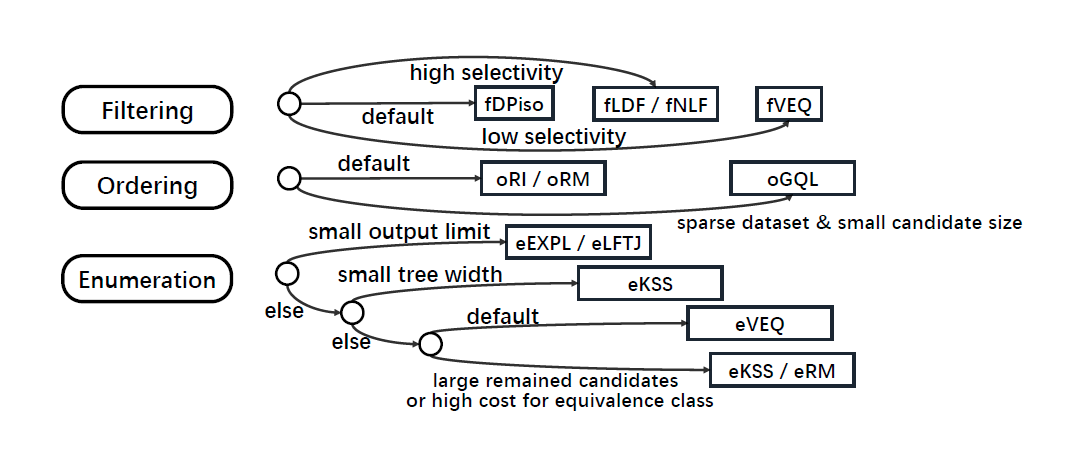
综述总结了近年来的子图匹配算法,通过对它们使用的优化策略的分析和在实际数据集下的实验,展现了不同算法在执行子图匹配任务时的性能表现。可以看出,每个算法的都在某个技术点上具有优势,没有一个算法可以完胜其余算法。最后,文章用下图来推荐不同算法的应用场景:
参考文献


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

